
ON THE EXPLORATION AND EXPLOITATION OF STRUCTURAL
SIMILARITIES IN ARGUMENTATIVE DISCOURSES
George Gkotsis and Nikos Karacapilidis
Industrial Management and Information Systems Lab
MEAD, University of Patras, Patras, Greece
Keywords:
Argumentation, Argument sequence, Similarity, Mining.
Abstract:
Motivated by the fact that contemporary argumentation systems provide low or no support with regards to
argument and information processing, this paper presents a generic computational model that is able to identify
and assess structural similarities in argumentative discourses. Focusing on the structure of such discourses,
we sketch representative scenarios where the proposed model can be applied at a wide range of argumentation
systems in order to define, elaborate and mine meaningful argumentation patterns. We argue that the proposed
model is of considerable contribution to both theoretical and practical aspects of argumentation.
1 INTRODUCTION
When engaged in argumentative discourses users
have to exploit their own cognitive abilities and sen-
timent. Reality shows that individuals react and un-
derstand differently upon the same input, i.e. it is
very likely for two users to process the same informa-
tion in a different manner. For instance, people tend
to overlook information that undermines their view-
points (confirmation bias phenomenon (Kuhn, 1991))
and prefer supportive information compared to op-
posing one (selective exposure phenomenon ((Jonas
et al., 2001)); some users - newcomers very likely
- might prefer to get an abstract representation of
the discourse taking place by viewing participants
and their corresponding contributions (Rees, 1995) or
may want to filter out old contributions, or focus on
a specific part of the dialogue; others might prefer
to analytically examine every aspect of the dialogue,
reconstruct argumentative discourse (Eemeren et al.,
1993), identify inconsistencies between peers and at-
tempt defeating standing arguments.
Today’s argumentation support systems have to
overcome a series of complex technological and so-
cial challenges (Shum et al., 2008). From a tech-
nological perspective, major advances already taken
place concern information exchange (Reed and Rowe,
2004), interoperability among applications and data
referring mechanisms (Karacapilidis et al., 2009);
however, the corresponding web 2.0 compliant ap-
plications do not eliminate the information overload
problem. At the same time, even though humans have
been extensively engaged in argumentativedialogues,
online participation in a discourse is a modern phe-
nomenon. Recent studies reveal facts like social loaf-
ing and attrition (e.g. (Johnson, 2001)). Generally
speaking, research has a long way to fight the low ac-
ceptance of argumentation support systems.
The problem of equipping an argumentation sup-
port system with mechanisms that ease information
processing has been addressed by various techniques,
which can be classified in two complementary cate-
gories. On the one hand, we find attempts to identify
specific attributes in arguments to be then exploited
by inference mechanisms (e.g. in agent-based deci-
sion support systems). Classifying arguments accord-
ing to the above attributes has proven to be a feasible
and effective way to compute features, such as ac-
ceptability (correct or wrong), ambiguity (agreement
vs. disagreement) and consistency (consistent conclu-
sions) (Caminada and Amgoud, 2007). The above can
be considered as an attempt to model arguments on a
microstructure level, since the focus in this case is on
the argumentper se and not on the complete discourse
or argumentation structure.
On the other hand, on a macrostructure level,
one of the key elements that characterize an argu-
mentation support system is the argumentation model
adopted. Although each model serves a specific pur-
pose, they all share some common characteristics:
137
Gkotsis G. and Karacapilidis N.
ON THE EXPLORATION AND EXPLOITATION OF STRUCTURAL SIMILARITIES IN ARGUMENTATIVE DISCOURSES.
DOI: 10.5220/0002845201370143
In Proceedings of the 6th International Conference on Web Information Systems and Technology (WEBIST 2010), page
ISBN: 978-989-674-025-2
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

they define the type of the argumentation objects and
the actions that can be performed on them
1
. Thus,
once the system has defined its model, every dis-
course is codified and validated against it. Afterward,
the interest is mainly focused on supporting well-
defined reasoning practices through the definition and
modeling of specific activities. From a computa-
tional perspective, depending on the formality level
adopted, the systems under consideration attempt to
ease decision support through reasoning algorithms,
assist the identification of logic violations, or simply
provide a convenient repository for accessing, amend-
ing and publishing knowledge.
