
A NEW DEPTH-BASED FUNCTION FOR 3D HAND MOTION
TRACKING
Ouissem Ben-Henia and Saida Bouakaz
LIRIS CNRS UMR 5205, Universit
´
e Claude Bernard Lyon 1
43 Boulevard du 11 novembre 1918, 69622 Villeurbanne, France
Keywords:
Hand tracking, Dissimilarity function, Minimization method.
Abstract:
Model-based methods to the tracking of an articulated hand in a video sequence generally use a cost function
to compare the hand pose with a parametric three-dimensional (3D) hand model. This comparison allows
adapting the hand model parameters and it is thus possible to reproduce the hand gestures. Many proposed
cost functions exploit either silhouette or edge features. Unfortunately, these functions cannot deal with the
tracking of complex hand motion. This paper presents a new depth-based function to track complex hand
motion such as opening and closing hand. Our proposed function compares 3D point clouds stemming from
depth maps. Each hand point cloud is compared with several clouds of points which correspond to different
model poses in order to obtain the model pose that is close to the hand one. To reduce the computational
burden, we propose to compute a volume of voxels from a hand point cloud, where each voxel is characterized
by its distance to that cloud. When we place a model point cloud inside this volume of voxels, it becomes
fast to compute its distance to the hand point cloud. Compared with other well-known functions such as the
directed Hausdorff distance(Huttenlocher et al., 1993), our proposed function is more adapted to the hand
tracking problem and it is faster than the Hausdorff function.
1 INTRODUCTION
Our research focuses on complex hand motion track-
ing, with the aim of developing vision-based ap-
proaches capable of reproducing the hand gestures.
These last years, research works on hand motion
tracking have been strengthened, especially due to the
growing need of human-computer interactions for en-
tertainment and video games. Many vision-based ap-
proaches have been proposed to solve the hand track-
ing problem. According to the considered applica-
tion, the existing methods could be grouped into two
categories: view-based and model-based.
View-based methods use a database of predefined
hand poses, which are generally recovered through
classification or regression techniques(Rosales et al.,
2001), (Shimada et al., 2001). A set of hand features
is labeled with a particular hand pose, and a classifier
is trained from this data. Due to the high dimension-
ality of the space spanned by possible hand poses, it
is difficult, or even impossible to perform dense sam-
pling. Therefore, when we consider a limited set of
predefined hand poses, it becomes possible to cope
with real-time applications such as a human-computer
interaction one (Ike et al., 2007).
Model-based methods use a parametric three-
dimensional (3D) hand model and provide more pre-
cise and smooth hand motion tracking(de La Gorce
et al., 2008), (Stenger et al., 2006), (Kerdvibulvech
and Saito, 2009), (Henia et al., 2010). The 3D hand
model is often represented as a hierarchical one with
approximately 26 degrees of freedom (DOF) (Kato
and Xu, 2006), (Wu et al., 2005). Its appearance
part is provided by an underlying geometric structure.
To achieve hand motion tracking, these methods es-
timate the hand model parameters which reproduce
the hand motion appearing in video sequences. For
this purpose, a cost function is defined to compare
the hand poses with the model ones. The well-know
cost functions exploit either silhouette or edge fea-
tures extracted from images shot by affordable cam-
eras (Stenger et al., 2001), (Kato and Xu, 2006).
These functions are fast to be computed but can-
not deal with the tracking of complex hand motion
such as the closing of hand. To solve this problem,
other alternatives have proposed to use a color glove
(Wang and Popovi
´
c, 2009) which eliminates ambi-
guities between the palm down pose and the palm
653
Ben-Henia O. and Bouakaz S..
A NEW DEPTH-BASED FUNCTION FOR 3D HAND MOTION TRACKING.
DOI: 10.5220/0003378106530658
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2011), pages 653-658
ISBN: 978-989-8425-47-8
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

up one. Another depth map based-function was pro-
posed in (Bray et al., 2004a). To speed up the track-
ing, the hand is subsampled at 45 stochastically de-
termined points (2 for each visible phalanx and 15 for
the palm). This simplification cause a loss of infor-
mation.
