
AN INFANT FACIAL EXPRESSION RECOGNITION SYSTEM
BASED ON MOMENT FEATURE EXTRACTION
C. Y. Fang, H. W. Lin and S. W. Chen
Department of Computer Science and Information Engineering, National Taiwan Normal University, Taipei, Taiwan
Keywords: Facial Expression Recognition, Decision Tree, Moment, Correlation Coefficient.
Abstract: This paper presents a vision-based infant surveillance system utilizing infant facial expression recognition
software. In this study, the video camera is set above the crib to capture the infant expression sequences,
which are then sent to the surveillance system. The infant face region is segmented based on the skin colour
information. Three types of moments, namely Hu, R, and Zernike are then calculated based on the
information available from the infant face regions. Since each type of moment in turn contains several
different moments, given a single fifteen-frame sequence, the correlation coefficients between two moments
of the same type can form the attribute vector of facial expressions. Fifteen infant facial expression classes
have been defined in this study. Three decision trees corresponding to each type of moment have been
constructed in order to classify these facial expressions. The experimental results show that the proposed
method is robust and efficient. The properties of the different types of moments have also been analyzed
and discussed.
1 INTRODUCTION
Infants are too weak to protect themselves and lack
disposing capacity, and therefore are more likely to
sustain unintentional injuries especially when
compared to children of other age groups. These
incidents are very dangerous and can potentially lead
to disabilities and in some cases even death. In
Taiwan’s Taipei city, the top three causes of infant
death are (1) newborns affected by maternal
complications during pregnancy, (2) congenital
anomalies, and (3) unintentional injuries, which in
total account for 83% of all infant mortalities (Doi,
2006). Unintentional injuries are a major cause of
infant deaths each year, a majority of which can be
easily avoided. Some of the most common causes
include dangerous objects surround the infant and
unhealthy sleeping environments. Therefore, the
promotion of safer homes and better sleeping
environments is critical to reducing infant mortality
caused by unintentional injuries.
Vision-based surveillance systems, which take
advantage of camera technology to improve safety,
have been used for infant care (Doi, 2006). The main
goal behind the development of vision-based infant
care systems is to monitor the infant when they are
alone in the crib and to subsequently send warning
messages to the baby-sitters when required, in order
to prevent the occurrence of unintentional injuries.
The Department of Health in Taipei city has
reported that the two most common causes of
unintentional injuries are suffocation and choking
(Department of Health, Taipei City Government,
2007). Moreover, in Alaska and the United States,
the biggest cause of death among infants due to
unintentional injuries is suffocation, which accounts
for nearly 65% of all mortalities due to unintentional
injuries (The State of Alaska, 2005). The recognition
of infant facial expressions such as those when the
infant is crying or vomiting may play an important
role in the timely detection of infant suffocation.
Thus, this paper seeks to address the above problems
by presenting a vision-based infant facial expression
recognition system for infant safety surveillance.
Many facial expression recognition methods
have been proposed recently. However, most of
them focus on recognizing facial expressions of
adults. Compared to an adult, the exact pose and
position of the infant head is difficult to accurately
locate or estimate and therefore, very few infant
facial expression recognition methods have been
proposed to date. Pal et al. (Pal, 2006) used the
position of the eyebrows, eyes, and mouth to
estimate the individual motions in order to classify
infant facial expressions. The various classes of
313
Y. Fang C., W. Lin H. and W. Chen S. (2010).
AN INFANT FACIAL EXPRESSION RECOGNITION SYSTEM BASED ON MOMENT FEATURE EXTRACTION.
In Proceedings of the International Conference on Computer Vision Theory and Applications, pages 313-318
DOI: 10.5220/0002814403130318
Copyright
c
SciTePress

(a) (b)
Figure 1: A video camera set above the crib.
facial expressions include anger, pain, sadness,
hunger, and fear. The features they used are the local
ones. However, we believe that global moments (Zhi,
2008) are more suitable for use in infant facial
expression recognition systems.
Figure 2: Flowchart of the proposed system.
2 SYSTEM FLOWCHART
The data input to the system consists of video
sequences, which have been acquired by a video
camera set above the crib as shown in Figure 1(a).
