
Identifying Conflicts through eMails by using an
Emotion Ontology
Chahnez Zakaria
1
, Olivier Cur
´
e
1
and Kamel Sma
¨
ıli
3
1
Universit
´
e Paris Est, Terre Digitale IGM LabInfo
5, bd Descartes Champs sur Marne, 77454 Marne la Vall
´
ee, France
2
Laboratory Loria, Campus Scientifique, BP 239, 54506 Vandoeuvre L
`
es-Nancy, France
Abstract. In the logic of text classification, this paper presents an approach to
detect emails conflict exchanged between colleagues, who belong to a geograph-
ically distributed enterprise. The idea is to inform a team leader of such situation,
hence to help him in preventing serious disagreement between team members.
This approach uses the vector space model with TF*IDF weight to represent
email; and a domain ontology of relational conflicts to determine its categories.
Our study also addresses the issue of building ontology, which is made up of two
phases. First we conceptualize the domain by hand, then we enrich it by using
the triggers model that enables to find out terms in corpora which correspond to
different conflicts.
1 Introduction
Geographically distributed teams of a given enterprise can overcome the problems of
distance by using Computer Supported Cooperative Work (CSCW) tools.
However it is still difficult for a team leader to remotely manage the emotions of its
members and the conflicts that may arise between them. Such situations can complicate
communication and cooperation between them. Indeed it has been proven over several
decades by Elton Mayo at the Hawthorne experiments [1], that good horizontal and / or
vertical relationships, in a professional environment, have a major influence on overall
satisfaction provided by the work and personal productivity.
The constitution of virtual teams has accentuated the difficulty of the understanding
an employee’s behaviour. Nevertheless, the team leader can overcome this situation
with the data generated by the CSCW tools, especially through the analysis of emails
which allows to generate substantial textual corpora due to its large exploitation in
professional environments [2]. The idea is to detect automatically, conflicts between
team members through exchange of emails, so that the team leader can understand their
behaviour, intervene and manage conflicts before they lead to irreversible situations.
Our approach solves the task of conflict detection by classifying emails, according to
our domain ontology of relational conflicts.
The remainder of the paper is organized as follows. Section 2 discusses related
work. Section 3 describes our conceptualization approach of the conflicts domain in
two stages. Section 4 describes the model which we have developed for classifying
Zakaria C., Curé O. and Smaïli K. (2009).
Identifying Conflicts through eMails by using an Emotion Ontology.
In Proceedings of the 6th International Workshop on Natural Language Processing and Cognitive Science , pages 46-54
DOI: 10.5220/0002172000460054
Copyright
c
SciTePress

email based on the concepts of our ontology. Section 5 shows experimental results.
Finally, Section 6 concludes with a discussion of future directions.
2 Related Work
Within the sphere of emails classification, some work deals with binary classification,
as in information filtering, e.g. separating spam from good emails, other work deals
with multiclass classification or classifying an email into one of many categories, e.g.
routing email to the concerned service, in a company.
Our study can be seen as a binary classification, because it filters emails with conflict
situations, but our approach is also concerned with the multiclass classification as we
also detect the type of conflict assigned to an email and provide a degree of importance.
In general, a classification model consists of two tasks: modeling the document
using a model of representation, as the vector model [3], and his assignment to the
topic that concerns through a classifier, as Na
¨
ıve Bayes [4], Support Vector Machine
(SVM) [5], etc.
Several approaches are proposed for building ontologies from corpora. They can be
grouped into two categories: structural approaches based on the use of formal grammar;
non-structural approaches, such as statistical approaches which must use enough cor-
pora, in order to have reliable measures and find out interesting relationships between
terms [6]. The acquisition of terms based on statistical approach exists since several
decades: Enguehard and Pantera (1995) [7], Dias (2002) [8], etc. This work is based on
the idea that words of the same area tend to often occur together. Similarity measures
are used to identify recurrent associations of terms. The correlated terms recurrences are
extracted by using different kind of measures [9]: Mutual Information, Dice coefficient,
etc.
3 Building Ontology
The ontology technology was born as a response to the need for representation of
knowledge in information systems. It allows to access not only to the terms used by
the human being, but also to meaning associated to the various terms. For instance T.
