
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE
REASONING SECURITY RISK ASSESSMENT RESULTS
Gregory M. Chavez, Brian P. Key, David K. Zerkle and Daniel W. Shevitz
Los Alamos National Laboratory, Los Alamos, New Mexico, U.S.A.
Keywords: Imprecise Information, Confidence, Triage application.
Abstract: The security risk associated with malevolent acts such as those of terrorism are often void of the historical
data required for a traditional PRA. Most information available to conduct security risk assessments for
these malevolent acts is obtained from subject matter experts as subjective judgements. Qualitative
reasoning approaches such as approximate reasoning and evidential reasoning are useful for modeling the
predicted risk from information provided by subject matter experts. Absent from these approaches is a
consistent means to compare the security risk assessment results. This paper explores using entropy
measures to quantify the information uncertainty associated with conflict and non-specificity in the
predicted reasoning results. Extensions of previous entropy measures are presented here to quantify the non-
specificity and conflict associated with security risk assessment results obtained from qualitative reasoning
models.
1 INTRODUCTION
In security risk assessment from malevolent actions
(SRAMA) such as those of terrorism, there is an
absence of quantitative historical data necessary for
a conventional probabilistic risk assessment. Much
of the information for SRAMA is elicited from
subject matter experts (SMEs) as subjective
judgements and is often available as qualitative
imprecise values. An Approximate Reasoning (AR)
model is a useful alternative to a probabilistic model
when drawing conclusions using imprecise
knowledge provided by SMEs. AR has numerous
applications in engineering and control (Ross 2005,
Barret and Woodall 1997, Lewis 1997) and recently
has been applied to security risk assessment for
malevolent actions (Bott and Eisenhawer 2006).
Important factors differentiating AR in control
applications with AR of SRAMA applications is the
type of information used to develop the model and in
the validation of the results. This paper is focused on
the validation phase. In control applications
historical data can be used to validate the AR results;
however, for particular terrorist attacks there is
generally an absence of historical data. For example,
prior to September 11, 2001, there was no historical
data for successful attempts using airplanes to attack
World Trade Center Towers in New York. In the
absence of specific historical data, the AR results for
SRAMA applications can be realistically verified by
the SMEs. Apart from the SMEs verification
approach there has not been a consistent means
presented to quantify the difference in competing
results. For example, triage studies of input values
contributing to the security risk are often a necessary
part of the security risk assessment model. A means
to consistently measure the effect of this change in
input value on the model result is critically
important in sensitivity studies and result
comparisons. The resulting deviation may not be
sufficiently or consistently recognized when relying
only on SME verification.
This study therefore proposes using entropy, i.e.
information uncertainty, to sufficiently and
consistently compare the AR model results.
Measures of entropy have not specifically been
developed for use in AR results. This study extends
entropy to AR results and it is unique in that a
similar approach has not been previously pursued in
AR or applied in the area of SRAMA as a means to
determine the confidence in the result. It is a novel
approach due to its application which is distinctly
different from previous approaches involving
linguistic values and entropy.
Like AR, Evidential Reasoning (ER) is an
alternative approach used to draw conclusions from
398
M. Chavez G., P. Key B., K. Zerkle D. and W. Shevitz D. (2010).
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE REASONING SECURITY RISK ASSESSMENT RESULTS.
In Proceedings of the 2nd International Conference on Agents and Artificial Intelligence - Artificial Intelligence, pages 398-405
DOI: 10.5220/0002748103980405
Copyright
c
SciTePress

information. The major difference between the two
approaches is in the uncertainty quantification. The
imprecision associated with describing the state is
captured with AR while the lack of certainty
associated with assigning a particular state to one of
several linguistic values is captured with ER. In this
study AR and ER are collectively referred to as
qualitative reasoning but each is treated separately.
In Section 2 both AR and ER are discussed and each
is illustrated with simple examples.
In Section 3 entropy as it applies to AR and ER
is discussed and a general discussion on entropy can
be found in Klir (Klir 2006). The utility of a
methodology is measured by its applicability;
therefore, the quantification of entropy using the
proposed approach in AR and ER is illustrated in
Section 3. The implications of quantifying entropy
in AR and ER for SRAMA are discussed in Section 4.