We view argumentation as an act of social prac-
tice, where discussion accommodates the sharing of
different opinions, blending of various ideas, and
knowledge building. According to (Weinberger and
Fischer, 2006), the participation in an argumenta-
tive dialogue is divided into several phases: early
phases include the externalization and elicitation of
opinions, ideas and arguments; intermediate ones in-
clude consensus building; last phases are described
as integration-oriented and conflict oriented consen-
sus building. Focusing on the intermediate and late
phases, we argue that contemporary systems pay little
attention and provide low support to them. We believe
that argumentation support systems should remedy
user disorientation through the provision of mecha-
nisms that allow easy and meaningful evaluation of
arguments and argumentation sequences.
An argumentation sequence may be described as
set of arguments interrelated in a specific way. Ar-
gumentation sequences have proven to be useful ab-
straction mechanisms that allow systems to elucidate
and simplify argumentation dialogues. Until now, the
main contribution of argumentation sequences is that
they can be used to aggregate small pieces of dialogue
to entities of higher meaning and stimulate specific
behavioral patterns in a dialogue (Baker, 1999). Fol-
lowing a specific argumentation formalism, and with-
out loss of generality, this paper describes a graph-
like model of argumentation dialogues. This repre-
sentation allows us to quantify node structure similar-
ity in an argumentation context, thus enabling us to
consider various aspects of argumentation at both the
micro and macro structure levels. The ultimate gain of
the proposed model resides in the ability to represent
diverse argumentation sequences in a generic, flexi-
ble and accurate way. Thus, argumentation sequences
can be indexed and handled appropriately. Mining of
1
Note that the pioneer argumentation model by Toulmin
focuses on describing the discourse in terms of claims, war-
rants and grounds; participants merely constitute an inter-
esting entity (Toulmin, 1958).
unnoticed sequences can also be achieved.
In the following sections, we describe the pro-
posed model, sketch representativescenarios of its us-
age, and conclude by discussing related work and the
contribution of our approach.
2 PROPOSED APPROACH
We first model an argumentative discussion as a dis-
cussion graph. For this graph, we assume the follow-
ing properties:
• The graph is a connected weighted undirected
tree;
• The issue or topic of the discussion is handled as
the root of the graph;
• Any alternative is linked to the root of the graph
through a neutral type edge. Neutral relationships
have weight equal to 0.
• Any argument is a node
2
connected to another ar-
gument or alternative. Any argument participat-
ing in a relationship expresses exclusively either
agreement or disagreement. Agreement has value
of 1, where disagreement has value -1.
Vertex refinement query, introduced in (Hay et al.,
2008), is a mathematical model that allows the iden-
tification of similarities in undirected, unweighted
graphs and has been applied in social networks. In
this paper, we are going to modify the vertex refine-
ment query process in order to apply it to a graph
with the above characteristics (undirected, weighted
discussion graphs).
2.1 Node Value Definition
For any node x - except the root of the graph - we
define a property called value: V
x
where V
min
≤V
x
≤
V
max
. V
min
and V
max
are the minimum and maximum
values of this property correspondingly. This value
may be computed by one or more argument attributes.
For example, this may be the average rating for a sys-
tem that supports item rating, the expertise of its au-
thor or any other scalable attribute any system might
introduce. Selecting an appropriate attribute is a cru-
cial step. In the simplest scenario, where no specific
attribute is chosen, the value for each node may be 1.
2
For the rest of this section, the terms node and vertex
will be treated interchangeably.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
138

2.2 Node Similarity for Degree Value 0
We define a node similarity function between ar-
guments x and y for degree value of 0
3
, noted as
Sim(x
0
,y
0
), which is the complement of the normal-
ized to the scale between 0 and 1 Euclidean differ-
ence, as:
Sim(x
0
,y
0
) = 1−
|V
x
−V
y
|
V
max
−V
min
2.3 Vertex Refinement Query
Vertexrefinement query for degree i and node x, noted
as H
i
(x), allows us to identify vertices structural sim-
ilarity by exploring the nearby vertices and is ex-
pressed as an iterative recursive query:
H
i
(x) = {±H
i−1
(z
1
),±H
i−1
(z
2
),...,±H
i−1
(z
m
)}
where H
0
(x) = {±V
x
}, z
1
,z
2
,...,z
m
are nodes adja-
cent to x, and i expresses the degree of the query. The
sign ± is inserted in front of every vertex refinement
query and is either positive, if the adjacent node is
supporting node x, or negative if it opposes node x.
