
PARSING BY SIMPLE INSERTION SYSTEMS
Gemma Bel-Enguix
1
, P´al D¨om¨osi
2
and Alexander Krassovitsky
1
1
GRLMC, Rovira i Virgili University, Avda. Catalunya 35, 43002 Tarragona, Spain
2
College of Ny´ıregyh´aza, Institute of Mathematics and Informatics
H-4400 Ny´ıregyh´aza, S´ost´oi ´ut 31/B, Hungary
Keywords:
Insertion systems, Parsing, Natural language, Multi-agent systems.
Abstract:
The aim of this paper is to initiate a new direction for the investigation of multi-agent systems. We will
consider the insertion systems as very simple multi-agent systems, where the agents are consisting of their
insertions. We define the systems and describe their working and main features. The central develoment of
the paper is the application of such systems to parsing. Some examples to natural language processing are
introduced that can illustrate the system.
1 INTRODUCTION
Although interaction between the fields of formal lan-
guages and multi-agents systems is not frequent, there
are some examples that illustrate the high theoretical
and applied potential of such collaboration.
Grammar Systems (Csuhaj-Varj´u et al., 1994) are
widely considered as a particular case of multi-agent
system focusing in the special task of generating – and
accepting (Fernau et al., 1996)– languages.
Another interesting interdisciplinar approach was
given by Networks of Evolutionary Processors
(NEPs), introduced in (Castellanos et al., 2003), a
type multi-agent systems in the area of formal lan-
guages and bio molecular computing. An overview
on the generative power and complexity results of
NEPs has can be found in (Mart´ın-Vide and Mitrana,
2005).
It is not easy to find in the literature practical ap-
plications of Grammar Systems or NEPs. In what
refers to Networks of Evolutionary Processors, some
ideas have been launched for parsing of natural lan-
guages (Bel-Enguix et al., 2009; Ortega et al., 2009)
starting from the idea of accepting NEPs, introduced
in (Margenstern et al., 2004) and developed in several
papers (Manea and Mitrana, 2009).
In this work, we will describe a polynomial parser
working on insertion (derivation) systems which can
be considered as very simple multi-agent systems.
Following with the tradition of NEPs, we want to use
a method that can make some contribution to both
multi-agent systems and formal languages. We are
also preliminary applying the mechanism to parsing
of natural languages.
2 INSERTION SYSTEMS
Insertion systems have been introduced and studied in
(Galiukschov, 1981). Characterization of recursively
enumerable languages by insertion systems is given
in (P˘aun et al., 1998; Kari and Sos´ık, 2009; Madhu
et al., 2009).
An insertion system (which is also called insertion
grammar in the literature) is a construct G = (V,A,P),
where V is the (finite) alphabet, A ⊂ V
∗
is the (fi-
nite) set of axioms, and P ⊂ {(u, α,v) | u,α,v ∈ V
∗
is the (finite) set of insertion rules. An insertion rule
(u,α,v) ∈ I indicates that the string α can be inserted
in between u and v. The rule (u,α,v) ∈ I corre-
sponds to the rewriting rule uv =⇒ uαv. We denote
by =⇒ the relation defined by an insertion rule (for-
mally, x =⇒ y iff x = x
1
uvx
2
,y = x
1
uαvx
2
, for some
(u,α,v) ∈ I and x
1
,x
2
∈ V
∗
). We denote by =⇒
∗
the
reflexive and transitive closure of =⇒ (as usual, =⇒
+
is its transitive closure). The language generated by G
is defined by
L(G ) = {w ∈ V
∗
| x =⇒
∗
w,x ∈ A}.
We say that an insertion system has weight
383
Bel-Enguix G., Dömösi P. and Krassovitskiy A. (2010).
PARSING BY SIMPLE INSERTION SYSTEMS.
