
UNORDERED TREE MATCHING AND TREE PATTERN
QUERIES IN XML DATABASES
Yangjun Chen
Dept. Applied Computer Science, University of Winnipeg, Manitoba, R3B 2E9, Canada
Keywords: Tree mapping, Tree pattern queries, XML databases, Query evaluation, Tree encoding.
Abstract: With the growing importance of XML in data exchange, much research has been done in providing flexible
query facilities to extract data from structured XML documents. In this paper, we discuss an efficient
algorithm for tree mapping problem in XML databases based on unordered tree matching. Given a target
tree T and a pattern tree Q, the algorithm can find all the embeddings of Q in T in O(|D||Q|) time, where D is
a largest data stream associated with a node of Q. More importantly, the algorithm is index-oriented: with
XB-trees constructed over data streams, disk access can be dramatically decreased.
1 INTRODUCTION
In this paper, we consider a kind of tree mappings
used in XML databases, in which a set of XML
documents is maintained. Abstractly, each document
can be considered as a tree structure with each node
standing for an element name from a finite alphabet
∑; and an edge for the element-subelement
relationship. Therefore, queries in XML query lan-
guages, such as XPath (Deutch et al., 1999), XQuery
(Wang et al., 2003; Wang et al., 2005), XML-QL
(Cooper et al., 2001), and Quilt (Chamberlin et al.,
2000; Chamberlin et al., 2002 ), typically specify
patterns of selection predicates on multiple elements
that also have some specified tree structured
relations. For instance, the XPath expression:
book[title = ‘Art of Programming’]//author[fn =
‘Donald’ and ln = ‘Knuth’]
matches author elements that (i) have a child
subelement fn with content ‘Donald’, (ii) have a
child subelement ln with content ‘Knuth’, and are
descendants of book elements that have a child title
subelement with content ‘Art of Programming’.
Figure 1: A query tree.
This expression can be represented as a tree
structure as shown in Fig. 1.
In this tree structure, the nodes v are labeled with
element names or string values, denoted as label(v).
In addition, there are two kinds of edges: child edges
(/-edges) for parent-child relationships, and
descendant edges (//-edges) for ancestor-descendant
relationships. A /-edge from node v to node u is
denoted by v → u in the text, and represented by a
single arc; u is called a /-child of v. A //-edge is
denoted v ⇒ u in the text, and represented by a
double arc; u is called a //-child of v. In addition, a
node in Q can be a wildcard ‘*’ that matches any
element in T. Such a query is often called a twig
pattern.
In any DAG (directed acyclic graph), a node u is
said to be a descendant of a node v if there exists a
path (sequence of edges) from v to u. In the case of a
twig pattern, this path could consist of any sequence
of /-edges and/or //-edges. We also use label(v) to
represent the symbol (∈ ∑ ∪ {*}) or the string
associated with v. Based on these concepts, the tree
embedding can be defined as follows.
Definition 1. An embedding of a twig pattern Q into
an XML document T is a mapping f: Q → T, from
the nodes of Q to the nodes of T, which satisfies the
following conditions:
(i) Preserve node label: For each u ∈ Q, label(u) =
label(f(u)).
(ii) Preserve parent-child/ancestor-descen-
book
title
A
uthor*
A
rt of Programming
f
n
D
onald
K
nuth
ln
191
Chen Y. (2009).
UNORDERED TREE MATCHING AND TREE PATTERN QUERIES IN XML DATABASES.
In Proceedings of the 4th International Conference on Software and Data Technologies, pages 191-198
DOI: 10.5220/0002238801910198
Copyright
c
SciTePress
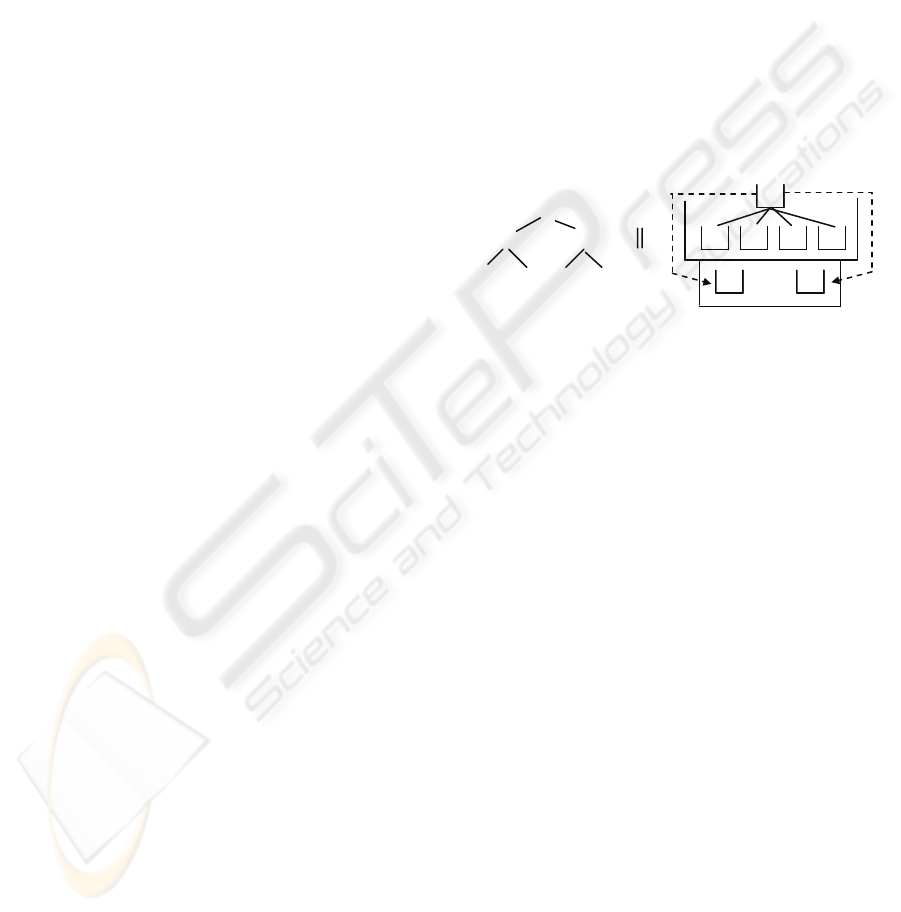
dant relationships: If u → v in Q, then f(v) is a
child of f(u) in T; if u ⇒ v in Q, then f(v) is a
descendant of f(u) in T.