2 QUALITATIVE REASONING
SMEs may indicate that the occurrence of a
particular result is “highly likely”, “somewhat
likely”, or ''negligible'' and the resulting
consequences are “extremely costly”, “moderately
costly”, or “insignificant”. These expressions are
called propositions and the kind of uncertainty
associated with these propositions can be from
vagueness, imprecision, a lack of information
regarding a specific state of the system, or lack of
certainty when assigning a specific state a particular
value. While a combination of all these uncertainties
can also be encountered this study does not address
the combination of these uncertainties. Uncertainty
due to vagueness, imprecision, and/or lack of
information is collectively referred to as fuzzy
uncertainty while a lack of uncertainty associated
with assigning a specific state to one of several
linguistic values is referred to as assignment
uncertainty (Klir 2006). Fuzzy set theory provides a
means for representing fuzzy uncertainty contained
in these propositions while evidence theory provides
a means for representing assignment uncertainty.
Both fuzzy set theory and evidence theory as they
apply to AR and ER, respectively, are discussed in
this section. The reader is referred to (Ross 2004) for
an in depth description of fuzzy set theory and
evidence theory.
2.1 Fuzzy Set Theory
Natural language tends to be interpreted differently
by various individuals. The linguistic values used by
SMEs are no different and have a tendency to be
vague and imprecise. For example, an SME may
indicate that the process to construct a weapon
device is “extremely difficult” or that it is
“somewhat difficult”. The precise meaning of these
linguistic values may be interpreted slightly
differently by various individuals; however,
linguistic values may often be the values the SME is
most confident in and comfortable providing. There
is vagueness and imprecision associated with a
linguistic value which has been termed fuzzy
uncertainty. Fuzzy uncertainty is different from
random uncertainty, where random uncertainty
arises due to chance and deals with specific and well
defined values such as the number on the top face of
a die that is thrown. Random uncertainty is referred
to as an aleatoric uncertainty and fuzzy uncertainty
is referred to as an epistemic uncertainty. In some
cases epistemic uncertainty may be reduced to
aleatoric uncertainty but aleatoric uncertainty is non
reducible uncertainty (Oberkampf et al. 2004, Zadeh
1995). Linguistic values such as “high”, “medium”,
and “low” describe several specific states or
conditions and are considered sets. The boundary
that defines any one of these sets is unclear or fuzzy
and thus these sets are called fuzzy sets.
A collection of elements having similar
characteristics defines a universe of discourse, X.
The individual elements, i.e. states, in X are denoted
as x
i
, with the same notations used for Y and y
j
, and
Z and z
k
, respectively. The elements can be grouped
into various sets, such as:
,
, or
. The set value
of
,
, or
may represent something like “high”
which has a fuzzy boundary. The individual states of
a fuzzy set can be mapped to a universe of
membership values using a function theoretic form.
If a specific state x
i
is a member of the set
, then
this mapping is given by Equation (1). A typical
mapping of
is shown in Figure 1.
0,1
(1)
The complement of
is defined as:
1
(2)
The mapping for the complement is also shown in
Figure 1. The mapping is known as a membership
function and the membership of a specific state is x
i
is referred to as the degree of membership. The
degree of membership of x
i
provides an indication of
the fuzzy set's ability to describe the state.
