
A CONCEPTUAL MODEL FOR DIGITAL LIBRARIES EVOLUTION
Andrea Baruzzo, Paolo Casoto, Antonina Dattolo and Carlo Tasso
Dept. of Computer Science, University of Udine, Via delle Scienze 206, Udine, Italy
Keywords:
Digital libraries, Metadata, Service-oriented architecture, Multi-agent systems, Schema evolution.
Abstract:
The evolution and preservation of digital libraries are not simply a matter of technological decisions, but
they can be better understood if treated as the integration of three complementary dimensions (based on the
informational, technological and social domains). These dimensions together form a conceptual framework
suitable to characterize the whole digital library concept.
In this paper, starting from the experience and the lessons learned in the realization of the EU-India E-Dvara
project, we propose such framework, providing motivational examples and discussing opportune solutions.
More in particular, we discuss the issues concerned the technical infrastructure adaptation, the coordination
of different user roles, and the data evolution in order to select the dimensions along which we base our
framework.
1 INTRODUCTION
Many works coming from both the academia and the
industry seem to suggest that preservation and evolu-
tion of digital libraries are firstly a matter of techno-
logical issues (Barkstrom et al., 2002). We recognize
the need of data storage infrastructures, knowledge
management systems (metadata and search mecha-
nisms) or data transport and security facilities. How-
ever, the technology should be viewed ”simply” as a
means to provide the services typically built around
a digital archive. We recognize a deeper meaning in
the evolution phenomena of digital libraries, taking
into account also social aspects such as the diverse
range of actor roles involved in the content produc-
tion and exploitation processes. Thus, we contrast
the “technology-centered” vision, characterizing the
evolution of both the digital content and the services
built upon it as the integration of three complemen-
tary dimensions (social, technological and informa-
tional). Such dimension form together a conceptual
framework suitable to better formalize the digital li-
brary concept and its evolution issues over the time.
This paper is based on a three-years experimen-
tation with the EU-India E-Dvara project
1
: a digi-
tal platform devoted to e-content management in In-
dian heritage and sciences (Challapalli et al., 2006;
Baruzzo and Casoto, 2008; Baruzzo et al., 2008).
1
http://edvara.uniud.it/india
The main contribution of this work is the charac-
terization of a digital library according to its evolution
aspects; in particular, we:
1) introduce a conceptual framework to handle the
evolution of digital archives along multiple dimen-
sions (Section 3);
2) provide representative examples concerning evolu-
tion issues, weaknesses, and mistakes emerged during
the evaluation of our current E-Dvara prototype (Sec-
tion 3.1 - Section 3.3);
3) propose a new, distributed approach to handle evo-
lution open problems (Section 4).
2 RELATED WORKS
In the last few years, several research projects have
been proposed in order to cope with data preservation
and organization (Bekaert et al., 2005; Lutzenkirchen,
2002; Candela and Pagano, 2007). For example, the
storage of XML-based document, one of the core ar-
chitectural properties of E-Dvara, has been previously
proposed in Greenstone (Bainbridge et al., 2001; Wit-
ten et al., 2000), a digital library designed to provide
librarians with the ability to create and publish het-
erogeneous collections of digital contents on the Web
like text, images, videos and e-books. Each content
in Greenstone can be described using metadata, ei-
ther imported from standard schemas (e.g. Dublin
299
Baruzzo A., Casoto P., Dattolo A. and Tasso C.
A CONCEPTUAL MODEL FOR DIGITAL LIBRARIES EVOLUTION.
DOI: 10.5220/0001835802990304
In Proceedings of the Fifth International Conference on Web Information Systems and Technologies (WEBIST 2009), page
ISBN: 978-989-8111-81-4
Copyright
c
2009 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
Core
2
) or manually provided by librarians. However,
Greenstone does not provide any policy or roles for
the management of the content submission process.
Moreover, it does not provide functionalities concern-
ing the evolution management of both contents and
collection templates.