If there exists a mapping from Q into T, we say, Q
can be imbedded into T, or say, T contains Q.
Notice that an embedding could map several nodes
with the same tag name in a query to the same node
in a database. It also allows a tree mapped to a path.
In fact, it is a kind of unordered tree matching, by
which the order of siblings is not significant. This
definition is quite different from the tree matching
defined in (Hoffman and O’Donnell, 1982).
In the past decade, there is much research on how to
find such a mapping efficiently; but all the proposed
methods can be categorized into two groups. By the
first group (Abiteboul et al., 1999; Chung, et al.,
2002; Chen, et al., 2006), a tree pattern is typically
decomposed into a set of binary relationships
between pairs of nodes, such as parent-child and
ancestor-descendant relations. Then, an index
structure is used to find all the matching pairs that
are joined together to form the final result. By the
second group (Bruno et al., 2002; Chen et al., 2005;
Choi et al., 2003; Lu, et al., 2005; Seo et al., 2003 ;
Li et al., 2001), a twig pattern is decomposed into a
set of paths. The final result is constructed by
joining all the matching paths together. As an
important improvement, TwigStack was proposed by
Bruno et al. (2002), which compresses the
intermediate results by the stack encoding, which
represents in linear space a potentially exponential
number of answers. However, TwigStack achieves
optimality only for the queries that contain only //-
edges. In the case that a query contains both /-edges
and //-edges, some useless path matchings have to be
performed. In the worst case, TwigStack needs
O(|D|
|Q|
) time for doing the merge joins as shown by
Chen et al. See page 287 in (Chen et al., 2006).
Here, D is a largest data stream associated with a
node q of Q and each element in a data stream is a
quadruple (DocId, LeftPos, RightPos, LevelNum)
representing an element v (matching q) in a
document, where DocId is the document identifier;
LeftPos and RightPos are generated by counting
word numbers from the beginning of the document
until the start and end of v, respectively; and
LevelNum is the nesting depth of v in the document.
This method is further improved by several re-
searchers. In (Chen et al., 2005), iTwigJoin was
discussed, which exploits different data partition
strategies. In (Lu et al., 2005), TJFast accesses only
leaf nodes by using extended Dewey IDs. By both
methods, however, the path joins can not be avoided.
The method Twig
2
Stack proposed by Chen et al.
(2006) works in a quite different way. It represents
the twig results using the so-called hierarchical
stack encoding to avoid any possible useless path
matchings. In (Chen et al., 2006), it is claimed that
Twig
2
Stack needs only O(|D|⋅|Q| + |subTwigResults|)
time for generating paths. But a careful analysis
shows that the time complexity for this task is
actually bounded by O(|D|⋅|Q|
2
+ |subTwigResults|).
It is because each time a node is inserted into a stack
associated with a node in Q, not only the position of
this node in a tree within that stack has to be
determined, but a link from this node to a node in
some other stack has to be constructed, which
requires to search all the other stacks in the worst
case. The number of these stacks is |Q|. See Fig. 4 in
(Chen et al., 2006) to know the working process.
The following example helps for illustration.
Figure 2: Illustration for hierarchical stacks.
In Fig. 2(b), we show the hierarchical stacks
associated with the two nodes A and B of Q with
respect to T shown in Fig. 2(a). In (Chen, et al.,
2006), the nodes in a data stream associated with
each node of Q are sorted by their (DocID,
RightPos) values. So a
1
is visited last. When it is
inserted into HS[A] (hierarchical stack of A), all
those stacks in HS[A], which are not a descendant of
some other stack, will be checked to establish ances-
tor-descendant links. In addition, to generate links to
some stacks in HS[B], similar checks will also be
performed. This needs O(|Q|) time in the worst case,
yielding an O(|D|⋅|Q|
2
) time complexity.
