
RERANKING WITH CONTEXTUAL DISSIMILARITY MEASURES
FROM REPRESENTATIONAL BREGMAN K-MEANS
Olivier Schwander and Frank Nielsen
´
Ecole Polytechnique, Palaiseau/Cachan, France
´
ENS Cachan, Cachan, France / Sony Computer Science Laboratories Inc, Tokyo, Japan
Keywords:
Image retrieval, Bregman divergences, Alpha divergences, Clustering, Reranking, Context.
Abstract:
We present a novel reranking framework for Content Based Image Retrieval (CBIR) systems based on con-
textual dissimilarity measures. Our work revisit and extend the method of Perronnin et al. (Perronnin et al.,
2009) which introduces a way to build contexts used in turn to design contextual dissimilarity measures for
reranking. Instead of using truncated rank lists from a CBIR engine as contexts, we rather use a clustering
algorithm to group similar images from the rank list. We introduce the representational Bregman divergences
and further generalize the Bregman k-means clustering by considering an embedding representation. These
representation functions allows one to interpret α-divergences/projections as Bregman divergences/projections
on α-representations. Finally, we validate our approach by presenting some experimental results on ranking
performances on the INRIA Holidays database.
1 INTRODUCTION
Our work is grounded in the field of Content Based
Image Retrieval (CBIR): given a query image, we
search similar images in a large dataset of images.
Results are displayed in the form of a rank list where
images are ordered with respect to their similarity to
the query image. Typical CBIR systems manipulate
databases of one million images or more (see (Douze
et al., 2009; J
´
egou et al., 2008; Sivic and Zisserman,
2003) for recent works and (Datta et al., 2008) for a
comprehensive survey of the field).
Contextual Similarity measures are a way to al-
gorithmically design new similarity measures tailored
to the datasets/queries. The word context may en-
compass different meanings in the literature. On
the one hand, it can refer to the transformation of a
classical divergence D(p, q) into a local divergence
D
0
(p, q) = δ(p)δ(q)D(p, q), where the local distance
between two points depends on the neighborhood of
these two points. This idea was in particular explored
in (J
´
egou et al., 2007), which uses a conformal defor-
mation of the geometry (Wu and Amari, 2002). On
the other hand, the notion of context can also refer to
a reranking stage with a similarity measure built on
the rank list returned by a CBIR system, as developed
in (Perronnin et al., 2009). The goal is not only to im-
prove the retrieval accuracy but also to get an ordering
that is close to the intent of the user.
Perronnin’s system et al. (Perronnin et al., 2009)
addresses this problem by building contexts and aver-
aging the distances obtained for each context. In this
case, contexts are defined as the centroids of truncated
rank lists of growing size. We propose to improve this
process by building contexts in a more meaningful
way: instead of taking the N nearest neighbors of the
query, we cluster the rank list and use the centroids of
the clusters as contexts in order to naturally take into
account the semantic of the rank list. We then use an
averaging process to get a unique similarity score to
rerank image matching scores.
Instead of using a classical k-means cluster-
ing algorithm based on the squared Euclidean dis-
tance, we rather introduce a modified clustering al-
gorithm based on α-divergences (see Amari (Amari,
2007; Amari and Nagaoka, 2007)). The family
of information-theoretic α-divergences are provably
more suited to handle histogram distributions at the
core of many CBIR systems (e.g., bag of words). We
extend the Bregman k-means algorithm introduced by
Banerjee et al. (Banerjee et al., 2005; Nock et al.,
2008).
Finally, we evaluate our clustering and reranking
framework on the INRIA holidays dataset (J
´
egou
et al., 2008) based on the novel contextual similarity
measures.
118
Schwander O. and Nielsen F. (2010).
RERANKING WITH CONTEXTUAL DISSIMILARITY MEASURES FROM REPRESENTATIONAL BREGMAN K-MEANS.
