
JSIMIL
A Java Bytecode Clone Detector
Luis Quesada, Fernando Berzal and Juan Carlos Cubero
Department of Computer Science and Artificial Intelligence, CITIC, University of Granada, Granada 18071, Spain
Keywords:
Java bytecode, Clone detection, Metrics, Hierarchical matching.
Abstract:
We present JSimil, a code clone detector that uses a novel algorithm to detect similarities in sets of Java pro-
grams at the bytecode level. The proposed technique emphasizes scalability and efficiency. It also supports
customization through profiles that allow the user to specify matching rules, system behavior, pruning thresh-
olds, and output details. Experimental results reveal that JSimil outperforms existing systems. It is even able
to spot similarities when complex code obfuscation techniques have been applied.
1 INTRODUCTION
Code clone detection can expose many interesting
features that are deeply embedded in the program
source code: common clusters of sentences, perfect
or almost perfect code matches, limits of the program-
ming language and derived workarounds, coding style
or lack thereof, and programming antipatterns.
Furthermore, tracking down duplicated code
clusters has many commercial applications, as it
can be used to prove plagiarism in legal disputes
over intellectual property rights or software patents
(Belkhouche et al., 2004), help in automatic refactor-
ization or code maintenance (Tairas, 2008), and com-
pare student assignments (Cosma and Joy, 2006).
Most traditional techniques include string match-
ing, whose variants are implemented by YAP3 (Wise,
1996) and Baker and Mamber’s (Baker and Manber,
1998); string hash matching, as in Moss (Schleimer
et al., 2003); token-based matching, as implemented
by JPlag (Prechelt et al., 2000), CP-Miner (Li et al.,
2006), and CCFinder (Kamiya et al., 2002); or
control-flow graph analysis and its variants, as the en-
hanced CFGs used by JDiff (Apiwattanapong et al.,
2007).
More recent techniques compare program depen-
dence graphs (Krinke, 2001), as in GPLAG (Liu et al.,
2006); analyze simplifications of program behavior,
either in the way of program slices (Weiser, 1981) or
by considering them as black boxes, as implemented
by Semantic Diff (Jackson and Ladd, 1994); or calcu-
late and compare metrics (Dunsmore, 1984).
These code clone detectors are hard-coded and
they are not customizable at all, hence the results they
produce can be inaccurate beyond the specific situa-
tions they are designed for. In contrast, JSimil is cus-
tomizable to fit any need.
2 JSIMIL
JSimil is a code clone detector that performs a heuris-
tic matching of program hierarchies at the bytecode
level.
JSimil results, which are comprised of nested ele-
ments matches, are generated by matching the classes,
the methods, and the basic blocks within Java soft-
ware. Several metrics, such as the number of differ-
ent kinds of instruction, are calculated for every basic
block.
JSimil input consists of a configuration file, which
determines the paths to both compiler and disassem-
bler and options about their usage; a profile, which
determines the system behavior, thresholds, pruning
rules, and output detail; and data input, which con-
tains the source code (.java) files, bytecode (.jar or
.class) files, or a mix of them, of the programs to com-
pare. The output is a browsable hierarchy of matches
across programs and their elements.
2.1 Hierarchical Matching
Matching is done at the block level, the method
level, the class level, and the program level. Cus-
333
Quesada L., Berzal F. and Carlos Cubero J. (2010).
JSIMIL - A Java Bytecode Clone Detector.
In Proceedings of the 5th International Conference on Software and Data Technologies, pages 333-336
DOI: 10.5220/0003013403330336
Copyright
c
SciTePress

tomized profiles determine how the system performs
the matching.
2.1.1 Block Matching
The normalized similarity S
b
for any two blocks (b
1
and b
2
) is calculated as follows:
S
b
(b
1
, b
2
) = 1−
∑
M
i=0
|b
1
(i) − b
2
(i)| ∗ w(i)
∑
M
i=0
max{b
1
(i), b
2
(i)} ∗ w(i)
(1)
where M is the number of metrics computed for the
blocks, b
x
(i) is the value of the ith measure for the x
block, and w(i) is the weight for the ith measure as
defined in the profile.
It should be noted that S
b
(b
1
, b
2
) = S
b
(b
2
, b
1
).
2.1.2 Method Matching
The normalized similarity S
m
for any two methods is
calculated by choosing one of them (m
1
) according
to profile parameters and method size, ordering its
blocks by decreasing size, and matching them with
the ones in the other method (m
2
) by applying the fol-
lowing expression:
S
m
(m
1
, m
2
) =
B
m
1
∑
i=0
S
b
(m
1
(b
i
), bm
b
(m
2
, m
1
(b
i
))) ∗ s(m
1
(b
i
))
(2)
where B
m
x
is the number of blocks contained in m
x
;
m
x
(b
i
) is the ith block in the method m
x
, ordered
by decreasing size; bm
b
(m
x
, m
y
(b
i
)) is the block con-
tained in m
x
that best matches the block b
i
in m
y
; and
s(m
x
(b
i
)) is the number of instructions of the block b
i
in m
x
.
