
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION
PROCESSING IN MOBILE AD-HOC NETWORKS
Sebastian Obermeier
1
and Stefan Böttcher
2
1
ABB Corporate Research, Segelhofstr 1K, 5405 Baden Daettwil, Switzerland
2
University of Paderborn, Fürstenallee 11, 33102 Paderborn, Germany
Keywords:
Mobile databases, Mobile transaction processing, Bi-state-termination.
Abstract:
Whenever business transactions involve databases located on different mobile devices in a mobile ad-hoc net-
work, transaction processing should guarantee the following: atomic commitment and isolation of distributed
transactions and data consisteny across different mobile devices. However, a major problem of distributed
atomic commit protocols in mobile network scenarios is infinite transaction blocking, which occurs when a
local sub-transaction that has voted for commit cannot be completed due to the loss of commit messages and
due to network partitioning. For such scenarios, Bi-State-Termination has been recently suggested to termi-
nate pending and blocked transactions, which allows to overcome the infinite locking problem. However, if
the data distributed on different mobile devices has to be consistent according to some local or global database
consistency constraints, Bi-State-Termination has not been able to check for the validity of these consistency
constraints on a database state involving the data of different mobile devices.
Within this paper, we extend the concept of Bi-State-Termination to arbitrary read operations. We show how
to handle several types of database consistency constraints, and experimentally evaluate our constraint checker
using the TPC-C benchmark.
1 INTRODUCTION
With increasing capabilities regarding processing
power and connectivity of mobile devices and a grow-
ing interest in mobile ad-hoc networks, the combina-
tion of database technology with mobile devices be-
comes an interesting and important challenge. We
consider an ad-hoc network of mobile devices, each
of which equipped with a local database. Within this
network, distributed transactions should be processed
and executed in an atomic fashion.
1.1 Problem Description
Whenever distributed databases must be accessed and
all of their operations must be executed or none of
them, traditional transaction processing would em-
ploy atomic commit protocols (ACPs) like 2-Phase-
Commit (2PC, (Gray, 1978)(Reddy and Kitsuregawa,
2003)), 3-Phase-Commit (3PC, (Skeen, 1981)), or
consensus based protocols (Paxos Consensus, (Gray
and Lamport, 2006)) to guarantee the atomicity of dis-
tributed transactions. However, during the execution
of an atomic commit protocol, each device suffers
from transaction blocking:
Definition 1. A transaction T is blocked, after a
database proposed to execute T (e.g. by sending a
voteCommit message) and waits for the final commit
decision, but is not allowed to abort or commit T uni-
laterally on its own.
Note that transaction blocking summarizes the
unilateral impossibility of a database to commit or
abort a transaction, but does not mean that a trans-
action U waits to obtain locks held by a concurrent
transaction T , since in this case U can be aborted by
the database itself.
Even time-out based approaches (e.g. “my com-
mit vote is valid until 3:23:34”) cannot solve the prob-
lem of transaction blocking, since this would fulfill
the requirements of the coordinated attack scenario
(Gray, 1978), in which a commit decision is not pos-
sible under the assumption of message loss.
The problem of infinite transaction blocking for
a transaction T occurs, if a local database has sent
a voteCommit message on T , but will never receive
the final commit decision, e.g. due to disconnection,
movement, or network partitioning. Whenever such a
166
Obermeier S. and Böttcher S. (2010).
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC NETWORKS.
In Proceedings of the 12th International Conference on Enterprise Information Systems - Databases and Information Systems Integration, pages
166-175
DOI: 10.5220/0002889301660175
Copyright
c
SciTePress

database is able to communicate, e.g. with the user,
the blocked data of T will prevent concurrent and con-
flicting transactions U from being processed.
Bi-State-Termination (Obermeier and Böttcher,
2007) has been suggested to overcome the infinite
transaction blocking problem by obeying both out-
comes – commit and abort – of the distributed trans-
action. Note that Bi-State-Termination is optional
for pending transactions; the database can choose for
each transaction whether to wait as yet, or to use Bi-
State-Termination, which is a promising approach in
case the pending transaction modifies only a small set
of data tuples.
However, when consistency constraints are im-
posed to the database, traditional consistency checks
cannot be applied as the current database state is un-
clear.
1.2 Contributions
This paper extends the technique of Bi-State-
Termination (BST) (Obermeier and Böttcher, 2007), a
transaction termination mechanism for mobile trans-
actions in unreliable environments that solves the in-
finite transaction blocking problem. Beyond the pre-
vious publication on BST (Obermeier and Böttcher,
2007), this paper further
• extends the BST concept to define and check con-
sistency constraints.
• describes how insert, update, delete, commit and
abort operations and arbitrary relational algebra
queries as set union, projection, cartesian product,
and set difference can be performed on the BST
implementation by introducing a query rewrite
system.
• shows experimental results comparing the per-
formance of different implementations of consis-
tency checks using a modified TPC-C benchmark.
2 BST MODEL
Bi-State-Termination is based on the following ob-
servation: whenever transaction blocking occurs, the
database does not know whether a transaction T wait-
ing for the commit decision will be aborted or com-
mitted. However, only if the transaction is commit-
ted, the database state changes. Let S
0
denote the
database state before T was executed. Although the
database does not know the commit decision for T ,
it knows that depending on the commitment of T , ei-
ther S
0
or S
T
:= T (S
0
), i.e. the state reached when
T is applied to S
0
, is the correct database state. With
this knowledge, the database can try to execute a con-
current conflicting transaction U on both states S
0
and S
T
. Whenever the two executions of U on S
0
and on S
T
return the same results to the Initiator, i.e.