In Proceedings of the International Conference on Computer Vision Theory and Applications, pages 118-123
DOI: 10.5220/0002842901180123
Copyright
c
SciTePress

2 REPRESENTATIONAL
BREGMAN DIVERGENCES
2.1 Definitions
Invariance and Information Monotonicity of
α-divergences. We recall the definition of α-
divergences (Amari and Nagaoka, 2007) that are de-
fined on positive arrays (unnormalized discrete prob-
abilities) for α ∈ R as:
D
α
(pkq) =
∑
d
i=1
4
1−α
2
1−α
2
p
i
+
1+α
2
q
i
− p
1−α
2
i
q
1+α
2
i
if α 6= ±1
∑
d
i=1
p
i
log
p
i
q
i
+ q
i
− p
i
= KL(pkq)
if α = −1
∑
d
i=1
p
i
log
q
i
p
i
+ p
i
− q
i
= KL(qkp)
if α = 1
(1)
This is all the more important that in the heart of
CBIR systems, we deal with histograms (e.g., bag-
of-words) that are considered as multinomial prob-
ability distributions. Therefore, we need a distri-
bution measure D to calculate the dissimilarity of
multinomials D(p(x; θ
p
)||p(x;θ
q
)) where θ
p
and θ
q
are the histogram distributions. Symmetrized α-
divergences S
α
(p, q) =
1
2
(D
α
(pkq) + D
α
(qkp)) be-
long to Csisz
´
ar’s f -divergences and therefore retain
the information monotonicity property.
From the pioneering work of Chentsov (Chentsov,
1982), it is known that the Fisher-Rao rieman-
nian geometry (with the induced Levi-Civita
connection) and the α-connections are the only
differential geometric structures that preserve the
measure of probability distributions by reparam-
eterization. We consider the α-divergences that
are a proper sub-class of Csisz
´
ar f -divergences
that satisfy both reparameterization invariance
(i.e., D(p(x;θ
p
)||p(x;θ
q
)) = D(p(x;λ
p
)||p(x;λ
q
))
for λ
x
= f (θ
x
) where f is a bijective mapping)
and information monotonicity (Csisz
´
ar, 2008):
D(p(x;θ
p
)||p(x;θ
q
)) ≥ D(p(x; θ
0
p
)||p(x;θ
0
q
)) for
θ
0
a coarser partition of the histogram. That is, if
we merge bins θ into coarser histograms θ
0
, the
distance measure should be less than the distance by
considering the higher-resolution histograms.
Bregman Divergences. Given a strictly convex and
differentiable function F : R
d
→ R, we define the
Bregman divergence associated with the generator F
as:
B
F
(pkq) = F(p) − F(q) − hp − q, ∇F(q)i (2)
The generator F(x) = x
>
x =
∑
d
i=1
x
2
i
yields to the
squared Euclidean distance. Using the Shannon neg-
ative entropy (F(x) =
∑
d
i=1
x
i
logx
i
) we get the well-
known Kullbach-Leibler (KL) divergence.
2.2 Representation Function
Nielsen and Nock (Nielsen and Nock, 2009) showed
that α-divergences (but also β-divergences (Mihoko
and Eguchi, 2002)) are representational Bregman di-
vergences in disguise. Let’s consider decomposable
Bregman divergences:
B
F
(pkq) =
d
∑
i=0
B
F
(p
i
kq
i
) (3)
With a slight abuse of notation, we denote its sep-
arable generator F as F(x) =
∑
d
i=0
F(x
i
). We call rep-
resentation function a strictly monotonous function k
that introduces a (possibly non-linear) coordinate sys-
tem x
i
= k(s
i
) where each s
i
comes from the source
coordinate system. This mapping is bijective since k
is strictly monotonous and s
i
= k
−1
(x
i
). We have the
following Bregman generator:
U(x) =
d
∑
i=1
U(x
i
) =
d
∑
i=1
U(k(s
i
)) = F(s) (4)
where F = U ◦ k.