An example image taken by the video camera is
shown in Figure 1 (b).
Figure 2 shows the flowchart of the infant facial
expression recognition system. The system first
pre-processes the input image to remove any noise
and to reduce the effects of lights and shadows. The
infant face region is then segmented based on the
skin colour information and then the moment
features are extracted from the face region. This
study extracts three types of moments as features,
including seven Hu moments, ten R moments, and
eight Zernike moments.
For each fifteen-frame sequence, the correlation
coefficients between two moments (features) of the
same type are calculated as the attribute of infant
facial expressions. These coefficients aid in the
proper classification of the facial expressions. Three
decision trees, which correspond to each different
type of moment, are used to classify the infant facial
expressions.
Five infant facial expressions, including crying,
gazing, laughing, yawning and vomiting have been
classified in this study. Different positions of the
infant head namely front, turn left and turn right
have also been considered. Thus, a total of fifteen
classes have been identified.
3 INFANT FACE DETECTION
Three color components from different color models
have been used to detect infant skin colour. They are
the S component from the HSI model, the Cb
component from the YCrCb model and a modified U
component from the LUX model. Given a pixel
whose colour is represented by (r, g, b) in the RGB
color model, its corresponding transfer functions in
terms of the above components are:
),,min(
)(
3
1 bgr
bgr
S
(1)
bgrCb 5.03313.01687.0
(2)
otherwise.255
, and 5.1 if 256 0gr
g
r
r
g
U
(3)
The ranges of the infant skin colour are defined
as S = [5, 35], Cb = [110, 133] and U = [0, 252].
These ranges have been obtained from experimental
results. Figure 3 (b) shows the skin color detection
results of the input image in Figure 3 (a). Figure 3 (c)
shows the result after noise reduction and image
binarization. Here, a 10x10 median filter has been
used to reduce the noise and the largest connected
component has been selected as the face region
(Figure 3 (d)).
4 FEATURE EXTRACTION
In this section, we will briefly explain the different
types of moments. Given an image I, let f represent
an image function. For each pair of non-negative
integers (p, q), the digital (p, q)
th
moment of I is
given by
(a) (b) (c) (d)
Figure 3: Infant face detection.
Iyx
qp
pq
yxfyxIm
),(
),( )(
(4)
Let
00
10
0
m
m
x
and
00
01
0
m
m
y
. Then the central (p,
q)
th
moments of I can be defined as
Infant's Face Detection
Feature Extraction
Class ification
Correlation Calculation
Image Sequence
VISAPP 2010 - International Conference on Computer Vision Theory and Applications
314

() ( ) ( ) (, )
00
(,)
pq
Ixxyyfxy
pq
xy I
(5)
Hu (
Hu, 1962) defined the normalized central
moments of I to be
00
pq
pq
where
1
2
qp
(6)
From these normalized moments, Hu defined
seven moments, which are translation, scale and
rotation invariant.
02201
H
2
11
2
02202
4)(
H
2
0321
2
12303
)3()3(
H
2
0321
2
12304
)()(
H
()(3)[)(3(
)(3))[()(3(
0321
2
123003210321
2
0321
2
1230123012305
H
))((4
])())[((
0321123011
2
0321
2
123002206
H
].)()(3)[)(3(
])(3))[()(3(
2
0321
2
123003213012
2
0321
2
1230123003217
H
(7)
Liu et al. (Liu, 2008) claimed that the Hu
moments do not have scale invariability in the
discrete case, and therefore proposed ten R moments,
which are an improvement over the Hu moment
invariants. These R moments can be obtained from
the Hu moments as shown below:
1
2
1
H
H
R
,
21
21
2
HH
HH
R
,
4
3
3
H
H
R
,
||
5
3
4
H
H
R
,
||
5
4
5
H
H
R
,
31
6
6
||
HH
H
R
,
||
||
51
6
7
HH
H
R
,
23
6
8
||
HH
H
R
,
||
||
52
6
9
HH
H
R
,
43
5
10
||
HH
H
R
(8)
Zernike moments (Alpaydin, 2004) are defined
using polar coordinates and have simple native
rotation properties. The kernel of the Zernike
moments consists of a set of orthogonal Zernike
polynomials defined inside a unit circle. The Zernike
moment of order p with repetition q for an image
function f is given by
2/1
22
)(
pqpqpq
GCZ
(9)
where C
pq
indicates the real part and G
pq
indicates
the imaginary part and are given by:
/2 8
22
(2 / ) cos ( , )
2
4
11
Nu
pqv
CFuNfuv
pq pq
u
uv
N
(10)
/2 8
22
(2 / ) sin ( , )
2
4
11
Nu
pqv
GFuNfuv
pq pq
u
uv
N
(11)
where
up
qp
u
pq
r
qupqupu
up
rF
2
2/|)|(
0
! 2/||2 ! 2/||2 !