If the adjacent node is the root of the tree (discussion
issue), the node is ignored.
2.4 Computing Sequence Similarity
In order to compute the sequence similarity between
nodes for a given degree, a function is introduced
that takes as input the result of the vertex refinement
queries. More specifically, the sequence similarity
function between 2 nodes takes as input the result
of the 2 corresponding vertex refinement queries (in
fact, the result of a vertex refinement query is a set
of signed nodes) and returns a real number between 0
and 1 that expresses the sequence similarity. More
precisely, sequence similarity is calculated through
the matching of nodes between the first and the sec-
ond set. Through this matching, the sequence similar-
ity is expressed as the sum of the similarities between
pairs of nodes and such that this sum is maximized.
Even though the thorough analysis of the com-
plexity of this problem exceeds the purpose of this
paper, we are going to present a solution for it, by de-
scribing how this problem can be reduced to a well
known problem cited in graph theory, as follows:
We create a bipartite graph G(A, B, E) where A
and B are the vertices of first and second set of the
signed nodes, respectively. Let E be the set of edges
connecting every vertex from A to B. The weight of
3
Degree value of 0 actually reflects the case where we
are only interested about the two nodes under consideration,
without paying attention to their adjacent nodes. In the gen-
eral case, as the degree value raises, so does the scope of the
similarity function.
every edge is computed following definition in 2.2
and expresses the node similarity for degree value of
0, including its ± sign. This bipartite graph is com-
plete (every vertex from set A is connected to every
vertex from set B, since we can always compute the
similarity for every pair of nodes). For this bipartite
graph, we seek to find a matching M ⊆ E among ver-
tices A, B such that the sum of the weight for edges
∈ M is maximized. This is an old problem and is
known as ”maximum weight matching in complete
bipartite graphs”. Hopcroft-Karpalgorithm (Hopcroft
and Karp, 1973) runs in O(
√
nW) = O(n
5/2
), where
n is the number of vertices and W is the total num-
ber of edges of graph G (in complete bipartite graphs
W = n
2
).
We define sequence similarity for degree i > 0 be-
tween arguments x, y as:
Sim(x
i
,y
i
) =
∑
i=|M|
i=1
weight(e)
max(|A|,|B|)
for every e ∈M,
where A, B are the vertex refinement queries of x,
y for the selected degree i and M is the maximum
weight matching described above. Furthermore, the
result is divided by the max set size in order to be
normalized to the scale between 0 and 1.
2.5 Vertex Equivalence
We define two nodes x and y as equivalent, with re-
spect to degree of value i, denoted as x ≡
i
y, iff:
Sim
H
i(x)
,H
i
(y)
> threshold
i
, where threshold
i
is a constant (user-defined) real number between 0
and 1.
2.6 Vertex Identity
We define two nodes x and y as identical with respect
to degree of value i, iff:
Sim
H
i(x)
,H
i
(y)
> threshold
t
for every t ∈ [0,i],
where threshold
t
is also a constant user-defined real
number between 0 and 1 (which does not necessarily
have the same value with equivalence threshold).
Note that equivalence relationship is weaker than
identity, since there might be several inequalities for
lower values of i.
2.7 Example
Figure 1 illustrates a simple argumentation graph.
P
1
,P
2
,P
3
,P
4
are arguments, A
1
,A
2
are alternatives
and I is the issue of the discussion. Dashed line de-
picts opposition, while solid line depicts agreement.
