
A GIBBS DISTRIBUTION THAT LEARNS FROM GA DYNAMICS
Manabu Kitagata and Jun-ichi Inoue
Complex Systems Engineering, Graduate School of Information Science and Technology
Hokkaido University, N14-W9, Kita-ku, Sapporo 060-0814, Japan
Keywords:
Genetic algorithms, Evolutionary optimization, Machine learning, Population dynamics, Thermodynamics,
Average-case performance, Spin glass model, Statistical physics.
Abstract:
A general procedure of average-case performance evaluation for population dynamics such as genetic algo-
rithms (GAs) is proposed and its validity is numerically examined. We introduce a learning algorithm of Gibbs
distributions from training sets which are gene configurations (strings) generated by GA in order to figure out
the statistical properties of GA from the view point of thermodynamics. The learning algorithm is constructed
by means of minimization of the Kullback-Leibler information between a parametric Gibbs distribution and
the empirical distribution of gene configurations. The formulation is applied to a solvable probabilistic model
having multi-valley energy landscapes, namely, the spin glass chain. By using computer simulations, we dis-
cuss the asymptotic behaviour of the effective temperature scheduling and the residual energy induced by the
GA dynamics.
1 INTRODUCTION
Genetic Algorithm (GA) (H.Holland, 1975) is a
heuristics to find the best possible solution for com-
binatorial optimization problems and it is based on
several relevant operators such as selection, crossover
and mutation on the gene configurations (strings)
leading to transition from one state to the others. In
this paper, in order to figure out the statistical prop-
erties of GA from the view point of thermodynamics,
we introduce a learning algorithm of Gibbs distribu-
tions from training sets which are gene configurations
generated by GA. A procedure of average-case per-
formance evaluation for genetic algorithms is exam-
ined. The learning algorithm is constructed by means
of minimization of the Kullback-Leibler information
between a parametric Gibbs distribution and the em-
pirical distribution of gene configurations. The for-
mulation is applied to a solvable probabilistic model
having multi-valley energy landscapes, namely, the
spin glass chain (Li, 1981) in statistical physics. By
using computer simulations, we discuss the asymp-
totic behaviour of the effective temperature schedul-
ing and the residual energy induced by the GA dy-
namics.
2 GA AND SA
As we mentioned, in this paper,we consider the statis-
tical properties of GA from the view point of thermo-
dynamics. In simple GA, we define each gene config-
uration (member) by a string of binary variables with
length N, that is, s
s
s = (s
1
,s
2
,··· ,s
N
),s
i
∈ {−1,+1},
and we attempt to make each configuration in ensem-
ble with size M to the state which gives a minimum
of the energy function H(s
s
s), say, s
s
s
∗
D The problem
is systematically solved by GA if the system evolves
according to a Markovian process and the gene distri-
bution P
(t)
GA
(s
s
s) at time (generation)t might convergeas
P
(t)
GA
(s
s
s) →P
(∞)
GA
(s
s
s) and we have P
(∞)
GA
(s
s
s) = δ(s
s
s−s
s
s
∗
) =
∏
N
i=1
δ(s
i
−s
i∗
). On the other hand, one of the ef-
fective heuristics which is well-known as Simulated
Annealing (SA) (Kirkpatrick et al., 1983) is achieved
by inhomogeneous Markovian process. The process
is realized by Markov chain Monte Carlo method
(MCMC) which leads to an equilibrium Gibbs distri-
bution at temperature T = β
−1
(from now on, the β is
referred to as ‘inverse temperature’), namely,
P
(t)
B
(s
s
s) =
e
−β
(t)
H(s
s
s)
Z
, Z =
∑
s
s
s
e
−β
(t)
H(s
s
s)
. (1)
In SA, the temperature is scheduled very slowly in
time as β
(∞)
→ ∞ (T
(∞)
→ 0), and then, we can solve
295
Kitagata M. and Inoue J..
