
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM
Ana Cristina Palacios-Garc´ıa, Ang´elica Mu˜noz-Mel´endez and Eduardo F. Morales
National Institute for Astrophysics, Optics and Electronics
Luis Enrique Erro No. 1, Santa Mar´ıa Tonantzintla, Puebla, Mexico
Keywords:
Robotics and automation mobile robots and autonomous systems, Vision, Recognition and reconstruction,
Network robotics.
Abstract:
Autonomous learning of objects using visual information is important to robotics as it can be used for local
and global localization problems, and for service tasks such as searching for objects in unknown places. In
a robot team, the learning process can be distributed among robots to reduce training time and produce more
accurate models. This paper introduces a new learning framework where individual representations of objects
are learned on-line by a robot team while traversing an environment without prior knowledge on the number
or nature of the objects to learn. Individual concepts are shared among robots to improve their own concepts,
combining information from other robots that saw the same object, and to acquire a new representation of an
object not seen by the robot. Since the robots do not know in advance how many objects they will encounter,
they need to decide whether they are seeing a new object or a known object. Objects are characterized by
local and global features and a Bayesian approach is used to combine them, and to recognize objects. We
empirically evaluated our approach with a real world robot team with very promising results.
1 INTRODUCTION
The design of robot teams is a very active research do-
main in the mobile robotics community. Robot teams
have effectively emerged as an alternative paradigm
for the design and control of robotic systems because
of the team’s capability to exploit redundancy in sen-
sing and actuation.
The research on robot teams has focused on de-
veloping mechanisms that enable autonomous robots
to perform collective tasks, such as strategies for co-
ordination and communication (Asada et al., 1994;
Matari´c, 1997); exploration, mapping and deploy-
ment (Howard et al., 2006); sensing, surveillance and
monitoring (Parker, 2002); and decentralized decision
making (Wessnitzer and Melhuish, 2003). In these
works, a robot team can reduce time to complete a
complex task that is allocated among its members.
Despite constant research on the design of robot
teams, very little attention has been paid so far to the
development of robot teams capable of learning from
their interaction with their environment. In addition
to their capability for accelerated learning, learning
robot teams can be used to acquire a much richer and
varied information compared to the information ac-
quired by single learning robots.
Learning is a key issue to achieve autonomy for
both, single robot and robot teams. Learning capa-
bilities can provide robots flexibility and adaptation
needed to cope with complex situations. In the con-
text of robot teams, the most common machine learn-
ing approach has been reinforcement learning, where
the idea is to learn optimal policies using a set of
robots to improve the coordination of individual ac-
tions in order to reach common goals (Asada et al.,
1994; Matari´c, 1997; Parker, 2002; Fern´andez et al.,
2005).
In this work we use visual information to learn,
with a team of robots, descriptions of objects placed
in a particular environment. Learning to recognize
particular objects in an environment is important for
robotics as it can be used for local and global local-
ization tasks as well as for simple service tasks such
as searching for objects in unknown places. Contrary
to previous approaches, in our learning setting, the
robots are not told the number or nature of the objects
to be learned.
Vision is a primary source of perception in
robotics and provides different features that can be
used to classify objects. In general, using a particu-
lar set of features can be adequate for particular tasks
but inadequate for other tasks. In this work, objects
are characterized by two complementary features: (i)
SIFT features (Lowe, 2004) and (ii) informationabout
79
Palacios-García A., Muñoz-Meléndez A. and F. Morales E. (2010).
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM.
In Proceedings of the 7th International Conference on Informatics in Control, Automation and Robotics, pages 79-88
DOI: 10.5220/0002952800790088
Copyright
c
SciTePress

the silhouettes of objects. Other features could be
used as well, but the main objective in this work is to
show the different cases and possible confusions that
can arise in the recognition of objects and merging of
concepts, and how they can be addressed.
Numerous difficulties arise in robot teams when
learning as well as sharing concepts that represent
concrete objects. Some of these issues are discussed
by Ye and Tostsos (1996) and include, how do robots
represent their local views of the world, how is the
local knowledge updated as a consequence of the
robot’s own action, how do robots represent the local
views of other robots, and how do they organize the
knowledge about themselves and about other robots
such that new facts can be easily integrated into the
representation. This article addresses the individual
and collective representation of objects from visual
information using a team of autonomous robots.
The rest of the paper is organized as follows. Sec-
tion 2 reviews related work. Sections 3 y 4 describe,
respectively, the stages of individual learning and col-
lective learning of concepts. Section 5 describes our
experimental results, and Section 6 provides conclu-
sions and future research work.
2 RELATED WORK
Interesting experiments where physical mobile robots
learn to recognize objects from visual information
have been reported. First we review significant work
developed for individual learning, and then we review
learning approaches developed for robot teams.
Steels and Kaplan (2001) applied an instance-
based method to train a robot for object recognition
purposes. In this work objects are represented by
color histograms. Once different representations have
been learned from different views of the same object,
the recognition is performed by classifying new views
of objects using the KNN algorithm (Mitchell, 1997).
Ekvall et al. (2006) used different learning tech-
niques to acquire automatically semantic and spatial
information of the environment in a service robot sce-
nario. In this work, a mobile robot autonomously
navigates in a domestic environment, builds a map,
localizes its position in the map, recognizes objects
and locates them in the map. Background sub-
traction techniques are applied for foreground ob-
jects segmentation. Then objects are represented
by SIFT points (Lowe, 2004) and an appearance-
based method for detecting objects named Receptive
Field Co-occurrence Histograms (Ekvall and Kragic,
2005). The authors developed a method for active ob-
ject recognition which integrates both local and global
information of objects.
