
ConTask
Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
Jan Haas
?
, Heiko Maus
?
, Sven Schwarz
?
and Andreas Dengel
?
†
?
German Research Center for Artificial Intelligence (DFKI GmbH), Kaiserslautern, Germany
†
Computer Science Department, University of Kaiserslautern, Kaiserslautern, Germany
Keywords:
Task management, Proactive information delivery, Personal knowledge space, User observation, Agile task
modelling, Semantic Desktop.
Abstract:
The paper presents an approach to support knowledge-intensive tasks with a context-sensitive task manage-
ment system that is integrated into the user’s personal knowledge space represented in the Nepomuk Semantic
Desktop. The context-sensitive assistance is based on the combination of user observation, agile task mod-
elling, automatic task prediction, as well as elicitation and proactive delivery of relevant information items
from the knowledge worker’s personal knowledge space.
1 INTRODUCTION
Corporate work routines have changed vastly in re-
cent years, and today’s knowledge workers are con-
stantly presented with the challenge of negotiating
multiple tasks and projects simultaneously (Gonz
´
alez
and Mark, 2005). Each of these projects and tasks
stereotypically requires collaboration with different
teams, and dealing with a varied plethora of data, re-
sources, and technologies. In contrast to traditional,
static business processes, the task-oriented work of
clerks today is often highly fragmented. Each in-
terruption requires knowledge workers to mentally
re-orientate themselves, and permanent task switches
and disruptions are associated with a significant over-
head cost (Mark et al., 2008). Especially for complex,
knowledge-intensive tasks requiring significant quan-
tities of related documents and resources, reorienta-
tion entails a substantial cognitive overhead.
While an efficient task execution requires the pro-
cessing of particularly task relevant information at
hand, today’s knowledge workers have to face the
known information overload. An increasing amount
of data is available, however, spread over various in-
formation sources such as email client, address book,
local and remote file systems, web browser, wikis,
and organizational structures. The efficient and suc-
cessful processing of a task depends on the quality
of finding and selecting the most relevant information
for the task at hand. This represents a source of er-
rors in daily knowledge work. Important information
is not found, connections are overseen or relevant ex-
perts are not identified. The result consists of sub-
optimal problem solutions, unnecessary repetitions of
already accomplished tasks or wrong decisions.
As a solution to the outlined problems of the
knowledge worker, this paper proposes a context-
sensitive task management system named ConTask.
ConTask focuses on the areas of knowledge captur-
ing, knowledge reuse, and interruption recovery. By
tracking the user’s actions, the system provides au-
tomatic means to intelligently elicit task-specific rel-
evant information items and, thus, capture a task’s
context. This is used for proactively delivering such
context-specific, task-relevant knowledge to a user to
ensure a reuse of valuable task know-how. Thereby,
ConTask aims at the following goals:
• Automatically capture created/consulted informa-
tion objects and assign these to tasks to cap-
ture task know-how and to structure the personal
knowledge space in a task-centric way.
• Increase potential productivity for knowledge
workers and reduce resource allocation costs by
proactively providing relevant, task-related infor-
mation and resources.
• Enable and ensure task-specific know-how reuse.
• Facilitate reorientation back into an interrupted
task by reducing the cognitive and administrative
task switching overhead.
• Improve task-specific assistance by learning from
30
Haas J., Maus H., Schwarz S. and Dengel A. (2010).
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work.
In Proceedings of the 12th International Conference on Enterprise Information Systems - Artificial Intelligence and Decision Support Systems, pages
30-39
DOI: 10.5220/0002895400300039
Copyright
c
SciTePress

knowledge workers’ feedback.
The paper is structured as follows: the next sec-
tions introduce the scientific background and give an
overview on related work. Section 4 explains the
main ingredients and concepts of ConTask. A sum-
mary and outlook on future work conclude the paper.
2 BACKGROUND
Various approaches identify business processes as
a means for structuring a company’s knowledge
(Abecker et al., 2002; Riss et al., 2005). As busi-
ness processes form the core operational sequences of
every company, their efficiency is critical for a com-
pany’s success. Knowledge workers are integrated
into crucial parts of the business processes, and the
quality of their (procedural) know-how decides be-
tween success and failure (for the company). They are
embedded in business processes where we are mainly
interested in supporting knowledge-intensive tasks for
know-how capture, provision, and reuse as well as as-
sistance in multitasking for supporting the knowledge
worker in his daily work directly.
Knowledge-intensive Tasks. Especially know-
ledge-intensive tasks entail the challenge of retriev-
ing, structuring and processing information, e.g.,
for judging a case or for making crucial decisions.
Knowledge-intensive tasks notably rely on pro-
cessing large quantities of relevant information and
coevally producing valuable knowledge to be reused
in similar situations (later on). Aiming at preserving
this valuable knowledge, tasks should be utilized to
structure a knowledge worker’s personal knowledge
space consisting of various resources like documents,
emails, and contact addresses, as well as real-life
concepts such as persons, projects, or topics.
Typically, knowledge-intensive activities are ex-
plorative and not completely known a priori (Elst
et al., 2003). As many parts of their execution might
not be predetermined, they can not be completely
modelled in advance. On the basis of this, we intro-
duce the concept of weakly-structured workflows con-
sisting of knowledge-intensive activities with specific
design decisions for applications supporting these
workflows. They mainly incorporate the two aspects
lazy and late modelling and the strong coupling of
modelling and execution of process-models. Lazy
modelling refers to an on demand refinement of pro-
cess models initially only partially specified. This
pays off for weakly-structured workflows as details
of the execution of agile knowledge-intensive tasks
are not known in advance. This aspect is strongly
related to the coupling of modelling and execution
of process-models. Starting with a partial model,
weakly-structured workflows allow for dynamical re-
finement of the process model during its execution.
Our work resulted in the TaskNavigator (Holz
et al., 2006; Rostanin et al., 2009), a browser-based
workflow system. It supports weakly-structured
workflows through agile task management for teams,
proactive information delivery (PID) based on the
task context (mainly consisting of task name, descrip-
tion, and attached documents, i.e. text-based), pro-
cess know-how capture and re-use. Evaluations have
shown that a main drawback was the effort for users
to maintain their task, i.e., by uploading documents
to the task represented in the browser. The work pre-
sented here, is a continuation of the overall goal by
integrating this into user’s personal knowledge space
and allowing a much easier management of their tasks
embedded on their personal desktops.