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE REASONING SECURITY RISK ASSESSMENT
RESULTS
399
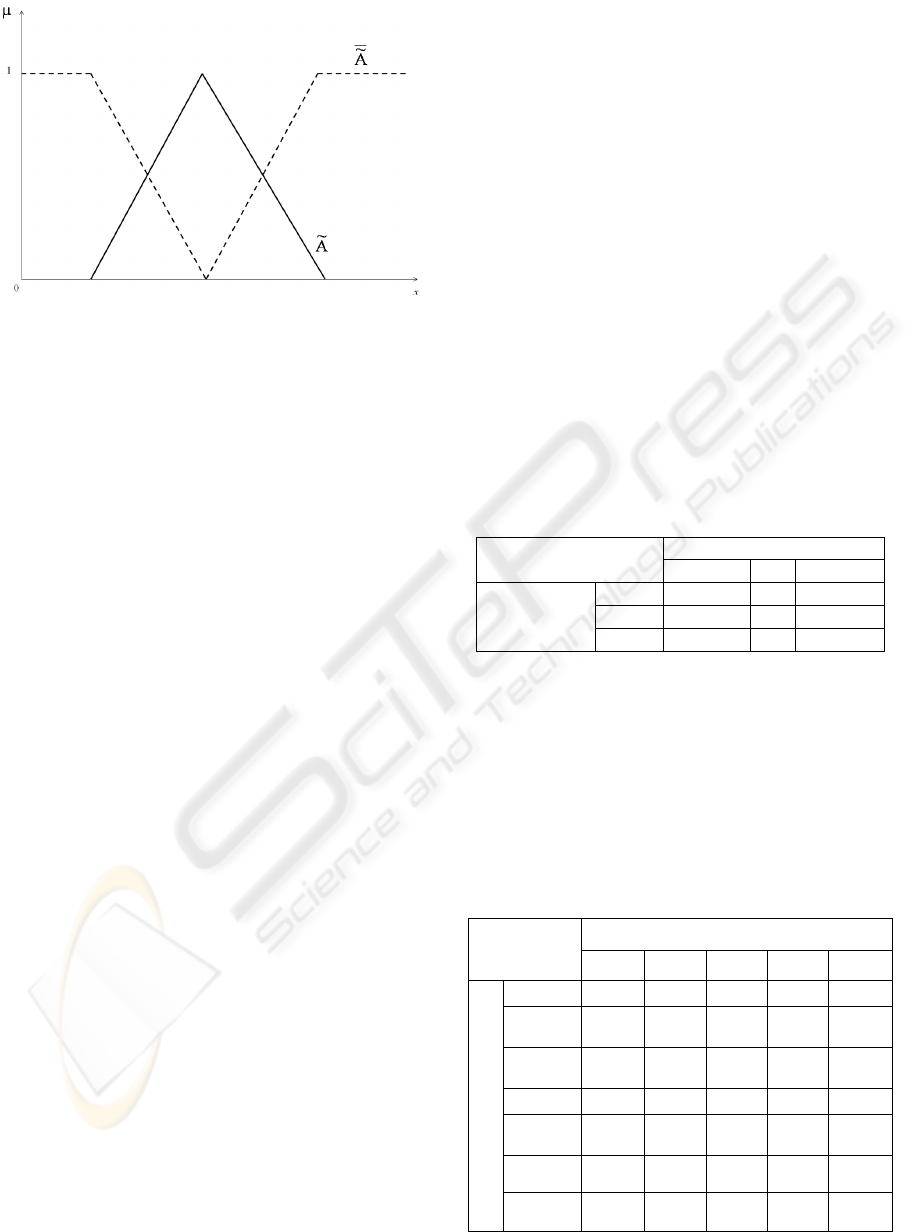
Figure 1: Mapping of
and its complement
.
2.2 Fuzzy Set Theory and Approximate
Reasoning
An AR model uses the degrees of membership of
states in fuzzy sets to draw conclusions about a
system, such as risk of attack on a facility. The AR
result is comprised of a vector of various fuzzy sets
used to describe a specific state of risk and a
respective degree of membership in each fuzzy set.
Now suppose that an SME indicates that values
and
for states x
i
and y
j
, respectively, infers a
particular value
for z
k
. The information provided is
considered a rule governing the outcome z
k
and can
be represented as follows:
Rule 1: IF x
i
is
and y
j
is
THEN z
k
is
These IF-THEN rules consist of an antecedent and a
consequence portion. The conditional portion of the
rule, i.e. the IF x
i
is
and y
j
is
of Rule 1, forms
the antecedent and the consequence of the
antecedent includes THEN z
k
is
. All the rules
governing the particular outcome z
k
involving values
for x
i
and y
j
can be grouped together into a rule base,
see Table 1. Now consider the situation when both x
i
and y
j
can be described by more than one value. In
such a situation, x
i
and y
j
have a degree of
membership in each value that describes them. The
values of x
i
and y
j
are used to identify the governing
rule and infer the value of z
k
. The inferred value of z
k
will have an associated degree of membership which
results from the conjunction , i.e. taking the
minimum value, of the degree of membership for x
i
AND y
j
included in the governing rule. Take for
example the rule specified above with
0.3
and
0.6, which results in a
0.3.