The method discussed in (Jiang et al., 2007)
improves the stack structure used in Twig
2
Stack to
avoid storing individual path matches and remove
subTwigResults time. But its theoretical time
complexity is still O(|D|⋅|Q|
2
).
In this paper, we present an new algorithm, tree-
matching( ), for evaluating tree pattern queries with
the following advantages:
- tree-matching( ) is able to handle twig patterns
containing /-edges, //-edges, *, and branches.
- tree-matching( ) takes a set of data streams as
inputs, over which XB-trees can be established to
speed up disk access.
a
1
b
1
b
2
a
2
a
3
a
4
a
5
T
:
A
Q:
B
b
2
b
1
a
1
a
2
a
3
a
4
2
a
5
(
a
)
(b)
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
192

- tree-matching( ) runs in O(|D|⋅|Q|) time and
O(|D|⋅|Q|) space.
The remainder of the paper is organized as follows.
In Section 3, we restate the tree encoding (Zhang et
al., 2001), which facilitates the recognition of
different relationships among the nodes of a tree. In
Section 3, we discuss our algorithm. Section 4 is de-
voted to the adaptation of our algorithm in an
indexing environment. Finally, a short conclusion is
given in Section 5.
2 TREE ENCODING
In (Zhang et al., 2001), an interesting tree encoding
method was discussed, which can be used to identify
different relationships among the nodes of a tree.
Let T be a document tree. We associate each node v
in T with a quadruple α(v) = (d, l, r, ln), where d is
the document identifier (DocId), l = LeftPos, r =
RightPos, and ln = LevelNum. By using such a data
structure, the structural relationship between the
nodes in an XML database can be simply deter-
mined (Zhang et al., 2001):
(i) ancestor-descendant: a node v
1
associated with
(d
1
, l
1
, r
1
, ln
1
) is an ancestor of another node v
2
with (d
2
, l
2
, r
2
, ln
2
) iff d
1
= d
2
, l
1
< l
2
, and r
1
> r
2
.
(ii) parent-child: a node v
1
associated with (d
1
, l
1
,
r
1
, ln
1
) is the parent of another node v
2
with (d
2
,
l
2
, r
2
, ln
2
) iff d
1
= d
2
, l
1
< l
2
, r
1
> r
2
, and ln
2
= ln
1
+ 1.
(iii) from left to right: a node v
1
associated with (d
1
,
l
1
, r
1
, ln
1
) is to the left of another node v
2
with
(d
2
, l
2
, r
2
, ln
2
) iff d
1
= d
2
, r
1
< l
2
.
Figure 3: Illustration for tree encoding.
In Fig. 3, v
2
is an ancestor of v
6
and we have
v
2
.LeftPos = 2 < v
6
.LeftPos = 6 and v
2
.RightPos = 9
> v
6
.RightPos = 6. In the same way, we can verify
all the other relationships of the nodes in the tree. In
addition, for each leaf node v, we set v.LeftPos =
v.RightPos for simplicity, which still work without
downgrading the ability of this mechanism.
In the rest of the paper, if for two quadruples α
1
=
(d
1
, l
1
, r
1
, ln
1
) and α
2
= (d
2
, l
2
, r
2
, ln
2
), we have d
1
=
d
2
, l
1
< l
2
, and r
1
> r
2
, we say that α
2
is subsumed by
α
1
. For convenience, a quadruple is considered to be
subsumed by itself. If no confusion is caused, we
will use v and α(v) interchangeably.
We can also assign LeftPos and RightPos values to
the query nodes in Q for the same purpose as above.
Finally we use T[v] to represent a subtree rooted at v
in T.
3 MAIN ALGORITHM
In this section, we discuss our algorithm according
to Definition 1. The input of the algorithm is a set of
data streams associated with the query nodes q
in Q,
which contains the positional representations
(quadruples) of the document nodes v that match q
(i.e., label(v) = label(q)). All the quadruples in a data
stream are sorted by their (DocID, RightPos) values.
For example, in Fig. 4, we show a query tree
containing 5 nodes and 4 edges and each node is
associated with a list of matching nodes of the
document tree shown in Fig. 3, sorted according to
their (DocID, LeftPos) values. For simplicity, we
use the node names in a list, instead of the node’s
quadruples.
We also note that the data streams associated with
different nodes in Q may be the same. So we use q
to represent the set of such query nodes and denote
by L(q) the data stream shared by them. Without loss
of generality, assume that the query nodes in q are
sorted by their RightPos values.
Figure 4: Illustration for L(q
i
)’s.
We will also use L(Q) = {L(q
1
), ..., L(q
l
)} to
represent all the data streams with respect to Q,
where each q
i
(i = 1, ..., l) is a set of sorted query
nodes that share a common data stream.
During the process, for each document tree node v, a
data structure is produced and maintained to
facilitate computation:
QS(v) - it contains all those query tree node q such
that Q[q] (the subtree rooted at q) can be imbedded
into T[v].