Multitasking. Nowadays knowledge workers are
engaged in multiple tasks and projects in parallel
(e.g., (Gonz
´
alez and Mark, 2004)). Several stud-
ies have shown that task-oriented knowledge work is
highly fragmented (Czerwinski et al., 2004). Typi-
cally, knowledge workers spend only little time on
a certain task before switching to another. Task
switches and disruptions cause significant overhead
costs (e.g., (Mark et al., 2008; Iqbal and Horvitz,
2007; Mark et al., 2005)). After an interrup-
tion, knowledge workers must reconstruct their task-
specific mental state. This encompasses, in amongst
other detail, memories around the task, including next
steps to take, required resources, critical factors and
deadlines.
In addition to the cognitive overhead, restructur-
ing of the desktop and physical work environment is
also often required. Resources such as documents,
websites, emails, and contact addresses must be relo-
cated and utilized. The retrieval of these various task-
specific resources represents a challenging and time
consuming problem. Furthermore, the cognitive chal-
lenge to remember all task-specific relevant informa-
tion can result in significant difficulty for the success-
ful completion of a given task. Short term memory
loss concerning critical resources or other task-related
information can have major ramifications.
The frequent interruption of knowledge-intensive
tasks is often a contributing factor to workplace stress
and frustration. Studies show that constant inter-
ruptions in these situations lead to changes in work
rhythm, mental states and work strategies (Mark et al.,
2008). Often this results in attempts to compensate
lost time through an accelerated and therefore even
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
31

more stressful work pace. The higher workloads and
additional effort associated with frequently switching
tasks increase both pressure and frustration for to-
day’s knowledge workers.
3 RELATED WORK
Many different approaches focus on assisting knowl-
edge workers with knowledge-intensive tasks and in
multitasking work scenarios.
The TaskTracer system (Stumpf et al., 2005b)
consists of an user observation framework collecting
events from various office applications. The system
utilizes the observed user actions and applies machine
learning algorithms for automatically predicting the
user’s current task and for associating accessed infor-
mation items like files or web pages with the elicited
task (Stumpf et al., 2005a). This enables a task-
specific provision of these information items.
The APOSDLE Project (Lokaiczyk et al., 2007)
represents a similar approach. The project integrates
task management, e-learning, knowledge manage-
ment and communication systems. APOSDLE uti-
lizes user observation to support the task-centric pro-
vision of suitable learning material and to associate
knowledge artefacts with corresponding tasks. The
user observation framework is realized by software
hooks on the operation system level. Observed user
actions are reported to the task predictor component, a
machine learning component that serves for task pre-
diction and task switch detection.
The OntoPIM (Lepouras et al., 2006) project sug-
gests an architecture for a task information system
including a monitoring system for user observation.
Observed user actions are interpreted by an inference
engine to elicit information relevant to the user’s tasks
and to proactively provide these items. This task-
specific PID is integrated into a selected target ap-
plication (e.g., into a web browser). Alternatively,
the windows context menu is enriched with task-
related information. Instead of integrating the task-
specific assistance into several applications, our ap-
proach aims at integrating the PID into a task manage-
ment system. This reduces the amount of applications
having to be adjusted and enables the agile task mod-
elling to directly use the captured and elicited task-
specific knowledge.
A task management system embedded in the per-
sonal knowledge space along the vision we presented
in (Riss et al., 2005) is KASIMIR (Grebner et al.,
2008). It focuses on capturing, evolving, and pro-
viding process patterns from an organisational reposi-
tory. The tasks within the processes are enriched with
information items from the Nepomuk Semantic Desk-
top (see next section) by user interaction similar to
ConTask. Similar work on identifying process pat-
terns but coming from the process management side
and embracing task management is the Collaborative
Task Management (CTM) approach (Stoitsev et al.,
2008). The main difference of both approaches from
ConTask is the lack of user observation and PID our
system applies and their steps further to apply evolv-
ing process patterns in process management. We will
investigate the combination of these approaches in the
joint project ADiWa
1
started in 2009.
4 INGREDIENTS OF ConTask
ConTask is based on the following base components
to achieve a context-oriented personal task manage-
ment: a task management system, the Semantic Desk-
top, and a framework for retrieving user context.
Based on these components, ConTask supports with
proactive information delivery and agile task mod-
elling. It enables observing task management, provid-
ing a task prediction, and allowing relevance feedback
and learning. These components and concepts will be
detailed in the remainder of this section.
Task Management. As mentioned in Section 2, in
order to support knowledge workers in working with
knowledge-intensive tasks directly on their desktops,
a task management system called TaskPad was devel-
oped. TaskPad provides the possibility to work on
personal tasks and to synchronize tasks from different
sources such as TaskNavigator, where the tasks were
part of some agile workflows. TaskPad allows to ac-
cess, attach, and upload documents to TaskNavigator.
As both TaskNavigator and TaskPad are fully RDF/S
based, they rely on the ontology for weakly-structured
workflows developed in (Elst et al., 2003).
Apart from this, TaskPad provides the usual task
management functionality such as maintaining tasks,
taking notes, attaching URLs, notes, or documents,
and filtering the task list
2
. Fig. 2 shows the task list as
Task Diary and the Task Editor.
Semantic Desktop. To represent and maintain the
user’s personal knowledge space we use and integrate
with the Nepomuk
3
Semantic Desktop which trans-
fers the idea of the Semantic Web to the user’s local
desktop (for a recent overview, see (Grimnes et al.,
1
http://www.adiwa.net
2
the filters are based on SPARQL queries
3
http://nepomuk.semanticdesktop.org/
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
32

2009)). It serves to capture and represent the knowl-
edge worker’s personal mental models (Sauermann
et al., 2005). This personal knowledge space con-
sists of real world concepts such as persons, places,
projects or topics, as well as, the connections and re-
lations between them (see Fig. 1). Documents con-
tain information about these concepts and represent
the knowledge worker’s individual background, tasks
or personal interests. In this context, the Personal
Information Model Ontology (PIMO) serves to for-
malize and structure the personal knowledge space (a
PIMO excerpt can be seen on the upper left side with
PIMO classes).
