
INCREMENTAL LEARNING OF CONVOLUTIONAL NEURAL
NETWORKS
Duˇsan Medera
Fac. of Electrical Engineering and Informatics, Technical University of Koˇsice, 042 00 Koˇsice, Slovakia
ˇ
Stefan Babinec
Fac. of Chemical and Food Technologies, Slovak University of Technology, 812 37 Bratislava, Slovakia
Keywords:
Convolutional neural networks, Incremental learning, Handwritten numbers classification.
Abstract:
Convolutional neural networks provide robust feature extraction with ability to learn complex, high-
dimensional non-linear mappings from collection of examples. To accommodate new, previously unseen
data, without the need of retraining the whole network architecture we introduce an algorithm for incremental
learning. This algorithm was inspired by AdaBoost algorithm. It utilizes ensemble of modified convolutional
neural networks as classifiers by generating multiple hypotheses. Furthermore, with this algorithm we can
work with the confidence score of classification, which can play crucial importance in specific real world
tasks. This approach was tested on handwritten numbers classification. The classification error achieved by
this approach was highly comparable with non-incremental learning.
1 INTRODUCTION
Many claims have been made about the importance
of neural networks in modeling nature and artificial
intelligence problem domains. To this stage, the neu-
ral networks have been applied to a variety of areas.
One of the most studied areas, where neural networks
were successfully applied and where they still have
a potential, is pattern recognition task. The perfor-
mance of neural networks as classifiers relies heavily
on the availability of a representative set of the train-
ing examples. In many practical applications, data ac-
quisition and the training process is time consuming.
It is not uncommon in applications, that the data are
available in small batches over a period of time. In
ideal case, the classifier should support an incremen-
tal fashion of accommodating new data without com-
promising old data classification performance. Learn-
ing new information without forgetting previously ac-
quired knowledge raises so-called stability-plasticity
dilemma (Grosberg, 1988).
Convolutional neural networks (CNN) are repre-
sentative of classifiers, which require retraining of the
classifier using all data that have been accumulated
so far. Why there is an effort to accommodate con-
volutional neural networks to incremental fashion?
They have been widely adopted in pattern recognition
(Y. LeCun and Haffner, 1998) and image recognition
areas (Delakis and Garcia, 2003). From their funda-
mental principles they lack the option to accommo-
date new unseen data without time consuming learn-
ing process, which can play a crucial role in many
applications (e.g. face recognition).
In this paper we introduce incrementallearning al-
gorithm of convolutional neural networks, which was
inspired by AdaBoost and Learn++ algorithm. This
algorithm allows us to accommodate new previously
unseen data without the need of retraining the whole
network architecture. It utilizes ensemble of modified
convolutional neural networks as classifiers by gen-
erating multiple hypotheses. Furthermore, with this
algorithm we can work with the confidence score of
classification, which can play crucial importance in
specific real world tasks. Classification results of this
incremental approach are better quality as the results
gained from the non-incremental approach.
2 BACKGROUND
The ability of multi-layer neural networks trained
with gradient descent to learn complex, high-
547
Medera D. and Babinec Š. (2009).
INCREMENTAL LEARNING OF CONVOLUTIONAL NEURAL NETWORKS.
In Proceedings of the International Joint Conference on Computational Intelligence, pages 547-550
DOI: 10.5220/0002316405470550
Copyright
c
SciTePress

dimensional, non-linear mappings from collection of
examples makes them candidates for image recogni-
tion tasks. In the traditional model of pattern recog-
nition, a hand-designed feature extractor gathers rel-
evant information from the input and eliminates ir-
relevant variabilities. A trainable classifier then cat-
egorizes the resulting feature vectors into classes. In
this scheme standard fully connected multi-layer net-
works can be used as classifiers. A potentially more
interesting scheme is relating on learning in the fea-
ture extractor itself as much as possible.
CNN combines three architectural ideas to ensure
some degree of shift, scale and distortion invariance:
local receptive fields, shared weights and temporal
sub-sampling. The CNN architecture used in our ex-
periments is inspired by Yann LeCun (Y. LeCun and
Haffner, 1998). CNN output layer consists of Eu-
clidean radial basis function (RBF) neurons. The rea-
son for using RBF neurons is to connect distributed
codes layer with classification classes in output layer.
Classification confidence score is very important in
the decision making support systems. We can deter-
mine it in the following way. Neurons in the out-
put layer can be considered as centers of individ-
ual classes of clusters defined through values of the
synaptic weights. We can use the following Gaussian
function for our purpose:
ϕ(y
i
) = e
−
y
i
σ
, (1)
where y
i
is the output of ith neuron in the output layer
and σ is the radius of the cluster defined through dis-
tributed codes. It is clear that values of the ϕ(y
i
) func-
tion are from the interval [0, 1] and we can consider
these values as a confidence score. For the output,
which is close to the distributed code of the corre-
sponding class, confidence will be close to 1 and vice
versa.