In this paper, we propose a new depth-based func-
tion which makes use of all the hand points appear-
ing in depth map. Our proposed function evaluates
a distance between two clouds of points, which rep-
resent respectively the hand and its underlying 3D
model. Each hand point cloud is compared with sev-
eral clouds of points which correspond to different
model poses in order to obtain the model pose that
is close to the hand one. The distance computation
by means of well-known functions such as the Haus-
dorff(Huttenlocher et al., 1993) one is computation-
ally expensive. To reduce the computational burden,
we propose to compute a volume of voxels from a
hand point cloud, where each voxel is characterized
by its distance to that cloud. Once this volume of
voxels is obtained, and when we place a model point
cloud inside this volume, it becomes fast to assess its
distance to the hand point cloud. The remainder of
this paper is organized as follows. The next section
presents the used 3D hand model. Our proposed func-
tion is detailed in section 3. Section 4 describes the
hand motion tracking algorithm. Before concluding,
experimental results from synthetic data are presented
in section 5.
2 THE HAND MODEL
The human hand is a complex and highly articu-
lated structure. Several models have been proposed
in the literature. In (Heap and Hogg, 1996) a 3D de-
formable point distribution model was implemented.
This model can not accurately reproduce all realistic
hand motion. Indeed, since this model is not based on
a rigid skeleton, fingers can be warped and reduced to
ensure tracking of the hand gestures.
On the other hand, skeleton animation based
model was used in (Bray et al., 2004b), (Ouhaddi and
Horain, 1999). This kind of models is usually defined
as hierarchical transformations representing the DOF
of the hand: position and orientation of the palm, joint
angles of the hand(Figure:1(a)). The variation in the
values of DOF animates the 3D hand model. Using
this kind of models, we can estimate not only the po-
sition and orientation of the hand, but also the joint
angles of fingers.
In our proposed work, we use a parametric hand
Distal interphalangeal (DIP)
Proximal interphalangeal (PIP)
Metacarpophalangeal (MCP)
Index
Annulaire
Auriculaire
Pouce
Interphalangeal(IP)
Metacarpophalangeal (MC)
Trapziometacarpal (TM)
x
y
z
Majeur
Articulation avec 6 degrés de liberté : 3 rotations et 3 translations
Articulation avec 2 degrés de liberté : rotations autour des axes X et Z
Articulation avec 1 seul degré de liberté : rotation autour de l’axe X
(a)
(b)
Figure 1: (a) Squeletal representation of the 3D model (b)
3D hand model appearance.
model which is conforming to the H-Anim standard
1
.
The H-Anim model is often used in the 3D animation
field. We can highlight its particularity to separate
the kinematic part (motion) from the appearance one.
This model consists of a hierarchy of 3D transforma-
tions (rotation, translation) allowing easy control of
its animation by modifying only the involved trans-
formations. Regarding the appearance, objects called
segments are placed in this hierarchical representation
to provide the shape of this model (Figure 1(b)). To
change the appearance of this model, we modify the
objects representing the model apprearence. In our
proposed work, these object segments are modeled
by quadric surfaces as shown in Figure 1(b). In our
hand model, each finger is modeled as a four DOF
kinematic chain attached to the palm. Together with
the position and orientation of the palm, there are 26
DOF to be estimated.
For the model appearance, we use a set of quadrics
approximately representing anatomy of a real human
1
Humanoid-Animation(H-ANIM) is an approved ISO
standard for humanoid modeling and animation. website
:www.h-anim.org
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
%p

hand (Figure 1(b)). The palm is modeled using a
truncated ellipsoid, its top and bottom closed half-
ellipsoids. Each finger is composed by three truncated
cones, i.e. one for each phalanx. Hemisphere was
used to close each truncated cone. The major advan-
tage of this model shape representation is its simplic-
ity to be adapted to any hand to track compared with
models based on 3D scans.