Another applicable governing rule may be:
Rule 2: IF x
i
is
and y
j
is
THEN z
k
is
with
0.7 and
0.6, which results
in
0.6. Both Rule 1 and Rule 2 result in
the value
for z
k
but there are now two different
values for the degree of membership in
. That is,
either Rule 1 OR Rule 2 is applicable and the
disjunction (), i.e. taking the maximum value, of
0.3 and
0.6, results in
0.6. The conjunction and disjunction operations are
used when the logical AND and OR are encountered,
respectively. In each of the rules the logical AND is
encountered and the conjunction operation is used to
determine the resulting degree of membership. The
logical OR is encountered in the example because
either Rule 1 OR Rule 2 result in
. Additional
logical operations can be found in (Ross 2005) as
well as the axioms involved in fuzzy sets. It is
important to note that the excluded middle axiom is
not required for fuzzy sets; therefore, the resulting
degree of membership for AR need not sum to 1.
Table 1: Rule Base.
Rule Base
Universe of Discourse X
Universe of
Discourse Y
2.2.1 Application of AR in Risk
This section illustrates the use of AR in SRAMA
using a simple example to determine the risk of
attack from success likelihood and the economic
consequences of the attack. Table 2 provides the rule
base used to infer the risk given the success
likelihood and the consequences.
Table 2: AR Risk Rule Base.
Risk
Economic Consequence
Very Low Low Medium High Very High
Negligible Very Low Very Low Very Low Very Low Very Low
Extremely
Unlikely
Very Low Very Low Very Low Very Low Low
Very
Unlikely
Very Low Very Low Very Low Low Medium
Unlikely Very Low Low Low Medium
Medium
Somewhat
Likely
Very Low Low Low Medium
Medium
Likely Low Low Medium High Very High
Nearly
Certain
Low Low Medium High
Very
High
Success Likelihood
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
400

An attack scenario S1 has the following input vector
of membership values for success likelihood and
economic consequences:
S1(success likelihood): [0, 0, 0, 0.57, 0.43, 0, 0]
S1(economic consequences): [0, 0, 0, 0, 1]
The leftmost entry for degree of membership in the
vector of success likelihood corresponds to
“negligible”, followed by “extremely unlikely”,
“very unlikely”, “unlikely”, somewhat likely”,
“likely” and the rightmost entry corresponds to
“nearly certain”. The leftmost entry for degree of
membership in the vector of economic consequences
corresponds to “very low” and so on to the rightmost
entry corresponding to “very high”. Using the rule
base of Table 2 and AR operations of Section 2.2,
“very high” economic consequences AND an
“unlikely” success likelihood results in a “medium”
risk with a degree of membership of 0.57. While a
“very high” economic consequences AND a “likely”
success likelihood results in a “medium” risk with a
degree of membership of 0.43. Since either of these
two rules, shown in bold in Table 2, result in
“medium” risk, the maximum of the resulting degree
of membership values is used to determine the final
degree of membership for a “medium” risk. The
resulting vector of membership values for risk in
scenario 1 are:
S1(risk): [0, 0, 0.57, 0, 0]
Corresponding to linguistic risk values of “very
low”, “low”, “medium”, “high”, and “very high”
from left to right. Inference trees, consisting of a
complex sequence of inference rules leading up to
risk are used to assess risk for each attack scenario
(see Bott and Eisenhawer 2006). Here only a
simplified portion is provided.
2.3 Evidential Reasoning
This paper is concerned with a particular aspect of
evidence theory which involves the uncertainty
associated with assigning a specific x to a particular
crisp value A. The SMEs’ degree of belief that x is A
is called a basic evidence assignment (bea). A crisp
set value has a precise well defined boundary and
precisely describes x. The ER model uses the bea in
the antecedent of the rule, to determine the bea for
the consequence of the rule. That is, the SMEs bea
quantifies the evidence supporting a particular claim,
i.e. x is , which can be used to form other belief,
plausibility, and probability measures (see Ross
2005). The bea does not account for the uncertainty
associated with imprecisely describing x with A. The
degree of membership is used to assess the
uncertainty involved in describing a specific state
using an imprecise linguistic value. There have been
recent attempts to combine AR and ER for SRAMA
applications which have been termed fuzzy
evidential reasoning (Yang et al. 2009) and belief
measures on fuzzy sets (Darby 2007). However, the
simultaneous quantification of fuzzy and assignment
uncertainty was not addressed by Yang et al. and
Darby and the reader is referred to Chavez (Chavez
2007). In this paper, AR and ER are recognized as
distinct methods and discretely applied.