Boosting
Boosting refers to a general and provably effective
method of producing a very accurate prediction rule
by combining rough and moderately inaccurate rules
of thumb in a manner similar to that suggested above.
Boosting has its roots in a theoretical framework for
studying machine learning called the ”Probably Ap-
proximately Correct (PAC)” learning model due to
Valiant (Valiant, 1984). Valiant was first to pose
the question of whatever a ”weak” learning algorithm
which performs just slightly better that random guess-
ing in the PAC model can be boosted into an ac-
curate ”strong” learning algorithm. Our inspiration
was AdaBoost algorithm introduced by Freund and
Schapire in 1995 (Freund and Schapire, 1999). Prac-
tically, AdaBoost has many advantages. It requires
no prior knowledge about the weak learner and so
can be flexibly combined with any method for finding
weak hypotheses. Finally, it comes with a set of the-
oretical guarantees given sufficient data and a weak
learner that can reliably provide only moderately ac-
curate weak hypotheses. On the other hand, the ac-
tual performance of boosting on a particular problem
is clearly dependent on the data and the weak learner.
Consistent with theory, boosting can fail to perform
well given insufficient data, overly complex weak hy-
potheses or weak hypotheses which are too weak.
Boosting seems to be especially susceptible to noise.
Boosting approach was also used to improve classifi-
cation performance on convolutional neural networks
(Y. LeCun and Haffner, 1998).
Ensemble of Classifiers
The proposed incrementallearning system using Con-
volutional Neural Networks described in this section
was inspired by the AdaBoost algorithm (Freund and
Schapire, 1999) and Learn++ algorithm (R. Polikar
and Udpa, 2001). Learn++ algorithm was designed
for incremental learning of supervised neural net-
works, such as multilayer perceptrons to accommo-
date new data without access to previously trained
data in the learning phase. Algorithm generates an
ensemble of weak classifiers, each trained using a dif-
ferent distribution of training samples. Outputs of
these classifiers are then combined using Littlestone‘s
majority-voting scheme to obtain the final classifica-
tion rule. Ensemble of classifiers can be optimized
for improving classifier accuracy or for incremental
learning or new data (Polikar, 2007). Combining en-
semble of classifiers is geared towards achieving in-
cremental learning besidesimproving the overall clas-
sification performanceaccording to the boosting. Pro-
posed architecture is based on this intuition: each
new classifier added to the ensemble is trained using
a set of examples drawn according to a distribution,
which ensures that examples that are misclassified by
the current ensemble have a high probability of being
sampled (examples with high error rates are precisely
those that are unknown).
Incremental Learning
We can describe the learning algorithm inspired
by (R. Polikar and Udpa, 2001) by assuming
following inputs. Denote training data S
k
=
[(x
1
, y
1
), .. . , (x
m
, y
m
)], where x
i
are training samples
and y
i
are corresponding correct labels for m sam-
ples randomly selected from the database Ω
k
, where
k = 1, 2, . . . , K. Algorithm calls weak learner repeat-
edly to generate multiple hypotheses using different
IJCCI 2009 - International Joint Conference on Computational Intelligence
548

subsets of the training data S
k
. Each hypothesis learns
only a portion of input space X and is weighted ac-
cording to the final hypothesis. The weight of dis-
tribution on training example i on round t is denoted
D
t
(i). Those weights are initialized by rule D
1
(i) =
w
1
(i) =
1
m
, unless there is a prior knowledge to select
otherwise. Learning process is iterative and in each
iteration t = 1, 2, . . . , T
k
, where T
k
is number of clas-
sifiers (weak learners used in current iteration), algo-
rithm dichotomizes S
k
into a training subset TR
t
and
test subset TE
t
according to D
t
. All classifiers are
called and the hypothesis h
t
: X → Y is generated. The
error of h
t
on S
k
is defined as
ε
t
=
∑
i:h
t
(x
i
)6=y
i
D
t
(i), (2)
which is simply the sum of distribution weights of
misclassified examples. If ε
t
>
1
2
, h
t
is discarded and
we repeat this step. Otherwise we compute normal-
ized error β
t
as
β
t
=
ε
t
1− ε
t
. (3)
All hypotheses generated in the previous t iterations
are then combined using weighted majority voting
scheme to obtain composite hypothesis (hypothesis
performs well on own training and testing data set by
giving them larger voting powers)
H
t
= argmax
y∈Y
∑
t:h
t
(x)=y
log
1
β
t
. (4)
The composite error made by hypothesis H
t
is com-
puted by following equation:
E
t
=
∑
t:H
t
(x
i
6=y
i
)
D
t
(i). (5)
If E
t
>
1
2
, current h
t
is discarded and a new TR
t
and
TE
t
is selected to obtain new h
t
. E
t
can only exceed
this threshold during the iteration after new database
Ω
k+1
is introduced. If E
t
<
1
2
, composite normalized
error is computed as
B
t
=
E
t
1− E
t
. (6)
After computing B
t
, the weights w
t
(i) are adjusted in
an incremental manner of the algorithm
w
t+1
(i) = w
t
(i)B
t
if H
t
(x
i
) = y
i
,
w
t+1
(i) = w
t
(i) otherwise.
