
CAPTURING USER’S PREFERENCES USING A GENETIC
ALGORITHM
Determining Essential and Dispensable Item Attributes
S. Valero, E. Argente and V. Botti
DSIC, Universidad Polit´ecnica de Valencia, Camino de Vera s/n, Valencia, Spain
Keywords:
Soft computing, Genetic algorithms, Recommender systems, Profile acquisition, Capturing preferences.
Abstract:
Determining the most desired product attributes would be crucial for companies that want to offer their clients
those products which best fit their preferences. In this work, a genetic approach is employed for establishing
the appropriate attribute weights of movies, determining which movie attributes are essential or dispensable
for users in their selection process. The obtained weights are employed to predict user’s ratings for a test set
of movies, proving that the obtained parameters really describe their preferences.
1 INTRODUCTION
Setting the most desired product attributes would be
very interesting for any companies which want to of-
fer its clients such items that best fit these desired fea-
tures. In this way, it would be interesting to know
which item attributes are essential or superfluous for
users in their selection process when buying prod-
ucts or paying for services. This problem could be
seen as a combinatorial problem, in which attribute
based profiles of items are used as start point to set the
appropriate attribute weights that make these prod-
ucts attractive for users. Thus, a soft computing ap-
proach based on genetic algorithms could be used
to set the optimum combination of the item attribute
weights that best fit the user’s preferences. Some Soft
Computing approaches have previously been applied
in user’s preference learning, such as (Guan et al.,
2002; Shibata et al., 2002). These works capture
users’ preferences but do not consider some start-
ing problems caused by missing information of new
users. In this way, a genetic algorithm (GA) capa-
ble of establishing the appropriate weights for item
attributes that define the users’ preferences, but need-
ing few starting data is presented in this work. Con-
cretely, this GA determines the suitable combination
of attributes that makes an specific item attractive for
users. These combinations are later used to predict
users’ rating movies, making recommendations about
unknown movies. Moreover, our approach needs few
users’ starting ratings (only 3 or 5) to obtain good rec-
ommendations (right rates closer to 75%). For this
purpose, the Movilens database will be used, which
contains ratings of movies made by MovieLens web
site
1
users in 2000 (Herlocker et al., 1999).
2 GENETIC APPROACH
The proposed approach for capturing users’ favorite
movie attributes is based on a real-coded GA (Gold-
berg, 1991). The developed codification problem al-
lows studying diverse kinds of problems and estab-
lishing rules at different levels that the obtained chro-
mosomes must satisfy (Valero et al., 2009). In this
case, each possible solution of the problem (chromo-
some) contains a descriptive movie attribute weight
(release data) and genre attributeweights (19 possibil-
ities: action, adventure, animation, children, comedy,
crime, etc.).
Figure 1 shows the steps followed by the devel-
oped GA. First, the GA obtains a starting generation,
selecting the most diverse one from several random
generations. Then, the GA proposes new solutions
employing crossover and mutation operators. The
mutation operator modifies some genes in a haphaz-
ard way, jumping randomly anywhere within the al-
lowed gene domain. Regarding the crossover oper-
ator, it has been adapted from the ones proposed in
(Ortiz et al., 2001), which is based on confidence in-
tervals. The new operator takes into account the rules
defined in the developed codification. This GA ap-
1
http://movielens.umn.edu
599
Valero S., Argente E. and Botti V. (2010).
CAPTURING USER’S PREFERENCES USING A GENETIC ALGORITHM - Determining Essential and Dispensable Item Attributes.