3 DISSIMILARITY FUNCTION
We propose to assess a distance between two clouds
of points, which represent respectively the hand and
its underlying 3D model. Two well-known functions
are often used to compute distance from a set of points
A to another one B. The first one is given by the fol-
lowing formula:
d
1
(A, B) =
1
|A|
∑
a
i
∈A
min
b
j
∈B
d(a
i
, b
j
) (1)
where |A| is the cardinal number of the set of points A,
and d(a
i
, b
j
) the Euclidean distance between the two
points a
i
and b
j
. The second well-known function is
the directed Hausdorff distance. We denote this func-
tion d
2
.and we present its by means of the following
equation :
d
2
(A, B) = max
a
i
∈A
{min
b
j
∈B
d(a
i
, b
j
)} (2)
where the Euclidean distance d(a
i
, b
j
) is identical to
the one described above in Eq.1 The distance com-
putation by means of this class of functions is per-
formed in a non-linear way. Indeed, the point cloud B
is sweeped as many times as points in A. In our case
study, these functions are computationally expensive
due to the fact that for each frame several distances
are to be computed. These distances are defined from
the same cloud of points of the hand to several point
clouds obtained by the hand model. In this paper we
propose a well suited function to our case study. This
function is based on 3D distance transform and per-
formed in two stages. The first one computes a vol-
ume of voxels from the cloud of points A, where each
voxel encompasses the distances of the voxel to A.
The cubic voxel is used in the second stage to evalu-
ate the distance from the point cloud A to another one
B.
The algorithm developed to compute the voxel
volume is inspired from the method proposed by A.
Meijster et all in(Meijster et al., 2000), where a dis-
tance map is computed from a 2-D (bidimensional)
image. This algorithm could be extended to an n-D(n-
dimensional) space. We implement an extension of
(a) (b)
Figure 2: (a) Point cloud A(b) A voxel volume obtained
from the point cloud A.
this algorithm for the 3-D (three-dimensional) space
to compute a cubic volume CV (Figure 2(b)) from the
point cloud A (Figure 2(a)). In Figure 2(b) color cor-
responds to distance value. More detailed could be
found in(Meijster et al., 2000).
Once the 3-D volume is obtained, we can compute
the distance of any point cloud B to the cloud A using
the following formula:
F(A, B) =
1
|B|
∑
b
i
∈B
CV [b
i
x
][b
i
y
][b
i
z
] (3)
where b
i
x
b
i
y
b
i
z
are the coordinates of the point b
i
.
4 THE TRACKING ALGORITHM
The tracking of the hand gestures in a video se-
quence is performed by seeking the hand model pa-
rameters which reproduce the hand motion as sum-
marized in Figure 3. We achieve this step by min-
imizing our dissimilarity function for each frame of
the video sequence. This minimization provides the
hand model parameters which align the model pose
with the hand one. We assume that the hand model
parameters are close to the solution associated with
the first frame of the video sequence. For the remain-
der of the video sequence, the minimization process
exploits the hand model parameters obtained at the
previous frame. We use the iterative algorithm pro-
posed by Torczon(Dennis et al., 1991) to explore dif-
ferent directions for each iteration and keep the one
minimizing the dissimilarity function. The Torczon’s
algorithm is an amelioration of the Nelder and Mead’s
one (Nelder and Mead, 1965).
The choice of the Torczon’s algorithm is sup-
ported by two main facts. Firstly, the use of this al-
gorithm does not require the knowledge of the deriva-
tive of the function to be minimized. The second fact
relates to the processing of the Torczon’s algorithm
itself. Indeed, the Torczon’s algorithm explores dif-
ferent directions for each iteration. These various ex-
plorations can be achieved in parallel to reduce the
computational burden.