To demonstrate our model, we are going to search
whether repetitions of argumentation sequences ap-
pear, i.e. we will search for structural similarity of
ON THE EXPLORATION AND EXPLOITATION OF STRUCTURAL SIMILARITIES IN ARGUMENTATIVE
DISCOURSES
139
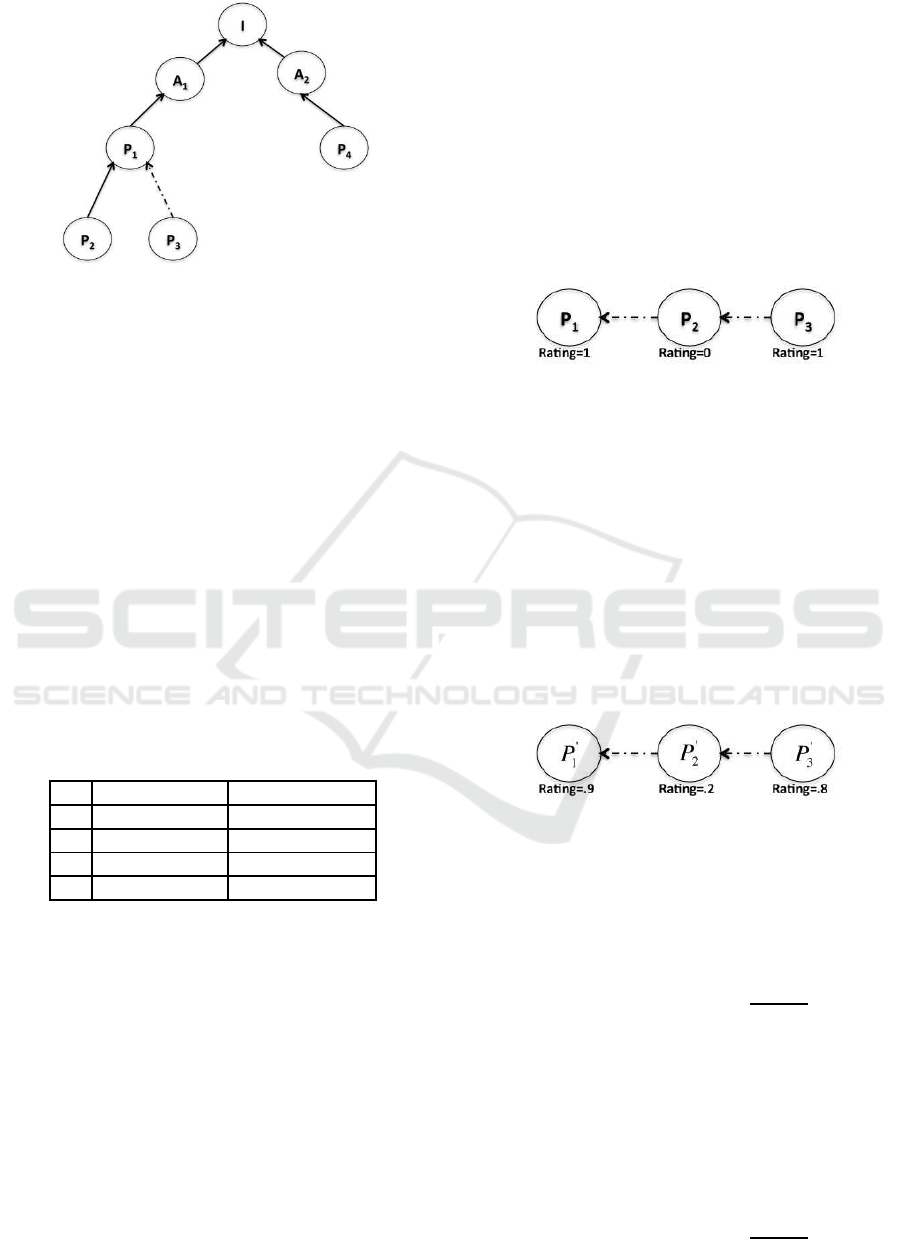
Figure 1: A simple argumentation graph.
each argument of the discussion against all other ar-
guments.
In order to keep the example simple, we assign to
each node a value of 1. It is clear that for our example:
Sim(x
0
,y
0
) = 1, for every x,y.