)!(
)1()(
which indicates the radial polynomials and the image
size as NxN. For each pixel (x, y) in an image,
|)||,max(| yxu
and if || xu , then
u
xy
yv 2
,
otherwise,
u
xy
y
yxu
v
||
)(2
.
As Zernike moments with a larger value of p
contain higher frequency information, we select
those moments whose value of p is either eight or
nine in our experiments. To simplify the index, we
use Z
1
, Z
2
, …, Z
10
to represent Z
80
, Z
82
, …, Z
99
respectively.
5 CORRELATION
COEFFICIENTS
Given a video sequence I = (I
1
, I
2
, …., I
n
) which
describes an infant facial expression, the system can
calculate one type of moment for each particular
frame. Suppose there are m moments, then the
system can obtain m ordered sequences A
i
=
},...,,{
21 n
iIiIiI
AAA
, i = 1, 2,…, m, where
k
iI
A
indicates the ith moment A
i
of the frame I
k
for
k = 1,
2,…, n. Now the variances of the elements in each
sequence A
i
can be calculated by
1
22
()
1
1
n
SAA
i
iiI
k
n
k
A
(12)
where
i
A is the mean of the elements in A
i
, and the
covariance between A
i
and A
j
is given by
1
[( )( )]
1
1
n
SAAAA
j
ijiI jI
i
kk
n
k
AA
(13)
Therefore, the correlation coefficients between A
i
and A
j
can be defined as
S
j
i
r
j
i
SS
ij
AA
AA
A
A
(14)
Moreover,
i
jj
i
rr
AAAA
,
1
ii
r
AA
, for i, j = 1,
2,…, m. For example, since seven Hu moments have
been defined, we can obtain a total of 21 beneficial
correlation coefficients. Figure 4 shows a video
sequence of an infant crying with fifteen frames. The
twenty-one correlation coefficients between the
seven ordering sequences are shown in Table 1.
AN INFANT FACIAL EXPRESSION RECOGNITION SYSTEM BASED ON MOMENT FEATURE EXTRACTION
315

Figure 4: A video sequence of an infant crying.
Table 1: The correlation coefficients between the seven Hu
moment sequences.
H
2
H
3
H
4
H
5
H
6
H
7
H
1
0.1222 0.2588 0.8795 -0.4564 -0.4431 -0.9140
H
2
-- -0.8272 -0.1537 0.6927 -0.1960 0.0573
H
3
-- 0.4458 -0.9237 0.2070 -0.3432
H
4
-- -0.6798 -0.2366 -0.9800
H
5
-- -0.1960 0.5663
H
6
-- 0.3218
Similarly, we can calculate the correlation
coefficients between every two R moments and
every two Zernike moments. We believe that the
correlation coefficients describe the relationship
between these moments, which vary depending on
for different facial expressions. Therefore, these
coefficients can provide important information,
which can be in turn used to classify the different
infant facial expressions.
6 CLASSIFICATION TREES
In this study, a decision tree (Alpaydin, 2004), which
implements the divide-and-conquer strategy, has
been used to classify the infant facial expressions. A
decision tree is a hierarchical model used for
supervised learning and is composed of various
internal decision nodes and terminal leaves. Each
decision node implements a split function with
discrete outcomes labeling the branches. The
advantages of the decision tree are (1) it can perform
a quick search of the class of the input features and
(2) it can be easily understood and interpreted by
mere observation. In this study, we have constructed
three binary classification trees corresponding to the
three different types of moments.
