SEMI-SUPERVISED LEARNING OF DOMAIN-SPECIFIC
LANGUAGE MODELS FROM GENERAL DOMAIN DATA
Shuanhu Bai and Haizhou Li
Institute for Infocomm Research, 1 Fusinaopolis Way, #21-01 Connexis, Singapore 138632
{sbai, hli}@i2r.a-star.edu.sg
Keywords: Machine learning, Natural language processing, Language model, Topic model.
Abstract: We present a semi-supervised learning method for building domain-specific language models (LM) from
general-domain data. This method is aimed to use small amount of domain-specific data as seeds to tap
domain-specific resources residing in larger amount of general-domain data with the help of topic modelling
technologies. The proposed algorithm first performs topic decomposition (TD) on the combined dataset of
domain-specific and general-domain data using probabilistic latent semantic analysis (PLSA). Then it
derives weighted domain-specific word n-gram counts with mixture modelling scheme of PLSA. Finally, it
uses traditional n-gram modelling approach to construct domain-specific LMs from the domain-specific
word n-gram counts. Experimental results show that this approach can outperform both stat-of-the-art
methods and the simulated supervised learning method with our data sets. In particular, the semi-supervised
learning method can achieve better performance even with very small amount of domain-specific data.
1 INTRODUCTION
LMs are widely used in various natural language
processing (NLP) applications such as text mining,
machine translation and speech recognition systems.
AS we know that the performances of LMs are
highly domain-dependent. Traditional approach
alleviates this problem by adapting a background
model with the data collected from the similar
application domains, which is called domain
adaptation. In order to achieve better performance,
domain specific application systems usually require
LMs to be built fully with domain-specific data for a
very particular task. Existing learning algorithms for
building these LMs rely heavily on the availability
of high-quality domain-specific data. Collecting
enough such data in most cases is not an easy task,
and it is much more difficult to achieve when we are
presented with a new domain. On the other hand, we
may have large amount of general-domain data on
hand. Tapping into such cheaper resources to
alleviate the shortage of domain-specific data seems
to be a good choice.
The efforts for building domain-specific LMs
have been mostly spent on the issue of obtaining
training texts from sources such as the Web
(Sarikaya et al., 2005; Sethy et al., 2006; Wan and
Hain, 2006). Although much of unnecessary data
can be filtered out by search engines, the data
collected from the Web is still far from direct use.
Some semi-supervised methods are employed to
identify useful sentences using selection criterions
such as BiLingual Evaluation Understudy (BLEU)
(Sarikaya et al., 2005) and relative entropy (Sethy et
al., 2006). Text data selection schemes can be
regarded as text/sentence classification methods.
Texts or sentences falling into the domain class are
used for LM training. In a similar effort, Liu and
Croft (2004) create cluster-based LMs for
clustering-based retrieval using clustered corpus.
Recently, topic modelling methods have been
introduced into language modelling efforts for
unsupervised topic adaptation (Gildea and Hof-
mann, 1999; Tam and Schultz, 2005; Heidel et al.,
2007; Liu, 2007). Although these methods can not
be directly used for generating high performance
domain-specific LMs, but their basic idea of using
latent topic as means to tap into domain-specific
knowledge is heuristic for our semi-supervised
learning. On the other hand, semi-supervised
learning techniques have been successfully used in
other NLP tasks such as text classification systems
using small number of labelled texts and larger pools
of unlabeled texts (Nigam et al.,2000; Druck et al.,
2007; Xue et al., 2008).

In this paper, we focus the problem of learning
domain-specific LMs from less domain-specific data
in a semi-supervised manner. Given a small domain-
specific dataset
I
D
, we are going to build a domain-
specific LM by taping into available larger general-
domain dataset
G
D
for “useful” information. Our
goal is to utilize this information in
G
D
to composite
for the insufficiency of domain data
I
D
to build
higher performance LMs. The key idea of our
approach is to use latent topics of a topic model as a
means of learning to obtain domain-specific
language use knowledge from general-domain data.
We can make use of the TD mechanisms of a topic
model to derive document-dependent topic
distribution of the documents in the training sets.
Their topic distributions may appear similarity to
some extent if documents from
I
D
and
G
D
share
some similar topics. Thus the topic distributions of
the documents actually provide a bridge between
dataset
I
D
and
G
D
. It allows us to derive language
uses such as n-grams in
G
D
that are highly
associated with topics that
I
D
prefers. Domain
specific n-gram data can further be obtained from
topic-specific data and topic-mixture modelling
scheme of PLSA. The major advantage of this
learning approach is that it is able to yield high
performance LMs with very small amount of
domain-specific data.
