
EVALUATION OF COLLECTING REVIEWS IN CENTRALIZED
ONLINE REPUTATION SYSTEMS
Ling Liu, Malcolm Munro and William Song
School of Engineering and Computing Sciences, Durham University, U.K.
Keywords:
Online reputation systems, Evaluation, e-Commerce.
Abstract:
Background: Centralized Online Reputation Systems (ORS) have been widely used by internet companies.
They collect users’ opinions on products, transactions and events as reputation information then aggregate and
publish the information to the public.
Aim: Studies of reputation systems evaluation to date have tended to focus on isolated systems or their aggre-
gating algorithms only. This paper proposes an evaluation mechanism to measure different reputation systems
in the same context.
Method: Reputation systems naturally have differing interfaces, and track different aspects of user behavior,
however, from information system perspective, they all share five underlying components: Input, Processing,
Storage, Output and Feedback Loop. Therefore, reputation systems can be divided into these five components
and measured by their properties respectively.
Results: The paper concentrates on the evaluation of Input and develops a set of simple formulas to represent
the cost of reputation information collection. This is then applied to three different sites and the resulting
analysis shows the pros and cons of the differing approaches of each of these sites.
1 INTRODUCTION
One of the biggest advantages that the Internet offers
is it largely reduced the transaction costs of collect-
ing, processing and distributing information. It cre-
ates new opportunities for people sharing their opin-
ions and communicating with others out of local area.
Online Reputation Systems use internet technologies
to build large scale word-of-mouth networks to col-
lect and disseminate individual’s opinions and expe-
riences on a wide range of topics, including products,
services, shops, etc (Dellarocas, 2003).
Based on information storage location, reputation
systems can be divided into two main types. One
is called Centralized Reputation Systems, which rely
on a central server to gather, process and disseminate
(e.g., by publishing on a web site) information. Dis-
tributed Reputation Systems, on the other hand, rely
on decentralized solutions where every peer stores in-
formation about the other agents (Jøsang et al., 2007).
This paper concentrates on centralized systems only,
hence in the following sections, all ‘reputation sys-
tems’ refer to centralized ones except special notes.
Online reputation systems have three main roles:
1) Online auction sites use reputation, one of the most
important factors for assessing trust (Falcone and
Castelfranchi, 2001), to build trust between buyers
and sellers. As long as agents value their esteem, the
long-term reputation based trust could be well con-
structed (Laat, 2005). 2) To reduce information asym-
metry, many online stores encourage users to write
reviews to help potential consumers gaining more in-
formation on products (David and Pinch, 2005; Del-
larocas, 2003). 3) Information centres interestingly
found that ‘the wisdom of crowd’ (Surowiecki, 2005)
can help internet users to filter information. For ex-
ample, Digg is a website made for people to share in-
ternet content by submitting links and stories. Voting
stories up (‘digging’) and down (‘buring’) is the site’s
cornerstone function. Each story and comment has a
number with them which is calculated by the number
of ‘diggs’ minus the number of ‘buries’. The bigger
the number is, the more interesting the story is.
Most work in reputation systems area focuses on
analyzing one-type-systems. For example, Dellarocas
(2001) and Resnick et al. (2006) discussed the value
of eBay-like mechanisms; David and Pinch (2005)
and Chevalier and Mayzlin (2006) focused on how
281
Liu L., Munro M. and Song W.
EVALUATION OF COLLECTING REVIEWS IN CENTRALIZED ONLINE REPUTATION SYSTEMS.
DOI: 10.5220/0002763802810286
In Proceedings of the 6th International Conference on Web Information Systems and Technology (WEBIST 2010), page
ISBN: 978-989-674-025-2
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
reviews influenced online book stores and some re-
searchers discussed the role of reputation systems in
social networks Lerman (2007); Lampe and Resnick
(2004). A few researchers lay emphasis on reviewing
of different reputation systems (Sabater and Sierra,
2005; Liang and Shi, 2005; Ruohomaa et al., 2007).
However most of these review papers concentrated on
the aggregating algorithms only, which is one part of
the whole process of reputation systems.
This paper proposes an evaluation mechanism
which aims at measuring different reputation systems
in the same context and covering all aspects of the
systems.
