
AN EXPERIENCE IN APPLYING MODEL-DRIVEN
ENGINEERING FOR AN ENTERPRISE MANAGEMENT
SYSTEM
Rodrigo García, Juan C. Dueñas, Félix Cuadrado
Universidad Politécnica de Madrid, ETSI Telecomunicación
Ciudad Universitaria s/n, 28040, Madrid, Spain
José Luis Ruiz
Indra, c/José Echegaray 8,28108, Parque Empresarial - Las Rozas, Madrid, Spain
Keywords: MDE, Enterprise Development, Information Systems, Report on Experience.
Abstract: The development of an enterprise management system is a very complex process. It must be able to
efficiently manage the heterogeneity and complexity of the enterprise infrastructure and services. This
situation is resolved by adopting a generic information model and reasoning over it. Moreover, the system
must support non-functional requirements, such as scalability or reliability. In this domain, these
requirements have matured into a cumbersome enterprise framework ecosystem, imposing a steep learning
curve to the development team. This paper presents a case study that tries to address these concerns. We
have applied MDE (Model-Driven Engineering) techniques and tools in order to reduce the coding effort
and partially abstract from the complexity. We detail here the decisions behind the followed process, and
provide a complete report on our experience, discussing the strong points and the limitations found in both
our approach and the supporting tools.
1 INTRODUCTION
Enterprise service management systems are very
complex and costly to develop. Its purpose is the
control and automation of the life cycle of software
services across a distributed and variable
environment. They must adapt to heterogeneous
distributed environments, controlling, processing
and managing large amounts of data. Also, their
internal architecture must support rapid system
evolution, in order to keep pace with new business
requirements. On top of that, non-functional
characteristics such as robustness and security must
be maintained.
When we were confronted with the task of
developing this kind of system we looked for
alternatives in order to simplify its complexity.
MDE (Model Driven Engineering) (Schmidt, 2006)
promises to speed the development and reduce
complexity by the abstraction of real entities into
models, and the application to them of automatic
code generation operations. Therefore, we opted to
integrate MDE techniques and tools in our
development process.
In this article we present a report on our
experience developing the system. Next section
provides an overview over the most important
concepts of MDE. Section 3 provides additional
information about the target domain, the reasoning
behind the adopted approach and the tool selection.
The fourth section provides additional details on the
case study, detailing the generation processes and
system architecture.
Finally, complete discussion on the results and
lessons learned after the development is provided,
offering some guidelines for similar experiments.
2 MODEL-DRIVEN
ENGINEERING
MDE is a methodology based on the use of abstract-
21
García R., Dueñas J., Cuadrado F. and Ruiz J. (2009).
AN EXPERIENCE IN APPLYING MODEL-DRIVEN ENGINEERING FOR AN ENTERPRISE MANAGEMENT SYSTEM.
In Proceedings of the 4th International Conference on Software and Data Technologies, pages 21-27
DOI: 10.5220/0002257400210027
Copyright
c
SciTePress

tions of entities called models. They only contain the
information relevant to a particular domain, being
oblivious to the remaining details. Their constraints,
characteristics and semantics are well defined
through metamodels (which are also models),
avoiding ambiguities.
The OMG (Object Management Group) is the
main standardization organization for MDE
languages and processes. Some of its most relevant
specifications are MOF (OMG, 2006), a language
used for the definition of metamodels, or UML,
which is in turn defined using MOF.
MDE processes consist of several kinds of
transformations, being model to model and model to
text the most prominent. An example model-to-
model transformation allows the enrichment and
modification of the definitions of Platform
Independent Models (PIM) until they are
transformed to Platform Specific Models (PSM).
These processes can be automated through the use of
transformation languages, such as QVT (Query,
View, Transformation).
Code generation activities are the most
representative applications of model-to-text
transformations. A PSM with enough information
can be used to automatically generate the actual
source code of the system. In less ideal cases, the
generated code base is completed with manual
implementation.
Adopting MDE can provide many benefits to the
development process. It allows the partial (and in
some cases complete) automation of several
activities and eases the response to changing
requirements or domain specifications. Also, it
allows the expression of the problems that need to be
solved in a more comprehensible way, providing to
architects a clearer view of the system entities.
Applying MDE to the development of enterprise
systems has the potential to greatly help in the
fulfillment of their particular characteristics
(Frankel, 2003). Enterprise management systems
present many similarities in the software
infrastructure and basic requirements such as
communications, or data persistence, which can be
captured in model and transformation definitions.