D-Space (Tansley et al., 2003) is an author-
oriented distributed digital library aimed at providing
long-term preservation of heterogeneous contents, by
improving some of the limitations affecting Green-
stone. It provides long-term preservation facilities,
by assigning a persistent identifier to each submit-
ted resource and supporting software and hardware
methodologies for data backup and content version-
ing. D-Space introduces also a multi-roles approach
to content publishing, identifying the following ac-
tors: (1) authors and organizations, providing the con-
tents, (2) librarians, performing content validation,
and (3) users, interested in content retrieval. Content-
based workflows can be customized in order to cope
with the needs of specific organizations. Part of the
policies defined in D-Space have been introduced also
in E-Dvara to structure content and to delegate proper
activities to different stakeholders.
Service-oriented architecture and data interoper-
ability issues in digital libraries have been explored
also by the Fedora Project (Lagoze et al., 2005), a
distributed architecture for contents publishing, ag-
gregation and retrieval. Composite information is
obtained by means of aggregation of physical con-
tents, viewed as bit-streams, located worldwide into
the Fedora repositories. Preservation of each con-
tent is achieved by means of a naming service, which
can be used to access the selected content. In addi-
tion to composition, Fedora provides users with the
ability to define new contents by applying to exist-
ing physical objects custom components called dis-
seminators (e.g.: a thumbnails generator applied to
high-resolution pictures or videos). Both Fedora and
E-Dvara allow content editors and archivists to de-
fine semantic connections between archived contents.
In Fedora, however, connections are defined between
two contents treated as set of physical contents. E-
Dvara, vice versa, allows content writers to define
relations implementing a specific template which en-
hances a closer semantic validation of the content.
The above mentioned systems are centred on con-
tents, defined as binary resources enriched by meta-
data devoted to preservation, storage and retrieval pur-
poses, but not intended for data structuring, as we
do in E-Dvara. Thus, preservation and evolution of
a data model is implemented as a low-level mecha-
nism, where data is processed as bit-streams instead
2
See for more details: http://dublincore.org/
of as instances of well-defined structures (i.e. XML
Schema). In E-Dvara we provide preservation fa-
cilities, managing both physical and logical evolu-
tion of the stored data. More specifically, E-Dvara
is conceived to explicitly deal with evolution of a data
model by means of preserving information integrity.
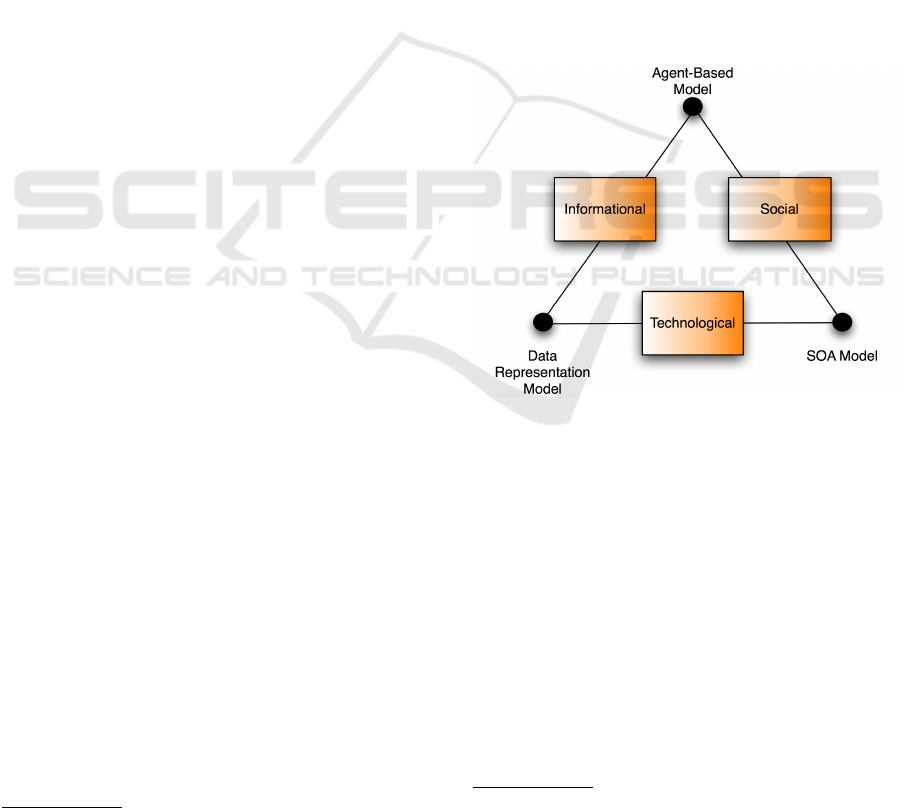
3 CONCEPTUAL FRAMEWORK
AND EVOLUTION ISSUES
Our conceptual framework is based on the topol-
ogy provided by Yates (Yates, 1989)
3
, by incorporat-
ing the vocabulary suggested by Rowlands-Bawden
(Rowlands and Bawden, 1999). The evolution of each
concept (point) in the topology is described by con-
sidering the different directions from which it can be
reached. The result, illustrated in Figure 1, highlights
three specific domains:
Figure 1: The evolution conceptual model.