In the work of Mitri et al. (2004), a scheme for
fast color invariant ball detection in the RoboCup con-
text is presented. To ensure the color-invariance of
the input images, a preprocessing stage is first applied
for detecting edges using the Sobel filter, and specific
thresholds for color removal. Then, windows are ex-
tracted from images and predefined spatial features
such as edges and lines are identified in these win-
dows. These features serve as input to an AdaBoost
learning procedure that constructs a cascade of clas-
sification and regression trees (CARTs). The sys-
tem is capable of detecting different soccer balls in
RoboCup and other environments. The resulting ap-
proach is reliable and fast enough to classify objects
in real time.
Concerning the problem of collective learning of
objects using robot teams there are, as far as we know,
very few works. Montesano and Montano (2003) ad-
dress the problem of mobile object recognition based
on kinematic information. The basic idea is that if
the same object is being tracked by two different
robots, the trajectories and therefore the kinematic in-
formation observed by each robot must be compati-
ble. Therefore, location and velocities of moving ob-
jects are the features used for object recognition in-
stead of features such as color, texture, shape and size,
more appropriate for static object recognition. Robots
build maps containing the relative position of moving
objects and their velocity at a given time. A Bayesian
approach is then applied to relate the multiple views
of an object acquired by the robots.
In the work of O’Beirne and Schukat (2004), ob-
jects are represented with Principal Components (PC)
learned from a set of global features extracted from
images of objects. An object is first segmented and
its global features such as color, texture, and shape are
then extracted. Successive images in a sequence are
related to the same object by applying a Kalman fil-
ter. Finally, a 3D reconstructed model of an object is
obtained from the multiple views acquired by robots.
For that purpose, a Shape From Silhouette based tech-
nique (Cheung et al., 2003) is applied.
In contrast to previous works, in our method each
member of the robot team learns on-line individual
representations of objects without prior knowledge on
the number or nature of the objects to learn. Indi-
vidual concepts are represented as a combination of
global and local features extracted autonomously by
the robots from the training objects. A Bayesian ap-
proach is used to combine these features and used for
classification. Individual concepts are shared among
robots to improve their own concepts, combining in-
formation from other robots that saw the same object,
ICINCO 2010 - 7th International Conference on Informatics in Control, Automation and Robotics
80

and to acquire a new representation of an unnoticed
object.
3 INDIVIDUAL LEARNING OF
CONCEPTS
The individual concepts are learned on-line by a robot
team while traversing an environment without prior
knowledge on the number or nature of the objects to
learn. The individual learning of concepts consists
of tree parts: object detection, feature extraction and
individual training.
Individual concepts of objects are represented by
Principal Component (PC) over the information about
the silhouettes of objects and Scale Invariant Features
(SIFT). Learned concepts are shared among robots.
3.1 Object Detection
Robots move through an environment and learn des-
criptions of objects that they encountered during na-
vigation. Objects are detected using background
substraction. In this paper we assume a uniform and
static background. We performed morphological o-
perations (closing - erode) to achieve better segmen-
tation. Once an object is detected, it is segmented and
scaled to a fixed size, to make the global PC features
robust to changes in scale and position.
3.2 Feature Extraction and Individual
Training
The segmented objects are grouped autonomously by
the robots in sets of images containing the same ob-
ject. Robots assume that they are observing to the
same object while it can be detected, and they finish
to see it when they can not detect objects in the cap-
tured images. Only one object can be detected in an
image at the same time. For each set of images, the
robot obtains an individual concept that represents the
object.
Training using Global Features. We applied Prin-
cipal Component Analysis (PCA) over the average
silhouettes that are automatically extracted from the
set of images of a particular object. The average pro-
vides a more compact representation of objects and
reduces segmentation errors. Figure 1 (a) shows an
object used in the training phase, Figure 1 (b) shows
its silhouette, and Figure 1 (c) illustrates the average
silhouette obtained from a set of images that represent
the object of Figure 1 (a). Once the robot has obtained
(a) (b) (c)
Figure 1: Examples of the silhouette (b) and average silhou-
ette (c) of an object (a).
Figure 2: Examples of the SIFT features extracted from a
set of images and the final set of SIFT features.
an average silhouette, this is added by the robot to a
set of known average silhouettes. After that, the robot
uses PCA to reduce the dimensionality of all average
silhouettes learned to get the PC features that repre-
sent them.
Training using Local Features. Each robot ex-
tracts local SIFT features of each image of the set of
images, and groups them in a final set which contains
all the different SIFT features that represent an object.
In Figure 2 we show an example of the SIFT points
obtained from a set of images of a vase and the final
set of SIFT points obtained. The PC features and the
SIFT features represent the individual concept of the
observed object.
3.3 Sharing Concepts
The concepts learned by robots are shared among
them to achieve collective learning. This can be done
off-line or on-line. In the case of collective off-line
learning the robots share their individual concepts
once they have learned all the training objects. On
the other hand, in the collective on-line learning the
robots share their individual concept as soon as a new
object is learned.
4 COLLECTIVE LEARNING OF
CONCEPTS
Collective learning of concepts enables robots to
improve individual concepts combining information
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM
81

from other robots that saw the same object, and to ac-
quire a new representation of an object not seen by the
robot. Therefore, a robot can learn to recognize more
objects of what it saw and can improve their own con-
cepts with additional evidence from other robots.
A robot has to decide whether the concept shared
by another robot is of a new object or of a previously
learned concept. A robot can face three possibilities:
coincident, complementary or confused information.
The shared concepts are fused depending on the kind
of information detected, as described below.
4.1 Pre-analysis of Individual Concepts
The concept learned by a robot is defined as follows:
C
i
k
=
Sil
i
k
, SIFT
i
k
(1)
where C
i
k
is the concept k learned by robot i, Sil
i
k
is
the average silhouette, and SIFT
i
k
is the set of SIFT
features that form the concept k.