Result
U
(S
0
) = Result
U
(S
T
), U can be committed re-
gardless of T , even though they are conflicting. Oth-
erwise it is the application’s choice whether it handles
two possible transaction results.
2.1 Bi-state-termination
Let Σ = {S
0
,... ,S
k
} be the set of all legal possible
database states for a database D. A traditional trans-
action T is a function T : Σ 7→ Σ, S
a
→ S
b
, which
means the resulting state S
b
of T depends only on the
state S
a
on which T is executed on.
A Bi-State-Terminated transaction T is a function
BST : 2
Σ
7→ 2
Σ
,
{S
i
,. .. ,S
j
}
| {z }
Initial States
→ {S
i
,. .. ,S
j
}
| {z }
T aborts
∪{T (S
i
),. .. ,T (S
j
)}
| {z }
T commits
that maps a set Σ
Initial
⊆ Σ of Initial States to a
super set Σ
Initial
∪ {T(S
x
)|S
x
∈ Σ
Initial
} of new states,
where T (S
x
) is the state that is reached when T is ap-
plied to S
x
.
3 BST REWRITE RULES
Whether or not some tuples finally belong to a
database relation depends on conditions, i.e. on the
commit or abort decisions of pending transactions.
In contrast to (Obermeier and Böttcher, 2007), our
new BST rewrite system extends each database rela-
tion with a single extra column Conditions to store
these conditions, and rewrites all queries, write oper-
ations, integrity constraint checks and data definition
statements in such a way that they reflect these con-
ditions. Furthermore, we add a single table Rules to
the database that contains rules that relate these con-
ditions to each other. BST is implemented by the fol-
lowing rewrite rules.
3.1 Creating Database Tables
The “create table” command for database relations is
modified by the following rewrite rule:
create table R ( <column definitions> )
⇒ create table R’( <column definitions, string condi-
tions>)
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC
NETWORKS
167

3.2 Status without Active Transactions
When all transactions are completed either by com-
mit or by abort, the column “Conditions” contains the
truth value “true” for each tuple in each relation of
the database. The truth value “true” represents the
fact that the tuple belongs to the relation without any
further condition on the commit status of an active
transaction.
3.3 Write Operations on the BST Model
Each time a write operation must be executed, it is
rewritten according to the following rules.
3.3.1 Insertion
Whenever a tuple t = (value
1
,. .. ,value
N
) is inserted
into a relation R by a transaction with transaction
identifier T
i
, we implement this by inserting t
0
=
(value
1
,. .. ,value
N
,T
i
) into the relation R
0
, i.e. the
database system implementation applies a rewrite
rule:
insert into R values (value
1
,...,value
N
)
⇒ insert into R’ values (value
1
,...,value
N
, T
i
).
The idea behind the value T
i
stored in the condi-
tion column of R
0
is to show that the tuple t belongs
to the database relation R if and only if transaction T
i
will be committed.
3.3.2 Deletion
Whenever a tuple t = (value
1
,. .. ,value
N
) is deleted
from a relation R by a transaction with trans-
action identifier T
i
, we look up the tuple t
0
=
(value
1
,. .. ,value
N
,C) ∈ R
0
representing the tuple t ∈
R, where C is the condition under which t belongs to
the database relation R.
We implement the deletion of t from R by the
transaction T
i
by replacing the condition C found in
t
0
with a condition C
2
and by adding a logical rule to
the table Rules stating that C
2
is true if and only if C is
true and T
i
is aborted. For this purpose, the database
system applies the following rewrite rule, where
A
1
,. .. ,A
N
denote the values (value
1
,. .. ,value
N
) for
the attributes of R:
delete t from R where t.A
1
=value
1
,.. .,t.A
N
=value
N
⇒ update t’ in R’ where t.A
1
=value
1
,.. .,t.A
N
=value
N
set
condition=C
2
;
insert into Rules values ( C
2
, C
1
and not T
i
)
The idea behind this rewriting is the follow-
ing. (not T
i
) represents the condition that transac-
tion T
i
will be aborted. The inserted rule states
that C
2
is true if C
1
is true and T
i
will be aborted.
After the update operation, we have a tuple t
0
=
(value
1
,. .. ,value
N
,C
2
) in R
0
which represents the
fact that t belongs to R if and only if C
2
is true, i.e.
if C
1
is true and T
i
is aborted.
3.3.3 Update
An update of a single tuple is simply executed as a
delete operation followed by an insert operation.
3.3.4 Set-oriented Write Operations
When a transaction inserts, updates, or deletes multi-
ple tuples within a single operation, this can be imple-
mented by a set of individual insert, update, or delete
operations.
3.3.5 Completion of a Transaction
When transaction T
i
is completed with commit, the
condition T
i
is replaced with true in each rule in the
Rules table and in each value found in the column
“Conditions” of a relation R
0
. However, when T
i
is
completed with abort, T
i
is replaced with false in each
rule found in the Rules table, and each tuple of R
0
containing the value T
i
in the column “Conditions” is
deleted.
Furthermore, rules that contain the truth value
true or false are simplified. Whenever this results in
a rule (C, true) or in a rule (C, false), then C itself is
replaced with the value “true” or “false” respectively.
Other rules that contain C are simplified as well.