In Proceedings of the 2nd International Conference on Agents and Artificial Intelligence - Artificial Intelligence, pages 599-602
DOI: 10.5220/0002727305990602
Copyright
c
SciTePress
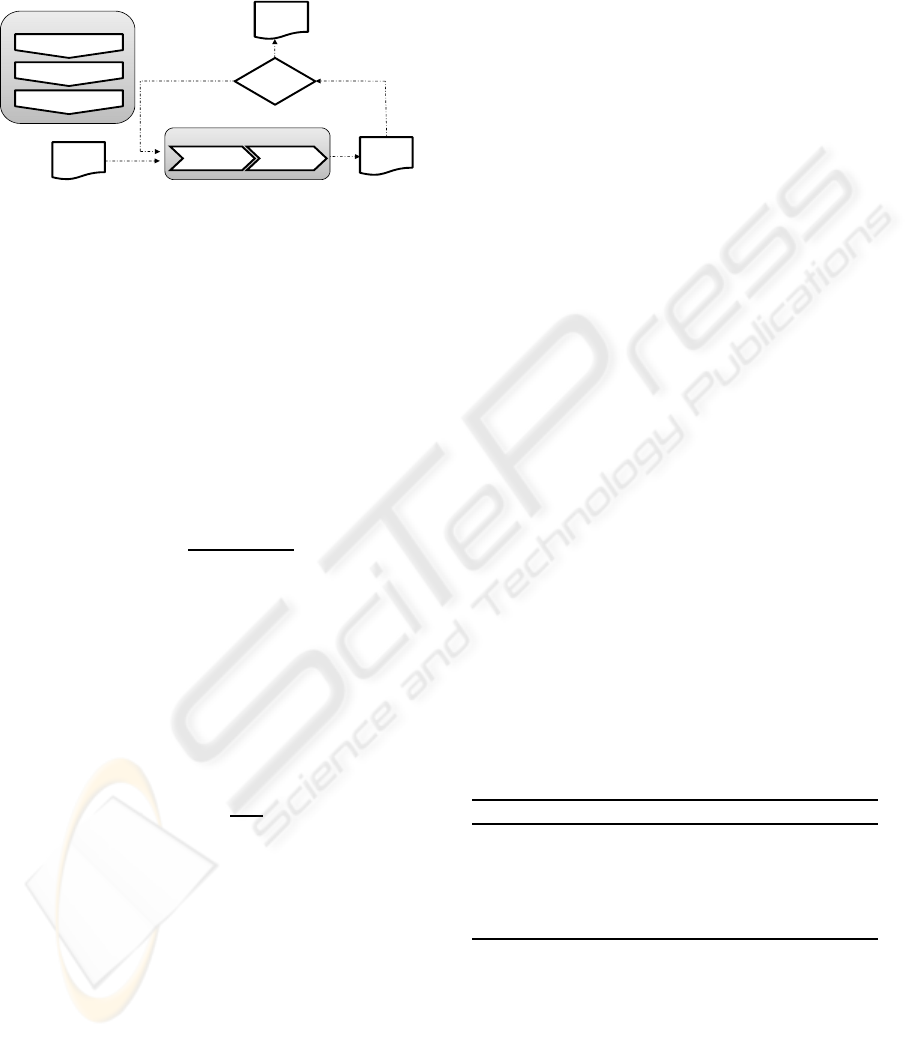
proach has been successfully employed in combina-
torial catalysis for high-throughput experimental de-
sign (Valero et al., 2004b; Valero et al., 2004a; Valero
et al., 2009).
Converge
criterion
Random
Gene ra tion 0
Problem Codification
Setting up
GA parameters
Starting Generation
Setting Up
GA Operators
Mutation Cros s over
Gene ra tion i
Fina l
Genera tion
Yes
No
i=0
i=i+1
Figure 1: Steps of the developed genetic approach.
As mentioned above, the GA has been used to es-
tablish the appropriate attribute weights for movies
that define the preferences of a set of one or more
users. These obtained weights were employed to pre-
dict users’ ratings for a test set of movies, in order
to prove that the obtained parameters really described
their preferences. Absolute Mean Error (MAE) and
Mean Square Error (MSE) were used as metrics ((Sar-
war et al., 1998; Shardnand and Maes, 1995; Her-
locker et al., 1999)). The objectivefunction optimized
by the proposed GA was:
MAE =
∑
M
i=1
|P
i
− R
i
|
M
(1)
where M indicates the number of users’ movie rat-
ings; P
i
represents the estimated user rating for the
movie i; R
i
is the user’s rating for the movie i. Func-
tion 2 describes the way in which P
i
is obtained:
P
i
=
N
∑
j= 1
w
j
q
j
(2)
where w
i
is the adjusted weight for the attribute j, q
i
is the value of the attribute j for the movie to be rated
and
∑
N
j= 1
w
j
= 1. Thus, the fitness of each possible
solution or chromosome was
1
MAE
. Finally, the devel-
oped GA proposed those attribute weights that best fit
users’ interests.