Berners-Lee [10] considers the ontology as a way to enable Web pages to integrate a
representation of the knowledge they contain and to represent semantic links with other
documents.
One widely cited definition of an ontology is Gruber’s [11] ”an ontology is a for-
mal, explicit, specification of a shared conceptualization”. In other words, an ontology
is designed to specify concepts and relations, and to make them understandable and
usable by several agents (human or software).
The approach we present builds an ontology in two steps; the first consists in con-
ceptualizing the domain of relational conflicts, based on human expertise; the second
enriches it automatically by using a trigger-based model that enables to find terms in
corpora which correspond to different conflicts.
47
3.1 Construction of a First Conflict Ontology Draft
To the best of our knowledge, there is no ontology of conflicts, that is why we decided to
focus our work on emotions. In fact, conflicts could be detected through the expression
of emotions. But, we are interested just by negative emotions which are at the origin
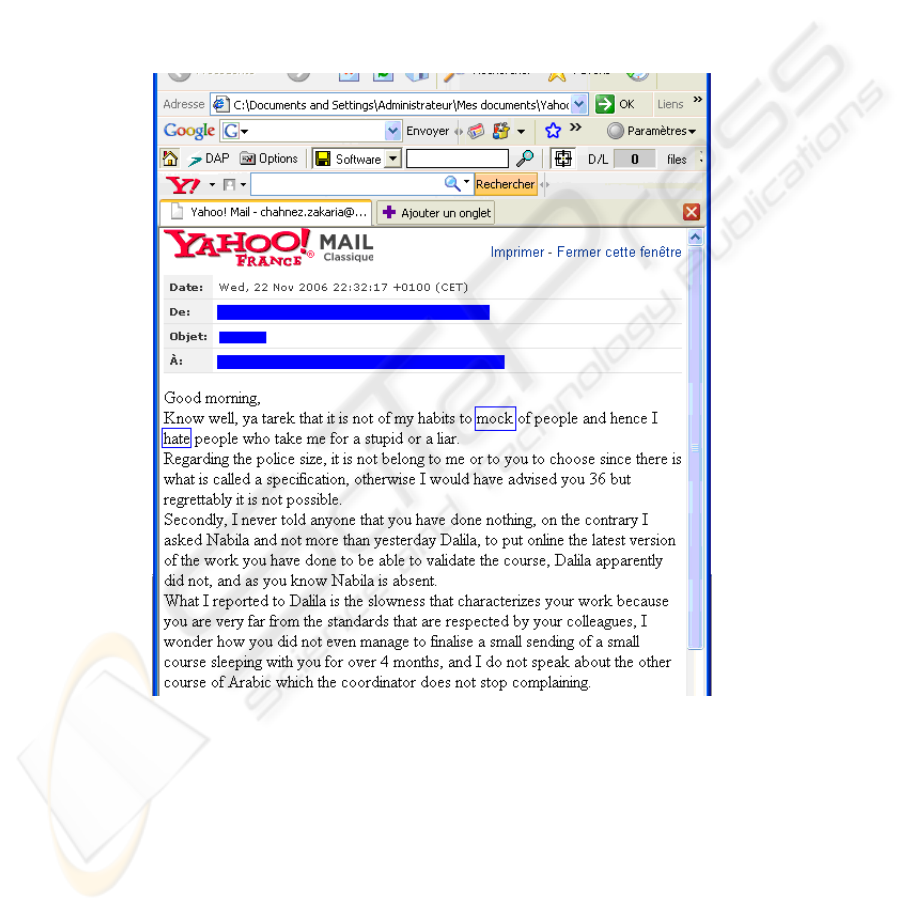
of disagreement situations. Figure 1 shows an example of a conflict between two col-
leagues. This email serves to illustrate our idea, in fact, conflicts are accompanied by
the expression of emotion. In the example, the terms boxes indicate the expression of
emotion, the first indicates ”humiliation” emotion and the second indicates the ”hate”
emotion.
Fig. 1. An example of conflict email between two colleagues.