1. the Informational domain, which describes
knowledge organization and description (e.g.
metadata).
2. the Technological domain, which describes
knowledge organization and discovery (e.g. soft-
ware agents), technical impacts on the infor-
mation transfer chain, technology factors (e.g.
human-computer interaction).
3. the Social domain, which describes human and or-
ganizational factors, information laws and poli-
cies, social impacts on the information transfer
chain, and library management concerns.
3
In the original Yates’ model, these domains were called
documents, technology, and work, respectively.
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
300
The open issues faced during our experimentation
with E-Dvara may be classified along three evolution
dimensions:
1. Informational-Technological dimension, which
identifies all data evolution problems due to
changes in the underlying data model (data
schema);
2. Technological-Social dimension, which identifies
problems concerning the need to adapt the tech-
nical infrastructure of a digital library in order to
fulfil new user requirements.
3. Social-Informational dimension, which concerns
the different conceptual models needed to support
the work of such different community of users,
and their impact on the documents, by providing
support to roles and workflows.
3.1 The Data Evolution Problem
The first prototype of E-Dvara provides users with a
flexible way to define and update the metadata associ-
ated to each project representing a digital archive. In
particular, users can define a set of schemata which
supplies the structure adopted for storing documents.
Each schema is expressed in terms of fields, data
types and constraints. Metadata definition and update
can take place every time during the digital collection
life-cycle, leading to the problem of correctly handle
the evolution of data defined by these mutable tem-
plates; in fact, each schema update should be prop-
erly spread to the previously validated archives, in or-
der to automatically adapt the existing content to the
new schema (or to provide modelers with the feed-
back necessary to manually fix the problem).
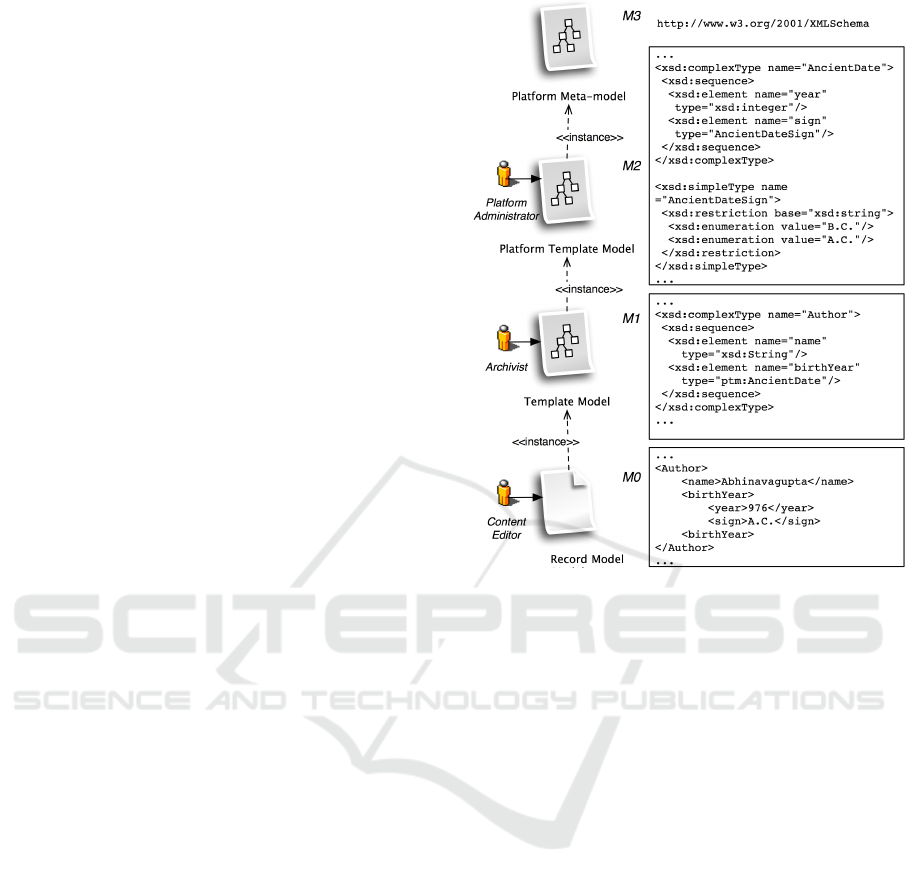
Examples of this process can be defined consid-
ering the data model illustrated in Figure 2; start-
ing from the schema at level M1, user may insert
more information into the Author element by adding
new fields (PlaceofBirth, Nationality), mod-
ifying existing fields (splitting Name into Suffix,
FirstName, LastName, Prefix) or removing fields
which are considered no more useful. Moreover,
user may also be interested in moving from the
AncientDate format to a type representing dates in