An ER result is comprised of a vector of bea
values for x is A
j
, where A
j
...A
n
are the available
crisp linguistic sets in the outcome. Comparing one
resulting vector to another is the focus of this paper.
Here we briefly discuss the operations used to obtain
an ER vector result in SRAMA. A simple method of
determining the bea associated with the inferred
linguistic value for each rule is to take the product of
the bea values involved in the antecedent of the rule.
This process is performed for all the inferred
linguistic values in the result. Two or more rules in
the rule base may result in the same linguistic value,
in such a case these resulting bea values are summed
to determine the resulting bea value for the linguistic
value. It is important to note that the bea (m) must
satisfy the following boundary conditions:
0 (3)
,,,…,
1
(4)
Equation 3 indicates that a bea value cannot be
assigned to the proposition that x
i
is defined by the
null set, , because the null set defines no states.
Equation 4 indicates that the sum of the bea values
for x
i
is A
j
is equal to 1 where, A
j
are crisp subsets of
the power set P(X). The power set P(X) is the set if
all subsets of X.
2.3.1 Application of ER
This section demonstrates the use of ER using a
simple example to determine the effectiveness of
physical inventory from the material inventory
frequency and effectiveness of inventory verification.
Table 3 provides the rule base used to infer the
effectiveness of physical inventory from the material
inventory frequency and effectiveness inventory
verification. A processing facility F1 has the
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE REASONING SECURITY RISK ASSESSMENT
RESULTS
401

following vector of bea values for a specific material
inventory frequency and a specific effectiveness of
inventory verification:
F1(material inventory frequency): [0, 0.1, 0.9, 0]
F1(effectiveness of inventory verification):
[0, 0, 1, 0]
The leftmost entry for bea in the vector of material
inventory frequency corresponds to “not applicable”
(NA), followed by “occasionally”, “regularly”, and
the rightmost entry corresponds to “continuously”.
The leftmost entry for the bea in the vector of
effectiveness of inventory verification corresponds
to “not applicable” (NA), followed by “low”,
“moderate”, and the rightmost entry corresponding
to “excellent”. Using the rule base of Table 3 and
ER operations of Section 2.3, a bea value of 0.1 in
“occasionally” for material inventory frequency
AND a bea value of 1.0 in “moderate” for
effectiveness of inventory verification results in a
bea value of 0.1 in “low” for effectiveness of
physical inventory. While a bea value of 0.9 in
“regularly” for physical inventory frequency AND a
bea value of 1.0 in “moderate” for effectiveness of
inventory verification results in a bea value of 0.9 in
“moderate” for effectiveness of physical inventory.
F1(effectiveness of physical inventory):
[0, 0.1, 0.9, 0],
The resulting vector of values for effectiveness of
physical inventory of: “not applicable”, “low”,
“moderate”, and “excellent” from left to right.
Table 3: Effectiveness of Physical Inventory ER Rule
Base.
Effectiveness of
Physical Inventory
Effectiveness of Inventory
Verification
NA Low Moderate Excellent
NA NA NA NA NA
Occasionally NA Low
Low
Low
Regularly NA Low
Moderate
Moderate
Continuously NA Low Moderate Excellent
3 QUANTIFICATION OF
INFORMATION
UNCERTAINTY
Decision makers are interested in the confidence
associated with each of the competing alternatives.
The quantity of uncertainty present in a result is
related to the confidence (Devore 1999). That is, the
less uncertainty present in the resulting alternative
the more confidence one can have in the result.
Thus, by measuring the information uncertainty
present in each resulting alternative, the possible
alternatives can be compared and the alternative
with the most confidence can be determined.
