
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC
APPLICATION
Thierry Germa, Michel Devy, Romain Rioux and Fr´ed´eric Lerasle
LAAS-CNRS, Universit´e de Toulouse; 7, Avenue du Colonel Roche, F-31077 Toulouse, France
Universit´e de Toulouse, UPS
Keywords:
Video-based face recognition, SVM, Tracking, Particle filtering.
Abstract:
This paper deals with video-based face recognition and tracking from a camera mounted on a mobile robot
companion. All persons must be logically identified before being authorized to interact with the robot while
continuous tracking is compulsory in order to estimate the position of this person. A first contribution relates
to experiments of still-image-based face recognition methods in order to check which image projection and
classifier associations lead to the highest performance of the face database acquired from our robot. Our
approach, based on Principal Component Analysis (PCA) and Support Vector Machines (SVM) improved by
genetic algorithm optimization of the free-parameters, is found to outperform conventional appearance-based
holistic classifiers (eigenface and Fisherface) which are used as benchmarks.
The integration of face recognition, dedicated to the previously identified person, as intermittent features in the
particle filtering framework is well-suited to this context as it facilitates the fusion of different measurement
sources by positioning the particles according to face classification probabilities in the importance function.
Evaluations on key-sequences acquired by the mobile robot in crowded and continuously changing indoor en-
vironments demonstrate the tracker robustness againstsuch natural settings. The paper closes with a discussion
of possible extensions.
1 INTRODUCTION
The development of autonomous robots acting as hu-
man companions is a motivating challenge and a
considerable number of mature robotic systems have
been implemented which claim to be companions,
servants or assistants in private homes. The dedi-
cated hardware and software of such robot compan-
ions are oriented mainly towards safety, mobility in
human centered environments but also towards peer-
to-peer interaction between the robot companion and
its unengineered human user. The robot’s interlocutor
must be logically identified before being authorized
to interact with the robot while his/her identity must
be verified throughout the performance of any coor-
dinated tasks. Automatic visual person recognition
is therefore crucial to this process as well as person
verification throughout his/her tracking in the video
stream delivered by the onboarded camera. Our par-
ticle filtering-based tracker will bring spatio-temporal
information in order to improve the FR robustness to
populated and cluttered environment.
Visual person recognition from a mobile platform
operating in a human-centered scene is a challenging
task which imposes several requirements. First, on-
board processing power must enable the concurrent
execution of other non-visual functionalities as well
as of decisional routines in the robot’s architecture.
Thus, care must be taken to design efficient vision
algorithms. Contrary to conventional biometric sys-
tems, the embedded visual sensor is moving in unco-
operative human centered settings where people stand
at a few meters - approximately at social and intimate
distances - when interacting with the robot. Because
of this context dependence, we can’t use well-known
public face still images (MIT, CMU, Yale, ... face
databases) for our evaluations.
Given this framework, our face recognition (FR)
system must be capable of handling: (i) poor video
quality and low image resolution which is compu-
tationally faster, (ii) heavier lighting changes, (iii)
larger pose variations in the face images.
The remainder of the paper is organized as fol-
lows. Section 2 depicts the prior related work linked
with our approach. Section 3 describes our still-
face image recognition system in our robotic con-
514
Germa T., Rioux R., Devy M. and Lerasle F. (2009).
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC APPLICATION.
In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications, pages 514-522
DOI: 10.5220/0001800105140522
Copyright
c
SciTePress

text. For enhancing recognition performances, tun-
ing of the classifier free-parameters is here focused.
Section 4 depicts the evaluation of several still face
image recognition systems while Section 5 shows the
improvements brought in the face recognition process
by such a stochastic framework as particle filtering.
Lastly, section 6 summarizes our contributions and
discuss future extensions.
2 PRIOR RELATED WORK
Still-image FR techniques can be classified into two
broad categories : holistic and analytic strategies even
if the two are sometimes combined to form a complete
FR system (Lam and Yan, 98). We focus on the for-
mer as analytic or feature-based approaches are not
really suited to our robotic context. In fact, possi-
ble small face (depending on the H/R distance) and
low image quality of faces captured by the onboard
camera increase the difficulty in extracting local fa-
cial features. On the contrary, holistic or appearance-
based approaches (Belhumeur et al., 1996) consider
the face as a whole and operate directly on pixel in-
tensity array representation of faces without the de-
tection of facial features.
For detecting faces, we apply the well known
window scanning technique introduced in (Viola and
Jones, 2003), which covers a range of ±45
◦
out-of-
plane rotation. The bounding boxes of faces seg-
mented by the Viola’s detector are then fed into the
face recognition systems referred to below.
Since the 1990s, appearance-based methods have
been dominant approaches in still-face image recog-
nition systems. Classically, theyinvolvethree sequen-
tial processes (Figure 1): (1) image pre-processing,
(2) image projection into subspaces to construct lower
dimensional image representation, (3) final decision
rule for classification purposes. (Adini et al., 1997)
points out that there is no image representation that
can be completely invariant to lighting conditions and
image-preprocessing is usually necessary. Like (Jon-
sson et al., 2000; Heseltine et al., 2002), histogram
equalization is here adopted.
Face representation
− PCA
− LDA
Decision rule
− Error norm
− Mahalanobis
− SVM
Pre−processing
− Histogram equalization
− ...
− High−pass filter
Figure 1: Face classification process.