To conceptualize the conflict domain, we based our work on the classification of
Antonio R Damasio [12] and Michelle Larivey [13]. We used their vocabularies, but
we changed the separation criteria of emotions. In figure 2 we show the separation
criteria. The first criterion separates emotions according to the degree of conflict, the
first category represents emotions that can produce substantial conflicts as ”anger”, the
second one leads to anticipate some indirect conflicts as ”indifference”. The second
48
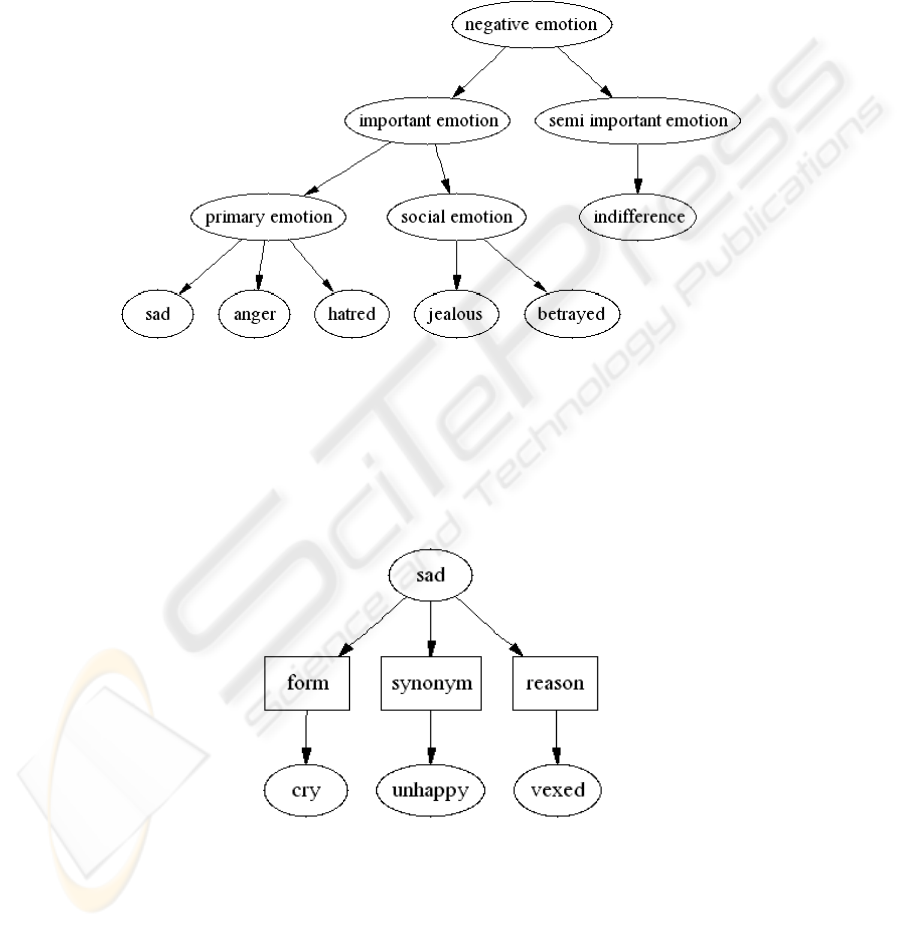
criterion deals with making the difference between personal and social emotions or
distinguish social emotions from others. This is due to the fact that it is very difficult
to determine a personal emotion, for instance, the ”sad” emotion may be social when
this feeling is due to the behaviour of another colleague or friend, and may be personal
when the person did not succeed to reach an objective; however, ”jealousy” can easily
be classified as social emotions.
Fig. 2. An extract of the ontology of relational conflicts.
And in figure 3 we show how we structure a concept. The terms which represent concept
are organized in three groups :
– synonymous: it regroups the synonyms of the term representing the concept
– forms: it regroups terms that indicate the expression of emotion
– causes: it regroups the reasons which may justify the expression of emotion
Fig. 3. The sad emotion.
In the next section we present the statistical model that we used to enrich our ontology
from corpora.