The quantification of entropy for random
uncertainty was addressed by Shannon (Shannon
1948). The term entropy is defined as a measured
quantity of information uncertainty related to non-
specificity and conflict (Klir and Wierman 1999).
The measure of entropy proposed by Shannon
measures conflict and works as follows: there exists
a regular die with six faces all of which are equally
likely to be thrown and there exists a six sided trick
die with one side being twice as likely to be thrown
as the remaining sides. The regular die has more
entropy than the trick die because all sides are
equally likely to occur in the regular die. The trick
die is less uncertain because one side is twice as
likely to be thrown as each of the remaining five;
thus, one can have more confidence in the resulting
trick die.
Klir and Wierman (Klir and Wierman 1999)
discuss measuring conflict from evidence on sets.
The ER problem examined here does not involve the
entire set but only one state assigned to one or more
set values. Klir (Klir 2006) elaborates on Shannon's
measure of entropy and identifies conflict as the
basis for the entropy measured by Shannon. De Luca
and Termini (Deluca 1972) extended Shannon's
measure of entropy to fuzzy uncertainty in a fuzzy
set while others also presented alternative measures,
see Yager (Yager 1979), and Higashi and Klir
(Higashi and Klir 1982). Pal and Bezdek (Pal and
Bezdek 1994) provide a good summary of many of
the approaches used to measure entropy associated
with a fuzzy set. All the previous approaches
examined for fuzzy uncertainty quantified the
entropy involved in an entire fuzzy set, whereas the
current study examines quantifying the entropy
involved in AR where one state is described using
several fuzzy sets.
Shannon's measure of conflict for probability (p)
has the form
Material Inventory Frequency
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
402

∑
log
. (5)
Klir and Wierman provide an extended measure of
conflict to bea values on sets, that is, in Equation 5,
x is replaced with A and p is replaced with m. For
ER applications, the focus is on a specific x assigned
to A
i
. Thus, the conflict in an ER vector result
is:
∑
log
, (6)
De Luca and Termini's (Deluca and Termini 1972)
measure for the entropy of a fuzzy set is similar to
Shannon's but conceptually different. Shannon
measures the conflict due to random uncertainty
while De Luca and Termini measure the conflict due
to the fuzzy uncertainty associate with a membership
function for a fuzzy set. As shown in Equation 7,
Deluca and Termini proposed quantifying the
conflict of a fuzzy set from its membership function
and the complement of its membership function. Pal
and Bezdek (Pal and Bezdek 1994) indicate that
inclusion of the complement in Equation 7 is
necessary to satisfy maximality.
log
log
(7)
In the previous approaches involving fuzzy
uncertainty, the entropy quantified involves all the
possible states described by a particular fuzzy set
(Pal and Bezdek 1994, Klir and Wierman 1999, Klir
2006); whereas, in this application the entropy
quantified is associated with only one state described
linguistically using various fuzzy sets.
The outcome resulting from the AR is expressed
as a vector of membership values for x in
. In an
AR model the conflict is not among one fuzzy set
but several, that is, there is conflict among all the
fuzzy set alternatives having a non-zero degree of
membership in the resulting vector. There exists a
fundamental difference between the application for
the previous approaches and the application of the
current study. However, Equation 7 can be modified
so that it is applicable to account for the conflict
involved in imprecisely describing a specific state x
with the various fuzzy sets
in the resulting vector
. The proposed equation, applicable to an AR
result, is presented in Equation 8. Note, the major
difference between Equation 7 and 8 is that Equation
8 involves one state x potentially described using n
fuzzy sets,
,,
; whereas, Equation 7 involves one
fuzzy set describing n different states,
,,
.
log
log
(8)
Where
is the vector consisting of the degree of
membership for each fuzzy set in the AR result for
one scenario, and C is the conflict,
is the
degree of membership of state x in the fuzzy set
.
Another type of entropy, known as non-
specificity, reflects the ambiguity in specifying the
exact solution (Klir 2006). Hartley (Hartley) first
proposed measuring the lack of specificity which is
simply related to the number of alternatives present.