The usage of MDE techniques allows the
automation of specific operations and brings
“information hiding” principles to the development
process, fostering specialization. Work towards
solving specific enterprise domain problems using
MDE has been performed recently and has shown
positive results (Quartel, 2008) (White, 2007).
However, a considerable effort may be needed
for the assimilation of these practices. Thus, the key
limiting factor for its enterprise adoption is the
availability of a comprehensive and mature tool
chain that seamlessly integrates with the
development processes and the specific
technologies.
3 CASE STUDY DESCRIPTION
3.1 System Requirements
The system under development is an enterprise
service management architecture. Its purpose is the
control and automation of life cycle of software
products and services across distributed
environments. The system will manage information
about the physical structure of the target
environment, its runtime state, the available software
and services, and the dependencies between them. It
will interact with the physical elements through a
well-defined information model, in order to abstract
from the complexity and heterogeneity of enterprise
systems.
The development of an enterprise system like the
one described in this paper is a complex process.
The system must be deployed over a distributed
environment, and operate with an adequate quality
of service, ensuring its high availability, fault
tolerance, or scalability. Some representative non-
functional requirements are:
• Information consolidation is a fundamental
requirement for any management system.
Runtime state, statistics, operation logs and
system resources must be persisted, sorted and
related between each other.
• System components are designed in a
decoupled, distributed way, which in turn
imposes a need to expose remote
communication mechanisms.
As these requirements are common to most
enterprise services, in the latest years several
frameworks and specifications have been developed
to provide pre-packed solutions to these aspects. In
fact, they have been so useful that its popularity has
turned them into additional requirements for the
developed services. However, the result is a
framework sprawl where the complexity has shifted
from the original requirements to a well-established
architecture and technology base.
3.2 Technical Approach
After analyzing the characteristics and requirements
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
22

of the system, we tried to address these concerns by
adopting MDE techniques and tools in our
development process. We wanted to achieve two
main objectives: First, by using the code generation
capabilities of MDE tools, we tried to reduce the
development effort of the described system,
improving development productivity. Second, by
selecting which parts of the system will be
generated, we wanted to abstract as much as possible
from the non functional concerns and the enterprise
frameworks, which were not familiar to the
development team.
There also was an additional factor supporting
the adoption of this approach: the existing
information model. As this model is the central
element of the management system, it must be
comprehensively modeled in the analysis stage. This
will provide us with an initial input for the selected
MDE tool chain. However, it is important to note
that it only describes the information and not the
system behavior.
In order to apply this approach it is necessary to
choose a modeling solution. In this process not only
the metamodeling language must be selected
(powerful, flexible and based upon open and widely
adopted standards). The specific requirements of our
development process will fundamentally impact the
tool support for modeling and code generation. We
established the following criteria:
• Comprehensive Java code generation
functionality from the available models. The
system requirements mandate a Java
development, supported by several enterprise
frameworks.
• Maturity of the tools. An unfinished or beta
solution should be discarded, as tracing errors
caused by the code generation are very difficult
and costly to detect.
• Out-of-the-box transformations for abstracting
from the required frameworks and non-
functional concerns (e.g. information
persistence through ORM frameworks).
Manually defined transformations will not be
adopted, as they require the acquisition of a
deep understanding in both the transformation
language and the underlying framework.
Because of that, we will partially adopt an
MDE approach.
• Quality of documentation and gentle learning
curve. As we will work over the MDE tools, a
fundamental factor for its selection is the
required effort for applying the technology to
our specific problem.
3.3 Tool Selection
After comparing the decision criteria with the
available models and tools we chose the following
options:
We selected EMF (Eclipse Modeling
Framework) (Steinberg, 2008) ECore as the
modeling language for the definition of the
information model. EMF is a modeling framework
that provides both an implementation of EMOF
(Essential MOF) named ECore and a set of
supporting tools for defined metamodels, which
automatically provide editors for defining model
instances, a set of transformations between ECore,
XSD and Java, XML-based model persistence and
unit test cases. EMF is a very mature and popular
project, which has fostered a very active open-
source community around the project, providing
multiple tools, languages and transformations on top
of it.
