
APPROXIMATE REASONING BASED ON LINGUISTIC
MODIFIERS IN A LEARNING SYSTEM
Saoussen Bel Hadj Kacem
National School of Computer Sciences, University campus Manouba, 2010, Manouba, Tunisia
Amel Borgi
National Institute of Applied Sciences and Technology, Centre Urbain Nord de Tunis, 1080, Tunis, Tunisia
Moncef Tagina
National School of Computer Sciences, University campus Manouba, 2010, Manouba, Tunisia
Keywords:
Approximate reasoning, Linguistic modifiers, Supervised learning, Classification rules, Multi-valued logic.
Abstract:
Approximate reasoning, initially introduced in fuzzy logic context, allows reasoning with imperfect knowl-
edge. We have proposed in a previous work an approximate reasoning based on linguistic modifiers in a
symbolic context. To apply such reasoning, a base of rules is needed. We propose in this paper to use a super-
vised learning system named SUCRAGE, that automatically generates multi-valued classification rules. Our
reasoning is used with this rule base to classify new objects. Experimental tests and comparative study with
two initial reasoning modes of SUCRAGE are presented. This application of approximate reasoning based on
linguistic modifiers gives satisfactory results. Besides, it provides a comfortable linguistic interpretation to the
human mind thanks to the use of linguistic modifiers.
1 INTRODUCTION
Most information expressed by human beings is un-
certain, vague or imprecise. However, these informa-
tion is necessary for the realization and the use of in-
telligent systems. In the literature, several approaches
have been proposed for the representation of these
types of knowledge, two of which dominate: fuzzy
logic (Zadeh, 1965) and multi-valued logic (Akdag
et al., 1992). To allow systems manipulating and
reasoning with imperfect knowledge, Zadeh (Zadeh,
1975) has introduced approximate reasoning concept
in the fuzzy logic context. This reasoning is based
on a generalization of Modus Ponens to fuzzy data,
known as Generalized Modus Ponens (GMP). It cor-
responds to the following schema:
If X is A then Y is B
X is A
′
Y is B
′
(1)
where X and Y are two variables and A , A
′
, B and
B
′
are predicates. Approximate reasoning can, not
only infer with an observation equivalent to the rule
premise A , but also with an observation A
′
which is
approximately equivalent to it.
In a previous work (Kacem et al., 2008; Borgi
et al., 2008), we noticed that both fuzzy and multi-
valued GMPs are generally based on the concept
of similarity (Akdag et al., 1992; Khoukhi, 1996;
Bouchon-Meunier et al., 1997). The weakness of this
type of reasoning is that it focuses on the modifica-
tion degree (the degree of similarity between A and
A
′
) and not to the way A has been modified to have
A
′
(weakening, reinforcement, etc.).
We also noted that the concept of linguistic mod-
ifiers reflects a form of similarity which can be used
in the GMP for the evaluation of the changes made on
the premise to lead to the conclusion. The diagram of
approximate reasoning based on linguistic modifiers
is as follows:
If X is A then Y is B
X is m(A )
Y is m
′
(B )
(2)
431
Bel Hadj Kacem S., Borgi A. and Tagina M. (2010).
APPROXIMATE REASONING BASED ON LINGUISTIC MODIFIERS IN A LEARNING SYSTEM.
In Proceedings of the 5th International Conference on Software and Data Technologies, pages 431-437
DOI: 10.5220/0002924204310437
Copyright
c
SciTePress

To determine the inference conclusion B
′
= m
′
(B ),
it is enough to determine the modifier m
′
. The lat-
ter is obtained based on the observed modifier m
(A
′
= m(A )) and the correlation intensity between the
premise and the rule’s conclusion.
To apply approximate reasoning, it is necessary to
have a base of rules. Two ways are possible to ob-
tain such a base. First, it can be directly provided
by the expert. Secondly it can be automatically built,
through the use of learning systems. In our work, we
choose to use the second solution, we used a clas-
sification system for automatic generation of rules,
called SUCRAGE (Borgi, 1999; Borgi and Akdag,
2001). This system generates classification multi-
valued rules, the context of our approximate reason-
ing (Kacem et al., 2008). A classification rule predicts
the class of a new object. For example, a patient is de-
scribed by a set of attributes such as age, sex, blood
pressure, etc, and the class could be a binary attribute
concluding or not the illness of the patient by a par-
ticular disease.
In this paper, we begin in section 2 by presenting
the symbolic multi-valued logic, the context of our
work. Then, section 3 deals with the concept of lin-
guistic modifiers. We present in section 4 the SU-
CRAGE system. Then, in section 5 we explain how
to adapt and apply approximate reasoning based on
linguistic modifiers on this system. Finally, before
concluding this work we present in section 6 a com-
parative study of experimental test results.
2 SYMBOLIC MULTI-VALUED
LOGIC
Multi-valued logic is a generalization of Boolean
logic. It provides truth values that are intermediate
between True and False. We denote by M the num-
ber of truth degrees in multi-valued logic. Akdag et
al. (Akdag et al., 1992) have introduced a new gen-
eration of multi-valent logic based on the theory of
multi-sets.
In symbolic multi-valued logic, each linguis-
tic term (such as large) is represented by a multi-
set (Akdag et al., 1992). To express the imprecision of
a predicate, a qualifier v
α
is associated to each multi-
set (such as rather, little, etc). When a speaker uses
a statement “X is v
α
A”, v
α
is the degree to which X
satisfies the predicate A
1
. A truth-degree τ
α
must cor-
respond to each adverbial expression v
α
so that:
1
Denoted mathematically by “X ∈
α
A”: the object X be-
longs with a degree α to a multi-set A.