The rest of the paper is organized as follows:
Section 2 will be dedicated to detailed introduction
to the modelling methods as well as the learning
algorithm. We show the experimental results in
section 3, and conclude our paper with section 4.
2 LEARNING METHOD
2.1 Learning Strategies
In this section we introduce our semi-supervised
learning method with the help of PLSA topic
modeling technologies (Hofmann, 1999, 2001).
Under the framework of PLSA, word
w
distribution
in document
d
can be described as mixture of latent
topics
t :
)|()|()|( twpdtpdwp
t
∑=
(1)
where
)|( dtp
represents topic distribution of the
documents, while
)|( twp
represents mixture
components in the form of word unigram model.
Both
)|( dtp
and
)|( twp
can be obtained by applying
expectation maximization (EM) algorithm on the
likelihood of a document collection. The training
process is referred to as topic decomposition (TD).
Suppose we have a combined dataset
IG
DDD ∪=
, we
treat
I
D
not only as a set of documents, but as a
domain as well. After applying TD on data
D
, we
can approximate latent topic distribution of
I
D
by
treating
I
D
as a single document, which can be
expressed as:
),|'(),(
),|(),(
)|(
',,
,
wdtpwdn
wdtpwdn
Dtp
II
tdw
II
dw
I
I
I
∑
∑
=
(2)
where
I
d
represents the elements of
I
D
and
),( wdn
I
is the count of word
w in document
I
d
. In PLSA
),|( wdtp
I
is interpreted as the probability of topic t is
used by document
I
d
to generate word w , thus the
term
),|(),( wdtpwdn
II
is the number of times
topic t is used by
I
d
for generating w . We can use
the E step of TD method (Hofmann, 2001) to
evaluation of
),|( wdtp
I
.
Topic distribution
)|(
I
Dtp
can be regarded as the
latent topic preference of the domain represented
by
I
D
. Since the topic-specific LMs will be working
in the same domain as
I
D
represents, we assume that
the topic distribution of incoming documents could
be simply modelled by
)|(
I
Dtp
during decoding.
Therefore, the domain-specific LM can be expressed
as:
),|()|()|( thwpDtphwp
I
t
I
∑=
(3)
where
),|( thwp
are topic-specific n-gram models.
It is more reasonable to assume that
),|( thwp
are
word unigram models because that is the assumption
of PLSA. Latent topics here only serve as
intermediate variables in building the domain-
specific models and are summed out afterwards.
Now the problem becomes the issue of TD and
derivation of high-order n-gram models
),|( thwp
.
2.2 Weighted Topic Decomposition
We know that the parameters of PLSA topic models
are estimated from the entire dataset through EM. As
it is assumed at the very beginning, we may have
only a few domain-specific texts available, and there
are plenty general-domain texts on hand. If we feed
the combined dataset into the training process
indiscriminately, the determining force for
parameter estimation will be dominated by the
general-domain data and the effect of domain-
specific data may be ignored. The solution for such
problems is to use multi-conditional learning scheme

(Druck et al., 2007) where a weighted objective
function can be used, which can be specified as:
λ
);();()( ΘΘ=Θ
GI
DPDPO
(4)
where
);( Θ
I
DP
and
);( Θ
G
DP
represent the likelihood
of domain-specific data
I
D
and general-domain data
G
D
. A new parameter
λ
introduced into the
likelihood function, can decrease the contribution of
the general-domain data to parameter estimation
when we choose
10
≤
≤
λ
. In practice, it is
convenient to maximize the log-likelihood of
O
:
);(log);(log)(log Θ+Θ=Θ
GI
DPDPO
λ
(5)
It is obvious that the different likelihoods of
I
D
and
G
D
share the same set of parameters. The
learning objective is to choose the model parameters
Θ
ˆ
that maximize the log likelihood. When we apply
this learning strategy to PLSA framework specified
by Eq.(1), the log-likelihood of general-domain data
in Eq.(5) can be expanded as:
)|(log),():(log
GG
d
w
G
dwpwdnDP
G
λ
λ
∑∑=Θ
(6)
where
GG
Dd ∈
,
),( wdn
G
is the count of word w in
document
G
d
and
)|(
G
dtp
can further be expanded
by Eq.(1). Most importantly, we notice that
parameter
λ
is always coupled to the counts
),( wdn
G
in the log-likelihood function, therefore it can be
regarded as a weighting factor for the document-
word counts of the general-domain data. We can use
a revised EM algorithm for PLSA model training,
which is very much similar to EM
λ
−
of Nigam
(2000).