As our system should support heavy workloads
and preserve data integrity, we could not use the
base XML serialization provided by EMF, needing
relational database support instead. Teneo is an EMF
extension that provides a database persistence
solution by generating a direct mapping between
ECore models and Java ORM (Object Relational
Mapping) frameworks, automatically generating the
mapping files from the ECore elements. Teneo
supports two different types of ORM solutions,
Hibernate and JPOX/JDO. We used Hibernate
because is the de-facto industry standard (and
compatible with the EJB 3.0 specification). It also
offers a simplified management interface for the
relational operations.
Another system requirement is the ability to
distribute the components providing a Web Services
remote communication layer on top of the business
logic. Web Services is the leading standard for
enterprise distributed communications. It promotes
contract-based design and loose coupling, through
well-defined XML documents for both the contract
definition and the information exchange. The
contract is expressed through WSDL (Web Services
Description Language) files.
The format of the messages in Web Services is
specified inside the WSDL descriptor by XSD
(XML Schema Definition). Since EMF allows the
usage of XSD for the definition of metamodels, we
wanted to use these XSDs to create part of the
WSDL. For the implementation of Web Services we
chose Spring Web Services, a contract-first Web
Services framework which was part of our enterprise
middleware layer.
AN EXPERIENCE IN APPLYING MODEL-DRIVEN ENGINEERING FOR AN ENTERPRISE MANAGEMENT
SYSTEM
23
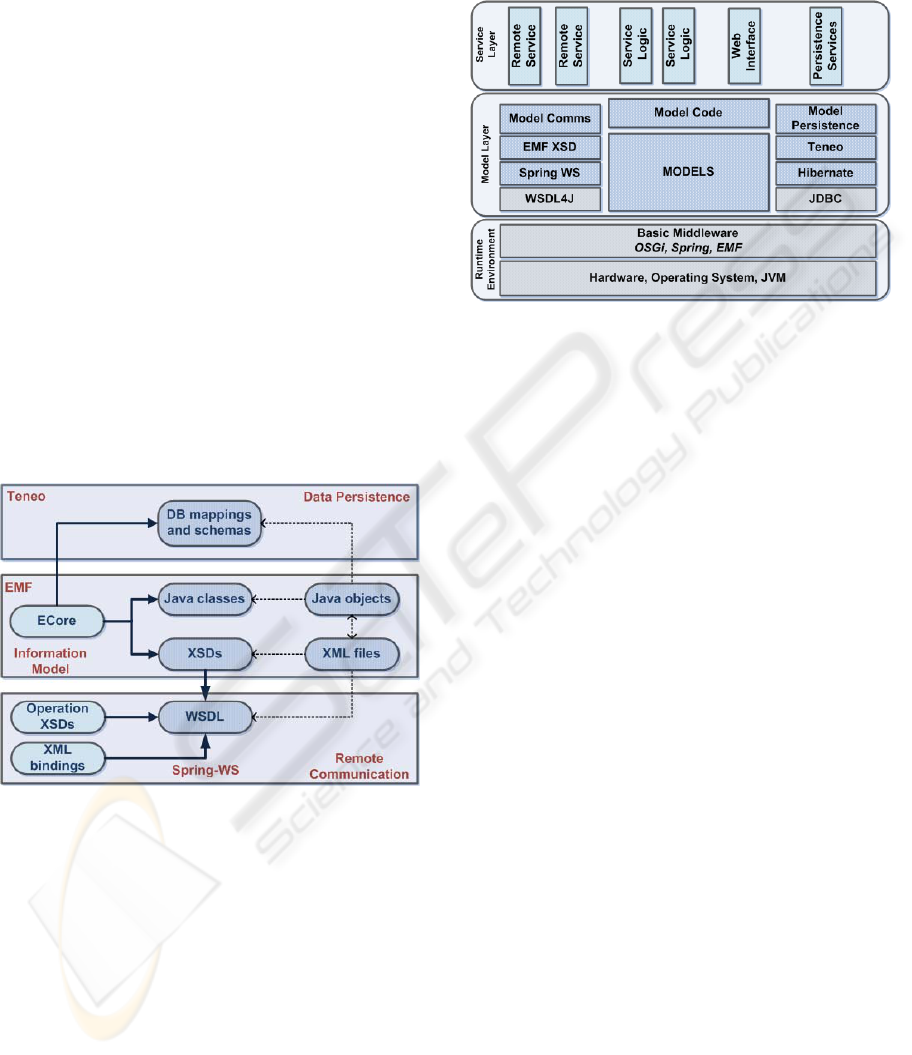
The selected tools (EMF, Teneo, Spring-WS)
partially address our requirements. They support the
definition of both models and metamodels and their
transformation to database mappings, WSDL files
and Java source code. We chose these solutions
discarding more generic transformation model tools
because of the previously mentioned requirements
(out-of-the-box functionality, abstraction from
middleware layers, simplicity and ease of learning).