Suppose K infant facial expressions are to be
classified, namely, C
i
where i = 1,…, K. Given a
decision node S, let N
S
indicate the number of
training instances reaching the node S and
i
S
N
indicate the number of N
S
belonging to the class C
i
.
It is apparent that
S
K
i
i
S
NN
1
. The impurity
measure applied in this study is an entropy function
given by
() log
2
1
hh
K
N
N
SS
ES
N
N
h
SS
(15)
where
00log0
. The range of this entropy
function is [0, 1]. If the entropy function is zero, then
node S is pure. It means that all the training instances
reaching node S belong to the same class. Otherwise,
if the entropy is high, it means that the many training
instances reaching node S belong to different classes
and hence should be split further.
The correlation coefficients
j
i
r
AA
(Eq. (14))
between two attributes A
i
and A
j
of a training
instance can be used to split the training instances. If
0
j
i
r
AA
, then the training instances can be
assigned to one branch. Otherwise, the instances can
be assigned to a second branch. Let the training
instances in S be split into two subsets S
1
and S
2
(where
SSS
21
and
21
SS ) by the
correlation coefficient
j
i
r
AA
. Then the accuracy of
the split can be measured by
K
h
K
h
S
h
S
S
h
S
S
h
S
S
h
S
r
N
N
N
N
N
N
N
N
SE
j
i
11
22
,loglog)(
2
2
2
2
1
1
1
1
AA
(16)
Finally, the best correlation coefficient selected
by the system is
)(minarg)(
,
*
*
SESr
j
i
j
i
r
ji
AA
AA
(17)
It is to be noted that once a correlation coefficient
has been selected, it cannot be selected again by its
descendants.
The algorithm to construct a binary classification
tree is shown here:
Algorithm: Decision Tree Construction.
Step 1: Initially, put all the training instances into
root S
R
Regard S
R
as an internal decision node
and input S
R
into a decision node queue.
Step 2: Select an internal decision node S from the
decision node queue. Calculate the entropy of
node S using Eq. 15. If the entropy of node S is
larger than a threshold T
s
, proceed to Step 3,
otherwise label node S as a leaf node and proceed
to Step 4.
Step 3: Find the best correlation coefficient
*
*
j
i
r
AA
to split the training instances in node S
using Eqs. 16 and 17. Split the training instances
in S into two nodes S
1
and S
2
using the correlation
coefficients
*
*
j
i
r
AA
and then subsequently add
S
1
and S
2
into the decision node queue.
VISAPP 2010 - International Conference on Computer Vision Theory and Applications
316
Step 4: If the queue is not empty, return to Step 2,
otherwise stop the algorithm.