Furthermore, all tuples t
0
in which C occurs are
treated as follows. If the rule is (C, true), the value
C is replaced with true in each tuple t
0
in which C
occurs in the column “Conditions”. However, if the
rule is (C, false), each tuple t
0
in which C occurs in
the column “Conditions” is deleted. Finally, rules (C,
true) or (C, false) are deleted from the relation Rules.
Example 1. Consider a database that executes
the following transactions on a relation R that only
consists of the attribute “Name” in the sequence
T
1
< T
2
< T
3
:
T
1
: insert "Miller"
T
2
: delete "Mitch"
T
3
: change "M" to "R" in each name
Line 1 of Table 1 represents the initial database
state S
0
of R
0
, lines 2-3 show the content of R
0
after
BST of T
1
, lines 4-5 represent the table content after
BST of T
1
and T
2
, while lines 6-9 show the table after
BST of T
1
,T
2
, and T
3
. The conditions C
i
in the col-
umn “Condition” of Table 1 are linked to the “Rules”
column of Table 2. Table 2 defines for each condition
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
168

Table 1: Content after Bi-State-Terminating T
1
, T
2
, and T
3
.
Line Name Condition Comment
1 Mitch Initial
2 Mitch
Content after BST
of T
1
3 Miller C
1
4 Mitch C
2
Content after BST
of T
1
,T
2
5 Miller C
1
6 Mitch C
3
Content after BST
of T
1
,T
2
,T
3
7 Miller C
4
8 Ritch C
5
9 Riller C
6
C
i
by a boolean formula composed of other conditions
and/or elementary conditions T
j
, T
k
, where T
j
in the
column “Definition” of Table 2 represents that trans-
action T
j
will commit and T
k
represents that T
k
will
abort. When C
i
is valid, the row (<t>, C
i
) of Table 1
represents that the tuple <t> is in R. The condition
C
4
, for example, is fulfilled when T
1
commits and T
3
aborts. In this case, line 7 of Table 1 becomes valid.
Table 2: Rules Table after Bi-State-Terminating T
1
, T
2
, and
T
3
.
Condition Definition Comment
– – Initial
C
1
T
1
Content after BST of T
1
C
1
T
1
Content after BST
of T
1
,T
2
C
2
T
2
C
3
T
2
T
3
Content after BST
of T
1
,T
2
,T
3
C
4
T
1
T
3
C
5
T
2
T
3
C
6
T
1
T
3
3.4 Read Operations on the BST Model
Whenever a read operation on R is implemented by a
read operation on R
0
, the conditions are kept as part
of the result. The relational algebra operations are
implemented as follows.
3.4.1 Selection
Each selection with selection condition SC that a
query applies to a relation R, will be applied to R
0
,
i.e. the database system applies the following rewrite
rule to each selection:
SC(R) ⇒ SC(R’)
3.4.2 Duplicate Elimination
Duplicate elimination is an operation that is used to
implement projection and union. When duplicates
occur, their conditions are combined with the logi-
cal OR operator. That is, given the relation R
0
con-
tains two tuples t
0
1
= (value
1
,. .. , value
N
, C
1
) and t
0
2
=
(value
1
,. .. ,value
N
,C
2
) these two tuples are deleted
and a single tuple t
0
= (value
1
,. .. ,value
N
, C
C12
) is
inserted into R, and a rule (C
C12
,C
1
or C
2
) is inserted
into the Rules table.
3.4.3 Set Union
Set union of two relations R
1
and R
2
is implemented
by applying duplicate elimination to the set union of
R
0
1
and R
0
2
. The database system applies the following
rewrite rule:
R
1
∪ R
2
⇒ removeDuplicates(R
1
’ ∪ R
2
’)
3.4.4 Projection
Projection of a relation R
1
on its attributes A
1
,. .. ,A
N
is implemented by applying duplicate elimination to
the result of applying the projection to R
0
1
including
the column “Conditions”. The database system ap-
plies the following rewrite rule:
P(A
1
,.. .,A
n
) (R
1
) ⇒ removeDuplicates(P(A
1
,.. .,A
n
, con-
ditions) (R
0
1
))
3.4.5 Cartesian Product
Whenever the cartesian product R
1
× R
2
of two re-
lations R
1
and R
2
must be computed, this is im-
plemented using R
0
1
and R
0
2
as follows. For each
pair (t
0
1
,t
0
2
) of tuples t
0
1
= (value
1
,. .. ,value
N
,C
1
) of
R
0
1
and t
0
1
=(value2
1
,. .. ,value2
N
, C
2
) of R
0
2
, a tuple
t
0
12
= (value
1
,. .. ,value
N
,value2
1
,. .. , value2
N
,C
C12
)
is constructed and stored in (R
1
× R
2
)
0
. The database
system applies the following rewrite rule:
R
1
× R
2
⇒ (R
1
× R
2
)’
where (R
1
× R
2
)’ can be derived by computing the set
{ (t
1
,t
2
,C
C12
) | (t
1
,C
1
) ∈ R
1
’ and (t
2
,C
2
) ∈ R
2
’ }
and by adding a rule ( C
C12
, C
1
and C
2
) for each pair of
C
1
and C
2
to the Rules table.