The class of α-divergences are representational
Bregman divergences for
U
α
(x) =
2
1 + α
1 − α
2
x
2
1−α
, k
α
(x) =
2
2 − α
x
1−α
2
(5)
Notice it turns out that F may not be strictly con-
vex (Nielsen and Nock, 2009) (U
α
◦ k
α
is linear) al-
though U always is strictly convex.
2.3 Contexts from α k-means:
α-centroids
Like (most of) the Bregman divergences, α-
divergences are not symmetrical. This yields two dif-
ferent ways of defining centroids: the left-sided cen-
troid c
L
and the right-sided centroid c
R
:
c
R
= argmin
c∈X
n
∑
i=1
B
U, k
(p
i
kc) (6)
c
L
= argmin
c∈X
n
∑
i=1
B
U, k
(ckp
i
) (7)
RERANKING WITH CONTEXTUAL DISSIMILARITY MEASURES FROM REPRESENTATIONAL BREGMAN
K-MEANS
119
Closed-form formulas are given in (Nielsen and
Nock, 2009):
c
R
= n
−
2
1−α
∑
p
1−α
2
i
2
1−α
(8)
c
L
= n
−
2
1+α
∑
p
1+α
2
i
2
1+α
(9)
2.4 Clustering with Representation
Functions
Banerjee et al. (Banerjee et al., 2005) showed that the
classical clustering algorithm k-means generalizes to
and only to Bregman divergences. Using the repre-
sentational framework of section 2.2, we extend their
algorithm to the α-divergences by plugging the rep-
resentation function. This leads to the algorithm 1,
which is nearly identical to the classical one except
for the centroid computation part. (Symmetrized α-
divergences S
α
are handled implicitly by two poten-
tial functions, similarly to (Nock et al., 2008).)
Algorithm 1 Representational Bregman k-means.
Require: A set X of n points x
i
of R
d
, a number of
clusters k, a Bregman representational divergence
B
U,k
Ensure: A hard partitioning {µ
i
}
1≤i≤k
of X which
is a local minimizer of the loss function
∑
k
h=1
∑
x
i
∈X
h
B
U,k
(x
i
, µ
h
)
Choose k points µ
i
(with k-means++ initialization
method (Nock et al., 2008))
repeat
{Assignment step}
Set X
h
←
/
0 for 1 ≤ h ≤ k
for i = 1 to n do
h ← argmin