2.3 Weighted N-gram Counts
PLSA topic model is known as a mixture model and
its mixture components are word unigram models.
Our objective is to derive high-order mixture
components for better performances. A direct
solution for building high-order mixture components
is to derive topic-specific n-gram counts first. Then
the topic-specific n-gram models can be constructed
with conventional n-gram modelling method from
the counts. For the convenience of later discussion,
we use
hw
to represent a word n-gram sequence.
Here
h
stands for a word sequence of length
1
−
n
, it
becomes an empty string when word unigram is
represented,
w
is an arbitrary word. Given a
document set
D
and
Dd∈
, if we take the view that
)|( dtp
is the result of soft classification of the
documents in
D
, then the count of n-gram
hw
in
the training corpus with respect to latent
topic
t
),( thwc
becomes
)|(),( dtphwdc
d
∑
. As
)|( twp
got from TD are considered to be better optimized,
thus we use PLSA topic modelling assumptions to
derive topic-specific word unigram counts
),( twc
with
),|(),( wdtpwdc
d
∑
, where
),|( wdtp
is the
probability that topic
t
is used by document
d
for
generating word
w
. By taking the weighting
factor
λ
for datasets
G
D
and
I
D
into consideration,
can be express as:
1
1
),|(),()(
)|(),()(
),(
=
>
⎩
⎨
⎧
∑
∑
=
n
n
wdtphwdcd
dtphwdcd
thwc
d
d
δ
δ
(7)
where
),( hwdc
is the original count of n-gram
hw
in document
d
,
)(d
δ
will be the weighting factor
λ
whenever
d
is in
G
D
, and will be 1
whenever
d
is in
I
D
.
After topic-specific n-gram counts have been
derived, we can estimate topic-specific n-gram
model parameters with maximum likelihood
approach, which can be expressed as:
),(/),(),|( thcthwcthwp ⋅
=
(8)
where
),( thn
⋅
represents the count of the word
sequence
h
followed by any word. By using Eq.(3)
and Eq.(8), we can further specify the domain-
specific model as follows:
),(/),()|()|( thcthwcDtphwp
I
t
I
⋅∑=
),(
),(
),()|(
),(
1
thwc
thc
khcDtp
khn
I
t
⋅
⋅
∑
⋅
=
),(),(
),(
1
thwcth
khc
t
α
∑
⋅
=
(9)
where
k
theoretically can be any of
t
. For the
convenience of later smoothing, we let
),( khc ⋅
be the
mean of
),( thc
⋅
to obtain the domain-specific n-gram
counts
),(),( thwcth
t
α
∑
, which can be regarded as
the mixture of topic-specific n-gram counts
),( thwn
with mixture weights:
),(/),()|(),( thckhcDtpth
I
⋅⋅=
α
(10)
Therefore, the modelling effort is changed from
mixture of probabilities to mixture of counts. That is,
instead of estimating the probability parameters for
each of the component models, we can conduct
count merging first. Thus we can save the smoothing
efforts for each individual topic-specific model. This
process can also be regarded as an n-gram weighting
scheme (Hsu, 2008) using topic distribution of
documents and topic distribution of domain.
Afterwards, the domain-specific models can be built
from the final counts by applying smoothing
methods such as cut-off and back-off technologies.
3 EXPERIMENTS
3.1 Datasets
Our experiments are carried out with part of LDC
corpus NA_News98 and some data from
20Newsgroups(http://people.csail.mit.edu/jrennie/20
Newsgroups/ , version 20news_bydate).
Table 1: Data sets used in the experiments.