4
It is the core of the Semantic Desk-
top and provides the possibility to associate real world
concepts with resources, such as documents, emails
or contact details, for personal information manage-
ment.
For example, Fig. 1 shows personal notes taken
during a meeting using a Semantic Wiki embedded
in the Nepomuk Semantic Desktop. Here, the meet-
ing itself is an instance of the PIMO class Meeting
together with linked concepts such as attendees, pre-
vious meetings or resources such as the calendar en-
try in MS Outlook. The wiki text shown is mixed
with concepts, such as the project it belongs to, top-
ics mentioned in the meeting, etc. Using a concept
within the text (e.g., by auto-completion) allows to
browse to the concept within the wiki text as well as
adds relations to the meeting instance automatically.
Furthermore, an ontology-based information extrac-
tion (iDocument, see (Adrian et al., 2009)) analyzes
text and provides proposals of concept which might
fit for the current thing (lower left tab). Thus, dur-
ing everyday usage, the PIMO evolves with relevant
concepts of the user’s work. As the meeting is then
linked
User Context. The Context Service elicits the
user’s work context, which is a snapshot consisting
of contextual elements with relevance to the user’s
present goal or task (Schwarz, 2006; Schwarz, 2010).
Each contextual element corresponds to an entity
from the user’s PIMO. Contextual elements also con-
tain a value describing the certainty for actually be-
longing to the current context. As knowledge work-
ers regularly switch their tasks and, hence, their work
context, the Context Service maintains several so
called context threads. Each context thread represents
a context snapshot associated with a certain task and
contains all information items from the user’s PIMO
4
The PIMO is represented in RDF/S – the basic lan-
guage of the Semantic Web – and is able to include different
vocabularies resp. ontologies, i.e., it can be adapted to dif-
ferent domains.
that are relevant to that task. The Context Service ex-
pects explicit notifications about context switches to
correctly maintain context snapshots. A designated
API allows to inform the Context Service whenever
the user is switching to a different context thread.
In this scenario, the User Observation Hub
5
(UOH) serves as a technical means to automatically
observe the user’s actions (see also Fig. 3). This is
used for gathering evidence about relevant concepts
belonging to the user’s current context. The UOH in-
cludes an extensive user action ontology formalizing
all types of so called native operations (NOPs) that
are observable during daily knowledge work. The on-
tology comprises operations such as browsing a web-
site, adding a bookmark, reading an email or access-
ing a file in the file system. To gather these user ac-
tions, the user observation framework provides a set
of installable observers, which report the correspond-
ing user actions to the UOH. The observer framework
includes plugins for Mozilla Firefox and Thunderbird
and a Windows file system observer. Observed user
actions are gathered in the UOH and distributed to
registered listeners. The Context Service is such a
designated user observation listener receiving notifi-
cations about observed user actions.
As outlined, the allocation and retrieval of relevant
information items represents a time consuming chal-
lenge for today’s knowledge workers. Thus, ConTask
aims at increasing potential productivity for knowl-
edge workers and reducing allocation costs by proac-
tively providing relevant, task-related information and
resources.
Proactive Information Delivery. The user’s PIMO
represents a range of concepts and resources the
knowledge worker deals with during daily work.
Therefore, elements in the worker’s PIMO are taken
to serve as items for the proactive information deliv-
ery (PID). Aiming at a task-centric work support, the
information items are provided in a task-centric man-
ner. Thus, the PID structures the personal knowledge
space in a task-oriented way.
To automatically elicit task-specific relevant infor-
mation items from the PIMO, ConTask utilizes the
Context Service. Based on the user’s interactions
with desktop applications, such as browsing a web-
site or writing an email, the Context Service elicits
task-specific relevant information items using tech-
niques of machine learning, entity recognition, and
document similarity (for details see (Schwarz et al.,
2008)). In addition, a History Service provides task-
specific records of all accessed information items.
5
http://usercontext.opendfki.de/wiki/UserObservationHub
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
33
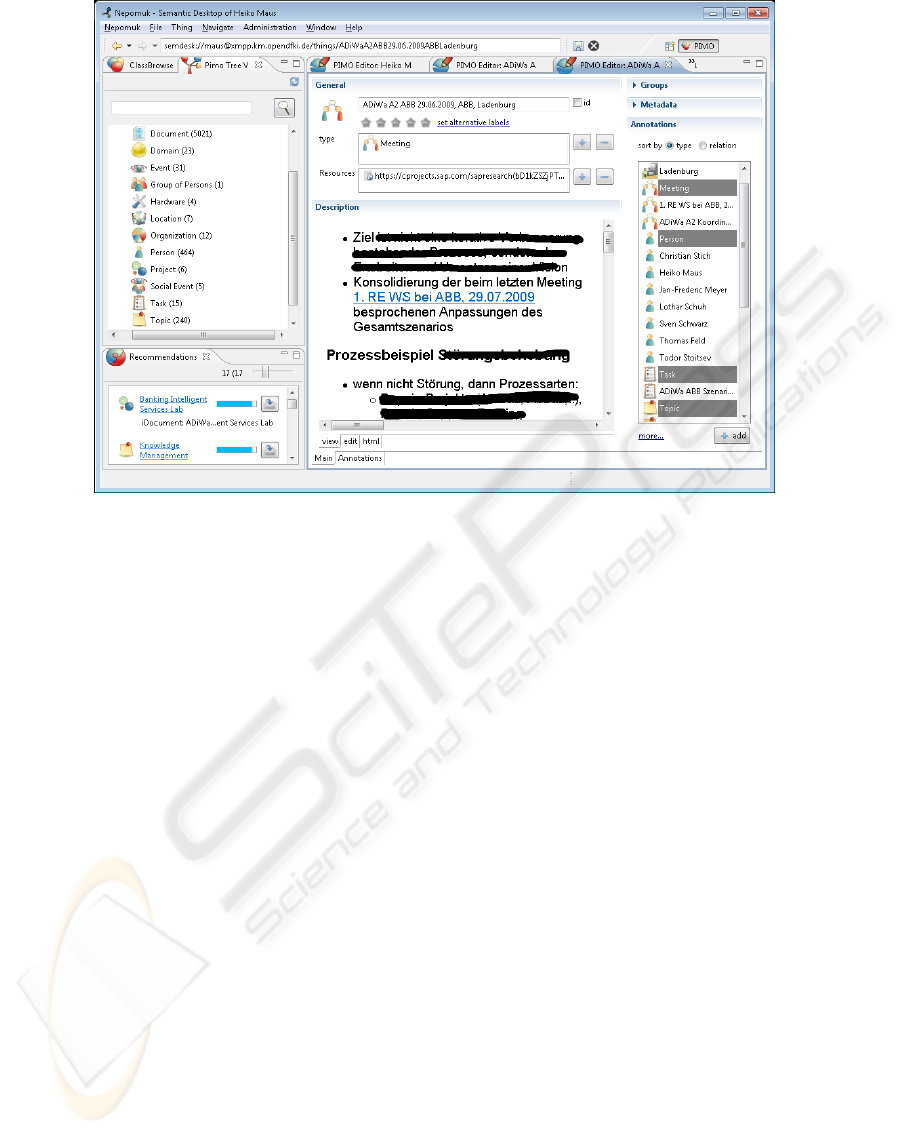
Figure 1: Nepomuk Semantic Desktop: semantically-enriched meeting notes (some text obscured) with PIMO relations
(among them the task accessible in ConTask as shown in Fig. 2).