(7)
In other words, if an example x
i
is correctly classified
by H
t
, its weight is multiplied by B
t
, otherwise the
weight is kept unchanged. This rule reduces the prob-
ability of correctly classified examples being chosen
to TR
t+1
. Using of composite hypothesis makes in-
cremental learning possible particularlyin cases when
examples from the new class are introduced.
Finally after T
k
hypotheses are generated for each
Ω
k
, the final hypothesis is obtained by the weighted
majority voting of all composite hypotheses:
H
final
= argmax
y∈Y
K
∑
k=1
∑
H
t
(x)=y
log
1
B
t
. (8)
Incremental learning is achieved through generating
additional classifiers and former knowledge is not lost
since all classifiers are retained.
3 EXPERIMENTS
Our goal in this paper was to compareresults achieved
by non-incrementallearning of CNN with our new ap-
proach. We have used standard benchmarking data
set MNIST in this paper. This data set represents
handwritten numbers samples from different people.
Every sample from this data set is represented in
grayscale with 28× 28 dimension and is centered in
the 32× 32 grid.
We have created 4 independent training sets D1,
D2, D3 and D4. Every training set was composed
of 2500 samples and the testing set was composed
of the next 5000 samples. We have used modi-
fied Levenberg-Marquadt backpropagation of error
method (LeCun, 1998) as a learning algorithm for
the individual classifiers. Regarding to smaller train-
ing set, the number of learning cycles was set to 20.
The initial value of the global learning parameter γ
in learning algorithm equals 5.10
−5
. In the 4th cycle
the value was decreased to 2.10
−5
and in the 12th cy-
cle to 1.10
−5
. The value of the parameter µ was set
to 0.02. Maximum number of classifiers per data set
was constrained to 5 for every training data set.
To allow comparison with non-incremental ap-
proach we have also trained one CNN, which was
still retrained for all gradually presented training data
sets. We have retrained it 4 times, where one retrain-
ing consisted of 40 learning cycles.
We can see the results of experimentsin the folow-
ing Tables 1 and 2. Best results were achieved with
the cluster radius parameter σ set to 1. As we can
see, our incremental approach achieved better results
during the whole gradual training process.
4 CONCLUSIONS
Incremental learning inspired by Learn++ algorithm
is based on ensemble of Convolutional Neural Net-
work classifiers. Algorithm’s update rule is optimized
for incremental learning of new data. It does not
INCREMENTAL LEARNING OF CONVOLUTIONAL NEURAL NETWORKS
549
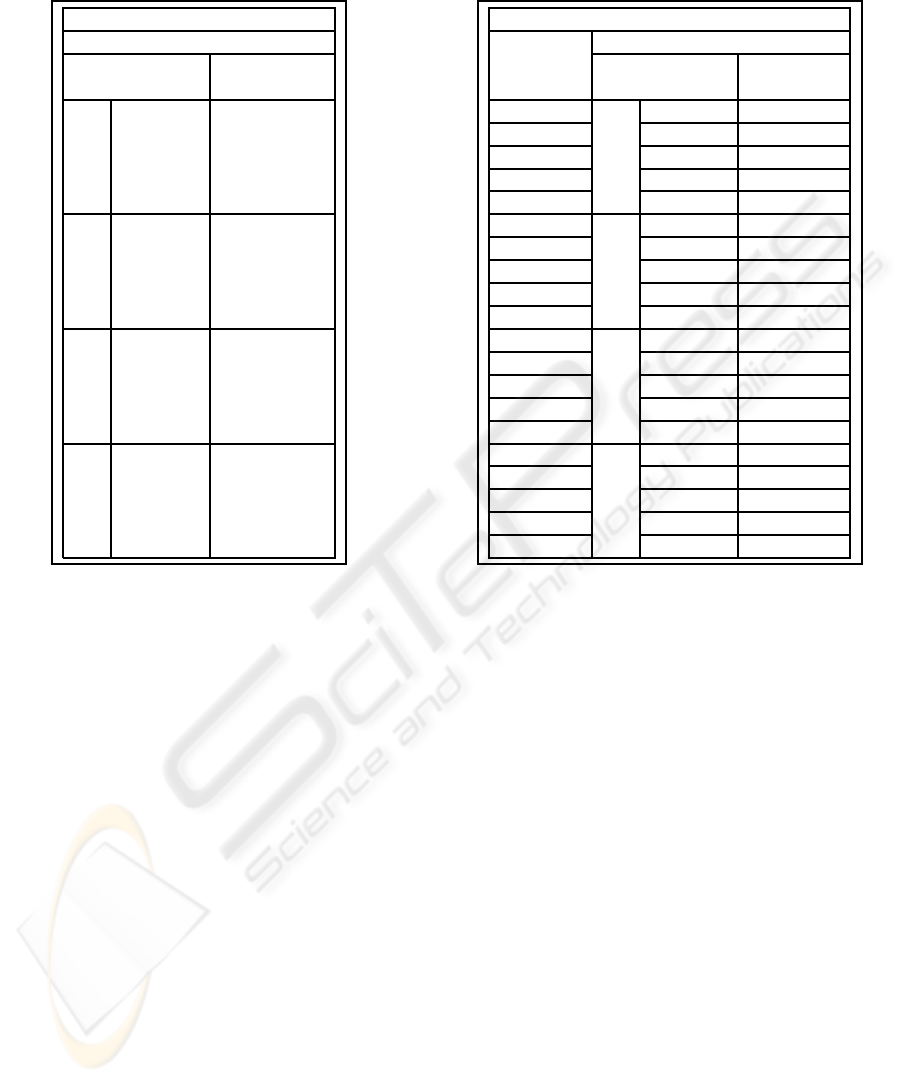
Table 1: Results of experiments for standard non-
