
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR
RELATIONAL DATABASES
Raju Halder and Agostino Cortesi
Dipartimento di Informatica, Universit
`
a Ca’ Foscari di Venezia, Venezia, Italy
Keywords:
Access control, Relational databases, Abstract interpretation.
Abstract:
Fine Grained Access Control (FGAC) provides users the access to the non-confidential database information
while preventing unauthorized leakage of the confidential data. It provides two extreme views to the database
information: completely public or completely hidden. In this paper, we propose an Observation-based Fine
Grained Access Control (OFGAC) mechanism based on the Abstract Interpretation framework where data are
made accessible at various level of abstraction. In this setting, unauthorized users are not able to infer the exact
content of a cell containing confidential information, while they are allowed to get partial information out of it,
according to their access rights. Different level of sensitivity of the information correspond to different level
of abstraction. In this way, we can tune different parts of the same database content according to different level
of abstraction at the same time. The traditional FGAC can be seen as a special case of the OFGAC framework.
1 INTRODUCTION
Due to emerging trend of Internet and database tech-
nology, the information systems are shared by many
people around the world. Also the businesses scenar-
ios have become more dependent on information. As
information usage proliferates among more and more
users, organizations must deliver their data only to
those people who are authorized for it. Thus, data
accessibility to the authorized people is at the heart of
the business processes, while on the other hand, infor-
mation leakage to unauthorized people may lead to a
huge loss in business.
Access control mechanism (Bertino et al., 1999;
Jajodia et al., 1997; Griffiths and Wade, 1976) is one
of the most effective solutions to ensure the safety
of the information in an information system. The
granularity of traditional access control mechanism
is coarse-grained and can be applied on database or
table level only. The need of more flexible busi-
ness requirements and security policies mandate the
use of Fine Grained Access Control (FGAC) mecha-
nisms (Wang et al., 2007; Zhu et al., 2008; Zhu and
L
¨
u, 2007; Rizvi et al., 2004; Kabra et al., 2006) that
provide the safety of the database information even
at lower level such as individual tuple level or cell
level. In general, FGAC aims at hiding the confi-
dential information completely while giving the pub-
lic access only to the non-confidential information.
The proposed schemes on FGAC suggest to mask
the confidential information by special symbols like
NULL (LeFevre et al., 2004) or Type-1/Type-2 vari-
ables (Wang et al., 2007), or to execute the queries
over the operational relations (Zhu et al., 2008; Shi
et al., 2009) or authorized views (Rizvi et al., 2004;
Kabra et al., 2006) etc. FGAC at database level can
ensure to apply consistently to every user and every
application.
The traditional FGAC policy provides only two
extreme views: completely public or completely hid-
den. There are many application areas where some
partial or relaxed view of the confidential information
is desirable. For instance, if the database in an on-
line transaction system contains credit card numbers
for its customers, according to the disclosure policy,
the employees of the customer-care section are able
to see the last four digits of the credit card number
whereas all the other digits must be completely hid-
den. The traditional FGAC policy is unable to imple-
ment this type of security framework without chang-
ing the database structure (e.g. by splitting the Credit
Card Number attribute into two sub-attributes - one
public, and the other private). To implement this re-
laxed scheme where an observer is allowed to ob-
serve specific properties or partial views of the pri-
vate data, we introduce an Observation-based Fine
Grained Access Control (OFGAC) mechanism on top
of the traditional FGAC, based on the Abstract Inter-
254
Halder R. and Cortesi A. (2010).
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES.
In Proceedings of the 5th International Conference on Software and Data Technologies, pages 254-265
DOI: 10.5220/0003006202540265
Copyright
c
SciTePress

pretation framework (Cousot and Cousot, 1977; Gia-
cobazzi et al., 2000; Halder and Cortesi, 2010). We
call the disclosure policy under OFGAC framework
as observation-based disclosure policy.
Unlike traditional FGAC, the database informa-
tion which are unauthorized under the observation-
based disclosure policy op, are masked by the in-
formation at various level of abstraction representing
some properties of interest. In other words, the con-
fidential database information are masked by abstract
values rather than NULL or special symbols (LeFevre
et al., 2004; Wang et al., 2007). The unauthorized
users, thus, could not be able to infer the exact con-
tent of the sensitive cells. Different level of sensitivity
of the information correspond to different level of ab-
straction. Less sensitive values can be abstracted at
lower level whereas higher sensitive information can
be masked with abstract values at higher level of ab-
straction. In this way, we can tune different parts of
the same database content according to different level
of abstraction at the same time, giving rise to various
observational access control for various part. Thus, in
contrast to traditional FGAC, the OFGAC allows ac-
cess control by splitting the database into multipart,
where each part represents different level of sensitiv-
ity of the data.
The query issued by the external users will be
directed to and executed over the abstract database
which yield to a sound approximation of the query
results. In particular, the result of a query contains
all those data for which the precondition part of the
query evaluates to either true or unknown logic values
(Halder and Cortesi, 2010). Special care should be
taken for the queries with aggregate functions (AVG,
SUM, MIN, MAX, COUNT) and negation (MINUS,
NOT EXISTS, NOT IN) to preserve soundness.
The traditional FGAC can be seen as a special case
of our OFGAC framework.
The structure of the paper is as follows: Section
2 introduces the notion of observation-based disclo-
sure policy. Section 3 discusses the possible multi-
party collusion attacks under the same or different
observation-based disclosure policies. In Sections 4
and 5 we discuss the referential integrity constraints
issues and the query evaluation techniques under OF-
GAC. In Section 6 we survey the related work in the
literature, and finally we draw our conclusions in Sec-
tion 7.
2 OBSERVATION-BASED
DISCLOSURE POLICIES
Whenever query Q is issued to a database, the tra-
ditional fine grained disclosure policy P determines
which database information is allowed to disclose
when answering the query Q. Given a database
schema DB, the disclosure policy P splits the database
states σ into two distinct parts: a public one (insensi-
tive data) and a private one (sensitive data). Thus,
under the disclosure policy P, we can represent the
database state by a tuple σ
P
= hσ
h
,σ
l
i where σ
h
and
σ
l
represent the states which correspond to the private
part and to the public part, respectively. Under policy
P, the generic users are able to see the database in-
formation from the public part appearing in the query
answer while the private part remains undisclosed. In
reality, the disclosure policy P depends on the con-
text in which the query is issued, for instance, the
identity of the issuer, the purpose of the query, the
data provider’s policy etc. Given a database state σ
P
under the policy P, and a query Q, the execution of
Q over σ
P
would return the query result ξ= [[Q]](σ
P
)
where the private part (σ
h
) of σ
P
is masked by special
symbols (for example, NULL (LeFevre et al., 2004)
or type-1/type-2 variable (Wang et al., 2007)). Thus,
each cell in ξ either takes a constant value or special
symbols (NULL or special variables) which indicates
that the cell is unauthorized and can not be disclosed
under P. As far as the security of the system is con-
cerned, the disclosure policy should comply with the
non-inter f erence policy (Sabelfeld and Myers, 2003)
i.e. the results of admissible queries should not de-
pend on the confidential data in the database. The
non-inter f erence says that a variation of private (sen-
sitive) database values does not cause any variation of
the public (insensitive) view (see Definition 1).
Definition 1. (Non-interference)
Let σ
P
= hσ
h
,σ
l
i and σ
0
P
= hσ
0
h
,σ
0
l
i be two database
states under the disclosure policy P. The non-
inter f erence policy says that
∀Q,∀σ
P
,σ
0
P
: σ
l
= σ
0
l
=⇒ [[Q]](σ
P
) = [[Q]](σ
0
P
)
That is, if the public (insensitive) part of any two
database states under the disclosure policy P are the
same, the execution of any admissible query Q over
σ
P
and σ
0
P
return the same results.
In the context of information flow security, the no-
tion of non-interference is too restrictive and imprac-
tical in some real systems where intensional leakage
of the information to some extent is allowed with the
assumption that the power of the external observer is
bounded. Thus, we need to weaken or downgrad-
ing the sensitivity level of the database information,
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
255

hence, the notion of non-interference which considers
weaker attacker model. The weaker attacker model
characterizes the observational characteristics of the
attacker and can be able to observe specific properties
of the private data.
Definition 2 defines the observation-based disclo-
sure policy under the OFGAC framework.
Definition 2. (Observation-based disclosure policy)
Given a domain of observable properties D, and
an abstraction function α
D
: ℘(val) → D, an
observation-based disclosure policy op assigned to
the observer O is a tagging that assigns each value
v in the database state σ a tag α
D
(v) ∈ D, meaning
that O is allowed to access the value α
D
(v) instead of
its actual value v.