3.4.6 Set Difference
Whenever the set difference R
1
− R
2
of two rela-
tions R
1
and R
2
must be computed, this is imple-
mented using R
0
1
and R
0
2
as follows. The set difference
contains all tuples t
0
1
= (value
1
,. .. ,value
N
,C
1
) of
R
0
1
for which no tuple t
0
2
= (value2
1
,. .. ,value2
N
,C
2
)
of R
0
2
exists, and furthermore, it contains a tuple
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC
NETWORKS
169

t
0
12
= (value
1
,. .. ,value
N
,C
C12
) for each tuple t
0
1
=
(value
1
,. .. ,value
N
,C
1
) of R
0
1
for which a tuple t
0
2
=
(value2
1
,.. ., value2
N
,C
2
), C
2
6= C
1
, of R
0
2
exists. The
condition C
C12
is true if and only if (C
1
and not C
2
)
is true. The database system applies the following
rewrite rule:
R
1
- R
2
⇒ R
1
’ - R
2
’
where ( R
1
’ - R
2
’ ) can be derived by computing the union
of the following sets S
1
and S
2
:
S
1
= { (t
1
,C
1
) | exists (t
1
,C
1
) ∈ R
1
’ and not exists C
2
such
that (t
1
,C
2
)∈ R
2
’ }
S
2
= { (t
1
,C
C34
) | exists (t
1
,C
3
)∈ R
1
’ and exists (t
1
, C
4
)∈
R
2
’ such that C
3
6= C
4
}
and by adding a rule (C
C34
, C
3
and not C
4
) for each pair
of C
3
and C
4
used in S
2
to the Rules table.
3.4.7 Other Algebra Operations
Other operations of the relational algebra like join, in-
tersection, etc. can be constructed by combining the
implementation of the basic operations. Query opti-
mization of operations like join etc. is also possible.
4 DATABASE CONSTRAINTS
We explain how the following types of database con-
straints are checked for a transaction T
check
on a
database that uses Bi-State-Termination. We assume
that the database is in consistent state before T
check
has been executed, thus only the effects of T
check
can
violate the database’s consistency.
4.1 Domain Constraints
Domain constraints restrict attribute values to a given
set. These constraints can be tested on each tuple in-
dividually.
Example 2. A flight booking can only reserve a pos-
itive, integer number of seats.
4.1.1 BST Check
Whenever a database contains Bi-State-Terminated
transactions, the following steps are required in order
to check that each given domain constraint D
c
holds:
D
c
is checked for only those tuples that have been
inserted by T
check
, i.e. tuples that are associated with a
condition C
i
that contains the string T
check
in its defi-
nition. Tuples that are going to be deleted do not need
to be checked since they already exist in the (con-
sistent) database, thus their validity regarding D
c
has
been checked before.
4.2 Referential Integrity
Let R and S be database realtions, and let R
i
be a ref-
erential integrity constraint R
i
of the following form.
R
i
:= ∀x ∈R ∃y∈S : (x.a
1
= y.a
1
∧ ... ∧ x.a
n
= y.a
n
)
Then, our algorithm first eliminates all duplicates
by using the removeDuplicates() function explained
in Section 3.4.2 on a projection of the attributes
a
1
,. .. ,a
n
and the condition attribute C.:
R
0
:= removeDuplicates(Π
a
1
,...,a
n
,C
(R))
S
0
:= removeDuplicates(Π
a
1
,...,a
n
,C
(S))
Thereafter, the following two sets are computed:
RICheck
1
:= {(C
1
)|(t
1
,C
1
) ∈ R
0
∧ (t
1
,C
2
) /∈ S
0
∧ 6 ∃(t
1
,C
2
) ∈ S}
RICheck
2
:= {(C
1
∧
C
2
)|(t
1
,C
1
)∈R
0
∧ (t
2
,C
2
)∈S
0
∧t
1
.a
1
= t
2
.a
1
∧ ... ∧t
1
.a
n
= t
2
.a
n
}
Both sets RICheck
1
and RICheck
2
describe con-
ditions that are associated with tuples that violate the
referential integrity constraint if their conditions be-
come true. RICheck
1
consists of all conditions of tu-
ples that may be present in R
0
, but have no reference
in S
0
. RICheck
2
identifies tuples t
1
of R that are ref-
erencing tuples t
2
in S that contain a condition C
2
. In
this case, when t
1
becomes present in R and t
2
be-
comes invalid in S, the referential integrity constraint
would be violated. Thus, RICheck
2
is composed of
conditions that would violate the referential integrity
when they would be fulfilled.
After both sets have been computed, the union of
both set is checked for satisfiability:
∃c∈ {RICheck
1
∪ RICheck
2
}: c is satisfiable
⇔ check failed
When at least one condition in {RICheck
1
∪
RICheck
2
} is satisfiable, the referential consistency
constraint can be violated. Thus, the check must fail.
Otherwise, when the set does not contain any condi-
tion that is satisfiable, the referential consistency can-
not be violated by T
check
.
4.3 Functional Dependencies
Let R denote a relation and α and β be sets of at-
tributes in R. Further, let F
i
: α ⇒ β be a functional
dependency, i.e.,
F
i
:= ∀t
1
,t
2
∈R : (t
1
[α]=t
2
[α] ⇒ t
1
[β]=t
2
[β])
In order to check F
i
, we first eliminate all duplicates
by using the removeDuplicates() function:
R
0
:= removeDuplicates(Π
α,β,C
(R))
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
170

Further, let FDCheck denote the following set:
FDCheck := {(C
1
∧C
2
)|(t
1
,C
1
) ∈ R
0
∧ (t
2
,C
2
) ∈ R
0
∧t
1
[α] = t
2
[α] ∧t
1
[β] 6= t
2
[β]}
The set FDCheck comprises of conditions for tu-
ples that may violate the functional dependency when
their conditions become true, i.e. tuples that have the
same value for their α attributes but different values
for their β attributes.