Being registered as a UOH listener, the History Ser-
vice maintains a detailed task-specific access history
of PIMO concepts and resources (based on the ob-
served user actions).
Fig. 2 depicts a screenshot of ConTask, where
the so called PID Sidebar proactively provides task-
centric access to relevant information items. The PID
Sidebar is part of the Task Editor which allows for
easy consultation and modification of a task’s prop-
erties. Below the task’s name, status, and time con-
straints, the so called task attachments represent the
information items explicitly associated with the task.
PID Sidebar and Task Editor are located on the right-
hand side of the screenshot. ConTask provides further
interaction possibilities on both PID items and task
attachments, such as viewing an item specific access
history, opening resources with the associated appli-
cation or viewing resp. editing PIMO elements with
the PIMO Editor.
While the Task Editor contains manually attached
information items, the PID Sidebar shows additional,
potentially relevant information items. The History
Service is used to deliver directly accessed items, and
the Context Service is used to propose automatically
reasoned items.
PID Categories. The PID Sidebar provides infor-
mation items in the following three categories:
• Elicitation For Task. This category contains the
most relevant information items from the user’s
PIMO with respect to the task. It comprises both
directly observed and also elicited items, that have
not been directly accessed by the user.
• History For Task. This section contains all PIMO
elements for which a user action has been ob-
served during the execution of this task. This
category does not comprise any concluded or
elicited elements, but only directly observed el-
ements such as directly accessed files or websites.
The items here stem from the History Service.
Items already shown in the Elicitation For Task
are omitted.
• History. This category contains the most fre-
quently accessed PIMO elements that are not con-
tained in the first two categories, but that have
been directly accessed by the user since a certain
point of time. These items also stem from the His-
tory Service.
Elicitation For Task provides the most relevant
elicited information items computed by the Context
Service’s machine learning techniques. The PID
Sidebar supports the user by proposing potentially rel-
evant items which have not been explicitly associated
with the task at hand. The effectiveness of these al-
gorithms is a critical factor for the acceptance of this
service. Low quality proposals will merely distract
and annoy the user while good quality proposals have
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
34
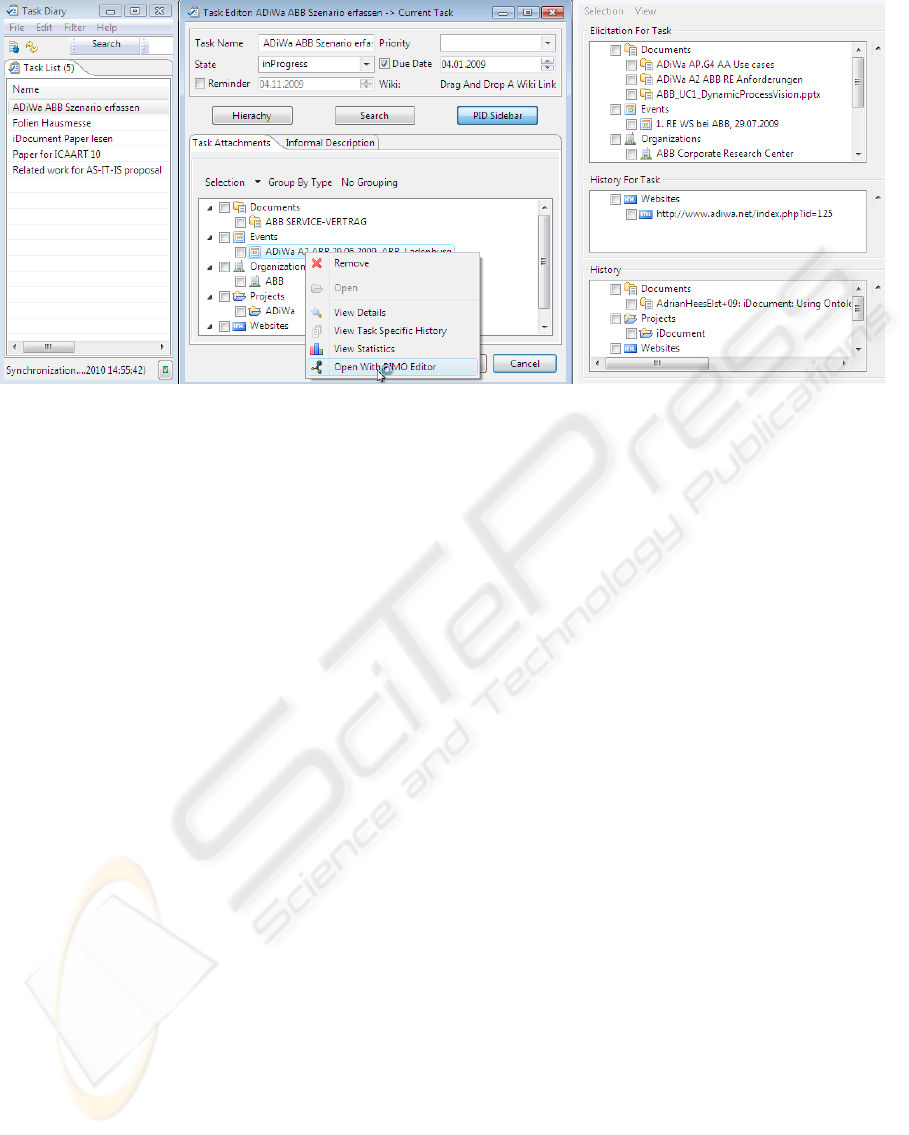
Figure 2: ConTask: Task Diary with open tasks; Task Editor with the current active task and the PID sidebar with proposed
concepts from the PIMO and recently accessed resources (the context menu opens the PIMO editor in Fig. 1).