Many popular linear techniques have been used
in the literature for face representation. PCA (prin-
cipal component analysis) uses image projection into
PC (eigenface) to determine basis vectors that capture
maximum image variance (Turk and Pentland, 1991)
while LDA (linear discriminant analysis) determines
a set of optimal discriminant basis vectors so that the
ratio of the between-class and within-class scatters is
maximized (Jonsson et al., 2000).
We design experiments in which faces are repre-
sented in both PC and LD subspaces, and focused
thereafter on the free-parameter tuning of the overall
FR system.
SVMs map the observations from input space into
a higher dimensional feature space using a non-linear
transformation, then find a hyperplane in this space
which maximizes the margin of separation in order to
minimize the risk of misclassification between faces.
A RBF kernel is usually used for this transformation
(Jonsson et al., 2000) where the width free-parameter
γ controls the width of the Gaussian kernel. An-
other important free-parameter to tune is C, the up-
per bound of Lagrangian multipliers required for the
minimization under constraints. Generally, the free-
parameters are determined arbitrarily by trial and er-
ror norm. Genetic algorithms (GA) are well-known
techniques for optimization problems, and have been
proved for being effective for selecting SVM param-
eters (Seo, 2007).
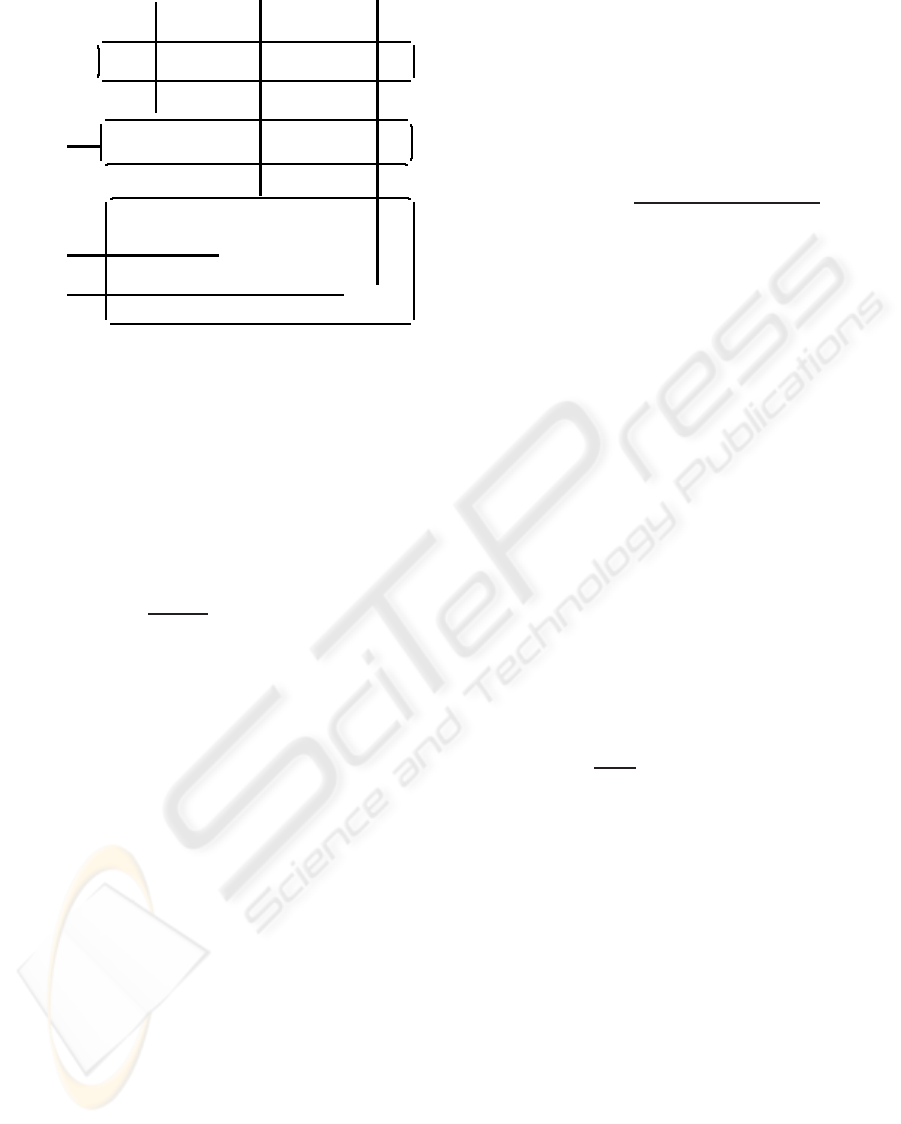
3 OUR APPROACH
From these insights, we propose to focus our de-
velopments on the training process, involving both
face representation and decision rule, but also the
tuning of the parameters defined below. Figure 2
shows recognition process performed for histogram
equalization-based preprocessing, two different rep-
resentations (PC and LD basis) described in subsec-
tion 3.1, and three decision rules (error norm, Maha-
lanobis distance and SVM) depicted in subsection 3.2.
In subsection 3.3, special emphasis concerns the tune
of the free-parameters of each FR system. The face
database is partitioned into four disjoint sets: (1) a
training set #1 (8 users, 30 images per class), (2) a
training set #2 (8 users, 30 images per class), (3) a
training set #3 (8 users, 40 images per class). The
training sets #1 and #2 are respectively used to learn
the users’ face representations and the class charac-
teristics while the training set #3 allows us to estimate
the free-parameters listed below.
Recall that the final goal is to classify facial re-
gions F , segmented from the input image, into either
one class C
t
out of the set {C
l
}
M
l=1
of M subject faces
using training algorithms.