In order to determine if a shared concept is pre-
viously known or not to a robot, it evaluates the pro-
babilities that the PC features and SIFT features are
previously known by the robot. The probability vec-
tors of PC features calculated by robot i, v
i
P
, indi-
cate the probability that a concept shared by robot
j, C
j
k
, is similar to the concepts known by robot i,
C
i
1
, . . . ,C
i
numObjs
, given the global features. numObjs
is the number of concepts of objects known by robot
i. The process to obtain the probability vector PC is
described as follows:
- A temporal training set of silhouettes is formed by
adding the average silhouettes of concepts known by
robot i or actual robot, Sil
i
1
, ..., Sil
i
numObjs
, and the a-
verage silhouette of the shared concept Sil
j
k
.
- The PCA is trained using the temporal set of average
silhouettes. The projection of the average silhouettes
know by robot i is obtained as a matrix of projections,
matProys. The projection of the average silhouette
Sil
j
k
is obtained in a vector, vectProys.
- The Euclidean distance (dE) is calculated between
each vector of the matrix matProys and the vector
vectProys as shown in formula 2, i.e, we obtain the
distance between all the projections already computed
and the projection of the new silhouette.
dE
i
l
=
v
u
u
t
nEigens
∑
r=1
(matProys
(l,r)
− vectProys
(1,r)
)
2
(2)
where nEigens is the number of eigenvectors used
during the PCA training (nEigens = numOb js
i
− 1),
and l is the index of the distance vector, where the
maximum size of the vector dE
i
is numObjs
i
.
- The distance value dE
i
is divided by a maximum dis-
tance value, ThresholdMax, determined experimen-
tally to obtain a similarity metric also called the pro-
bability vector v
i
P
as shown in formula 3.
v
i
P
l
= 1 −
dE
i
l
ThresholdMax
(3)
If dE
i
l
is bigger than the ThresholdMax value, then
the probability will be fixed as shown in formula 4,
which indicates that the projections of the object j and
the one of the object i are completely different.
v
i
P
l
=
1
numObjs
(4)
The value of the SIFT similarity metric also called
the probability vector SIFT at the position v
i
S
l
, is
obtained calculating the number of coincident SIFT,
n
coin
, between the individual SIFT concept SIFT
i
l
learned by robot i, and the individual SIFT concept
SIFT
j
k
shared by robot j. If the number n
coin
is big-
ger than an average of coincidences determined ex-
perimentally, AverageCoin, then the probability will
be fixed to v
i
S
l
= 1.0, which means that both concepts
contain the same local features SIFT. In other case,
the probability will be calculated using formula 5.
v
i
S
l
=
n
coin
AverageCoin
(5)
The constant AverageCoin represents the average
of coincidences between two sets of SIFT points of
the same object from different perspectives.
4.2 Analysis and Fusion of Individual
Concepts
This section describes how to detect if the shared con-
cept is coincident, complementary or confused, and
how the individual concepts are fused to form collec-
tive concepts depending on the kind of detected con-
cept.
4.2.1 Coincident Concepts
A coincident concept is detected when two or more
robots of the robot team learned individual concepts
from similar views of the same object. A shared con-
cept is classified as coincident if v
i
P
l
≥ α and v
i
S
l
≥ α.
That is, if both probabilities (PC and SIFT) of a pre-
viously learned concept are greater than a predefined
threshold value (α). If a shared concept is determined
as coincident it is merged with the most similar known
concept as follows:
ICINCO 2010 - 7th International Conference on Informatics in Control, Automation and Robotics
82

PCA Fusion. It is obtained by evaluating a new a-
verage silhouette from the average of the known Sil
i
l
and new Sil
j
k
silhouettes. After that, it is necessary to
re-train the PCA substituting the concept Sil
i
l
with the
new average silhouette which contains information of
the concept learned by robot j.
SIFT Fusion. It is obtained by adding the comple-
mentary SIFT points of concept SIFT
j
k
to the set of
SIFT points of concept SIFT
i
l
. Also, each pair of
coincident SIFT points of both concepts is averaged
in terms of position and their correspondingSIFT des-
criptors.
The main idea to fuse individual concepts is to im-
prove their representation.
4.2.2 Complementary Concepts
A concept C
j
k
contains complementary information
if it differs with all known concepts by robot i, i.e.,
if both shape and local features are different to all
known concepts by robot i, C
i
1
, . . . ,C
i
numObjs
. That is,
if v
i
P
< α and v
i
S
< α.
A complementary concept C
j
k
is fused with the
collective concepts known by the robot i as follows:
PCA Fusion. The new average silhouette is added
and the new PC concepts are obtained by re-training
the PCA using the updated set of average silhouettes.
SIFT Fusion. The new SIFT features are simple
added to the current set of SIFT concepts known by
the robot i.
4.2.3 Confused Concepts
There are two types of confusion that can occur bet-
ween concepts:
Different Shape and Similar Local Features (type
1). This type of confusion occurs when the new con-
cept C
j
k
is complementary by shape, Sil
j
k
, to all the
concepts known by the robot i, Sil
i
1
, ..., Sil
i
numObjs
i
but
it is coincident by local SIFT features, SIFT
j
k
, with
at least one concept known by the robot i. That is,
v
i
S
l
≥ α and if v
i
P
< α.
Similar Shape and Different Local Features (type
2). This type of information occurs when concept
C
j
k
is coincident by shape, Sil
j
k
, to at least one concept
known by the robot i, but it is complementary using
its local SIFT features, SIFT
j
k
. That is, if v
i
P
l
≥ α and
v
i
S
< α.
