
Contextualising Information Quality:
A Method-Based Approach
Markus Helfert
1
and Owen Foley
2
1
School of Computing, Dublin City University, Glasnevin, Dublin 9, Ireland
2
School of Business, Galway Mayo Institute of Technology, Dublin Road, Galway, Ireland
markus.helfert@computing.dcu.ie, owen.foley@gmit.ie
Abstract. Information Quality is an ever increasing problem. Despite the
advancements in technology and information quality investment the problem
continues to grow. The context of the deployment of an information system in a
complex environment and its associated information quality problems has yet to
be fully examined by researchers. Our research endeavours to address this
shortfall by specifying a method for context related information quality. A
method engineering approach is employed to specify such a method for context
related information quality dimension selection. Furthermore, the research
presented in this paper examined different information systems’ context factors
and their effect upon information quality dimensions both objectively and
subjectively. Our contribution is a novel information quality method that is
context related; that is it takes the user, task and environment into account.
Results of an experiment indicate as well as feedback from practitioners
confirm the application of our method and indeed that context affects the
perception of information quality.
Keywords. Information quality, Method, Context, Method engineering.
1 Introduction
With the increasing importance of Data and Information Quality (DIQ), much
research in recent years has been focused on developing DIQ frameworks and
dimensions as well as assessment approaches. Researchers have developed a plethora
of frameworks, criteria lists and approaches for assessing and measuring DIQ. Despite
the vast amount of DIQ research, discussions with experts and practitioners as well as
recent studies indicate that assessing and managing DIQ in organizations is still
challenging and current frameworks offer only limited benefit.
Several researchers have addressed the question on how to define DIQ and many
have confirmed that DIQ is a multi-dimensional concept [1, 2]. Following prominent
definitions of “quality” as “fitness for use”, most researchers acknowledge the
subjective nature of data and information quality. Aiming to assess DIQ, many
objective and subjective assessment techniques have been proposed. Mostly, these are
developed for one specific context or domain, with limited general applicability.
Furthermore, despite the inherent subjective character of quality, foremost
frameworks and assessment methodologies are limited to consider the subjective
character in which the assessment is performed.
Helfert M. and Foley O.
Contextualising Information Quality: A Method-Based Approach.
DOI: 10.5220/0004466101490163
In Proceedings of the 4th International Workshop on Enterprise Systems and Technology (I-WEST 2010), pages 149-163
ISBN: 978-989-8425-44-7
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Objective DIQ assessment uses software to automatically measure the data in
database by a set of quality rules whereas subjective DIQ assessment uses a survey or
interview approach to measure the contextual information by data consumers. A
single assessment result can be obtained from objective DIQ assessment. However,
we may obtain different assessment results from different information consumers.
With the development of both objective and subjective DIQ assessment, researchers
suggested to combine these two assessment methodologies. For example, Pipino et al.
[3] provide a framework to combine objective and subjective DIQ assessments. Kahn
et al [4] propose the PSP/IQ model, in which they assign two views of quality:
conforming to specifications (objective) and meeting or exceeding consumer
expectations (subjective).
Recognising the problem of limited context in DIQ frameworks, the aim of this
paper is to present an approach, which assist in adapting DIQ frameworks to various
contexts. In our work we follow the recent observation by researchers, to adapt
research results to specific application by providing an approach of contextualising
models [5]. In contrast to contribute yet another DIQ framework, in this article, we
describe a method to contextualise DIQ frameworks. In this sense, “context” relates
the content of the DIQ framework to the IS environments [6]. Context itself is
described by various contextual factors characterizing the IS environment. Following
design science research, the method is being developed and refined using a method
engineering (ME) approach. The proposed method was developed based on
experiences from the airline industry. A number of experiments are conducted to test
the proposed method. In addition, IS professionals are interviewed to further verify
the method and to study the impact of IS context on DIQ.
The paper is organised as follows. The research is introduced in general terms
followed by an outline of the problem statement and objective. A review of related IQ
work as a field within IS follows. Subsequently, details of the contextualisation
method together with an initial application are presented. Contribution, limitations
and future work conclude the paper.
2 Problem Statement and Research Objective
As a direct result of user dissatisfaction with the quality of the information produced
by IS [7], practitioners and researchers have been concerned for several years about
the quality of information and data. The problem becomes increasingly important
with the rapid growth in the amount of data that enterprises store and access [8-10].
The information –often of poor IQ- is being used ever increasingly for critical
decision making at all levels within the organisation, resulting in significant IQ
related problems.
Some examples of these problems are summarized for instance in Al Hakim [11]
who provides examples from many areas, outlining the reason along with the
particular IQ dimension affected. The examples indicate how the generation of
information from disparate sources can impact on many aspects of an enterprise, often
not even considered when the IS was initially designed. The impact of these IQ
problems has prompted researchers to examine such aspects as IQ dimensions, IQ
assessment and IQ management. The impact of the various dimensions of IQ requires
151

measurement and examination. Furthermore, there has been a huge financial impact
associated with the lack of IQ. For instance, it is estimated that poor quality
information costs American business some $611 billon a year [12]. Addressing this
problem, several enterprises have invested considerably in efforts to “clean up” their
information, to improve IQ and to define rules and routines to assess and manage IQ.