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC APPLICATION
515
?
Training set #1
Decision rule
- Error norm
- Mahalanobis
- SVM
?
Training set #2
Error norm (σ
t
)
Mahalanobis (µ
t
, Σ
t
)
SVM
?
Training set #3
ROC points
GA
-
-
-
η in equation (2)
(C, γ) for SVM
Free-parameters
- Histogram equalization
Pre-processing
Face representation
- PCA
- LDA
Figure 2: Face learning process.
3.1 Face Representation
Eigenface W
pca
basis is deduced by solving
S
T
.W
pca
−W
pca
.Λ = 0, (1)
with S
T
the scatter matrix, and Λ the ordered eigen-
value vector. We keep the first N
v
eigenvectors as the
eigenface basis such that
∑
N
v
i=0
Λ
i
∑
Λ
i
≤ η, (2)
accounting for a predefined ratio η of the total vari-
ance.
Another approach is to use Linear Discriminant
Analysis (known as Fisherspace). Fisherface W
lda
basis is deduced by solving
S
B
.W
lda
− S
W
.W
lda
.Λ = 0,
where S
B
, and S
W
are the between-class, and within-
class scatter matrices while the eigenvectors selection
follows also equation (2).
3.2 Decision Rule
Several methods are proposed to evaluate the deci-
sion rule which best fullfil our goals namely (i) Error
norm, (ii) Mahalanobis distance, (iii) SVM.
The decision rule based on the error norm intro-
duced in (Germa et al., 2007) is described as follow.
Given an unknown test face F = {F (i)}
nm
i=1
and F
r,t
the reconstructed face onto PC basis of the class C
t
,
this error norm is given by
D(C
t
, F ) =
nm
∑
i=1
(F (i) − F
r,t
(i) − µ)
2
,
and the associated likelihood follows
L (C
t
|F ) = N (D (C
t
, F );0, σ
t
),
where F − F
r,t
is the difference image of mean µ, σ
t
terms the standard deviation of the error norms within
the C
t
’s training set, and N (.;m, σ) is the Gaussian
distribution with moments m and covariance σ. This
error norm has been shown to outperform both the
Euclidian distance and the DFFS.
The well-known Mahalanobis distance can be
used in case of global space representation (Global
PCA or LDA). It is defined as follow:
D(C
t
, F ) =
q
(F
t
− µ
t
)
T
Σ
−1
t
(F
t
− µ
t
),
where F
t
is the vector resulting of the projection of F
in W
t
basis, and the class C
t
is represented by µ
t
and
Σ
t
, respectively its mean and covariance.
As described below, our motivation is to use a
SVM as a base for our decision rule. The material
about SVM framework will not be described hereafter
for space reasons (see (Jonsson et al., 2000) for more
details). The SVM method using RBF kernels needs
two parameters to be fully defined. The first parame-
ter is C, linked to the noise in the dataset. We choose
its value as the greatest standard deviation computed
on each class. The second, γ, is computed by heuristic
methods from a set of tests on database called cross-
validation.
The last issue concerns the appropriate decision
rule. From a set of M learnt subjects/classes noted
{C
l
}
M
l=1
and a detected face F , we can define for each
class C
t
the likelihood L
t
= L (C
t
|F ) for the de-
tected face F and the posterior probability P(C
t
|F , z)
of labeling to C
t
as
∀t P(C
t
|F , z) = 0 and P(C
/
0
|F , z) = 1 when ∀t L
t
< τ
∀t P(C
t
|F , z) =
L
t
∑
p
L
p
and P(C
/
0
|F , z) = 0 otherwise ,
(3)
where C
/
0
refers to the void class, and τ is a predefined
threshold for each class C
t
.
3.3 Free Parameters Optimization
Several free parameters have to be tuned in order to
optimze the FR process i.e. PC threshold η, SVM
parameters C and γ and decision rule threshold τ.
The performances of the classifiers are analyzed
by means of ROC when varying the free-parameter
vector q subject to optimization for each classifier.
The idea, pioneered by Provost et al. in (Provost and
Fawcett, 2001), is outlined as follows. We search
over a set of free-parameters by computing a ROC
point i.e. the false rejection and false acceptance rates,
namely FRR and FAR. For a given classifier, the set
Q of all admissible parameter vectors q generates a
set of ROC points, of which we seek the dominant,
or optimal Pareto points along the ROC convex hull.
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
516
More formally, we seek for the subset Q
∗
1:n
⊂ Q
1:n
of parameter vectors q
1:n
= ((γ
1
,C
1
), . . . , (γ
n
,C
n
)) for
which there is no other parameter vector that outper-
forms both objectives in O = {FRR, FAR}:
Q
∗
= {q ∈ Q |∀ q
′
∈ Q ,
∀ f
1
∈ O , f
1
(q) ≥ f
1
(q
′
)∧ ∃ f
2
∈ O , f
2
(q) > f
2
(q
′
)}
(4)
Clearly, Q
∗
identifies the subset of parameter vectors
that are potentially optimal for a given classifier.
Traditional methods using Genetic Algorithms are
single-objective optimization problems (Seo, 2007).