Data Source # of Docs
G
D
NA_NEWS98 part of
NYT/1997
Total: 106,431
cat=’s’: 13,239
Easy
I
D
NA_NEWS98 part of
NYT/1998 with cat=‘s’
100 / 500 / 900 /
1300 / 1700
Hard
I
D
20NEWSGROUP in
category ‘sci.med’
400
Easy
I
D
test set
NA_NEWS98 part of
NYT/1998 with cat=‘s’
500
Hard
I
D
test set
20NEWSGROUP
in category ‘sci.med’
100
Table 1 shows the structure of the datasets used
in our experiments. Because texts of NA_News98
are well categorized into different domains, it
enables us to conduct simulation experiments using
comparatively larger scale datasets. Dataset
G
D
is
built by randomly choosing texts from subset
NYT/1997, it consists of total 106,431 documents,
among which 13,239 documents are in the category
of ‘s’ (sports). We compile two groups of
I
D
, one is
referred to as “easy domain” where the documents
are selected from subset NYT/98 with the same
category ‘s’. We call it “easy domain” because
G
D
does contain documents of the same domain as
I
D
does. In order to study the relationship between the
amount of domain-specific data and performance of
our learning algorithm,
I
D
s in this group are created
in different size. We also compiled a
I
D
of a “hard
domain” form 20Newsgroups of the category
‘sci.med’ standing for medical domain. We call it
hard domain because
G
D
hardly contains documents
of the same domain as
I
D
does. Given
datasets
G
D
and
I
D
, document-word tables for TD are
built by applying a stop-word list around 500 entries
and words with original counts of less than 3 are not
used. The vocabulary of the most frequent 60K
words for each model is selected from the weighted
counts when semi-supervised learning method is
used. We use word tri-gram models in our
experiments unless it is specially mentioned.
3.2 Experiments on Easy Domain
To investigate whether the learning algorithm can
effectively tap into the domain knowledge residing
in general-domain data, we create domain-specific
document sets
sD
I
in the domain of sports in
different size, as is indicated by Easy
I
D
in Table 1.
For comparison purpose we build different models
from both
G
D
and
sD
I
using different approaches.
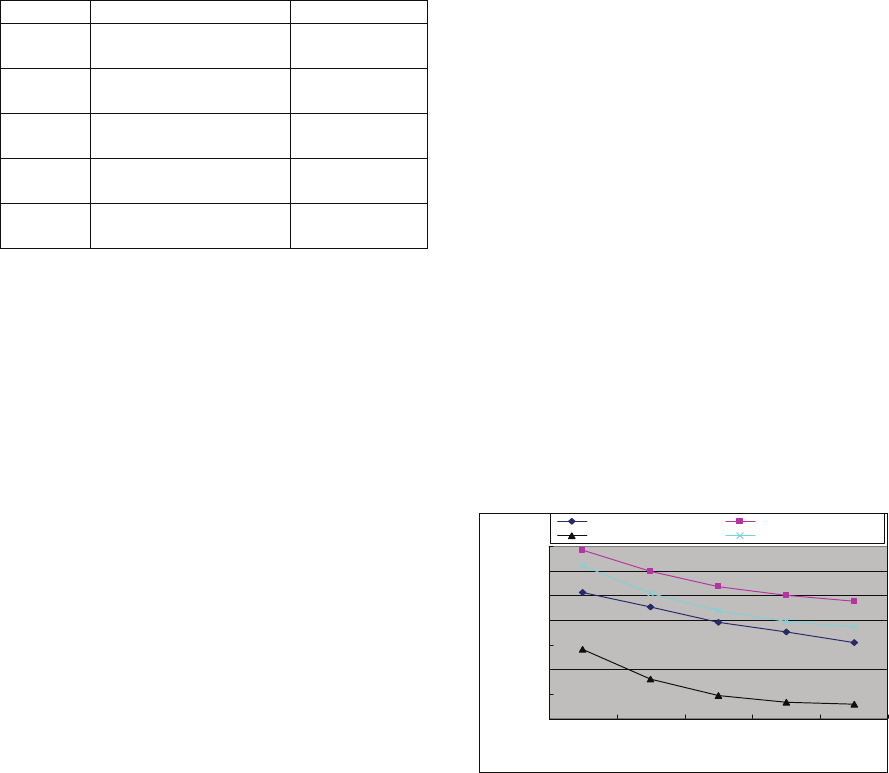
Figure 1 shows the perplexity test results. Model of
supervised learning means it is built from a
I
D
as
well as the documents of category ‘s’ in
G
D
. It is
simply used to simulate manual data collection
process. Model of domain adaptation represents it is
the result of liner interpolation of the background
model built form
G
D
and the domain-specific model
built from a
I
D
. Model of relative entropy means it is
created with relative entropy text selection scheme
(Sethy, 2007) which extract relevant documents
from
G
D
with a bootstrap model built from a
I
D
.
Model of semi-supervise learning means it is built
with our approach as is described in Algorithm 1
with the setting of 8 latent topics and optimized
λ
.