A NEW DEPTH-BASED FUNCTION FOR 3D HAND MOTION TRACKING
%p
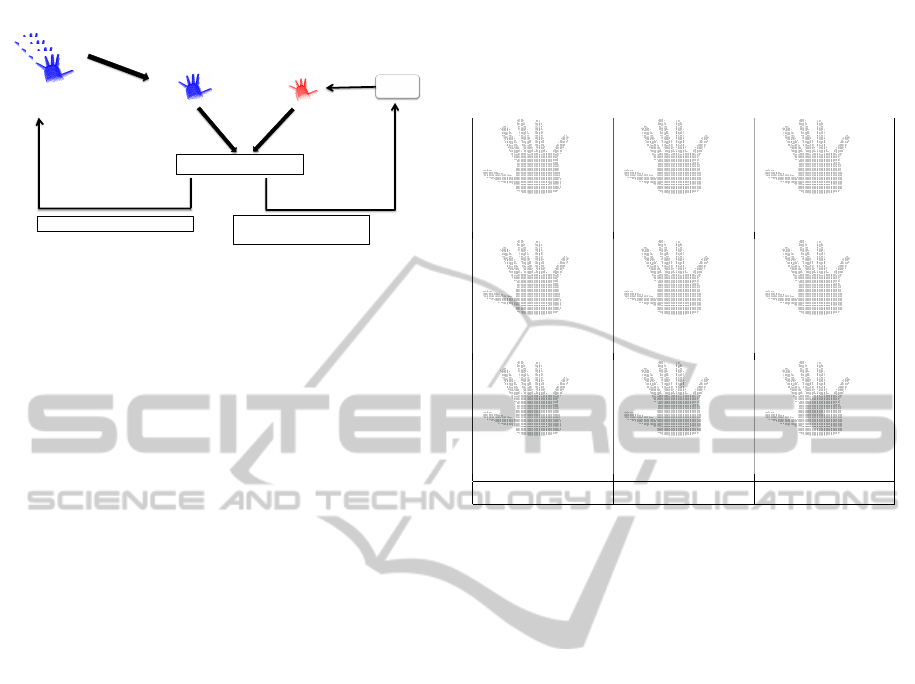
3D point clouds obtained
from depth maps
Dissimilarity function
Validation and go to the next frame
Updating the parameters
of the hand model
Hand cloud point Model point cloud
3D
model
Figure 3: Tracking process.
Due to the high number of the model parame-
ters to be estimated, we use a simplification proposed
in (Henia et al., 2010) to minimize the dissimilarity
function in two steps. The first one estimates the
position and orientation of the hand. The parame-
ters representing the joint angles of fingers are fixed,
whereas those representing the position and orienta-
tion of the palm are processed by the minimization
algorithm. The processing is reversed at the second
step, i.e. the orientation and position parameters are
fixed to those obtained in the first step, and the joint
angles of the hand are estimated. Besides simplifying
the minimization problem, this approach can be sup-
ported by the slow variation of the hand pose in two
successive frames.
5 EXPERIMENTAL RESULTS
The performances achieved by our proposed work
are evaluated for tracking hand motion appearing in
synthetic images. A video sequence of one hundred
320x240 synthetic images of the hand model is ac-
quired (Table 1). To obtain this sequence of im-
ages, we vary the parameters of each finger except
the thumb and the index. Through this test benchmark
we can highlight the importance of the depth informa-
tion to cope with complex hand motion. Our proposed
function compares point clouds generated from depth
maps obtained by means the OpenGL library.
We compare the results obtained by our pro-
posed function with those achieved by means of the
silhouette-based function proposed in (Henia et al.,
2010). The silhouette-based function is not adapted to
the tracking of abduction finger motion. Indeed, the
finger motion tracking is lost at the frame 50 of the
video sequence (Table 1). To estimate the error of the
tracking algorithm, we compute a difference between
the tracking results and the ground truth. The tracking
error is then plotted as a curve in Figure 4, in which
we only consider the PIP(Figure 1(a)) joint angles of
Table 1: Tracking results using synthetic data : the first
line represents 3d point clouds corresponding to the ground
truth, the second line shows the tracking results using a
silhouette-based function, the third line represents the track-
ing results using our proposed depth-based function.
Frame 1 Frame 50 Frame 100
the middle finger. With our proposed depth-based
function, the error is very small when it is compared
with another silhouette-based function (Henia et al.,
2010). Indeed, the average tracking error drops from
0.5 radian with the silhouette-based function to 0.1 ra-
dian with our proposed depth-based function (Figure
4). Our observation concerning the tracking error of
the PIP joint angle of the middle finger could be still
valid for other parameters.
Using the same test benchmark (Table 1), the re-
sults obtained by our proposed function are also com-
pared with those achieved by means of the Hausdorff
function. The tracking results are very close in terms
of accuracy but are very different regarding comput-
ing time. The running time is about 3 seconds per
frame using our proposed function, whereas 300 sec-
onds per frame are required by the Hausdorff func-
tion. We can highlight that the average cardinal of the
point clouds used in our test benchmark is approxi-
mately 3000 points. We can see that our proposed
function is well-adapted to the hand tracking prob-
lem because the computing time is acceptable even if
the point cloud is significant. The processing is per-
formed using a PC Intel-Centrino 2 GHZ processor
and Nvidea graphic card (GeoForce 8600MGT).