In Proceedings of the 2nd International Conference on Agents and Artificial Intelligence, pages 383-387
DOI: 10.5220/0002784803830387
Copyright
c
SciTePress

(l,m, m
′
) if
l =max{|α| | (u,α,v) ∈ P};
m =max{|u| | (u,α,v) ∈ P};
m
′
=max{|v| | (u, α,v) ∈ P}.
For example, consider an insertion system of the
weight (2,0,0) Π = ({a,b},{ε},{(ε,ab, ε)}). Then,
it is clear that Π generates the Dyck language.
We denote by INS
m,m
′
l
the family of languages
generated by insertion systems of weight (l,m,m
′
).
In the sequels we will restrict ourselves to inser-
tion systems of weight (l,1,1), i.e., we assume that
all insertions have the form (a,a
1
··· a
k
,b), where
a,a
1
,... ,a
k
,b ∈ V, and k ≤ l. It is well-known that the
family of languages INS
1,1
l
,l ≥ 1 is a proper subfam-
ily of context-free languages (P˘aun, 1997), for which
there are well-known parsers working in polynomial
time. Therefore, we expect to find parsers of poly-
nomial power for insertion systems of weight (l,1,1)
too.
3 PARSING FOR SIMPLE
INSERTION SYSTEMS
For the sake of simplicity, first we assume that A is a
singleton having a string of length two. We call this
type of insertion systems simple.
For simple insertion systems, we can show an ef-
fective parsing technique based on the idea of CYK
algorithm (Cocke and Schwartz, 1970; Kasami, 1965;
Younger, 1967). The input to the algorithm is a
simple insertion system G = (V,A,P) and a string
w = a
1
··· a
n
∈ V
∗
. In O(n
3
) time, the algorithm con-
structs a table that checks whether w is in L(G ). Note
that when computing the running time of the check-
ing, the system itself is considered fixed, and its size
contributes only a constant factor to the running time,
which is measured in terms of the length of the string
w whose membership in L(G ) is being tested. In this
algorithm, we construct a triangular table, called pars-
ing table, as shown in Table 1.
The parsing table consists of n− 1 rows and n− 1
columns, where n denotes the length of the parsed
word. To fill the table, we work row-by-row up-
wards. Each row corresponds to substrings of the
given length; the bottom row is for strings of length 2,
the second row for strings of length 3, etc., until the
top row corresponds to the only substring of length
n, which is the parsed word. By the proposed algo-
rithm it takes O(n) time to compute each entry of the
table. Since there are n(n − 1)/2 entries, the whole
table construction takes O(n
3
) time.
Table 1: Parsing Table.
X
15
X
14
X
25
X
13
X
24
X
35
X
12
X
23
X
34
X
45
a
1
a
2
a
3
a
4
a
5
The Algorithm
1. If a
1
a
m
is not the (only) axiom (i.e. {a
1
a
m
} 6= A)
then a
1
···a
m
/∈ L(G ) and we are ready.
2. Otherwise, we consider the following treatment.
(a) for every j = 1, ..., m−1, we put ( j, j + 1) into
X
j, j+1
.
(b) for every i = 2,...,m − 1 and j = 1,..., m − i,
we put ( j,i+ k) into X
j,i+k
if we did not do
it so far in the previous steps, and there ex-
ists an insertion (a
j
,a
j
1
a
j
2
···a
j
s
,a
i+k
) (1 ≤
j < j
1
< j
2
< ··· < j
s
< i + k ≤ m) such that
( j, j
1
) ∈ X
j, j
1
,( j
1
, j
2
) ∈ X
j
1
, j
2
,... ,( j
s−1
, j
s
) ∈
X
j
s−1
, j
s
,( j
s
,i+ k) ∈ X
j
s
,i+k
1
(c) Finally, if (a
1
,a
m
) ∈ X
1,m
then a
1
···a
m
∈ L(G ),
otherwise not.
Prove that the algorithm works in polynomial
(O(n
3
)) time. Moreover, for every string a
1
··· a
m
∈
V
∗
, we have a
1
···a
m
∈ L(G ) if and only if (a
1
,a
m
) ∈
X
1,m
.