2 EVALUATION MECHANISM
Reputation systems naturally have different inter-
faces, and track different aspects of user behavior,
however, they all share certain underlying compo-
nents (Friedman et al., 2007). From the perspective
of the information flow, reputation systems can be de-
fined as systems that use internet technologies to col-
lect users’ experiences and opinions as ‘reputation in-
formation’, and then aggregate, store and publish it to
the public.
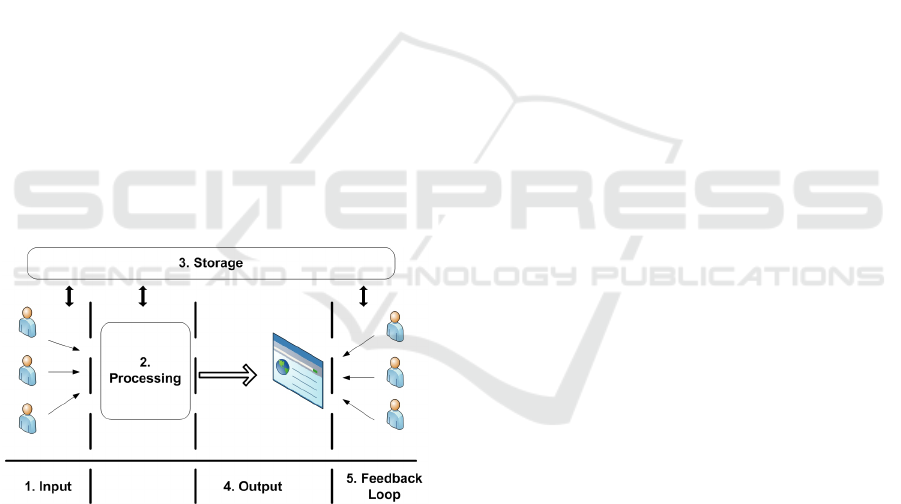
Therefore all reputation systems have the follow-
ing five underlying components (see Figure 1):
Figure 1: ORS Structure.
1. Input refers to the collection of reputation infor-
mation (ratings, reviews, feedback, etc) and other
related data.
2. Processing. The aim of processing is to aggregate
ratings to a comparable format. In most cases,
systems just use simple aggregation such as sum-
mation or average.
3. Storage. All information that has been collected
and processed need to be stored.
4. The processes of publishing processed reputation
information to the public is the Output.
5. Feedback Loop. To ensure the accuracy of reputa-
tion information and to filter the ‘bad’ reputation
information, some systems choose to let users to
‘evaluate’ the reputation information, it is the ‘re-
view of the reviews’. For example, Amazon.com
asks users to rate on whether ‘the review is help-
ful’ and the reviews can be ranked by their ’use-
fulness’.
By identifying these components, a series of
benchmark criteria can be built for each of them.
Thus reputation systems can be measured regardless
of their different forms or roles. This paper takes In-
put as an example to explain how the criteria are de-
fined.
3 INPUT EVALUATION
The paper chooses input is because it is the founda-
tion reputation system. It decides who can supply rep-
utation information, what and how the information is
collected. All other components are based on the con-
tent collected from Input. The criteria of Input are de-
fined based on the following four aspects: collection
channel, information source, reputation information
and collection costs. The first three aspects cover the
properties of the whole collection process, while the
last one assesses the costs. A summary of each aspect
is given below.
It worth noted here that the evaluation mechanism
is aimed to measure reputation systems rather than the
whole application websites or their companies. Hence
if there is any factor that relates to business strategies
instead of the system, it may be ignored or assigned
to a constant which can be applied to all applications.
3.1 Collection Channel
Collection Channel (CC) refers to how a reputation
system collects information from evaluators. Cur-
rently three main channels are used:
• CC
1
: Most systems allow users leave reviews on
their website directly.
• CC
2
: A few systems collect reputation informa-
tion through a third party platform. For example,
BizRate.com, the price comparison website, co-
operates with many online stores and these have
agreed to allow BizRate to collect product and
store feedback from their customers when they
make purchases.
• CC
3
: Some sites actively track reputation infor-
mation from evaluators. For instance, Google
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
282

uses their web crawling robots to collect informa-
tion from users’ websites rather than waiting for
them submitting their ratings.