In both types of confusion, type 1 or type 2, there
can be two options:
a) Different Objects. Both concepts correspond to
different objects.
b) Same Object. Both concepts correspond to the
same object but they were learned by robots from
different points of view.
In our current approach, both types of confusions
are solved as complementary objects. The reason is
that robot i cannot distinguish with its current infor-
mation between both, differentobjects or same object,
using only the individual and the shared concepts. To
solve the ambiguity, as future work each robot should
build autonomously a map and locate its position in
the map. In addition, for each learned object, robots
will locate them in the map. For confused objects a
robot can move to the position of the object marked
in the map to see the object from different perspec-
tives in order to solve the conflict.
5 EXPERIMENTS AND RESULTS
We performed several experiments to demonstrate the
proposed algorithm. In section 5.1, we show the re-
sults of a general experiment that demonstrates the
main features of the proposed approach. In section
5.2 we present the accuracy of the collective concepts
versus the individual concepts.
In these experiments we used a robot team con-
sisting of two homogeneous Koala robots equipped
with a video camera of 320× 240 pixels. For more
than two robots our method can be applied straight-
forward. The only difference is that robots will need
to consider the information from more than one robot,
possibly reducing confused concepts.
5.1 Concept Acquisition and Testing
The mobile robots learn on-line a representation of
several objects while following a predefined trajec-
tory without prior knowledge on the number or nature
of the objects to learn. The idea of using pre-planned
trajectories instead of making the robots wandering
randomly, is that we can control the experimental
conditions to show different aspects of the proposed
methodology.
Each robot shares its individual concept as soon as
it is learned to improve the representation of this con-
cept or to include a new concept in the other robot.
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM
83
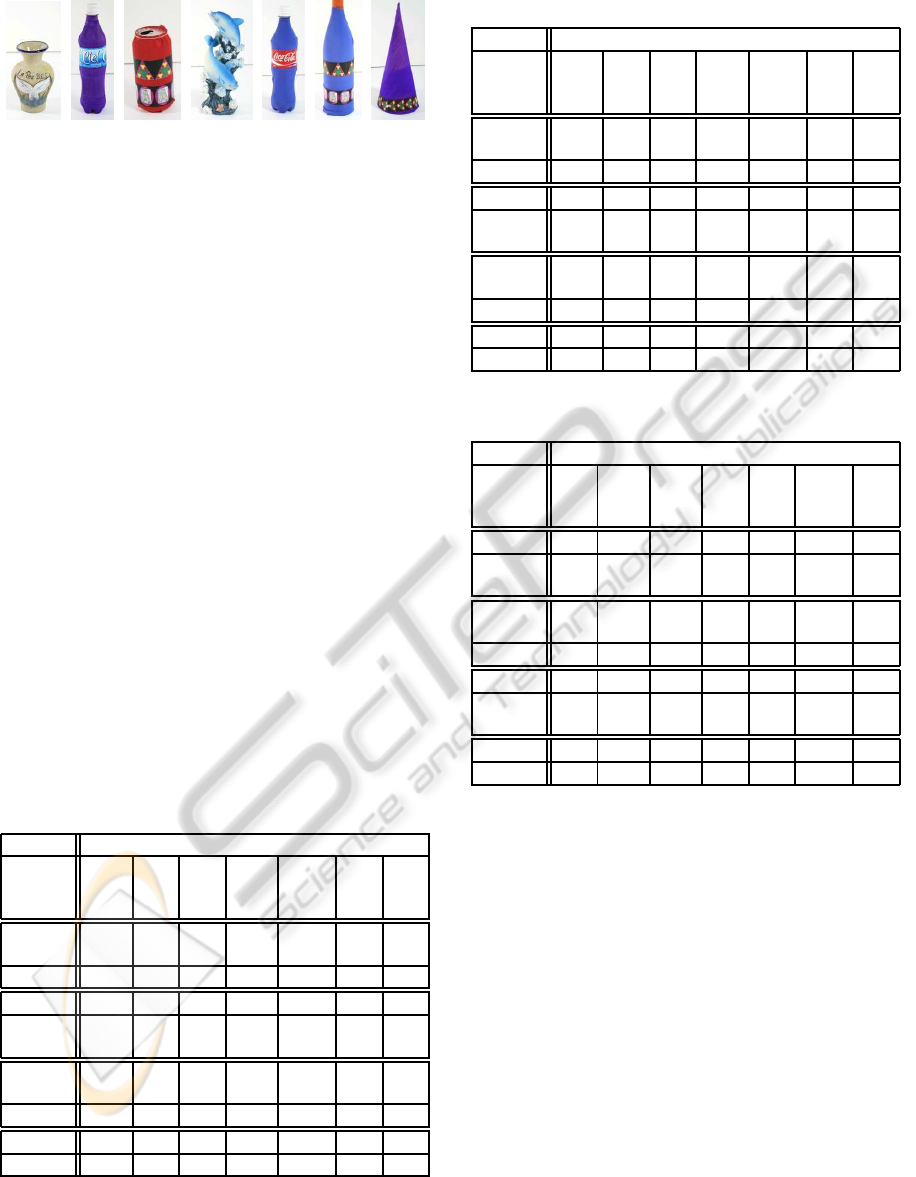
(a) (b) (c) (d) (e) (f) (g)
Figure 3: Training objects. a) vase, b) water bottle, c) can,
d) dolphin, e) soda bottle, f) bottle and g) cone.
Figure 3 shows the training objects used in this ex-
periment. As can be seen in the figure, some objects
have the same shape but different texture, some have
the same texture but different shape, some others are
not symmetric in their shape. The objective of this
experiment is to show the performance of the system
to detect coincident, complementary and confused in-
formation under a wide variety of conditions.