Figure 1 depicts the relations between these tools
and how they work to generate the base artifacts for
different aspects of the system (logic, persistence,
and communications). In the middle box, EMF
automates the generation of both Java classes and
XSD files which represent the metamodels obtained
from the ECore information model. On the data
persistence layer, Teneo automates the generation of
database mappings and schemas from the same
ECore model that was used in EMF.
Lastly, on the remote communication domain,
Spring-WS generates a WSDL descriptor from the
XSDs created in the information model layer, XSDs
specifying the operations of the interface and XML
bindings of the remote interfaces to Java code.
Figure 1: Transformation flows.
4 REPORT ON EXPERIENCE
4.1 System Description
As we have described previously, the developed
system is a distributed enterprise application, with
multiple entities collaborating to provide the
required functionality. For its design we have
followed a layered architecture, adopting the
middleware open-source stack (Spring, OSGi,
Hibernate, Web Services) for modular, enterprise
applications. The adoption of middleware and
framework components greatly reduces the coding
effort, and promotes best practices for solving
common concerns of every development project.
Figure 2: System structural view.
Figure 2 shows a model-focused structural view
of one component of our distributed system. It
shows three different areas. The system runs over a
runtime environment, formed by hardware,
operating system, a Java virtual machine and a set of
provided libraries, On top of this substrate reside the
models layer. These components are the result of our
generation process. Finally, the third group is
composed by the actual functionality of the
application, the service layer. Developers should
focus only on these elements, which are the business
logic units, user interfaces, remote services, and
inventory services. As the model layer provides
automatic transformations it abstracts from the
middleware infrastructure in charge of the remote
serialization and persistence.
4.2 Process Practices
With the characteristics of the selected tools and the
requirements of the system in mind we defined a
flow for the detailed design and implementation
activities. Figure 3 shows its steps and the transitions
between them. The application of MDE translates
into the following tasks:
• Definition of models using MDE models and
metamodels.
• Modification of already created models, in order
to adapt them either by using transformations
(model-to-model) or by hand (model tuning).
• Generation of code from the models, mainly
using model-to-code transformations.
• Modification of generated code (code tuning).
• Implementation of code not covered by MDE,
which in our case pertains to the system logic.
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
24
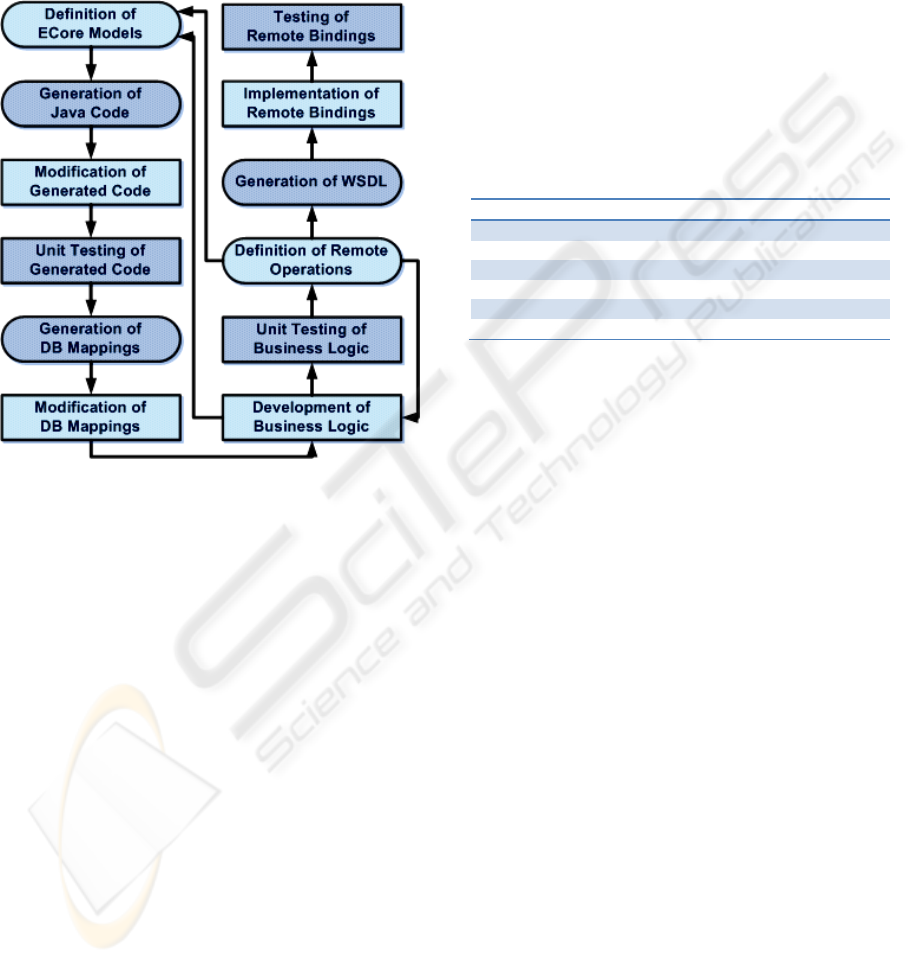
• Testing of both the generated and manually
created elements.