Consider a database that consists of two tables as
depicted in Table 1(a) and 1(b) respectively, contain-
ing information about employees and departments for
an organization. Suppose the names of all employees,
phone numbers of all departments, age and salaries
of some employees are sensitive data. Cells contain-
ing sensitive data are marked with ’N’ within paren-
thesis. To implement the observational access con-
trol, we can mask or abstract those sensitive informa-
tion by the abstract values representing specific prop-
erties of interest as depicted in Table 2(a) and 2(b)
respectively. The corresponding abstract lattices for
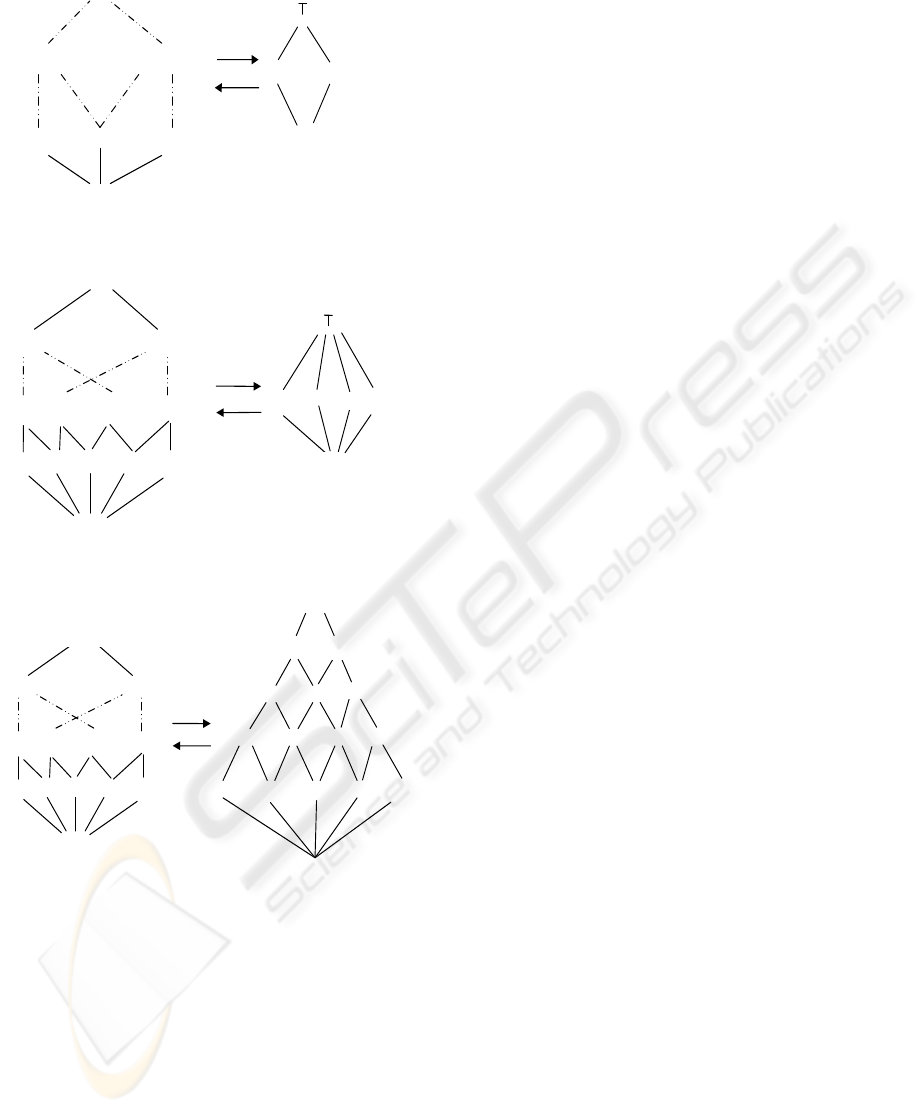
the attributes ”name”, ”sal” and ”age” are shown in
Figure 1(a), 1(b) and 1(c) respectively. Observe that
in emp
]
, the ages are abstracted by the elements from
the domain of interval, the salaries are abstracted by
the relative measures: low, medium, high, very high
and the names are abstracted by their sex property. It
is worthwhile to note that here we assume that salary
is more sensitive than the age of employees and so,
sensitive salary values are abstracted by a higher level
of abstraction than that of age, although both are nu-
meric data. The correspondence between the concrete
values of salaries and the abstract values that partially
hide sensitive salary values can be formally expressed
by the abstraction and concretization functions α
sal
and γ
sal
respectively as follows:
α
sal
({µ}) ,
low i f µ ∈ [500, 1999]
medium i f µ ∈ [2000, 3999]
high i f µ ∈ [4000, 5999]
very high i f µ ∈ [6000, 10000]
γ
sal
(d) ,
{[a,b] : a ≤ b, a ≥ 500, b < 2000} i f d = low
{[a,b] : a ≤ b, a ≥ 2000, b < 4000} i f d = medium
{[a,b] : a ≤ b, a ≥ 4000, b < 6000} i f d = high
{[a,b] : a ≤ b, a ≥ 6000, b < 10000} i f d = very high
Most importantly, in the abstract table dept
]
, since
the phone numbers of all departments are strictly con-
fidential they are abstracted by the top-most element
> of their corresponding lattice. For the attribute att,
the values which are completely public, we can con-
sider the abstraction function α
att
and concretization
function γ
att
as the identity function id.
Table 1: Database consists of table ”emp” and ”dept”.
eID Name Age Dno Sal
1 Matteo (N) 30 2 2800 (N)
2 Pallab (N) 22 1 1500
3 Sarbani (N) 56 (N) 2 2300
4 Luca (N) 35 1 6700 (N)
5 Tanushree (N) 40 3 4900
6 Andrea (N) 52 (N) 1 7000 (N)
7 Alberto (N) 48 3 800
8 Mita (N) 29 (N) 2 4700 (N)
(a) Table ”emp”
Dno Name Loc Phone DmngrID
1 Financial Venice 111-1111 (N) 6
2 Research Rome 222-2222 (N) 8
3 Admin Treviso 333-3333 (N) 3
(a) Table ”dept”
Table 2: Database consists of masked table ”emp
]
” and
”dept
]
” abstracted by different level of abstraction.
eID
]
Name
]
Age
]
Dno
]
Sal
]
1 Male 30 2 Medium
2 Male 22 1 1500
3 Female [50,59] 2 2300
4 Male 35 1 Very high
5 Female [40,49] 3 4900
6 Male [50,59] 1 Very high
7 Male 48 3 800
8 Female [20,29] 2 High
(a) Abstract Table ”emp
]
”
Dno
]
Name
]
Loc
]
Phone
]
DmngrID
]
1 Financial Venice > 6
2 Research Rome > 8
3 Admin Treviso > 3
(b) Abstract Table ”dept
]
”
Observe that the traditional FGAC (LeFevre et al.,
2004; Zhu et al., 2008; Shi et al., 2009) is a special
case of our observation-based fine grained access con-
trol framework where each unauthorized cell is ab-
stracted by the top-most element > of its correspond-
ing abstract lattice.
A database is a collection of tables and a table t
of arity k can be defined as t ⊆ D
1
× D
2
× ··· × D
k
where attribute(t) = {a
1
,a
2
,...,a
k
} and attribute a
j
( j ∈ [1..k]) corresponding to the typed domain D
j
.
Given a database state σ without any access con-
trol policy. Under the OFGAC policy op, it is rep-
resented as σ
op
. When observer O issues a query Q
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
256
⊥
{Andrea} .. . . . {Michel} . . . . {Zidan}
Male Female
⊥
name
α
na me
γ
{Andrea, . . . . , Michel} . . . . . {Michel, . . . . , Zidan}
{Andrea, . . . . , Zidan}
(a) Abstract lattice for attribute “name”
⊥
{500 } { 501} {502} . . . . {9999} {10000}
⊥
sal
α
sal
γ
Low Medium High Very high
{500 ,501} {501,502} . . . {502,9999} . . . {9999,10000}
{500 , . . . . , 9999} {501, . . . . , 10000}
{500 , . . . . , 10000}
(b) Abstract lattice for attribute “sal”
[20,29]
[40,49]
[20,39]
[30,49]
[20,49]
⊥
⊥
{20 }
{ 21} {22} . . . . {61} {62}
[50,59]
[40,59]
[30,59]
[20,59]
[30,39]
age
α
age
γ
{20,21} {21,22} . . . {22,61} . . . { 61,62}
{20 , . . . . ,61} {21, . . . . , 62}
{20 , . . . . , 62}
[60,69]
[50,69]
[40,69]
[30,69]
[20,69]
(c) Abstract lattice for attribute “age”
Figure 1: Abstract Lattices for attributes “name”, “sal” and
“age”.
over σ
op
, all the unauthorized cells of σ
op
belonging
to one or more attributes of the tables in the database
are abstracted which results in an abstract database
state σ
]
op
and the abstract query Q
]
obtained from
Q is executed on this σ
]
op
. For each of these sen-
sitive attributes there exists a corresponding abstract
lattice. The value of the unauthorized cell c belonging
to the attribute a in the database is abstracted by fol-
lowing the Galois Connection (℘(D
con
a
),α
a
,γ
a
,D
abs
a
)
where ℘(D
con
a
) represent the powerset of concrete
domain of a whereas D
abs
a
represents abstract do-
main of a, and α
a
, γ
a
are the abstraction and con-
cretization function for a respectively. For insen-
sitive attributes a, thus, we have the Galois Con-
nection (℘(D
con
a
),id, id,℘(D
con
a
)) where id represents
the identity function. For any sensitive attribute a, the
abstraction and concretization function may be iden-
tity function when abstracting the cells of a contain-
ing public values. Thus when we consider the whole
database state σ
op
under the policy op, the abstract
state is obtained by performing σ
]
op
= α(σ
op
) where
abstraction function α can be expressed as collec-
tion of abstraction functions for all attributes in the
database.