A GIBBS DISTRIBUTION THAT LEARNS FROM GA DYNAMICS.
DOI: 10.5220/0003047102950299
In Proceedings of the International Conference on Evolutionary Computation (ICEC-2010), pages 295-299
ISBN: 978-989-8425-31-7
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

the problem as P
(∞)
B
(s
s
s) = δ(s
s
s−s
s
s
∗
) =
∏
N
i=1
δ(s
i
−s
i∗
).
Therefore, both the GA and the SA share a concept
to make the distribution convergence to a single (or
several) delta-peak(s) at the solution(s). However, in
general, the Markovian (dynamical) process of GA is
very hard to treat mathematically due to the global
transition between the states by the crossoveror, espe-
cially, the mutation operator, whereas the SA causes
only local transitions between the states. From the
view point of EDA (Baluja, 1994), the dynamics of
GA should lead to an empirical distribution of states.
3 FORMULATION AND TOOLS
In this section, we explain our formulation and sev-
eral tools to evaluate the average-case performance of
GA through the effective temperature scheduling of
the Gibbs distribution that is trained from gene con-
figurations of simple GA.
3.1 Kullback-Leibler Information
We start our argument from the distance between an
empirical distribution from GA dynamics P
(t)
GA
(s
s
s) and
a Gibbs distribution P
(t)
B
(s
s
s) at the effective tempera-
ture T = β
−1
. The distance is measured by the fol-
lowing Kullback-Leibler information (KL)
KL(P
GA
kP
B
) =
∑
s
s
s
P
GA
(s
s
s)log
P
B
(s
s
s)
P
SA
(s
s
s)
(2)
where the summation with respect to all possible
gene configurations s
s
s = (s
1
,··· ,s
N
) is defined by
∑
s
s
s
(···) ≡
∑
s
1
=±1
···
∑
s
N
=±1
(···). In this paper, we
represent each component of gene configurations by
s
i
= ±1 instead of s
i
= 0,1 because we choose the cost
function of spin glasses to be minimized as a bench-
mark test later on. The ‘spin’ here means a tiny mag-
net in atomic scale-length and s
i
= +1 stands for ‘up-
spin’ and vice versa. We should keep in mind that the
above distance is dependent on the inverse temper-
ature β. Thus, we obtain the following Boltzmann-
machine-type learning equation with respect to β as
dβ
dt
= −
∂KL(P
(t)
GA
kP
(t)
B
)
∂β
=
∑
s
s
s
P
(t)
GA
(s
s
s) ·
∂P
(t)
B
(s
s
s)/∂β
P
(t)
B
(s
s
s)
.
(3)
We naturally expect that the effective temperature
evolves so as to minimize the KL information for each
time step. When both distributions become identical
one in the limit of t → ∞, namely, P
(∞)
GA
(s
s
s) = P
(∞)
B
(s
s
s),
we obtain
dβ
dt
=
∑
s
s
s
P
(∞)
GA
(s
s
s) ·{∂P
(∞)
B
(s
s
s)/∂β}/P
(∞)
B
(s
s
s)
= (∂/∂β)
∑
s
s
s
δ(s
s
s−s
s
s
∗
) = ∂α/∂β = 0 (4)
and the time evolution of inverse-temperature then
stops. We should notice that α ≡
∑
s
s
s
δ(s
s
s−s
s
s
∗
) is the
number of degeneracy at the lowest energy states.
3.2 Learning Equation for Spin Systems
Here we attempt to restrict ourselves to more particu-
lar problems, namely, we deal with a class of combi-
natorial optimization problems whose cost functions
are described by the energy function of Ising model.
We first reformulate the equation (3) by means of
Ising spin systems having the energy function H(s
s
s) =
−
∑
ij
J
ij
s
i
s
j
. For the case of positive constant spin-
spin interaction J
ij
= J > 0, ∀
i, j
, the lowest energy
state is apparently given by s
i
= +1, ∀
i
(all-up spins)
or s
i
= −1, ∀
i
(all-down spins). However, as we shall
see in the following sections, for the case of randomly
distributed J
ij
(the ± sign is also random), the low-
est energy state is highly degenerated and it becomes
very hard to find the state.