Theorem 1. Let Π be a simple insertion systems and
let n be the length of the parsed word. There exists a
parser working on Π in polynomial (O(n
3
)) time.
Proof:
The reason the algorithm puts the correct pairs of
characters is the following. In the bottom row, which
has the length n − 1, for every position we put a pair
consisting of the line number of the position and the
consecutive one. Thus, the first pair is (1,2) and the
last pair is (n− 1,n).
Then, for every i = 2,...,m− 1 and j = 1, ..., m−i,
we can put (s,t) into the j-th position of the i-th row
if and only if two conditions are holding: a.) s = j; b.)
there exist an insertion (a
j
,a
j
1
a
j
2
···a
j
s
,a
i+1
) and po-
sitions X
j, j
1
−1
,X
j
1
, j
2
−1
,... ,X
j
s−1
, j
s
−1
,X
j
s
, j
i+k
which
1
Note that, by our assumptions, | a
j
1
a
j
2
···a
j
s
| ≤ ℓ.
Therefore, the number of elementary operations in step 2
is not more that (m− 2)(m− i)ℓ.
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
384

contain pairs of line numbers of the parsed string such
that their column index is the same as the first mem-
ber of the contained pair, and their first indexesform a
sequence j
1
−1, j
2
−1,. .., j
s
−1, where j
1
,..., j
s
are
the indexes of letters in the parsed strings for which
a
j
1
a
j
2
··· a
j
s
is the middle part of the insertion rule
(a
j
,a
j
1
a
j
2
··· a
j
s
,a
i+k
).
For the running time, note that there are O(n
2
) to
compute, and each involves comparing and comput-
ing with not more than nℓ pairs of entries, where ℓ
denotes the maximum of the length of the middle part
in the insertion rules. We mention that the considered
simple insertion system is fixed, and the number of its
letters, its insertions do not depend on n, the length
of the parsed string w. Thus, the time to compare at
most ℓ positions is O(1). As there are at most nℓ such
pairs for each position of the parsing table, the total
working time is O(n). Therefore, the running time of
the parser is O(n
3
).
4 PARSING FOR INSERTION
SYSTEMS OF WEIGHT (l,1,1)
On the basis of our previous algorithm, we give a
parser for general insertion systems of weight (l,1,1)
working also in polynomial time. Thus, the input to
the algorithm is an insertion system G = (V,A,P) of
weight (l, 1,1) and a string w = a
1
··· a
n
∈ V
∗
.
Let us denote by ℓ the maximal length of axioms,
and for every 1 ≤ i < i + k ≤ n, denote by G
i,i+k
the simple insertion system G
i,i+k
= (V,{a
i
a
i+k
},P).
The algorithm works as follows. First we built a di-
graph with set of vertices {1,...,n} such that the pair
(i, j),1 ≤ i < j ≤ n is an edge if there is a path from
the vertex 1 to the vertex i having its length not more
then ℓ − 1. Listing and checking the paths in this di-
graph, leading from 1 to n, we terminate the algorithm
if one of the following conditions holds:
1. we found a path 1, i
1
,... ,i
j
,n with a
1
a
i
1
···a
i
j
a
n
∈
L(G ), or
2. for every path 1,i
1
,... ,i
j
,n such that it leads
from the vertex 1 to the vertex i, we have
a
1
a
i
1
··· a
i
j
a
n
/∈ L(G ).
We establish a
1
a
i
1
···a
i
j
a
n
∗
⇒
G
a
1
··· a
n
(i.e., we
establish a
1
··· a
n
∈ L(G ) such that, we use con-
secutively our parser for simple insertion sys-
tems in order to show that a
1
a
i
1
∗
⇒
G
a
1
···a
i
1
,a
i
1
a
i
2
∗
⇒
G
a
i
1
···a
i
2
, ..., a
i
j
−1
a
i
j
∗
⇒
G
a
i
j
−1
··· a
i
j
,a
i
j
a
n
∗
⇒
G
a
i
j
··· a
n
.