From Figure 1 we can see that our semi-
supervised learning method can easily outperform
other three approaches in terms of test set perplexity
reduction. The models yielded through domain
adaptation approach perform the worst. This means
that domain adaptation is not a good way to create
domain-specific models. The performance of the
models built with relative entropy text selection
criteria is between that of supervised learning and
domain adaptation. We found that it is still very
important for this method to have a bootstrap model
that is built from sizeable balanced data.
220
230
240
250
260
270
280
290
100 500 900 1300 1700
number of domain-specific documents
perplexity
supervised learning domain adaptation
semi-supervised learning relative entropy
Figure 1: Perplexity test results of different learning
approaches with different size of
I
D
.
We also notice that our semi-supervised learning
method outperforms supervised learning method
with present configuration. The reason could be that
the documents in the training set probably are not
well categorized, there exist some texts that should
be classified as category sport, our learning
algorithm can manage to find out and make use of
them. The simulated supervised learning method, on
the other hand, is not able to retrieve such texts
using simple string matching mechanism and the
collected training data is not enough. Another reason
may be due to the fact that the category boundaries
of texts from news media are not so clear. Our
algorithm may somehow borrow some information,
such as topic-specific word co-occurrence
preferences that an n-gram model wants to capture,
from texts of other domains.
In addition, our semi-supervised learning
algorithm works well with smaller domain-specific
dataset. Particularly, with the
I
D
of only 100 texts,
which is only about 0.1% of the size of
G
D
, we can
yield models with higher performances than those
created by other three methods. Its perplexity of
248.3 at this point is the lowest comparing with
271.4 of the second best performing method of
supervised learning at the same point and 251 at
1,700.
3.3 Experiments on Hard Domain
It is much more important if it is able to learn
knowledge from general-domain data for hard
domains. In order to carry out such experiment, we
create a domain-specific dataset hard
I
D
as well as a
hard test set, as are shown in Table 1. The
experimental results are presented in Table 3.
Table 3: Experimental results on hard domain.
Modeling methods Perplexity OOV rate
Baseline built from
G
D
533 5.4%
Baseline(
G
D
)+Domain(
I
D
) 359 3.3%
SSL with T=12,
λ
=1.0 317 3.6%
SSL with T=12,
λ
=0.8 281 2.8%
SSL with T=12,
λ
=0.6 263 2.1%
SSL with T=12,
λ
=0.4 292 3.4%
We observe form Table 3 that there exists
significant domain mismatch between
G
D
and the
test set. Without the help of
I
D
, the baseline model
built from
G
D
alone generate an astonishing
perplexity of 533 and out-of-vocabulary (OOV) rate
of 5.4% against the test set. Domain adaptation with
liner interpolation method can achieve significant
perplexity reduction even with a very small amount
of data. But our semi-supervised learning (SSL)
method can make further improvement. Contrary to
the phenomena in previous experiment, our method
can only reach optimal state by setting
λ
with
smaller value of 0.6. This can be explained by the
fact that
G
D
does not clearly contain much domain-
specific data, we need to decrease its influence over
I
D
to find useful information during DT and n-gram
model training. We also notice that both perplexity
number and OOV rate are consistently improving
when we decrease
λ
from 1 to 0.6. This means that
the learning algorithm is able to extract more helpful
information from the training corpus through
appropriately re-weighting of the datasets.
3.4 Experiments on Parameter Setting
As mentioned earlier, there are two free parameters
need to be set for our learning algorithm: the number
of latent topics
T
and the weighting factor
λ
for
general-domain data. In order to investigate how
these parameters affect the learning performance, we
conduct experiments on different parameter setting.
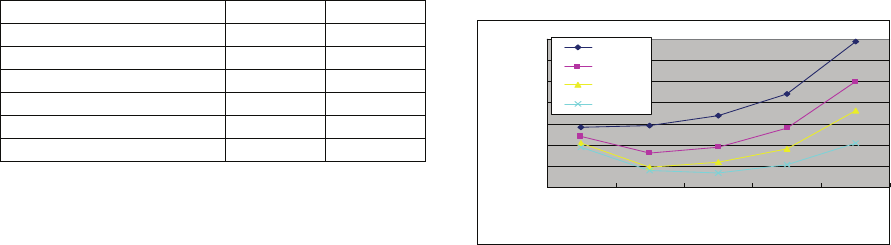
Figure 2 shows the performance of the models
obtained with different weighting factor
λ
and 8
latent topics. The experiments are carried out with
I
D
in different size. We observe that our learning
algorithm can hardly achieve best performance with
the setting of
1
=
λ
. Therefore the weighting factor
is important for us to derive higher-performance
models. In particular, model obtained with
I
D
of
size 100 become little bit worse off with perplexity
of 249 when
λ
is set 0.8 comparing perplexity of
248.3 when
λ
is set 1. On the other hand, the
overall trend becomes worse when
λ
is set with 0.4
or below. This can be explained by the fact that
excessively lowering the weighting for
G
D
equals to
intensively raising the weighting for
I
D
.