Non dominated sorting GA (NSGA-II) has been
proved to be suited to multi-objective optimization
problem (Xu and Li, 2006) as no solution can achieve
a global optimum for several objectives, namely min-
imizing both the FRR and the FAR. If the value of
first objective function cannot be improved without
degrading the second objective function, the solu-
tion is referred to Pareto-optimal or non dominated
ones (Gavrila and Munder, 2007). Algorithm 1 de-
scribes the steps of the process used for our free-
parameters optimization. This algorithm is iterated on
the overall FR process so as to find the best parame-
ters for the complete system. This approach allows us
to find the best compromise between FAR and FRR
by finding the Pareto front
F
i
= { f(q) ∈ O |q ∈ Q
∗
}
with Q
∗
the Pareto optimal set.
4 EVALUATIONS AND RESULTS
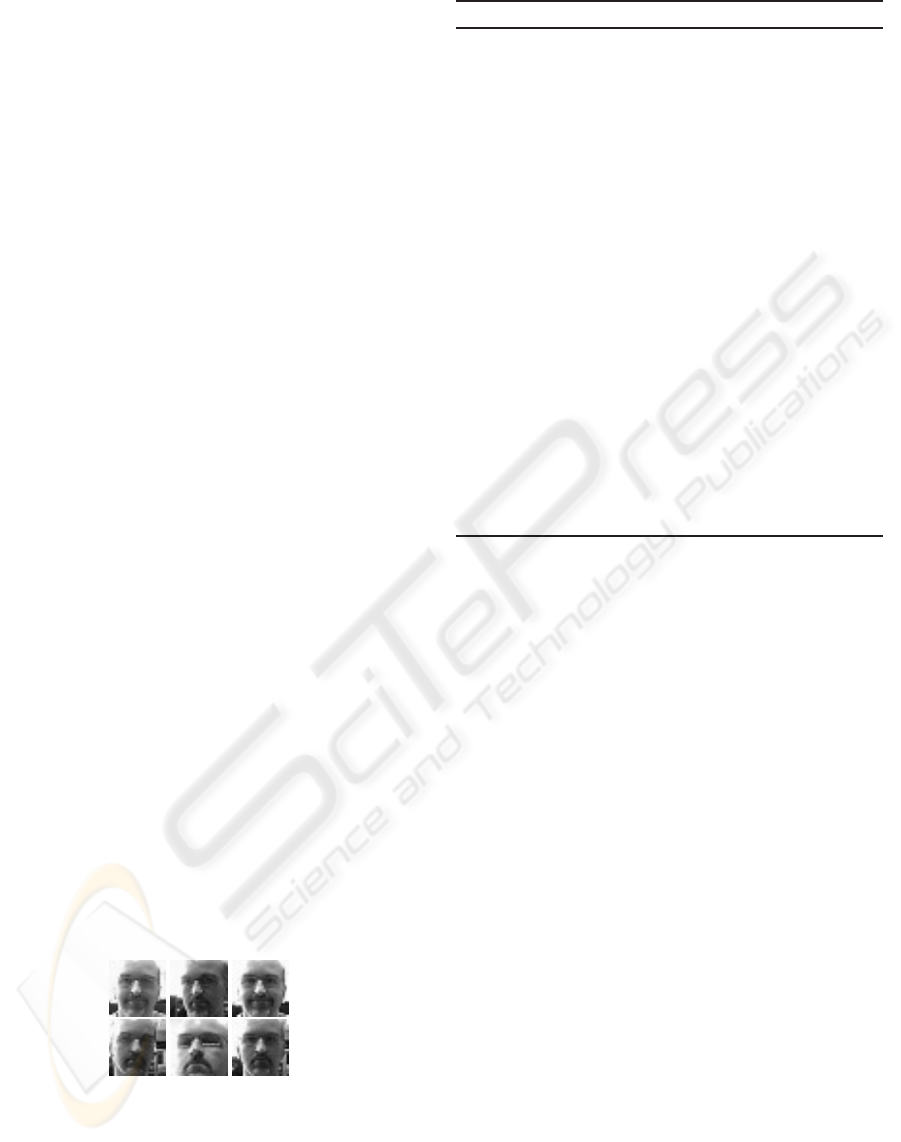
We conducted FR experiments using the proposed
framework on the face dataset composed of 5500 test
examples including 8 possible human users and 3 im-
postors corresponding to unknown individuals for the
robot. In this dataset, the subjects arbitrarily move
Figure 3: Samples for a given class.
their heads, possibly change their expressions while
the ambient lighting, the background, and the relative
distance might change. A few example images from
this dataset are shown in figure 3 while the entire face
gallery is available on demand.
Algorithm 1 NSGA-II algorithm.
1: Create a random parent population P
0
of size N.
Set t = 0.
2: Apply crossover and mutation to P
t
to create off-
spring population Q
t
of size N.
3: if Equation (4) is not satisfied then
4: Set R
t
= P
t
∪ Q
t
.
5: Identify the non-dominated fronts F
1
, F
2
, . . . , F
k
in R
t
.
6: for i = 1, . . . , k do
7: Calculate crowding distance of the solutions
in F
i
. Sort by crowding.
8: if |P
t+1
| + |F
i
| > N then
9: Add the least crowded N − |P
t+1
| solu-
tions from F
i
to P
t+1
.
10: else
11: Set P
t+1
= P
t+1
∪ F
i
.
12: end if
13: end for
14: Use binary tournament selection based on the
crowding distance to select parents from P
t+1
.
15: Set t = t + 1. Go to step (2).
16: end if
4.1 Evaluated Recognition Systems
1. System FSS+EN: Face-Specific Subspace and
Error Norm. As described in (Shan et al., 2003),
for each class C
t
, we compute W
pca,t
thanks to equa-
tion (1), and keep the N
v,t
eigenvectors (equation (2)).