Whenever a condition exists in FDCheck that may
be satisfiable, the functional dependency may get vi-
olated. Thus, the check of functional dependencies
must fail:
∃c∈ {FDCheck}: c is satisfiable ⇔ check failed
4.4 Multiple Tuple Constraints
A different type of constraints are multiple tuple con-
straints (MTC) that apply to a set of tuples. Thus, an
MTC check comprises several or all tuples of a rela-
tion and cannot be checked individually for each data
tuple instead. We focus on a constraint that defines
a limit on the sum of attribute values of a given at-
tribute of a relation. These types of constraints are
practically relevant, e.g. for specifying a maximum
amount of seats, a limit on bank account transfers, or
a maximum number of costs.
4.4.1 BST Check
As with other integrity constraints, we allow a trans-
action T
check
that has inserted or deleted tuples from a
relation R for which an MTC exists to vote for com-
mit only if we can guarantee that the MTC evaluates
to true independent of the commit decisions of the Bi-
State-terminated transactions. A principal way to test
this is the following check based on combinations of
transaction decision and on combinations of tuples vi-
olating a constraint.
All combinations of transaction IDs that occur in
the Conditions definition of R are computed, and all
possible combinations of transaction decisions “com-
mit” and “abort” of these transactions are created.
This number grows exponentially in the number of
Bi-State-Terminated transactions. Each combination
of tuples that violates the MTC is checked for satis-
fiability of the combination of conditions. Whenever
each tuple combination violating the constraint has an
insatisfiable combination of transaction decisions, the
MTC cannot be violated. Otherwise, T
check
must be
aborted.
As the number of combinations and checks grows
exponentially, we present two optimizations for the
MTC check.
4.4.2 Bounded MTC Check
We check a worst case approximation of the MTC,
called Bounded MTC Check instead of checking MTC
itself on all combinations of commit decisions of Bi-
State terminated transactions. Whenever an MTC has
the form
∑
attribute
1
< x, i.e. the sum of all attribute
values must not be greater than or equal to x, the
bounded MTC check optimizes the check as follows:
Only those values v of the attribute
1
are summed up
that are greater than 0, regardless of their associated
condition.
Whenever the sum exceeds x, there may be a vio-
lation of the MTC and the check fails. This check cor-
responds to the worst-case scenario for the inequal-
ity constraint, where all transactions that add nega-
tive values abort, and all transactions that add positive
values commit. If even this worst-case scenario does
not violate the inequality constraint, the transaction
results in a valid database state and the voteCommit
can be sent.
Whenever an MTC has the form
∑
attribute
2
> x,
i.e. the sum of all attribute values must not be smaller
than or equal to x, the bounded MTC check opti-
mizes the check as follows: Only those values v of the
attribute
2
are summed up that are smaller than 0, re-
gardless of their associated condition. Whenever the
sum is equal to or less than x, there may be a viola-
tion of the MTC and the check fails. This check cor-
responds to the worst-case scenario for the inequal-
ity constraint, where all transactions that add positive
values abort, and all transactions that add negative
values commit.
However, the bounded MTC check can lead to
false positives as a failure of the bounded MTC
check includes impossible combinations of values and
commit decisions of transaction that can violate the
bounded MTC.
Therefore, this check is extremely fast (only one
summation), but may produce unnecessary aborts.
4.4.3 Optimized MTC Check
The optimized MTC check combines the bounded
MTC check with the regular check. For all values
except the n greatest values, the sum is calculated ac-
cording to the bounded MTC check. Then, n+1 com-
binations of the greatest values and the bounded MTC
sum are evaluated regarding their satisfiability.
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC
NETWORKS
171

5 EXPERIMENTAL EVALUATION
We have evaluated the runtime for the consistency
checks explained in Section 4 depending on the
number of Bi-State-Terminated transactions. We
have used a modified version of the online trans-
action processing benchmark TPC-C (Kohler et al.,
1991), which contains additional consistency con-
straints. The TPC-C simulates an online-shop-like en-
vironment in which users execute order transactions
against a database. The transactions additionally in-
clude recording payments, checking the status of or-
ders, and monitoring the level of stock at the ware-
houses. Each TPC-C run consists of 1,000 transac-
tions. In order to simulate Bi-State-Termination with
n pending transactions, we delayed the outcome of
the atomic commit protocol for n Bi-State-Terminated
transactions, such that the n transactions are Bi-State-
Terminated. During the simulation, the number of Bi-
State-Terminated transactions remains constant, but
the transactions itself vary. For our measurements, we
have repeated each simulation run 10 times and mea-
sured the time that was needed for each consistency
check.
Furthermore, we have implemented two versions,
called internal and external implementation, of the
consistency checking algorithms. The external imple-
mentation uses a separate definition table where the
conditions under which each row becomes valid are
stored.
The internal implementation does not use a sep-
arate condition definition table anymore. Instead, it
directly adds the condition’s definition to each data
row. Thus, conditions need not be derived from the
separate Conditions table, instead each tuple contains
its conditions within the “Condition” column of the
relation. Thus, Rules table lookups to derive the con-
ditions under which a tuple becomes valid become su-
perfluous in the internal implementation. This speeds
up write operations that operate on many tuples for
the following reason: The database does not need to
generate and associate unique Condition IDs to re-
placed conditions, instead it can update the “Condi-
tion” column in one pass by concatenating its value
with the transaction ID.