X is v
α
A ⇐⇒ ”X is v
α
A” is true
⇐⇒ ”X is A” is τ
α
-true
For example, the statement “John is rather tall”
means that John satisfies the predicate tall with the
degree rather.
The set of symbolic truth-degrees forms an or-
dered list L
M
= {τ
0
,...,τ
i
,...,τ
M−1
}
2
with the total or-
der relation: τ
i
≤ τ
j
⇔ i ≤ j, its smallest element is
τ
0
(false) and the greatest is τ
M−1
(true). In practice,
the number of truth-degrees is often close to 7. The
expert can even propose his own list of truth-degrees;
the only restrictive condition is that they must be or-
dered.
3 GENERALIZED SYMBOLIC
MODIFIERS
A modifier is an operator that builds linguistic terms
from a primary linguistic term. This concept was in-
troduced by Zadeh (Zadeh, 1975) in the fuzzy logic
framework. We distinguish two types of fuzzy mod-
ifiers. First, reinforcing modifiers that reinforce the
notion expressed by the term (as very). Then weaken-
ing modifiers, which weaken the notion expressed by
the term (as more or less).
As already mentioned, we have used linguis-
tic modifiers in approximate reasoning process in
(Kacem et al., 2008; Borgi et al., 2008). Since our
work falls in multi-valued framework, we use modi-
fiers defined in this particular context.
A set of linguistic modifiers were proposed in the
multi-valued framework by Akdag and al. in (Akdag
et al., 2001), they were named the Generalized Sym-
bolic Modifiers. A Generalized Symbolic Modifier
(GSM) is a semantic triplet of parameters: radius,
nature (i.e dilated, eroded or preserved) and mode
(i.e reinforcing, weakening or central). The radius is
noted ρ with ρ ∈ IN
∗
.
Definition 1. Let us consider a symbolic degree τ
i
with i ∈ IN in a scale L
M
of a base M ∈ IN
∗
r {1},
and i < M. A GSM m with a radius ρ is denoted m
ρ
.
The modifier m
ρ
is a function which applies a linear
transformation to the symbolic degree τ
i
to obtain a
new degree τ
i
′
∈ L
M
′
(where L
M
′
is the linear trans-
formation of L
M
) according to a radius ρ such as:
m
ρ
: L
M
→ L
M
′
τ
i
7→ τ
i
′
A proportion is associated to each symbolic de-
gree within a base denoted Prop(τ
i
) =
i
M−1
.
2
With M a positive integer not null.
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
432
By analogy with fuzzy modifiers, the authors pro-
pose a classification of symbolic modifiers according
to their behavior: weakening and reinforcing mod-
ifiers, and they add the family of central modifiers
(Akdag et al., 2001) that neither reinforce nor weaken
the concept. The definitions of the reinforcing, weak-
ening and central modifiers are given in table 1
3
.
We have studied composition of these modifiers in
(Kacem et al., 2009).
4 THE LEARNING SYSTEM
SUCRAGE
To apply our approximate reasoning based on linguis-
tic modifiers, a rules base is needed. We used a learn-
ing system to obtain this base. SUCRAGE (SUper-
vised Classification by Rule Automatic GEneration)
is a supervised learning system which was proposed
by Borgi in (Borgi, 1999; Borgi and Akdag, 2001).
The construction of a classification function in
SUCRAGE is done through two phases: the learning
phase and the recognition or classification one (Borgi
et al., 2003; Borgi, 2006; Borgi et al., 2007).
4.1 Learning Phase
The rule base is generated thanks to a learning base: a
set of objects already classified. We denote by B
1
,...,
B
b
the classes defined by the experts, X
1
,..., X
t
the
attributes of the objects. The rules generated by SU-
CRAGE have the following form:
If X
e
1
is v
α
1
A and ... and X
e
n
is v
α
n
A then the class
is B
i
with p
where:
X
e
j
is v
α
j
A a proposition which means that the
value of X
e
j
is in [a,b]
X
e
j
an attribute, X
e
j
∈ {X
1
,...,X
t
}
[a,b] the sub-interval of index v
α
i
in the
field of X
e
j
A a multi-set for the attributes fields
B
i
the i
th
class
p a belief degree representing the
uncertainty of the conclusion
The interval [a,b] is a sub-interval of the field of
the attribute X
ej
. It is obtained by the a regular dis-
cretization of this field.
3
We have modified some definitions in order to respect
the bounds of M and i.
4.1.1 Construction of the Premise
To construct the rule premise, the first task consists on
determining what are the attributes to regroup. In SU-
CRAGE, the attributes that appear in a same premise
are the correlated ones. For that, a correlation ma-
trix C is calculated: C = (r
i, j
)
t×t
, with r
i, j
the linear
correlation coefficient between X
i
and X
j
.
Then, one considers that X
i
and X
j
are correlated if
the absolute value of r
i, j
is greater than a fixed thresh-
old θ.
One must then discretizes the attributes fields. In
this work, we retained the regular discretization: it
leads to M sub ranges denoted by v
0
, v
1
, ..., v
M−1
.