We use the predefined error norm as the decision rule.
2. System GPCA+MD: Global PCA and Ma-
hanalobis Distance. Here a single PC basis is esti-
mated given equation (1) and the total scatter matrix
S
T
. The decision rule is based on the Mahanalobis
distance.
3. System LDA+MD: Fisherface and Mahanalobis
Distance. Fisherfaces are used thanks to equation (1)
so as to get W
lda
as the projection basis to compute
Mahalanobis distance.
4. System GPCA+SVM: Global PCA and SVM.
This system performs global PCA and SVM deliv-
ers probability estimates. The associated theory and
implementation details are described in (Wu et al.,
2004). This classifier model produces the free-
parameters η, C, γ and τ.
4.2 Results
All the above classifiers lead to the same perfor-
mances in terms of sensitivity (∼ 75%) and selectivity
(∼ 90%). These results are very promising given the
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC APPLICATION
517
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
True Positive Rate
(a) System 1, q = (η, τ)
′
:
EER=0.51.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
True Positive Rate
(b) System 2, q = (η, τ)
′
:
EER=0.44.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positive Rate
True Positive Rate
(c) System 3, q = (η, τ)
′
:
EER=0.37.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
False Positive Rate
True Positive Rate
(d) System 4,
q = (η,C, γ, τ)
′
: EER=0.29.
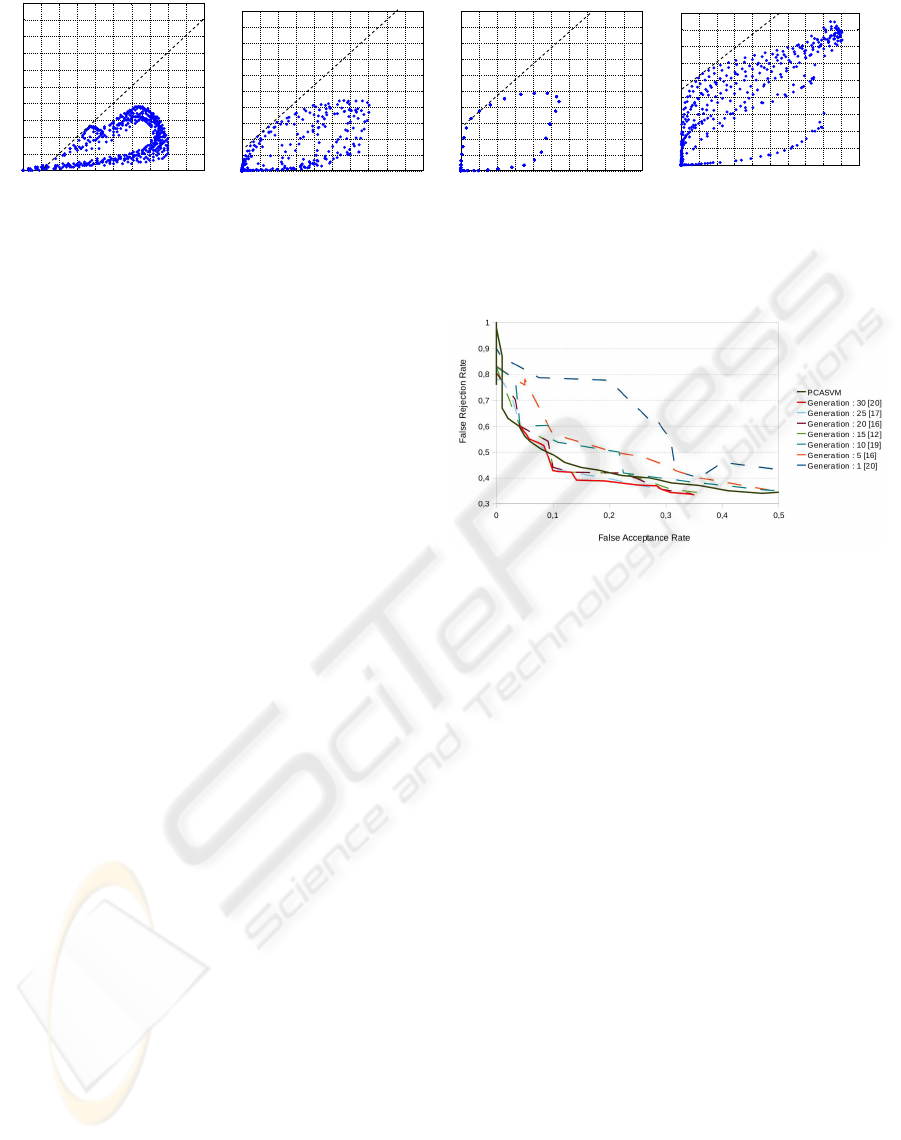
Figure 4: ROC points for each classifier and the associated isocost line for EER. Free-parameter vector q for optimization are
listed under the corresponding classifier.
extent of pose, varying illumination, expression, and
distance to individuals. On the contrary, significant
differences between the face recognition systems are
observed for FAR (misclassification) and FRR (mis-
rejection). This is highlighted in the ROC analysis
(figure 4) which shows the results of the different FR
systems in terms of FAR and FRR when varying the
corresponding free-parameters.
Figure 4 shows ROC points and the Pareto front
when varying the free-parameters over their ranges.
