
CLUSTERING OF THREAD POSTS IN ONLINE DISCUSSION
FORUMS
Dina Said
Department of Computer Science, University of Calgary, Calgary, AB, Canada
Nayer Wanas
Cairo Microsoft Innovation Lab, Cairo, Egypt
Keywords:
Distance metrics, Clustering, Online forums mining, Post clustering.
Abstract:
Online discussion forums are considered a challenging repository for data mining tasks. Forums usually
contain hundreds of threads which which in turn maybe composed of hundreds, or even thousands, of posts.
Clustering these posts potentially will provide better visualization and exploration of online threads. Moreover,
clustering can be used for discovering outlier and off-topic posts. In this paper, we propose the Leader-
based Post Clustering (LPC), a modification to the Leader algorithm to be applied to the domain of clustering
posts in threads of discussion boards. We also suggest using asymmetric pair-wise distances to measure the
dissimilarity between posts. We further investigate the effect of indirect distance between posts, and how
to calibrate it with the direct distance. In order to evaluate the proposed methods, we conduct experiments
using artificial and real threads extracted from Slashdot and Ciao discussion forums. Experimental results
demonstrate the effectiveness of the LPC algorithm when using the linear combination of direct and indirect
distances, as well as using an averaging approach to evaluate a representative indirect distance.
1 INTRODUCTION
Online discussion boards, also known as newsgroups
or online forums, are amongst the most popular forms
of user generated content. Through these discus-
sion boards, users share opinions, experiences, post
questions and search for answers. Online discussion
boards differ from other web-based information re-
sources in that they are organized in tree structures
known as threads. The thread head (lead post) ini-
tiates the discussion. Subsequent posts present ad-
ditional content that extends the discussion. This,
in turn, implies that knowledge within threads is re-
tained in a sequence of posts within them, rather than
a specific post. Overall, forums remain to be a rich
repository of user generated content that contain vast
resources of knowledge.
However, there are several issues that render dis-
cussion boards difficult to use, more than other forms
of user generated content. Amongst the major prob-
lems is the limited ability to filter and search the con-
tent to meet a specific need. Irrelevant posts that infil-
trate the sequence could obscure the ability to isolate
nuggets of knowledge. Moreover, users might devi-
ate from the initial topic of the thread to discuss other
issues and several trains of thought might flow con-
currently. These issues might obscure the usability of
discussion forums.
In order to overcome these issues, posts need to
be organized differently based on their relevance to
each other. Clustering posts within a given thread
based on their content could assist this organization.
While document clustering has been a well addressed
problem in the literature, online discussion boards are
significantly different in their nature. Posts in fo-
rums are short and fragmented allowing limited de-
tection of context. To the best of our knowledge,
this is the first work to attempt to cluster online dis-
cussion posts within a thread. However, several re-
searchers have addressed the issue of clustering short
text. Clustering of web snippets for search organiza-
tion has been suggested in (Carullo et al., 2009) and
primarily focused on hierarchal clustering. These ap-
proaches aim to identify clusters based on low level
element matching between the different snippets and
assign appropriate tags and structure to each cluster.
314
Said D. and Wanas N..
CLUSTERING OF THREAD POSTS IN ONLINE DISCUSSION FORUMS.
DOI: 10.5220/0003104303140319
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (KDIR-2010), pages 314-319
ISBN: 978-989-8425-28-7
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

However, they don’t consider the interdependence be-
tween these elements which is more profound in on-
line threads. Several researchers have clustered email
messages, yet most have focused on spam-detection
rather than topical clustering of emails (Li and Hsieh,
2006; Xiang, 2009). Huang and Mitchell (Huang and
Mitchell, 2009) suggested a hierarchal email cluster-
ing algorithm that is adaptable based on user feed-
back. However, these approaches focus on clustering
emails threads at a coarse level. This is in contrast to
the need to cluster posts within individual threads in
online discussion forums.
In this work, we present an iterative distance based
approach to cluster posts within online discussion fo-
rums. This approach is rooted in the fact that the order
is important in online discussion forums and that the
relationships between posts can be both direct and in-
direct.