Research has addressed this challenge from various directions. Management
process and guidelines have been proposed in order to manage IQ. The database
community has contributed several approaches for data cleansing and assessing data
quality in databases. In addition, software engineering has focused on improving the
quality of software. As a result, research related to IQ has evolved significantly over
the last two decades. Numerous frameworks, dimensions and metrics have been put
forward [1, 2]. Approaches have been developed to measure the impact of these
dimensions on IQ and to improve IQ. However, the benefits of these approaches such
as better quality software, easier to use systems, readily acceptable software and
increased IQ all have the potential to be foregone by changing contexts or situations.
The evolving nature of IS context presents new and very distinct challenges to IQ
research. Primarily among these is the dynamic nature of IS context. IS designers no
longer have the luxury of complete control over the nature of the IS context post
deployment of the IS. Usually software systems are developed with tried and tested
methodologies for a particular context with certain requirements. IQ measurements
and management approaches can be defined and deployed for this particular context.
Once implemented, contexts evolve and requirements may change. However with
such fundamental changes in context, a question about its impact on IS become
significant [13, 14].
IQ measurements and management approaches are usually not evolving along the
various contexts, and indeed changes in context do usually not undergo a systematic
consideration. Systems and IQ measurement approaches are developed for a particular
context. Nonetheless the importance of a high level of IQ remains a requirement. As a
result often the perception of IQ via subjective survey instruments is progressively
getting poorer [15]. Indeed, this observation may explain a frequent criticism, that
despite large investments in IQ and software systems, end users are still not satisfied
with IQ and the usability of systems. Variation in the context, require adaptation of
the IQ measurement approach to cater at least for different requirements and changes
in perception. Presently the approach to a changing context and IQ is ad-hoc and not
systematic.
The problem can be illustrated by an example from the airline sector, which has
been examined by us. The organisation has an airline maintenance and information
system in use for many years. Different types of users using the IS on a regular basis
for the performance of their duties. Also, for several years the organisation has IQ
routines and assessment approaches in place. Pilots, engineers, administrators and
technicians are required to rate the IQ of the system on a regular basis for quality
control and legal obligations. Surprisingly, over the last two years, the MIS
(Management Information Systems) department has experienced a dramatic increase
for requests to verify IQ of the IS. This has become a very resource intensive exercise
with many of the requests requiring no alteration to data values. On closer
examination, we observed that in tandem with the increase in IQ requests the IS
context has changed. For instance, the access modes to the system have changed over
the years. The single point of access via data entry personnel has evolved over time to
152
the point where many users interface with the IS from mobile devices over wireless
networks. As a consequence, the procedures and IQ assessment approaches in place
did not reflect the current situation with various access modes and changing contexts.
The organisation did not have any systematic approach to cater for these changes.
The brief example from the airline industry illustrates the requirement for a
systematic approach to adapt IQ frameworks for various contexts. Our approach
presented in this article, assists to contextualise IQ frameworks and thus cater for
various and changing contexts. The necessity for this research arises from the ever
increasing dynamics that exists with respect to IS deployment. As our observation
from the case study shows, perceptions of IQ may alter as the result of evolving
contexts. Research related to IQ has not or only in a limited manner addressed and
recognised this problem. In contrast to define yet another IQ framework, we believe
that the application of existing IQ frameworks requires a clear, concise and systematic
approach to cater for dynamic and evolving contexts. The traditional static
deployment of IQ frameworks do not consider adequately the changing factors of IS
context. The challenge of this research is to specify a systematic approach in the form
of a method that considers the IS context, allowing for the evaluation of IQ in various
contexts.
3 Related Work
Our work builds on and contributes to the research related to IQ, which has developed
a large number of frameworks, assessment approaches and criteria list. An overview
of research related to IQ is provided for instance in Ge and Helfert [16]. Ge and
Helfert have examined the definition of IQ and suggest that it can be defined from a
consumer perspective and a data perspective. The concept of fitness for use [2] is
widely regarded in the literature as a definition for IQ from the consumers view point.
Table 1. Selected Information quality frameworks and its application context.
Author and year of
Publication
Application context Author and year of
Publication
Application context
Morris et al. 1996 [17] Management Huang et al. 1999 [18] Knowledge Management
Redmann 1996 [7] Data Bases
Chengalur-Smith et al.