Furthermore, since we decided to assign the same
value for each node, we raised the threshold for both
equivalence and identity operations to 1. Neverthe-
less, if we had used real data - where the value for
every node rarely should be expected to have value of
1-, we should experiment with lower threshold values.
We obtain the following (see Table 1):
There is no node that appears structurally identical
to another if the degree is higher than 1. However,
for degree value of 1, nodes P
2
and P
4
are identical
since they are the only nodeswith their adjacent nodes
connected in the same way.
Table 1: Vertex refinement queries for the graph of Figure
1.
H
1
H
2
P
1
{A
1
,P
2
,−P3} {P
1
,P
1
,−P1}
P
2
{P
1
} {P
2
,−P
3
,A
2
}
P
3
{−P
1
} {−P
2
,P
3
,−A
1
}
P
4
{A
2
} {P
4
}
3 ARGUMENTATION SEQUENCE
IDENTIFICATION
3.1 Case 1: Finding Specific
Argumentation Sequences
In this case, we assume that a user wants to search
in one or more discussion graphs for arguments inter-
related in some meaningful way. This includes cases
where a set of arguments connected to each other con-
stitutes a structure of higher meaning, such as de-
feated arguments, well supported arguments, under-
cutters or ill supported arguments . Thus, a structure
of higher meaning refers to an aggregation of argu-
ments interrelated in such a way that these arguments
can be regarded as a meaningful concept from an ar-
gumentation point of view. In that way, these struc-
tures can assist the user analyze the outcome of a dis-
cussion in a more convenient way, so that ultimately
he will be able to identify expressed behaviors, like
consensus, disputes and refutes.
We assume a system supporting community rating
for every argument. Without loss of generality, let this
rating be a real number between 0 and 1.
Figure 2: A defeated argument.
In the argumentation sequence shown in Figure
2, dashed lines depict disagreement and rating is an-
notated for every argument. This argumentation se-
quence describes that a user tried to defeat argument
P
1
through argument P
2
, P
2
received low rating, while
one more argument (P
3
) defeated argument P
2
and re-
ceived high rating. In summary, we can claim that
this argumentation sequence is a sequence where ar-
gument P
2
is defeated.
We are going to use the above argumentation se-
quence as a training sequence. A real-world dialogue
may contain approximate values, like the argumenta-
tion sequence shown in Figure 3.
Figure 3: A real-world argumentation sequence.
Following our model, we are going to calculate
the similarity for degree values 0 and 1 of arguments
P
′
1
,P
′
2
, and P
′
3
against argument P
2
. It is:
• For argument P
′
1
:
Sim(P
′
1
,P
2
)
degree=0
= 1−
0.9−0
1−0
= 0.1
Sim(P
′
1
,P
2
)
degree=1
= sim
{−P
′
2
},{−P
1
,−P
3
}
= sim
{−0.2},{−1, − 1}
= 0.1
• For argument P
′
2
:
Sim(P
′
2
,P
2
)
degree=0
= 1−
0.2−0
1−0
= 0.8
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
140

Sim(P
′
2
,P
2
)
degree=1
=
= sim
{−P
′
1
,−P
′
3
},{−P
1
,−P
3
}
= sim
{−0.9, −0.8}, { −1,−1}
= 0.85
• For argument P
′
3
:
Sim(P
′
3
,P
2
)
degree=0
= 1−
0.8−0
1−0
= 0.2
Sim(P
′
3
,P
2
)
degree=1
= sim
{−P
′
2
},{−P
1
,−P
3
}
= sim
{−0.2},{−1, − 1}
= 0.1
The above reveal that P
′
2
is identical to P
2
, given
that our threshold is equal to or higher than 0.8, while
arguments P
′
1
and P
′
3
have value lower than 0.2 for
every degree.
This argumentation sequence can be subject of
further exploitation: one may choose to filter out ev-
ery argumentation sequence marked as defeated ar-
gument; more generally speaking argumentation se-
quences can be highlighted as indicators for further
processing. A similar rule may be applied for ”well-
supported arguments”. Furthermore, due to the fact
that the proposed model matches similar and not iden-
tical structures, it is clear that training the model with
an additional small set of sequences can cover even
the most complex structures.