2 CLUSTERING POSTS IN
DISCUSSION BOARDS
Discussion forums have several characteristics that
should be considered when clustering posts within
their threads. Among these characteristics are the fol-
lowing:
1. Online discussion boards usually include differ-
ent topics which in turn have sub-topics. Each
sub-topic usually involves many threads. Some
of these threads may be very large and/or very di-
verse. This makes different threads in a single dis-
cussion board potentially demonstrating different
characteristics. Hence, the clustering algorithm
should not require any predefined parameters to
make it as general as possible.
2. Posts are ordered in the thread, mostly according
to the post date. Therefore, one might model this
as a sequential clustering to capture the time de-
pendency among posts. Therefore, a post that is
not related to clusters formed for previous posts
should be assigned to a new cluster.
3. The head post in a thread is of a special impor-
tance. Eventually, posts are determined to be off-
topics, or outliers, based on how relevant they are
to the head post in the thread (Wanas et al., 2009).
Therefore, the head post should be considered a
core node in the clustering algorithm.
4. The number of discussions addressed in a sin-
gle thread is hard to estimate. Additionally, on-
line threads may have a large number of off-topic
and outlier posts that do not relate to any dis-
cussion in thread. Therefore, the clustering algo-
rithm should allow the number of clusters to grow
accordingly, and each outlier post should be as-
signed to a single-post cluster.
5. Posts may be subsets of each other by using
the tagging facility available in most discussion
boards. Therefore, pair-wise distance between
any two posts should reflect this tagging, or ref-
erencing. Consequently, the probability of assign-
ing the new post to the same cluster of the post it
tags should increase.
6. Discussion boards usually involve a hierarchy of
discussions, where a post P
i
may refer to or com-
ment on another post P
l
. In turn, another post P
j
may refer to or comment on P
l
. Therefore, there
is indirect relation between posts P
i
and P
j
that
should be captured in the assessment of pair-wise
distance. This also dictates that the pair-wise dis-
tance between posts should be asymmetric.
With these characteristics in mind, we suggest
the Leader-based Posts Clustering (LPC) Algorithm.
This algorithm is a modification of the leader algo-
rithm (Babu and Murty, 2001), which starts with se-
lecting a pattern randomly to be the first leader. Con-
sequently, distance of every other pattern is compared
with that of the current selected leaders. If the min-
imum distance between the new pattern and the cur-
rent leaders is less than a predefined threshold, the
corresponding pattern is assigned to the cluster of the
closest leader. Otherwise, the pattern is identified as a
new leader.
The leader algorithm maintains the dependencies
amongst posts in online threads. First, it captures
the time dependency among posts. Second, it allows
novel posts to form new clusters. Moreover, it does
not require any prior knowledge about the number of
clusters in the thread. Several modifications are sug-
gested to the leader algorithm to adapt to clustering
posts on online threads. First, the initial leader is pre-
defined to be the head post, instead of selecting it ran-
domly. In addition, the distance between a post P
i
and a cluster C
m
is considered to be the average dis-
tance between P
i
and all posts P
j
∈ C
m
. Eventually,
this leads to a better assessment of distances between
posts and the candidate cluster. Additionally, after as-
signing all posts to clusters, we iteratively repeat the
whole process until no change in the assignment of
posts to clusters occurs, or the number of iterations
exceeds a maximum preset threshold.
While the Leader algorithm does not require the
predetermination of the number of clusters, it how-
ever requires a threshold of distances which is a very
critical parameter. A large threshold would produce a
CLUSTERING OF THREAD POSTS IN ONLINE DISCUSSION FORUMS
315

smaller number of clusters with low cohesion. Conse-
quently, a small threshold would produce more clus-
ters with higher cohesion and less separation. In order
to adjust to the diversity that exists between different
threads, the LPC algorithm uses the median of pair-
wise distances between posts in the same thread as a
robust threshold of distances.
3 DISTANCE METRICS
As previously mentioned, the nature of discussion
posts suggests the potential of using asymmetric pair-
wise distance between posts, while taking into consid-
eration the indirect distance between them. We define
asymmetric direct distance D
d
between posts P
i
and
P
j
as follows:
D
d
(P
i
, P
j
) = 1 −
∑
|b
i
∩b
j
|
k=1
min(w
k
i
, w
k
j
)
∑
|b
i
|
k=1
w
k
i
, (1)
where b
i
and b
j
are the bags of non-stop stemmed
words of posts p
i
and p
j
respectively, and w
k
i
is the
term frequency of word k in post P
i
. Hence, D
d
(i, j) =
0 if b
i
⊆ b
j
. Consequently, D
d
(i, j) = 1 if b
i
∩ b
j
= φ
which means that there is no direct distance between
these posts. Besides its appropriateness to the domain
of post clustering, asymmetric distance has been used
in (Song and Li, 2005; Song and Li, 2006) to clus-
ter text documents. Asymmetric distance has shown a
potential to enhance the clustering performance com-
pared to the symmetric distance, based on the cosine
similarity.