(a) turn right (b) front (c) turn left
Figure 5: Three head poses of infant yawning.
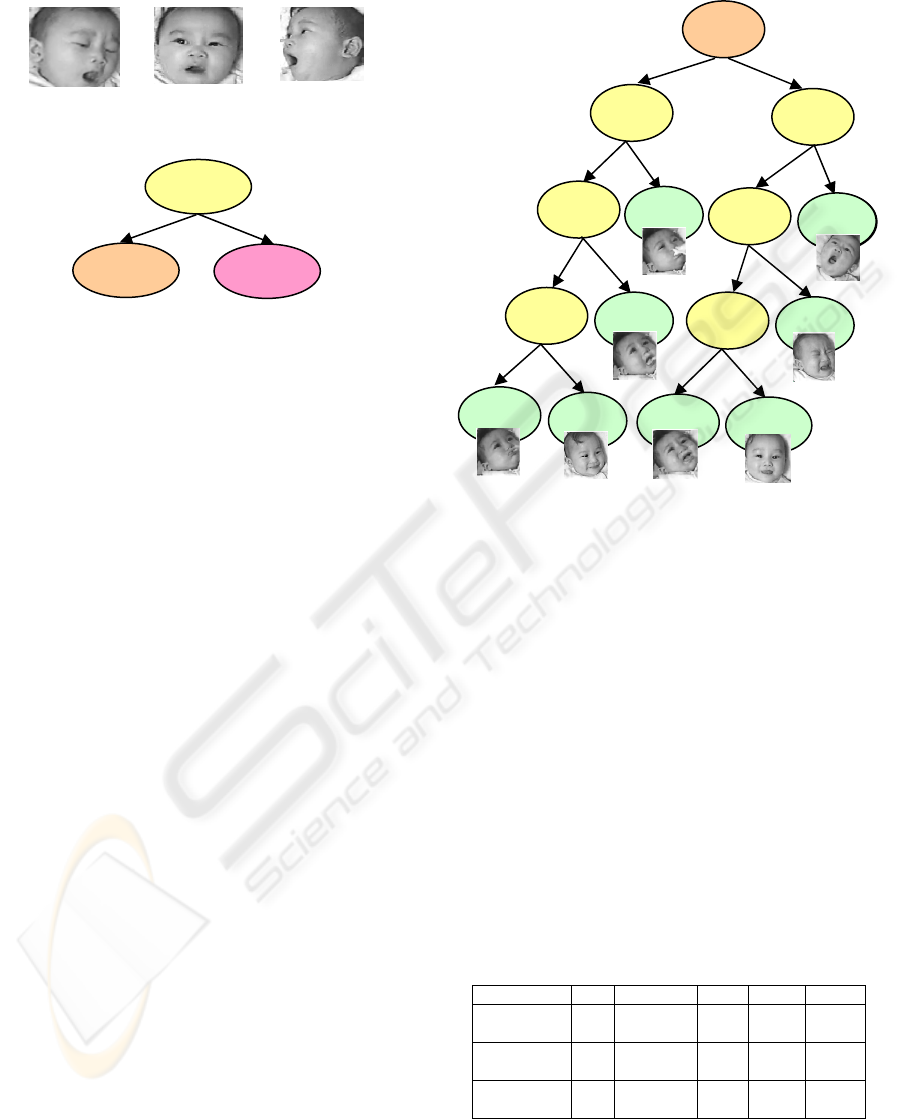
Figure 6: The decision tree of the Hu moments.
7 EXPERIMENTAL RESULTS
The input data for our system was acquired using a
SONY TRV-900 video camera mounted above the
crib and processed on a PC with an Intel
R
Core™
21.86GHz CPU. The input video sequences recorded
at a rate of 30 frames/second were down-sampled to
a rate of six frames/second, which is the processing
speed of our current system. In order to increase the
processing rate, we further reduced the size (640 x
480 pixels) of each image to 320 x 240 pixels.
Five infant facial expressions, including crying,
dazing, laughing, yawning and vomiting have been
classified in this study. Three different poses of the
infant head, including front, left, and right (an
example of an infant yawning as shown from the
three positions is shown in Figure 4) have been
considered and a total of fifteen classes have been
identified.
In the first experiment, the Hu moments and their
correlation coefficients were calculated using Eqs. 7
and 14. A corresponding decision tree was
constructed using the decision tree construction
algorithm. Figure 7 shows the decision tree
constructed using the correlation coefficients
between the Hu moments as the split function. Node
H
S
1
is the root, and the split function of
H
S
1
is
0
5
4
HH
r . Nodes
H
S
2
and
H
S
9
are the left and
right branches of
H
S
1
respectively. The left subtree
of the decision tree shown in Figure 6 is illustrated in
Figure 7 and the right subtree is depicted in Figure 8.
The split functions of the roots of the left subtree
and the right subtree are,
0
5
3
HH
r and
0
7
6
HH
r
respectively.
Figure 7: The left subtree of the decision tree depicted in
Figure 6.
When Figure 7 and Figure 8 are compared with
each other, it can be seen that most of the sequences
of the infant head position ‘turn right’ are classified
into the left subtree as shown in Figure 7. Similarly,
many sequences of the infant head position ‘turn left’
are classified into the right subtree as shown in
Figure 8.
Similarly, the same fifty-nine fifteen frame
sequences were used to train and create the decision
trees of the R and Zernike moments. The R moments
and their correlation coefficients are calculated using
Eqs. 8 and 14. The decision tree created based on the
correlation coefficients of the R moments consists of
fifteen internal nodes and seventeen leaves with a
height of ten. The experimental results are shown in
Table 2.