49

3.2 Triggers to Enrich Ontology
Development of statistical language models is historically related to the construction
of the first significant linguistic corpora [14]. For these models, a corpus represents
a raw material, it is used to learn a maximum of linguistic events (n-grams, part of
speech, etc.) [6]. In other words statistical processing of corpora allows to get knowl-
edge by studying recurrent phenomenon. A corpus should be large in order to model
statistically a maximum of reliable constructions. The more a corpus is important, the
better the events are modeled [6]. For machine translation or speech recognition, it is
not surprising to train the language model on a corpus of more than 300 million of
words. Classical n-grams models are often enriched by language models based on trig-
gers which are used in several domains, for example in translation, they are exploited
to build multilingual dictionaries [15].
We use the triggers to enrich our ontology, our aim is to find terms that are seman-
tically related to the terms of the ontology, then we integrate them into the ontology,
to better represent its concepts. The triggers focus on terms that often appear together.
That is to say, a term w
i
will probably trigger the term w
j
. That means we can predict
the term w
j
when w
i
occurs (it can be written as: w
i
→ w
j
). For instance the term insult
will probably predict the term humiliation. The triggers are determined by calculating
for each ontology term its Mutual Information with each term in the dictionary. Then,
only terms with a high mutual information are kept and are used as triggered terms [6].
The mutual information is a measure of distance stemming from the information the-
ory, which allows to measure the degree of association between two events. The mutual
information M I(x, y) represents the importance of the relationship between two events
x and y. The non-weighted MI is given below:
MI(x, y) = log
P (x, y)
P (x)P (y)
(1)
where:
P(x) is the marginal probability of x
P(y) is the marginal probability of y
P(x,y) is joint probability xy
In the formula (1) the event x represents the term trigger, y represents its triggered term
in the corpus and xy illustrates the occurrence of trigger with its triggered term in the
corpus.
We use this principle of trigger to enrich ontology at the level of concepts, i.e. each
triggered term will be integrated as synonym, as form or as reason in concept by hand.
This model allowed to enrich ”sad” concept with terms: ”tear”, ”painful”, ”hurt” and
”annoyed”, as shown in figure 4.
In the next section, we present the aim of conceptualizing of the conflicts domain.
The concepts of the ontology will be used to detect the conflicts emails.
4 Classification eMails
Our approach solves the task of detecting conflicts in the emails by their classification,
it consists to identify the concept to which an email belongs to and therefore to rec-
50
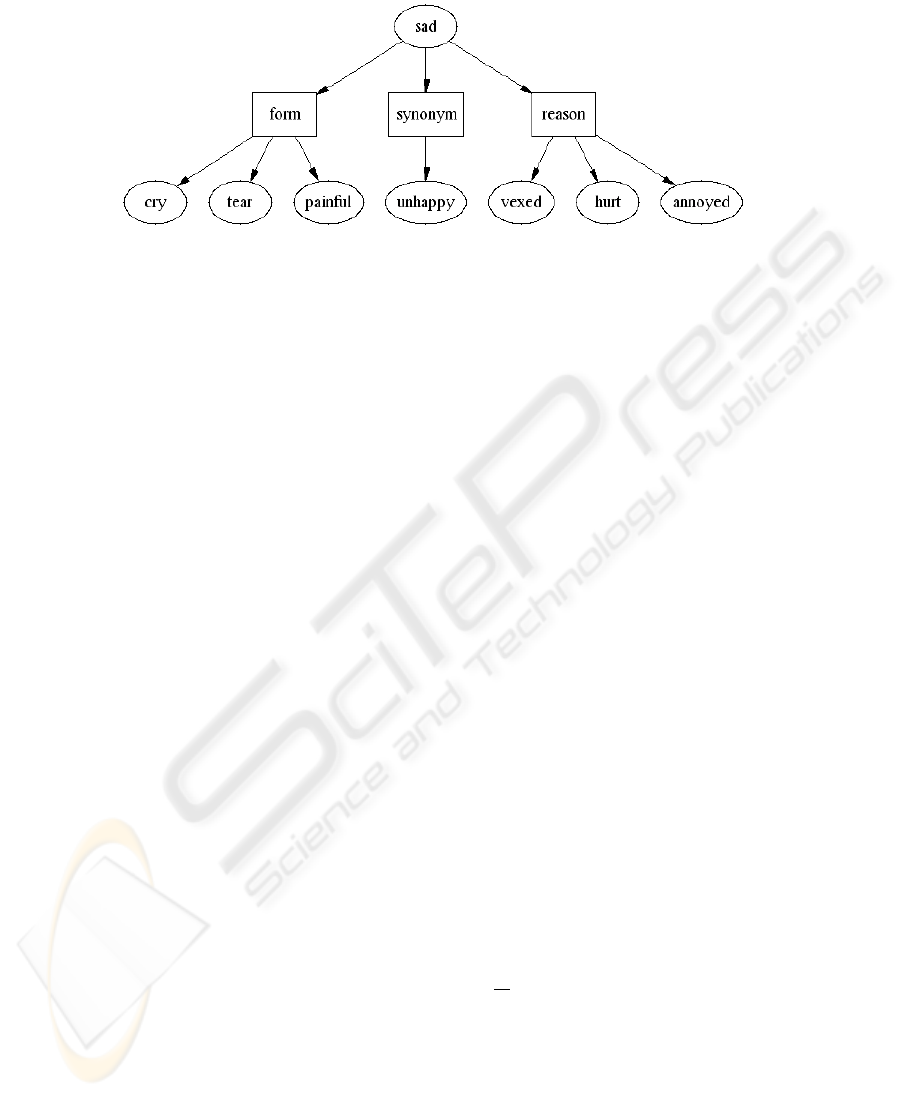
Fig. 4. The sad emotion after the addition of the triggers.
ognize the emotion expressed in this email. The domain of classification is made up of