Condition parts of rules are then obtained by consid-
ering for each correlated components subset, a sub-
interval (v
i
) for each component in all possible com-
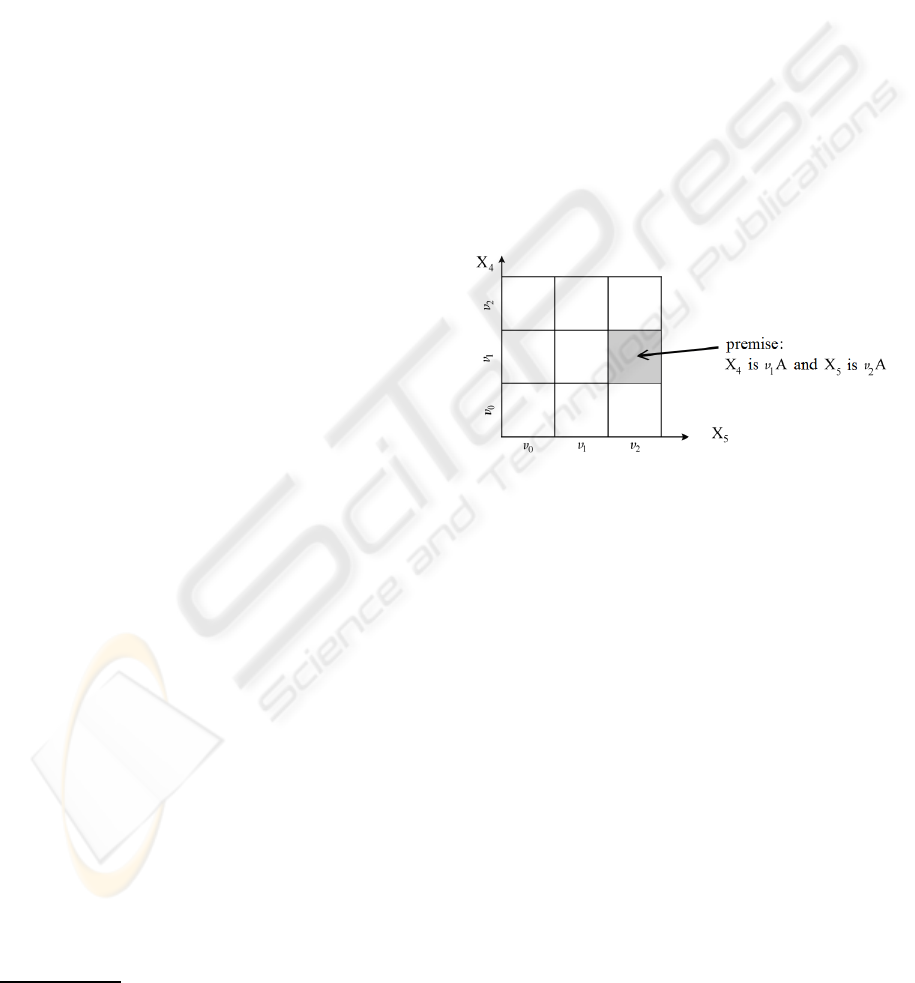
binations. Figure 1 illustrates such a partition in the
case of two correlated features with a subdivision size
M = 3.
Figure 1: Example of partition of the correlated attributes
space.
4.1.2 Construction of the Rule
Each constructed premise according to the method ex-
posed above conducts to the generation of b rules,
with b the number of classes. The last stage con-
sists in calculating this belief degree p, which can
be represented by the conditional probability to get
the conclusion when the premise is verified: p =
proba(premise/conclusion). Conditional probabili-
ties are estimated on the training set using a frequen-
tist approach.
4.2 Classification Phase
During the classification phase, the inference engine
associates a class to a vector representing an object
to classify. Two types of reasoning are used: an ex-
act reasoning and an approximate reasoning. For ex-
act inference, the used method is the classic one. It
consists on the use of the Modus Ponens. The ap-
proximate inference method applies the Generalized
Modus Ponens:
APPROXIMATE REASONING BASED ON LINGUISTIC MODIFIERS IN A LEARNING SYSTEM
433
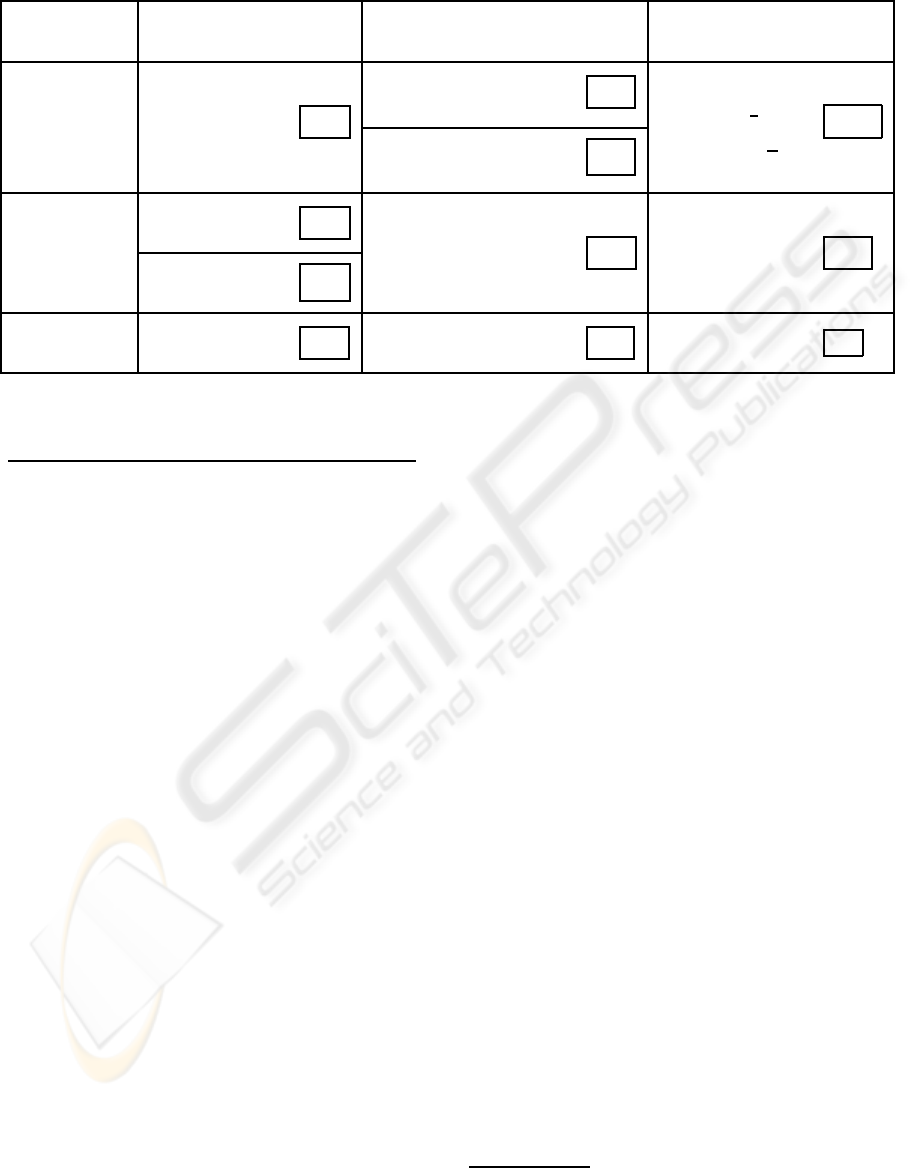
Table 1: Definitions of weakening, reinforcing and central modifiers.
MODE Weakening Reinforcing Central
NATURE
Erosion
τ
i
′
= τ
i
ER
ρ
τ
i
′
= τ
max(0,i−ρ)
EW
ρ
L
M
′
= L
max(2,i+1,M−ρ)
τ
i
′
= τ
max(⌊
i
ρ
⌋,1)
EC
ρ
*
L
M
′
= L
max(2,M−ρ)
τ
i
′
= τ
max(0,min(i+ρ,M−ρ−1))
ER
′
ρ
L
M
′
= L
max(⌊
M
ρ
⌋+1,2)
L
M
′
= L
max(2,M−ρ)
Dilation
τ
i
′
= τ
i
DW
ρ
L
M
′
= L
M+ρ
τ
i
′
= τ
i+ρ
DR
ρ
τ
i
′
= τ
iρ
DC
ρ
τ
i
′
= τ
max(0,i−ρ)
DW
′
ρ
L
M
′
= L
M+ρ
L
M
′
= L
Mρ−ρ+1
L
M
′
= L
M+ρ
Conservation
τ
i
′
= τ
max(0,i−ρ)
CW
ρ
τ
i
′
= τ
min(i+ρ,M−1)
CR
ρ
τ
i
′
= τ
i
CC
L
M
′
= L
M
L
M
′
= L
M
L
M
′
= L
M
* ⌊.⌋ is the floor function.
If “X
e
1
is v
α
1
A” and . . . and “X
e
n
is v
α
n
A” then the class is B
i
with p
“X
e
1
is v
γ
1
A” and ... and “X
e
n
is v
γ
n
A”
The class is B
i
with p
′
To be more precise in determining the distance be-
tween the premise and the observation in approximate