Concerning testing it is important to note that
EMF generates unit tests that validate the generated
source code. Therefore, the testing tasks can be
performed with automatically created or hand-
written tests.
Figure 3: Development process.
5 DISCUSSION
This section provides additional discussion on the
followed approach after its completion. We will
present both a small quantitative analysis of the
finished system and a summary of the lessons we
have learned. We think that information can be
useful to not only evaluate the success of the
approach but also improve similar processes.
5.1 Quantitative Analysis
To evaluate the generated code some metrics have
been performed. The results of this analysis are
depicted in Table 1.
The first two rows contain the most basic
information that can be obtained: the raw number of
lines of code and Java classes. It is important to note
that the size of the modeled part weights roughly
half of the system (60.000 lines of code excluding
libraries). Most of this code contains the information
model and the XML serialization engine.
The remaining rows comprise some software
metrics that try to measure the quality of the code.
Efferent couplings indicates how focused are the
classes. The remaining metrics (cyclomatic
complexity, number of lines per method and number
of locals) indicate the complexity and
comprehensibility of the code. All the values are
averages for all the classes or methods.
Since generated and manually written code
cannot be compared side by side, we compared the
amounts of code of the model definitions and the
generated elements. The model definitions span
1609 lines, the ratio is of 20.6 Java lines generated
per line of model definition written.
Table 1: Code metrics.
Metric Value
LinesofCode 33125
Classes 290
AverageEfferentCouplings 6.91
AverageCyclomaticComplexity 2.06
AverageNumberofLinesperMethod 13.63
AverageNumberofLocals 1.44
5.2 Lessons Learned
During the process we identified some critical risks
for the success of the development with this
approach. Most of these pitfalls could be avoided
taking some factors into consideration. Further on,
we expose the most remarkable issues:
Application of Mature Transformations. Our
intent with the described generation process was to
take models as a foundation, trying to abstract
whenever possible of the specific middleware for the
previously described concerns, such as persistence
or remote communications.
Although our experience was positive (used
these capabilities seamlessly over the model layer),
we found some problems using one of the
transformation frameworks (Teneo 0.8): its data
persistence service did not work as expected in
common situations (updating operations). Detection
of such failures was difficult because the source of
problems could be in any of the layers, and we had
to jump into their source code, losing the theoretical
advantages of abstraction. Therefore, tool and
framework maturity are a fundamental risk to be
assessed for adopting this type of approach.
Limits in the Abstractions. We were also affected
by the law of leaky abstractions (Spolsky, 2004), as
the transformations hid useful concepts in the lower
levels that could only be obtained by respecting
AN EXPERIENCE IN APPLYING MODEL-DRIVEN ENGINEERING FOR AN ENTERPRISE MANAGEMENT
SYSTEM
25

these low-level constraints in the business logic
(lazy loading from the database improves efficiency
but imposes session management in the upper layer).
Model Definition Accuracy. The success of the
complete development is heavily dependent on this.
During our development, an error in the business
logic was finally traced to a mistake in the definition
of the information model. We expressed a
relationship between elements as a composition
instead of an aggregation, and the generated code
did behave as we defined (but not intended).
Application of Corrective Changes. Probably the
most important model transformation that a solution
can offer is the generation of code. In our experience
almost all the chosen solutions behaved perfectly on
this matter. However, the generation process can in
some cases be far from perfect and the generated
code could not be used directly.