(1, 5, 5, 4
)
(1, 3, 3, 3
)
(
1
,
10
,
10
,
2
)
(1, 2, 9, 2
)
A v
1
B v
1
v
3
C B v
4
B v
8
D v
7
v
6
C v
5
C
(1, 1, 11, 1
)
(1, 4, 8, 3
)
(1, 7, 7, 4
)
(1, 6, 6, 4
)
T
:
A q
1
q
1
B B q
5
q
3
C C q
4
{v
4
, v
2
, v
8
}
{v
3
, v
5
, v
6
}
{v
1
}
Query nodes with the same
tag will be associated with
the same data stream:
Q:
L
(q
2
) = L(q
5
= {v
4
, v
2
, v
8
}
UNORDERED TREE MATCHING AND TREE PATTERN QUERIES IN XML DATABASES
193

In addition, each q is associated with a variable,
denoted χ(q). During the tree matching process, χ(q)
will be dynamically assigned a series of values a
0
,
a
1
, ..., a
m
for some m in sequence, where a
0
= φ and
a
i
’s (i = 1, ..., m) are different nodes of T’. Initially,
χ(q) is set to a
0
= φ. χ(q) will be changed from a
i
-1
to a
i
= v (i = 1, ..., m) when the following conditions
are satisfied.
i) v is the node currently encountered.
ii) q appears in QS(u) for some child node u of v.
iii) q is a //-child, or
q is a /-child, and u is a /-child with label(u) =
label(q).
Then, each time before we insert q into QS(v), we
will do the following checking:
1. Let q
1
, ..., q
k
be the child nodes of q.
2. If for each q
i
(i = 1, ..., k), χ(q
i
) is equal to v and
label(v) = label(q), insert q into QS(v).
Since we search both T and Q bottom-up, the above
checking guarantees that for any q ∈ QS(v), T[v]
contains Q[q].
Below we show our algorithm tree-matching(L(Q))
for queries containing /-edges, //-edges, *, and
branches. During the execution, another algorithm
subsumption-check(v, q) may be invoked to check
whether any q ∈ q can be inserted into QS(v).
In the whole process, the quadruples will be
removed one by one from the data streams and for
each of them a node will be created and inserted into
a temporary tree structure, called a matching
subtree.
Algorithm tree-matching(L(Q))
input: all data streams L(Q).
output: a matching subtree T’ of T, D
root
and D
output
.
begin
1. repeat until each L(q) in L(Q) becomes empty {
2. identify q such that the first node v of L(q) is of the
minimal RightPos value; remove v from L(q);
generate node v;
3. if v is the first node created then
4. {QS(v) ← subsumption-check(v, q);}
5. else
6. {let v’ be the quadruple chosen just before v, for
which a node is constructed;
7. if v’ is not a child (descendant) of v then
8. {left-sibling(v) ← v’; (*generate a left-sibling link
from v to v’.*)
9. QS(v) ← subsumption-check(v, q);}
10. else
11. {v’’ ← v’; w ← v’; (*v’’ and w are two temporary
units.*)
12. while v’’ is a child (descendant) of v do
13. {parent(v’’) ← v; (*generate a parent link. Also,
indicate whether v’’ is a /-child or a //-child.*)
14. for each q in QS(v’’) do {
15. if ((q is a //-child) or
16. (q is a /-child and v’’ is a /-child and
17. label(q) = label(v’’)))
18. then χ(q) ← v;}
19. w ← v’’; v’’ ← left-sibling(v’’);
20. remove left-sibling
(w);
21. }
22. left-sibling(v) ← v’’;
23. }
24. q ← subsumption-check(v, q);
25. let v
1
, ..., v
j
be the child nodes of v;
26. q’ ← merge(QS(v
1
), ..., QS(v
j
));
27. remove QS(v
1
), ..., QS(v
j
);
28. QS(v) ← merge(q, q’);
29.}}
end
The outputs of the above algorithm are mainly two
data structures:
D
root
- a subset of document nodes v such that Q
can be embedded in T[v].
D
output
- a subset of document nodes v such that
Q[q
output
] can be embedded in T[v], where
q
output
is the output node of Q.
In these two data structures, all nodes are
increasingly sorted by their RightPos values. Based
on them, we can find all the answers.
In addition, special attention should be paid to
merge(QS
1
, QS
2
), which puts QS
1
and QS
2
together
with any duplicate being removed. Since both QS
1
and QS
2
are sorted by RightPos values, merge(QS
1
,
QS
2
) works in a way like the sort-merge join and
takes only O(max{|QS
1
|, |QS
2
|}) time. We define
merge(QS
1
, ..., QS
k-1
, QS
k
) to be merge(merge(QS
1
,
..., QS
k-1
), QS
k
).
In lines 14 - 18, we set χ values for some q’s. Each
of them appears in a QS(v’), where v’ is a child node
of v, satisfying the conditions i) - iii) given above. In
lines 24 - 28, we use the merging operation to
construct QS(v).