reasoning, the attributes values have undergone a dis-
cretization finer than exact reasoning, specifically M
2
instead of M.
The approach consists in using a 0+ order infer-
ence engine. The engine has to manage the rules’ un-
certainty and take it into account within the inference
dynamic. More precisely, for a new object O to clas-
sify, the inference engine allows to obtain a final be-
lief degree associated to each class. The final belief
degree is the result of a triangular co-norm applied on
the probabilities of the fired rules that conclude to this
considered class. Finally, the winner class associated
to the new object is the class where the final belief
degree is maximal.
5 INTEGRATION OF
LINGUISTIC MODIFIERS IN
SUCRAGE
The rule of Generalized Modus Ponens with linguis-
tic modifiers that we proposed in (Kacem et al., 2008),
and that we intend to use for classifying objects with
SUCRAGE, deals with multi-sets. However, the con-
clusion part of SUCRAGE rules contains a numerical
belief degree. To apply our GMP, the probability mea-
sure of class B
i
must be symbolic. In this section we
explain the adaptation made on SUCRAGE in order
to use our approximate reasoning based on linguistic
modifiers.
5.1 Symbolic Probability
In (Seridi and Akdag, 2001), the authors have defined
a symbolic probability theory. This theory is an alter-
native to the classical theory of probability, in the spe-
cial case where values of probabilities are symbolic
degrees of uncertainty. The authors used this proba-
bility in SUCRAGE in (Seridi et al., 2006), and this
by replacing the probability measure p of the rules
by a symbolic degree of uncertainty. With the spe-
cific notation of our work, the rules generated by SU-
CRAGE become of the form:
If X
e
1
is v
α
1
A
1
and ... and X
e
n
is v
α
n
A
n
then the
class is v
β
B
i
with B
i
a class and τ
β
4
the symbolic belief degree
associated with this class. Thus, a degrees scale has
been introduced to represent uncertainty L
M
p
com-
posed of M
p
degrees: L
M
p
= {τ
i
,i = 0, . . . , M
p
− 1}
totally ordered. The boundaries of these sub-intervals
are denoted a
0
, a
1
, ..., a
M
p
. Therefore, it is associated
with each probability measure p a symbolic degree of
uncertainty τ
i
.