We assume that for each type of values in
database there exists a hierarchy of abstractions such
that Galois Connections combine consistently i.e. if
(X, α
1
,γ
1
,Y ) and (Y, α
2
,γ
2
,Z) represent two Galois
Connection, then we have the following:
i f (X ,α
1
,γ
1
,Y ) and (Y,α
2
,γ
2
,Z) then (X, α
2
◦α
1
,γ
1
◦γ
2
,Z)
Definition 3. Let σ
op
be a database state under the
observation-based disclosure policy op. Then σ
]
op
=
α(σ
op
) where α is the abstraction function, is said to
be abstract version of σ
op
if there exists a represen-
tation function γ, called concretization function such
that for all tuple hx
1
,x
2
,...,x
n
i ∈ σ
op
there exists a
tuple hy
1
,y
2
,...,y
n
i ∈ σ
]
op
such that ∀i ∈ [1...n] (x
i
∈
id(y
i
) ∨ x
i
∈ γ(y
i
)).
In the example, the table ”emp
]
” of Table 2(a) is a
abstract version of ”emp” of Table 1(a) since, for in-
stance, for the tuples h6, Andrea,52, 1, 7000i ∈ emp
there exists h6,Male, [50, 60], 1,Very highi ∈ emp
]
such that Andrea ∈ γ
name
(Male), 52 ∈ γ
age
([50,60]),
7000 ∈ γ
sal
(Very high) and for other values the con-
cretization and abstraction functions represents iden-
tity function id. Similar for the other tuples.
3 COLLUSION ATTACKS
Wang et al. in (Wang et al., 2007) illustrate the se-
curity of the system that implements traditional fine
grained access control policy under the collusion and
multi-query attack. They define the security aspect
in one-party single-query/weak security and multi-
party multi-query/strong security context and prove
that the systems with weak-security is also secure un-
der strong-security.
In observation-based fine grained access control
policy, transforming abstract domains means trans-
forming the attackers, and the attackers are modeled
by abstractions. The robustness of the database under
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
257
α
α
α
Observer O
1
Policy op
1
Observer O
2
Policy op
2
Observer O
3
Policy op
3
(a) Case 1: Multiple policies/Single abstraction
1
α
Policy op
Observer O
Policy op
Observer O
Policy op
2
α
(b) Case 2: Single policy/Multiple abstraction
Observer O
1
Policy op
1
Observer O
2
Policy op
2
Observer O
3
Policy op
3
1
α
2
α
3
α
(c) Case 3: Multiple policies-abstraction
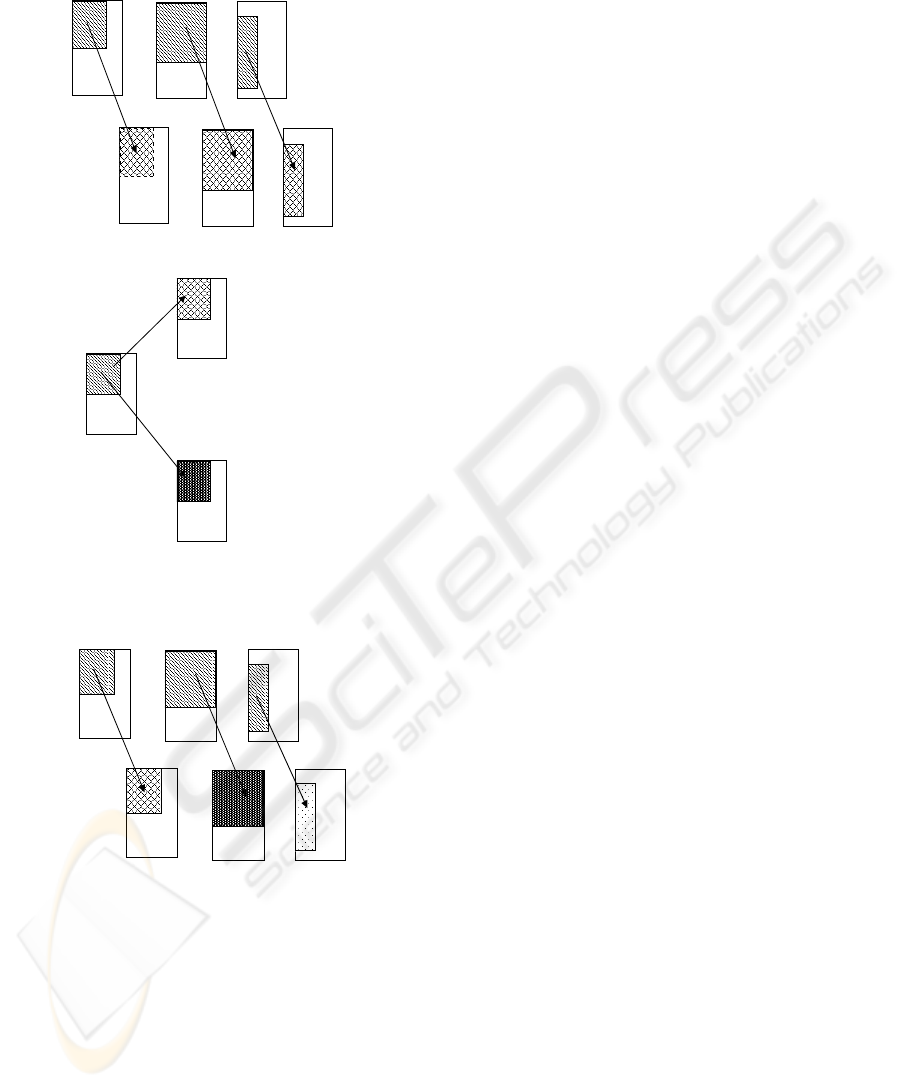
Figure 2: Policies and Observations.
the OFGAC policy depends on the ability of the exter-
nal observers to distinguish the database states based
on the observable properties of the query results.
Here we consider three different scenarios: figure
2(a), 2(b) and 2(c) illustrates these three cases where
the shaded portion indicates the sensitive information
and α (α
i
6= α
j
if i 6= j) is the abstraction function
used to abstract those sensitive information.
Case 1: Multiple Policies/Single Level Abstraction.
Suppose each of the n observers under
op
1
,op
2
,...,op
n
respectively issues a query
Q. Let σ be the database state without any
policy. Under op
i
, i=1, . . . , n the database state
σ is represented as σ
op
i
and is abstracted into
σ
]
op
i
= α(σ
op
i
). Thus the observer O
i
under op
i
will get the query result ξ
]
i
= [[Q
]
]](σ
]
op
i
) where
Q
]
is the abstract version of Q. When these n
users collude, they feed the query results ξ
]
i
,
i = . . . , n to a function f which can perform
some comparison or computation (viz, difference
operation) among the results and infer about
some sensitive information for some observers.
For instance, suppose a portion of database infor-
mation is sensitive under policy op
j
while it is not
sensitive under another policy op
k
, j 6= k. For
the first case this part of information will be ab-
stracted while in the latter it will not. Thus, if
this portion of information appears in both of the
query results ξ
]
j
and ξ
]
k
, then it is possible for the
j
th
observer to infer the exact content of that por-
tion of information as it is not abstracted in ξ
k
.
Let us explain this case with an example. Suppose
the manager of a department can view all the de-
tails of employees working under him whereas the
clerk under that manager can view only his own
details. So, to the clerk all the details of other
clerks (except him) under the same manager are
abstracted and similarly, to the manager all the de-
tails of others except the employees under him are
abstracted to the same level of abstraction. But if
the manager and the clerk collude and share the
query answers they obtain, then it is possible for
the clerk to acquire some confidential information
(confidential to him, but not to the manager) about
the other clerks under the same manager.