Robot 1 (R1) learned during individual training
concepts for: dolphin, can, water bottle and vase.
Robot 2 (R2) learned individual concepts for: vase,
soda bottle, bottle and cone. Note that some ob-
jects are learned by both robots while others are only
learned by one robot.
While learning a new concept, each robot has to
decide whether to fuse the current concept with a pre-
viously known concept or include it as a new one. Ta-
bles 1 and 2 show the probability vectors of the PC
features based on shape (v
1
P
) and of the SIFT features
(v
1
S
) obtained by Robot 1. Tables 3 and 4 show the
probability vectors of the PC (v
2
P
) and SIFT (v
2
S
) fea-
tures obtained by Robot 2. In these tables the coinci-
dent information is represented in bold.
Table 1: Probability vectors PC (v
1
P
) obtained by R1.
New (collective concepts R1)
Objects Dol-
phin
Vase Can Soda
bot-
tle
Water
bot-
tle
Bot-
tle
Co-
ne
Dol-
phin
R1
- - - - - - -
Vase
R2
0.19 - - - - - -
Can
R1
0.31 0.26 - - - - -
Soda
bottle
R2
0.36 0.28 0.58 - - - -
Water
bottle
R1
0.43 0.28 0.53 0.73 - - -
Bottle
R2
0.31 0.17 0, 56 0.61 0.58 - -
Vase
R1
0.25 0.69 0.42 0.43 0.41 0.32 -
Cone
R2
0.31 0.01 0.28 0.28 0.33 0.43 -
We used the defined criteria in Section 4.2 to
recognize coincident, complement or confused con-
Table 2: Probability vectors SIFT (v
1
S
) obtained by R1.
New (collective concepts R1)
Objects Dol-
phin
Vase Can Soda
bot-
tle
Water
bot-
tle
Bot-
tle
Co-
ne
Dol-
phin
R1
- - - - - - -
Vase
R2
0.09 - - - - - -
Can
R1
0.12 0.12 - - - - -
Soda
Bottle
R2
0.28 0.11 0.40 - - - -
Water
bottle
R1
0.15 0.59 0.20 0.20 - - -
Bottle
R2
0.08 0.15 0.65 0.04 0.12 - -
Vase
R1
0.16 1.00 0.23 0.10 0.08 0.09 -
Cone
R2
0.05 0.28 0.43 0.10 0.14 0.09 -
Table 3: Probability vectors PC (v
2
P
) obtained by R2.
New (collective concepts R2)
Objects Vase Dol-
phin
Soda
bot-
tle
Can Bot-
tle
Water
bot-
tle
Co-
ne
Vase
R2
- - - - - - -
Dol-
phin
R1
0.19 - - - - - -
Soda
bottle
R2
0.28 0.36 - - - - -
Can
R1
0.26 0.31 0.58 - - - -
Bottle
R2
0.17 0.31 0.61 0.56 - - -
Water
bottle
R1
0.29 0.44 0.73 0.54 0.58 - -
Cone
R2
0.01 0.31 0.28 0.28 0.43 0.33 -
Vase
R1
0.69 0.25 0.43 0.42 0.32 0.41 0.01
cepts, with α = 0.65 as threshold value, and the
probability vectors of Tables 1, 2, 3 and 4.
Tables 5 and 6 show the results of the analysis per-
formed by each robot. As can be seen from these ta-
bles, each robot encountered the three types of possi-
ble information and fuse its concepts accordingly.
For instance, Table 1 shows how are the probabi-
lities of objects of R1 affected using only PCA over
shapes of objects, as both robots encounter and learn
concepts while traversing the environment. In the first
row, R1 learns about the concept dolphin and acquires
it. In the second row, R2 then learns about vase and
shares this concept to R1. The probability, according
to the PCA features to be a dolphin is 0.19 (second
row). R1 learns the object can, which has a probabi-
lity of 0.31 to be a dolphin and a probability of 0.26
to be a vase, which was learned by R2 and shared to
R1 (third row). In the fifth row, R1 learns about a wa-
ter bottle but it confuses with the soda bottle learned
ICINCO 2010 - 7th International Conference on Informatics in Control, Automation and Robotics
84

Table 4: Probability vectors SIFT (v
2
S
) obtained by R2.
New (collective concepts R2)
Objects Vase Dol-
phin
Soda
bot-
tle
Can Bot-
tle
Water
bot-
tle
Co-
ne
Vase
R2
- - - - - - -
Dol-
phin
R1
0.18 - - - - - -
Soda
bottle
R2
0.11 0.28 - - - - -
Can
R1
0.12 0.12 0.04 - - - -
Bottle
R2
0.15 0.08 0, 04 0.64 - - -
Water
bottle
R1
0.59 0.15 0.20 0.20 0.12 - -
Cone
R2
0.09 0.05 0.10 0.43 0.09 0.14 -
Vase
R1
1.00 0.16 0.10 0.23 0.09 0.08 0.12
Table 5: Detected information by R1 for each own and
shared individual concepts.
Individual
concepts
Related
objects
v
1
P
v
1
S
Kind of
info.