1999 [19]
Decision-Making
Miller 1996 [20] Information Systems Berndt et al. 2001 [21] Healthcare
Wang/Strong 1996 [2] Data Bases Xu et al. 2002 [22]
Enterprise Resource
Planning
Davenport 1997 [23]
Information
Management
Helfert/Heinrich 2003 [24]
Customer Relationship
Management
Ballou et al.1998 [25] Data Warehousing Amicis/ Batini 2004 [26] Finance
Kahn/Strong 1998 [27] Information Systems Xu/Koronios 2004 [28] E-business
Rittberger 1999 [29]
Information Service
Providers
Knight/Burn 2005 [15] World Wide Web
English 1999 [30] Data Warehousing Li/Lin 2006 [31]
Supply Chain
Management
Ballou/Tayi 1999 [32] Data Warehousing
153

The definition of IQ from a data perspective examines if the information meets the
specifications or requirements as laid down in IS design. IQ from a consumer
perspective led to the development of subjective IQ measures, whereas IQ from a
database perspective resulted in objective IQ measures.
Many IQ frameworks have been developed in order to classify dimensions that
will allow for IQ assessment. As shown in table 1, we reviewed prominent
frameworks and analyzed these according to the application context for which they
were proposed. Although claims are sometimes made to provide a generic criteria
lists, on closer examination most research has been focused on investigating IQ within
a specific context. The frameworks differ in selected IQ criteria as well as assessment
techniques.
The complexity of the information system architecture is just one of several
contextual factors to characterise IS environments. In literature there is strong support
that types of users and types of IS result in different requirements and therefore
perceptions of DIQ [33-35]. Empirical research concluded that user evaluation of IS is
directly influenced by system, task and individual characteristics. Besides, several
examples in DIQ literature illustrate that the departmental (organisational) role plays
an important factor in user’s opinion and perspectives [11, 33, 36]. Although
recognising that there are several contextual factors, in our research we limit the set of
contextual factors to 4:
(1) User role
(2) Organisational department,
(3) IS Architecture
(4) Task complexity.
The initial deployment of an IS generally caters adequately for these context factors.
However over time these evolve and require a fresh analysis in order to accurately
represent the true nature of the context of the IS. This can only be done if
examinations of the factors within a context are continually updated and revised.
These factors can be further classified with appropriate components. The updating of
the factors and reclassification of components should be carried out in an iterative and
systematic fashion similar to TDQM [37].
Table 2. Common IS Context Factors.
Factor Component
User Role Manager / Specialist
Organisational Department IT Department / Non IT Department
IS Architecture Workstation, Service Oriented, Mobile
Task Complexity Operational, Strategic
The significant change and increase in complexity of IS context has in many cases
occurred independently of the underlying databases that are accessed [13]. An
application may have been designed, built and tested with a mature software
development method for a particular context. Yet within a very short period of time it
may be accessed and predominantly employed from a different context [11]. Data
models have also evolved [9]. However a considerable number of IS in use today
have data models designed prior to the contexts that are employed to access them.
There are as a result multiple accesses from diverse and complex contexts.
154
4 A Method for Contextualising IQ Frameworks
In order to develop an approach to contextualise IQ frameworks, we follow design
science and apply a method engineering (ME) approach. ME as a discipline has been
recognised over the last decade. It is concerned with the process of designing,
constructing and adapting generic artefacts such as models, methods, techniques and
tools aimed at the development of IS [38]. Punter [39] describes the discipline from a
process perspective where methods are comprised of phases, phases are comprised of
design steps, and design steps are comprised of design sub-steps. He states that to
every design step or sub-step, certain product-oriented method constituents (e.g.
techniques, procedures) can be assigned.
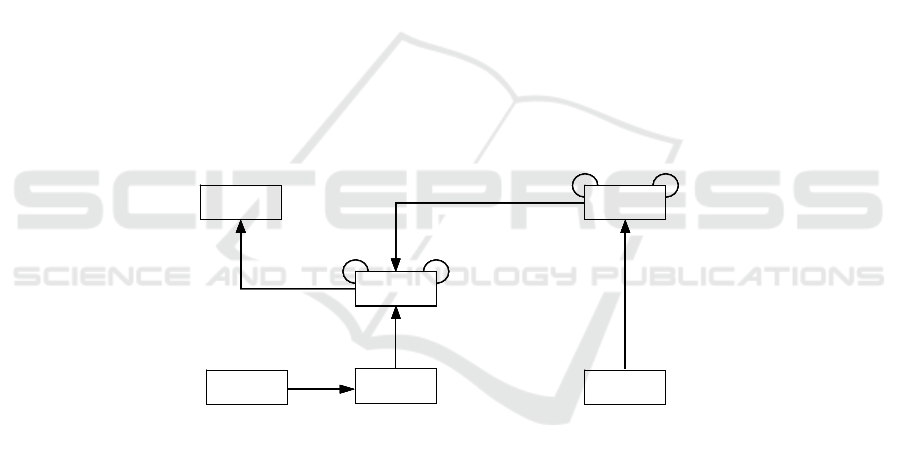
In order to describe methods, Gutzwiller [40] proposes a meta-model for methods
that includes activities, roles, specifications, documents and techniques. Figure 1
below illustrates the relationship between these elements. The meta-model facilitates
a consistent and concise method, which in turn allows for their application in a goal
oriented, systematic and repeatable fashion. According to Gutzwiller [40] activities
are the construction of tasks which create certain results. These activities are assigned
to roles and the results are recorded in previously defined and structured specification
documents. The techniques comprise of the detailed instructions for the production of
the specification documents. Tools can be associated with this process. The meta-
model describes the information model of the results.