6 CONCLUSIONS
AND FUTURE WORK
This paper presents a new depth-based function that
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
%p
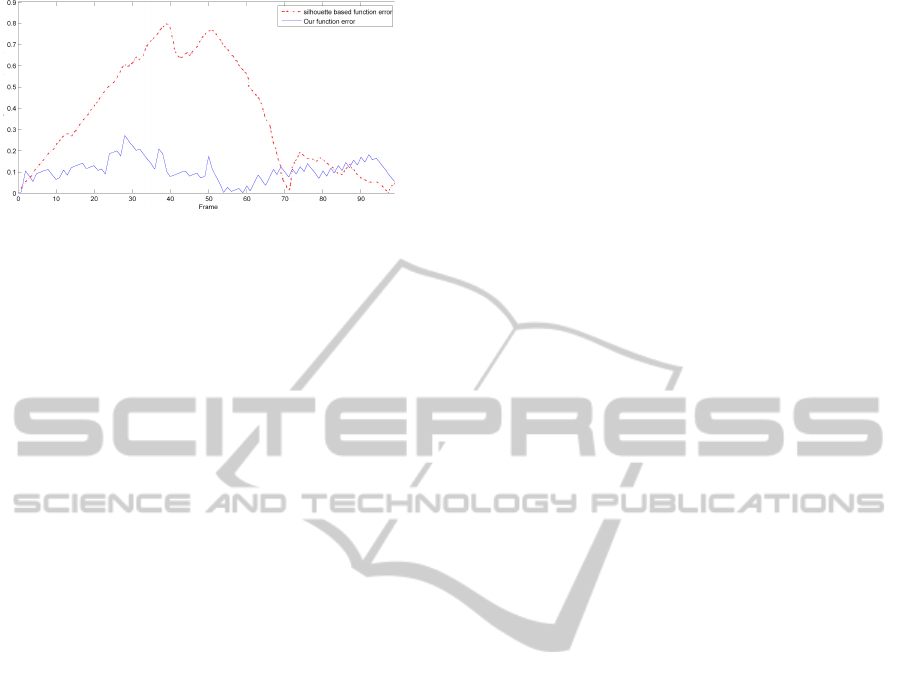
Figure 4: Tracking error of the PIP middle finger.
is well-adapted to the 3D hand tracking. A 3D para-
metric hand model is used to achieve the tracking by
comparing its poses with the hand ones using our pro-
posed function. The depth-based function compares
3D point clouds stemming from depth maps. Each
hand point cloud is compared with several clouds of
points which correspond to different model poses in
order to obtain the model pose that is close to the hand
one. Classical functions comparing 3D point clouds
such as the Hausdorff one are not adapted for the
hand tracking problem because of the expensive time
needed to achieve both the comparison and track-
ing. To reduce the computational burden, we propose
to compute a volume of voxels from the hand point
cloud, where each voxel is characterized by its dis-
tance to that cloud. By placing any model point cloud
in the computed volume, it becomes fast to compute
its distance to the hand point cloud. We experiment
our proposed function using synthetic data obtained
from depth maps generated by means of the OpenGL
library. The preliminary results obtained so far are
very encouraging because we are able to track com-
plex hand motion such as the closing of hand. Besides
tracking complex hand motion, our proposed function
is faster than other well-known functions such as the
Hausdorff one.
We plan to extend our experimental study using
real data. For this propose, different methods could
be used to collect 3D hand point cloud. Stereo vi-
sion could be a solution to the problem of acquiring
3D cloud point of the hand but it requires the use two
video cameras. Another alternative consists to use a
new generation of video cameras, called time of flight
cameras, and provides a 3D cloud point of the ob-
served scene in real-time. However, this new technol-
ogy is deemed to be not very precise. Structured light
sensor could also be used to obtain depth maps of the
hand as it is done in (Bray et al., 2004a). This method
seems to provide accurate results but it is slower than
a time of flight camera. A comparative study between
these different methods must be performed to select
the one yielding the best results in terms of accuracy
and computing time.
REFERENCES
Bray, M., Koller-meier, E., Mller, P., Gool, L. V., and
Schraudolph, N. N. (2004a). 3d hand tracking by rapid
stochastic gradient descent using a skinning model. In
In 1st European Conference on Visual Media Produc-
tion (CVMP, pages 59–68.
