
A NEW APPROACH TOWARDS VERTICAL SEARCH ENGINES
Intelligent Focused Crawling and Multilingual Semantic Techniques
Sybille Peters, Claus-Peter R
¨
uckemann and Wolfgang Sander-Beuermann
Regionales Rechenzentrum f
¨
ur Niedersachsen (RRZN), Leibniz Universit
¨
at Hannover (LUH), Hannover, Germany
Keywords:
Focused crawling, Search engine, Vertical search engine, Metadata, Educational research, Link analysis.
Abstract:
Search engines typically consist of a crawler which traverses the web retrieving documents and a search front-
end which provides the user interface to the acquired information. Focused crawlers refine the crawler by
intelligently directing it to predefined topic areas. The evolution of search engines today is expedited by
supplying more search capabilities such as a search for metadata as well as search within the content text.
Semantic web standards have supplied methods for augmenting webpages with metadata. Machine learning
techniques are used where necessary to gather more metadata from unstructured webpages. This paper ana-
lyzes the effectiveness of techniques for vertical search engines with respect to focused crawling and metadata
integration exemplarily in the field of “educational research”. A search engine for these purposes implemented
within the EERQI project is described and tested. The enhancement of focused crawling with the use of link
analysis and anchor text classification is implemented and verified. A new heuristic score calculation formula
has been developed for focusing the crawler. Full-texts and metadata from various multilingual sources are
collected and combined into a common format.
1 INTRODUCTION
This investigation is part of a an ambitious scheme
funded by the European Commission under the 7th
Framework Programme: The European Educational
Research Quality Indicators (EERQI) project was
launched 2008 for a duration of three years with the
purpose of finding new indicators and methodologies
for determining research quality of scientific publica-
tions in the field of “educational research” (EERQI-
Annex1, 2008). A key task within this project is the
development of an exemplary vertical search engine
for “educational research” documents. For this pur-
pose, mechanisms must be found for locating “educa-
tional research” publications in the WWW as well as
for distinguishing scientific research documents from
non-scientific documents.
The goal is to provide extensive search capabili-
ties for the user of the search engine. It should be pos-
sible to search within the full-text and metadata (lan-
guage, publisher, publication date, peer-review sta-
tus etc.) of the document. The methods described
exemplarily in this case study might then be applied
to any vertical search engine.
1.1 Existing Search Engines
A number of search engines focusing on scien-
tific research were analyzed. These included OAIs-
ter (OAIster, 2009), Scirus (Scirus, 2009), Google
scholar (Google Scholar, 2009), and the Education
Resources Information Center (ERIC, 2009). None of
these search engines provided all required features in-
cluding a granular topical selection, searching within
content and metadata such as title, subject, author
and/or language and inclusion of documents in other
languages than English in the corpus.
1.2 Focused Crawling
The goal of a focused crawler is to limit crawling
to a specific field of interest. Frequency measures
for the keywords within URLs (Zheng et al., 2008),
link anchor texts (Zhuang et al., 2005), title, and full-
text (Bergmark et al., 2002) as well as occurrences
of links to and from other pages (Chakrabarti et al.,
1998) are some of the parameters that have been eval-
uated. Machine learning methods have been applied
to steer the crawler to pages with a higher probability
of compliance with the requested topic and determine
whether the documents meet the criteria. The crawl
181
Peters S., RÃijckemann C. and Sander-Beuermann W.
A NEW APPROACH TOWARDS VERTICAL SEARCH ENGINES - Intelligent Focused Crawling and Multilingual Semantic Techniques.
DOI: 10.5220/0002777901810186
In Proceedings of the 6th International Conference on Web Information Systems and Technology (WEBIST 2010), page
ISBN: 978-989-674-025-2
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

must also be refined by selecting a list of high qual-
ity start URLs (“seeds”). Starting the crawler on open
access archives, academic author or institutional web-
sites are some of the strategies that have been used
(Zhuang et al., 2005). It must also be established how
far the crawler may deviate from topically relevant
pages (“tunneling”) to find more clusters of relevant
pages (Bergmark et al., 2002).