Figure 1 shows the experimental results for do-
main constraints. The x−axis indicates whether the
test run was done with the internal implementation
(“Int”), or with the external implementation (“Ext”).
Furthermore, the number n of Bi-Sate-Terminated
transactions is shown under each box. The y−axis
shows the running time in msec. As the time for a sin-
gle consistency check depends on the transaction, the
consistency definition, and the database state, we have
0
200
100
50
150
Runtime
Domain Constraints
Int 1 Int 4 Int 7 Ext 1 Ext 4
Ext 7
in msec
Figure 1: Domain constraint evaluation.
repeated our experiments 10 times and have used box
plots to display the range of the runtimes by boxes.
Each box consists of two horizontal lines indicating
the mininum and maximum value. These horizon-
tal lines are connected by a centered vertical line to
the box. The box comprises 50% of all values, in de-
tail it consists of all values within the second and the
third quartile. Thus, 25% of all values are smaller and
greater than the box, respectively.
A box plot gives an impression of how the values
are spread. For our TPC-C measurement, this allows
us to compare the runtimes for the internal and exter-
nal implementation, and the absolute runtime ranges
for the different types of consistency checks.
The box plot of Figure 1 shows that the aver-
age runtime of the domain constraint check is sig-
nificantly greater for the external implementation
than for the internal implementation. Furthermore,
the runtime increases with the number of Bi-State-
Terminated transactions.
0
1000
500
250
750
Functional Dependency
Int 1 Int 4 Int 7 Ext 1 Ext 4
Ext 7
Runtime
in msec
Figure 2: Functional dependency evaluation.
Figure 2 illustrates the runtimes for the func-
tional dependency checks. For this kind of consis-
tency check, the external implementation needs only
slightly more runtime than the internal implementa-
tion. However, the runtime of the functional depen-
dency check increases significantly with the number
of Bi-State-Terminated transactions, as the check con-
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
172
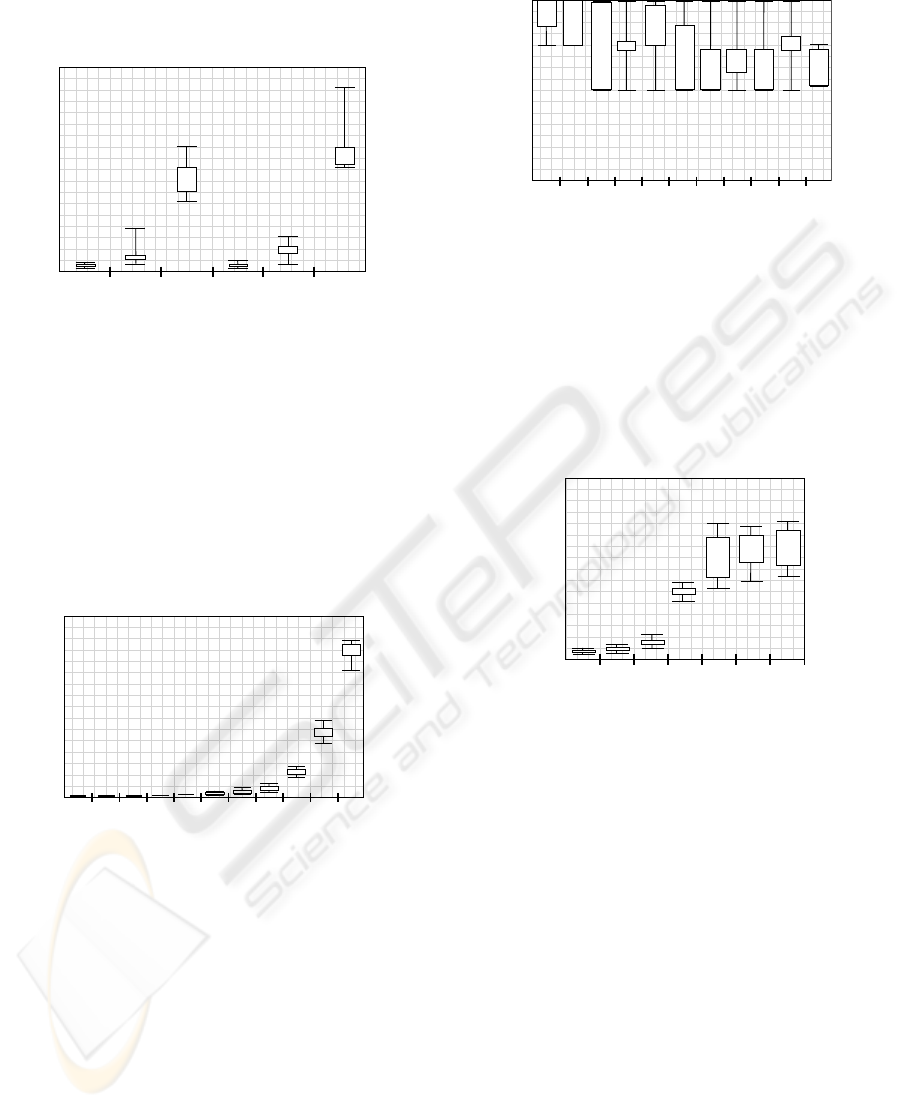
tains more value comparisons than the domain con-
straint check.
0
500
250
125
375
Referential Integrity
Int 1 Int 4 Int 7 Ext 1 Ext 4
Ext 7
Runtime
in msec
Figure 3: Referential integrity evaluation.