The profile parameters also determine which
method matchings are tried and which blocks are ef-
fectively matched, according to similarity thresholds,
elements sizes, and already matched elements, among
other factors.
In general, S
m
(m
x
, m
y
) 6= S
m
(m
y
, m
x
) because the
best match for m
x
(b
i
) might be m
y
(b
j
) but the best
match for m
y
(b
j
) might not be m
x
(b
i
).
2.1.3 Class Matching
The normalized similarity S
c
for any two classes is
calculated like the S
m
method similarity, just by re-
placing blocks (b) with methods (m) and methods (m)
with classes (c). Formally:
S
c
(c
1
, c
2
) =
M
c
1
∑
i=0
S
m
(c
1
(m
i
), bm
m
(c
2
, c
1
(m
i
))) ∗ s(c
1
(m
i
))
(3)
Two classes will be matched only if their similar-
ity is higher than an user-defined profile threshold.
When any class is not matched, its methods ascend
through the hierarchy and the program temporary be-
comes their parent, so they can be matched in the pro-
gram matching step.
It should be noted that S
c
(c
1
, c
2
) 6= S
c
(c
2
, c
1
), by
the same reason that S
m
(m
1
, m
2
) 6= S
m
(m
2
, m
1
).
2.1.4 Program Matching
The normalized similarity S
p
for any two programs is
calculated by choosing one of them (p
1
) according to
its size and the profile parameters, ordering its classes
and still-unmatched methods by decreasing size, and
matching them with the ones in the other program
(p
2
) by applying the following expression:
S
p
(p
1
, p
2
) =
C
p
1
∑
i=0
S
c
(p
1
(c
i
), bm
c
(p
2
, p
1
(c
i
))) ∗ s(p
1
(c
i
))+
U
p
1
∑
i=0
S
m
(p
1
(u
i
), bm
u
(p
2
, p
1
(u
i
))) ∗ s(p
1
(u
i
))
(4)
where C
p
x
is the number of classes contained in p
x
;
p
x
(c
i
) is the ith class in the program p
x
, ordered by
decreasing size; bm
c
(p
x
, p
y
(c
y
)) is the class contained
in p
x
that best matches the class c
i
of p
y
; s(p
x
(c
i
)) is
the number of instructions in class c
i
in p
x
; U
p
x
is the
number of still unmatched methods contained in p
x
;
p
x
(u
i
) is the ith unmatched method in the program
p
x
, ordered by decreasing size; bm
u
(p
x
, p
y
(u
i
)) is the
unmatched method contained in p
x
that best matches
the method u
i
in p
y
; and s(p
x
(u
i
)) is the number of
instructions of the still-unmatched method u
i
in p
x
.
It should be noted that S
p
(p
1
, p
2
) 6= S
p
(p
2
, p
1
), by
the same reason that S
m
(m
1
, m
2
) 6= S
m
(m
2
, m
1
) and
S
c
(c
1
, c
2
) 6= S
c
(c
2
, c
1
).
2.2 JSimil Profiles
Profiles are the main novelty of the proposed clone
detector and they are, indeed, key to JSimil flexibility.
Profiles contain parameters that allow the user
to fine-tune the behavior of the system by adjusting
matching thresholds, and rules, output detail level,
pruning thresholds and metrics weights.