The discretization of probability can be regular or
irregular. Seridi et al. (Seridi et al., 2006) chose to
use an irregular discretization to obtain a scale L
7
of
7 sub-intervals. The numerical probability is subdi-
vided as follows:
4
Let’s remind that τ
β
is the symbolic degree associated
to the linguistic expression v
β
.
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
434
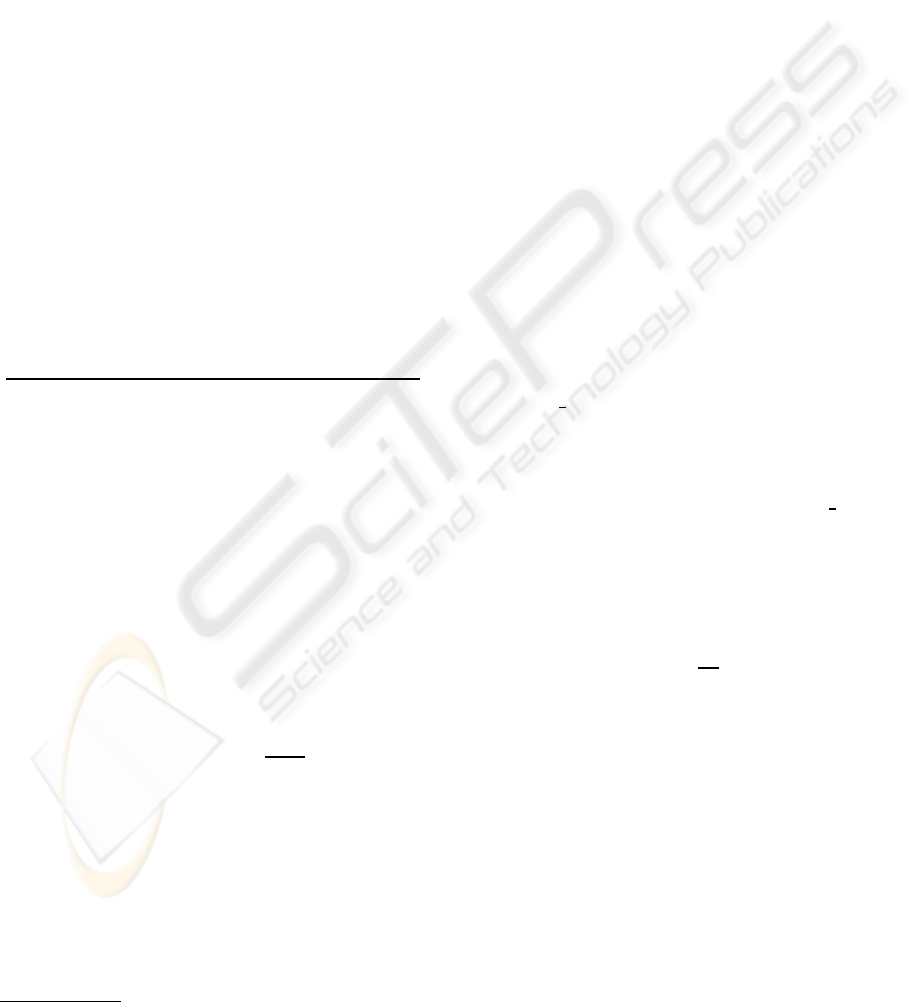
p = 0 ⇔ τ
0
⇔ Impossible
p ∈]0,0.5[ ⇔ τ
1
⇔ Very little possible
p ∈ [0.5,0.7[ ⇔ τ
2
⇔ Little possible
p ∈ [0.7,0.8[ ⇔ τ
3
⇔ Possible
p ∈ [0.8,0.9[ ⇔ τ
4
⇔ Enough possible
p ∈ [0.9,0.95[ ⇔ τ
5
⇔ Very possible
p ∈ [0.95,1] ⇔ τ
6
⇔ Certain
In this work, we use the irregular discretization, as
used by Seridi and al. (Seridi et al., 2006). In (Seridi
et al., 2006) symbolic probabilities are used in SU-
CRAGE with exact inference, unlike our work where
we are interested in approximate reasoning.
5.2 Conclusion Deduction
After building the rules, we have to exploit them. An
inference must be applied in order to classify new ob-
jects.
5.2.1 Simple Premise
Let us start with a simple case where the rule has a
simple premise. The corresponding rule of General-
ized Modus Ponens based on linguistic modifiers is as
follows:
Rule : If ”X
e
is v
α
A” then ”Y is v
β
B”
Fact : ”X
e
is m(v
α
A)”
Conclusion : ”Y is m
′
(v
β
B)”
The modifier m
′
to apply to the conclusion is ob-
tained according to the modifier m. The first step is to
determine the modifier m. As in the case of the orig-
inal approximate reasoning used in SUCRAGE, the
attributes subdivision cardinal in the rules premises is
M, while the one in the observations is M
2
. The pro-
posed solution is to first find the decomposition of the
modifier m with the dilating central DC operator. In-
deed, the observation base is a multiple of the premise
base, so it undergoes a dilatation. Let τ
γ
the member-
ship degree of the observation in the base L
M
2
, the
decomposition of the modifier m is given as follows:
m = m
ρ
1
◦ DC
ρ
2
with: ρ
1
= |γ− αρ
2
|
ρ
2
=
M
2
−1
M−1
= M+ 1
(3)
with m
ρ
1
an elementary modification operator of
radius ρ
1
. This operator m
ρ
1
may be eitherCW, CR or
CC, since it acts only on the truth degree
5
. Its choice
depends on the sign of (γ− α.ρ
2
). Thus:
m
ρ
1
=
CW
ρ
1
, if (γ− α.ρ
2
) < 0;
CR
ρ
1
, if (γ− α.ρ
2
) > 0;
CC, else.