It is worth noting that our example was based on
the definition of the rating attribute. Further attributes
(or even a set of relevant attributes) can be used to
identify similar sequences. The only prerequisite is to
define the node similarity function for degree of value
0. Representative attributes that can be also taken into
account are:
• Authorship. Our model keeps track of argument
creators. The function for calculating similarity
for degree of value 0 returns 0 for same names
and 1 for different names. A more sophisticated
way to find relevant sequences given that our sys-
tem supports user profiling and clustering could
be to define the similarity function so that it re-
turns the similarity value between user profiles.
Using authorship enables to allow searching for
argumentation sequences where ”user x defeats
user y while user z defeats user x”, or where ”peo-
ple with opposite/similar profiles dispute in this
community”.
• Creation Date. In this case, the similarity func-
tion returns the time distance between two differ-
ent arguments. Using creation date, we can find
sequences where ”an argument has been asserted
after time instance x and was defeated after a pe-
riod of time y”.
• Element Type. Even though most argumentation
support systems are based on the IBIS-like model,
it is very common that their model can use dif-
ferent terminology. Our reasoning model can be
configured to take into account the associated ar-
gument types. Thus, the similarity function for
degree value 0 will return 1 if the element type
is the desired one or 0 if it is not. For example,
it is possible to define an argumentation sequence
as inconsistency if an element of type ”idea” is
opposed to an argument, or detect arguments that
defy first-order logic. Exploiting the element type
in similarity measurements can be a very useful
technique to identify dialogue inconsistencies or
setting ad-hoc new rules.
3.2 Case 2: Extracting Unnoticed
Sequences
In this case, we assume that many discussions have al-
ready taken place. Similarly to case-based reasoning
(more specifically, analogy-based reasoning (Aamodt
and Plaza, 1994)), where the system tries to re-use
existing similar argumentation situations, our model
will be used to mine unnoticed argumentation se-
quences. In order to achieve the above, the model
is going to search for structural similarity of every ar-
gument in any dialogue against any other argument.
From a technological point of view, this is a time-
consuming process, which can be handled by modern
computer technology (e.g. cloud computing, where
splitting the process into tasks can be parallelized and
run periodically).
The attempt to identify structural similarities of
every argument against another argumentin a big cor-
pus of argumentative dialogues is expected to return
a large number of similarities. In order to present
valuable information to the user, a ranking of these
results is needed. The criteria for ranking similar ar-
gumentation sequences are the degree of the similar-
ity, the number of occurrences and some user pref-
erences. More specifically, argumentation sequences
with higher degree and/or more occurrences will have
higher ranking and will therefore be promoted, since
it is rational to expect from them to carry more valu-
able information. User preferences may include one
or more attributes (see previous case) that the user
wants to take into account while mining for argumen-
tation sequences.
Mining argumentation sequences in an argumen-
tation corpus is a procedure that can be especially
valuable for newcomers and users with low partici-
ON THE EXPLORATION AND EXPLOITATION OF STRUCTURAL SIMILARITIES IN ARGUMENTATIVE
DISCOURSES
141

pation activity. Users with low experience in an on-
line community have difficulties in getting socially
attached to already existing users. One of the pri-
mary reasons for this is the fact that once they enter
the community, they are called to catch up with dis-
courses that have already occurred and analyze user
behavior. This cultivates a sense of being left behind,
since the online community already carries a lot of
collective experience, knowledge and social interac-
tion. Our model assists users identify relationships
that have come up already in this community, since it
highlights sequences that have appeared elsewhere.
4 RELATED WORK
On the broad field of collaboration support systems,
several models that quantify participation and interac-
tion have been already proposed. For instance, OCAF
(Avouris et al., 2002) follows a generic diagrammatic
collaborative model and introduces terms like den-
sity and degree of participation as metrics that quan-
tify group participaton. CAF (Fesakis et al., 2003)
is a model that can be applied in synchronous com-
munication, providing teachers with a mechanism for
tracking information about the collaboration. Kalei-
doscope (Dimitrakopoulou et al., 2006) attempts to
quantify several aspects of learning activities, through
the exploitation of social networking analysis tech-
niques like the measurement of activity level, net-
work density and centrality in order to provide social
awareness about actors. Even though the above sys-
tems are inspired by common ideas with our model,
they differentiate in the fact that their approach does
not take advantage of the structural dimension in in-
formation flow, and more specifically, of the argu-
mentation sequences.