3 RESULTS
A user contained in the MovieLens database was se-
lected taking into account the amount of available in-
formation about him. This user was employed to set
up the GA parameters. Then, the GA was used for
capturing the preferences of a cluster of users. These
weights were later used to estimate both cluster rat-
ings and ratings made on some other movies by simi-
lar users.
3.1 GA Setting Up Process
One user (identifier 276) with a lot of ratings (518)
was selected, hence well informed data was used for
the GA setting up process. The available information
of user 276 was divided into training (90%) and test-
ing (10%) data sets. Training data was used by the
GA for fitness evaluation (function 1), whereas the
testing data set was employed to predict the user’s
ratings. The testing data set contains information
about recently rated movies. First of all, param-
eters concerning population size and crossover op-
erator were set: α value, parents ratio and popu-
lation size. A battery of tests was performed us-
ing all possible combinations of the values: pop-
ulation size= {100, 200, 300, 400, 500}; α value =
{0.6, 0.7, 0.8, 0.9}; parents ratio= {10%, 20%, 30%}.
Mutation probability was set to 0; thus, the muta-
tion operator did not act in these tests. The pro-
posed GA reached 25 optimization cycles for each
parameter combination (convergence criterion). At
the end of each test, the best chromosome (attribute
weights with best fitness) was selected in order to pre-
dict the user’s ratings on movies in the testing data set.
Also, the number of right movie recommendations
was computed. A right recommedation was computed
when the predicted rating for a movie indicated that
the user would really like that movie and the stored
rating at the database was also favorable (rating ≥ 0.5
in both cases). Similarly, a right recommendation was
also computed when the predicted rating for a movie
shown a user dislike for the movie and its stored rat-
ing was also desfavorable (rating< 0.5 in both cases).
Besides right recommendations, MAE and MSE were
also considered to select the most suitable values for
the studied parameters.
Table 1: Best results obtained during the optimization of the
crossover and population parameters.
Parameters MAE MSE Right Recom.
500-0.7-10 0.2885 0.1250 69.23%
500-0.6-10 0.3029 0.1358 63.46%
100-0.6-10 0.3413 0.1550 50.00%
400-0.7-30 0.3413 0.1550 50.00%
400-0.9-30 0.3413 0.1550 50.00%
Best results obtained during the reported study are
shown in Table 1. The selected combination of pa-
rameters was: population size=500; α value=0.7 and
parents ratio=10. The GA (using them) proposed a set
of attribute weights which reached a 69.23% rate of
right recommendations and the least MAE and MSE
at the test phase.
Secondly, mutation parameter values (mutation
probability and number of genes to be mutated) were
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
600

Table 2: Best results obtained during the optimization of the
mutation parameters.
Parameters MAE MSE Right Recom.
15% - 2 0,2644 0,0925 78,85%
15% - 3 0,2645 0,0974 76, 92%
15% - 1 0,2836 0,1166 69, 23%
5% - 3 0,2836 0,1166 69, 23%
10% - 3 0,2788 0,1179 69, 23%
set following the above-mentioned process. The
values studied for these parameters were: mutation
probability= {5%, 10%, 15%}; number of genes to be
mutated= {1, 2, 3}. Crossover and population param-
eter values were those previously selected ones. Ob-
tained results are shown in Table 2.