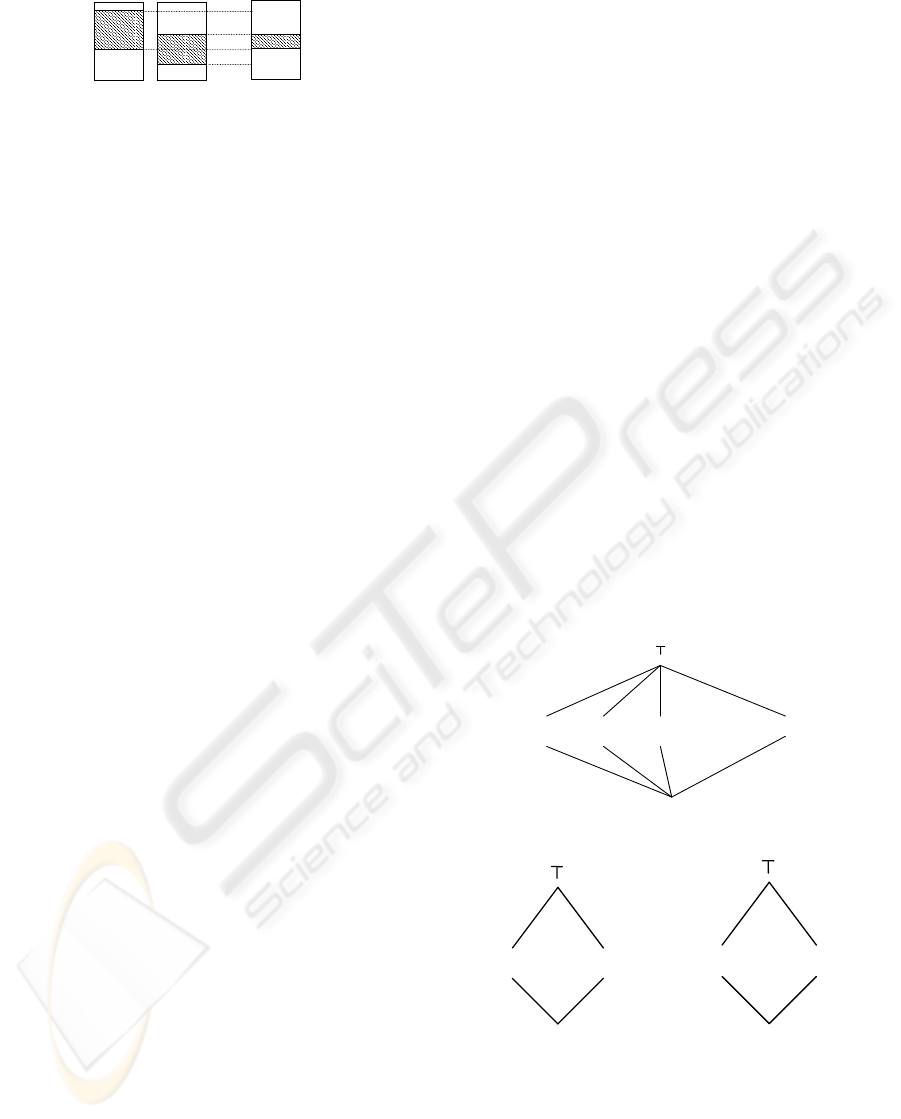
Let σ
op
= {σ
l
,σ
h
} and σ
op
0
= {σ
0
l
,σ
0
h
} be the
database states under two different policies op and
op
0
. The database state σ
op•op
0
obtained by com-
bining two policies op and op
0
are defined as fol-
lows:
σ
op•op
0
= {((σ
l
∪ σ
h
) − (σ
h
∩ σ
0
h
)),(σ
h
∩ σ
0
h
)}
This fact is depicted in Figure 3. So when the ob-
servers under op and op
0
collude and share the
query results, both will act as equivalent to the
observer under the policy op • op
0
and thus they
can infer the values belonging to the public part
of op • op
0
i.e. ((σ
l
∪ σ
h
) − (σ
h
∩ σ
0
h
)) by issuing
a sequence of queries individually and by compar-
ing the results together.
Case 2: Single Policy/Multiple Level Abstraction.
Consider n different observers O
1
,O
2
,...,O
n
under the same policy op and the sensitive
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
258
Policy op Policy op’ op
•
op’
Figure 3: Combination of policies.
information part is abstracted to different level of
abstraction to different observers. Higher levels
of abstraction make the database information less
precise whereas lower levels of abstraction repre-
sent them with more precision. Thus, the result
of a query for the one with higher abstraction
contains less precise information than that with
lower abstraction.
Consider two different observers O
1
and O
2
un-
der op where the sensitive database information
of σ
op
are abstracted by the domains of abstrac-
tion D
abs
1
and D
abs
2
, and results into σ
1]
op
and σ
2]
op
respectively.
First consider the case where D
abs
2
is a more ab-
stract domain than D
abs
1
, i.e., D
abs
2
is an abstrac-
tion of D
abs
1
. Since both observers are under the
same policy, the query results over σ
1]
op
and σ
2]
op
may contain some common abstract information -
one from D
abs
1
and other from D
abs
2
. Thus when O
1
and O
2
collude, it is possible for O
2
to obtain sen-
sitive information with lower level of abstraction
from the result obtained by O
1
as it is abstracted
with lower level of abstraction for O
1
. But no real
collusion may arise in this case, as the overall in-
formation available to O
1
and O
2
together is at
most as precise as the one already available to O
1
.
The other case is where the two domains are not
one the abstraction of the other. For example,
let in a particular database state an attribute of a
table have the sensitive values represented by an
ordered list h5, 0, 2, 3, 1i. Suppose the observer
O
1
is limited by the property DOM represented by
domain of intervals as shown in Figure 4(a), while
O
2
is limited by parity property represented by
the abstract domain PAR = {⊥, EV EN, ODD, >}
as depicted in Figure 4(c). Thus O
1
sees
h[4,5],[0,1],[2,3],[2,3],[0,1]i while O
2
sees
hODD,EV EN,EV EN,ODD,ODDi. When O
1
and O
2
collude they can infer the exact values
for the attribute i.e. h5, 0, 2, 3, 1i by combining
the query results. The corresponding combined
lattice obtained by combining the above two
abstract lattices DOM and PAR is shown in
Figure 5(a).
Given an OFGAC under Single policy/Multiple
level abstraction scenario where same informa-
tion under the same policy op is abstracted by
n different level of abstraction to n different ob-
servers. Such OFGAC is collusion-prone when
the intersection of the sets (not singletons) ob-
tained by concretization of n different abstract val-
ues for the same sensitive cell appearing in the
query results for n different observers, yield to a
singleton. This is depicted in Definition 4.
We now show an example where no collusion
takes place in practice. Consider the sensitive val-
ues h−2, 0, 2, −1, 1i. The observer O
1
and O
2
are limited by the sign property represented by
the abstract domain SIGN = {⊥, +, −, >} and by
the parity property represented by the abstract do-
main PAR = {⊥,EV EN, ODD, >} respectively.
Thus O
1
sees h−, +, +, −, +i while O
2
sees
hEV EN,EV EN,EV EN,ODD,ODDi. Figure
4(b) and 4(c) shows the abstract lattices for SIGN
and PAR respectively. When O
1
and O
2
collude
they can infer the abstract values for the attribute
as hEV EN
−
,EV EN
+
,EV EN
+
,ODD
−
,ODD
+
i
by combining the query results. However, al-
though these combined abstract values represent
more precise information than that of the individ-
ual queries, the observer still could not be able
to infer the exact content. Figure 5(b) shows the
combined abstract lattice obtained by combining
two abstract lattices SIGN and PAR.
[0,1] [2,3] [4,5] …. [2n, 2n+1]
⊥
(a) DOM
⊥
+ -
⊥
EVEN ODD
(a) SIGN (b) PAR
Figure 4: Abstract Lattices of DOM, SIGN and PAR.