two distinct approaches: supervised and unsupervised learning. The distinction between
these two approaches comes from the knowledge or not of categories. Indeed, super-
vised classification learns to assign instances to predefined categories, but unsupervised
classification is a task, which learns classification from the data, because categories are
unknown. For the purposes of this paper we will focus on supervised learning. We clas-
sify emails according to concepts of ontology, i.e. that the categories of classification
are emotions of ontology.
4.1 The Classification Model
Each email (M
i
) to classify is coded by a vector according to the terms of a concept
(C
i
). Then a similarity is calculated to quantify the semantic proximity between the
email (its representation by the concept vector) and an emotion. This process is re-
peated for each emotion. Once all similarities are calculated, the classification process
associates to each email the emotion with the highest similarity.
C
i
= {c
i1
..., c
ij
, ..., c
in
}
where c
ij
is the weight of the term w
j
in the ith concept, and n is the number of terms
in the concept which varies from one concept to another.
M
k
= {m
i1
, ..., m
ij
, ..., m
in
}
where m
ij
is the weight of the term w
j
in the ith concept. Weights are estimated using
the TF*IDF (Term Frequency, Inverse Document Frequency):
m
ij
= T F (w
ij
, M) × IDF (w
ij
)
IDF (w
ij
) = log(
T
t
j
)
where T F (w
ij
, M) is the frequency of the term w
ij
of the ith concept within the email
M. T is the size of the corpus of the ith concept and t
j
is the number of emails in which
the term w
ij
occurs.
51

The classification is done by calculating for each pair (C
i
, m
i
) the cosine of the
angle between vectors C
i
and m
i
defined as follows:
Cos(C
i
, M
i
) =
P
n
j=1
c
ij
m
ij
q
P
n
j=1
c
ij
2
P
n
j=1
m
ij
2
4.2 Labeling
We labelled the corpus according to the emotions of our ontology. We set up a semi-
automatic procedure to label the corpus, first we automatically labeled the corpus through
a function that we developed, then we manually corrected the errors of the function.
5 Evaluation and Proposals
To evaluate our email classification model, we have chosen to use precision, recall and
F measure. Recall is defined as the fraction of relevant emails that are retrieved by the
system; and Precision is defined as the fraction of retrieved emails that are in fact rele-
vant. The F measure characterizes the combined performance of Recall and Precision.
These measures are calculated as follows [6]:
Recall =
Number of relevant emails retrieved
Number of emails to retrieve
P recision =
Number of relevant emails retrieved
Number of emails retrieved
F measure = 2 ×
P recision × Recall
P recision + Recall
Recall and precision are often used because they reflect the point of view of the user:
if precision is low, the team leader will be dissatisfied, because he will waste time for
reading emails which do not deal with conflicts, and if recall is low, he will not access
to the emails of conflicts.