Table 2: The experimental results.
(1) (2) (3) (4) (5)
Hu
Moments
59 16+17 8 30 90%
R
Moments
59 15+17 10 30 80%
Zernike
Moments
59 19+20 7 30 87%
PS. (1) Number of training sequences
(2) Number of nodes (internal node + leaf)
(3) Height of the decision tree
(4) Number of testing sequences
(5) Classification Rate
yes
vomiting
0
53
HH
r
H
S
2
yes
no
0
76
HH
r
H
S
3
0
61
HH
r
H
S
6
yes
no
0
63
HH
r
H
S
4
vomiting
yes
no
0
63
HH
r
H
S
5
vomitin
g
no
laughing
yes
n
0
51
HH
r
H
S
7
y
awnin
yes
no
0
31
HH
r
H
S
8
cr
y
in
g
yes
no
laughing
crying
yawning
yes
no
0
54
HH
r
H
S
1
H
S
2
H
S
9
o
AN INFANT FACIAL EXPRESSION RECOGNITION SYSTEM BASED ON MOMENT FEATURE EXTRACTION
317
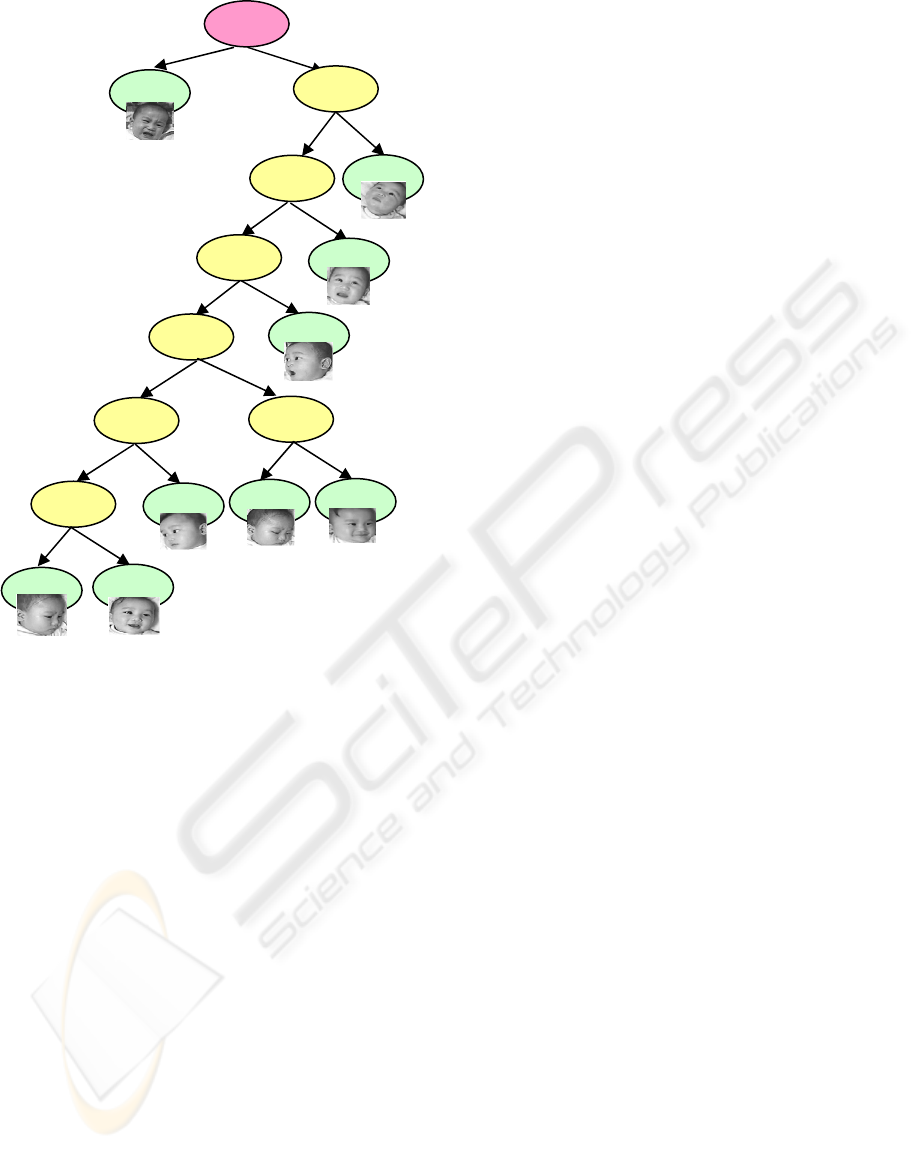
Figure 8: The right subtree of the decision tree shown in
Figure 6.