The GA approach was finally parametrized as fol-
lows: population size = 500; α value = 0.7; parents
ratio = 10; mutation probability=15% and 2 genes
to be mutated. Using these parameters, the GA pro-
posed a set of attribute weights which performed a
rate of 78, 85% of right recommendations. These at-
tribute weigths indicated that the essential movie at-
tributes for user 276 were the release date (19.32%)
and action (23.51%), comedy (19.93%) and drama
(20.73%) movie genres. In the same way, the dispens-
able movie attributes (0%) were animation, musical,
mystery, romance, science fiction, war western and
unknoun movie genres.
3.2 Employing Clusters Preferences
In this section the proposed GA is used to capture the
preferences of system users which are similar to a ref-
erence user, employing few ratings of this reference
user (i.e. 3 movie ratings). This approach can be used
by recommender systems to offer acceptable sugges-
tions when few starting data for a user is available.
Clusters of similar users were obtained using
Pearson correlation as a proximity measure and
center-based as a neighborhood scheme (Sarwar et al.,
2000). All the data about clusters movie rating was di-
vided into training and testing data sets. Then, the GA
was employed for getting the appropriate movie at-
tribute weights which define the preferences of these
clusters (using training data for fitness evaluation).
These optimized weights were later used to estimate
reference users’ ratings on the 20 movies recently
rated by them. In this study, several experiments were
carried out using two different reference users: user
276 (518 ratings), previously employed, and user 710
(86 ratings), selected in a haphazard way.
For each reference user, his first rated movies
where considered to obtain his cluster of similar users.
Each cluster is composed of users that have seen the
same films and have evaluated them in a similar way
with regard to the reference user. More specifically,
clusters were formed considering three (3M) or five
(5M) reference users’ movie ratings and neighbor-
hoods of 10, 15 or 20 users (k). Six clusters were
computed for each user, but since for user 710 all clus-
ters obtained with 3M were equal to those obtained
with 5M, then less tests were performed for this user.
The optimized movie attribute weights proposed
by the GA for each computed cluster were later used
to estimate the cluster ratings on the movies in the
testing data set. The results obtained in these estima-
tions are shown in Table 3.
These appropriate movie attribute weights that de-
fine the cluster preferences were also used to predict
the ratings on the 20 movies recently ranked by simi-
lar users. This study simulated the way in which real
users act in Recommender Systems. In such environ-
ments, users enter few starting information (3M or
5M in this case) but expect good recommendations.
Table 4 describes the achieved results. It should be
pointed out the excellent results which were obtained
for similar users different from the reference ones
(even 100%). These users were computed as similar
to the reference ones during the different cluster for-
mations (they also rate the same three or five movies),
but they were not included in those clusters.
Table 3: Best right movie recommendations rate (in %)
computed using cluster preferences achieved by the GA at
the testing phase.
Cluster 10k 15k 20k
276-3M 59.40 59.90 55.40
276-5M 63.96 59.34 65.16
710-3M/5M 61.09 51.80 57.68
Table 4: Right movie recommendations rate (in %) com-
puted using cluster preferences to estimate similar users’
ratings on 20 recently rated movies.
Cluster User Right User Right
276-3M-10k 276 75.00 251 80.00
276-3M-15k 276 75.00 54 90.00
276-3M-20k 276 75.00 554 83.33
276-5M-10k 276 65.00 382 60.00
276-5M-15k 276 75.00 906 100.00
276-5M-20k 276 80.00 879 90.00
710-3M/5M-10k 710 70.00 62 80.00
710-3M/5M-15k 710 70.00 533 75
710-3M/5M-20k 710 70.00 492 70
Finally, the best results for reference users were
obtained with the cluster formed for user 276 with 5
starting ratings and 20 neighbors (276-5M-20k). In
this case, the obtained attribute weights indicated that
the essential movie attributes for users similar to 276
CAPTURING USER'S PREFERENCES USING A GENETIC ALGORITHM - Determining Essential and Dispensable
Item Attributes
601

were: release date (20%), action (18.46%), comedy
(18.52%) and drama (27.65%) movie genres. The dis-
pensable movie attributes (0%) were animation, chil-
drens, crime, documentary, fantasy, film noir, musi-
cal, mystery, war and western movie genres.