We used two other measures to estimate the performance of a system from its errors,
namely the False Acceptance (FA), where an email is wrongly considered as conflictual,
and the False Rejection (FR), where an email is wrongly rejected. These measures are
calculated as follows [6]:
F A =
Number of F alse Acceptances
Number of emails retrieved
F R =
Number of F alse Rejections
Number of emails to retrieve
52
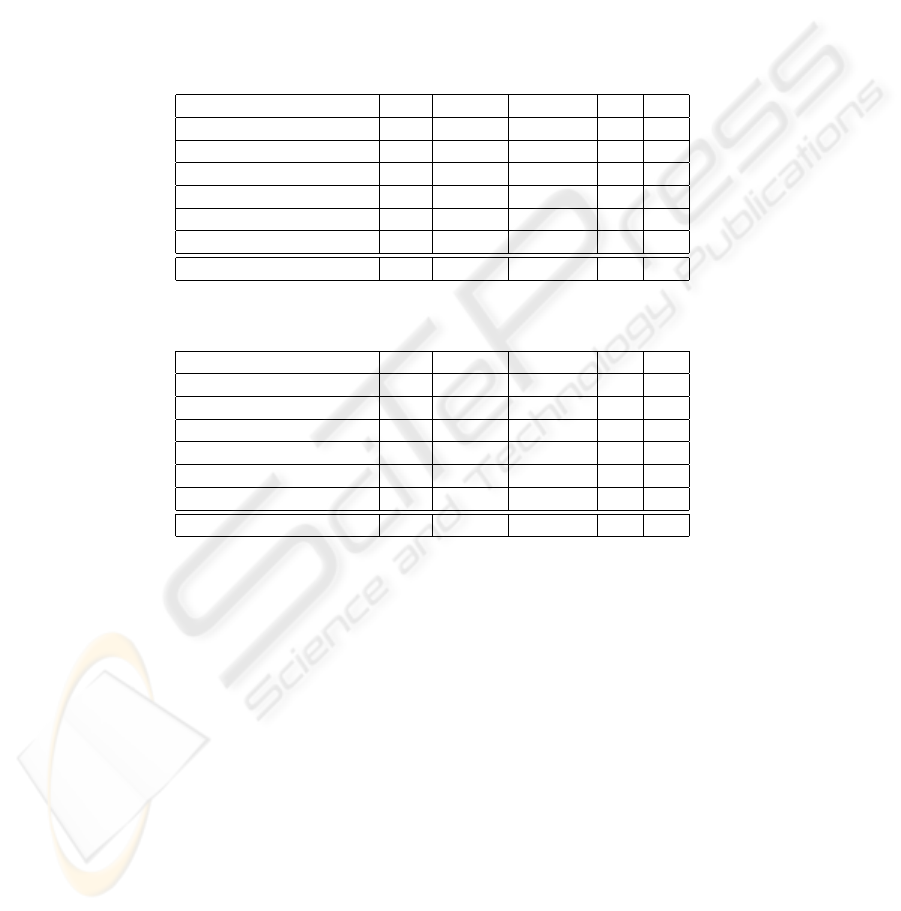
For our experiments, we used a corpus of ”Le Monde” newspaper, it is made up
of 7854 paragraphs, we have divided into two sets, 90 % of the corpus for training
and the 10 % remaining for test. We first evaluated our classifier based on the use of
the first version of the ontology (table 1). Then we evaluated it again when we use
the version of ontology augmented by triggers (table 2). The experiments given below
illustrates results on only few concepts of our ontology. These results show that triggers
have allow to maximize classification performance, for certain concepts all measures
have increased, as ”treason”, for others, precision and false acceptance show that the
triggers have improved the accuracy of the selection of conflicts emails, such as ”fear”.
Table 1. Performance of the classifier with the initial ontology.