a modern way.
3.2 Technical Infrastructure Adaptation
One of the recurring issues we have faced during de-
velopment of the first prototype of E-Dvara was the
request for integrating new heterogeneous functional
modules at the top of the digital library (e.g. vir-
tual museums, meta-search engines, or applications
Figure 2: XML Representation of Data Model.
for mobile devices). These requests lead to several is-
sues such as ad-hoc business logic customization and
service duplication; these issues clearly demanded for
a reusable integration layer.
Moreover, we have learned also that integrating sev-
eral applications in a common environment requires
a substantial investment in understanding and imple-
menting their orchestration, in order to handle incom-
patibilities between different business logics in a stan-
dard and transparent way.
3.3 Roles Coordination Issues
The integration of different applications, concerning
different domains, may lead to new requirements in-
volving user roles and the policies they were sub-
jected to during information access. For example an
external service, in according to its own data manage-
ment policy, states when a particular workflow is re-
quired to organize the archived contents. In E-Dvara,
a workflow expresses a set of roles, related activities
and constraints that define together the structure of the
information management process.
As an example of such a workflow, consider the
curator of a digital museum which has to arrange a
new gallery, composed by paintings, ancient books
and movies hosted in three projects and owned by
A CONCEPTUAL MODEL FOR DIGITAL LIBRARIES EVOLUTION
301

three different users. Consider now the case in which
the curator wants to incorporate in the same gallery
a set of features to search, organize and enrich the
existing records, by adding new fields describing the
position each item will have in the 3D rendering of
the virtual museum. Moreover, final users may also
be interested in improving the quality of the exhibi-
tion, by creating new relations between the existing
content (e.g. opinions and links to a specific content
in a typical Web 2.0 style).
These scenarios pose several issues that must be
faced in order to provide flexibility in the way data
management is achieved.
4 HANDLING EVOLUTION
This section proposes a distributed approach to handle
the evolution problems discussed in Section 3.
4.1 Evolution Along the Informational -
Technological Dimension
In order to handle the evolution problems concerning
the changes in data format and schemata described in
Section 3.1, we propose here a four-layer data repre-
sentation model (Figure 2).