In order to find the indirect pair-wise distance be-
tween posts P
i
and P
j
, the indirect links between them
should be first determined. In this research, we con-
sider only indirect links that span one level. There-
fore, an indirect link exists between posts P
i
and P
j
through post P
l
if there is direct links between {P
i
, P
l
}
and {P
l
, P
j
}. In turn, the indirect distance (D
i
) be-
tween P
i
and P
j
through post P
l
is defined as follows:
D
i
(P
i
, P
l
, P
j
) =
D
d
(P
i
,P
l
)+D
d
(P
l
,P
j
)
2
if D
d
(P
i
, P
l
) < 1
and D
d
(P
l
, P
j
) < 1
1 otherwise,
(2)
The aggregated indirect distance (D
a
(P
i
, P
j
)) be-
tween posts P
i
, P
j
can be evaluated using one of the
following functions:
• Minimum Distance (Min) which represents the
shortest indirect distance between P
i
, P
j
.
• Average Distance of Indirect Links (Avg) which
tries to suppress the bias to the shortest indirect
path
• Median Distance of Indirect Links (Med)
which eliminates the effects of very small and
very large indirect distances.
• Average Distance of the Smallest Five Indirect
Links (AvgF) which is based on the assumption
that the smallest five indirect links are the most
representative links to the indirect distance be-
tween the posts. It should be noted that if the num-
ber of indirect links is less than five, the AvgF is
calculated based on only actual indirect links.
In order to cluster posts, direct and indirect dis-
tance between posts should be combined together
to form the combined distance (D
c
). D
c
(P
i
, P
j
)
between posts P
i
and P
j
based on the direct dis-
tance (D
d
(P
i
, P
j
)) and the aggregated indirect distance
(D
a
(P
i
, P
j
)) can be defined as follows:
• The Constant Function where combined dis-
tance between two posts equals the direct dis-
tance between them without considering the in-
direct distance.
D
c
(P
i
, P
j
) = D
d
(P
i
, P
j
)
• The Power Function which bounds the effect of
the indirect distance on the direct distance.
D
c
(P
i
, P
j
) = D
d
(P
i
, P
j
)
D
a
(P
i
,P
j
)
• The Linear Function which provides equal effect
of the direct distance and indirect distance on the
combined distance.
D
c
(P
i
, P
j
) = D
d
(P
i
, P
j
) × D
a
(P
i
, P
j
)
• The Tanh Function which increases the contribu-
tion of the indirect distance in the combined dis-
tance.
D
c
(P
i
, P
j
) = D
d
(P
i
, P
j
) × tanh(D
a
(P
i
, P
j
))
In total, four different functions of aggregating
indirect distances are suggested, along with four to
combine indirect and direct distances. In the fol-
lowing, we present an experimental study to evaluate
these different approaches.
4 EXPERIMENTS
In this section, the various experiments performed in
order to evaluate our methods are introduced.
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
316

4.1 Datasets
In this work, we experimented using two corpora pro-
vided through CAW 2.0
1
. The first corpus is crawled
from the Slashdot discussion board
2
while the second
corpus is collected from the Ciao discussion board
3
for movies reviews.
It is worth noting that the Slashdot corpus is
significantly larger than the Ciao corpus in terms
of both the number of threads and the number of
posts. Threads in Slashdot average over 500 posts
per thread, which is substantially larger than those
of the Ciao, whose average is just over 40. Another
distinction between the two corpora is in the number
of words per post. Ciao is mainly a forum regarding
movie reviews, and hence posts are generally lengthy,
which renders clustering easier compared to Slashdot.