220
230
240
250
260
270
280
290
1 0.8 0.6 0.4 0.2
weight for general purpose data
perplexity
size 100
size 500
size900
size 1300
Figure 2: Perplexity test results of different models
obtained with different size of
I
D
and different
λ
.

We also study the effect of number of latent
topics on the performance of our learning algorithm.
Table 4 summarizes the experimental results with
different number of topics.
Table 4: perplexities for different number of latent topics.
# latent topic T 4 8 12 16 20
|
I
D
| =500 ,
λ
= 1 267 239 229 224 221
|
I
D
| =1300 ,
λ
= 0.8 261 227 222 219 218
From Table 4 we notice that larger number of
topics can result in better performance, which is in
line with the results of prior arts. But the
performance does not improve much when
T
reaches 16. This trend is different from the results of
Liu (2007) and Tam (2005) where much larger
numbers of topics are applied (from 50 to 200 topics)
with word unigram models. The experiments also
preliminarily reveal that the setting of
λ
has no
direct impact on the setting of
T
.
4 CONCLUSIONS
In this paper we proposed a novel semi-supervised
learning method for building domain-specific LMs.
The innovative aspects of our method are: the
learning strategy and the derivation of topic
distribution of an interested domain; the weighted
TD method for combined dataset of domain-specific
and general-domain data; the weighting strategy of
n-grams for domain-specific LMs. The whole
learning process is under the multi-conditional
learning scheme which can effectively balance the
influence of the domain-specific and general-domain
data. We conducted experiments on easy domain as
well as hard domain and the results show that the
proposed method is very effective. It can not only
achieve better performance than state-of-art method
can, it can also deliver better result than the
simulated supervised learning process does with the
present configuration.
As future works, we may extend the learning
strategy to other domains. We will also consider
using other topic modelling method to make the
learning method more effective.
REFERENCES
Druck, G., Pal, C., Zhu, X., McCallum, A., “Semi-
Supervised Classification with Hybrid Generative/
Discriminative Method”. KDD’07. August 12-25, CA
USA, 2007.
Gildea, D. and Hofmann, T., “Topic-based lan-guage
models using EM”, Proc. of Eurospeech. 1999.
Heidel, A., Chang, H.A. and Lee, L.S., “Language Model
Adaptation Using Latent Dirichlet Allocation and
Efficient topic Inference Algorithm”,
INTERSPEECH’2007.
Hofmann, T., “Unsupervised Learning by Probabilistic
Latent Semantic Analysis”, Machine Learning,
42,177-196,2001.
Hsu, B. J., and Glass, J., “N-gram Weighting: Reducing
Training Data Mismatch in Cross-Domain Language
Model Estimation”, p829-838, Proc. EMNLP’08, 2008.
Liu, F. and Liu, Y., “Unsupervised Language Model
Adaptation Incorporating Named Entity Information”,
ACL’2007, Prague, Czech Republic. 2007.
Liu, X., and Croft, W.B., “Cluster-Based Retrieval Using
Language Model” SIGIR’04, July 25-29, UK, 2004.
Nigam, K., McCallum, A.K., Thrun, S., and Mitchell,
T.M., “Text classification from labeled and unlabeled
documents using EM”, machine learning , 39, 103-134,
2000.
Sarikaya, R., Gravano, A. and Gao, Y., “Rapid language
model development using external resources for new
spoken dialogue domain”, ICASSP2005, 2005.
Sethy, A., Georgiou, P.G., and Narayanan, S., “Text data
acquisition for domain-specific language models”
p382-389, EMNLP 2006.
Tam, Y. and Schultz, T., “Dynamic Language Model
Adaptation using Variational Bayes Inference”,
INTERSPEECH’05, 2005.
Wan, V., Hain, T., “strategies for language model web-
data collection”, ICASSP’2006, 2006.
Xue, G.R., Dai, W.Y., Yang, Q.and Yi, Y., “Topic-
bridged PLSA for cross-domain text classification”,
SIGIR'08 July20-24, 2008, Singapore.