Function subsumption-check(v, q) (*v satisfies the node
name test at each q in q.*)
1. QS ← F;
2. for each q in q do {
3. let q
1
, ..., q
j
be the child nodes of q.
4. if for each /-child q
i
χ(q
i
) = v and for each //-child
q
i
χ(q
i
) is subsumed by v then
5. {QS ← QS ∪ {q};
6. if q is the root of Q then
7. D
root
← D
root
∪ {v};
8. if q is the output node then D
output
← D
output
∪ {v};}}
9. return QS;
end
In Function subsumption-check( ), we check whether
any q in q can be inserted into QS by examining the
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
194

ancestor-descendant/parent-child relationships (see
line 4). For each q that can be inserted into QS, we
will further check whether it is the root of Q or the
output node of Q, and insert it into D
root
or D
output
,
respectively (see lines 6 - 8).
The algorithm handles wildcards in the same way as
any non-wildcard nodes. But a wildcard matches any
tag name. Therefore, L(*) should contain all the
nodes in T. However, as with twigStack (Bruno, et
al., 2002), we establish an XB-tree over the data
stream and take an element from it as it is needed.
We discuss this issue in Section 4.
Example 1. Applying Algorithm tree-matching to
the data streams shown in Fig. 4, we will find that
the document tree shown in Fig. 3 contains the query
tree shown in Fig. 4. We trace the computation
process as shown in Fig. 5.
Figure 5: Sample trace.
4 INDEX-BASED ALGORITHM
In this section, we discuss how the algorithm
presented in the previous section can be adapted to
an indexing environment by constructing XB-trees
(Bruno, et al., 2002) over data streams. However,
XB-trees require that the quadruples in a data stream
are sorted by their LeftPos values while our
algorithm accesses data stream in the order of
increasing RightPos values. For this reason, we
maintain a global stack ST to make a transformation
of data streams using the following algorithm. In ST,
each entry is a pair (q, v) with q ∈ Q and v ∈ T (v is
represented by its quadruple.)
In the following algorithm, B(q) represents a data
stream sorted by LeftPos values and will be
transformed to another data stream L(q) sorted by
RightPos values. We note that an XB-tree will be
generated over B(q), instead of L(q).
Algorithm stream-transformation(B(q
i
)’s)
input: all data streams B(q
i
)’s, each sorted by LeftPos.
output: new data streams L(q
i
)’s, each sorted by RightPos.
begin
1. repeat until each B(q
i
) becomes empty
2. {identify q
i
such that the first element v of B(q
i
) is of
the minimal LeftPos value; remove v from B(q
i
);
3. while ST is not empty and ST.top is not v’s ancestor
do
4. { x ← ST.pop(); Let x = (q
j
, u);
5. put u at the end of L(q
i
); }
7. ST.push(q
i
, v);
8. }
end
In the above algorithm, ST is used to keep all the
nodes on a path until we meet a node v that is not a
descendant of ST.top. Then, we pop up all those
nodes that are not v’s ancestor; put them at the end
of the corresponding L(q
i
)’s (see lines 3 - 4); and
push v into ST (see line 7.) The output of the
algorithm is a set of data streams L(q
i
)’s with each
being sorted by RightPos values. However, we
remark that the popped nodes are in postorder. So
we can directly handle the nodes in this order
without explicitly generating L(q
i
)’s. That is, in the
main loop of Algorithm tree-matching( ), we handle
the popped nodes one by one.
In the XB-tree established over an B(q), each entry
in a page is a pair a = (LeftPos, RightPos) (referred
to as a bounding segment) such that any entry
appearing in the subtree pointed to by the pointer
associated with a is subsumed by a. In addition, all
the entries in a page are sorted by their LeftPos val-
ues. As an example, consider a sorted quadruple
sequence shown in Fig. 6(a), for which we may
generate an XB-tree as shown in Fig. 6(b).
Figure 6: A quadruple sequence and the XB-=tree over it.
In each page P of an XB-tree, the bounding
segments may partially overlap, but their LeftPos
positions are in increasing order. Besides, it has two
extra data fields: P.parent and P.parentIndex.
P.parent is a pointer to the parent of P, and
P.parentIndex is a number i to indicate that the ith
pointer in P.parent points to P. For instance, in the
1, 9 3, 6 5, 8
1, 9 3, 6 1, 9 3, 6 1, 9 3, 6
(1, 1, 9, 1)
(1, 2, 7, 2)
(1, 3, 3, 3)
(1, 4, 6, 3)
(1, 5, 5, 4)
(1, 8, 8, 2)
p
.parentIndex
p
.parent
(a) (b)
{q
3
, q
4
}
{q
3
, q
4
}
v
6
{q
5
}
v
8
C C
B
L
eft-sibling link
{q
3
, q
4
}
v
5
v
6
v
5
v
4
{q
2
, q
5
}
B
C
C
B
v
8
χ
(q
3
) = v
4
χ
(q
4
) = v
4
v
8
v
4
{q
2
, q
5
}
B
χ
(q
3
) = v
4
χ
(q
4
) = v
4
v
3
v
6
v
5
B
C
C
C
B
B
{q
2
, q
5
} v
2
v
3
v
6
v
5
B
C
C
C
v
8
χ
(q
3
) = v
2
χ
(q
4
) = v
2
χ
(q
2
) = v
2
χ
(q
5
) = v
2
v
3
v
5
B
C
v
6
C
C
v
2
B
v
1
{q
1
}
v
4
v
8
B
χ
(q
3
) = v
2
χ
(q
4
) = v
2
χ
(q
2
) = v
1
χ
(q
5
) = v
1
(a)
(b)
(c)
(d)
(e)
UNORDERED TREE MATCHING AND TREE PATTERN QUERIES IN XML DATABASES
195

XB-tree shown in Fig. 6(b), P
3
.parentIndex = 2 since
the second pointer in P
1
(the parent of P
3
) points to
P
3
.