(4)
5
The base is already dilated by the central operator DC.
The operator m
ρ
1
represents the real modification
made on the premise. Indeed, the DC operator is cen-
tral, so it acts as a zoom on the base and has no ef-
fect on the proportion of degrees. For this reason, the
operator m
ρ
1
which we denote by m
⋄
is the one that
we consider in determining the modifier m
′
to be de-
duced. The problem in that this operator is compatible
with the observations base L
M
2
. It can not be directly
applied to the symbolic probability, given that its base
is different from the base of the symbolic probability.
Thus, it is necessary to convert the modifier m
⋄
to be
compatible with the conclusion base L
M
p
. We pro-
pose to keep the same type of operator and change
only the radius ρ
1
.
The conversion of the modifier m
⋄
when the sym-
bolic probability is irregular is a complex task. In-
deed, the amplitudes of the probability sub-intervals
are different. For this reason, we propose a solu-
tion that takes into account these amplitudes. We as-
sociate with each symbolic probability degree τ
α
=
{α ∈ [0..M − 1]} a value called weight(τ
α
), which is
equal to the amplitude of the sub-interval number α.
The weight value is given by the following function:
weight : [0..M − 1] → [0,1]
α 7→ a
α+1
− a
α
with a
i
the discretization bounds. Then, the new
radius ρ
1
of formula (3) is obtained by the algorithm
conversion mod above. The principle of this algo-
rithm is to find the radius which causes the same mod-
ification percentage in the probability base L
M
p
that is
caused by the radius ρ
1
in the basis L
M
2
.
Algorithm 1. Begin of algorithm conversion mod.
• Input values:
– The radius ρ
1
of the modifier to translate;
– The symbolic probability degree to modify;
– The size of the base M
2
.
• The values to initialize:
– A real proportion ←
ρ
1
M
2
which represents the
proportion of the radius ρ
1
in the correspond-
ing base L
M
2
;
– A real compteurPoids ← 0, a weight counter.
• loop through the symbolic probability degrees
with a decrement, beginning with the degree to
modify. Until compteurPoids ≤ proportion, in-
crease compteurPoids by the weight of the current
degree.
• The new radius is equal to the degree to modify
minus the current degree minus 1.
End of algorithm.
Thus, with this algorithm we determine the radius
ρ
′
1
to use to modify the probability degree, ie: m
′
=
m
ρ
′
1
.
APPROXIMATE REASONING BASED ON LINGUISTIC MODIFIERS IN A LEARNING SYSTEM
435
5.2.2 Composed Premise
SUCRAGE generates rules whose premise consists
of a conjunction of propositions. Thus, the infer-
ence process can be achieved through the Generalized
Modus Ponens based on generalized linguistic modi-
fiers in the case of conjunctive rules. It is as follows:
If ”X
e
1
is v
α
1
A
1
” and ... and ”X
e
n
is v
α
n
A
n
” then ”Y is v
β
B”
”X
e
1
is m
1
(v
α
1
A
1
)” and .. . and ”X
e
n
is m
n
(v
α
n
A
n
)”
”Y is m
′
(v
β
B)”
The determination of m
i
is performed by the mod-
ifier determination method of simple rule, case that
we have described above. Thus, they must be oper-
ators of type CR, CW or CC. The deduced modifier
m
′
is determined by aggregating the modifiers m
i
. We
define for that an operator that aggregate modifiers.
In this application framework, the conclusion uncer-
tainty degree weakens when the observation moves
away from the premise. For this reason, we defined
an aggregator which is adaptable to the rules in the
SUCRAGE system:
A
S
(m
α
,m
′
β
) = CW
γ
so that τ
γ
= S(τ
α
,τ
β
) (5)
with:
m and m
′
: modifiers of type CR, CW or CC;
τ
α
, τ
β
and τ
γ
: symbolic degrees belonging to L
M
;
S: a T-conorm such as the Lukasiewicz T-conorm.
As in the original SUCRAGE, the rules triggered
are grouped by class. Then, the final symbolic belief
degree of each class is calculated, and that by aggre-
gating the belief degrees by the max T-conorm. Fi-
nally, the selected class is whose final belief degree is
the greater one.
6 EXPERIMENTAL STUDY
In this section, we first describe the extension done
on SUCRAGE, in order to integrate approximate rea-
soning with linguistic modifiers. Then, we present
experimental results obtained with this application.
As we noted earlier, to implement our approach,
we need to use symbolic probability as belief degree
of the rules. For this, we integrated into SUCRAGE,
in addition to numerical probability, a new type of be-
lief degrees: irregular symbolic probability.