Fig. 1. Method Engineering Approach.
Applying a method based perspective on contextualising IQ frameworks, we
identified four main activities that describe the contextualisation process: (1) Identify
and prioritising contextual factors, (2) Selecting and prioritise IQ dimensions with
associated IQ measures, (3) Implement IQ measures, (4) review and improve.
Besides the contextualisation process (activities), the second main element is the
description of result documents. We provide a consistent result document for
contextualised IQ frameworks. The meta-model is illustrated in Figure 2 that outlines
the relationship between the different components of context factors and IQ
measurements.
Meta Model
Component
-
Result
Document
Technique Role
Design
Activity
creates
performs
contains
precedes
consists of
defines
precedes consists of
uses
Tool
uses
Meta Model
Component
-
Result
Document
Technique Role
Design
Activity
creates
performs
contains
precedes
consists of
defines
precedes consists of
uses
Tool
uses
Consistency;
guidelines and
reference models
Meta Model
Component
-
Result
Document
Technique Role
Design
Activity
creates
performs
contains
precedes
consists of
defines
precedes consists of
uses
Tool
uses
Meta Model
Component
-
Result
Document
Technique Role
Design
Activity
creates
performs
contains
precedes
consists of
defines
precedes consists of
uses
Tool
uses
Consistency;
guidelines and
reference models
155
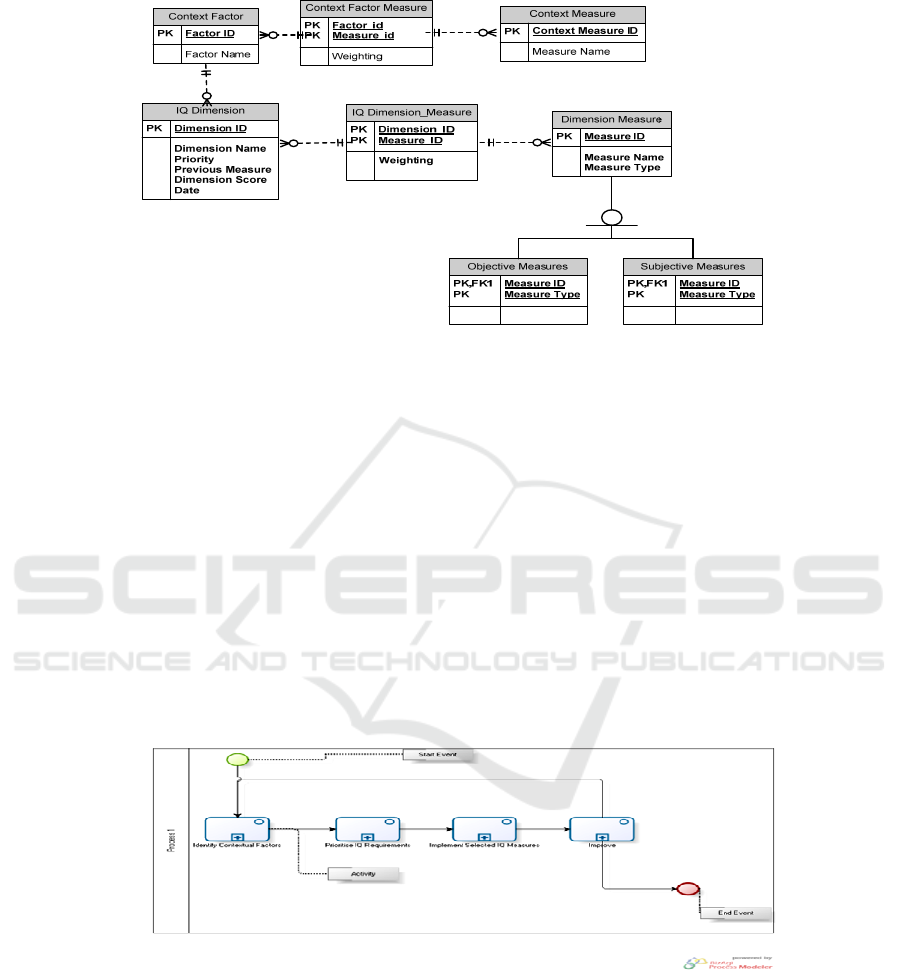
Fig. 2. Meta Model for Contextualising IQ Frameworks.
The initial application of the ME approach to our problem was examined with
respect to a library IS. A diverse user population accesses this IS from three different
contexts. Figure 3 specifies the general contextualisation processes that allow us to
conduct an experiment to validate our approach. We consider 4 main activities (1)
Identify contextual factors, (2) Quantify and prioritise IQ requirements, (3)
Implement selected IQ Measures, (4) Improve. Activity (1) is usually carried out by
the IS Manager, involving interviews and surveys with domain experts. This activity
completes and measures context factors. Activity (2) identifies and prioritises IQ
metrics and requirements. Carried out by Business Analysts, for this activity and to
priorities IQ dimensions we selected a specific technique: Leung’s metric ranking.