We experienced this drawback with Teneo. The
generated mapping files had to be manually edited to
solve various problems. The greatest time sink here
was to trace the failure to the generated model and
figure what tweaks were needed.
On the other hand, the automatic generation of
unit test cases that EMF provided helped greatly to
discard those models as the source of any failure.
Application of Perfective Changes. Sometimes the
generated elements do not accomplish all the goals
that have been set. In these situations the missing
features have to be implemented into the generated
code by hand. If the generated artifacts are well
documented and easily readable applying these
improvements is a good way to build over the base
functionality.
In our case, the code generated by EMF lacked
proper methods for asserting the equality between
two elements, managing collections or generating a
unique identifier. Their implementation did not
require a deep knowledge of EMF. With the help of
annotations to preserve these non-generated methods
in future transformations and thanks to the clean and
organized code generated, the application of these
perfective changes was straightforward.
Cost of Starting a New Iteration. It is very
common during the development to go back to a
previous point, make some changes and continue the
process from there. This causes the redefinition of
models and regeneration of code. In these cases it is
very important to keep track of all the manual
changes and procedures that have to be applied after
finishing the automated tasks. For instance,
performing the correct code modifications after its
regeneration.
Therefore, is vital to have a detailed and
documented process for the development with MDE.
We addressed this point by adopting the detailed
flow shown in previous sections.
Coverage of Transformations. MDE is based upon
transformations. However, special attention needs to
be put in the system parts where the needed
transformations are not automatically performed.
These sections must be reviewed after each code
regeneration operation and usually must be manually
implemented, following the underlying elements.
During the development of the system we found
that Spring Web Services, although generated the
WSDL, lacked the tools to do the same with the
bindings between the logic and the interfaces. In the
end we implemented those bindings manually.
However, in retrospective we think that defining and
implementing these transformations could have been
a better solution. The workload would have been
similar but in further iterations the benefits of
extending MDE coverage would have been
considerable.
6 CONCLUSIONS
In this case study we have developed a real-world
enterprise management system in a model-centric
view through MDE processes. This approach has
allowed us to implement some non-functional
requirements such as remote communications or
information persistence with model transformation
techniques and tools, using available open source
tools and libraries.
The results obtained during this development
have been satisfactory. The reduced effort obtained
by the code generation capabilities greatly helped to
speed the process. The general perception of both
the developers and project managers are that the use
of these methodologies, albeit the problems faced,
has eased the development process and improved the
quality of the produced system. It seems clear that
the characteristics of the enterprise domain make it
perfectly-suited for automating the generation of
parts of the system.
However, regarding the level of achieved
abstraction from the middleware layers we identified
several key factors that greatly impact the results in
this area. We believe that our lessons learned in this
case study can help with the execution of similar
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
26

processes to greatly reduce the risks involved and
shorten the development cycles.
ACKNOWLEDGEMENTS
The work presented here has been performed in the
context of the CENIT-ITECBAN project, under a
grant from the Ministerio de Industria, Comercio y
Turismo de España.
REFERENCES
Steinberg, D.; Budinsky, F.; Paternostro, M; Merks, E.,
December 2008. EMF: Eclipse Modeling Framework,
Second Edition, Addison-Wesley Professional. ISBN:
978-0321331885.
Frankel, D.S., January 2003. Model Driven Architecture:
Applying MDA to Enterprise Computing, Wiley.
ISBN: 978-0471319207.
Schmidt, D.C., February 2006. Guest Editor’s
Introduction: Model-Driven Engineering. In
Computer, Volume: 39, Issue: 2, Pages: 25–31.
Object Management Group, January 2006. Meta Object
Facility Specification 2.0. Available online in:
http://www.omg.org/spec/MOF/2.0/
Quartel, D.; Pokraev, S.; Pessoa, R.M.; van Sinderen; M.,
September 2008. Model-Driven Development of a
Mediation Service. In 12
th
International IEEE
Enterprise Distributed Object Computing Conference.
White, J.; Schmidt, D.C.; Czarnecki, K.; Wienands, C.;
Lenz, G., October 2007. Automated Model-Based
Configuration of Enterprise Java Applications. In 11
th
International IEEE Enterprise Distributed Object
Computing Conference.
Spolsky, J., August 2004. Joel on Software, Apress. ISBN:
978-1590593899.
AN EXPERIENCE IN APPLYING MODEL-DRIVEN ENGINEERING FOR AN ENTERPRISE MANAGEMENT
SYSTEM
27