Classification methods are then applied to deter-
mine whether the retrieved page belongs to a target
topic. For this purpose a set of training documents
are used. Common methods are a vector space model
with tf-idf term weights and a Naive Bayes, k–nearest
neighbor, or support vector machine classifier (Pant
et al., 2004; Manning et al., 2008). In addition to lim-
iting the crawl to a certain topic, mechanisms must
be applied to assure that the retrieved documents are
actually scientific research documents. It needs to be
determined how well existing classifiers are capable
of doing this. In order to retrieve only academic doc-
uments, the documents themselves may be analyzed
for structure or content as well as the sites on which
they are located.
1.3 Metadata
Metadata in this paper means any information further
describing a digital “educational research” document
(referred to as ERD in this paper). This may be any in-
formation such as the title, author, publisher, abstract
or ISSN which are assigned by the time of publish-
ing and additional keywords or quality criteria which
may be automatically or manually attributed to the
document. It may also be the language, file format
or number of pages.
Metadata is useful for searching and browsing
within a set of documents (Witten et al., 2004). Com-
bining full-text search with metadata search greatly
enhances the capabilities of the user to refine queries.
Displaying the metadata in the search results provides
additional valuable information. Sources for gather-
ing metadata may be combined. Metadata may also
be extracted from the full-text documents themselves.
Extensive research has been done on various meth-
ods to achieve this, for example using a support vec-
tor machine based classification method (Han et al.,
2003).
The Web pages themselves also contain metadata
that is not marked as metadata but may be identified
with machine learning methods (e.g. result pages of
search results, table of content pages). Some work
has also been done on supervised and unsupervised
learning approaches in this area (Liu, 2008).
2 IMPLEMENTATION
The EERQI crawler is based on Nutch (Nutch, 2009),
which is an open source web crawler, that is highly
configurable and extensible via plugins. It is scal-
able across CPU clusters by incorporating the Apache
Hadoop (Hadoop, 2009) framework.
The following sections discuss the implementa-
tion of the search engine regarding the significant
goals mentioned in the introduction.
2.1 Combining Techniques for Best-first
Focused Crawling
2.1.1 Crawl Cycle
The Nutch crawler used within this investigation is
substantially optimized. The Nutch software itself
is not implemented for focused crawling but is ex-
tendable in this respect. The crawl is initialized with
a seed list: a set of start URLs. Most of these
start URLs have been selected from lists of electronic
journals in “educational research”. These URLs are
injected into the Nutch crawl database (“crawldb”),
which includes some information about each URL,
such as the current status (e.g. fetched or unfetched)
and time of last fetch.
Each crawl cycle generates a list of top scoring
unfetched URLs or URLs which need to be refetched.
These URLs are then retrieved from the WWW and
the resulting files are parsed. The URLs and corre-
sponding anchor texts are also extracted and inserted
into the link database (“linkdb”). This contains a list
of inlink URLs and anchor texts for each URL. The
parsed text is indexed if the document meets the Ed-
ucational Research Document Detection (ERDD) cri-
teria. A partial index is created for each crawl cy-
cle. Duplicate documents are deleted from the in-
dexes (“dedup”). At last, the indexes from each crawl
cycle are merged into the final index. The modi-
fied status information for each URL is rewritten to
the “crawldb”. The score for each URL is adapted
for EERQI focused crawling (“rescore”). Nutch uses
the OPIC (On-line Page Importance Computation)
(Abiteboul et al., 2003) algorithm to assign scores to
each URL.
2.1.2 Focused Crawling based on Link Analysis
A basic premise in OPIC and PageRank is (Abite-
boul et al., 2003): a page is important, if important
pages are pointing to it and important pages should
be fetched first and more often. Within the EERQI
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
182

crawler, we know which pages are important, aka rel-
evant, as soon as we have fetched and analyzed them.
These are the pages that have been indexed after being
detected as Educational Research Documents (ERD).
We must learn to predict, which pages will be im-
portant before they are fetched, and follow the most
promising paths.