Concept Recall Precision F-Measure FA FR
fear 0.98 0.91 0.94 0.091 0.020
disgust 0.96 0.93 0.94 0.069 0.036
treason 0.84 0.84 0.84 0.158 0.158
arrogance 1.0 0.75 0.86 0.25 0.0
protest 0.81 1.0 0.9 0.0 0.186
discouragement 1.0 0.77 0.87 0.225 0.0
Average on all the concepts 0.93 0.87 0.89 0.132 0.067
Table 2. Performance of the classifier by using the augmented ontology.
Concept Recall Precision F-Measure FA FR
fear 0.96 0.97 0.96 0.031 0.041
disgust 1.0 0.9 0.95 0.103 0.0
treason 0.94 0.92 0.93 0.075 0.057
arrogance 0.9 0.99 0.94 0.011 0.103
protest 0.89 1.0 0.94 0.0 0.105
discouragement 0.96 0.9 0.93 0.103 0.037
Average on all the concepts 0.94 0.95 0.94 0.054 0.057
6 Discussion and Conclusions
The classifier achieve good performance in terms of recall and precision. Increasing the
ontology by triggers allows us to outperfom the results obtained by the initial ontology.
In fact, the initial ontology has been developped by hand. For each concept only few
words have been used. Using triggers allows to adapt the ontology to the used corpus.
Nowadays, we concentrate our effort in collecting more appropriate and significant cor-
pus from certain forums in which conflicts are more frequent than what we get from our
”Le Monde” corpus, in order to test our ontology in its context, because we have found
a cases of polysemy. However, it is necessary to consider the problem of polysemy in
the detection of emails of conflict. We propose to take advantage of the relations be-
tween emotions. An email which includes the expression of two emotions or more, it
has more chances to represent a conflict between two persons, for instance the existence
of concept ”anger” with concept ”humiliation”.
53

References
1. Broches, R. S.: Unraveling the Hawthorne Effect: An Experimental Artifact ’Too Good to
Die’. PhD thesis, University of Wesleyan (2008)
2. Whittaker, S., Sidner, C.: Email overload: exploring personal information management of
email. In: CHI ’96: Proceedings of the SIGCHI conference on Human factors in computing
systems, New York, NY, USA, ACM Press (1996) 276–283
3. Salton, G., Wong, A., Yang, C.S.: A vector space model for automatic indexing. Commun.
ACM 18 (1975) 613–620
4. Friedman, N., Geiger, D., Goldszmidt, M.: Bayesian network classifiers. Mach. Learn. 29
(1997) 131–163
5. Cortes, C., Vapnik, V.: Support vector networks. In: Machine Learning. (1995) 273–297
6. Haton, J., Cerisara, C., Fohr, D., Laprie, Y., Smaili, K.: Reconnaissance automatique de la
parole. Du signal
`
a son interpr
´
etation. Dunod (2006)
7. Enguehard, C., Pantera, L.: Automatic natural acquisition of a terminology. Journal of
Quantitative Linguistics 2 (1995) 27–32
8. Dias, G.: Extraction automatique d’associations lexicales
`
a partir de corpora. PhD thesis,
University of Orleans (2002)
9. Voltz, R., Oberle, D., Staab, S., Motik, B.: Kaon server - a semantic web management system.
In: Alternate Track Proceedings of the Twelfth International World Wide Web Conference,
Budapest, Hungary, ACM. (2003) 139–148
10. McGuinness, D. L.: Ontologies come of age. In Fensel, D., Hendler, J., Lieberman, H.,
Wahlster, W., eds.: Spinning the Semantic Web: Bringing the World Wide Web to Its Full
Potential. MIT Press (2002) 171–194
11. Gruber, T.: A translation approach to portable ontology specifications. Knowledge Acquisi-
tion 5 (1993) 199–220
12. Debois, N.: Les
´
emotions en eps: comprendre et intervenir. EP.S 1 (2007) 7
13. Larivery, M.: Les genres d’
´
emotions. La lettre du psy 2 (1998)
14. Denoual, E.: Mthodes en caract
`
eres pour le traitement automatique des langues. PhD thesis,
University of Joseph Fourier (2006)
15. Lavecchia, C., Sma
¨
ıli, K., Langlois, D., Haton, J.P.: Using inter-lingual triggers for machine
translation. In: Eighth conference INTERSPEECH. (2007)
54