the potential to increase the user’s work performance
and foster a successful task execution. Particularly for
newly created tasks, there is not enough explicit in-
formation available that can be used to automatically
learn what this task is about. As a consequence, the
Context Service is not able to determine good propos-
als. For these cases, the PID Sidebar’s category His-
tory For Task contains all information items the user
has accessed while working on the task. According to
the user observation, these items have been recently
touched by the user while the task at hand was se-
lected as the current task.
The problem is, we can not expect the user to
make every task and every task switch explicit—
consider interruptions or phone calls, for example.
The task management tool does not know whether the
user is actually working on the currently selected task.
As a consequence, one can not automatically attach
recently touched items to the task. Rather ConTask
proposes the items allowing users to attach them with
a simple drag&drop gesture. The section Task Predic-
tion will explain the how ConTask tries to keep track
of the user’s current task nevertheless.
For example consider the following scenario. The
user accesses a website that is associated with the
current task, but the Context Service does not deter-
mine this website as relevant, as it has to be further
stimulated by being re-accessed by the user. In this
case, the website would be provided in the History
For Task section. If the relevance value of the web-
site increased based on further stimulation, the web-
site would be included into the Elicitation For Task
category and would therefore be removed from the
History For Task.
Manual task switches sometimes have fuzzy
boundaries (Stumpf et al., 2005a). For instance if a
knowledge worker is just reading a web page that is
related to his current task but that leads him to switch
to a new one: should the resource be associated with
the old or with the new task? Additionally, if a knowl-
edge worker explicitly consults a related task (and
hence switches to the other task) for reusing there-
stored know-how, the History For Task for the orig-
inating task will not contain the consulted material.
A solution for this case provides the History category
at the bottom of a task’s PID Sidebar. It contains all
information items which have been recently accessed
by the user, but which have neither been associated
with, nor elicited for, nor accessed during the task at
hand. This overview over all recently accessed items
allows an easy reuse of know-how across different
tasks (via simple drag&drop a resource can be added
as a task attachment).
Agile Task Modelling. Based on the proactively
provided PIMO elements, ConTask enables agile, on-
the-fly task modelling. As knowledge-intensive tasks
can not be completely designed or modelled before
their execution, agile, lazy modelling was chosen to
allow for task refinement during the execution pro-
cess. Via context menu or drag&drop, new items, e.g.,
proposed items from the PID Sidebar, can be easily
added as task attachments. This enables knowledge
workers to associate information objects to tasks and
to thereby classify work knowledge to independent
task information units. The result is a task-centric
structuring of the user’s personal knowledge space.
This aligns with suggestions in (Abecker et al., 2002;
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
35

Holz et al., 2005), where minimal analysis and initial
modelling overhead are identified as one of the key
requirements for successful business process-oriented
knowledge management.
Furthermore, task-oriented structuring of the
user’s personal knowledge space enables intuitive and
direct process know-how reuse. For example, while
working on a report document for project x, the
knowledge worker may remember an already com-
pleted similar report for project y. In case a relevant
information item of project y is actually relevant for
project x, ConTask allows to sight, attach, and reuse
these items from one task to another with a few clicks.
By explicitly attaching reused items to tasks, Con-
Task supports a light-weight capturing of task-specific
knowledge and, hence, provides the basis for the inte-
gration of these tasks in organizational workflow sys-
tems such as TaskNavigator.
The explicitly attached and conserved task-
specific items as well as the task-specific history also
facilitate rapid reorientation when switching back to
an interrupted task. ConTask reduces the mentioned
cognitive and administrative overhead consisting of
remembering and reallocating task-specific relevant
information items. By double clicking attached or re-
cent documents and resources, task-specific working
states can be easily reconstructed and the task can be
resumed without much delay.
As the PID Sidebar merely proposes potentially
relevant items, ConTask provides the possibility of re-
jecting non-relevant or unsuitable suggestions. The
system remembers these decisions and does not pro-
vide rejected information items again. Both kinds
of feedback, acceptance and rejection, represent ev-
idences for adapting the context of a task and serve
as relevance feedback for the task-specific PID. That
way, user feedback enables automatic learning and
system improvement (Abecker et al., 2002; Riss et al.,
2005; Holz et al., 2006).
Observing Task Management. During the execu-
tion of a task, the User Observation Hub (UOH)
observes the user’s task-specific behavior. Besides
tracking actions inside office applications, ConTask
also observes the user’s explicit task management in-
teractions such as reuse/open, drag&drop, and reject
operations within the Task Editor and the PID Side-
bar. Automatic, unobtrusive learning is applied to im-
prove the task-specific PID. The observed user events
are utilized for the following two goals:
• Relevance feedback on proactively provided in-
formation items.
• Automatic task switch detection based on the
user’s interaction with the system.
To integrate explicit task management operations
into the user observation framework, the user action
ontology has been enriched with NOPs for task oper-
ations. These additional NOPs resemble a task oper-
ations ontology capable of representing user interac-
tion with an agile task management tool. Observable
actions of the ConTask system which are also passed
to the UOH are switching to some task or giving rel-
evance feedback on PID items, for example. The task
operations ontology is designed to represent NOPs
from different task management applications. It com-
prises a minimal set of operations that are necessary
for the purpose of relevance feedback on proactively
provided information items and automatic task switch
detection. It contains operations such as task creation,
attribute modification such as by adding a task de-
scription or attachments. Further operations inform
about accessing attachments or interacting with the
PID sidebar. A Task Observation Service inside Con-
Task describes the user’s task actions according to the
NOP ontology and report these to the UOH.