To perform a comparative study on the classifi-
cation results, we used the learning set Iris. These
data are available on the server of the Irvine Univer-
sity of California
6
. This database consists of 150 ex-
amples represented by 4 numerical attributes (sepal
6
//ftp.ics.uci.edu/pub/machine-learning-databases/
lenth, sepal width, petal lenth, petal width). The ex-
amples are divided over 3 classes: Iris setosa, Ver-
sicolor and Virginica. The tests are made by 10-
folds cross-validation. We use different thresholds for
correlation and for discretization cardinals of the at-
tributes. We tested our approximate reasoning based
on linguistic modifiers with irregular symbolic prob-
abilities in Table 2.
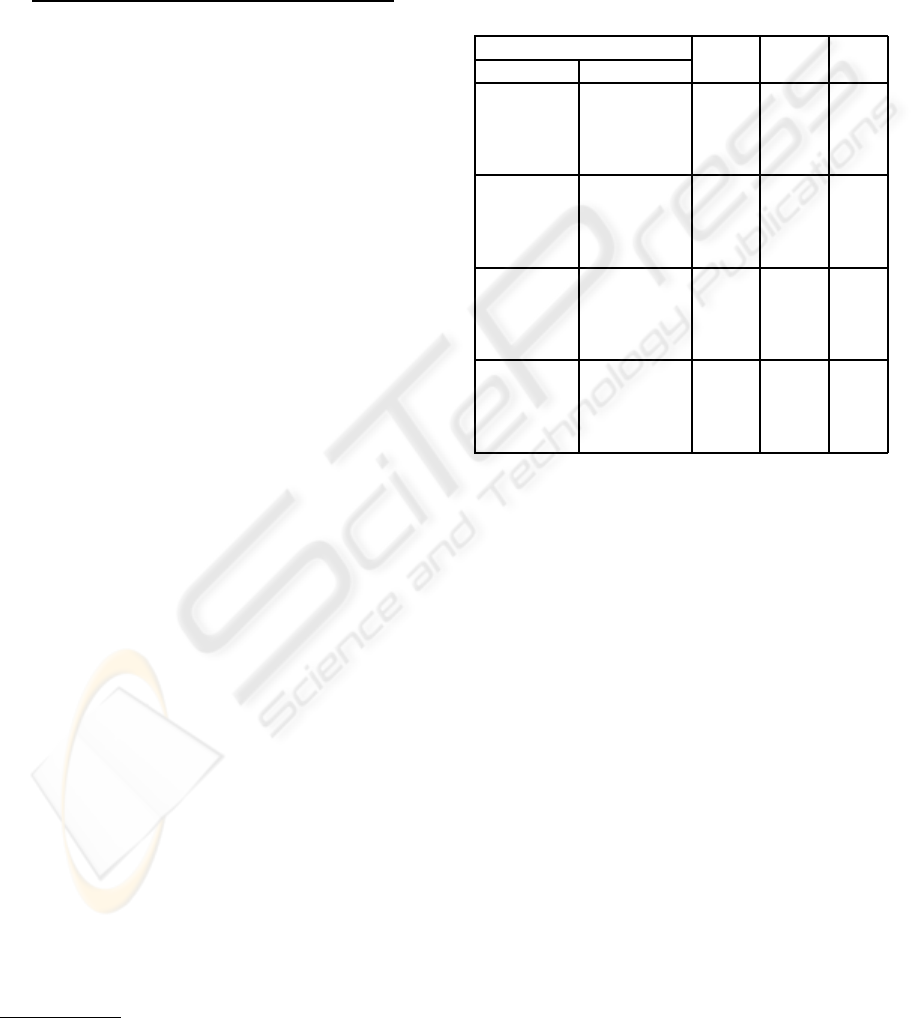
Table 2: Iris, comparative study of approximate reasoning
with irregular symbolic probability.
Subdivision size 3 5 7
threshold Reasoning
0.95 AR
is
98 93.33 96
AR
is
/ER
is
1 1 1.09
AR
is
/ER
n
1 1.01 1.08
AR
is
/AR
n
1 1.03 1.08
0.9 AR
is
98 93.33 96
AR
is
/ER
is
1 1 1.09
AR
is
/ER
n
1 1.01 1.08
AR
is
/AR
n
1 1.03 1.08
0.8 AR
is
97.33 95.33 98
AR
is
/ER
is
1 1.05 1.11
AR
is
/ER
n
1.01 1.05 1.13
AR
is
/AR
n
1.01 1 1.05
0.5 AR
is
97.33 95.33 98
AR
is
/ER
is
1 1.05 1.11
AR
is
/ER
n
1.01 1.05 1.13
AR
is
/AR
n
1.01 1 1.05
The ratio rows AR
is
/ER
is
gives the division of the
classification rate of approximative reasoning AR
is
by
whose of exact reasoning ER
is
with irregular sym-
bolic probability (corresponding to the subscript is).
We note that the approximate reasoning based on
linguistic modifiers gives a best results in all cases.
Moreover, it improves the results of exact reasoning
with irregular symbolic probability when the subdivi-
sion cardinal increases. This is because the variation
of this parameter introduces imperfections (Borgi and
Akdag, 2001). Indeed, approximate reasoning helps
to limit borders problems of the discretization: the
imperfections due to a high subdivision size are cor-
rected. The rate reaches at 98% for a subdivision of
7 which represents the best rates obtained by the SU-
CRAGE system.
We also compare our approximate reasoning to
the original exact and approximate reasoning of SU-
CRAGE. The ratio rows AR
is
/ER
n
and AR
is
/AR
n
present a comparison of our approximate reasoning
with respectively the original exact reasoning ER
n
and the original approximate reasoning AR
n
of SU-
CRAGE that is based on numerical probability (cor-
responding to the subscript n). We note through this
table that in all cases, the new version gives better re-
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
436

sults than the original version.