Moreover, the Zernike moments and their correlation
coefficients are calculated using Eqs. 9 and 14. The
decision tree created based on the correlation
coefficients of the Zernike moments includes
nineteen internal nodes and twenty leaves, with a
height of seven.
Table 2 also shows the classification results of
the same thirty testing sequences. We observe that
the correlation coefficients of the moments are
useful attributes for classifying infant facial
expressions. Moreover, the classification tree created
from the Hu moments has a smaller height and a
fewer number of nodes but a higher classification
rate.
8 CONCLUSIONS
This paper presented an infant facial expression
recognition technique for a vision-based infant
surveillance system. In order to obtain more reliable
experimental results, we will be collecting more
experimental sequences to construct a more
complete infant facial expression database. Binary
classification trees constructed in this study may be
less tolerant of. If the correlation coefficients are
close to zero, then the noise will greatly affect the
results of the classification. The fuzzification of the
decision tree may help solve this problem. The infant
facial expression recognition system is only one part
of the intelligent infant surveillance system. We
hope that this recognition system will be embedded
into the intelligent infant surveillance system in the
near future.
ACKNOWLEDGEMENTS
The authors would like to thank the National Science
Council of the Republic of China, Taiwan for
financially supporting this research under Contract
No. NSC 98-2221-E-003-014-MY2 and NSC
98-2631-S-003-002.
REFERENCES
Doi, M., Inoue, H., Aoki, Y., and Oshiro, O., 2006. Video
surveillance system for elderly person living alone by
person tracking and fall detection, IEEJ Transactions
on Sensors and Micromachines, Vol. 126, pp.457-463.
Department of Health, Taipei City Government, 2007.
http://www.health.gov.tw/.
The State of Alaska, 2005. Unintentional infant injury in
Alaska, Women’s, Children’s, and Family Health, Vol.
1, pp. 1-4, http://www.epi.hss.state.ak.us/mchepi/
pubs/facts/fs2005na_v1_18.pdf.
Pal, P., Iyer, A. N., and Yantorno, R. E., 2006. Emotion
detection from infant facial expressions and cries,
IEEE International Conference on Acoustics, Speech
and Signal Processing, Vol. 2, pp. 14-19.
Zhi, R., and Ruan, Q., 2008. A comparative study on
region-based moments for facial expression
recognition, The Proceedings of Congress on Image
and Signal Processing, Vol. 2, pp. 600-604.
Hu, M. K., 1962. Visual pattern recognition by moment
invariants, IRE Transactions on Information Theory,
Vol. 8, pp. 179-187.
Liu, J., Liu, Y., and Yan, C., 2008. Feature extraction
technique based on the perceptive invariability,
Proceedings of the Fifth International Conference on
Fuzzy Systems and Knowledge Discovery, Shandong,
China, pp. 551-554.
Alpaydin, E., 2004. Introduction to Machine Learning,
Chapter 9, MIT Press, Massachusetts, U.S.A.
0
76
HH
r
H
S
9
yes
no
0
41
HH
r
H
S
10
crying
yes
no
0
62
HH
r
H
S
11
yawning
yes no
0
61
HH
r
H
S
12
crying
yes
no
y
awnin
g
H
S
13
0
75
HH
r
0
21
HH
r
H
S
16
yes
no
H
S
14
0
43
HH
r
no
laughing
no
dazing
dazing
yes
yes
H
S
15
0
31
HH
r
no
crying dazing
yes
VISAPP 2010 - International Conference on Computer Vision Theory and Applications
318