On the field of argumentation, Belvedere (Suthers
et al., 1995) adopts a diagrammatic visual represen-
tation with special notation, to assist students iden-
tify the overall structure of arguments. Araucaria in-
troduces the notion of argumentation scheme, to re-
fer to ”stereotypical patterns of nondeductive reason-
ing” (Reed and Rowe, 2004) that allow the description
of argumentation components. Moreover, both Com-
pendium (Selvin et al., 2001) and CoPe It! (Karacapi-
lidis et al., 2009) allow users to organize sets of argu-
ments in higher structures (maps and adornments, re-
spectively). In summary, several argumentation sup-
port systems have attended the need of providing ab-
stractions and mechanisms for an argumentative dis-
course; nevertheless, none has presented mechanisms
that allow the computational processing of argument
aggregations.
5 DISCUSSION
We have presented a generic computational model,
that is able to identify and assess structure similarities
in argumentation-based discourses. Through the de-
duction of discourses as graphs, the model establishes
a way to represent diverse and meaningful argumen-
tation sequences in a generic, flexible and quantified
way. In this section, we discuss the benefits of our
approach, focusing on how the proposed model may
affect the system performance from a user perspec-
tive.
As stated above, argumentation sequence is an ab-
straction that can aggregate discourse parts and be
exploited in several ways. First, a set of argumenta-
tion sequences can be defined to represent meaning-
ful (and well-known) reasoning patterns. The above
set of sequences can act as a training dataset that
will assist users during the analysis of a discourse
and provide them with hints about parts of the dis-
course. This set of sequences can grow by users
through the addition of new sequences found in a dis-
course or can be personalized according to specific
user needs. In such a way, discourses can be repre-
sented in a more abstract way and their analysis is fa-
cilitated. Moreover, notification mechanisms can be
integrated to help users keep track of changes in dis-
courses. For example, an argumentation support sys-
tem that adopts the proposed model can inform a user
that his argument has been defeated, accepted, or even
that a new alternative appears as a leading candidate.
Finally, argumentation sequences can be exploited in
queries such as ”show me sequences where users A,
B, C attempt and fail to defeat user D’s contributions”.
We have also described how our model can be
used to extract unnoticed argumentation sequences.
Similarly to data mining, this functionality can result
to the acquisition of useful information that in most
cases would havepassed unnoticed. In that way, states
of passiveness and quiescence that are commonly met
in online communitiescan be significantly eliminated.
Moreover, our model can help discussion moderators
or community leaders identify meaningful patterns of
communication. For example, it can detect that one or
more users have constant disputes with another group
of users or that certain dialogues tend to develop in
never-ending conflicts. In this case, community lead-
ers can choose to get notified for such behaviors, so
that they can take appropriate actions against them.
Thus, they will be able to act preemptively in favor of
the community.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
142

6 CONCLUSIONS
Engaging in online argumentative discourses is a
complex and challenging task. Amongst other re-
quirements, users have to surpass social and techno-
logical barriers in order to process and evaluate infor-
mation provided by their peers. We argue that con-
temporary argumentation support systems pay little
attention to the above. Motivated by the fact that
argumentation sequences can aggregate arguments
into entities of higher meaning, we have presented a
generic but flexible model that is capable of discov-
ering and assessing similar argumentation sequences.
We argue that this model is of considerable contribu-
tion to both theoretical and practical aspects of argu-
mentation.
As a a note for further study it is worth investi-
gating whether mining argumentation sequences may
improve the performance of relevant features in an ar-
gumentation support system, like user profiling, rat-
ing, social network analysis and decision support al-
gorithms.
REFERENCES
Aamodt, A. and Plaza, E. (1994). Case-based reasoning.
Proc. MLnet Summer School on Machine Learning
and Knowledge Acquisition, pages 1–58.
Avouris, N., Dimtracopoulou, A., Komis, V., and Fidas, C.