Substituting the corresponding Gibbs distribution
P
B
(s
s
s) = exp[−βH(s
s
s)]/
∑
s
s
s
exp[−βH(s
s
s)] into equation
(3), the learning equation leads to
dβ
dt
=
∑
s
s
s
P
GA
(s
s
s)
∑
ij
J
ij
s
i
s
j
!
−
∑
s
s
s
(
∑
ij
J
ij
s
i
s
j
)exp[β
∑
ij
J
ij
s
i
s
j
]
∑
s
s
s
exp[β
∑
ij
J
ij
s
i
s
j
]
(5)
where the second term appearing in the right hand
side of the above equation is internal energy of
the system described by the Hamiltonian H(s
s
s) =
−
∑
ij
J
ij
s
i
s
j
at temperature T = β
−1
, whereas the first
term is the energy H(s
s
s) averaged over the empirical
distribution P
GA
(s
s
s) of GA. Then, we immediately find
that the condition
∑
s
s
s
P
GA
(s
s
s)(
∑
ij
J
ij
s
i
s
j
) =
∑
s
s
s
P
B
(s
s
s)(
∑
ij
J
ij
s
i
s
j
)
=
∑
s
s
s
(
∑
ij
J
ij
s
i
s
j
)exp[β
∑
ij
J
ij
s
i
s
j
]
∑
s
s
s
exp[β
∑
ij
J
ij
s
i
s
j
]
(6)
yields dβ/dt = 0 for P
GA
(s
s
s) = P
B
(s
s
s).
In general, it is very hard to calculate the internal
energy of the spin system
U({J}: β) ≡ −
∑
s
s
s
(
∑
ij
J
ij
s
i
s
j
)exp[β
∑
ij
J
ij
s
i
s
j
]
∑
s
s
s
exp[β
∑
ij
J
ij
s
i
s
j
]
(7)
ICEC 2010 - International Conference on Evolutionary Computation
296
because 2
N
sums for all possible configurations in
∑
s
s
s
(···) are needed to evaluate the E({ J} : β), where
we defined a set of interactions by {J} ≡ {J
ij
|i, j =
1,··· ,N}. To overcome this difficulty, we usually use
the so-called Markov chain Monte Carlo (MCMC)
method to calculate the expectation (7) by important
sampling from the Gibbs distribution at temperature
T = β
−1
.
On the other hand, the first term appearing in the
right hand side of (5), we evaluate the expectation by
making use of
U
GA
({J}) ≡ −
∑
s
s
s
P
GA
(s
s
s)
∑
ij
J
ij
s
i
s
j
!
= − lim
L→∞
1
L
L
∑
l=1
∑
ij
J
ij
s
i
(t,l)s
j
(t,l)
!
(8)
where s
i
(t,l) is the l-th sampling point at time t from
the empirical distribution of GA. Namely, we shall
replace the expectation of the cost function H(s
s
s) =
−
∑
ij
J
ij
s
i
s
j
over the distribution P
GA
(s
s
s) by sampling
from the empirical distribution of GA.
By a simple transformation β → T
−1
in equation
(5), we obtain the Boltzmann-machine-type learning
equation with respect to effective temperature T as
follows.
dT
dt
= −T
2
U({J}: T
−1
) −U
GA
({J})
(9)
From this learning equation, we find that time-
evolution of effective temperature depends on the dif-
ference between the expectations of the cost function
over the Gibbs distribution at temperature T and the
empirical distribution of GA.