The referential integrity check experiments are vi-
sualized by Figure 3. Again, the internal implemen-
tation is slightly faster. Although the overall runtime
for this kind of test is smaller than for the functional
dependency check, the growth of runtime motivates
a restriction of the number of Bi-State-Terminated
transaction by the database. Instead of Bi-State-
Terminating a blocked transaction, the database can
wait and block resources as traditional transaction
processing does.
0
2000
1000
500
1500
Multiple Tuple Constraints (Internal)
1
2 3 4 5 6 7 8 9 10
11
Transactions
Runtime
in msec
Figure 4: MTC evaluation – internal implementation.
Figure 4 shows the results for the internal imple-
mentation of the MTC checks. As the external imple-
mentation shows almost the same behavior, we have
omitted to show these graphs. However, we have
extended the number of Bi-State-Terminated transac-
tions to 11, in order to show the exponential growth of
runtime. However, our boxes indicate nicely that the
time ranges in which the runtimes for each check fall
are quite small. This allows the database to get quite
exact estimations on the runtime of the consistency
checks, and thus allows using Bi-State-Termination
of a transaction as an option that can be chosen de-
pending on the current database load situation.
Figure 5 uses the same setup as the MTC experi-
ments shown by Figure 4, but uses the bounded MTC
0
4
2
1
3
Multiple Tuple Constraints (Bounded)
1
2 3 4 5 6 7 8 9 10
11
Transactions
Runtime
in msec
Figure 5: MTC evaluation – bounded optimization.
check instead. The runtime for this check is – in
theory – linear in the number of Bi-State-Terminated
transactions. However, as the bounded MTC check
requires only one additional operation per Bi-State-
Terminated transaction, our experiments show an al-
most constant runtime behavior.
0
200
100
300
Runtime
Multiple Tuple Constraints
1
2 4 8 16 32 64
Used Tuples for Optimization
in msec
(Optimized, Internal)
Figure 6: Optimized MTC evaluation for 8 Bi-state-
terminated transactions.
The optimized MTC check shown in Figure 6
shows results for 8 Bi-State-Terminated transactions.
The number m of used tuples for the optimization cor-
responds to the number of the m greatest tuple val-
ues. These m tuples are combined as in the regular
MTC check, while the remaining tuples are summed
up as in the bounded MTC check. Thus, the opti-
mized MTC check combines the accuracy of the reg-
ular MTC check with the improved performance of
the bounded MTC check.
In order to compare the quality of both optimiza-
tions, the bounded MTC check and the optimized
MTC check, we have additionally measured the num-
ber of unnecessary aborts caused by the optimization.
These results are shown in Figure 7. The gray parts
of the bars show the amount of transactions where
the MTC was violated. As we can see, all MTC
checks work correct as they recognize this inconsis-
tency. However, the extremely fast bounded MTC
check classifies the outcome of 20% of the transac-
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC
NETWORKS
173

Multiple Tuple Constraints
0%
Comparison
20% 40% 60% 80% 100%
MTC violated
false positive
MTC not violated
MTC opt
MTC bounded
MTC
Figure 7: MTC optimization comparison.
tions that do not violate the MTC as inconsistent.
As this results in an unnecessary abort, the bounded
MTC check should only be used in situations in which
the check must be very fast. However, the optimized
MTC check using the eight largest tuples caused only
5% of unnecessary aborts by reducing the runtime
compared to the regular MTC check by 50%. Thus,
we consider the optimized MTC check as a good
tradeoff between time and accuracy.
6 RELATED WORK
Our proposed solution relates to four ideas that
are used in different contexts: Bi-State-Termination
(Obermeier and Böttcher, 2007), Escrow locks (Gray
and Reuter, 1993), and Speculative locking (Reddy
and Kitsuregawa, 2004), multiversion databases
(Katz, 1990), (Cellary and Jomier, 1990), (Chen et al.,
1996).
Bi-State-Termination has been recently proposed
in (Obermeier and Böttcher, 2007), but only for in-
sert, update, and delete operations. We extend this
concept to be able to deal with any relational ex-
pression including union, projection, cartesian prod-
uct, and set difference. Furthermore, our approach
allows the definition of database constraints like do-
main constraints, functional dependency constraints,
referential integrity constraints, and multiple tuple
constraints. We have experimentally evaluated sev-
eral consistency constraints and have proposed an op-
timization to multiple tuple constraint checks.
Escrow locks are mainly used in environments
with high transaction load within certain data
hotspots. Instead of locking an entire data item, the
escrow lock calculates an interval [i, j] for each at-
tribute a that is updated by a transaction T
1
, which
corresponds to an upper and lower bound of the at-
tribute. Whenever a concurrent transaction T
2
checks
a precondition P for a, this check is evaluated on the
interval [i, j] instead of trying to evaluate P on the data
item a that is locked by T
1
. In comparison the escrow
locking technique, Bi-State-Termination does neither
rely on numerical values, nor does it assume that an
attribute may lie in an interval. Furthermore, all rela-
tional expressions can be evaluated by BST.
Speculative Locking (SL) (Reddy and Kitsure-
gawa, 2004) is another related technology. SL was
proposed to speed up transaction processing in envi-
ronments with high message delivery times by spawn-
ing multiple parallel executions of a transaction that
waits for the acquisition of required locks. Like BST,
SL also allows the access to after-images of a trans-
action U while U is still waiting for its commit deci-
sion. However, SL does not allow the commit of T
before the final commit decision for U has been re-
ceived. This means, SL cannot successfully terminate
T while the commit vote for U is missing, which is
possible with BST.