Definition 4. An OFGAC under Single pol-
icy/Multiple level abstraction scenario is
collusion-prone for n different observers under
the same policy op, if
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
259
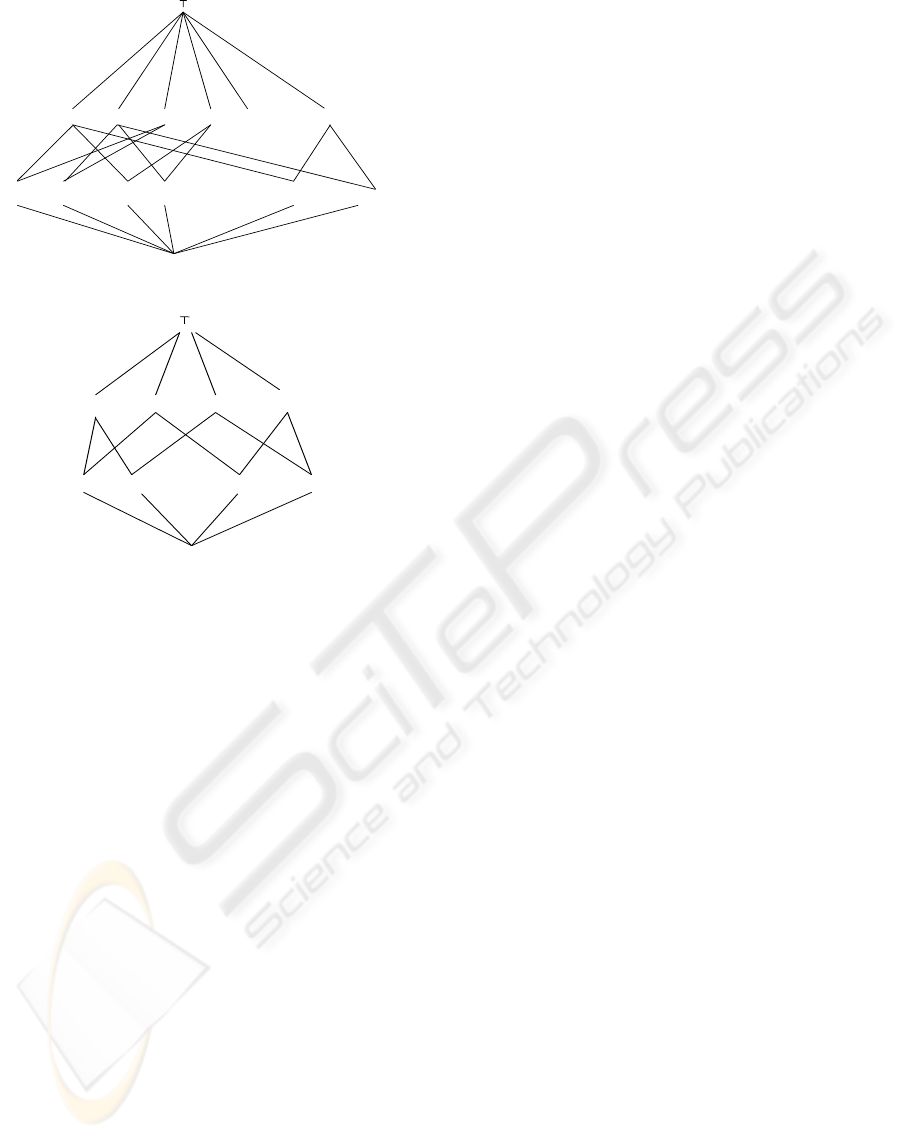
EVEN ODD [0,1] [2,3] [4,5] …. [2n, 2n+1]
⊥
0 1 2 3 2n 2n+1
(a) Combined lattice of DOM and PAR
⊥
EVEN + - ODD
EVEN
+
EVEN
-
ODD
+
ODD
-
(b) Combined lattice of SIGN and PAR
Figure 5: Combination of lattices.
∃(d
1
,d
2
) ∈ D
abs
1
× D
abs
2
: γ(d
1
) ∩ γ(d
2
) = {e}
while γ(d
1
) 6= {e}, and γ(d
2
) 6= {e}.
Theorem 1. An OFGAC under Single pol-
icy/Multiple level abstraction scenario is
collusion-free for n different observers under the
same policy op, if
∀(d
1
,d
2
) ∈ D
abs
1
× D
abs
2
, if either γ(d
1
) or γ(d
2
)
are not singletons, then γ(d
1
) ∩ γ(d
2
) is not a
singleton.
Theorem 2. If the reduced product (Cousot and
Cousot, 1977) of D
abs
1
and D
abs
2
is equivalent to
the concrete domain D, then OFGAC is collusion-
prone.
Case 3: Multiple Policies / Level Abstractions.
This is the combination of the previous two cases.
Observers may collude to act as the observer
under the combination of their individual poli-
cies, or may try to infer about the confidential
information appearing in the query results which
are abstracted by different level of abstraction
by combining (e.g. intersecting) their domain of
abstract values.
4 PRESERVING REFERENTIAL
INTEGRITY CONSTRAINTS
BETWEEN DATABASE
RELATIONS UNDER OFGAC
We know that the primary key values of a relation
can not be NULL as they are used to identify indi-
vidual tuple in the relation. The foreign key of the
relation is used to maintain referential integrity con-
straints between relations of the database. Normal-
ization of relations is mostly desirable operation to
reduce redundant values and NULL values of the tu-
ples and to disallow the possibility of generating spu-
rious tuples. In case of normalization, the database
relations are divided into multiple relations which are
linkable through foreign key. However, we should
keep in mind that the secure linking i.e. the refer-
ential integrity among the database relations can not
be hampered by the abstraction operation of OFGAC
policy. In (Wang et al., 2007), authors used type-2
variable to keep these referential integrity constraints
intact while masking operation is performed. The at-
tribute values which are sensitive and act as primary
key or foreign key are masked by the type-2 variables.
We extend the same approach of Wang et al.
(Wang et al., 2007) in our OFGAC where Type − 2
variables are represented by tuple habstract value,
variablei where the variable can take only one con-
crete value from the set of values obtained by con-
cretizing the abstract value. Formally, Type − 2 vari-
able is denoted by hβ,di where d ∈ D
abs
and β is a
variable that can take its value from γ(d). Definition
5 defines the Type − 2 variables.
Definition 5. (Type-2 Variable)
A type-2 variable is represented by hβ, di, where
β and d are the name and the abstract value of
the variable, respectively. Given β
1
,β
2
,d
1
,d
2
,
”hβ
1
,d
1
i=hβ
1
,d
1
i” and ”hβ
1
,d
1
i 6= hβ
2
,d
1
i”
are true, while whether ”hβ
1
,d
1
i=hβ
1
,d
2
i”,
”hβ
1
,d
1
i=hβ
2
,d
2
i”, ”hβ
1
,d
1
i=c are unknown,
where c is a constant value.
Example 1. Consider the supplier-parts database
and its abstract version under the observation-based
access control policy as depicted in Table 3. The at-
tributes S-id and P-id are the primary key for the ta-
bles ”Supplier” and ”Part” respectively whereas the
composite attribute {S-id, P-id} is used as the pri-
mary key for the table ”Supp-Part”. Observe that
S-id and P-id in ”Supp-Part” table are used as the
foreign key that link to the primary key of ”Supplier”
and ”Part” respectively and relate the suppliers with
the parts sold by them. Suppose, according to the
policy the values of the attribute S-id, P-id and some
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
260
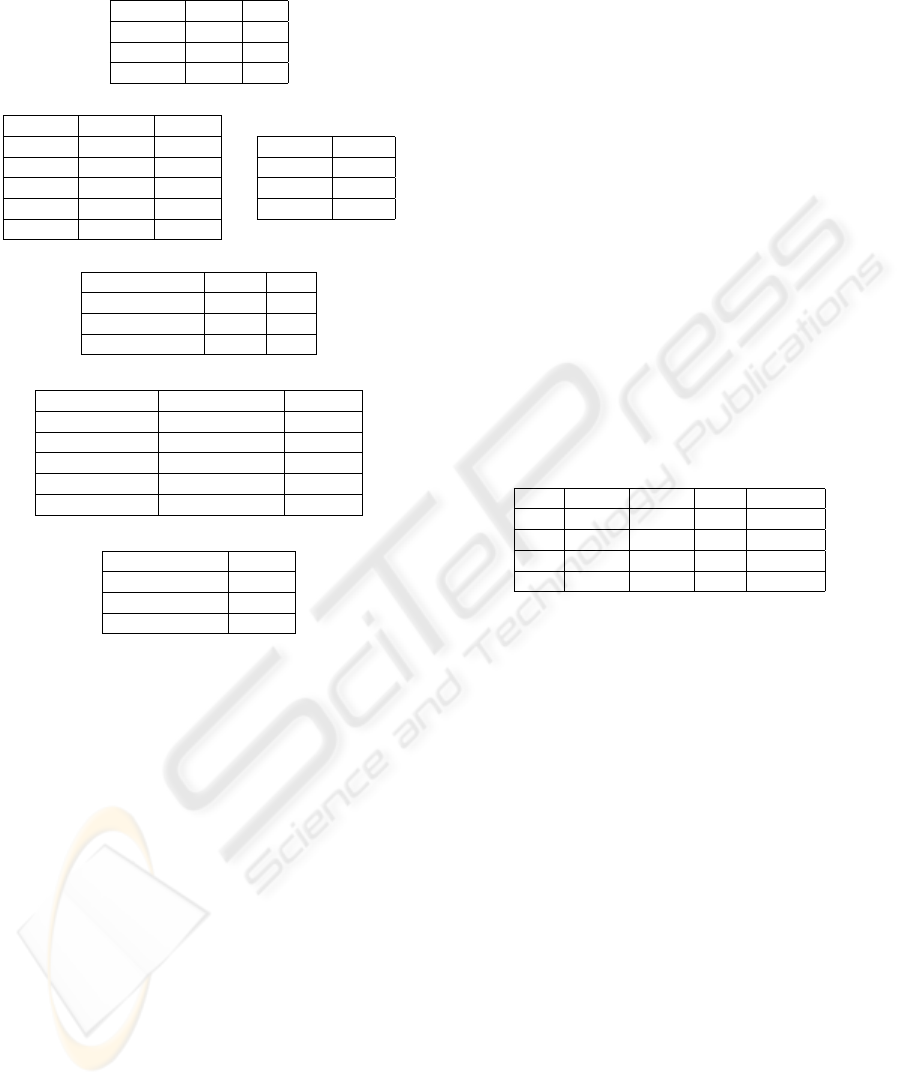
Table 3: Preserving Referential Integrity Constraint by us-
ing Type − 2 variable.