h
0
B
U,k
(x
i
||µ
h
0
)
Add x
i
to X
h
end for
{Relocation step}
for h = 1 to k do
µ
h
← k
−1
(
∑
n
i=1
k(x
i
))
end for
until convergence
Return {µ
1
, . . . , µ
k
}
3 CONTEXTUAL
DISSIMILARITY MEASURES
3.1 Definition
Perronnin et al. (Perronnin et al., 2009) introduces
a framework to improve the retrieval performance of
the bag-of-word CBIR systems. The following is de-
fined for any arbitrary divergence f . Let’s first define
a function Φ:
Φ
f
(ω;q, p, u) = f (q, ωp + (1 − ω)u) (10)
The contextual dissimilarity will be defined as the
following minimization problem
1
:
cs
f
(q, p|u) = arg min
0≤ω≤1
Φ
g
(ω;q, p, u) (11)
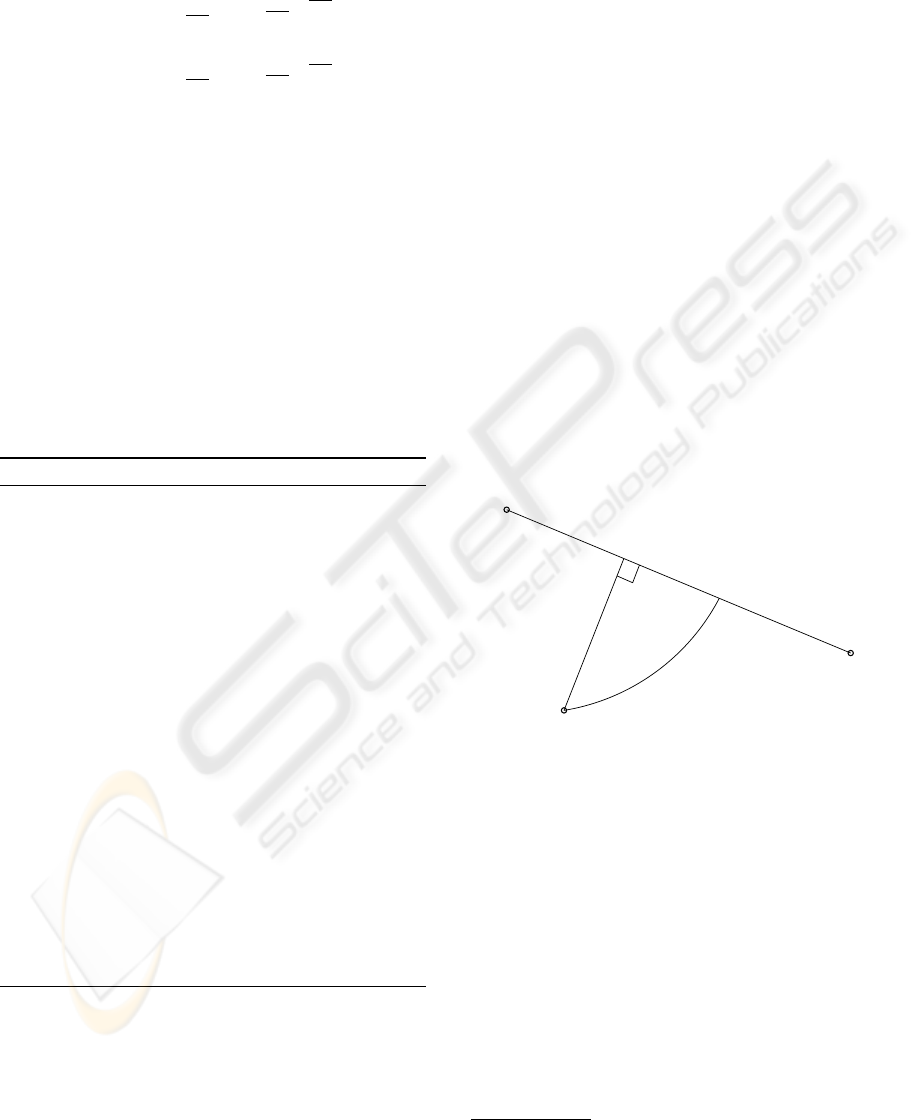
This minimization is equivalent to searching for
the generalized Bregman projection of the point q
on the (euclidean) line segment [p, u] (see Figure 1,
p
⊥
denotes the usual Euclidean projection and p
?
the
Bregman projection) and thus can be solved using a
simple convex minimization algorithm.
p
u
q
q
⊥
q
?
Figure 1: Contextual similarity and Bregman projection.
One can also use the symmetrized version of this
measure. In this case, we take:
Φ
f
(ω;q, p, u) = f (q, ωp + (1 − ω)u)
+ f (q, ωp + (1 − ω)u)
(12)
4 RETRIEVAL PROCESS
4.1 Retrieval
We choose to use a retrieval system based on GIST
descriptors as described in J
´
egou et al. (J
´
egou et al.,
1
Here, we use dissimilarity instead of similarity, so we
get a min instead of the max of Perronnin et al.
VISAPP 2010 - International Conference on Computer Vision Theory and Applications
120

2007). GIST descriptors are global image descrip-
tors (introduced in (Oliva and Torralba, 2006)) that
allow quite good performances scores (even if infe-
rior to state-of-the-art bag of words approaches, see
(J
´
egou et al., 2008)) with reduced memory footprint
and high speed that allow systems to scale well on
large datasets.