3.3 Average-case Performance
We should evaluate the ‘average-case performance’of
the learning equation which is independent of the re-
alization of ‘problem’ {J}. Namely, one should eval-
uate the ‘data-averaged’ learning equation
dT
dt
= −T
2
E
{J}
U({J}: T
−1
)
−E
{J}
(U
GA
({J}))
(10)
to discuss the average-case performance, where
we defined the average E
{J}
(···) by E
{J}
(···) ≡
∏
ij
R
dJ
ij
(···)P(J
ij
). We should keep in mind that
in this paper we deal with the problem in which
each interaction J
ij
has no correlation with the oth-
ers, namely, E
{J}
(J
ij
J
kl
) = J
2
δ
i,k
δ
j,l
where we de-
fined J
2
as a variance of P(J
ij
) and δ
x,y
stands for a
Kronecker’s delta.
4 MATHEMATICALLY
TRACTABLE MODEL
In this section, we introduce a spin glass model which
will be used as a benchmark cost function to be mini-
mized by GA. The model is called as spin glass chain.
It is one-dimensional spin glass model having only
nearest neighboring interactionsD It is possible for us
to investigate the temperature dependence of internal
energy and moreover, one can obtain the lowest en-
ergy exactly. The energy function (Hamiltonian in the
literature of statistical physics) is given by
H = −
N
∑
i=1
J
i
s
i
s
i+1
, J
i
= N (0, 1) (11)
where J
i
stands for the interaction between spins s
i
and s
i+1
. N (a, b) denotes a normal Gaussian distri-
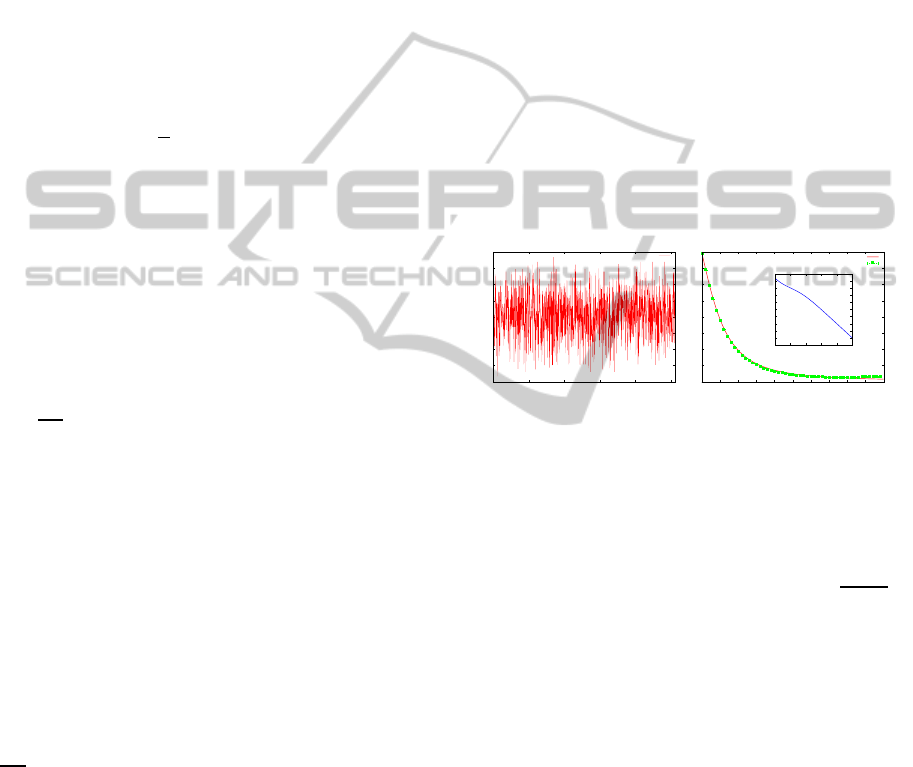
bution with mean a variance bD We plot the typical
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
0 200 400 600 800 1000
H/N
S
N = 10
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
U
β
Theory
N = 3000, MCS = 20000
-5.5
-5
-4.5
-4
-3.5
-3
-2.5
-2
-1.5
-1
-0.5
0 1 2 3 4 5
U
min
J
0
Figure 1: Typical energy landscape H(s
s
s) = −
∑
i
J
i
s
i
s
i+1
with P(J
i
) = N (0,1), E(J
i
J
j
) = δ
i, j
of the spin glass chain.