JSimil distribution package includes JSimil Pro-
file Manager, a tool for designing profiles that offers
contextual help and shows several profile properties,
both as normalized numeric values and as a Kiviat di-
agram called profile fingerprint (Figure 1):
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
334
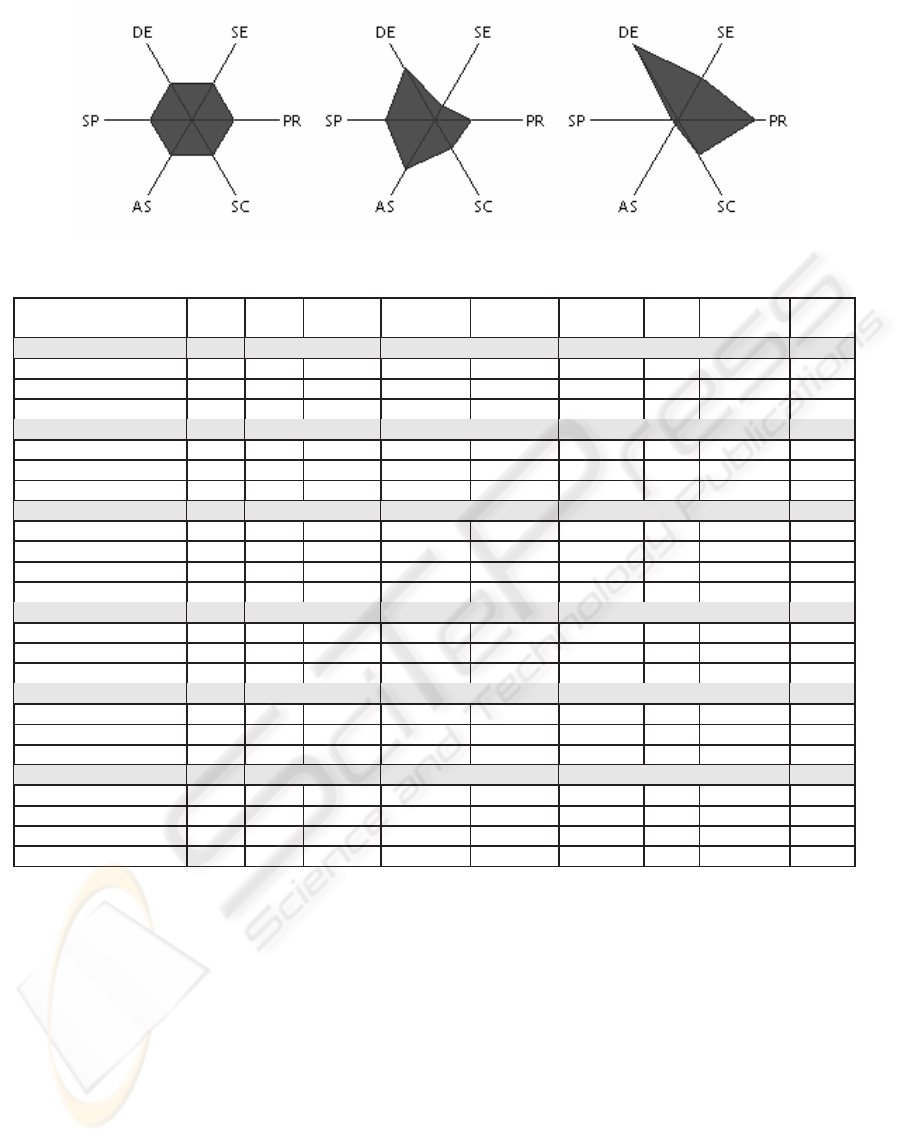
Figure 1: Fingerprints for default, student assignment plagiarism detection, and exhaustive profiles.
JPlag Moss GPLAG CP-Miner CCFinder Semantic JDiff Baker and JSimil
Diff Manber’s
Applications
Plagiarism ✓ ✓ ✓ ✗ ✗ ✗ ✗ ✗ ✓
Copy&Pasted code ✗ ✗ ✗ ✓ ✓ ✗ ✗ ✓ ✓
Diff ✗ ✗ ✗ ✗ ✗ ✓ ✓ ✗ ✓
Supported inputs
Source code (java) ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✗ ✓
Bytecode (jar/class) ✗ ✗ ✗ ✗ ✗ ✓ ✗ ✓ ✓
Mixed ✗ ✗ ✗ ✗ ✗ ✓ ✗ ✗ ✓
Supported outputs
Plain text ✗ ✓ ✗ ✓ ✓ ✓ ✓ ✓ ✓
HTML ✓ ✗ ✓ ✗ ✗ ✗ ✗ ✗ ✓
XML ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Diff alike ✗ ✗ ✗ ✗ ✗ ✓ ✓ ✓ ✓
Robustness
Textual changes ✓ ✓ ✓ ✗ ✓ ✓ ✓ ✓ ✓
Code reordering ✗ ✗ ✓ ✗ ✗ ✓ ✗ ✗ ✓
Code insertion ✗ ✗ ✓ ✗ ✗ ✓ ✗ ✗ ✓
Optimizations
Parallelized ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Supports pruning ✗ ✗ ✓ ✗ ✗ ✗ ✗ ✗ ✓
Hierarchical matching ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Customization
System behavior ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Matching rules ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Output detail ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✗ ✓
Pruning thresholds ✗ ✗ ✓ ✗ ✗ ✗ ✗ ✗ ✓
Figure 2: Qualitative comparison of existing clone detectors and JSimil.
• Speed (SP) measures the number of used options
that help reduce processing time.
• Detail (DE) measures the amount of data that will
be generated.
• Sensibility (SE) measures how much partial re-
sults may influence global results.
• Precision (PR) measures how small the margin of
error will be.
• Specialization (SC) measures the amount of op-
tions with non-standard values.