Subsequently the Information Technology Manager and Software developers
implement the IQ measures, in the form of Service Analysers, Integrity Checker and
IQ surveys. Finally, IS manager, Information Technology managers together with the
Business Analyst review the context factors as well as IQ measures, and thus initiate a
continuous improvement process.
Fig. 3. High Level View of IQ Dimension Selection Method.
This general contextualisation process was detailed in sub-processes. Figures 4 to
7 outline in detail the process description that is required in order to apply our
method. In conjunction with the meta-model in figure 2, the result of the subsequent
156
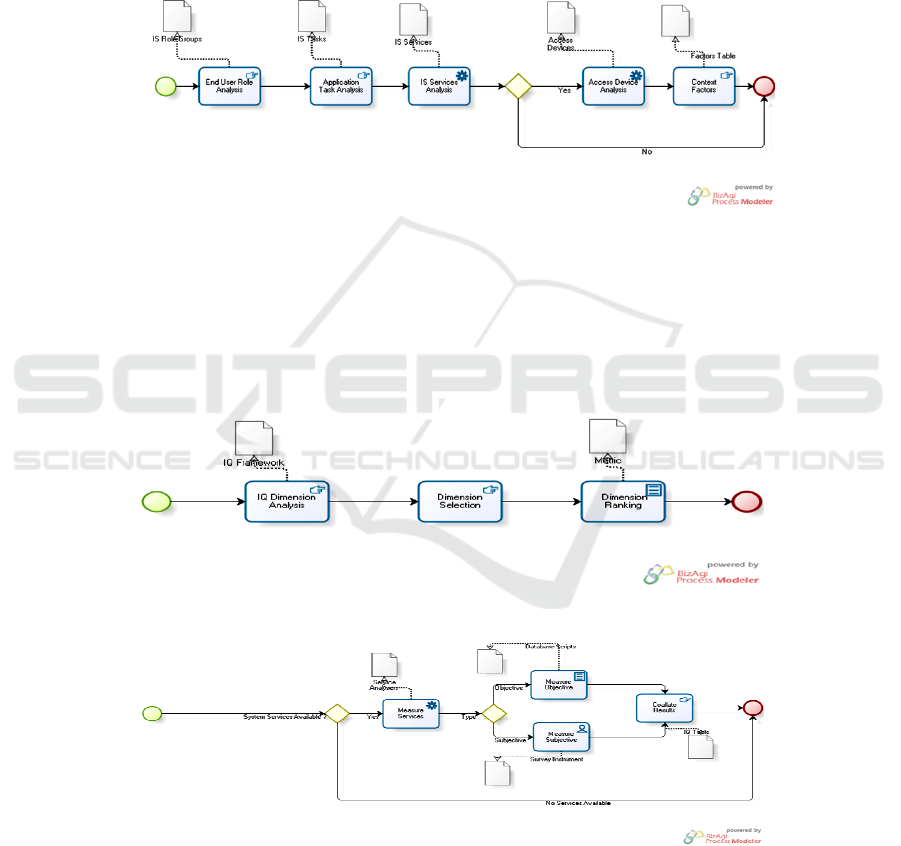
processes, provides us with a detailed set of activities and tools that allow for context
factor and dimension selection.
In order to select appropriate context factors as described in figure 4 the role
groups of the IS, tasks, associated IS service and access devices are identified and
assessed. This assessment is done in conjunction with the domain users and IS
experts. Upon identification of these a classification order is assigned to each of the
context factors. The context factor and context factor measure tables in figure 2 are
propagated with the appropriate values.
Fig. 4. Identify Contextual Factors.
Upon identification of the context factors there is a requirement to identify and
prioritise dimension selection appropriate to a particular context. This requires
domain experts, IS and IT managers to rank dimensions in order of priority. This may
involve the application of domain metrics or survey instruments to ascertain the most
important dimensions. Once this process is completed the appropriate dimension
tables outlined in figure 2 are updated.
Fig. 5. Prioritise IQ Dimension Requirement.
Fig. 6. IQ Measurement.
157

The selection of appropriate dimensions requires them to be measured. It is
important that the sequence of measures is followed correctly as outlined in figure 6.
The measures as outlined in table 3 require the availability of services to be checked
initially followed by the objective database and subjective measures.
Fig. 7. Improve.
The final process of improvement involves revised context factor analysis by
means of user work and measures. The revised factors are updated in the contect
factors table.
The contextualisation process and the result meta-model are further extended by a
set of objective and subjective IQ measures. These are part of the meta-model in
Figure 2. The objective measures are further subdivided into two categories data base
integrity measure and software service measure. A summary of the objective and
subjective IQ measures is available in Table 3. Subjective IQ Measures follow a
common questionnaire approach, using questionnaire construct and a 5-point Likert
scale.