The subfigures, when plotting TPR and FPR on the
Y- and X-axis, allows an informal visual comparison
of the four classifiers. System 4 clearly dominates the
other classifiers as its Pareto front lies in the nortwest
corner of the ROC space (TPR is higher, FPR is
lower). Considering the equal error rate (EER) leads
to the same analysis. The best system, namely 4, pro-
vides a Pareto front with a lower EER, namely 0.29.
Finally, note that its computational cost is 0.5 ms
against 0.3 ms per image for systems 2-3. Unfortu-
nately, an exhaustive search for the selection of all
parameters, especially for model 4 which produces
more free-parameters, is computationally intractable
on a autonomous robot as the finality is to learn hu-
man faces on-the-fly when interacting with new per-
sons. Consequently, we propose a genetic algorithm
(GA) to discover optimal free-parameter vectors of
system 4 more quickly due to its multi-objective opti-
mization framework. By limiting the number of ROC
points to be considered, GA renders the optimization
procedure computationally feasible.
Figure 5 shows the evolution of the Pareto front
when varying the population size in the range [16, 20]
and the preset generation count in the range [1, 30].
Note that the generated solutions “move” so as
to reduce both FPR and FRR objectives. This opti-
mization strategy is no longer guaranteed to find the
Pareto front optimum but there is an experimental ev-
idence that the solution is close to optimal when in-
creasing the preset generation count. Given a popula-
Figure 5: NSGA-II Pareto front evolution vs. PCA+SVM
based system D.
tion initialized randomly (first generation in figure 5),
we can see that after the first 10 generations, there is
already one solution that outperforms the one without
optimization while 30 generationsincrease the perfor-
mance compared to ROC means slightly. Therefore,
the minimum EER for 30 generations becomes 0.26
against 0.29 in subfigure 4(d).
5 FACE TRACKING AND
ROBOTIC EXPERIMENTS
Spatiotemporal FR analysis is here considered even if
FR and tracking process are split : the person-specific
estimated dynamic characteristics helped the FR sys-
tem and reciprocally. Solving these two tasks simulta-
neously by probabilistic reasoning (Zhou et al., 2004)
has been proven to significantly enhance the recogni-
tion performances.
5.1 Tracking Framework based on Face
Recognition
Particle filters (PF) aim to recursively approximatethe
posterior probability density function (pdf) p(x
k
|z
1:k
)
of the state vector x
k
at time k conditioned on the set
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
518

of measurements z
1:k
= z
1
, . . . , z
k
. A linear point-mass
combination
p(x
k
|z
1:k
) ≈
N
∑
i=1
w
(i)
k
δ(x
k
− x
(i)
k
),
N
∑
i=1
w
(i)
k
= 1, (5)
is determined – with δ(.) the Dirac distribution–
which expresses the selection of a value – or “par-
ticle” – x
(i)
k
with probability – or “weight”– w
(i)
k
,
i = 1, . . . , N. An approximation of the conditional ex-
pectation of any function of x
k
, such as the MMSE
estimate E
p(x
k
|z
1:k
)
[x
k
], then follows.
Recall that the SIR – or “Sampling Importance
Resampling” – algorithm is fully described by the
prior p
0
(x
0
), the dynamics pdf p(x
k
|x
k−1
) and the
observation pdf p(z
k
|x
k
). After initialization of inde-
pendent identically distributed (i.i.d.) sequence drawn
from p
0
(x), the particles evolve stochastically, being
sampled from an importance function q(x
k
|x
(i)
k−1
, z
k
).
They are then suitably weighted so as to guarantee the
consistency of the approximation (5). Then a weight
w
(i)
k
is affected to each particle x
(i)
k
involving its like-
lihood p(z
k
|x
(i)
k
) w.r.t. the measurement z
k
as well as
the values of the dynamics pdf and importance func-
tion at x
(i)
k
. In order to limit the well-known degen-
eracy phenomenon (Arulampalam et al., 2002), a re-
sampling stage is introduced so that the particles as-
sociated with high weights are duplicated while the
others collapse and the resulting sequence {x
(i)
k
}
N
i=1
is
i.i.d. according to (5).
With respect to our data fusion context, we opt for
using ICONDENSATION (Isard and Blake, 1998),
that consists in sampling some particles from the ob-
servation image (namely π(.)), some from the dynam-
ics and some w.r.t. the prior p
0
(.) so that importance
function reads as, with α, β ∈ [0;1]
q(x
(i)
k
|x
(i)
k−1
, z
k
) =
απ(x
(i)
k
|z
k
) + βp(x
k
|x
(i)
k−1
) + (1− α − β)p
0
(x
k
). (6)
where π(.) relates to detector outputs which, despite
their intermittent nature, are proved to be very dis-
criminant when present (P´erez et al., 2004).
5.1.1 Tracking Implementation
The aim is to fit the template relative to the targeted
person all along the video stream through the es-
timation of his/her image coordinates (u, v) and its
scale factor s of his/her head. All these parameters
are accounted for in the above state vector x
k
re-
lated to the k-th frame. With regard to the dynam-
ics p(x
k
|x
k−1
), the image motions of humans are dif-
ficult to characterize over time. This weak knowl-
edge is formalized by defining the state vector as x
k
=
[u
k
, v
k
, s
k
]
′
and assuming that its entries evolve ac-
cording to mutually independent random walk mod-
els, viz. p(x
k
|x
k−1
) = N (x
k
;x
k−1
, Σ) where covari-
ance Σ = diag(σ
2
x
, σ
2
y
, σ
2
s
).