We notice that in a Q we may have more than one
query nodes q
1
, ..., q
k
with the same label. So they
will share the same data stream and the same XB-
tree. For each q
j
(j = 1, ..., k), we maintain a pair (P,
i), denoted , to indicate that the ith entry in the page
P is currently accessed for q
j
. Thus, each (j = 1, ...,
k) corresponds to a different searching of the same
XB-tree as if we have a separate copy of that XB-
tree over B(q
j
).
In (Bruno, et al., 2002) two operations are defined to
navigate an XB-tree, which change the value of β
q
.
1. advance(β
q
) (going up from a page to its parent):
If β
q
= (P, i) does not point to the last entry of P,
i ← i + 1. Otherwise, β
q
← (P.parent,
P.parentIndex + 1).
2. drilldown(β
q
) (going down from a page to one of
its children): If β
q
= (P, i) and P is not a leaf
page, β
q
← (P’, 1), where P’ is the ith child page
of P.
Initially, for each q, β
q
points to (rootPage, 0), the
first entry in the root page. We finish a traversal of
the XB-tree for q when β
q
= (rootPage, last), where
last points to the last entry in the root page, and we
advance it (in this case, we set β
q
to φ, showing that
the XB-tree over B(q) is exhausted.) As with
TwigStackXB, the entries in B(q)’s will be taken
from the corresponding XB-tree; and many entries
can be possibly skipped. Again, the entries taken
from XB-trees will be reordered as shown in
Algorithm stream-transformation( ). According to
(Bruno et al., 2002), each time we determine a q (∈
Q), for which an entry from B(q) is taken, the
following three conditions are satisfied:
i) For q, there exists an entry v
q
in B(q) such that it
has a descendant in each of the streams B(q
i
)
(where q
i
is a child of q.)
ii) Each recursively satisfies (i).
iii) LeftPos(v
q
) is minimum.
In the case of XB-trees, we modify the function
getNext( ) given in (Bruno et al., 2002) to do the task
and fit it for our strategy, in which the following
functions are used.
isLeaf(q) - returns true if q is a leaf node of Q;
otherwise, false.
currL(β
q
) - returns the leftPos of the entry pointed to
by β
q
.
currR(β
q
) - returns the rightPos of the entry pointed
to by β
q
.
isPlainValue(β
q
) - returns true if β
q
is pointing to a
leaf node in the corresponding XB-tree.
end(Q) - if for each leaf node q of Q β
q
= φ (i.e.,
B(q) is exhausted), then returns true; otherwise,
false.
Function getNext(q) (*Initially, q is the root of Q.*)
begin
1. if (isLeaf(q)) then return q;
2. for each child q
i
of q do
3. {r
i
← getNext(q
i
);}
4. if (there exists at least an r
i
such that r
i
≠ q
i
)
5. then return r
j
such that currL() is minimal
among all r
i
’s and RightPos(r
j
) is maximum
6. else
{q
min
← q’’ such that currL() = min
i
{currL()};
7. q
max
← q’’’ such that currL() = max
i
{currL()};
8. while (currR(β
q
) < currL() do advance(β
q
);
9. if (currL(β
q
) < currL() then return q;
10. else return q
min
; }
end
The goal of the above function is to figure out a
query node to determine what entry from data
streams will be checked in a next step, which has to
satisfy the above conditions (i) - (iii). So the
algorithm works in a recursive way (see line 3 and
condition (ii).) Lines 6 - 9 are used to find a query
node satisfying condition (i). Lines 4, 5, 9 and 10
show that condition (iii) must be met. Special
attention should be paid to line 5. We may have
more than one r
i
’s with the same minimal currL(). In
this case, the one with the maximum RightPos is
returned. It is because the access sequence of the
document nodes will be reordered. This arrangement
enables us to check query nodes (against a certain
document node) in postorder.
Based on the above algorithm, tree-matching( ) is
extended to tree-matchingXB( ) with β
q
’s being used
to navigate different XB-trees, which is controlled
by a specific procedure called XB-navigation( ) (see
below). In addition, for each created node v in T’,
both S
v
and A
v
are handled as global variables. For
each q, R
q
is also a global variable such that for each
v ∈ R
q
T’[v] embeds Q[q].