The GIST CBIR framework works as follows:
1. Given a query image, compute its GIST descrip-
tor.
2. Search for N-nearest neighbors of the query in the
dataset (where N is the size of the short list).
3. Display the neighbors ordered with respect to
their distances to the query.
4.2 Reranking
The contextual dissimilarity takes place as a rerank-
ing step after the use of a classical retrieval system.
It was shown empirically in (Perronnin et al., 2009)
that images that are not in the short list have very low
chance to be in the new N-neighborhood.
Given a short list of size N, the algorithm is the
following:
1. Take only the first k elements (i.e. the k nearest
neighbors of the query).
2. Estimate a context using the selected points by
computing their centroids.
3. For all elements of the short list, compute
cs
f
(q, p
i
|u
k
).
4. Rerank the list according to these scores.
4.3 Reranking with Multiple Contexts
The previous algorithm uses only one context which
may be not sufficient to capture the information re-
lated to contexts. The original framework of Per-
ronnin et al. (Perronnin et al., 2009) used truncated
rank lists to build the contexts. The full dissimilar-
ity is computed by doing a weighted average of the
dissimilarities with context built using the centroid of
growing size short lists. This approach leads to good
experimental results. However, the truncated rank list
is not the better method to capture the meaning of
clusters. As depicted in Figure 2, a truncated rank
list may group images from different groups of simi-
lar images.
So instead of using the k nearest neighbors of the
query to define a context, we cluster the rank list in
order to get meaningful contexts which best describe
the query. We then propose the following average
scheme:
p
6
p
2
p
3
p
N
p
5
p
6
p
4
p
1
q
class 1
class 2
class 3
Figure 2: Different contexts and potential rank lists.
cs
f
(q, p) =
∑
u∈U
cs
f
(q, p |u) (13)
5 EXPERIMENTS
5.1 Experimental Setup
Dataset. We use the Holidays dataset from INRIA:
this set was introduced to evaluate state-of-the-art
framework (J
´
egou et al., 2008). It contains 1491 per-
sonal holiday photos with approximately 500 image
groups. Thanks to INRIA, this dataset is publicly
available on the author’s website
2
.
Baseline. We first report the results for a simple
ranking system based on GIST global descriptors (see
(Douze et al., 2009)). We use α-divergences as dis-
similarity measures.
Contextual Measure of Dissimilarity. We next
present results for the Contextual Measure of Dis-
similarity of (Perronnin et al., 2009). The results
are not directly comparable with the original paper
since we use global descriptors instead of a bag-of-
features approach. Moreover, we do not only use
Kullbach-Leibler divergence to do the ranking but
also α-divergences.
Evaluation. The retrieval accuracy is measured in
terms of mean average precision (mAP) which is a
very common measure in the information retrieval
field.