Bray, M., Koller-Meier, E., Schraudolph, N. N., and Gool,
L. V. (2004b). Stochastic meta-descent for tracking
articulated structures. In CVPRW ’04: Proceedings
of the 2004 Conference on Computer Vision and Pat-
tern Recognition Workshop (CVPRW’04) Volume 1,
page 7, Washington, DC, USA. IEEE Computer So-
ciety.
de La Gorce, M., Paragios, N., and Fleet, D. J. (2008).
Model-based hand tracking with texture, shading and
self-occlusions. In CVPR.
Dennis, J. E., Jr., and Torczon, V. (1991). Direct search
methods on parallel machines. SIAM Journal on Op-
timization, 1:448–474.
Heap, T. and Hogg, D. (1996). Towards 3d hand tracking
using a deformable model. In In Face and Gesture
Recognition, pages 140–145.
Henia, O. B., Hariti, M., and Bouakaz, S. (2010). A two-
step minimization algorithm for model-based hand
tracking. In WSCG.
Huttenlocher, D. P., Klanderman, G. A., Kl, G. A., and
Rucklidge, W. J. (1993). Comparing images using
the hausdorff distance. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 15:850–863.
Ike, T., Kishikawa, N., and Stenger, B. (2007). A real-time
hand gesture interface implemented on a multi-core
processor. In MVA, pages 9–12.
Kato, M. and Xu, G. (2006). Occlusion-free hand mo-
tion tracking by multiple cameras and particle filter-
ing with prediction. IJCSNS International Journal of
Computer Science and Network Security, 6(10):58–
65.
Kerdvibulvech, C. and Saito, H. (2009). Model-based hand
tracking by chamfer distance and adaptive color learn-
ing using particle filter. J. Image Video Process.,
2009:2–2.
Meijster, A., Roerdink, J., and Hesselink, W. H. (2000). A
general algorithm for computing distance transforms
in linear time. In Mathematical Morphology and its
Applications to Image and Signal Processing, pages
331–340. Kluwer.
Nelder, J. A. and Mead, R. (1965). A simplex method
for function minimization. The Computer Journal,
7(4):308–313.
Ouhaddi, H. and Horain, P. (1999). 3d hand gesture tracking
by model registration. In Proc.IWSNHC3DI99, pages
70–73.
Rosales, R., Athitsos, V., Sigal, L., and Sclaroff, S. (2001).
3d hand pose reconstruction using specialized map-
pings. In ICCV, pages 378–385.
A NEW DEPTH-BASED FUNCTION FOR 3D HAND MOTION TRACKING
%p

Shimada, N., Kimura, K., and Shirai, Y. (2001). Real-
time 3-d hand posture estimation based on 2-d appear-
ance retrieval using monocular camera. In RATFG-
RTS ’01: Proceedings of the IEEE ICCV Work-
shop on Recognition, Analysis, and Tracking of Faces
and Gestures in Real-Time Systems (RATFG-RTS’01),
page 23, Washington, DC, USA. IEEE Computer So-
ciety.
Stenger, B., Mendonca, P. R. S., and Cipolla, R. (2001).
Model-based 3d tracking of an articulated hand.
In Computer Vision and Pattern Recognition, 2001.
CVPR 2001. Proceedings of the 2001 IEEE Computer
Society Conference on, volume 2, pages II–310–II–
315 vol.2.
Stenger, B., Thayananthan, A., Torr, P. H. S., and Cipolla,
R. (2006). Model-based hand tracking using a hier-
archical bayesian filter. IEEE Trans. Pattern Analysis
and Machine Intelligence(PAMI), 28(9):1372–1384.
Wang, R. Y. and Popovi
´
c, J. (2009). Real-time hand-
tracking with a color glove. In SIGGRAPH ’09: ACM
SIGGRAPH 2009 papers, pages 1–8, New York, NY,
USA. ACM.
Wu, Y., Lin, J., and Huang, T. S. (2005). Analyzing
and capturing articulated hand motion in image se-
quences. Pattern Analysis and Machine Intelligence,
IEEE Transactions on, 27(12):1910–1922.
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
%p