Some samples from the WWW have shown that
the ERDs, most often do not link to other important
ERD, if they link to anything at all. However, the
pages linking to ERDs can be regarded as important
pages, because they often consist of tables of content
pages for an entire journal volume or year. They will
not be indexed but are important in finding links to
other relevant pages. It makes sense to use backpropa-
gation for boosting the relevance score of pages which
link to ERDs. These pages are comparable to the
hubs in Kleinberg’s HITS (Hyperlink-Induced Topic
Search) algorithm (Kleinberg, 1999). The HITS al-
gorithm assumes that a good hub is a document, that
links to many good authorities (authorities are impor-
tant pages, comparable to ERD). Simply using the
above mentioned link importance algorithms (such as
OPIC, HITS or PageRank) is not feasible because we
will not crawl a significant portion of the WWW and
these algorithms do not take into account whether a
document is an ERD.
The web may be displayed as a directed graph.
Intuitively, an ideal crawl path would retrieve a very
high number of ERD and a small number of non-ERD
pages. The ratio of ERD pages to the total num-
ber of fetched pages should be as high as possible.
When considering specific URLs, pages are impor-
tant, if they link to a high number of pages classified
as ERD. Indirect outlinks (outlinks of outlinks) will
be considered up to a certain distance. Effectively,
the high score of an ERD will be backpropagated to
pages linking to it. The resulting score must then be
passed on to the outlinks of these pages, until they
reach a significant amount of unfetched pages.
We calculate the score based on the ratio of ERD
classified outlinks to all outlinks. Ultimately, the to-
tal number of ERD classified outlinks was included
into the equation but experimental results showed that
this did not improve results significantly. Because
the total score of each link level should be smaller
with growing distance from start level, it must be di-
vided by a constant, here named g, which should ful-
fill g > 1 (experimentally a value of g = 2 has proven
to yield best results), exponentiated with the link level
k. So the score will become weaker, the farther it
is propagated. Experiments were used to refine the
equation based on the results.
Equation 1 is an heuristic approach newly devel-
oped within this project to sum up the score calcu-
lations based on backpropagation. It is applicable to
a vertical search engine in other fields of interest as
well. It has proven to yield optimum results as will be
shown later within Figure 1.
h
i
=
l
∑
k=0
c
k
d
k
+ 1
g
k
(1)
h
i
is the score for page i, l is the number of link
levels, c
k
is the number of links of i in link level k that
have been classified as ERD, d
k
is the total number of
links of i in link level k.
2.1.3 Anchor Text Analysis
Up to now, 60,000 anchor texts were analyzed. It
may be assumed that words such as “pdf”, “full”, “ar-
ticle”, and “paper” are good indicators of research
documents but they do not contain any information
about whether the referenced document is about “ed-
ucational research”. The word “abstract” is a good
hint, that the referenced document contains only an
abstract, which is currently not considered as ERD by
the search engine.
SVMLight (SVMLight, 2009) was used to train
the anchor texts. SVMLight is a Support Vector
Machine based classifier. Single-word anchor texts
that are a good indicator of a direct link to research
texts (“pdf”) obtained almost the same result as sin-
gle words that would most likely not point to re-
search documents (“sitemap” and “abstract”). It is as-
sumed that this is due to the large number of non-ERD
documents (for example research from other fields)
that were also linked with potentially promising an-
chor text words. However, the classifier works well
on anchor texts containing typical “educational re-
search” terms, for example “Teacher” received a score
of 4.28, “Learning” a score of 4.84.
When training the classifier, not only the anchor
texts with direct links to ERD were used, but also an-
chor texts of indirect links up to a level of three.
An SVMLight score above 0 may be interpreted
as a positive hit. The higher the score, the higher the
probability of being in the trained class. The max-
imum score obtained in a list of 30000 samples was
4.89 while the minimum was −4.99. While using this
score may optimize the focused crawler, it may also
bias the search engine towards documents with “typi-
cal” mainstream titles.
A NEW APPROACH TOWARDS VERTICAL SEARCH ENGINES - Intelligent Focused Crawling and Multilingual
Semantic Techniques
183

2.2 Educational Research Document
Detection
Before analyzing how an ERD may be detected, we
must first define the term ERD more precisely: An
ERD is a digital scientific research document which
may be classified within the topic “educational re-
search”. It may be for example a journal article, a
conference paper, a thesis or a book. An ERD may
consist of one or more ERDs as in conference pro-
ceedings or entire journals. Abstracts are a part of an
ERD but are not considered as a fully qualified ERD.
Educational Research Document Detection may
be regarded as a combination of identifying scien-
tific research documents and topical (“educational re-
search”) classification.