Now we have described the process steps (activities) for contextualising IQ
frameworks. Further we have specified objective and subjective measures for IQ.
Reviewing the meta model in Figure 2, we also need to specify how various IQ
measures from different IQ dimensions are aggregated.
Many researchers have proposed ways to aggregate single measures of IQ
dimensions, often underlying a weighted aggregate of single values for IQ dimensions
[2]. Although, recently some researchers have attempted to propose IQ value curves
and trade-offs by analysing the potential impacts of IQ, many researchers propose to
measure the overall impact of IQ as weighted aggregate. A principle measure of the
weighed sum of all the criteria (IQC
i
) is illustrated below
where
Equation 1. Aggregate measure of information quality.
We follow this prominent aggregation of IQ measures by weighted sums. This is
reflected in our method and meta-model by specifying priorities in forms of weights.
The aggregated value should define the quality level that characterizes information
source. The approach to use the average as an aggregation functions may not be
suitable among heterogeneous dimensions since dependencies introduces bias that
negatively affect the reliability of the assessment procedure. This might be
problematic, as changes in the context will have an impact on other dimensions and as
a consequence the aggregate score.
∑
=
=
N
i
ii
IQCIQ
1
α
∑
=
=
≤
≤
∀
N
i
i
ii
1
1
10:
α
α
α
158

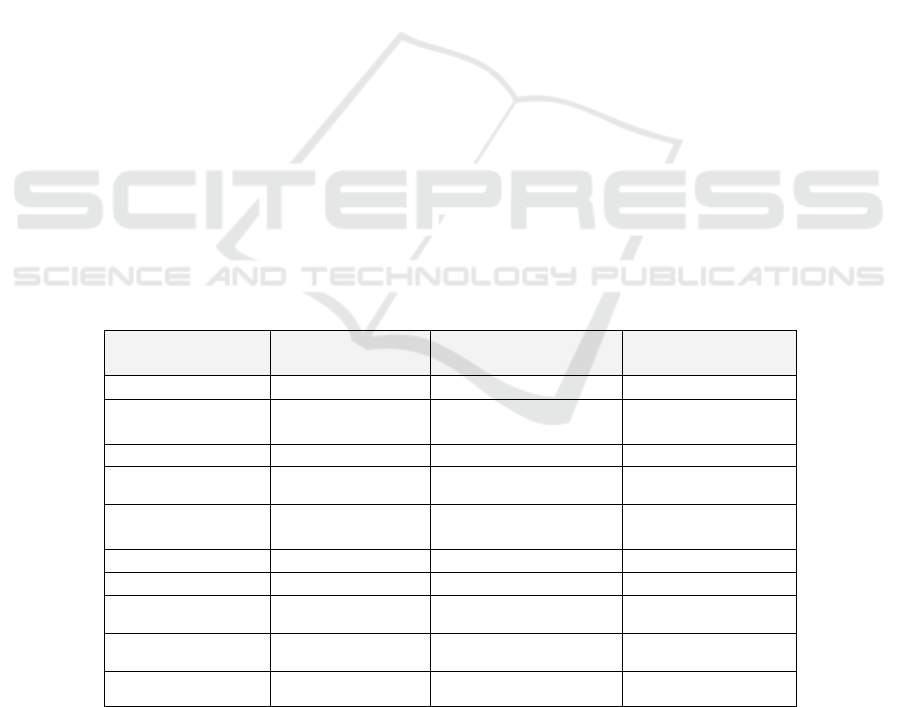
Table 3. Information Quality Measures.
Measure Name Description Measure
Data base Integrity
Free-of-Error
The dimension that represents
whether data are correct.
Free-of-Error Rating = 1-
Where N = Number of data units
in error and T = Total number of
data units.
Completeness
Schema, Column and
Population
Completeness Rating = 1-
Where C = Number of
incomplete items and T = Total
number of items.
Consistency
Referential Integrity, Format
Consistency Rating = 1-
Where C = Number of instances
violating specific consistency
type and T = Total number of
consistency checks performed.
Timeliness
The delay in change of real
world state compared to the
modification of the ISs state.
The difference between the
times when the process is
supposed to have created a
value and when it actually has.
Timeliness Rating = R – I
Where R = IS State Time I =
Real World Time
Software
Service
Database Listener
DB process Binary Measure
Web Service
Web Service Process Binary Measure
Mobile Access
Security Access User Profile Dependent
Subjective Information Quality Measures
Timeliness
This information is sufficiently current for our work.
This information is not sufficiently current for our work.
This information is sufficiently timely.
This information is sufficiently up-to-date for our work.
Free of Error
This information is correct.
This information is incorrect.
This information is accurate.
This information is reliable.
Completeness
This information includes all necessary values.
This information is complete.
This information is sufficiently complete for our needs.
This information covers the needs of our tasks.
This information has sufficient breadth depth for our task.
Consistency
This information is consistently presented in same format
This information is presented consistently.
This information is represented in a consistent format.