Task Prediction. As outlined, Context and History
Service form the basis of the task-specific PID. Both
services observe the user’s desktop activity and record
or elicit relevant information items corresponding to
a certain context thread. However, both services rely
on explicit information about the currently processed
task. If users are stressed or get interrupted, they will
not use the task management tool for every tiny task
deviation. Hence, not every task switch is technically
observed. To compensate for this, ConTask contains
a Task Elicitation Service realizing a task prediction.
The Task Elicitation Service maps the tasks of the
task management tool to context threads maintained
by the Context Service. The observed user actions
are treated as evidences to predict and update the cur-
rently active context thread. If the Context Service
detects a context switch, a corresponding task switch
is also proposed to the user. And vice versa: If the
user switches a task, the Context Service is informed
to switch to the corresponding context thread, too.
The detection of the currently processed task is
based on the observed user interaction with ConTask,
such as attaching relevant information items to a task.
To realize this, the task operations ontology is divided
into the following two categories:
• Operations with a Direct Implication on a Task
Switch. These operations are interpreted as strong
indication for the fact that the user works on a
certain task. Based on that, any of these user ac-
tions immediately leads to the conclusion of a task
switch. They comprise all write access operations
on a task, such as adding an attachment or editing
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
36
the task’s description, as well as opening the Task
Editor window.
• Operations with a Weak Implication on a Task
Switch. These operations only lead to a task
switch conclusion if the following condition holds
true: No other operation with either weak or di-
rect implication on a task switch occurs within a
certain amount of time t. Operations with weak
implications consist of the selection of a task in
the task list and the event that occurs if the Task
Editor becomes the active window.
The reasoning for the timeout value, associated with
the selection of a task, is that knowledge workers
sometimes browse their task list by clicking on each
single entry. This serves to get an overview on their
tasks and to determine which tasks are most critical
at the moment. To avoid that each selection during
browsing triggers a task switch and therefore context
thread switch, selections are only interpreted as task
switches after the timeout.
A similar reason explains the timeout value corre-
sponding to the focus gain event of the Task Editor.
As several Task Editor windows might be open at the
same time, the user might quickly switch focus be-
tween two or more Task Editors to compare the cor-
responding tasks. The timeout value avoids that every
focus change directly determines a task switch.
The automatic task elicitation serves to precisely
determine which user actions and corresponding in-
formation objects occurred in the context of which
task. This aims at increasing the Context and History
Service’s effectiveness. As the assistance is realized
in an unobtrusive way, the user just needs to work
and interact with ConTask, without having to deal
with explicitly telling the system to perform a task
switch. Since knowledge workers frequently perform
task switches and face interruptions of their current
task, automatic switch detection reduces interaction
overhead and still guarantees that information items
are associated with the correct task.
In addition to this, the Context Service also
provides the possibility of automatically detecting
whether the last user action(s) match better with dif-
ferent context thread(s) than the current one. In this
case, the service notifies interested listeners about a
potential switch. ConTask utilizes these switch de-
tection capabilities. However, a task switch can not
be performed automatically and, hence, the user is
consulted via a specific popup listing potential task
switches. The window slides up from the bottom of
the screen and only remains visible for a short amount
of time. If the user does not interact within this time-
frame, the popup disappears.
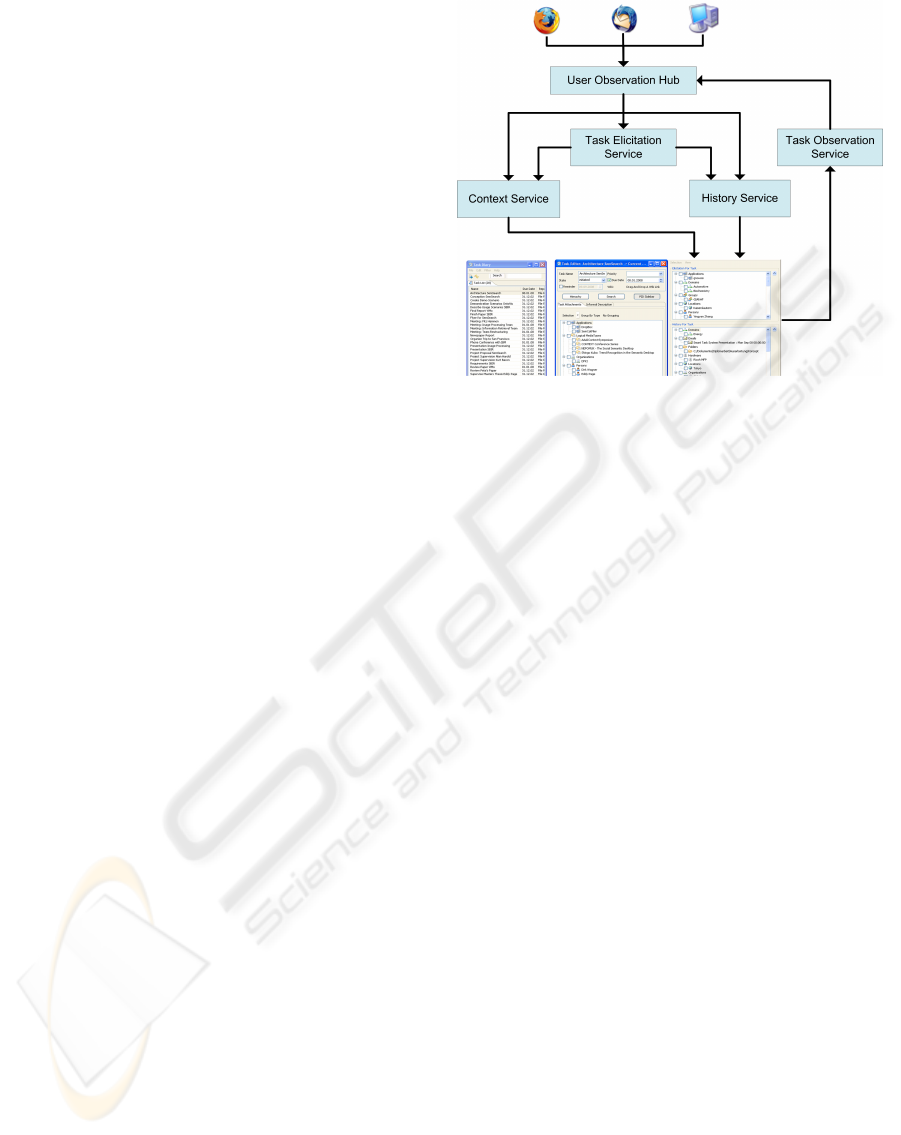
Figure 3: ConTask components and interrelations.