• Assimilation (AS) measures the amount of pre-
vious knowledge provided by the user to obtain
better results.
These properties correspond to the visible charac-
teristics of the system behavior the user will be most
concerned about.
3 EXPERIMENTAL
COMPARISON
A table summarizing the capabilities of similarity de-
tection systems is shown in Figure 2.
JSimil was able to obtain more accurate results
than other system in the comparison of 222 student
JSIMIL - A Java Bytecode Clone Detector
335

assignments that was performedin order to detect pla-
giarism. JSimil matched the 222 student assignments,
of 200KB source code each on average, among them-
selves (a total of 24753 program-program matches) in
30 seconds using JSimil plagiarism detection profile,
which corresponds to a millisecond per match on an
mid-range Intel Quad Core personal computer.
4 CONCLUSIONS
We have described a Java code clone detector sys-
tem that uses a novel hierarchical matching technique
that solves issues that affect similar existing systems
and offers advantages over them, such as: support for
all Java constructs, the possibility of comparing pro-
grams when only bytecode is available, browsing re-
sults, a parallelized implementation, and pruning non-
significant matches to reduce processing time.
The profiles allow users to adjust system behavior
so unwanted features may be removed and algorithm
adjustments can be made.
The proposed algorithm is not sensitive to com-
mon obfuscation and plagiarism concealing tech-
niques that other systems are sensitive to. In fact, the
experimental results revealed that JSimil outperforms
existing systems as it is able to detect similarities they
cannot.
Currently, JSimil matches hierarchies of Java
bytecode whose leaf nodes are sets of metrics com-
puted from basic blocks. JSimil can be extended by
giving the system a description of the hierarchy to
be used to match data from different sources using
the same profiles. This will give researchers the pos-
sibility of developing general profiles (for example,
for difference detection or similarity detection) that
would define how to match any kind of hierarchical
data.
REFERENCES
Apiwattanapong, T., Orso, A., and Harrold, M. J. (2007).
JDiff: a differencing technique and tool for object-
oriented programs. Automated Software Engineering,
14(1):3–36.
Baker, B. S. and Manber, U. (1998). Deducing similarities
in java sources from bytecodes. In Proc. of Usenix
Annual Technical Conference, pages 179–190.
Belkhouche, B., Nix, A., and Hassell, J. (2004). Plagiarism
detection in software designs. In Proc. of the 42nd An-
nual Southeast Regional Conference, pages 207–211.
Cosma, G. and Joy, M. (2006). Source-code plagiarism:
a UK academic perspective. Technical Report 422,
University of Warwick.
Dunsmore, H. E. (1984). Software metrics: an overview
of an evolving methodology. Information Processing
and Management, 20(1-2):183–192.
Jackson, D. and Ladd, D. A. (1994.). Semantic Diff: a tool
for summarizing the effects of modifications. In Proc.
of the International Conference on Software Mainte-
nance, pages 243–252.
Kamiya, T., Kusumoto, S., and Inoue, K. (2002). CCFinder:
a multilinguistic token-based code clone detection
system for large scale source code. IEEE Transactions
on Software Engineering, 28(7):654–670.
Krinke, J. (2001). Identifying similar code with program
dependence graphs. In Proc. of the 8th Working Con-
ference on Reverse Engineering, pages 301–309.
Li, Z., Lu, S., Myagmar, S., and Zhou, Y. (2006). CP-
Miner: Finding copy-paste and related bugs in large-
scale software code. IEEE Transactions on Software
Engineering, 32(2):176–192.
Liu, C., Chen, C., and Han, J. (2006). GPLAG: Detection
of software plagiarism by program dependence graph
analysis. In Proc. of the 12th ACM SIGKDD Interna-
tional Conference on Knowledge Discovery and Data
Mining, pages 872–881.
Prechelt, L., Malpohl, G., and Philippsen, M. (2000). JPlag:
Finding plagiarism among a set of programs. Techni-
cal Report 2000-1, University of Karlsruhe.
Schleimer, S., Wilkerson, D. S., and Aiken, A. (2003). Win-
nowing: Local algorithms for document fingerprint-
ing. In Proc. of the 22nd ACM SIGMOD International
Conference on Management of Data, pages 76–85.
Tairas, R. (2008). Clone maintenance through analysis and
refactoring. In Proc. of the 2008 Foundations of Soft-
ware Engineering Doctoral Symposium, pages 29–32.
Weiser, M. (1981). Program slicing. In Proc. of the 5th
International Conference on Software Engineering,
pages 439–449.
Wise, M. J. (1996). YAP3: Improved detection of similari-
ties in computer program and other texts. In Proc. of
the 27th SIGCSE Technical Symposium on Computer
Science Education, pages 130–134.
ICSOFT 2010 - 5th International Conference on Software and Data Technologies
336