Dol-
phin
R1
- - - Comple-
mentary
Vase
R2
All l
(l = 1 to
numObj
1
)
v
1
P
(2,l)
<
0.65
v
1
S
(2,l)
<
0.65
Comple-
mentary
Can
R1
All l v
1
P
(3,l)
<
0.65
v
1
S
(3,l)
<
0.65
Comple-
mentary
Soda
bottle
R2
All l v
1
P
(4,l)
<
0.65
v
1
S
(4,l)
<
0.65
Comple-
mentary
Water
bottle
R1
Soda
bottle
v
1
P
(5,4)
=
0.73
v
1
S
(5,i)
<
0.65
Confuse
type 2
Bottle
R2
Can v
1
P
(6,l)
<
0.65
v
1
S
(6,3)
=
0.65
Confuse
type 1
Vase
R1
Vase v
1
P
(7,2)
=
0.69
v
1
S
(7,2)
=
1.00
Coinci-
dent
Cone
R2
All l v
1
P
(8,l)
<
0.65
v
1
S
(8,l)
<
0.65
Comple-
mentary
and shared before by R2. As can be seen from Fig-
ure 3, both objects have the same shape and conse-
quently the PCA features are not able to discriminate
between these two objects. This is not the case for
the SIFT features, which prevent R1 to consider it as
the same object (as explained below). In the seventh
row, R1 learns about vase which was already learned
and shared by R2, and in this case both concepts are
merged.
To test the performance of the individual concepts
and the collective concepts acquired by each robot,
the concepts were used in an object recognition task.
Each robot followed a predefined trajectory to recog-
nize objects in the environment. The objects were de-
Table 6: Detected information by R2 for each own and
shared individual concepts.
Individual
concepts
Related
objects
v
2
P
v
2
S
Kind of
info.
Vase
R2
- - - Comple-
mentary
Dol-
phin
R1
All k v
2
P
(2,k)
<
0.65
v
2
S
(2,k)
<
0.65
Comple-
mentary
Soda
bottle
R2
All k v
2
P
(3,k)
<
0.65
v
2
S
(3,k)
<
0.65
Comple-
mentary
Can
R1
All k v
2
P
(4,k)
<
0.65
v
2
S
(4,k)
<
0.65
Comple-
mentary
Bottle
R2
All k v
2
P
(5,k)
<
0.65
v
2
S
(5,k)
<
0.65
Confuse
type 1
Water
bottle
R1
Soda
Bottle
v
2
P
(6,3)
=
0.73
v
2
S
(6,k)
<
0.65
Confuse
type 2
Cone
R2
All k v
2
P
(7,k)
<
0.65
v
2
S
(7,k)
<
0.65
Comple-
mentary
Vase
R1
Vase v
2
P
(8,1)
=
0.69
v
2
S
(8,1)
=
1.00
Coinci-
dent
tected by the robot team in the following order: cone,
water bottle, vase, bottle, soda bottle and dolphin.
Once an object is detected, the robot (i) evaluates its
class using the PC (v
i
P
) and SIFT (v
i
S
) probability vec-
tors and combines both probabilities using a Bayesian
approach:
P
i
B
l
=
v
i
P
l
× v
i
S
l
× P
u
v
i
P
l
× v
i
S
l
× P
u
+
(1− v
i
P
l
) × (1− v
i
S
l
) × (1− P
u
)
(6)
where P
u
is a uniform probability distribution
(P
u
=
1
numObjs
i
), v
i
P
= p(PC projection | Class =
i), v
i
S
= p(SIFT matching | Class = i), P
i
B
is
the Bayesian probability vector (p(Class = i |
PCprojection, SIFTmatching), and l is the index of
the Bayesian probability vector, where the maximum
size of the probability vector is numObjs
i
.
Figures 4, 5 and 6 show the average probabilities
obtained during the object recognition task for each
set of images of the same class, using the individual
and collective learned concepts. The dotted bars in-
dicate the classification errors. A classification error
is produced when a robot classifies an unknown ob-
ject with a probability ≥ 0.6. The unknown objects
for robots 1 and 2 are those which were not learned
during their individual training.
The classification errors of Robot 1 in Figure 4
occur when the objects cone, bottle and soda bottle
are classified as dolphin, water bottle and water bot-
tle, respectively. The classification errors of Robot 2
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM
85
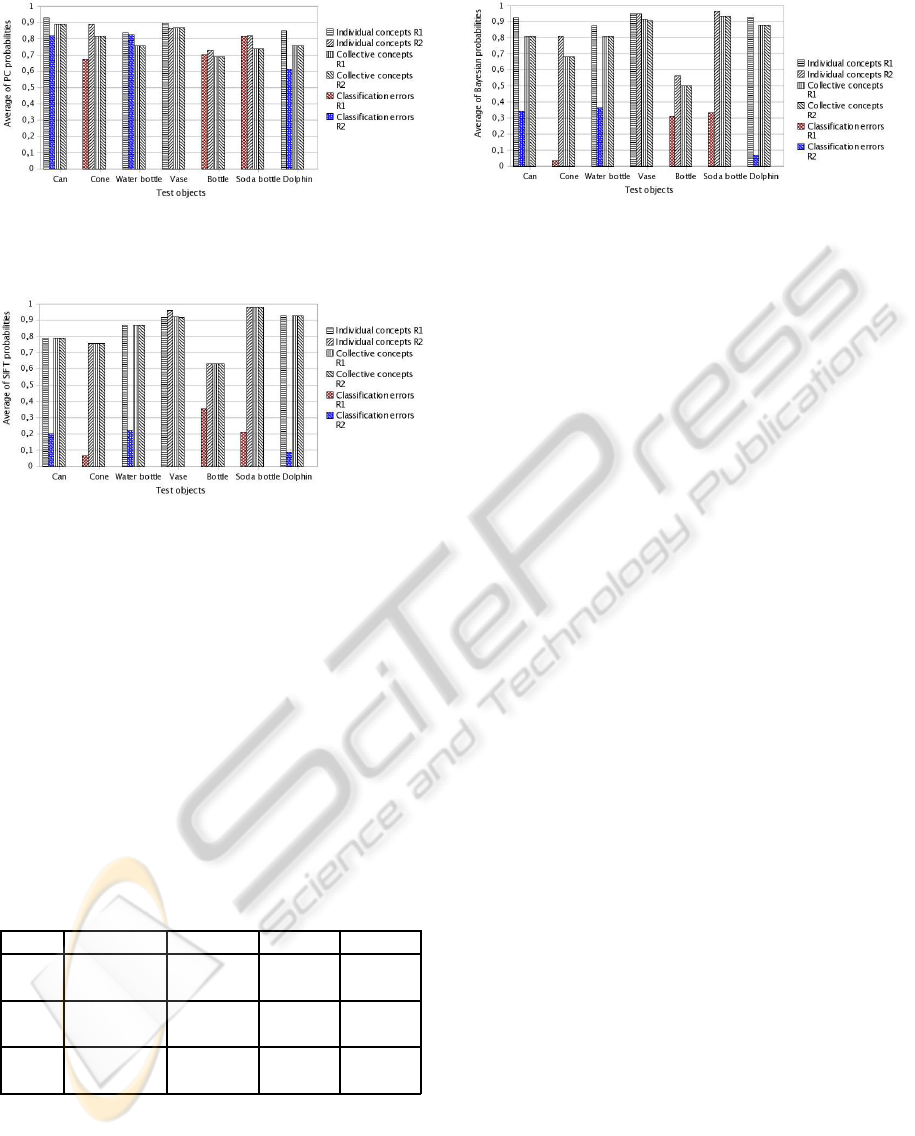
Figure 4: Average PC classification probabilities for the ob-
ject recognition task using the individual and collective PC
concepts.