incremental learning.
Non-incremental approach
Prediction accuracy
Training Testing
set [%] set [%]
D1 92.13 88.07
D1
D2
91.42 87.76
D1
D2
D3
91.99 89.36
D1
D2
D3
D4
92.12 89.63
require access to previously seen data during subse-
quent training process and it is able to retain previ-
ously acquired knowledge. We have chosen hand-
written numbers set as a testing data for our classi-
fication experiments. Our aim was to find out if this
approach can give better results in comparison with
standard non-incremental algorithm and in the same
time offer incremental form of learning. From the re-
sults shown in this paper, it is clear that this aim has
been accomplished. Classification results of our in-
cremental algorithm are better as the results gained
from the non-incremental approach. In addition, our
approach brings the possibility to work with the con-
fidence score of classification.
ACKNOWLEDGEMENTS
This work was supported by Scientific Grant Agency
Vega of Slovak Republic under grants 1/4053/07,
1/0804/08 and 1/0848/08.
Table 2: Results of experiments for our new approach.
Our new approach
Number Prediction accuracy
of Training Testing
classifiers set [%] set [%]
1
D1
95.52 91.95
2 98.88 92.76
3 99.44 93.02
4 99.56 92.87
5 99.56 92.76
6
D2
95.36 93.80
7 98.04 94.14
8 99.32 94.12
9 99.40 94.00
10 99.56 93.98
11
D3
98.04 94.70
12 99.60 94.90
13 99.76 94.92
14 99.84 94.86
15 99.84 94.82
16
D4
97.32 95.18
17 99.20 95.42
18 99.68 95.62
19 99.96 95.62
20 99.96 95.59
REFERENCES
Delakis, M. and Garcia, C. (2003). Training convolutional
filters for robust face detection. In Proc. of the IEEE
international Workshop of Neural Networks for Signal
Processing, pages 739–748.
Freund, Y. and Schapire, R. (1999). A short introduction
to boosting. Journal of Japanese Society for Artificial
Intelligence, 14:771–780.
Grosberg, S. (1988). Nonlinear neural networks princi-
ples, mechanisms and architectures. Neural Networks,
1(1):17–61.
LeCun, Y. (1998). Efficient backprop, neural networks
tricks of the trade. Lecture Notes in Computer Sci-
ence, 1524:9–53.
Polikar, R. (2007). Bootstrap inspired techniques in com-
putational intelligence. IEEE Signal Processing Mag-
azine, 24(4):56–72.
R. Polikar, L. U. and Udpa, S. (2001). Learn++, an incre-
mental learning algorithm for supervised neural net-
works. IEEE Trans. on Systems, 31(4):497–508.
Valiant, L. (1984). A theory of the learnable. Communica-
tions of the ACM, 27:1134–1142.
Y. LeCun, L. Bottou, Y. B. and Haffner, P. (1998). Gradient-
based learning applied to document recognition. Proc.
of IEEE, 86(11):2278–2324.
IJCCI 2009 - International Joint Conference on Computational Intelligence
550