Records (level M0, Record Model) are aimed at
representing the archived data; a record is an instance
of a document stored in the digital platform. Every
record must conform to a document template (level
M1, Template Model), providing structural defini-
tions (e.g. the document contains the Title, Author,
and Date fields) and constraints (e.g. the Data field
must conform to the mm/dd/yy format or the Title
field is mandatory). Document templates are them-
selves conformed to a platform template (level M2,
Platform Template Model) devoted to define both
business rules and data types the archivists can use
to build document templates (e.g. each record in
every archive must contain the CreationDate and
Owner fields). Finally, platform templates are in-
stances of a more general layer, the platform meta-
model (level M3, Platform Meta-Model), which de-
fines a set of common low-level structures (e.g. prim-
itive data types as xsd : String) and operations (e.g.
data sequencing) available in order to define more
complex data structures. This level is that of the W3C
XML Schema specifications
4
.
The overall data model involves the interaction
with three different actors:
4
http://www.w3.org/XML/Schema
• Content editor, devoted to data entry, with respect
to a specific document template but not allowed to
perform any template change.
• Archivist, devoted to document templates defini-
tion.
• Platform administrator, devoted to the manage-
ment of platform templates.
This hierarchical data model provides automatic data
validation policies, which play a central role in our
vision. Indeed, validation is applied both to the tem-
plates and (recursively) to all the records stored in
the platform archives. Templates which do not re-
spect the business rules defined in the platform tem-
plate model should be manually updated by either
archivists or content providers in order to become
consistent. A detailed description of the proposed
data model has been presented in (Baruzzo and Ca-
soto, 2008; Baruzzo et al., 2008).
4.2 Evolution Along the Technological -
Social Dimension
In order to handle the evolution issues concerning
the adaptation to new requirements such as the inte-
gration of heterogeneous services described in Sec-
tion 3.2 we base the second prototype of E-Dvara
according to a Service-Oriented Architecture (SOA)
model (Figure 3), characterized by:
• the introduction of an explicit integration layer,
which unifies the interfaces of different subsys-
tems into the same interoperable environment.
• the migration toward autonomous and compos-
able services;
• the adoption of a common peer-to-peer, message-
based communication protocol supported by the
Enterprise Service Bus (ESB), devoted to service
orchestration, which acts as a centralized author-
ity to coordinate interaction between services and
applications.
At the top of our SOA architecture we have placed
applications such as administration interfaces to man-
age users and archives, publication interfaces to pro-
duce new content in the digital library, or virtual mu-
seums to exhibit a document archive in a “museum-
like” setting. All these heterogeneous modules can
exploit any reusable service available in the Integra-
tion layer, (e.g. to perform searches in the platform
archives).
Archives are placed at the bottom of the architec-
ture; they are managed by two modules: the Archive
Manager which stores and retrieves documents, and
the Policy Manager which manages users, accessing