Figure 5: Average SIFT classification probabilities for the
object recognition task using the individual and collective
SIFT concepts. Any robot makes classification errors.
occur when the objects can, water bottle and dolphin
are classified as bottle, soda bottle and soda bottle,
respectively. For the vase there is no classification er-
ror because both robots learn individual concepts of
it.
Although the probability bars presented in the pre-
vious figures show a higher probability for individual
concepts than for collective concepts, in reality the
collective concepts are more robust as they represent
the probabilities considering a larger number of ob-
jects. This will be discussed in Section 5.2.
Table 7: Precision in the object recognition task using the
individual and collective concepts acquired by each robot.
R1 R2 R1-R2 R2-R1
PCA 55.69 %
(100.00%)
49.98 %
(94.82 %)
86.15 % 86.16 %
SIFT 48.32 %
(86.23 %)
42.89 %
(79.11 %)
87.84 % 87.84 %
Bayes 52.59 %
(94.20 %)
51.68 %
(81.54 %)
80.73 % 80.73 %
We show in Table 7 the precision of the object
recognition task using the individual and collective
concepts. The precision is presented in two ways,
one considering the total number of objects, and the
other one taking into a count only the number of ob-
jects used during the individual training (reported in
Figure 6: Bayesian classification probabilities which uses
the Bayesian fusion of the PCA and SIFT classification
probabilities.
parentheses). As can be seen the collective concepts
produce a significantly better precision.
5.2 Accuracy of the Individual and
Collective Concepts
In this section we compare the results of the indivi-
dual concepts with that of collective concepts. In each
experiment, a different set of objects was used, and
both robots learned the same set of objects. There-
fore, all the shared concepts were coincident, that is,
robots learned both individually and collectively the
same number of concepts. At the end of each ex-
periment the robots learned four concepts that were
proved by a test sequence. In Figure 7 we present
the accuracy obtained by the robots using the PC fea-
tures of the individual and collective concepts in an
object recognition task. Figure 7 shows the averages
in accuracy of the number of images well classified
under six experiments (correct), the average percent-
ages of the number of non detected or non classified
images (no detected), and the average percentage of
false positives for each concept (false +). Figure 8
and 9 show, respectively, the accuracy obtained by the
robots when using the SIFT vectors and the Bayesian
approach.
As it can be observed in Figures 7, 8 and 9, the
accuracy that indicate the quantity of well classified
images (correct) using the collective concepts for the
object recognition task, is in general better than the
accuracy using the individual concepts. For PC, SIFT
and Bayes there is an improvement in the accuracy up
to 2.56 %, 13.79 % and 20.62 %, respectively. This
demonstrates that the collective concepts have better
coverage than the individual concepts because they
contain information acquired from different points of
view, which allows a better recognition of test ob-
jects. Also, the percentages of the number of non de-
tected images of collective concepts are smaller than
the ones of the individual concepts.
In Table 8 we present the average percentages of
ICINCO 2010 - 7th International Conference on Informatics in Control, Automation and Robotics
86

false positives for both, the individual and the collec-
tive concepts acquired by the robots. We conclude
that the collective concepts have better quality than
the individual concepts.
In general for both, the individual and the collec-
tive concepts, we observed an improvement in the ac-
curacy when using the Bayesian approach. In Table 9
we present the average percentages of accuracy using
the individual and collective concepts.
The average profit in the percentages of classifica-
tion using the Bayesian approach using the collective
concepts with regard to the individual concepts is of
14.63 %.
Figure 7: Accuracy in coverage using the part PC of con-
cepts.
Figure 8: Accuracy in coverage using the part SIFT of con-
cepts.
Figure 9: Accuracy in coverage using the Bayesian ap-
proach.
Table 8: Average percentages of false positives.
PCA SIFT Bayes
Individual 14.42 % 0.64 % 0.64 %
Collective 13.14 % 0.00 % 0.00 %
Table 9: Average percentages of accuracy.
PCA SIFT Bayes
Individual 84.94 % 67.88 % 80.18 %
Collective 87.18 % 81.12 % 94.81 %
6 CONCLUSIONS AND FUTURE
WORK
In this paper we have introduced a new on-line learn-
ing framework for a team of robots. Some of the main
features of the proposed scheme are:
• The robots do not know in advance how many
objects they will encountered. This pose several
problems as the robots need to decide if a new
seen object or shared concept, is of a previously
learned concept or not.