S − id Name Age
S230 (N) Alice 24
S201 (N) Bob 21
S368 (N) Tea 22
(a) Table ”Supplier”
S − id P − id QTY
S230 (N) P140 (N) 120
S201 (N) P329 (N) 260 (N)
S230 (N) P563 (N) 200
S368 (N) P329 (N) 450 (N)
S368 (N) P140 (N) 430 (N)
P −id Pname
P140 (N) Screw
P329 (N) Bolt
P563 (N) Nut
(b) Table ”Supp − Part” (c) Table ”Part”
S − id
]
Name
]
Age
]
hβ
1
,[S200, S249]i Alice 24
hβ
2
,[S200, S249]i Bob 21
hβ
3
,[S350, S399]i Tea 22
(d) Abstract Table ”Supplier
]
”
S − id
]
P −id
]
QTY
]
hβ
1
,[S200, S249]i hβ
4
,[P100, P149]i 120
hβ
2
,[S200, S249]i hβ
5
,[P300, P349]i [250,299]
hβ
1
,[S200, S249]i hβ
6
,[P550, P599]i 200
hβ
3
,[S350, S399]i hβ
5
,[P300, P349]i [450,499]
hβ
3
,[S350, S399]i hβ
4
,[P100, P149]i [400,449]
(e) Abstract Table ”Supp − Part
]
”
P −id
]
Pname
]
hβ
4
,[P100, P149]i Screw
hβ
5
,[P300, P349]i Bolt
hβ
6
,[P550, P599]i Nut
(f) Abstract Table ”Part
]
”
QTY in ”Supp-Part” table are confidential (marked
with N in parenthesis). If we abstract S-id and P-
id in ”Supp-Part” only by the abstract values from
the domain of intervals, we may loose the ability to
identify the tuples uniquely and also the secure link-
ing between ”Supplier” and ”Part” as well. To allow
the linking and to preserving the uniqueness of values
over abstract domain we use Type-2 variable while
abstracting the confidential information as depicted
in abstract tables ”Supplier
]
”, ”Part
]
” and ”Supp-
Part
]
” in Table 3. To perform this we follow the la-
beling algorithm of (Wang et al., 2007). Observe that
since the attribute QTY is not primary key or foreign
key we abstract them only by the abstract values from
the domain of intervals.
5 QUERY EVALUATION UNDER
OFGAC
A general framework for Abstract Interpretation of
Relational Databases has been introduced in (Halder
and Cortesi, 2010). Here, we briefly recall some no-
tions on query abstraction, and we extend them by
considering queries on multiple abstractions as well.
Consider the following query Q
1
issued by an ex-
ternal user under the observational disclosure policy
op:
Q
1
= SELECT ∗ FROM emp WHERE Sal > 4800;
The original query above will be transformed into the
following abstract query under the policy op:
Q
]
1
= SELECT ∗ FROM emp
]
W HERE Sal
]
> 4800;
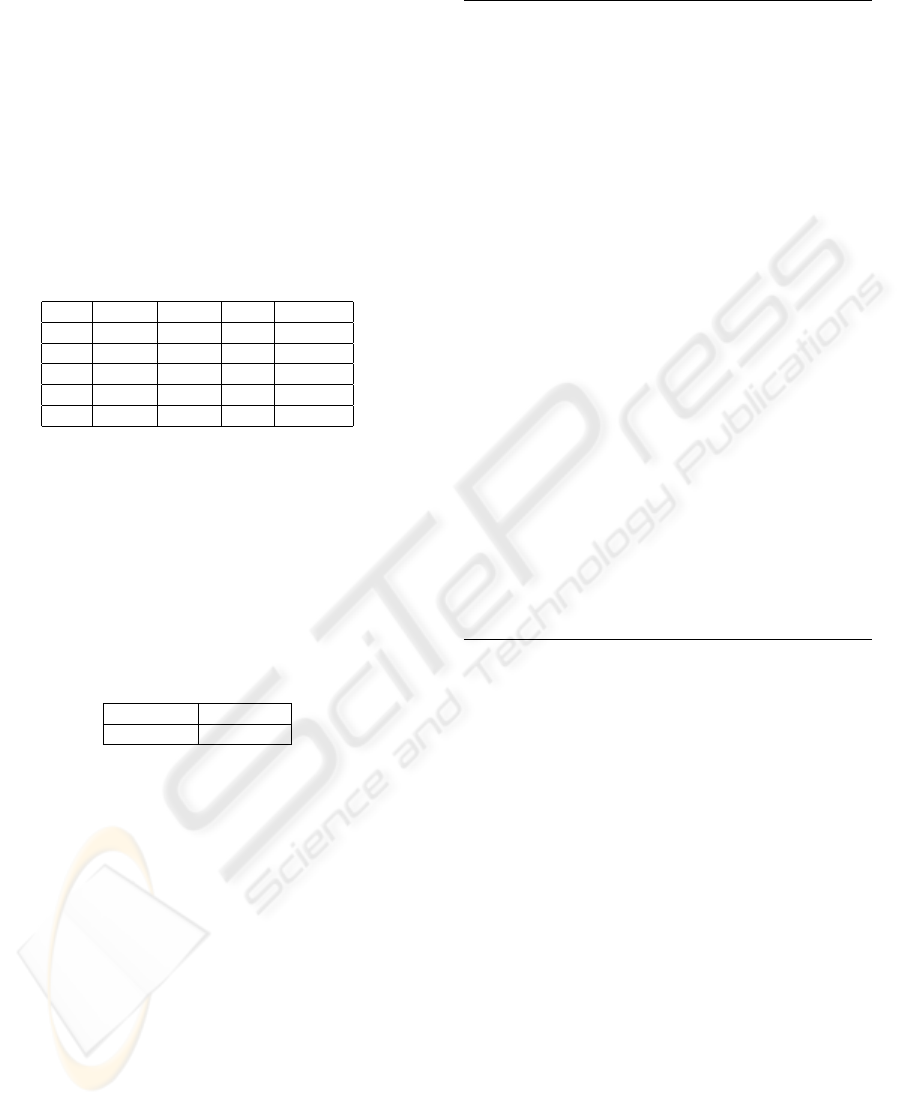
The result of Q
]
1
is depicted in Table 4. Observe that
for the first three tuples in the result, the condition
in the W HERE clause evaluates to true whereas for
the last tuple it evaluates to unknown (may be true
or may be f alse) logic value because x may be less,
equal or greater than 4800 where x ∈ γ(high). The re-
sult of Q
]
1
is sound (Halder and Cortesi, 2010) as it
over-approximate the result of the query Q
1
. Observe
in fact that Q
]
1
includes also the ”false positive” cor-
responding to the concrete information about Mita.
Table 4: The result of the query Q
]
1
.
eID
]
Name
]
Age
]
Dno
]
Sal
]
4 Male 35 1 Very high
5 Female [40,49] 3 4900
6 Male [50,59] 1 Very high
8 Female [20,29] 2 High
We denote any SQL command by a tuple Q ,
hA
sql
,φi. We call the first component A
sql
the active
part and the second component φ the passive part of
Q. In an abstract sense, any SQL command Q first
identifies an active data set from the database using
the pre-condition φ and then performs the appropriate
operations on that data set using the SQL action A
sql
.
The pre-condition φ appears in SQL commands as a
well-formed formula in first-order logic (Halder and
Cortesi, 2010).
Thus the evaluation of the pre-condition φ
]
of the
abstract query over the abstract database may results
into three logic values: true, f alse or unknown. The
evaluated value true indicates that the tuple satisfies
the semantic structure of φ
]
and f alse indicates that
the tuple does not satisfy φ
]
. The logic value unknown
indicates that the tuple may or may not satisfy the se-
mantic structure of φ
]
.
Given any abstract query Q
]
and abstract database
state σ
]
op
under the observation-based policy op, the
result for the query can, thus, be denoted by a tuple
ξ
]
= [[Q
]
]](σ
]
op
) = {ξ
]
yes
,ξ
]
may
}
where ξ
]
yes
is the part of the query result for which
semantic structure of φ
]
evaluates to true and
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
261
ξ
]
may
represents the remaining part for which φ
]
evaluates to unknown. Observe that we assume
ξ
]
yes
∩ ξ
]
may
=
/
0. For example, in the query result for
Q
]
1
as depicted in the Table 4, the first three tuples
belong to ξ
]
yes
1
whereas the last tuple belongs to ξ
]
may
1
.
Now consider the following query Q
]
2
:
Q
]
2
= SELECT ∗ FROM emp
]
W HERE Age
]
BETW EEN 32 AND 55;
The result of Q
]
2
is depicted in Table 5 where the
tuples with age values 35, 40 and 48 belong to ξ
]
yes
2
and the remaining tuples belong to ξ
]
may
2
.