The Algorithm
1. The algorithm constructs a digraph D with set of
vertices {1,... , n} in the following way.
(a) let us label the edge 1 by 0.
(b) For every i = 2, ... ,n, Let (1, i) be a (directed)
edge of D if (a
1
,... ,a
i
) ∈ L(G
1,i
),
2
, and in this
case, let us label the edge i by 1.
(c) For every j = 3, . ..,ℓ, i = j, ... ,n let (s,i) be
an edge of D if s is labeled by j − 1 and
(a
s
,a
s+1
,..., a
i
) ∈ L(G
s,i
), and in this case, let
us label the edge i by j.
2. If the vertex n has no incoming edge, then w /∈
L(G ), and we are ready.
3. Otherwise let us continue our treatment as fol-
lows.
(a) Omit the vertices having no labels.
(b) One after the other consider the paths
1,i
1
,... ,i
j
,n (which have less than ℓ length,
leading from the edge 1 to the edge n
in the reduced digraph), and check whether
a
1
a
i
1
··· a
i
j
a
n
is an axiom or not. If yes then
w ∈ L(G ), and we are ready.
(c) Running out of the paths such that nothing
leads to an axiom, we can conclude w /∈ L(G ),
and we are ready again.
The system can have several interesting applica-
tions, like the use for parsing of natural language. Let
us consider an example, with the following insertion
rules:
(0) (¢,<boy> <eats> <cake>,$)
(1) (<a>,<very>,<very>)
(2) (<a>,<very>,<nice>)
(3) (<a>,<nice><young>,<boy>)
(4) (<a>,<nice><apple>,<cake>)
(5) (<¢>,<a>,<boy>)
(6) (<eats>,<a>,<cake>)
By this simple insertion system sentences like [1]
can be parsed.
[1] ¢ a very very nice young boy eats a very nice apple
cake $
The procedure is shown in Table 2.
Theorem 2. There exists a parser working on inser-
tion systems of weigh (l, 1,1) in polynomial (O(n
5
))
time.
2
We can decide by the previously discussed parser
whether it is true or not.
PARSING BY SIMPLE INSERTION SYSTEMS
385
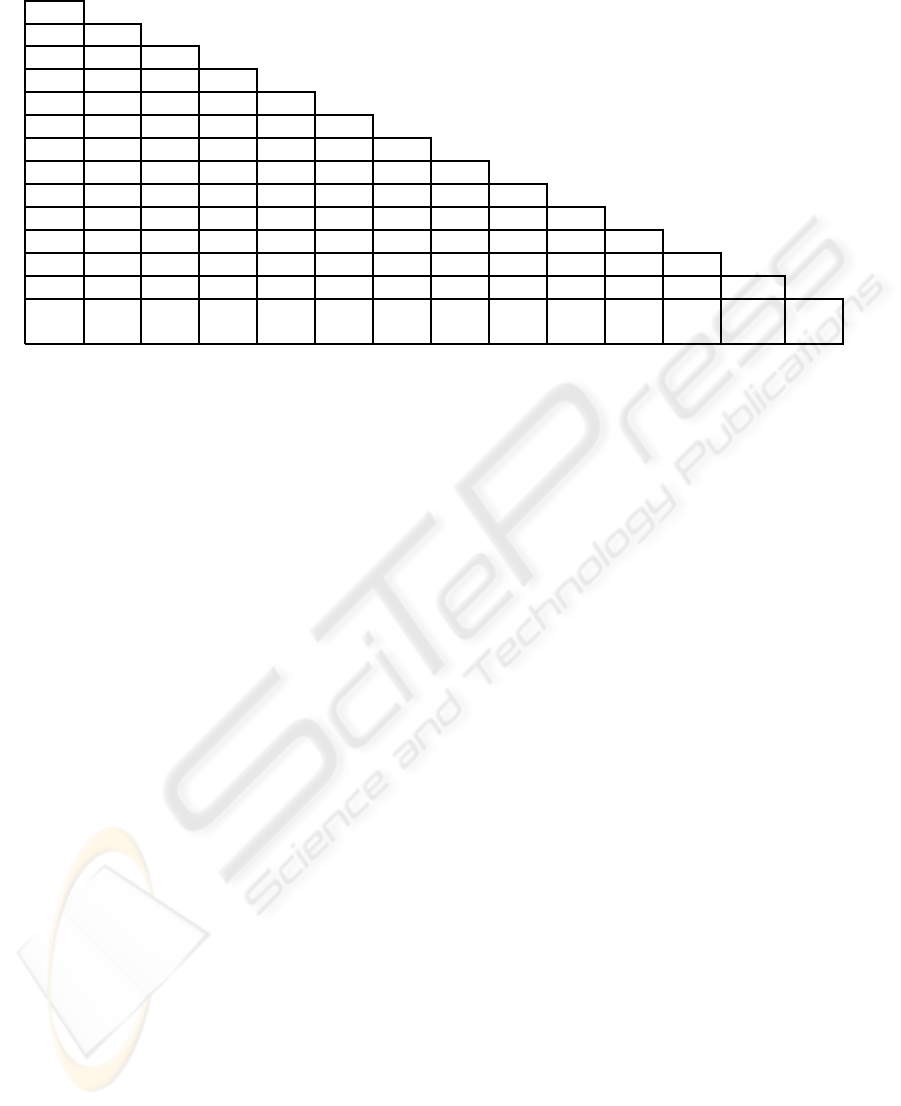
Table 2: An example of parsing by simple insertion system.
(1,14)
(1,7)
(2,7) (8,13)
(9,13)
(2,5)
(2,4) (9,11)
(1,2) (2,3) (3,4) (4,5) (5,6) (6,7) (7,8) (8,9) (9,10) (10,11) (11,12) (12,13) (13,14)
¢ a very very nice young boy eats a very nice apple cake $
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Proof: The correctness of the algorithm has been
already explained. We built the digraph D in
∑
ℓ
i=1
n − ℓ = n(n − 1)/2 − (n − ℓ)(n − ℓ − 1)/2 ele-
mentary steps. Thus the number of elementary steps
is O(n
2
). On the other hand, each of the elementary
steps takes O(n