The way how information has been collected in-
fluences many aspects of reputation information. For
example, CC
3
usually can collect information from
more sources, however it may cause lack accuracy of
the reputation information.
3.2 Information Source
Information Source is the evaluators who provide the
reputation information to the system. They measure:
• Information Source Scale (ISC): The scale of in-
formation source relates to whether a reputation
system has any restrictions on them.
– ISC
1
: There is no restrictions on people leaving
reviews, which means all internet users can be
evaluators.
– ISC
2
: Only registered users can leave reviews.
– ISC
3
: Only some of registered users are capable
to leave reviews. For example, eBay requires
users to leave feedback only after a transaction
has finished.
Sufficient evaluators can help reputation systems
to avoid personal bias whereas the restriction of
evaluators may influence level of granularity be-
tween evaluators and targets (target refers to the
entity that evaluators leave reputation information
to).
• Granularity (GRN): Reputation is a multidimen-
sional value. An individual may enjoy a very high
reputation for their expertise in one domain, while
having a low reputation in another (Zacharia and
Maes, 2000). Therefore, Granularity identifies
how information sources associates to the target.
– GRN
1
: When a system does not have strict re-
quirements on evaluators (for instance, ISC
1
and ISC
2
), the granularity is usually very loose.
– GRN
2
: A system has the requirements of inter-
actions between evaluators and targets.
– GRN
3
: A system requires information source to
have a good credibility to leave reviews.
A high level GRN, for instance, GRN
2
or GRN
3
,
can increase the cost for an evaluator leaving reviews,
which means, it may reduce the number of fake or
‘bad’ reputation information.
3.3 Reputation Information
Reputation information is the key factor of online rep-
utation systems.
• Breadth: The number of properties that have been
collected. It is considered that more information
can give users a better understanding of the tar-
get, but on the other hand, too much informa-
tion may reduce evaluators’ passion on leaving re-
views. Most reputation systems let evaluators to
choose how much information they want to pro-
vide by marking the properties as ‘Required’ or
‘Optional ’.
• Format (IPF): The format of reputation informa-
tion:
– IPF
1
: Rating Scales. For example, evaluators
need to rate the product from 1 to 5.
– IPF
2
: Text comments. Evaluators are asked to
write a text comments of targets.
– IPF
3
: Other Formats, for example, pictures or
videos.
3.4 Collection Costs
Considering ‘money costs’ always can be influenced
by business selections, this paper discusses the time
costs only. Therefore, the Collection Costs refers to
how much time it takes to collect a single unit reputa-
tion information. The costs are estimated by different
collection channels (CC
1
, CC
2
, CC
3
).
3.4.1 Time Costs for CC1
CC
1
systems require evaluators to leave reviews on
their sites, therefore the collection costs is how much
time it takes an evaluator to browse the website be-
fore they could input the reputation information (T
br
)
plus the time to input (T
in
) and submit the information
(T
st
).
T
ct
= T
br
+ T
in
+ T
st
(1)
1. T
br
is decided by the page’s loading time (T
ld
) and
how much it takes to browse the page(T
rd
) as well
as the number of pages need to be browsed (N
p
):
T
br
= (T
ld
+ T
rd
) ∗ N
p
(2)
It is considered that T
br
is a factor which relates to
business strategies rather than the reputation sys-
tem itself, the following assumptions can be made
to simplify the formula:
• With the development of internet technologies,
T
ld
is a very small number when comparing to
human reading/inputing time. Thus it can be
assumed: T
ld
= 0.
• According to Weinreich et al. (2008), average
browsing time can be estimated as:
EVALUATION OF COLLECTING REVIEWS IN CENTRALIZED ONLINE REPUTATION SYSTEMS
283

T
rd
= 0.044 ∗ W
pp
+ 25.0 (3)
If all systems have the same W
pp
= 200, then:
T
rd
= 0.044 ∗ 200 + 25 = 33.8(seconds) (4)
• Suppose all systems require users to browse
two pages: N
p
= 2.