Moreover, the potential of off-topic, outliers and devi-
ated discussion posts is smaller in Ciao posts compar-
ing with Slashdot. This is due to the nature of threads
in Ciao, which are more independent posts about spe-
cific movies. This is in contrast to threads in Slashdot
which cover a wide spectrum of topics and sub-topics,
which in turn means that clustering is a more chal-
lenging task. It should be noted that each thread is
considered as a dataset since we are performing clus-
tering for posts within each thread separately.
Due to the absence of labeled data, we evaluate the
performance on both corpora based on the clustering
quality. Additionally, and to overcome the lack of la-
beled data, we have constructed two artificial corpora
(a) Slashdot-Art and (b) Ciao-Art which are formed
from the Slashdot and Ciao respectively. A number
of artificial threads are created by concatenating sev-
eral posts from different threads in the original cor-
pus. The posts are labeled to belong to the same clus-
ter if they are selected from the same original thread,
which provides a pseudo-label for all posts. Each ar-
tificial corpus consists of 15 threads. The number
of true clusters is maintained to be {2, 5, 10, 15, 20}
while the number of posts per cluster varies between
{1, 5, 10}. To ensure the quality of the constructed
corpus, we exclude posts that are either tagged as off-
topics and those labeled automatically according to
(Wanas et al., 2009) to be outliers. Additionally, the
diversity among clusters is maintained in the Slash-
dot corpus by selecting posts in threads from different
topics.
1
http://caw2.barcelonamedia.org/
2
http://slashdot.org/
3
http://www.ciao.com/
4.2 Performance Measure
Clustering performance of the artificial threads, where
true clusters are known, is measured in terms of F
1
(Tan et al., 2005). F
1
for a cluster C is defined as:
F
1
[C] =
2 ∗ Recall[C] ∗ Precision[C]
Recall[C] + Precision[C]
. (3)
For real threads, we have adopted the silhouette
factor measure (Tan et al., 2005) which combines
the classical separation and cohesion measures in one
measure. The silhouette factor (SF) for post P as-
signed to cluster C is defined as:
SF[P] = 1 −
a[P]
b[P]
, (4)
where a[P] is the average distance between Post P and
all posts in C while b[P] is the minimum average dis-
tance between Post P and all clusters in the thread
excluding C. The clustering performance for SF[P] is
considered pretty good when a[P] << b[P] and hence
SF[P] ≈ 1. It should be noted that the silhouette fac-
tor of Cluster C (SF[C]) is the average SF of all posts
assigned to this cluster.
The overall F
1
and SF measures for the whole
thread is calculated based on the weighted average
of the F1 and SF measures of all the clusters in the
thread. Since it would be hard to provide results for
each thread, we further calculate these measures for
the whole corpus based on weighted averaging over
all threads in the corpus. In turn, this implies that
the threads with a large number of posts have more
contribution in the performance evaluation compared
with those with a small number of posts.
4.3 Results
Figure 1 compares the clustering performance based
on the F
1
measure of different combining and aggre-
gate functions using Slashdot and Ciao artificial cor-
pora. In this set of experiments, the k-means algo-
rithm is used to benchmark the performance of the
LPC algorithm suggested. It is worth noting that a
cap on the number of iterations has been set to 100
for both algorithms. Moreover, we set k to be the true
number of clusters. Clearly, this is the best setting for
k-means since its performance is expected to decline
if k is over-estimated or under-estimated.