Algorithm tree-matchingXB(Q)
begin
1. while (¬end(Q)) do
2. {q ← getNext(root-of-Q);
3. if (isPlainValue(β
q
) then
4. {let v be the node pointed to by β
q
;
5. while ST is not empty and ST.top is not v’s ancestor
do
6. {x ← ST.pop(); Let x = (q’, u); (*a node for u will
be created.*)
7. call embeddingCheck(q’, u); }
8. ST.push(q, v); advance(β
q
);
9. }
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
196

10. else call XB-navigation(q);}
end
In the above algorithm, all the entries from data
streams will be visited through XB-trees (see line 3
and 10.) But they will be reordered by using a global
stack ST so that they are handled actually in
postorder (see lines 4 - 9; also see Algorithm stream-
transformation( ) for comparison.) For checking the
tree embedding, Algorithm embeddingCheck( ) is
invoked (see line 7) while for navigating an XB-tree
Algorithm XB-navigation( ) is called (see line 10.)
Procedure XB-navigation(q)
Input: a query node q.
Output: β
q
is changed.
begin
1. if q is the first node (in postorder) then downtrill(β
q
);
2. else {let q’ be the node just before q (in postorder);
3. if q’ is to the left of q then
4. {if empty(R
q’
) ∧ (currL(β
q’
) > currR(β
q
))
5. then advance(β
q
) (*not part of a solution*)
6. else drilldown(β
q
);} (*may have a child in
some solution*)
7. else (*q is the parent of q’.*)
8. if (¬empty(R
q’
) ∨ (currL(β
q’
) > currL(β
q
) ∧
currL(β
q’
) < currR(β
q
))
9. then drilldown(β
q
)
10. else advance(β
q
);
11. }
end
The above procedure shows a way different from
TwigStackXB to control the navigation of XB-trees.
On the one hand, it is because we check the tree
embedding bottom-up. On the other hand, we use
not only ancestor-descendant, but also left-to-right
relationships to control the XB-tree traversal. First,
we examine whether q is the first node in postorder
(see line 1.) If it is the case, we will drill down the
corresponding XB-tree since along the branch we
may find some entries which are part of a solution.
In general, we will check the query node q’ which is
the predecessor of q in postorder. It can be to the left
of q or the right-most child of q. In the former case,
we will compare currL(β
q’
) and currR(β
q
). If
empty(R
q’
) and currL(β
q’
) > currR(β
q
), any entry in
the subtree rooted at the entry pointed to by β
q
,
cannot be part of a solution, so β
q
will be advanced
(see lines 4 - 5.) Otherwise, we will drill down the
subtree to find some entries which might be part of a
solution (see line 6.) A similar analysis applies to
lines 7 - 10.
Procedure embeddingCheck(q, v)
Input: a query nodes q; a document tree node v.
output: a matching subtree T’ of T, D
root
and D
output
.
begin
1. generate node v;
… … (*same as lines 3 – 29 in tree-matching*)
end
5 CONCLUSIONS
In this paper, a new algorithms is presented to
evaluate twig pattern queries based on unordered
tree matching. The main idea is a process for tree
reconstruction from data streams, during which each
node v that matches a query node will be inserted
into a tree structure and associated with a query node
stream QS(v) such that for each node q in QS(v) T[v]
embeds Q[q]. Especially, by using an important
property of the tree encoding, this process can be
done very efficiently, which enables us to reduce the
time complexity of the existing methods such as
Twig
2
Stack (Chen et al., 2006) and One-Phase
Holistic (Jiang et al., 2007) by one order of
magnitude. Our experiments demonstrate that the
new algorithm is both effective and efficient for the
evaluation of twig pattern queries.
REFERENCES
Abiteboul, S., Buneman, P. and Suciu, D., 1999. Data on
the web: from relations to semistructured data and
XML, Morgan Kaufmann Publisher, Los Altos, CA
94022, USA.
Aghili, A., Li, H., Agrawal, D. and Abbadi, A.E., 2006.
TWIX: Twig structure and content matching of
selective queries using binary labeling, in:
INFOSCALE.
Al-Khalifa, S., Jagadish, H.V., N. Koudas, Patel, J.M.,
Srivastava, D. and Wu, Y., 2002. Structural Joins: A
primitive for efficient XML query pattern matching, in
Proc. of IEEE Int. Conf. on Data Engineering.
Bruno, N., Koudas, N. and Srivastava, D., 2002. Holistic
Twig Joins: Optimal XML Pattern Matching, in Proc.
SIGMOD Int. Conf. on Management of Data,
Madison, Wisconsin, June 2002, pp. 310-321.
Chamberlin, D.D., Clark, J., Florescu, D. and Stefanescu,
M., 2002. XQuery1.0: An XML Query Language,
http:/ /www.w3.org/TR/
querydatamodel/.
Chamberlin, D.D., Robie J. and D. Florescu, D., 2000.
Quilt: An XML Query Language for Heterogeneous
Data Sources, WebDB 2000.