3
) running time. Thus the running
time of the parser to built D is O(n
5
). The time to
omit the non-labeled vertices is O(n). Because the de-
rived digraph is loop- and circle-free having not more
than ℓ edges, the total number of the path in this di-
graph starting by 1 and finishing by n, is 2
ℓ−1
. Re-
call that the considered insertion system with weight
(l,1,1) is also fixed and the number of its letters, its
insertions, its axioms, and thus the maximum ℓ of the
length of the axioms does not depend on n, the length
of the parsed string. Therefore, the running time of
the enumeration of the considered paths and checking
whether the strings characterized by these paths are
axioms or not, is O(1). Therefore, the running time of
the parser in total is O(n
5
).
5 CONCLUSIONS
It is well-known that the family of languages, gener-
ated by insertion systems of weight (l,1,1),l ≥ 1, is
a proper subfamily of context-free languages (P˘aun,
1997), for which there are well-known parsers work-
ing in polynomial time. Therefore, it can be pre-
dicted that there are parsers of polynomial time com-
plexity for languages generated by insertion systems
of weight (l, 1,1) too. In this paper, we have intro-
duced the concept of simple insertion systems and
showed a parser running on the generated languages
in time O(n
3
). On the basis of this result, we showed
another parser for the languages generated by inser-
tion systems working in O(n
5
) time. To find parsers
of polynomial time complexity for languages gener-
ated by general insertion systems or, even by inser-
tion systems of weight (l,2,1) is not expected. It
is shown in (P˘aun, 1997) that insertion systems of
the weight (2, 2,2) can generate non-semililear lan-
guages. Hence, it is unlikely there is a polynomial
time parser for these type of systems. For the future,
it could be interesting to refine the presented parsers
having lower time complexity (at least) for some fam-
ily of languages generated by special insertion sys-
tems. Also, it is interesting to consider the parsing
of insertion systems if an additional encoding of the
output words (e.g. by the finite state transducer) is
used. Some examples for application in natural lan-
guage processing are also shown. It could be worth-
while to check the capacity of these systems and their
future developments for parsing different syntactical
structures.