T
N
T
C
T
C
159

5 Initial Application and Analysis
We applied the developed Method to contextualise IQ Frameworks in an experiment
involving 48 users. By considering various contexts, this allows us to measure the
impact of the context on the perception of IQ. The USER ANALYSIS in Figure 4
identified 3 groups broken down between librarians, library users and technicians.
This involved the users completing a number of TASKS with respect to information
retrieval as they pertained to each particular group. The selected dimensions of the
framework for the particular ENVIRONMENT are then broken down into objective
and subjective measures. The results from application of the measures are compared
upon completion.
The tasks for each user group were specific to that group. Members of the groups
were randomly allocated to each of the access devices. The experiment involved
control of one independent variable namely the access device. Each of the groups
were assigned tasks particular to their profile. The tasks within each group were
conducted from three different contexts namely workstation, web, and mobile. The
first requirement of the method is to analyse the software services identified and
selected. This is a binary test and examines the availability of the service. The
application of the method first checks the availability of the three software services
identified. In the event of service availability the objective integrity analysers are
initiated. The results of this analysis are stored in an IQ table-space similar to an audit
table-space [41]. The subjective survey instrument is run in conjunction with the
objective integrity analysers.
The analysis of results indicate that a relationship exists between the level of IQ
and the context of IS access. This confirms the requirement to select IQ dimensions
appropriate to individual contexts. The implementation of our method and its
validation by means of an experiment demonstrate the significance of context. A
uniform application of dimensions without consideration for context we contend will
not accurately reflect the true state of IQ for an IS.
We describe the process of data collection and analysis. The initial step in the
analysis is the binary test of services. This important step in our method as outlined in
Figure 6 it allows for the identification of dimensions associated with various
software services. Subjective analysis only takes place when this analysis is complete.
All the services were present therefore the subjective and objective tests were applied
to all participants. In order to test the level of significance of the remainder of the
results it is necessary to apply an appropriate statistical technique to the data gathered.
We need to ascertain if there is a relationship between the context of the IS (Web,
Workstation or Mobile) and the level of IQ. As IQ is a multidimensional concept it is
necessary to do this at a dimension level.
There is a clear indication from this initial analysis that the context of the IS is
significant. However in order to strengthen and build on this finding Field [42],
suggests that appropriate inferential statistical techniques should be applied. A review
of this literature indicates that One Way Independent Analysis of Variance (ANOVA)
is appropriate. Field [42] also suggests that this technique be used when three or more
statistical groups and different participants in each group will be used.
160

Based on confidence interval of 95%, v
1
=2 and v
2
=27, the critical F statistic,
F
.05,2,15
= 3.354 are within the “Reject H
0
” which leads us to the conclusion that the
population means are not equal.
The ANOVA test statistically indicates that the population means are not even.
We have rejected H
0.
Caulcutt [43] indicates that it is possible to determine which of
the sample means is statistically significant using the Scheffé Test. According to our
results statistically users rate the IQ dimension of free-of-error best from the
workstation context in comparison with both web and mobile. They also rate the web
context statically more significant or satisfied than the mobile context.
6 Summary, Future Research and Limitations
This research contributes to the analysis of IS context and IQ. Although frequently
mentioned, foremost research lacks in explaining adequately the impact that IS
context has on IQ [15]. In recent times companies have invested heavily in IQ
programmes in an effort to improve IQ [11]. Our research demonstrates that a
relationship exists between IS context and other dimensions in an IQ framework. We
have specified a method that allows context to be considered when selecting
dimension. The traditional techniques of measuring IQ dimensions will also require
examination as relationships between the context and other dimensions have also been
established. This research contributes to the field of IQ research by providing a
method and test environment that can be employed in a context related manner. It has
the potential to allow organisations to measure the impact of introducing new contexts
post the development of an IS.
Although the research revealed interesting results, our research currently
concentrates only on a subset of dimensions. The application of further experiments
addresses this limitation. Correlation has been used to examine the relationship
between IQ dimensions; Analysis of Variance will be completed for all sections of the
research. This will allow for a full examination of experimental data. Furthermore it is
intended to improve and extend the prototypical implementation of the tool as
software application.
References
1. Wand, Y. and R. Wang, Data Quality Dimensions in Ontological Foundations.
Communications of the ACM, 1996. 39: p. 184-192.
2. Wang, R. and D. Strong, Beyond Accuracy: What Data Quality Means to Data Consumers.
Journal of Management Information Systems, 1996. 12: p. 5-34.
3. Pipino, L., Y. Lee, and R. Wang, Data Quality Assessment. Communications of the ACM,
2002: p. 211-218.
4. Kahn, B. and D. Strong, Information Quality Benchmarks: Product and Service.
Communications of the ACM, 2002: p. 184-192.
5. Recker, J., et al. Model-Driven Enterprise Systems Configuration. in 18th Conference on
Advanced Information Systems Engineering. 2006. Luxembourg: Springer.
6. Lee, Y., Crafting Rules: Context-Reflective Data Quality Problem Solving. Journal of
161

Management Information Systems, 2004. 20(3): p. 93-119.