Chen, T., Lu, J. and Ling, T.W., 2005. On Boosting
Holism in XML Twig Pattern Matching, in: Proc.
SIGMOD, pp. 455-466.
Choi, B., Mahoui, M. and Wood, D., 2003. On the
optimality of holistic algorithms for twig queries, in:
Proc. DEXA, pp. 235-244.
Chung, C., Min, J. and Shim, K., 2002. APEX: An
adaptive path index for XML data, ACM SIGMOD.
Chen, S., Li, H-G., Tatemura, J., Hsiung, W-P., Agrawa,
D. and Canda, K.S., 2006. Twig
2
Stack: Bottom-up
Processing of Generalized-Tree-Pattern Queries over
XML Documents, in Proc. VLDB, Seoul, Korea, pp.
UNORDERED TREE MATCHING AND TREE PATTERN QUERIES IN XML DATABASES
197

283-294.
Cooper, B.F., Sample, N., Franklin, M., Hialtason, A.B.
and Shadmon, M., 2001. A fast index for
semistructured data, in: Proc. VLDB, pp. 341-350.
Deutch, A., Fernandez, M., Florescu, D., Levy, A. and
Suciu, D., 1999. A Query Language for XML, in:
Proc. 8th World Wide Web Conf., pp. 77-91.
Florescu, D. and Kossman, D., 1999. Storing and
Querying XML data using an RDMBS, IEEE Data
Engineering Bulletin, 22(3):27-34.
Goldman R. and Widom, J. 1997. DataGuide: Enable
query formulation and optimization in semistructured
databases, in: Proc. VLDB, pp. 436-445.
C.M. Hoffmann, C.M. and M.J. O’Donnell, M.J., 1982.
Pattern matching in trees, J. ACM, 29(1):68-95.
Lu, J., Ling, T.W., Chan, C.Y. and Chan, T., 2005 From
Region Encoding to Extended Dewey: on Efficient
Processing of XML Twig Pattern Matching, in: Proc.
VLDB, pp. 193 - 204.
McHugh, J. and Widom, J., 1999. Query optimization for
XML, in Proc. of VLDB.
Seo, C., Lee, S. and Kim, H., 2003. An Efficient Index
Technique for XML Documents Using RDBMS,
Information and Software Technology 45(2003) 11-22,
Elsevier Science B.V.
Li Q. and Moon, B., 2001. Indexing and Querying XML
data for regular path expressions, in: Proc. VLDB, pp.
361-370.
Shanmugasundaram, J., Tufte, K., Zhang, C., He, G.,
Dewitt, D.J., and J.F. Naughton, J.F., 1999. Relational
databases for querying XML documents: Limitations
and opportunities, in Proc. of VLDB.
U. of Washington, 2007. The Tukwila System, available
from http://data.cs.washington.edu.
integration/tukwila/.
U. of Wisconsin, 2007. The Niagara System, available
from http://www.cs.wisc.edu/
niagara/.
U of Washington XML Repository, 2007. available from
http://www.cs.washington.edu/
research/xmldatasets.
Wang, H., S. Park, Fan, W. and Yu, P.S., 2003. ViST: A
Dynamic Index Method for Querying XML Data by
Tree Structures, SIGMOD Int. Conf. on Management
of Data, San Diego, CA.
Wang H. and Meng, X., 2005. On the Sequencing of Tree
Structures for XML Indexing, in Proc. Conf. Data En-
gineering, Tokyo, Japan, April, pp. 372-385.
World Wide Web Consortium, 2007. XML Path Language
(XPath), W3C Recommendation. See http://
www.w3.org/TR/xpath20.
World Wide Web Consortium, 2007. XQuery 1.0: An
XML Query Language, W3C Recommedation,
Version 1.0. See http://www.w3.org/TR/xquery.
XMARK: The XML-benchmark project, 2002.
http://monetdb.cwi.nl/xml.
C. Zhang, C., J. Naughton, Dewitt, D., Luo, Q. and G. Lo-
hman, G., 2001. on Supporting containment queries in
relational database management systems, in
Proc. of
ACM SIGMOD.
Kaushik, R., Bohannon, P., Naughton, J. and Korth, H.,
2002. Covering indexes for branching path queries, in:
ACM SIGMOD.
Schmidt, A.R., F. Waas, Kersten, M.L., Florescu, D.,
Manolescu, I., Carey, M.J. and R. Busse, 2001. The
XML benchmark project, Technical Report INS-
Ro1o3, Centrum voor Wiskunde en Informatica.
Jiang, Z., Luo, C., Hou, W.-C., Zhu, Q., and Che, D.,
2007. “Efficient Processing of XML Twig Pattern: A
Novel One-Phase Holistic Solution,” In Proc. the 18th
Int’l Conf. on Database and Expert Systems
Applications (DEXA), pp. 87-97.
Bar-Yossef, Z., Fontoura, M., and V. Josifovski, V. 2007.
On the memmory requirements of XPath evaluation
over XML streams, Journal of Computer and System
Sciences 73, pp. 391-441.
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
198