Klir simply defines the Hartley measure of
uncertainty as:
H
|
|
, (9)
where
is any function of the subset E. Klir
discusses the Hartley measure as it applies to
probability distribution functions and membership
functions which are not discussed here and the
reader is referred to (Klir 2006, Klir and Wierman
1999). In this paper, the measure of non-specificity
is considered as a means to determine the lack of
specificity in the resulting AR or ER vector using
the number of non-zero alternatives in the vector. By
considering that
instead represents a vector result
and E represents R, the number of nonzero values in
the resulting vector, the non-specificity of the
resulting vector is determined. The measure for non-
specificity in an AR or an ER result is thus
quantified using Equation 10:
N
|
|
, (10)
Where R is the number of linguistic sets in the
resulting AR or ER vector having a non-zero degree
of membership or bea, respectively.
Random uncertainty may be present in available
information elicited from SMEs but it is at an
epistemic level and captured in the linguistic values
provided by the SMEs. As a result the conflict due to
random uncertainty is captured by Equation 6 for ER
or Equation 8 for AR. Conflict is determined
differently in AR and ER applications due the
restrictions of Equation 2 on the degree of
membership and the restrictions of Equations 3 and
4 on the bea. Equations 6, 8 and 10 have units of bits
of information from the use of the logarithm base 2
(Klir 2006). A simple determination of maximum
confidence can be made from minimum information
uncertainty among competing alternatives.
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE REASONING SECURITY RISK ASSESSMENT
RESULTS
403

3.1 Entropy in AR and ER Results
The quantification of conflict and non-specificity in
AR and ER results are demonstrated here using the
examples provided in Section 2. Using Equation 6
the conflict involved in the ER result
F1(effectiveness of physical inventory):[0, 0.1, 0.9,
0], is calculated as.
0.1log
0.1
0.9log
0.9 0.469
The non-specificity involved in the ER result is
calculated using Equation 10.
N
|
2
|
1
Using Equation 8 the conflict involved in the AR
result S1(risk): [0, 0, 0.57, 0, 0], is calculated as
follows. Recall that the membership of the
complement is determined from Equation 2.
0.57log
0.57
0.43log
0.43 0.9858
The non-specificity involved in the AR result is
calculated using Equation 10.
N
|
1
|
0
In addition to the ER and AR example provided
previously two additional ER results and AR results
are provided. The ER and AR results and their
quantities of information uncertainty are presented
in Tables 4 and 5, respectively.
Table 4: ER entropy results for Effectiveness of Physical
Inventory example.
ER result Conflict Non-specificity
F1[0, 0.1, 0.9, 0] 0.469 1
F2[0, 0.2, 0.8, 0] 0.722 1
F3[0, 0.15, 0.75, 0.1] 1.054 1.585
Table 5: AR Entropy results for Economic Risk example.
AR result Conflict Non-specificity
S1[0, 0, 0.57, 0, 0] 0.9858 0
S2[0, 0.3, 0.7, 0.2, 0] 2.883 1.585
S3[0, 0.2, 0.6, 0.2, 0.1] 2.484 2.000
The results demonstrate the utility of quantifying
information uncertainty to compare the results. In
Table 4, the effectiveness of physical inventory, F1,
F2 and F3 all result in a linguistic value as “mostly
moderate”. There is an observable difference in each
resulting vector; however, a realistic comparison is
not possible without a useful metric. Entropy
measures, specifically conflict, provide a
recognizable and comparable difference with all
three ER results. In the case of the AR results, Table
5, there is also a recognizable difference in the
conflict and the non-specificity. The non-specificity
reflects a difference that can also be discerned
visually, i.e. the greater number of non-zero
alternatives the greater the non-specificity.
Alternatively, measuring the conflict provides
comparative information that is not as easily
discerned visually.
Tables 4 and 5 illustrate the quantification of
the conflict and non-specificity using simple AR and
ER models. Based on information uncertainty, the
alternative with the least information uncertainty is
also the alternative with the most confidence.
Therefore, F1 and S1 are the alternatives providing
the most confidence.
4 CONCLUSIONS
ER and AR results for SRAMA have quantifiable
amounts of information uncertainty and this study
extends information theory to AR and ER SRAMA
models. Straight-forward extensions of previous
approaches are presented in this paper and used to
quantify the information uncertainty in AR results.