Multiversion database systems (Katz, 1990), (Cel-
lary and Jomier, 1990), (Chen et al., 1996) are used to
support different expressions of a data object and used
for CAD modeling, and versioning systems. How-
ever, compared to BST, multiversion database sys-
tems allow multiple versions to be concurrently valid,
while BST allows only one valid version, but lacks the
knowledge which of the multiple versions is valid due
to the atomic commit protocol. Furthermore, multi-
version database systems are mostly central embed-
ded databases that are not designed to deal with dis-
tributed transactions. Instead, the user specifies on
which version he wants to work.
Other approaches rely on compensation of trans-
actions. (Kumar et al., 2002), for instance, pro-
poses a timeout-based protocol especially for mobile
networks, which requires a compensation of trans-
actions. However, inconsistencies may occur when
some databases do not immediately receive the com-
pensation decision or when the coordination process
fails.
7 SUMMARY AND
CONCLUSIONS
A major challenge for the integration of mobile
databases into transaction processing is to guarantee
atomic commit and isolation of distributed transac-
tions and global database consistency, even in the case
of communication failures. We have presented and
extended Bi-State-Termination, a technique to handle
the case that a participant does not receive the coor-
dinator’s commit decision for a long period of time.
Bi-State-Termination allows continuing the process-
ing of transactions U, even in the case that conflicting
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
174

transactions T that hold locks on resources required
by U are blocked, by obeying both possible outcomes
of the blocked transactions T . This allows transac-
tions U to commit even if they conflict with pending
transactions T .
We have focused on database table definitions,
on arbitrary read- and write-operations, and we pro-
posed a rewrite rule system that allows all these kinds
of operations to be executed on a database that uses
Bi-State-Termination. Furthermore, we presented a
technique for checking typical integrity constraints
even in situations where a database using Bi-State-
Termination is not sure about its current state as pend-
ing transactions may commit or abort. Our proposed
technique for consistency constraint checking allows
checking whether or not a transaction may violate
given constraints. The experimental evaluation has
shown the feasibility of our constraints checker and
has proposed an optimization for checking time con-
suming multiple tuples constraints.
Altogether, the constraint checking technique pro-
posed in this paper is feasible and efficient, and it can
be done in combination with Bi-State-Termination
in mobile databases, even in case of network fail-
ures. This is why we consider the constraint check-
ing technique as a very important addition to Bi-
State-Termination, which is useful to integrate mobile
databases into business transactions.
REFERENCES
Cellary, W. and Jomier, G. (1990). Consistency of versions
in object-oriented databases. In McLeod, D., Sacks-
Davis, R., and Schek, H.-J., editors, 16th International
Conference on Very Large Data Bases, August 13-16,
1990, Brisbane, Queensland, Australia, Proceedings,
pages 432–441. Morgan Kaufmann.
Chen, I.-M. A., Markowitz, V. M., Letovsky, S., Li, P., and
Fasman, K. H. (1996). Version management for sci-
entific databases. In Apers, P. M. G., Bouzeghoub,
M., and Gardarin, G., editors, Advances in Database
Technology - EDBT’96, 5th International Conference
on Extending Database Technology, Avignon, France,
March 25-29, 1996, Proceedings, volume 1057 of
Lecture Notes in Computer Science, pages 289–303.
Springer.
Gray, J. (1978). Notes on data base operating systems. In
Flynn, M. J., Gray, J., Jones, A. K., et al., editors,
Advanced Course: Operating Systems, volume 60 of
Lecture Notes in Computer Science, pages 393–481.
Gray, J. and Lamport, L. (2006). Consensus on transaction
commit. ACM Trans. Database Syst., 31(1):133–160.
Gray, J. and Reuter, A. (1993). Transaction Processing:
Concepts and Techniques. Morgan Kaufmann.
Katz, R. H. (1990). Toward a unified framework for ver-
sion modeling in engineering databases. ACM Com-
put. Surv., 22(4):375–409.
Kohler, W., Shah, A., and Raab, F. (1991). Overview
of TPC Benchmark C: The Order-Entry Benchmark.
Technical report, http://www.tpc.org, Transaction Pro-
cessing Performance Council.
Kumar, V., Prabhu, N., Dunham, M. H., and Seydim, A. Y.
(2002). Tcot-a timeout-based mobile transaction com-
mitment protocol. IEEE Trans. Com., 51(10):1212–
1218.
Obermeier, S. and Böttcher, S. (2007). Avoiding infinite
blocking of mobile transactions. In Proceedings of the
11th International Database Engineering & Applica-
tions Symposium (IDEAS), Banff, Canada.
Reddy, P. K. and Kitsuregawa, M. (2003). Reducing the
blocking in two-phase commit with backup sites. Inf.
Process. Lett., 86(1):39–47.
Reddy, P. K. and Kitsuregawa, M. (2004). Speculative lock-
ing protocols to improve performance for distributed
database systems. IEEE Transactions on Knowledge
and Data Engineering, 16(2):154–169.
Skeen, D. (1981). Nonblocking commit protocols. In Lien,
Y. E., editor, Proceedings of the 1981 ACM SIGMOD
International Conference on Management of Data,
Ann Arbor, Michigan, pages 133–142. ACM Press.
CONSTRAINT CHECKING FOR NON-BLOCKING TRANSACTION PROCESSING IN MOBILE AD-HOC
NETWORKS
175