In both importance sampling and weight update
steps, fusing multiple cues enables the tracker to bet-
ter benefit from distinct information, and decrease its
sensitivity to temporary failures in some of the mea-
surement processes. The underlying unified likeli-
hood in the weighting stage is more or less conven-
tional. It is computed by means of several measure-
ment functions introduced in (Germa et al., 2007),
according to persistent visual cues, namely: (i) mul-
tiple color distributions to represent the person’s ap-
pearance (both head and torso), (ii) edges to model
the silhouette. Otherwise, our importance function is
unique in the literature and so is detailed here below.
5.1.2 Importance Function based on Face
Recognition
Recall that the function π(.) in equation (6) offers a
mathematically principled way of directing search ac-
cording to multiple and possibly heterogeneous de-
tectors and so to (re)-initialize the tracker. Given L
independent detectors and κ their weights, the func-
tion π(.) can be reformulated as
π(x
k
|z
1
k
, . . . , z
L
k
) =
L
∑
l=1
κ
l
.π(x
k
|z
l
k
), with
∑
κ
l
= 1.
(7)
Two functions π(x
k
|z
c
k
) and π(x
k
|z
s
k
), respectively
based on skin probability image (Lee et al., 2003) and
face detector are here considered.
The importance function π(x
k
|z
c
k
) at location x
k
=
(u, v) is described by
π(x|z
c
) = h(c
z
(x)) (8)
given that c
z
(x) is the color of the pixel situated in x in
the input image z
c
and h is the normalized histogram
representing the color distribution of the skin learnt a
priori. The function π(x
k
|z
s
k
) is based on a probabilis-
tic image based on the well-known face detector pio-
neered in (Viola and Jones, 2003). Let N
B
be the num-
ber of detected faces and p
i
= (u
i
, v
i
), i = 1, . . . , N
B
the
centroid coordinate of each such region. The function
π(.) at location x = (u, v) follows, as the Gaussian
mixture proposal
1
π(x|z
s
) ∝
N
B
∑
j=1
P(C|F
j
, z
s
).N (x;p
j
, diag(σ
2
u
j
, σ
2
v
j
)),
(9)
1
Index k and (i) are omitted for the sake of clarity and
space.
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC APPLICATION
519

Data fusion strategy t = 15 t = 81 t = 126 t = 284
q(x
k
|x
k−1
, z
k
) = απ(.) + βp(.)
(a) with face detection
q(x
k
|x
k−1
, z
k
) = απ(.) + βp(.)
(b) with face classification
Table 1: Different data fusion strategies involved in importance sampling.
Figure 6: From left to right: original image, skin probability image (8), face recognition (9), unified importance function (6)
(without dynamic), accepted particles (yellow dots) after rejection sampling.
with P(C|F
j
, z) the face ID probabilities described in
equation (3) for each detected face F
j
.
The particle sampling is done using the impor-
tance function q(.) in equation (6) and a process of
rejection sampling. This process constitutes an alter-
native when q(.) is not analytically described. The
principle is as follows with Mg(.) an envelope distri-
bution to make the sampling easier (M > 1):
Algorithm 2 Rejection sampling algorithm.
1: Draw x
(i)
k
according to Mg(x
k
)
2: r ←
q(x
k
|x
k−1
,z
k
)
Mg(x
(i)
k
)
3: Draw u according to U
[0,1]
4: if u ≤ r then
5: Accept x
(i)
k
6: else
7: Reject it
8: end if
Figure 6 shows an illustration of the rejection sam-
pling algorithm for a given image. Our importance
function (6) combined with rejection sampling en-
sures that the particles will be (re)-placed in the rele-
vant areas of the state space i.e. concentrated on the
tracked person.
5.2 Live Experiments
The above tracker has been prototyped on a 1.8GHz
Pentium Dual Core using Linux and the OpenCV li-
brary. Both quantitative and qualitative off-line eval-
uations on sequences are reported here below. This
database of two different sequences (800 images) ac-
quired from our mobile robot in a wide range of re-
alistic conditions allows us to: (i) determine the op-
timal parameter values of the tracker, (ii) identify its
strengths and weaknesses, and in particular character-
ize its robustness to environmental artifacts: clutter,
occlusion or out-field of sight, lighting changes. Sev-
eral filter runs per sequence are performed and ana-
lyzed.
The runs presented in Table 1 show the efficiency of
the strategy of data fusion in both importance and
measurement function. Let us comment these results.
The template corresponding to the estimate of the po-
sition of the target is represented by the blue rect-
angles (color template) and the green curve (shape
template) while the dots materialize the hypotheses
and their weight after normalization (black is 0 and
red is 1). The run (a) in Table 1 combines face and
skin color detection with the random walk dynamic in
the importance function in order to guide the particle
sampling on specific additional areas of the current
image (mainly on detected faces). We can see that
this strategy is not sufficient to distinguish whether
the template is on the right targeted person or not.
The last run in Table 1(b) shows the complete system
used in our experiments involving the face classifica-
tion process in the importance function as described
in (9). We can see, at time t = 81, that after a spo-
radic occlusion of the target by another person (with
the black trousers), the face classification helps to di-
rect the particle sampling only on the desired person
and so enables the template to recover the target.
Quantitative performance evaluations summarized
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
520

below havebeen carried out on the sequence database.
Table 2 consider the FR performance with or without
tracking and presents the classification results. For
each sequence, these results are compared to tracking
results in terms of FAR (False Acceptance Rate) and
FRR (False Rejection Rate). To be more consistent,
the only images involving face detection have been
taken into account. We note that the runs involving
tracking are more robust to environmental changes,
mainly due to spatio-temporal effects.