According to Equation (2–4),
T
br
= (0 + 33.8) ∗ 2 = 67.6 (5)
2. T
in
depends on the number of different format
information(IPF) and how much time it takes to
finish each of them:
T
in
= N
f 1
∗ T
ip,1
+ N
f 2
∗ T
ip,2
+ N
f 3
∗ T
ip,3
(6)
N
f 1
, N
f 2
, N
f 3
: The number of format IPF
1
, IPF
2
and IPF
3
information.
T
ip,1
, T
ip,2
, T
ip,3
: The time the evaluator needs to
complete IPF
1
, IPF
2
and IPF
3
format information
respectively.
• T
ip,1
: To complete an IPF
1
information, it needs
to use the mouse to make the selection. Accord-
ing to Hansen et al. (2003), the time for com-
pleting a task by mouse is between 932ms −
1441ms, on average, it is 1.2 seconds.
• T
ip,2
: The time for inputting IPF
2
format de-
pends on the words to be written and the human
input speed. From a research that for average
computer users, the average rate for composi-
tion is 19 words per minute (Karat et al., 1999).
• T
ip,3
is the time for creating and uploading a
picture or video depends on the size of the file
and the their internet connections.
Based on above analysis, Equation (6) becomes:
T
in
= N
f 1
∗ 1.2 +
N
f 2
∑
i=1
W
pr,i
∗
60
19
+
N
f 3
∑
i=1
T
ip,3,i
= 1.2 ∗ N
f 1
+ 3.16 ∗
N
f 2
∑
i=1
W
pr,i
+
N
f 3
∑
i=1
T
ip,3,i
(7)
W
pr,i
is the words count of review i.
3. T
st
is the time for submitting reputation informa-
tion to the server. Based on today’s technology
condition, T
st
for IPF
1
and IPF
2
can be assumed to
be 0 when comparing to human input time. While
IPF
3
costs much more time than the first two for-
mats. Considering at the moment, most reputation
systems accept IPF
1
and IPF2 only, and in order
to simplify the equation, T
ip,3
can be used to esti-
mate T
st
for IPF
3
, which means, all T
st
= 0.
Therefore, according to Equation (1–7):
T
ct,cc
1
= 67.6 + 1.2 ∗ N
f 1
+
3.16 ∗
N
f 2
∑
i=1
W
pr,i
+
N
f 3
∑
i=1
T
ip,3,i
(8)
It can clearly be seen that creating a rich media
review takes more time than generating a text review.
However, at the moment rich media reviews are very
rare in applications, which means, W
pr,i
becomes the
decisive factor.
3.4.2 Time Costs for CC2
CC
2
allows evaluators to go to the page of leaving re-
views directly, which means:
T
ct,cc
2
= T
in
+ T
st
(9)
According to Equation (6–8):
T
ct,cc
2
= 1.2 ∗ N
f 1
+ 3.16 ∗
N
f 2
∑
i=1
W
pr,i
+
N
f 3
∑
i=1
T
ip,3,i
(10)
3.4.3 Time Costs for CC3
When using CC
3
to collect reputation information,
usually reputation systems do not need evaluators to
‘input’ any specific reputation information like CC
1
and CC
2
do. Therefore, their collection costs can be
estimated as their information tracking time only:
T
ct,cc
3
= indexing speed (11)
4 APPLICATION REVIEWS
Three applications have been selected, each of
them represents one different role of reputation
systems: eBay (www.ebay.com) is one of the
world’s largest online auction websites. Amazon
(www.amazon.com) is an multi-functional electronic
commerce company, which acts as an online retailer
as well as a fixed-price online marketplace. This pa-
per evaluates the product review system in their on-
line retailer markets only. Digg (www.digg.com) as
introduced in Section 1 is the third site.
4.1 Collection Channel
All three applications collect reputation information
through their websites, which means they all use CC
1
.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
284
4.2 Information Source
The applications have different information scales
and granularity requirements (See Table 1).
Table 1: Information Source.
Scale Granularity
eBay ISC
3
GRN
2
Amazon ISC
2
GRN
1
Digg ISC
2
GRN
1
As a platform which can track and record trans-
actions, eBay only allows agents to leave feedback
where a transaction has been made. Although Ama-
zon sells products through their website, it encour-
ages all register users to leave reviews no matter they
bought the product from Amazon or not. Digg, like
Amazon, allows all registered users to leave feedback.