Relevance Feedback and Learning. The Task
Elicitation Service also utilizes the observed interac-
tions with ConTask for the transmission of feedback
to the Context Service. Actions such as the assign-
ment of a PID item to a task are interpreted as pos-
itive feedback. They increase the relevance value of
the item in the corresponding context thread.
The relevance feedback serves to increase the
Context Service’s effectiveness. The cycle of proac-
tively providing contextual information to the user
and transmitting user feedback to the Context Service
leads to a better synchronization of context thread
and task: Relevant information items from the con-
text thread are proposed in the PID Sidebar. Some
of them may be added to the task by the user (via
drag&drop from the sidebar to the task attachments).
In that case, the resulting feedback leads to increased
relevance values of these items in the context thread.
Fig. 3 shows how user observation data is utilized in
ConTask to realize a knowledge improvement cycle.
As an extension to the mentioned user observa-
tion providers, such as Mozilla Firefox, ConTask uti-
lizes the Task Observation Service to become observ-
able. Interested listeners, such as the Task Elicitation
Service, receive the transmitted task events from the
User Observation Hub. On the basis of the received
task NOPs, the Task Elicitation Service transmits rel-
evance feedback to the Context Service and switches
both Context and History Service to the thread be-
longing to the current task. The History and Context
Service gain their data from the UOH and complete
the loop by providing information items for the PID
within ConTask.
The Task Elicitation Service only depends on the
task operations ontology and the assumptions on task-
oriented work that are utilized for the purpose of task
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
37

prediction. The History and Context Service only
depend on the NOP ontology formalizing the user’s
desktop activity. Thus, any task management appli-
cation that is compatible with the task operations on-
tology can be integrated into the created scenario re-
alizing the knowledge improvement cycle. Necessary
integration steps involve the extension of the system’s
user interface with observation calls to the Task Ob-
servation Service. If the task management application
includes a PID component and allows for agile task
modelling, the Context and History Service could be
utilized to proactively provide relevant, task-specific
PIMO elements to the user.
Feasibility Study. The current proof-of-concept
implementation of ConTask delivers early indications
that the system actually has the potential to assist the
user while keeping the additional work at a minimum.
In the long run, a robust context identification is es-
sential for keeping the assistance scalable: The con-
text identification algorithm is expected to estimate
the correct context in most of the cases. We created
a ground truth by tagging a large set of observed user
operations, manually assigning user actions to “con-
texts”. A ten-fold cross validation on this ground
truth data shows that 78% of the operations are iden-
tified correctly, 9% of the guesses were incorrect, and
13% of the cases were not identified at all. Striving
for a best-effort strategy, a relatively high number of
unidentified cases (13%) is not considered harmful for
the user’s actual work. An amount of 9% incorrect
context guesses is not very high, but this is a critical
value as false identifications may lead to false con-
text switch proposals and, hence, to disruptions of the
user. One cause for the false identifications is that the
user observation software does not recognize some of
the user operations. Additionally, users mentally sep-
arated some contexts which were technically identi-
cal. Additional sensors providing evidences for ad-
ditional contextual elements will reduce these prob-
lems. Hence, we will continuously enhance the user
observation and context elicitation technology.
5 SUMMARY AND OUTLOOK
This paper addressed challenges in today’s knowledge
work: continuously increasing quantities of infor-
mation, knowledge intensive tasks, and highly frag-
mented multitasking work scenarios.
The context-sensitive task management system
ConTask was designed to address these challenges
and alleviate the knowledge worker’s job. ConTask
is integrated into the Semantic Desktop and com-
bines task management with context-specific assis-
tance. The assistance is based on the combination of
user observation, automatic elicitation and proactive
information delivery of relevant information items
from the user’s PIMO. ConTask enables agile task
modelling for defining tasks on the fly and striving
for a task centric structuring of the personal knowl-
edge space. Observation of the user’s interaction with
ConTask is utilized for relevance feedback and auto-
matic task prediction to increase the precision of the
PID while keeping the required task management to a
minimum. Thereby, the system realizes a knowledge
improvement and learning cycle.
As ConTask is only capable of detecting task
switches to already existing tasks, a possible improve-
ment would be an algorithm for detecting the user is
working on a new task which is not yet reflected in
the system. Similarly, making proposals for refining a
task into subtasks based on the observations (e.g., by
detecting that involved resources of a task can be sep-
arated in two topic clusters but within the task). This
would significantly support agile task modelling.
We currently expand the observed area to the
physical desktop of a user by using a digital camera
and applying image recognition algorithms to recog-
nize user actions with paper documents on the desk
(Dellmuth et al., 2009). So far, recognizable actions
are placing, removing, and moving a paper document
on the desk as well as arranging a pile all enriching
the user context.
For getting better suggestions on PID, we cur-
rently investigate to embed the ontology-based infor-
mation extraction system iDocument to extract PIMO
entities in observed text snippets as well as to contex-
tualize with the PIMO as background knowledge as
it is done in the Nepomuk Semantic Desktop (Adrian
et al., 2009) and the TaskNavigator in (Rostanin et al.,
2009).
In the ADiWa project we will investigate the usage
of the PIMO-based user context for to realise dynamic
business processes.
ACKNOWLEDGEMENTS
This work has been partly funded by the German Fed-
eral Ministry of Education and Research (BMBF) in
the ADiWa project (01IA08006).