A large number of publications have analyzed
the use of Vector Space Model based algorithms
for document classification. Sebastiani (Sebastiani,
2002) provided an overview. These methods may be
used for matching new documents with existing cate-
gories, such as specific topics (e.g. physics, biology),
spam / no-spam etc. The document is represented as
a vector. Each dimension of the vector represents a
term, the value is a representation of the frequency
that the term exists in the document (e.g. tf-idf may
be used). When classifying a document, the term vec-
tor of the document is matched with the term vectors
of the classes. ERDD may be regarded as a binary
classification problem, because there is only one class
(ERD), or a ranking problem where the documents are
sorted by their ERD ranking score.
For supervised learning text classification, a col-
lection of documents is required, which may be used
as a training base. This collection should cover all ar-
eas of “educational research”. A negative collection
should be provided as well, which covers documents
that should not be considered as ERD, such as re-
search documents from other fields and non-research
documents.
The detection mechanism is implemented using
the following criteria:
1. A rule based content analysis is used in order to
ensure a high probability that the document is a re-
search document. The document must have a min-
imum text length, it must contain defined terms
(such as references, abstract) and it must contain
references which may be existing in various for-
mats.
2. A number of significant “educational research”
keywords must exist in the document. Further
work needs to be done to replace or augment this
with a vector space model based classifier.
2.3 Metadata
A common Dublin Core based XML format was de-
fined for metadata. The local content base consists
of a number of full-text documents and metadata, that
have been supplied by various publishers. The full-
text content and available metadata was indexed using
Lucene (Lucene, 2009).
The Nutch (Nutch, 2009) crawler also uses a
Lucene (Lucene, 2009) index. The EERQI index-
ing plugin was modified to write the full-text content,
file format (Internet media type), number of pages (in
case of PDF), and the language (as detected by the
Nutch LanguageIdentifier) to the index. A list of in-
formation about journals was generated by combining
the lists of educational research journals from various
journals lists with information supplied by EERQI
partners. Metadata information in the index was ex-
panded with journal information such as peer-review
status, publisher, and ISSN. This may later be en-
hanced with information about the title, authors, and
date of publication.
2.4 Multilingualism
Multilingualism is of special importance for Euro-
pean search engines due to Europe’s diversity of lan-
guages. The documents and metadata indexed by
our search engine are in fact supplied in several lan-
guages. Furthermore the documents themselves may
contain more than one language: often the abstract
is in English and the rest of the document is in the
native language of the authors. In order to provide
full multilingualism, it is necessary to use language
independent algorithms wherever possible and supply
translations for the supported languages.
Our focused crawling scheme based on link analy-
sis is language independent. The ERDD must supply
mechanisms for all supported languages.
When submitting a query from the web user in-
terface, the search engine may return results match-
ing the query and related terms in all supported lan-
guages. This will be implemented in the very near
future of the project using a multilingual thesaurus.
To the best of our knowledge this will soon be the