7. Redman, T., Data Quality for the Information Age. 1996: Artech House Publishers.
8. AlHakim, L., Challenges of Managing Information Quality in Service Organizations. 2007:
Idea Group Pub.
9. Date, C., Databases in Depth. 2005: O Reilly.
10. Loshin, D., Enterprise Knowledge Management - The Data Quality Approach. 2001:
Morgan Kaufmann.
11. AlHakim, L., Information Quality Management Theory and Applications 2007.
12. Olson, J., Data Quality: The Accuracy Dimension. 2003: Morgan Kaufmann.
13. Adelman, S., L. Moss, and M. Abai, Data Strategy. 2005: Addison-Wesley.
14. Sangwan, R., et al., Global Software Development Handbook. 2007: Auerbach
Publications.
15. Knight, S. and J. Burn, Developing a Framework for Assessing Information Quality on the
World Wide Web. Informing Science, 2005. 8: p. 159-172.
16. Helfert, M. and M. Ge. A Review of Information Quality Research. in 11th International
Conference on Information Quality. 2006.
17. Morris, S., J. Meed, and N. Svensen, The Intelligent Manager. 1996, London: Pitman
Publishing.
18. Huang, K., Y. Lee, and R. Wang, Quality Information and Knowledge Management. 1999.
19. Chengalur-Smith, I. and P. Duchessi, The Initiation and Adoption of Client Server
Technology in Organizations. Information and Management, 1999. 35(7): p. 77-88.
20. Miller, An expanded instrument for evaluating information system success. Information and
Management, 1996. 31(2): p. 103-118.
21. Berndt, E.R. and D.M. Cutler, Medical Care Output and Productivity. 2001: National
Bureau of Economic Research.
22. Xu, H., et al., Data Quality Issues in implementing an ERP. Industrial Management & Data
Systems, 2002. 102(1): p. 47-59.
23. Davenport, T., Information Ecology: Mastering the Information and Knowledge
Environment. 1997, Oxford: Oxford Universirty Press.
24. Heinrich, B. and M. Helfert. Analyzing Data Quality Investments in CRM: a Model Based
Approach. in 8th International Conference on Information Quality. 2003. Boston,
Massachusetts, USA.
25. Ballou, D.P., et al., Modelling Information Manufacturing Systems to Determine
Information Product Quality. Management Science, 1998. 44(4): p. 462-484.
26. Amicis, F.D. and C. Batini, A Methodology for Data Quality Assessment on Financial
Data. Studies in Communication Sciences, 2004. 4(2): p. 115-137.
27. Kahn and Strong. Product and Service Performance Model for Information Quality: an
update. in 4th International Conference on Information Quality. 1998. Boston,
Massachusetts, USA.
28. Xu, H. and A. Koronios, Understanding Information Quality in E-business. Journal of
Computer Information Sytems, 2004. 45(2): p. 73-82.
29. Rittberger, M. Certification of Information Services. in Proceedings of the 1999 Conference
on Information Quality. 1999. Boston, Massachusetts, USA.
30. English, L., Improving Data Warehouse and Business Information Quality. 1999, New
York: Wiley & Sons.
31. Li, S. and B. Lin, Accessing Information Sharing and Information Quality in Supply Chain
Management. Decision Support Systems, 2006. 42(3): p. 1641-1656.
32. Ballou, D.P. and G.K. Tayi, Enhancing Data Quality in Data Warehouse Environments.
Communications of the ACM, 1999. 42(1): p. 73-78.
33. Fisher, C., et al., Introduction to Information Quality. 2006: MIT.
34. Goodhue, D.L., Understanding user evaluations of Information Systems. Management
Science, 1995. 41(12): p. 1827-1842.
35. Misser, P., et al., Improving data quality in practice: a case study in the Italian public
162

administration. Distributed and Parallel Databases, 2003. 13(2): p. 125-169.
36. Ballou, D.P. and H. Pazher, Modeling completeness versus consistency tradeoffs in
information decision contexts. IEEE Transactions in Knowledge and Data Engineering,
2003. 15(1): p. 240-243.
37. Wang, R.Y., A Product Perspective on Total Quality Management. Communications of the
ACM, 1998. 41(2): p. 58-65.
38. Brinkkemper, S., K. Lyytinen, and R.J. Welke, Method Engineering Principles of method
construction and tool support. 1996: Chapman & Hall.
39. Punter, T. and K. Lemmen, The META-model: towards a new approach for Method
Engineering. Information and Software Technology, 1996. 38(4): p. 295-305.
40. Gutzwiller, T., Das CC fur den Entwurf von betrieblichen, transaktionsrieentierten
Informationssytems, Physica. 1994: Heidelberg.
41. Greenwald, R., R. Stackowiak, and R. Stern, Oracle Essentials: Oracle Database 11g. 4th
ed. 2004: O Reilly.
42. Field, A. and G. Hole, How to Design and Report Experiments. 2006.
43. Caulcutt, R., Statistics in research and development. 1991: CRC Press.
163