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
302
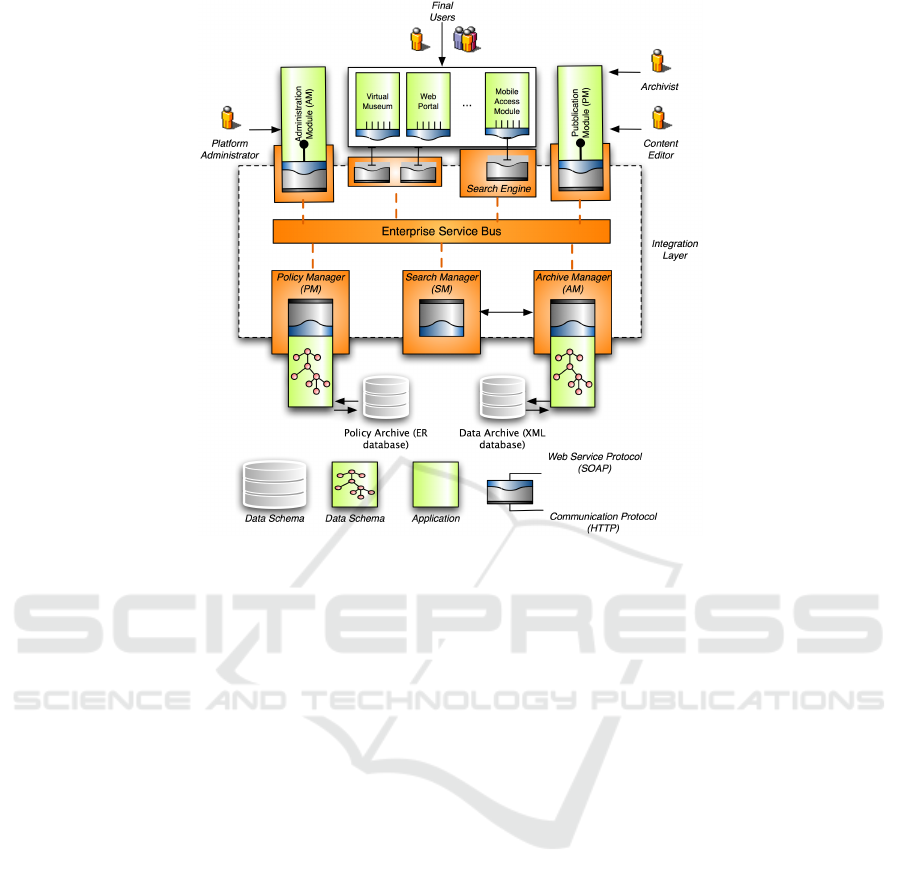
Figure 3: The architecture of the E-Dvara platform.
policies, and projects. The Archive Manager isolates
the business logic needed to realize the data-model
described in Section 4.1, whereas the Policy Manager
implements the data validation rules, decoupling them
from other architectural components.
4.3 Evolution Along the Social -
Informational Dimension
The introduction of mutable templates in content rep-
resentation leads to the challenge of evolution and re-
evaluation of existing archives. In this section, we
introduce a multi-agent approach to tackle the prob-
lem, aimed (when possible) to automatically resolve
evolution issues.
The levels from M1 to M3, proposed in Figure 2,
can be affected by updates during the digital library
life-cycle. In particular, such updates can involve
XML Schema definitions (level M3, with a low fre-
quency), Platform Template Models (level M2, with a
low-medium frequency) and Template Models (level
M1, with a rather high frequency).
Each schema is connected by a dependency bond
with: 1) the schemata on its top for validation pur-
poses; 2) other schemata of the same project (e.g.
template Book can be related with template Author
by relation WrittenBy); 3) other schemata from dif-
ferent collections (e.g. template GalleryRoom, de-
fined by the virtual museum application, can be re-
lated with templates Book and Painting defined in
different collections). This propagation mechanism
is achieved by means of a multi-agent system. Each
agent is assigned to a specific schema, monitoring its
evolution; an agent can interact with other agents as-
signed to depending schemata, send them messages
and apply evolution to the instances of its schema.
A coordinator agent is assigned to each instance
of the platform, in order to monitor the updates of the
Platform Template Model and to activate the agents
connected to each schema when required. The coor-
dinator agent is also devoted to the creation of a new
agent every time a new schema is defined.
A schema agent is devoted to the evolution of con-
tents related to a specific template at level M1. It can
perform a set of actions on the existing data, accord-
ingly to the updates affecting related schemata.
Agents perform several evolutionary operation on
data, in order to preserve data validity and, at the
same time, to prevent archivists and content editors to
spend a lot of time re-entering the whole set of exist-
ing contents. In (Guerrini et al., 2005; Guerrini et al.,
2007) a complete taxonomy of updates, which can af-
fect a generic XML schema, is described. A subset
of the listed operations, covering the set of updates
archivists can perform, has been implemented in E-
Dvara, like the extraction of a vocabulary from the
A CONCEPTUAL MODEL FOR DIGITAL LIBRARIES EVOLUTION
303

set of values assigned to a free-text String element.
When archivist updates the type of the element Name
from String to Vocabulary, the agent assigned to
that schema should access each instance of the tem-
plate and perform a change item type, verifying if
the old values assigned to Name are still valid with
respect to the new element type. When task is com-
pleted, the agent should notify the schema updates to
the related agents (according to the dependency chain
between schemata), in order to grant the consistency
of any inter-dependent data.