4 CONCLUSIONS
This work shows the application of a genetic algo-
rithm for capturing user preferences in Recommender
Systems. More specifically, the genetic algorithm al-
lows setting an appropriate weight for each attribute
of a product or service, thus defining the preferences
of one user or a set of users over these attributes.
These obtained attribute weights permit to determine
which product or service attributes are more or less
valuables for users in their selection process when
buying products or paying for services.
All this ranking information given by the GA
could be employed by companies which want to of-
fer their clients those products which best fit their de-
sired attributes. Also, as it has been shown in this
paper, the obtained weights could be employed to pre-
dict user ratings for a test set of movies with a highly
good rate of right predictions. Moreover, the GA re-
sults could be used for offering good recommenda-
tions even when there is not enough informationof the
current user. In this way, the GA could be employed
for capturing the preferences of the users of the sys-
tem that are similar to the current user, and then for
applying the learned weights in order to provide suit-
able recommendations to the current user. This aspect
is especially useful when new users enter into a Rec-
ommender System, since the genetic approach per-
mits offering acceptable recommendations even when
few starting data for a user is available.
ACKNOWLEDGEMENTS
Thanks to GroupLens Research Group to allow the
use of MovieLens data for researching purposes.
This work is partially supported by CONSOLIDER-
INGENIO 2010 under grant CSD2007-00022 and
TIN2008-04446/TIN project, which is co-funded by
the Spanish government and FEDER funds.
REFERENCES
Goldberg, D. (1991). Real-coded genetic algorithms, virtual
alphabets, and blocking. Complex Systems, 5:139–
157.
Guan, S., Ngoo, C., and Zhu, F. (2002). Handy broker: an
intelligent product-brokering agent for m-commerce
applications with user preference tracking. Electron.
Commer. Res. Appl., 1(Issues 3-4):314–330.
Herlocker, J. L., Konstan, J. A., Borchers, A., and Riedl,
J. (1999). An algorithmic framework for performing
collaborative filtering. In ACM SIGIR ’99 Proceed-
ings, pages 230–237, New York, NY, USA. ACM.
Ortiz, D., Hervas, C., and Mu˜noz, J. (2001). Genetic algo-
rithm with crossover based on confidence interval as
an alternative to traditional nonlinear regression meth-
ods. In ESANN’2001 Proceedings, pages 193–198,
Bruges,Belgium.
Sarwar, B., Karypis, G., Konstan, J., and Riedl, J.
(2000). Analysis of recommendation algorithms for e-
commerce. In ACM EC ’00 Proceedings, pages 158–
167, New York, NY, USA. ACM Press.
Sarwar, B. M., Konstan, J. A., Borchers, A., Herlocker,
J., Miller, B., and Riedl, J. (1998). Using filtering
agents to improve prediction quality in the grouplens
research collaborative filtering system. In CSCW ’98
Proceedings, pages 345–354, New York, NY, USA.
ACM Press.
Shardnand, U. and Maes, P. (1995). Social information file-
tering: Algorithms for automating “word of mouth”.
In ACM CHI’95 Proceedings, pages 210–217.
Shibata, H., Hoshiai, T., Kubota, M., and Teramoto, M. (6-
7 Nov. 2002). Agent technology recommending per-
sonalized information and its evaluation. In 2nd In-
ternational Workshop on Autonomous Decentralized
System, 2002, pages 176–183.
Valero, S., Argente, E., Botti, V., Serra, J., and Corma, A.
(2004a). A soft computing technique applied to in-
dustrial catalysis. In ECAI2004 Proceedings, pages
765–769. IOS Press.
Valero, S., Argente, E., Botti, V., Serra, J., and Corma, A.
(2004b). Soft computing techniques applied to cat-
alytic reactions. LNAI, 3040:550–559.
Valero, S., Argente, E., Botti, V., Serra, J., Serna, P., Mo-
liner, M., and Corma, A. (2009). Doe framework for
catalyst development based on soft computing tech-
niques. Comput. Chem. Eng., 33:225–238.
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
602