The number of spins is N = 10. It should be noted that
the horizontal axis S denotes the label of states, that is,
S = 1, 2,··· ,2
N
(= 1028). For instance, S = 1 stands for a
state, say, s
s
s(S = 1) = (+1,+1,··· , +1) and S = 2
N
denotes
s
s
s(S = 2
N
) = (−1, −1,··· ,−1). The right panel stands for
internal energy of spin glass chain as a function of temper-
ature. The solid line is exact result U = −β
R
∞
−∞
Dx
cosh
2
βx
,
whereas the dots denote the internal energy calculated by
the MCMC for N = 3000. The error-bars are calculated
by 10-independent runs for different choice of the {J} ≡
{J
i
|i = 1,··· ,N}. The inset indicates the U
min
as a function
of J
0
. We set J = 1.
energy landscape in Figure 1 (left). From this figure,
we find that the structure of the energy surface is com-
plicated and it seems to be difficult for us to find the
lowest energy state.
However, we should notice that in (11) s
i
takes ±1
and the product s
i
s
i+1
also has a value ±1. Hence, we
introduce the new variable τ
i
which is defined by τ
i
=
s
i
s
i+1
, then τ
i
takes τ
i
∈ {1, −1}. Therefore, in order
to minimize H(τ
τ
τ) = −
∑
i
J
i
τ
i
, we should determine
τ
i
= sgn(J
i
) for each i and then, we have the lowest
energy as U
min
= −
∑
i
J
i
sgn(J
i
) = −
∑
i
|J
i
|. Namely,
when J
i
obeys a Gaussian with mean J
0
and variance
J
2
, the lowest energy for a single spin is obtained in
A GIBBS DISTRIBUTION THAT LEARNS FROM GA DYNAMICS
297

the thermodynamic limit N → ∞ as
lim
N→∞
U
min
N
= E
{J}
(|J
i
|) =
Z
∞
−∞
dJ
i
√
2πJ
e
−
(J
i
−J
0
)
2
2J
2
|J
i
|
= −J
0
−J
r
2
π
e
−
J
2
0
2J
2
where E
{J}
(···) here stands for the average over the
configuration {J} ≡ (J
1
,··· ,J
N
).
Thus, for the choice of (J
0
,J) = (1, 0), namely, in
the limit of the ferromagnetic Ising model, we have
the lowest energy as U
min
/N = −1 (all spins align in
the same direction), On the other hand, for the choice
of (J
0
,J) = (0,1), we have U
min
= −
p
2/π. These
facts mean that the lowest energy changes according
to the value of ratio J
0
/J.
We next consider the case of finite effective tem-
perature, namely, β < ∞. For this case, internal en-
ergy per spin is explicitly given by lim
N→∞
hHi
τ
/N =
E
{J}
(hHi
τ
) = −(∂/∂β)log
∑
τ
τ
τ
e
β
∑
i
J
i
τ
i
with h···i
τ
≡
∑
τ
τ
τ
exp[β
∑
i
J
i
τ
i
]/Z
τ
where we defined
∑
τ
τ
τ
(···) ≡
∑
τ
i
=±1
···
∑
τ
N
=±1
(···) and the partition function
Z
τ
=
∑
τ
τ
τ
e
β
∑
i
J
i
τ
i
is now calculated as {2cosh(βJ
i
)}
N
.