The results demonstrate the superiority of the LPC
algorithm compared with the k-means for most dis-
tance functions. This is with the exception of us-
ing the power and constant distance functions for the
Slashdot-Art corpus where k-means marginally out-
performs LPC, while clearly underperforms in the
CLUSTERING OF THREAD POSTS IN ONLINE DISCUSSION FORUMS
317
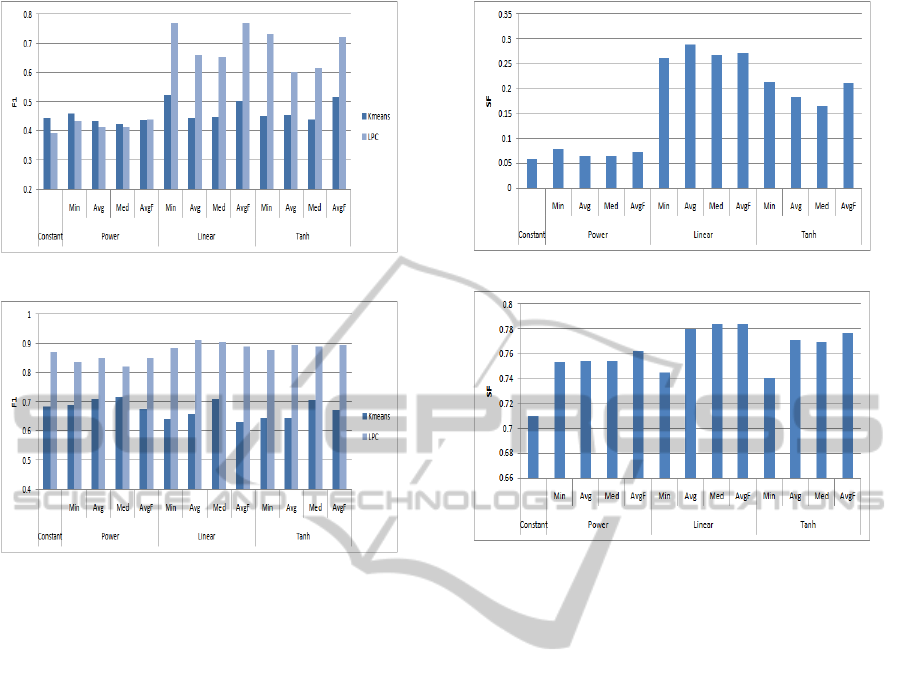
(a) Slashdot-Art Corpus
(b) Ciao-Art Corpus
Figure 1: Weighted average F1 for the k-Means algorithm
and the LPC algorithm using different combining and ag-
gregate functions a) Slashdot-Art Corpus and b) Ciao-Art
Corpus.
Linear and Tanh. It is worth noting that unlike
the k-means, the LPC algorithm doesn’t require any
prior knowledge about the number of clusters in each
thread.
Moreover, while the range of performance of the
LPC algorithm is limited on the Ciao-Art dataset,
the Linear and Tanh combining-aggregation functions
demonstrate a better performance on Slashdot-Art
compared to the corresponding Constant and Power
functions. This is not as significant when using the k-
means algorithm. As mentioned in section 4.1, the
clustering task for the Slashdot-Art corpus is more
challenging than that of the Ciao-Art corpus. This is
reflected in the limited diversity in the performance of
both LPC and k-means in the Ciao-Art corpus using
different combining-aggregate functions compared to
Slashdot-Art. For the LPC algorithm, the best F
1
achieved by the LPC was 0.911 while the worst F
1
was 0.821. For the k-means algorithm, the best F
1
at-
tained was 0.711 and the worst F
1
was 0.643. Since,
the performance of the k-means is not significantly
affected by the combining-aggregate function used,
it was excluded from the performance evaluation of
Slash and Ciao corpora.
(a) Slashdot Corpus
(b) Ciao Corpus
Figure 2: Weighted average Silhouette Factor (SF) for the
LPC algorithm using different combining and aggregate
functions for a) Slashdot Corpus, and b) Ciao Corpus.
Figure 2 shows the performance of the LPC al-
gorithm using the Slashdot and Ciao corpora. Since
the true clusters for these corpora is not known, the
weighted average Silhouette Factor (SF) has been
used to evaluate the performance (section 4.2).
The results demonstrate the superiority of the Lin-
ear and Tanh combining functions where indirect dis-
tance contributes intensively in the combined dis-
tance. This is more profound for the Slashdot corpora.
In this case, the SF of the Linear and Tanh functions is
at least three times better than that of the Constant and
Power functions. Overall, the Linear function demon-
strates a slightly better performance compared with
the Tanh function. This is due to the fact that Linear
function gives equal weights to the direct and indirect
distances, while the Tanh function is more biased to
the indirect distance. This may lead to a concealing of
the effect of the direct distance which represents the
direct dissimilarity between posts. Generally, incor-
porating the indirect distance using any of the three
combining function (Power, Linear, Tanh) improves
the performance on the Ciao-Art and Ciao corpora by
at least 4%.
The diversity of performance of the LPC accord-
ing to using different aggregate function is limited us-
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
318

ing the same combining function. For example, the
performance of the Avg and Med is about 1% less
that of the Min and AvgF for the Slashdot-Art corpus
while the performance of the Min is about 0.4% less
that of the AvgF for the Ciao corpus. In general, we
recommend the using of the AvgF function since it
is not biased towards the minimum indirect distance
like the Min. Additionally, it considers only the five
indirect links which makes it a more reflecting to the
indirect distance compared with the Avg and Med.