Table 5: The result of the query Q
]
2
.
eID
]
Name
]
Age
]
Dno
]
Sal
]
3 Female [50,59] 2 2300
4 Male 35 1 Very high
5 Female [40,49] 3 4900
6 Male [50,59] 1 Very high
7 Male 48 3 800
5.1 Queries with Aggregate Functions
Let us apply the aggregate functions in the query Q
]
2
which yield to the modified query Q
]
3
as follows:
Q
]
3
=SELECT COUNT
]
(∗), AV G
]
(Age
]
)
FROM emp
]
W HERE Age
]
BETW EEN 32 AND 55;
The query result of Q
]
3
is depicted in Table 6.
Table 6: The result of the query Q
]
3
.
COUNT
]
(∗) AV G
]
(Age
]
)
[3,5] [41.33,48.2]
To illustrate the execution of Q
]
3
we first define
some functions: let the elements of the domain of in-
tervals are represented by [x,y] where x,y ∈ Z ∧x ≤ y,
and ξ
]
= {ξ
]
yes
,ξ
]
may
} be the result of the query Q
]
over
the abstract database state σ
]
op
under OFGAC policy
op. Table 7 defines some essential functions over the
concrete/abstract elements.
We are now in position to illustrate the execution
of the aggregate functions involved in Q
]
3
.
1. COUNT
]
(∗): The result for COUNT
]
(∗) is rep-
resented by the abstract value [a,b] where a =
count(ξ
]
yes
) and b = count(ξ
]
yes
∪ ξ
]
may
).
In the result of Q
]
3
, three tuples satisfy the pre-
condition and belong to ξ
]
yes
3
whereas remaining
two tuples belong to ξ
]
may
3
. Thus the result of
COUNT
]
(∗) is represented by the abstract value
[3,5]. It means the count of the tuples in the result
of Q
]
3
is any value within the interval of 3 and 5.
Table 7: The functions over the concrete/abstract domain.
min([x,y]) returns x
max([x,y]) returns y
average(hx,yi) returns the average of x and y
average(h[x,y],zi) [average(hx,zi),average(hy,zi)]
average(h[x,y],[w,z]i) [average(hx, wi),average(hy, zi)]
summation(hx,yi) returns the sum of x and y
summation(h[x,y],zi) [summation(hx, zi),summation(hy,zi)]
summation(h[x,y],[w,z]i) [summation(hx,wi),summation(hy, zi)]
minimum(hx,yi) returns the minimum between x and y
minimum(h[x,y], zi) [min([x,z]), min([y, z])]
minimum(h[x,y], [w, z]i) [min([x, w]),min([y,z])]
maximum(hx,yi) returns the maximum between x and y
maximum(h[x,y], zi) [max([x,z]), max([y,z])]
maximum(h[x,y], [w, z]i) [max([x, w]),max([y,z])]
ξ
]
(att
]
) returns the list of values of the attribute
att
]
appearing in the query result ξ
]
count(ξ
]
) returns the number of tuples in ξ
]
2. AV G
]
(Age
]
): The average value of ages over
the abstract domain (represented by the do-
main of intervals) is denoted by AV G
]
(Age
]
) =
[min(a),max(b)] where a = average(ξ
]
yes
(Age
]
))
is the average value of those ages for which
the precondition evaluates to true and b =
average(ξ
]
yes
(Age
]
) ∪ ξ
]
may
(Age
]
)) represents the
average value of the ages for which precondition
evaluates to either true or unknown.
In the result of Q
]
3
, thus, we have a = [a
1
, a
2
]
= average(35, [40,49], 48) = [41.33, 44] where
a
1
= average(35, 40, 48) = 41.33 and a
2
=
average(35, 49, 48) = 44. Similarly, b = [b
1
, b
2
] =
average([50,59], 35, [40,49], [50,59], 48) = [44.6,
48.2] where b
1
= average(50, 35, 40, 50, 48) =
44.6 and b
2
= average(59, 35, 40, 59, 48) = 48.2.
Thus AV G
]
(Age
]
) = [min(a), max(b)] = [41.33,
48.2] where min(a) = min([41.33,44]) = 41.33 and
max(b) = max([44.6,48.2]) = 48.2.
Similarly, we can define the computation of other ag-
gregate functions as follows:
• SUM
]
(att
]
) = [min(a), max(b)],
where a = summation(ξ
]
yes
(att
]
)) ∧ b =
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
262

summation(ξ
]
yes
(att
]
) ∪ ξ
]
may
(att
]
))
• MAX
]
(att
]
) = [max(a), max(b)], where
a = maximum(ξ
]
yes
(att
]
)) ∧ b = maximun(ξ
]
yes
(att
]
) ∪
ξ
]
may
(att
]
))
• MIN
]
(att
]
) = [min(a), min(b)], where
a = minimum(ξ
]
yes
(att
]
)) ∧ b = minimum(ξ
]
yes
(att
]
) ∪
ξ
]
may
(att
]
))
5.2 Query with Negation i.e. MINUS,
NOT IN, NOT EXISTS
Consider the query of the form Q
]
= Q
]
1
−Q
]
2
. Let the
query result for Q
]
1
is ξ
]
1
= hξ
]
yes
1
,ξ
]
may
1
i. Similarly,
the query result for the query Q
]
2
is ξ
]
2
= hξ
]
yes
2
,ξ
]
may
2
i.
The query result for Q
]
after performing difference
operation between the result of Q
]
1
and Q
]
2
is as fol-
lows:
ξ
]
= hξ
]
yes
1
− (ξ
]
yes
2
∪ ξ
]
may
2
),ξ
]
may
1
− ξ
]
yes
2
i
Observe that to ensure the soundness of the result
of the query involving negation the first component
ξ
]
yes
1
− (ξ
]
yes
2
∪ ξ
]
may
2
) contains those tuples for which
the precondition strictly evaluates to true whereas for
the second component ξ
]
may
1
− ξ
]
yes
2
the precondition
may evaluate to either true or unknown.
Let us illustrate with an example. Consider the fol-
lowing query:
Q
]
= Q
]
1
− Q
]
2
where,
Q
]
1
= SELECT ∗ FROM emp
]
W HERE sal
]
> 2500;
and
Q
]
2
= SELECT ∗ FROM emp
]
W HERE sal
]
> 5500;
The query results for Q
]
1
and Q
]
2
are depicted in Table
8(a) and 8(b) respectively. In Table 8(a), for the first
tuple the pre-condition of Q
]
1
evaluates to unknown
(thus, belongs to ξ
]
may
1
) whereas for the remaining
four tuples it evaluates to true logic value (thus, be-
longs to ξ
]
yes
1
). Similarly, in Table 8(b), for the first
two tuples the pre-condition of Q
]
2
evaluates to true
(hence, belongs to ξ
]
yes
2
) whereas for the last one it
evaluates to unknown logic value (hence, belongs to
ξ
]
may
2
). Thus the first component ξ
]
yes
of the result
of Q
]
is obtained by MINUS-ing (ξ
]
yes
2
∪ ξ
]
may
2
) from
ξ
]
yes
1
which consists of the tuple with eID
]
=5 and the
second component ξ
]
may
of the result of Q
]
is obtained
by MINUS-ing ξ
]
yes
2
from ξ
]
may
1
which consists of the
tuple with eID
]
=1 as shown in Table 8(c).
Table 8: Query results for Q
]
1
, Q
]
2
and Q
]
.
eID
]
Name
]
Age
]
Dno
]
Sal
]
1 Male 30 2 Medium
4 Male 35 1 Very high
5 Female [40,49] 3 4900
6 Male [50,59] 1 Very high
8 Female [20,29] 2 High
(a) Query result for Q
]
1
eID
]
Name
]
Age
]
Dno
]
Sal
]
4 Male 35 1 Very high
6 Male [50,59] 1 Very high
8 Female [20,29] 2 High
(b) Query result for Q
]
2
eID
]
Name
]
Age
]
Dno
]
Sal
]
1 Male 30 2 Medium
5 Female [40,49] 3 4900
(c) Query result for Q
]
Observe that the treatment of queries under our
OFGAC framework extends the corresponding sce-
nario discussed in (Wang et al., 2007; Zhu et al., 2008;
Shi et al., 2009), that can be seen as a special case
when the only abstraction considered on to NULL
(and the ”may” part of the query results is always
empty).
6 RELATED WORKS
In (Wang et al., 2007) the authors proposed a for-
mal notion of correctness in fine-grained database ac-
cess control. They show why the existing approaches
(LeFevre et al., 2004) fall short in some circumstances
with respect to soundness and security requirements,
like when a query contains any negation, as expressed
using the keywords MINUS, NOT EXISTS or NOT
IN. Moreover, they proposed a labeling approach for
masking unauthorized information by using two types
of special variables as well as a secure and sound
query evaluation algorithm in case of cell-level dis-
closure policies.
In (Zhu et al., 2008; Shi et al., 2009), the authors
observe that the proposed algorithm in (Wang et al.,
2007) is unable to satisfy the soundness property for
the queries which include the negation NOT IN or
NOT EXISTS. They divide the approaches which im-
plement FGAC into two: FGAC-then-enforced (FTE)
and FGAC-first-enforced (FFE). In the first case i.e.