first and only search engine implementing this kind
of extended multilingualism.
3 RESULTS
At this stage, a prototype search engine has been de-
signed and tested. The primary targets as described in
this case study have been implemented.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
184
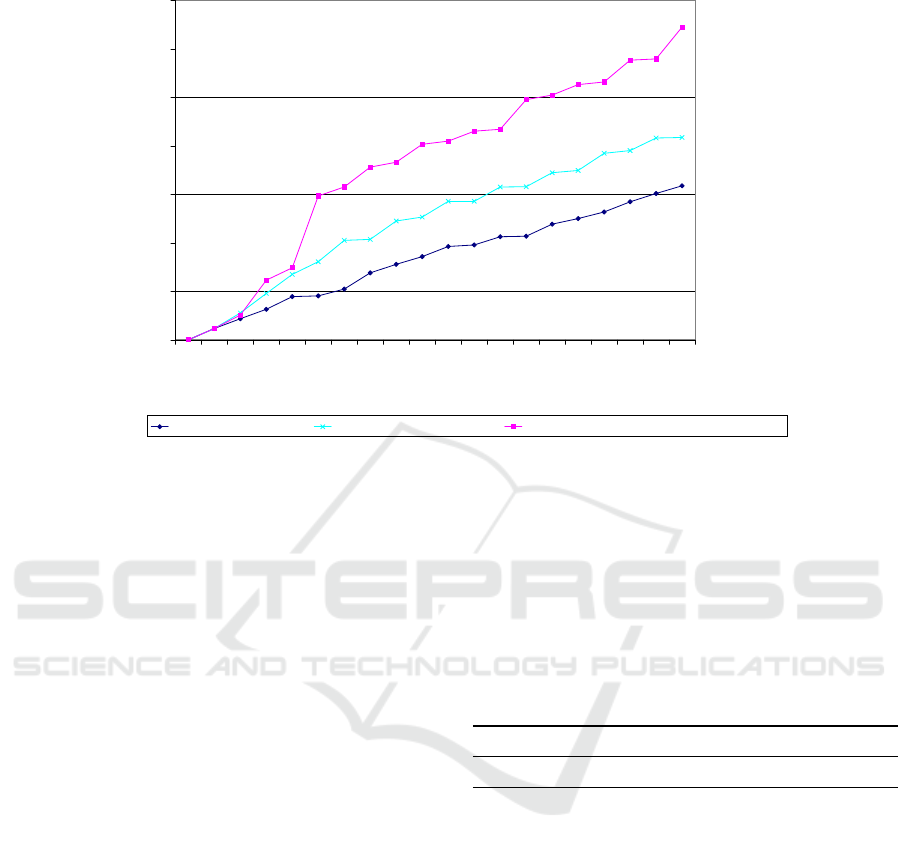
0
200
400
600
800
1000
1200
1400
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
crawl cycle
number of ERD found
without optimization anchor text optimization link analysis optimization (equation 1)
Figure 1: Crawl results with and without optimizations.
In order to test the search engine, a number of 100
URLs were randomly selected from the seed list to
test the crawler. A mutually exclusive list of 100 fur-
ther URLs was used to train the anchor text classifier.
When crawling, 1000 URLs were generated for each
crawl cycle. The crawling alternates between select-
ing the 1000 best-scoring URLs and selecting the 10
top-scoring URLs for each of the sites from the seed
list. This was done to prevent an excessive downgrad-
ing of individual sites.
The total number of ERDs found for each crawl
cycle is shown in Figure 1. Crawling was done with a
total depth of 100 crawl cycles. The three lines show
the execution of the runs:
1. without optimization,
2. with anchor text optimization: A preliminary train
crawl of depth 50 was done with the aforemen-
tioned train URLs. When optimizing during the
test crawl, anchor texts were rated by SVMLight
based on the previous training set,
3. with link analysis optimization by equation 1:
Pages linking to ERD were boosted in score up
to a level of three outlink levels and one inlink
level. Equation 1 so has proven to be of significant
value for intelligent focused crawling and might
therefore be used for any vertical search engine
crawler.
Using various sources, such as input from EERQI
partners, and the ERIC database (ERIC, 2009), a list
of URLs was compiled for measuring ERDD. This
list included “educational research” documents, re-
search documents from other areas of research, non-
research, and other documents (such as bibliogra-
phies, book reviews etc.). Applying the ERDD mech-
anism to these documents produced the following re-
sults (Table 1):
Table 1: Precision, recall, and accuracy ratios in ERDD re-
sults.
Precision Recall Accuracy
0.73 0.89 0.86
For the four project languages (English, French,
German, and Swedish) a sufficient number of docu-
ments has been gathered from the WWW which is
further to be used for testing quality indicators detec-
tion within the EERQI project. Results of this detec-
tion may be used to enrich document metadata within
the search engine.
4 SUMMARY AND
CONCLUSIONS
It has been shown that an advanced vertical search
engine collecting full-text and metadata from inho-
mogeneously structured information sources can be
successfully implemented by integrating an intelli-
gent focused crawler. Content classification (ERDD)
A NEW APPROACH TOWARDS VERTICAL SEARCH ENGINES - Intelligent Focused Crawling and Multilingual
Semantic Techniques
185

and metadata extraction have been shown as valuable
methods for enhancing search results. Link analysis
optimization achieved considerably better results than
anchor text optimization or no optimization. Using
link analysis, the number of necessary crawl cycles
are reduced by at least 50 %, leading to faster results
and less use of resources. The EERQI search engine,
accessible on the EERQI project website (EERQI,
2009), provides extensive search capabilities within
metadata and full-texts. It is the goal of the search
engine to gather information about a large number of
relevant “educational research” documents and pro-
vide access to information about these documents.