Approximate reasoning with linguistic modifiers
gives satisfactory results, moreover it presents a great
advantage with regard to the numerical approach. In-
deed, approximate reasoning with linguistic modi-
fiers can refine the interpretation of classification re-
sults. The original version of SUCRAGE is a numer-
ical approach, the results of objects assignments to
classes are provided through numerical probabilities.
On the other side, approximate reasoning with lin-
guistic modifiers is a linguistic approach which pro-
vides a linguistic interpretation of the results, allow-
ing readability and easy interpretation by the human
mind. Moreover, the use of approximate reasoning
is more advantageous when the data provided by the
experts are imprecise.
7 CONCLUSIONS
In this work, we have presented an application of ap-
proximate reasoning with linguistic modifiers that we
have defined in (Kacem et al., 2008; Borgi et al.,
2008). For this purpose, we have used a rule base
generated by a supervised learning system: SU-
CRAGE (Borgi, 1999). Some adaptations have been
made to this system in order to infer with our approx-
imate reasoning. More precisely, we have included
the use of symbolic probability (Seridi and Akdag,
2001) as belief degree of the generated rules. More-
over, we have defined an aggregator of modifiers in
order to aggregate the modifiers that transform the ob-
servation elements to the premise elements. We have
noticed that classification results were improved by
using our approximate reasoning based of linguistic
modifiers. This improvement was noticed in compar-
ison with the exact reasoning, as well as with the ap-
proximate reasoning introduced in (Borgi and Akdag,
2001). In addition, our approach provides a linguistic
interpretation through the use of linguistic modifiers.
It would be interesting to complete the validation tests
with other data, and more generally to consider an ap-
plication of our approximate reasoning on a base of
rules resulting from expert knowledge acquisition.
REFERENCES
Akdag, H., Glas, M. D., and Pacholczyk, D. (1992). A
qualitative theory of uncertainty. Fundam. Inform.,
17(4):333–362.
Akdag, H., Truck, I., Borgi, A., and Mellouli, N. (2001).
Linguistic modifiers in a symbolic framework. In-
ternational Journal of Uncertainty, Fuzziness and
Knowledge-Based Systems, 9(Supplement):49–61.
Borgi, A. (1999). Apprentissage supervis´e par g´en´eration
de r`egles : le syst`eme SUCRAGE. PhD thesis, Univer-
sit´e Paris 6, France.
Borgi, A. (2006). Approximate reasoning to learn classifi-
cation rules. In First International Conference on Soft-
ware and Data Technologies (ICSOFT), pages 203–
210.
Borgi, A. and Akdag, H. (2001). Knowledge based su-
pervised fuzzy-classification: An application to image
processing. Annals of Mathematics and Artificial In-
telligence, 32:67–86.
Borgi, A., Akdag, H., and Ghedjati, F. (2003). Using ge-
netic algorithms to optimize the number of classifica-
tion rules in sucrage. ACS/IEEE International Confer-
ence on Computer Systems and Applications, Tunis,
pages 110–116.
Borgi, A., Kacem, S. B. H., and Gh´edira, K. (2008).
Approximate reasoning in a symbolic multi-valued
framework. In Computer and Information Science,
volume 131 of Studies in Computational Intelligence,
pages 203–217. Springer.
Borgi, A., Lahbib, D., and Gh´edira, K. (2007). Optimiz-
ing the number of rules in a knowledge based classi-
fication system. In International Conference on Arti-
ficial Intelligence and Pattern Recognition, AIPR-07,
Orlando, Florida, USA, pages 185–192.
Bouchon-Meunier, B., Delechamp, J., Marsala, C., and
Rifqi, M. (1997). Several forms of fuzzy analogi-
cal reasoning. In IEEE International Conference on
Fuzzy Systems, pages 45–50, Barcelone, Spain.
Kacem, S. B. H., Borgi, A., and Gh´edira, K. (2008). Gener-
alized modus ponens based on linguistic modifiers in
a symbolic multi-valued framework. In Proceeding of
the 38th IEEE International Symposium on Multiple-
Valued Logic, pages 150–155, Dallas, USA.
Kacem, S. B. H., Borgi, A., and Tagina, M. (2009). On
some properties of generalized symbolic modifiers
and their role in symbolic approximate reasoning. In
ICIC - Emerging Intelligent Computing Technology
and Applications. Lecture Notes in Computer Science,
volume 5755, pages 190–208.
Khoukhi, F. (1996). Approche logico-symbolique
dans le traitement des connaissances incertaines et
impr´ecises dans les syst`emes `a base de connaissances.
PhD thesis, Universit´e de Reims, France.
Seridi, H. and Akdag, H. (2001). Approximate reason-
ing for processing uncertainty. Journal of Advanced
Computational Intelligence and Intelligent Informat-
ics, 5(2):110–118.
Seridi, H., Akdag, H., Mansouri, R., and Nemissi, M.
(2006). Approximate reasoning in supervised classi-
fication systems. Journal of Advanced Computational
Intelligence and Intelligent Informatics, 10(4):586–
593.
Zadeh, L. A. (1965). Fuzzy sets. Information and Control,
8(3):338–353.
Zadeh, L. A. (1975). The concept of a linguistic variable
and its application to approximate reasoning - i - ii -
iii. Information Sciences, pages 8:199–249, 8:301–
357, 9:43–80.
APPROXIMATE REASONING BASED ON LINGUISTIC MODIFIERS IN A LEARNING SYSTEM
437