5 CONCLUSIONS
Online discussion boards represent a rich repository
for data mining tasks in user generated texts. This re-
search addresses the problem of clustering posts in
different threads. The purpose of this clustering is
mainly to provide improved usability of threads in on-
line discussion boards. This may also facilitate the
discovery of off-topic and outlier posts in discussion
threads. The Leader-based Posts Clustering (LPC)
approach suggested captures the time dependency be-
tween posts. Starting from the head post, subsequent
posts are assigned to either the most related clus-
ter or to new clusters, based on an automatically-
determined threshold of distances. An asymmetric
distance is suggested for measuring the pair-wise dis-
tance between posts. This distance allows for model-
ing the inter-post tagging and commenting. Addition-
ally, we suggest incorporating the indirect distance
between posts. Four functions, the Minimum, Aver-
aging, and Median aggregating functions, have been
suggested for aggregating different indirect links. In
addition, four methods for combining indirect and di-
rect distances have been proposed; namely the Con-
stant, Power, Linear, and Tanh functions.
Our experiments have been conducted using four
corpora, two of them are artificially generated, where
true clusters are known and the others are real online
threads. These were geenrated from threads crawled
from Slashdot and Ciao discussion boards. The re-
sults show the potential of the LPC, while using Lin-
ear combining function and averaging aggregate func-
tion (Avg, AvgF). This is in comparison with the
performance of the k-means algorithm on the artifi-
cial corpora while setting k to be the true number
of clusters. Moreover, the LPC algorithm, unlike
the k-means, eliminates the requirement to estimate
the number of actual clusters or predefined thresh-
olds. For real corpora, the Linear combining func-
tion along with the averaging aggregate function has
demonstrated the best performance among all the ex-
amined methods.
ACKNOWLEDGEMENTS
The authors would like to thank the Fundacion
Barcelona Media (FBM) for crawling the corpora
used in this research and making them available for
research use. This research has been conducted dur-
ing an internship granted to the first author at the
Cairo Microsoft Innovation Lab.
REFERENCES
Babu, T. and Murty, M. (2001). Comparison of genetic al-
gorithm based prototype selection schemes. Pattern
Recognition, 34(2):523–525.
Carullo, M., Binaghi, E., and Gallo, I. (2009). An online
document clustering technique for short web contents.
Pattern Recognition Letter, 30(10):870–876.
Huang, Y. and Mitchell, T. (2009). Toward mixed-initiative
email clustering. In AAAI Spring Symposia 2009:
Agents that learn from human teachers, pages 71–78,
Stanford University, CA, USA.
Li, F. and Hsieh, M.-H. (2006). An empirical study of clus-
tering behavior of spammers and group-based anti-
spam strategies. In CEAS 2006: 3rd Conference on
E-mail and Anti-Spam, Mountain Veiw, CA, USA.
Song, S. and Li, C. (2005). Tcuap: a novel approach of text
clustering using asymmetric proximity. In Proc. 2nd
Indian International Conf. on Artificial Intelligence,
pages 447–453, Pune, India.
Song, S. and Li, C. (2006). Improved rock for text cluster-
ing using asymmetric proximity. In SOFSEM 2006:
Theory and Practice of Computer Science, 32nd Con-
ference on Current Trends in Theory and Practice of
Computer Science, volume 3831 of Lecture Notes in
Computer Science, pages 501–510, Mer
´
ın, Czech Re-
public.
Tan, P., Steinbach, M., and Kumar, V. (2005). Introduction
to data mining. Addison-Wesley Longman Publishing
Co., Inc. Boston, MA, USA.
Wanas, N., Magdy, A., and Ashour, H. (2009). Using au-
tomatic keyword extraction to detect off-topic posts in
online discussion boards. In content Analysis in Web
2.0 Workshop (CAW2.0), In conjunction with 18th In-
ternational World Wide Web Conference (WWW2009),
Madrid, Spain.
Xiang, Y. (2009). Managing email overload with an au-
tomatic nonparametric clustering system. Journal of
Supercomputing, 48(3):227–242.
CLUSTERING OF THREAD POSTS IN ONLINE DISCUSSION FORUMS
319