2
http://lear.inrialpes.fr/people/jegou/data.php
RERANKING WITH CONTEXTUAL DISSIMILARITY MEASURES FROM REPRESENTATIONAL BREGMAN
K-MEANS
121
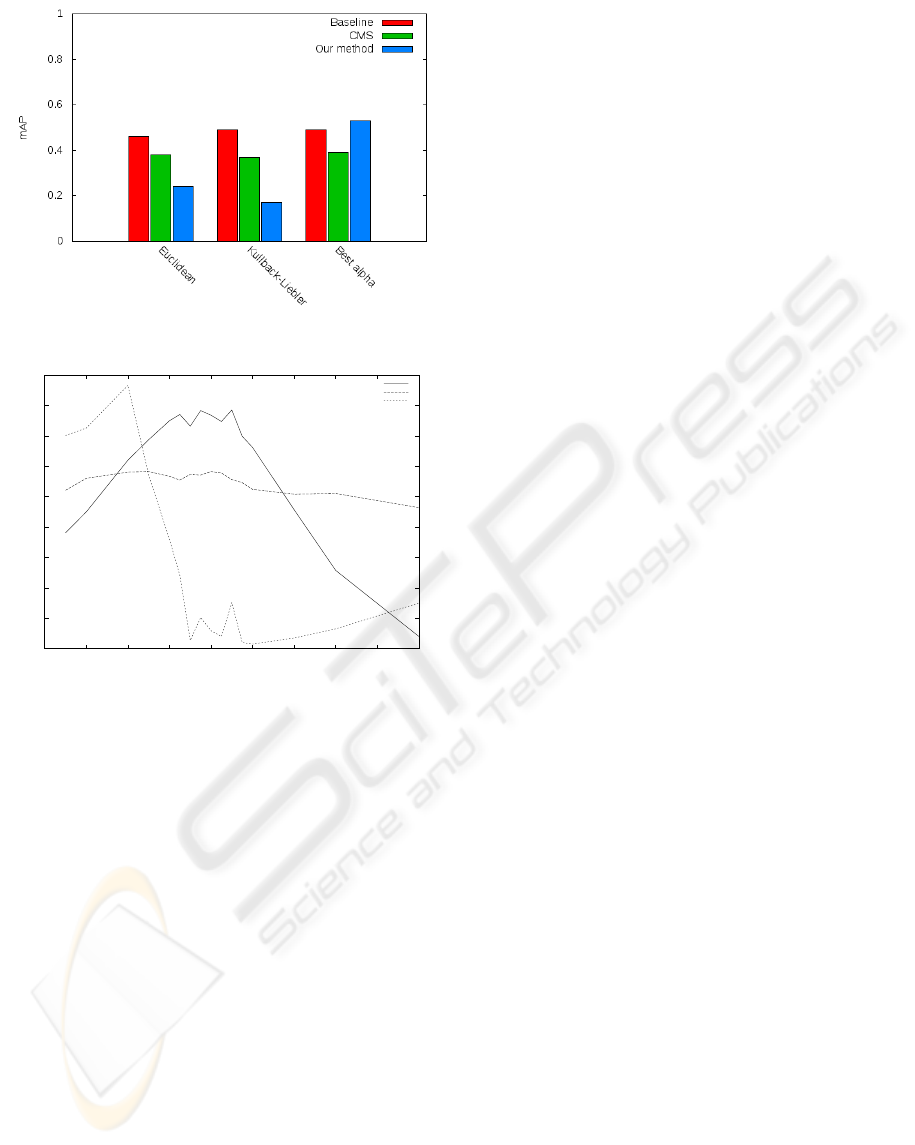
(a) Comparison between different reranking methods
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
-8 -6 -4 -2 0 2 4 6 8 10
mAP
alpha
Baseline
CMS
Our method
(b) Impact of the α parameter
Figure 3: Experimental results. Baseline is the raw rank list.
CDM is the Contextual Dissimilarity Measure of (Perronnin
et al., 2009)
5.2 Results
We compare on the Figure 3a the results we get
for: a rank list without any reranking (baseline), the
(Perronnin et al., 2009) contextual dissimilarity mea-
sure (CDM) and our method. Results are shown for
the Euclidean divergence, the Kullbach-Leibler diver-
gence and the α-divergence with the α which gave the
best mAP score.
We see that our reranking method behaves badly
for the Euclidean and Kullbach-Leibler divergence
but we manage to outperform these two divergences
with a well-chosen α.
In the Figure 3b, we study the impact of the α pa-
rameter for the three different methods (baseline, Per-
ronnin and ours). The influence is not so big on (Per-
ronnin et al., 2009) CDM but the scores really depend
on the α for the two other methods. Moreover, the
behavior is completely different for our method and
for the Perronnin one’s: our method reaches an opti-
mum near α = −4 and is not symmetrical whereas the
CDM curve is symmetrical and centered on α = 0.