The information uncertainty measurements of
conflict and non-specificity associated with AR and
ER results are illustrated and used to compare the
results to one another. Maximum confidence is
simply based on minimum measured information
uncertainty in each result. Through ongoing
research, the results can be further extended through
the development of a metric comparing measured
confidence to the maximal potential value of
confidence determined from a combined measure of
information uncertainty. Moreover, future work will
involve comparisons of the results obtained using
the proposed metrics to rank the results to those
obtained from a SME ranking of the results.
REFERENCES
Barret, J., and Woodall, W.: A Probabilistic Alternative to
Fuzzy Logic Controllers. IEEE Transactions Vol. 29,
459-467 (1997)
Bott, T. F., Eisenhawer, S. W.: Risk Assessment When
Malevolent Actions Are Involved, Proc. of the RAMS
’06. Annual Reliability and Maintainability Sym-
posium, 2006. Washington, DC USA.
Chavez, G. M.: On Fusing Linguistic and Assignment
Uncertainty in Damage Assessment of Structures,
Diss, University of New Mexico, Dec. 2007
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
404

Darby, J. L.: Evaluation of Risk from Acts of Terrorism
Using Beliefs and Fuzzy Sets, Journal of Nuclear
Materials Management, Winter 2007, Vol. 35, No. 2,
pp 19-34odel Using Belief and Fuzzy Sets, Sandia
Report SAND2006-5777 September 2006
De Luca, A., Termini, S.: A definition of a
Nonprobabilistic Entropy in the Setting of Fuzzy Sets
Theory. Infor. and Control, Vol. 20, 310--312 (1972)
Devore, J.: Probability and Statistics for Engineering and
the Sciences, Fifth Edition. Duxbury Pacific Grove,
California (1999) Duxbury
Hartley, R.: Transmission of Information. The Bell
Technical Journal, Vol. 7, 3, 535--563
Higashi, M., Klir, G.: On Measures of Fuzziness and
Fuzzy Compliments., Int. J. of Gen.Sys., Vol 8, 169--
189, (1982)
Klir, G.: Uncertainty and Information, Foundations of
Generalized Information Theory. John Wiley and
Sons, New York (2006)
Klir, G., Wierman, M.: Uncertainty Based Information,
Elements of Generalized Information Theory. Physica-
Verlag, Heidelberg (1999)
Klir, G., Yuan, B.: Fuzzy Sets and Fuzzy Logic, Theory
and Applications. Prentice Hall, New Jersey (1995)
Lewis, H.: The Foundations of Fuzzy Control. Plenum
Press, New York (1997)
Oberkampf, W., Helton, J., Joslyn, C., Wojtkiewicz, S.,
Ferson, S.: Challenge Problems: uncertainty in System
Response Given Uncertain Parameters, Reliability
Engineering and System Safety, Vol. 85, 11--19 (2004)
Pal, N., Bezdek, J.: Measuring Fuzzy Uncertainty. IEEE
Transactions on Fuzzy Systems. Vol. 2, No. 2, 107--
118 (1994)
Ross, T.: Fuzzy Logic with Engineering Applications, 2nd
Edition. John Wiley and Sons, West Sussex, (2004)
Shannon, C.: The Mathematical Theory of Comm.
University of Illinois Press, Urbana, IL (1948)
Yang, Z. L., Wang, J., Bonsall, S., and Fang, Q. G., Use of
Fuzzy Evidential Reasoning in Maritime Security
Assessment, Risk Analysis Vol. 29, No. 1, 2009, pp
95-120
Yang , J., Liu, J., Wang, J., Sii, H., Wang, H., Belief Rule-
Base Inference Methodology Using the Evidential
Reasoning Approach-Rimer, IEEE Transactions on
Systems, Man and Cybernetics Part A: Systems and
humans Vol 36, No. 2, March 2006 pp 266-285
Yager R.: On Measures of Fuzziness and Negation, Part I:
Membership in the Unit Interval., Int. J. General
Systems, Vol. 5, 221--229, (1979)
Zadeh, L.: Discussion: Probability Theory and Fuzzy
Logic are Complementary Rather than Competitive.
Technometrics Vol. 37, 271--276 (1995)
INFORMATION UNCERTAINTY TO COMPARE QUALITATIVE REASONING SECURITY RISK ASSESSMENT
RESULTS
405