5 CONCLUSIONS
In this paper we have extended an existing con-
ceptual model for digital libraries, introducing the
notion of evolution dimension and describing our
proposal along three dimensions: Informational-
Technological, Technological-Social, and Social-
Informational. This characterization comes from the
lessons learned during the experimentation with our
E-Dvara platform. Now we are working to complete
the second prototype which embodies the improve-
ments described in this paper.
Our future plans include a validation of the overall
prototype in different areas, concerning the exploita-
tion of both information and services by means of mo-
bile applications, virtual museums, and Web 2.0 envi-
ronments.
REFERENCES
Bainbridge, D., Buchanan, G., Mcpherson, J., Jones, S.,
Mahoui, A., and Witten, I. (2001). Greenstone: A
platform for distributed digital library applications.
In ECDL ’01: European Digital Library Conference,
pages 137–148. Springer.
Barkstrom, B., Finch, M., Ferebee, M., and Mackey,
C. (2002). Adapting digital libraries to continual
evolution. In JCDL ’02: Proceedings of the 2nd
ACM/IEEE-CS Joint Conference on Digital Libraries,
pages 242–243. ACM.
Baruzzo, A. and Casoto, P. (2008). A flexible service-
oriented digital platform for e-content management in
cultural heritage. In IABC ’08: Intelligenza Artificiale
nei Beni Culturali Workshop, pages 38–45.
Baruzzo, A., Casoto, P., Challapalli, P., and Dattolo, A.
(2008). An intelligent service oriented approach for
improving information access in cultural heritage. In
IACH ’08: Information Access in Cultural Heritage
(IACH) Workshop, European Conference on Digital
Libraries. Springer.
Bekaert, J., Liu, X., and Van de Sompel, H. (2005). adore:
A modular and standards-based digital object repos-
itory at the los alamos national laboratory. In JCDL
’05: Joint Conference on Digital Library, pages 367–
367. ACM.
Candela, L., C. D. and Pagano, P. (2007). A reference archi-
tecture for digital library systems: Principles and ap-
plications. In Digital Libraries: Research and Devel-
opment, 1
st
International DELOS Conference, pages
22–35.
Challapalli, S., Cignini, M., Coppola, P., and Omero, P.
(2006). E-dvara: an xml based e-content platform.
In AICA.
Guerrini, G., Mesiti, M., and Rossi, R. (2005). Impact of
xml schema evolution on valid documents. In WIDM
’05: Proceedings of the 7th annual ACM Interna-
tional Workshop on Web Information and Data Man-
agement, pages 39–44. ACM.
Guerrini, G., Mesiti, M., and Sorrenti, M. A. (2007). Xml
schema evolution: Incremental validation and effi-
cient document adaptation. In Database and XML
Technologies, 5
th
International XML Database Sym-
posium, pages 92–106.
Lagoze, C., Payette, S., Shin, E., and Wilper, C. (2005).
Fedora: An architecture for complex objects and their
relationships. CoRR.
Lutzenkirchen, F. (2002). Mycore - ein open-source-system
zum aufbau digitaler bibliotheken. Datenbank-
Spektrum, 4:23–27.
Rowlands, I. and Bawden, D. (1999). Digital libraries: A
conceptual framework. Libri: International Journal
of Libraries and Information Services, 49:192–202.
Tansley, R., Bass, M., Stuve, D., Branschofsky, M., Chud-
nov, D., McClellan, G., and Smith, M. (2003). The
dspace institutional digital repository system: current
functionality. In JCDL ’03: Joint Conference on Dig-
ital Libraries, pages 87–97. IEEE.
Witten, I., McNab, R., Boddie, S., and Bainbridge, D.
(2000). Greenstone: A comprehensive open-source
digital library software system. In ICDL ’00: Interna-
tional Conference on Digital Libraries. ACM.
Yates, J. (1989). Control through communication. The
Johns Hopkins University Press.
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
304