Table 2: Face classification performance for the database
image subset involving detected frontal faces.
Face classif. without tracking with tracking
FAR 35.09% 26.47% (σ = 1.97%)
FRR 60.22% 25.73% (σ = 0.25%)
6 CONCLUSIONS AND
PERSPECTIVES
This paper presented the development of a still-image
FR system dedicated to Human/Robot interaction in
a household framework. The main contribution is the
improvement of the known FR algorithms thanks to a
genetic algorithm for free-parameter optimization.
Off-line evaluations on sequences acquired from
the robot show that the overall system enjoys the valu-
able capabilities: (1) efficiency of the recognition pro-
cess against face pose changing, (2) robustness to il-
lumination changes. Eigenface subspace and SVM
makes it possible to avoid misclassification due to the
environment while NSGA-II improves the FR pro-
cess. Moreover, the fusion of FR outputs in the track-
ing loop enables the overall system to be more robust
to natural and populated settings.
Several directions are studied regarding our still-
image FR system. A first line of investigation con-
cerns the fusion of heterogeneous information such
as RFID or sound cues in order to keep the identifi-
cation process more robust to the environment. De-
tection of an RFID tag worn by individuals will allow
us to drive the camera thanks to a pan-tilt unit and
so trigger tracker initialization, and will contribute as
another measurement in the tracking loop. The sound
cue will endow the tracker with the ability to switch
its focus between known speakers.
REFERENCES
Adini, Y., Moses, Y., and Ullman, S. (1997). Face recog-
nition: the problem of compensating for changes in
illumination direction. 19(7):721–732.
Arulampalam, S., Maskell, S., Gordon, N., and Clapp, T.
(2002). A tutorial on particle filters for on-line non-
linear/non-gaussian bayesian tracking. Trans. on Sig-
nal Processing, 2(50):174–188.
Belhumeur, P., Hespanha, J., and Kriegman, D. (1996).
Eigenfaces vs. fisherfaces. In European Conf. on
Computer Vision (ECCV’96), pages 45–58.
Gavrila, D. and Munder, S. (2007). Multi-cue pedestrian
detection and tracking from a moving vehicle. Int.
Journal of Computer Vision (IJCV’07), 73(1):41–59.
Germa, T., Br`ethes, L., Lerasle, F., and Simon, T. (2007).
Data fusion and eigenface based tracking dedicated to
a tour-guide robot. In Int. Conf. on Vision Systems
(ICVS’07), Bielefeld, Germany.
Heseltine, T., Pears, N., and Austin, J. (2002). Evaluation of
image pre-processing techniques for eigenface based
recognition. In SPIE: Image and Graphics, pages
677–685.
Isard, M. and Blake, A. (1998). I-CONDENSATION: Uni-
fying low-level and high-level tracking in a stochastic
framework. In European Conf. on Computer Vision
(ECCV’98), pages 893–908.
Jonsson, K., Matas, J., Kittler, J., and Li, Y. (2000). Learn-
ing support vectors for face verification and recogni-
tion. In Int. Conf. on Face and Gesture Recognition
(FGR’00), pages 208–213, Grenoble, France.
Lam, K. and Yan, H. (98). An analytic-to-holistic approach
fo face recognition based on a single frontal view.
7(20):673–686.
Lee, K., Ho, J., Yang, M., and Kriegman, D. (2003). Video-
based face recognition using probabilistic appearance
manifolds. Computer Vision and Pattern Recogni-
tion, 2003. Proceedings. 2003 IEEE Computer Society
Conference on, 1:I–313–I–320 vol.1.
P´erez, P., Vermaak, J., and Blake, A. (2004). Data fusion for
visual tracking with particles. Proc. IEEE, 92(3):495–
513.
Provost, F. and Fawcett, T. (2001). Robust classifica-
tion for imprecise environments. Machine Learning,
42(3):203–231.
Seo, K. (2007). A GA-based feature subset selection and
parameter optimization of SVM for content-based im-
age retrieval. In Int. Conf. on Advanced Data Min-
ing and Applications (ADMA’07), pages 594–604,
Harbin, China.
Shan, S., Gao, W., and Zhao, D. (2003). Face recognition
based on face-specific subspace. Int. Journal of Imag-
ing Systems and Technology, 13(1):23–32.
Turk, M. and Pentland, A. (1991). Face recognition using
eigenfaces. In Int. Conf. on Computer Vision and Pat-
tern Recognition (CVPR’91), pages 586–591.
Viola, P. and Jones, M. (2003). Fast multi-view face de-
tection. In Int. Conf. on Computer Vision and Pattern
Recognition (CVPR’03).
Wu, T., Lin, C., and Weng, R. (2004). Probability esti-
mates for multi-class classification by pairwise cou-
pling. Journal of Machine Learning Research, 5:975–
1005.
A TUNING STRATEGY FOR FACE RECOGNITION IN ROBOTIC APPLICATION
521

Xu, L. and Li, C. (2006). Multi-objective parameters selec-
tion for SVM classification using NSGA-II. In Indus-
trial Conference on Data Mining (ICDM’06), pages
365–376.
Zhou, S., Chellappa, R., and Moghaddam, B. (2004). Visual
tracking and recognition using appearance-adaptive
models in particle filters. Trans. on Image Process-
ing, 13(11):1491–1506.
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
522