6 CONCLUSIONS
We present a new family of clustering algorithms
based on k-means and α-divergences. We recall how
representational functions can be used to map α-
divergences to the space of the well-known Bregman
divergences. Using this mapping, we show that we
can adapt the Bregman k-means algorithm in order to
build an α k-means clustering algorithm.
We then focus on contextual similarity measure by
using this family of k-means algorithms to build con-
texts by clustering the rank list given by a traditional
(that is to say, not contextual) retrieval system.
Using α-divergences with a well-chosen α pa-
rameter and our cluster based contextual dissimilarity
measure, we are able to outperform other contextual
similarity measures. Since the choice of α is critical
for the quality of the results, we can conclude that the
α divergences are a very interesting family of dissim-
ilarity measures.
ACKNOWLEDGEMENTS
We thank Herv
´
e J
´
egou (INRIA) and Shun-ichi
Amari (Brain Science Institute) for insightful email
exchanges considering respectively the reranking
methodologies and the α-divergences. We also thank
the referees for their helpful observations.
REFERENCES
Amari, S. (2007). Integration of stochastic models
by minimizing α-divergence. Neural computation,
19(10):2780–2796.
Amari, S. and Nagaoka, H. (2007). Methods of information
geometry. AMS.
Banerjee, A., Merugu, S., Dhillon, I., and Ghosh, J. (2005).
Clustering with Bregman divergences. The Journal of
Machine Learning Research, 6:1705–1749.
Chentsov, N. (1982). Statistical Decision Rules and Opti-
mal Inferences. Trans. of Math. Monog., n 53.
Csisz
´
ar, I. (2008). Axiomatic characterizations of informa-
tion measures. Entropy, 10(3):261–273.
Datta, R., Joshi, D., Li, J., and Wang, J. (2008). Image
retrieval: Ideas, influences, and trends of the new age.
ACM Comput. Surv.
VISAPP 2010 - International Conference on Computer Vision Theory and Applications
122

Douze, M., J
´
egou, H., Singh, H., Amsaleg, L., and Schmid,
C. (2009). Evaluation of GIST descriptors for web-
scale image search. In International Conference on
Image and Video Retrieval. ACM.
J
´
egou, H., Douze, M., and Schmid, C. (2008). Hamming
embedding and weak geometric consistency for large
scale image search. In European conference on com-
puter vision, pages 304–317. Springer.
J
´
egou, H., Harzallah, H., and Schmid, C. (2007). A con-
textual dissimilarity measure for accurate and efficient
image search. In Conference on Computer Vision &
Pattern Recognition.
Mihoko, M. and Eguchi, S. (2002). Robust blind source
separation by beta divergence. Neural computation,
14(8):1859–1886.
Nielsen, F. and Nock, R. (2009). The dual Voronoi dia-
grams with respect to representational Bregman diver-
gences. In International Symposium on Voronoi Dia-
grams (ISVD).
Nock, R., Luosto, P., and Kivinen, J. (2008). Mixed breg-
man clustering with approximation guarantees. In
Daelemans, W., Goethals, B., and Morik, K., editors,
ECML PKDD (2), volume 5212 of Lecture Notes in
Computer Science, pages 154–169. Springer.
Oliva, A. and Torralba, A. (2006). Building the gist of a
scene: The role of global image features in recogni-
tion. Progress in Brain Research, 155:23.
Perronnin, F., Liu, Y., and Renders, J. (2009). A family
of contextual measures of similarity between distribu-
tions application to image retrieval. In CVPR09, pages
2358–2365.
Sivic, J. and Zisserman, A. (2003). Video Google: A text
retrieval approach to object matching in videos. In
Proc. ICCV, volume 2, pages 1470–1477. Citeseer.
Wu, S. and Amari, S. (2002). Conformal transformation of
kernel functions: A data-dependent way to improve
support vector machine classifiers. Neural Processing
Letters, 15(1):59–67.
RERANKING WITH CONTEXTUAL DISSIMILARITY MEASURES FROM REPRESENTATIONAL BREGMAN
K-MEANS
123