(2002). OCAF: An object-oriented model of analysis
of collaborative problem solving. Computer Support
for Collaboratie Learning: Foundations for A Cscl
Community (cscl 2002 Proceedings), page 92.
Baker, M. (1999). Argumentation and constructive inter-
action. Foundations of argumentative text processing,
pages 179–202.
Caminada, M. and Amgoud, L. (2007). On the evaluation
of argumentation formalisms. Artificial Intelligence,
171(5-6):286–310.
Dimitrakopoulou, A., Petrou, A., Martinez, A., Marcos, J.,
Kollias, V., Jermann, P., Harrer, A., Dimitriadis, Y.,
and Bollen, L. (2006). State of the art of interaction
analysis for Metacognitive Support & Diagnosis. In-
teraction Analaysis (IA) JEIRP Deliverable D.31.1.1.
Eemeren, F. H. V., Grootendorst, R., Jackson, S., and
Jacobs, S. (1993). Reconstructing Argumentative
Discourse (Studies in Rhetoric and Communication).
University of Alabama Press.
Fesakis, G., Petrou, A., and Dimitracopoulou, A. (2003).
Collaboration activity function: an interaction anal-
ysis tool for computer supported collaborative learn-
ing activities. In 4th IEEE International Conference
on Advanced Learning Technologies (ICALT 2004),
pages 196–200.
Hay, M., Miklau, G., Jensen, D., Towsley, D., and Weis,
P. (2008). Resisting structural re-identification in
anonymized social networks. Proceedings of the
VLDB Endowment archive, 1(1):102–114.
Hopcroft, J. and Karp, R. (1973). An n
5/2
Algorithm for
Maximum Matchings in Bipartite Graphs. SIAM Jour-
nal on Computing, 2:225.
Johnson, C. (2001). A survey of current research on on-
line communities of practice. The internet and higher
education, 4(1):45–60.
Jonas, E., Schulz-Hardt, S., Frey, D., and Thelen, N. (2001).
Confirmation bias in sequential information search af-
ter preliminary decisions: An expansion of dissonance
theoretical research on selective exposure to informa-
tion. Journal of Personality and Social Psychology,
80(4):557–571.
Karacapilidis, N., Tzagarakis, M., Karousos, N., Gkotsis,
G., Kallistros, V., Christodoulou, S., Mettouris, C.,
and Nousia, N. (2009). Tackling cognitively-complex
collaboration with cope it! International Journal
of Web-Based Learning and Teaching Technologies,
4(3):22–38.
Kuhn, D. (1991). The skills of argument. Cambridge Univ
Pr.
Reed, C. and Rowe, G. (2004). Araucaria: Software for
argument analysis, diagramming and representation.
International Journal of AI Tools, 14(3-4):961–980.
Rees, M. (1995). Analysing and evaluating problem-
solving discussions. Argumentation, 9(2):343–362.
Selvin, A., Buckingham Shum, S., Sierhuis, M., Conklin,
J., Zimmermann, B., Palus, C., Drath, W., Horth, D.,
Domingue, J., Motta, E., et al. (2001). Compendium:
Making meetings into knowledge events. In Knowl-
edge Technologies, volume 2001. Citeseer.
Shum, B. et al. (2008). Cohere: Towards Web 2.0 Argu-
mentation. In Proceeding of the 2008 conference on
Computational Models of Argument: Proceedings of
COMMA 2008, pages 97–108. IOS Press.
Suthers, D., Weiner, A., Connelly, J., and Paolucci, M.
(1995). Belvedere: Engaging students in critical dis-
cussion of science and public policy issues. In Pro-
ceedings of AI-Ed, volume 95, pages 266–273. Cite-
seer.
Toulmin, S. (1958). The uses of argument. Cambridge Uni-
versity Press.
Weinberger, A. and Fischer, F. (2006). A framework
to analyze argumentative knowledge construction in
computer-supported collaborative learning. Comput-
ers & Education, 46(1):71–95.
ON THE EXPLORATION AND EXPLOITATION OF STRUCTURAL SIMILARITIES IN ARGUMENTATIVE
DISCOURSES
143