Hence, we have the average free energy density de-
fined by f = lim
N→∞
(logZ/N) = N
−1
E
{J}
(logZ) is
evaluated as follows.
f =
Z
∞
−∞
Dxlog2coshβ(J
0
+ Jx) (12)
where we defined Dx ≡ dxe
−x
2
/2
/
√
2π. From the
above result, we immediately obtain the internal en-
ergy per spin U = −∂f/∂β by
U = −β
Z
∞
−∞
Dx
cosh
2
βx
. (13)
for the case of (J
0
,J) = (0, 1). In Figure 1 (right), we
show the U as a function of T. From the arguments
we provided above, we have the following learning
equation (14) for the spin glass chain whose Hamilto-
nian is given by (11) is now rewritten as
dT
dt
= T
2
lim
L→∞
1
L
L
∑
l=1
∑
i
J
i
s
i
(t,l)s
i+1
(t,l)
!
− T
Z
∞
−∞
Dx
cosh
2
T
−1
x
. (14)
5 RESULTS
The results are summed up below. We show the time-
evolution of effective temperature (14) and the resid-
ual energy for the case of spin glass chain with pa-
rameter sets: σ = 2 (The number of members in selec-
tion of tournament -type at each generation), p
c
= 0.1
(The rate for a single point crossover), p
m
= 0.001
(The mutation rate) in Figure 2. From this figure,
we find that the asymptotic behaviour of the effec-
tive temperature follows a power-law. This schedule
is faster than the effective temperature scheduling for
the optimal simulated annealing ∼ 1/log(1+t) (Ge-
man and Geman, 1984), however, slower than the ex-
ponential decreasing. Thus, here we define the resid-
ual energy and its time-dependence as the difference
between the lowest energy and current energy ob-
tained by the GA dynamics. We find that the residual
energy which is defined by
ε ≡ H(s
s
s) −min
s
s
s
H(s
s
s) (15)
also asymptotically goes to zero and it follows a
power-law in the scaling regime t ≫ 1.
0
5
10
15
20
25
30
35
0 200 400 600 800 1000 1200 1400
T
t
0
0.5
1
1.5
2
2.5
3
3.5
0 1 2 3 4 5 6 7
log(T)
log(t)
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 200 400 600 800 1000 1200 1400
ε
t
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0 1 2 3 4 5 6 7
log(ε)
log(t)
Figure 2: Time evolution of the effective temperature (up-
per panel) and the residual energy defined by (15) (lower
panel) for the case of spin glass chain. We used a simple
GA having σ = 2, p
c
= 0.1, p
m
= 0.001. We set the number
of spins N = 2000 and population M = 100, respectively.
The inset stands for the asymptotic behaviour.
6 CONCLUDING REMARKS
We introduced a learning algorithm of Gibbs dis-
tributions from training sets which are gene strings
generated by GA to figure out the statistical prop-
erties of GA from the view point of thermodynam-
ics. A procedure of average-case performance eval-
uation for genetic algorithms was numerically ex-
amined. The formulation was applied to a solvable
probabilistic model having multi-valley energy land-
scapes, namely, the spin glass chain. By using com-
puter simulations, we discussed the asymptotic be-
haviour of the effective temperature scheduling and
the residual energy induced by the GA dynamics.
REFERENCES
Baluja, S. (1994). Population-based incremental learning:
A method for integrating genetic search based func-
tion optimization and competitive learning. Technical
Report, School of Computer Science, Carnegie Mellon
University, CMU-CS-94:163.
ICEC 2010 - International Conference on Evolutionary Computation
298

Geman, S. and Geman, D. (1984). Stochastic relaxation,
gibbs distributions, and the bayesian restoration of im-
ages. IEEE Trans. on Pattern Analysis and Machine
Intelligence, PAMI-6:721–741.
H.Holland, J. (1975). Adaptation in natural and artificial
systems. The University of Michigan Press.
Kirkpatrick, S., D.Galatt, C., and P.Vecchi, M. (1983). Op-
timization by simulated annealing. Science, 220:671–
680.
Li, T. (1981). Structure of metastable states in a random
ising chain. Physical Review B, 24:6579–6587.
A GIBBS DISTRIBUTION THAT LEARNS FROM GA DYNAMICS
299