ACKNOWLEDGEMENTS
This work has been supported by the project
MTM2007-64322 from the Ministerio de Ciencia y
Tecnolog´ıa, and by the Active Researchers Program
from the URV, Department of Romance Phylologies.
REFERENCES
Bel-Enguix, G., Jim´enez-L´opez, M. D., Mercas, R., and
Perekrestenko, A. (2009). Networks of evolutionary
processors as natural language parsers. In Filipe, J.,
Fred, A., and Sharp, B., editors, Proceedings of the
1st International Conference on Agents and Artificial
Intelligence, pages 619–625. INSTICC Press.
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
386

Castellanos, J., Mart´ın-Vide, C., Mitrana, V., and Sempere,
J. M. (2003). Networks of evolutionary processors.
Acta Informatica, 39:1–13.
Cocke, J. and Schwartz, T. (1970). Programming languages
and their compilers: Preliminary notes. Technical re-
port, Courant Institute of Mathematical Sciences, New
York.
Csuhaj-Varj´u, E., Dassow, J., Kelemen, J., and P˘aun, G.
(1994). Grammar Systems. A Grammatical Approach
to Distribution and Cooperation. Gordon and Breach,
London.
Fernau, H., Holzer, M., and Bordihn, H. (1996). Accept-
ing multi-agent systems: The case of cooperating dis-
tributed grammar systems. Computers and artificial
intelligence, 15(2–3):105–264, 123–139.
Galiukschov, B. (1981). Semicontextual grammars (in rus-
sian). Mat. Logica i Mat. Ling., pages 35–80.
Kari, L. and Sos´ık, P. (2009). On the weight of universal
insertion systems. Manuscript.
Kasami, T. (1965). An efficient recognition and syntax-
analysis algorithm for context-free languages. Tech-
nical Report AFCRL-65-758, Air Force, Cambridge
Research Lab, Bedford, MA.
Madhu, M., Krithivasan, K., and Reddy, A. (2009). On
characterizing recursively enumerable languages by
insertion grammars. Technical report, III T, Hyber-
abad.
Manea, F. and Mitrana, V. (2009). Accepting networks
of evolutionary processors. complexity aspects. In
Proceedings of the 1st International Conference on
Agents and Artificial Intelligence, pages 597–604. IN-
STICC Press.
Marcus, S. (1969). Contextual grammars. Rev. Roum. Math.
Pures Appl., 14:1525–1534.
Margenstern, M., Mitrana, V., and P´erez-Jim´enez, M.
(2004). Accepting hybrid networks of evolutionary
processors. In Pre-proceedings of DNA 10, pages
107–117.
Mart´ın-Vide, C. and Mitrana, V. (2005). Networks of evo-
lutionary processors: results and perspectives, vol-
ume Molecular Computational Models: Unconven-
tional Approaches, pages 78–114. Idea Group Pub-
lishing, Hershey.
Ortega, A., del Rosal, E., P´erez, D., Mercas, R.,
Perekrestenko, A., and Alfonseca, M. (2009). Pneps,
neps for context free parsing: Application to natural
language processing. LNCS, 5517:472–479.
P˘aun, G., Rozenberg, G., and Salomaa, A. (1998). DNA
Computing. New Computing Paradigms. Springer-
Verlag, Berlin.
P˘aun, G. (1997). Marcus Contextual Grammars. Kluwer,
Dordrecht.
Younger, D. (1967). Recognition and parsing of context-
free languages in time n
3
. Information and Control,
10(2):189–208.
PARSING BY SIMPLE INSERTION SYSTEMS
387