FTE, three types of information leakages may take
place: Truth Value Information Leakage, Range In-
formation Leakage and UnNull Information Leakage.
They propose an enforcing rule to control the infor-
mation leakage by using FFE approach where the
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
263

query is executed on an operational relation rather
than the original relation. The operational relation is
obtained from the original one by disregarding those
tuples in the original relation for which the value of
the sensitive attributes (the attributes occur in the con-
ditional part of the query) are not authorized. How-
ever, although the algorithm for Enforcing Rule satis-
fies the soundness and security properties for all SQL
queries, it would not reach the maximum property.
The authors in (B
¨
ottcher et al., 2008) consider the
environment where the secret information is shared
among multiple partners and has a strong possibility
for the secret information to be inferred from database
queries and disclose to a third party illegally. They
model the secret information by an existentially quan-
tified boolean query. They have presented a formal
model of secret information disclosure that defines a
query to be suspicious if and only if the disclosed se-
cret could be inferred from its answer.
Agrawal et al. (Agrawal et al., 2005) introduced
the syntax of a fine grained restriction command at
column level, row level, or cell level. The purposes
and/or recipients for which the access is allowed can
also be specified in the restriction. Multiple restric-
tion can be combined by performing Intersection or
Union of all restrictions. The enforcement algorithm
automatically combines the restrictions relevant to in-
dividual queries annotated with purpose and recipi-
ent information and transforms the user’s query into
an equivalent query over a dynamic view that imple-
ments the restriction.
In (Zhu and L
¨
u, 2007) the authors extend the
SQL language to express the FGAC security policies.
Many policy instances of a policy type can be created
when needed. The created policy statement takes at
least two parameters: subjects and target. The sub-
ject can be user, role or users in a group whereas
target specifies a table or view or columns in the ta-
ble. Moreover it specifies the operations on the ob-
jects that the security policy restricts and the filter list
that specifies the data to be accessed in the specific
objects. Finally it has constraint expressions whose
truth value determine whether the policy will be exe-
cuted or not.
Rizvi et al. in (Rizvi et al., 2004) described
two models for fine-grained access control: the Tru-
man and Non-Truman models. Both models support
authorization-transparent querying. They defined the
notions of unconditional and conditional validity of
the query, and presented several inference rules for
validity. They outlined an approach to validity test-
ing, based on extending an existing query optimizer
to carry out validity checking, minimizing the extra
effort required during coding as well as during valid-
ity testing.
In the view replacement approach, the base rela-
tions in a query submitted by a user are replaced by
authorized views. The original query is added with
additional predicates/joins that ensure that the query
accesses only authorized tuples. In such cases the
additional authorization checks introduced by view
replacement would be redundant. In (Kabra et al.,
2006), authors described the set of transformation
rules for redundancy removal. They defined when a
query plan is safe with respect to user defined func-
tions (UDFs) and other unsafe functions (USFs), and
proposed techniques to generate safe query plans.
However, this safe query plan may yield to un-
optimized plan. The study also showed that leakage
of information through USFs, exceptions and error
messages can be efficiently tackled by choosing good
safe plans.
In (Hsu et al., 2002), authors present a quantita-
tive model for privacy protection. In the model, a for-
mal representation of the user’s information states is
given, and they estimate the value of information for
the user by considering a specific user model. Un-
der the user model, the privacy protection task is to
ensure that the user cannot profit from obtaining the
private information. They further define the useful-
ness of information based on how easy the data user
can locate individuals that fit the description given in
the queries. The knowledge states and the usefulness
of information can be changed or refined by receiving
some answer to the user’s query.
7 CONCLUSIONS
In this paper we introduce an Observation-based Fine
Grained Access Control (OFGAC) framework on top
of the traditional FGAC where the confidential infor-
mation in the database are abstracted by their observ-
able properties and the external observers are able to
see this partial or abstract view of the confidential in-
formation rather than their exact contents. The tra-
ditional FGAC can be seen as a special case of our
OFGAC, where the confidential information are ab-
stracted by the top-most element of the corresponding
abstract lattices.
ACKNOWLEDGEMENTS
Work partially supported by Italian MIUR COFIN’07
project “SOFT” and by RAS project TESLA - Tec-
niche di enforcement per la sicurezza dei linguaggi e
delle applicazioni.
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
264

REFERENCES
Agrawal, R., Bird, P., Grandison, T., Kiernan, J., Logan, S.,
and Rjaibi, W. (2005). Extending relational database
systems to automatically enforce privacy policies. In
Proceedings of the 21st International Conference on
Data Engineering, ICDE ’05, pages 1013–1022. IEEE
Computer Society.
Bertino, E., Jajodia, S., and Samarati, P. (1999). A flexi-
ble authorization mechanism for relational data man-
agement systems. ACM Transactions on Information
Systems, 17(2):101–140.
B
¨
ottcher, S., Hartel, R., and Kirschner, M. (2008). Detect-
ing suspicious relational database queries. In Proceed-
ings of the 3rd International Conference on Availabil-
ity, Reliability and Security, ARES ’08, pages 771–
778. IEEE Computer Society.
Cousot, P. and Cousot, R. (1977). Abstract interpretation: a
unified lattice model for static analysis of programs by
construction or approximation of fixpoints. In Con-
ference Record of the Sixth Annual ACM SIGPLAN-
SIGACT Symposium on Principles of Programming
Languages, pages 238–252, Los Angeles, CA, USA.
ACM Press.
Giacobazzi, R., Ranzato, F., and Scozzari, F. (2000). Mak-
ing abstract interpretations complete. Journal of the
ACM (JACM), 47(2):361–416.
Griffiths, P. P. and Wade, B. W. (1976). An authorization
mechanism for a relational database system. ACM
Transactions on Database Systems, 1(3):242–255.
Halder, R. and Cortesi, A. (2010). Abstract interpretation
for sound approximation of database query languages.
In Proceedings of the IEEE 7th International Confer-
ence on INFOrmatics and Systems (INFOS2010), Ad-
vances in Data Engineering and Management Track,
pages 53–59, Cairo, Egypt. IEEE Catalog Number:
IEEE CFP1006J-CDR.
Hsu, T.-s., Liau, C.-J., Wang, D.-W., and Chen, J. K.-P.
(2002). Quantifying privacy leakage through answer-
ing database queries. In Proceedings of the 5th Inter-
national Conference on Information Security, ISC ’02,
pages 162–176, London, UK. Springer-Verlag.
Jajodia, S., Samarati, P., Subrahmanian, V. S., and Bertino,
E. (1997). A unified framework for enforcing multiple
access control policies. SIGMOD Record, 26(2):474–
485.
Kabra, G., Ramamurthy, R., and Sudarshan, S. (2006). Re-
dundancy and information leakage in fine-grained ac-
cess control. In Proceedings of the ACM SIGMOD in-
ternational conference on Management of data, SIG-
MOD ’06, pages 133–144, Chicago, IL, USA. ACM
Press.
LeFevre, K., Agrawal, R., Ercegovac, V., Ramakrishnan,
R., Xu, Y., and DeWitt, D. (2004). Limiting disclosure
in hippocratic databases. In Proceedings of the 30th
international conference on Very large data bases,
VLDB ’04, pages 108–119. VLDB Endowment.
Rizvi, S., Mendelzon, A., Sudarshan, S., and Roy, P.
(2004). Extending query rewriting techniques for fine-
grained access control. In Proceedings of the ACM
SIGMOD international conference on Management of
data, SIGMOD ’04, pages 551–562, Paris, France.
ACM Press.
Sabelfeld, A. and Myers, A. C. (2003). Language-based
information-flow security. IEEE Journal on selected
areas in Communications, 21(1):5–19.
Shi, J., Zhu, H., Fu, G., and Jiang, T. (2009). On the sound-
ness property for sql queries of fine-grained access
control in dbmss. In ICIS ’09: Proceedings of the
2009 Eigth IEEE/ACIS International Conference on
Computer and Information Science, pages 469–474,
Shanghai, China. IEEE Computer Society.
Wang, Q., Yu, T., Li, N., Lobo, J., Bertino, E., Irwin, K.,
and Byun, J.-W. (2007). On the correctness criteria
of fine-grained access control in relational databases.
In Proceedings of the 33rd international conference
on Very large data bases, VLDB ’07, pages 555–566,
Vienna, Austria. VLDB Endowment.
Zhu, H. and L
¨
u, K. (2007). Fine-grained access control for
database management systems. In Proceedings of the
24th British National Conference on Databases, pages
215–223, Glasgow, UK. Springer Verlag LNCS.
Zhu, H., Shi, J., Wang, Y., and Feng, Y. (2008). Controlling
information leakage of fine-grained access model in
dbmss. In Proceedings of the 9th International Con-
ference on Web-Age Information Management, WAIM
’08, pages 583–590, Zhangjiajie, China. IEEE Com-
puter Society.
OBSERVATION-BASED FINE GRAINED ACCESS CONTROL FOR RELATIONAL DATABASES
265