The first steps have been taken to achieve this goal.
A new formula (equation 1) has been developed for
focused crawling.
5 FUTURE WORK
Based on the current implementation, the next stage
of the EERQI search engine development will con-
centrate on optimized content classification (ERDD)
and metadata extraction. Further effort needs to be
put into metadata extraction from anchor texts and
full text. Preliminary tests revealed that a significant
number of anchor texts include title, author, and / or
journal names. This may be combined with metadata
extraction from full-texts. The search engine user in-
terface will be enhanced to facilitate ergonomic us-
ability for a number of features, such as clustering and
sorting of results as well as complex search queries.
ACKNOWLEDGEMENTS
We kindly thank the partners within the EERQI
project and the colleagues at RRZN for their valuable
input and support. EERQI is funded by the European
Commission under the 7th Framework Programme,
grant 217549.
REFERENCES
Abiteboul, S., Preda, M., and Cobena, G. (2003). Adaptive
On-Line Page Importance Computation. In Proceed-
ings of the 12th international conference on World
Wide Web, pages 280–290. ACM.
Bergmark, D., Lazoze, C., and Sbityakov, A. (2002). Fo-
cused Crawls, Tunneling, and Digital Libraries. In
Proceedings of the 6th European Conference on Digi-
tal Libraries.
Chakrabarti, S., Dom, B., Raghavan, P., Rajagopalan, S.,
Gibson, D., and Kleinberg, J. (1998). Automatic Re-
source Compilation by Analyzing Hyperlink Structure
and Associated Text. In Proceedings of the Seventh
International World Wide Web Conference.
EERQI (2009). EERQI project website.
http://www.eerqi.eu.
EERQI-Annex1 (2008). EERQI Annex I - Description of
Work. http://www.eerqi.eu/sites/default/files/11-06-
2008 EERQI Annex I-1.PDF (PDF).
ERIC (2009). Education Resources Information Center
(ERIC). http://www.eric.ed.gov.
Google Scholar (2009). Google Scholar.
http://scholar.google.com.
Hadoop (2009). Apache Hadoop.
http://hadoop.apache.org/.
Han, H., Giles, C. L., Manavoglu, E., Zha, H., Zhang, Z.,
and Fox, E. (2003). Automatic Document Metadata
Extraction using Support Vector Machines. In Pro-
ceedings of the 2003 Joint Conference on Digital Li-
braries (JCDL 2003).
Kleinberg, J. (1999). Authoritative Sources in a Hyper-
linked Environment. Journal of the ACM, pages 604–
632.
Liu, B. (2008). Web Data Mining. Springer.
Lucene (2009). Apache Lucene. http://lucene.apache.org/.
Manning, C. D., Raghavan, P., and Sch
¨
utze, H. (2008). In-
troduction to Information Retrieval. Cambridge Uni-
versity Press.
Nutch (2009). Apache Nutch. http://lucene.apache.org/
nutch/.
OAIster (2009). OAIster. http://oaister.org.
Pant, G., Tsioutsiouliklis, J. J., and Giles, C. L. (2004).
Panorama: Extending Digital Libraries with Topi-
cal Crawlers. In Proceedings of the 2004 Joint
ACM/IEEE Conference on Digital Libraries.
Scirus (2009). Scirus. http://www.scirus.com.
Sebastiani, F. (2002). Machine Learning in Automated Text
Categorization. ACM Computing Surveys, 34:1–47.
SVMLight (2009). SVMlight.
http://svmlight.joachims.org/.
Witten, I., Don, K. J., Dewsnip, M., and Tablan, V. (2004).
Text mining in a digital library. International Journal
on Digital Libraries.
Zheng, X., Zhou, T., Yu, Z., and Chen, D. (2008). URL Rule
Based Focused Crawler. In Proceedings of 2008 IEEE
International Conference on e-Business Engineering.
Zhuang, Z., Wagle, R., and Giles, C. L. (2005). What’s there
and what’s not? Focused crawling for missing docu-
ments in digital libraries. In Proceedings of the 5th
ACM/IEEE-CS Joint Conference on Digital Libraries.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
186