4.3 Reputation Information
Table 2 shows the evaluation of reputation informa-
tion of the applications. The Breadth are shown by the
number of ‘required’ and ‘optional’ information, for
example, R(1), O(1) means the application has one re-
quired review and one optional review. Similarly, the
number in brackets followed each IPF is the number
of that format reviews.
Table 2: Reputation Information.
Breadth Format
eBay R(2), O(4) IPF
1
(5), IPF
2
(1)
Amazon R(2), O(2) IPF
1
(1), IPF
2
(2), IPF
3
(1)
Digg R(1), O(1) IPF
1
(1), IPF
2
(1)
eBay asks agents to rate the transaction as pos-
itive(‘+1’), negative(‘-1’), or neutral rating(‘0’) as
well as a short comments to explain their ratings.
They also offer an optional opportunity for users to
rate more details of the transaction.
Amazon allows users to leave two kinds of re-
views: text comments and videos. Both reviews re-
quire users to give a overall rating (from 1 to 5) for
the product and a title for the review.
Leaving reviews in Digg is simpler than the other
sites. The evaluator can choose ‘digg or bury’ the
story or to leave a text comments.
4.4 Collection Costs
As all applications use CC
1
to collect information,
Equation (8) is used to estimated the collection costs
(see Table 3, results are in seconds). Take eBay as an
example, the application has 5 IPF
1
and 1 IPF
2
, bring
these numbers into Equation (8):
T
ct,cc
1
= 67.6 + 1.2 ∗ 5 + 3.16 ∗ W
pr
= 73.6 + 3.16W
pr
(seconds)
(12)
From the results, it can be seen that if W
pr
are the
same, Digg has the lowest cost and Amazon has the
highest (it is considered that T
ip,3
is at lease more than
10 minutes).
Table 3: Collection Costs.
Costs Model
eBay 73.6 + 3.16W
pr
Amazon 68.8 + 3.16W
pr,1
+ 3.16W
pr,2
+ T
ip,3
Digg 68.8 + 3.16W
pr
However actually each application has different
limitations on W
pr
: eBay only allows at most 80 char-
acters, Amazon does not accept reviews more than
1000 words. For a better comparison, it is worth eval-
uating the applications by their minimum and maxi-
mum costs. Considering the limit popularity of IPF
3
and to make a clear comparison with the other ap-
plications, the costs for leaving IPF
3
on Amazon is
temporarily removed.
Minimum Costs. is the cost of finishing required
information with least W
pr
. eBay requires evaluator
to leave at least one IPF
1
and one IPF
2
; Amazon re-
quires one IPF
1
and two IPF
2
s; while Digg allows
users to leave either one IPF
1
or one IPF
2
. Compar-
ing the costs of leaving the two formats, IPF
1
is used
to calculate DIgg’s minimum costs.
Maximum Costs. is the cost of finishing both re-
quired and optional information with maximum W
pr
.
eBay has a limitation of maximum 80 characters for
W
pr
. Assuming that five characters counts as one
word, then, eBay’s maximum W
pr
is 16. Amazon
has a clearly limitation of maximum 1,000 words per
review and 20 words for review title. Digg has no
limitation on the maximum words, to normalize the
result, it’s W
pr
can be assigned to 2000 (as twice as
Amazon’s limit).
The calculated minimum and maximum costs are
shown on Table 4:
EVALUATION OF COLLECTING REVIEWS IN CENTRALIZED ONLINE REPUTATION SYSTEMS
285

Table 4: Minimum and Maximum Costs.
Min. Costs Max. Costs
eBay 71.96 124.16
Amazon 75.12 3292.00
Digg 68.80 6388.80
4.5 Summary
The result of the evaluation shows that although
eBay’s stricter requirements may limit the number of
evaluators, it also brings a higher granularity between
evaluators and targets. All three sites have similar
minimum collection costs, while Amazon and Digg
have much higher maximum costs than eBay. Con-
sidering as CC
1
systems, the collection cost is how
much it takes the evaluators to leave reviews, higher
cost hints the system needs a better incentive mecha-
nism to encourage their evaluators to leave reviews.