• The representation of objects are learned on-line
while the robots are traversing a particular en-
vironment. This is relevant for constructing au-
tonomous robots.
• Three possible cases in which to merge concepts
and how to merge them were identified.
The detection of coincident concepts avoids pro-
ducing multiple concepts for the same object. The
detection of complementary concepts allows to detect
and learned unknown objects not seen by a particular
robot. The detection of confused concepts allows to
fuse information: 1) when the object have different
shape and similar SIFT features, and 2) when the ob-
jects have similar shape and different SIFT features.
These cases are particularly difficult to deal with be-
cause the objects may be genuinely different or may
be the same but seen from different points of view by
the robots.
In general, the object recognition using the collec-
tive concepts had a better performance than using the
individual concepts in terms of accuracy. This occurs
because the collective concepts consider information
from multiple points of view producing more general
concepts.
As future work we propose to integrate schemes to
object segmentation for dynamic environments. For
instance, using an object segmentation based on dis-
tance as in M´endez-Polanco et al., 2009. Use a differ-
ent set of features and identify possible conflicts be-
COLLECTIVE LEARNING OF CONCEPTS USING A ROBOT TEAM
87

tween more that two kind of features. We also plan to
incorporate planning of trajectories to autonomously
allocate the environment among robots. We also plan
to add strategies to solve some confusions in shared
concepts by taking different views from these objects.
Finally, we plan to incorporate our algorithm for robot
localization and search of objects, and to test our work
for robot teams with three or more robots.
ACKNOWLEDGEMENTS
The first author was supported by the Mexican Na-
tional Council for Science and Technology, CONA-
CYT, under the grant number 212422.
REFERENCES
Asada, M., Uchibe, E., Noda, S., Tawaratsumida, S., and
Hosoda, K. (1994). Coordination of multiple behav-
iors acquired by vision-based reinforcement learning.
Proceedings of the International Conference on Intel-
ligent Robots and Systems, pages 917–924.
Cheung, G. K. M., Baker, S., and Kanade, T. (2003). Vi-
sual hull alignment and refinement across time: A 3-
D reconstruction algorithm combining Shape-From-
Silhouette with stereo. Proceedings of the IEEE Com-
puter Society Conference on Computer Vision and
Pattern Recognition (CVPR ’03), 2:375–382.
Ekvall, S., Jensfelt, P., and Kragic, D. (2006). Integrating
active mobile robot object recognition and SLAM in
natural environments. IEEE/RSJ International Con-
ference on Intelligent Robots and Systems (IROS ’06),
pages 5792–5797.
Ekvall, S. and Kragic, D. (2005). Receptive field cooccur-
rence histograms for object detection. IEEE/RSJ In-
ternational Conference on Intelligent Robots and Sys-
tems (IROS ’05), pages 84–89.
Fern´andez, F., Borrajo, D., and Parker, L. E. (2005). A re-
inforcement learning algorithm in cooperative multi-
robot domains. Journal of Intelligent and Robotic Sys-
tems, pages 161–174.
Howard, A., Parker, L. E., and Sukhatme, G. S. (2006).
Experiments with a large heterogeneous mobile robot
team: Exploration, mapping, deployment and detec-
tion. International Journal of Robotics Research,
25:431–447.
Lowe, D. G. (2004). Distinctive image features from scale
invariant keypoints. International Journal of Com-
puter Vision, 60(2):91–110.
Matari´c, M. J. (1997). Reinforcement learning in the multi-
robot domain. Autonomous Robots, 4(1):73–83.
M´endez-Polanco, J. A., Mu˜noz-Mel´endez, A., and Morales,
E. F. (2009). People detection by a mobile robot using
stereo vision in dynamic indoor environments. Pro-
ceedings of the 8th Mexican International Conference
on Artificial Intelligence (MICAI ’09), pages 349–359.
Mitchell, T. M. (1997). Machine Learning. McGraw-Hill
Science/Enginering/Math.
Mitri, S., Pervolz, K., Surmann, H., and Nuchter, A.
(2004). Fast color independent ball detection for mo-
bile robots. Proceedings of the IEEE International
Conference Mechatronics and Robotics (MechRob
’04), pages 900–905.
Montesano, L. and Montano, L. (2003). Identification of
moving objects by a team of robots based on kine-
matic information. Proceedings of the IEEE/RSJ In-
ternational Conference on Intelligent Robots and Sys-
tems (IROS ’03), 1:284–290.
O’Beirne, D. and Schukat, M. (2004). Exploration and ob-
ject recognition using cooperative robots. Proceedings
of the International Conference on Imaging Science,
Systems and Technology (CISST ’04), pages 592–598.
Parker, L. E. (2002). Distributed algorithms for multi-robot
observation of multiple moving targets. Autonomous
Robots, 3(12):231–255.
Steels, L. and Kaplan, F. (2001). AIBO’s first words. The
social learning of languaje and meaning. Evolution of
Comunication, 4(1):3–32.
Wessnitzer, J. and Melhuish, C. (2003). Collective decision-
making and behaviour transitions in distributed ad hoc
wireless networks of mobile robots: Target-hunting.
Advances in Artificial Life, 7th European Conference
(ECAL ’03), pages 893–902.
Ye, Y. and Tsotsos, J. K. (1996). On the collaborative object
search team: a formulation. Distributed Artificial In-
telligence Meets Machine Learning (ECAI ’96 Work-
shop), pages 94–116.
ICINCO 2010 - 7th International Conference on Informatics in Control, Automation and Robotics
88