REFERENCES
Abecker, A., Hinkelmann, K., Maus, H., and Mller, H.-J.,
editors (2002). Geschftsprozessorientiertes Wissens-
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
38

management. xpert.press. Springer.
Adrian, B., Klinkigt, M., Maus, H., and Dengel, A.
(2009). Using idocument for document categorization
in nepomuk social semantic desktop. In Pellegrini,
T., editor, i-Semantics: Proceedings of International
Conference on Semantic Systems 2009, JUCS.
Czerwinski, M., Horvitz, E., and Wilhite, S. (2004). A diary
study of task switching and interruptions. In CHI’04:
SIGCHI conference on Human factors in computing
systems, pages 175–182. ACM.
Dellmuth, S., Maus, H., and Dengel, A. (2009). Support-
ing knowledge work by observing paper-based activ-
ities on the physical desktop. In 3rd Int. Workshop
on Camera Based Document Analysis and Recogni-
tion (CBDAR’09). Proceedings.
Elst, L. v., Aschoff, F.-R., Bernardi, A., Maus, H., and
Schwarz, S. (2003). Weakly-structured workflows
for knowledge-intensive tasks: An experimental eval-
uation. In IEEE WETICE Workshop on Knowledge
Management for Distributed Agile Processes (KM-
DAP’03). IEEE Computer Press.
Gonz
´
alez, V. M. and Mark, G. (2004). “Constant, constant,
multi-tasking craziness”: managing multiple working
spheres. In CHI’04: SIGCHI conference on Human
factors in computing systems, pages 113–120. ACM.
Gonz
´
alez, V. M. and Mark, G. (2005). Managing currents of
work: multi-tasking among multiple collaborations.
In ECSCW’05: 9th European Conference on Com-
puter Supported Cooperative Work, pages 143–162.
Grebner, O., Ong, E., and Riss, U. (2008). Kasimir - work
process embedded task management leveraging the
semantic desktop. In Multikonferenz Wirtschaftsinfor-
matik, pages 1715–1726.
Grimnes, G. A., Adrian, B., Schwarz, S., Maus, H., Schu-
macher, K., and Sauermann, L. (2009). Semantic
desktop for the end-user. i-com, 8(3):25–32.
Holz, H., Maus, H., Bernardi, A., and Rostanin, O. (2005).
From Lightweight, Proactive Information Delivery
to Business Process-Oriented Knowledge Manage-
ment. Journal of Universal Knowledge Management,
0(2):101–127.
Holz, H., Rostanin, O., Dengel, A., Suzuki, T., Maeda,
K., and Kanasaki, K. (2006). Task-based process
know-how reuse and proactive information delivery in
TaskNavigator. In CIKM’06. ACM Conference on In-
formation and Knowledge Management.
Iqbal, S. T. and Horvitz, E. (2007). Disruption and recov-
ery of computing tasks: field study, analysis, and di-
rections. In CHI’07: SIGCHI conference on Human
factors in computing systems, pages 677–686. ACM.
Lepouras, G., Dix, A., and Katifori, A. (2006). OntoPIM:
From personal information management to task infor-
mation management. In SIGIR’06 Personal Informa-
tion Management Workshop.
Lokaiczyk, R., Faatz, A., Beckhaus, A., and Goertz,
M. (2007). Modeling and Using Context, volume
4635/2007 of LNCS, chapter Enhancing Just-in-Time
E-Learning Through Machine Learning on Desktop
Context Sensors, pages 330–341. Springer.
Mark, G., Gonzalez, V. M., and Harris, J. (2005). No
task left behind?: examining the nature of fragmented
work. In CHI’05: SIGCHI conference on Human fac-
tors in computing systems, pages 321–330. ACM.
Mark, G., Gudith, D., and Klocke, U. (2008). The cost of
interrupted work: more speed and stress. In CHI’08:
SIGCHI conference on Human factors in computing
systems, pages 107–110. ACM.
Riss, U., Rickayzen, A., Maus, H., and van der Aalst, W.
(2005). Challenges for Business Process and Task
Management. Journal of Universal Knowledge Man-
agement, 0(2):77–100.
Rostanin, O., Maus, H., Zhang, Y., Suzuki, T., and Maeda,
K. (2009). Lightweight conceptual modeling and
concept-based tagging for proactive information de-
livery. Ricoh technology report 2009, no. 35, Ricoh
Co Ltd., Japan.
Sauermann, L., Bernardi, A., and Dengel, A. (2005).
Overview and Outlook on the Semantic Desktop. In
1st Workshop on The Semantic Desktop at ISWC’05,
volume 175 of CEUR Proceedings, pages 1–19.
Schwarz, S. (2006). A context model for personal knowl-
edge management applications. In Modeling and Re-
trieval of Context, Second Int. Workshop, MRC 2005,
volume 3946 of LNCS, pages 18–33. Springer.
Schwarz, S. (2010). Context-Awareness and Context-
Sensitive Interfaces for Knowledge Work Support.
PhD thesis, University of Kaiserslautern.
Schwarz, S., Kiesel, M., and van Elst, L. (2008). Adapting
the multi-desktop paradigm towards a multi-context
interface. In HCP-2008 Proc., Part II, MRC 2008
– 5th Int. Workshop on Modelling and Reasoning in
Context, pages 63–74. TELECOM Bretagne.
Stoitsev, T., Scheidl, S., Flentge, F., and Mhlhuser, M.
(2008). From personal task management to end-user
driven business process modeling. In Business Pro-
cess Management, volume 5240 of LNCS. Springer.
Stumpf, S., Bao, X., Dragunov, A., Dietterich, T. G., Her-
locker, J., and et al. (2005a). Predicting user tasks: I
know what you’re doing! 20th National Conference
on Artificial Intelligence (AAAI-05).
Stumpf, S., Bao, X., Dragunov, A., Dietterich, T. G., Her-
locker, J., Johnsrude, K., Li, L., and Shen, J. (2005b).
The TaskTracer system. 20th National Conference on
Artificial Intelligence (AAAI-05).
ConTask - Using Context-sensitive Assistance to Improve Task-oriented Knowledge Work
39