5 CONCLUSIONS
This paper has proposed an evaluation mechanism of
online reputation systems by identifying reputation
systems into five components. A detailed set of cri-
teria for Input was defined and tested by applying to
three applications. Further work is in process to for-
mulise analysis of the other four components (pro-
cessing, storage, output and feedback loop). More-
over, the criteria for Input could be improved with
more objective and quantitative criteria. Although the
evaluation mechanism provides an effective measure-
ment of different systems, it can be extended to ob-
jective and quantified analysis of single type systems
by defining specific criteria.
REFERENCES
Chevalier, J. A. and Mayzlin, D. (2006). The effect of word
of mouth on sales: Online book reviews. Journal of Mar-
keting Research (JMR), 43(3):345–354.
David, S. and Pinch, T. (2005). Six degrees of reputation:
The use and abuse of online review and recommendation
systems. Social Science Research Network Working Pa-
per Series.
Dellarocas, C. (2001). Analyzing the economic efficiency
of ebay-like online reputation reporting mechanisms. In
EC ’01: Proceedings of the 3rd ACM conference on Elec-
tronic Commerce, pages 171–179. ACM.
Dellarocas, C. (2003). The digitization of word of mouth:
Promise and challenges of online feedback mechanisms.
Manage. Sci., 49(10):1407–1424.
Falcone, R. and Castelfranchi, C. (2001). Social trust:
A cognitive approach. In Castelfranchi, C. and Tan,
Y.-H., editors, Trust and deception in virtual societies,
pages 55–90. Kluwer Academic Publishers, Norwell,
MA, USA.
Friedman, E., Resnick, P., and Sami, R. (2007).
Manipulation-resistant reputation systems. In Nisan, N.,
Roughgarden, T., Tardos, E., and Vazirani, V. V., editors,
Algorithmic Game Theory, pages 677–697. Cambridge
University Press.
Hansen, J. P., Johansen, A. S., Hansen, D. W., and Itoh, K.
(2003). Command without a click: Dwell time typing
by mouse and gaze selections. In Rauterberg, M., editor,
Proceedings of Human-Computer Interaction - Interac-
tion’03, pages 121–128. IOS Press.
Jøsang, A., Ismail, R., and Boyd, C. (2007). A survey of
trust and reputation systems for online service provision.
Decis. Support Syst., 43(2):618–644.
Karat, C.-M., Halverson, C., Horn, D., and Karat, J. (1999).
Patterns of entry and correction in large vocabulary con-
tinuous speech recognition systems. In CHI ’99: Pro-
ceedings of the SIGCHI conference on Human factors in
computing systems, pages 568–575. ACM Press.
Laat, P. (2005). Trusting virtual trust. Ethics and Informa-
tion Technology, 7(3):167–180.
Lampe, C. and Resnick, P. (2004). Slash(dot) and burn: dis-
tributed moderation in a large online conversation space.
In CHI ’04: Proceedings of the SIGCHI conference on
Human factors in computing systems, pages 543–550.
ACM.
Lerman, K. (2007). Social information processing in news
aggregation. IEEE Internet Computing, 11(6):16–28.
Liang, Z. and Shi, W. (2005). Performance evaluation of
rating aggregation algorithms in reputation systems. In
International Conference on Collaborative Computing:
Networking, Applications and Worksharing, page 10 pp.
IEEE Computer Society.
Resnick, P., Zeckhauser, R., Swanson, J., and Lockwood,
K. (2006). The value of reputation on ebay: A controlled
experiment. Experimental Economics, 9(2):79–101.
Ruohomaa, S., Kutvonen, L., and Koutrouli, E. (2007).
Reputation management survey. In ARES ’07: Pro-
ceedings of the The Second International Conference
on Availability, Reliability and Security, pages 103–111,
Washington, DC, USA. IEEE Computer Society.
Sabater, J. and Sierra, C. (2005). Review on computational
trust and reputation models. Artificial Intelligence Re-
view, 24(1):33–60.
Surowiecki, J. (2005). The Wisdom of Crowds. Anchor.
Weinreich, H., Obendorf, H., Herder, E., and Mayer, M.
(2008). Not quite the average: An empirical study of
web use. ACM Trans. Web, 2(1):1–31.
Zacharia, G. and Maes, P. (2000). Trust management
through reputation mechanisms. Applied Artificial Intel-
ligence, 14(9):881–907.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
286
