
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS
An Unsupervised Feature Extraction for Document Clustering
Tomonari Masada, Yuichiro Shibata and Kiyoshi Oguri
Graduate School of Engineering, Nagasaki University, 1-14 Bunkyo-machi, Nagasaki-shi, Nagasaki, 8528521, Japan
Keywords:
Maximal substrings, Document clustering, Suffix array, Bayesian modeling.
Abstract:
This paper provides experimental results showing how we can use maximal substrings as elementary features
in document clustering. We extract maximal substrings, i.e., the substrings each giving a smaller number
of occurrences even after adding only one character at its head or tail, from the given document set and
represent each document as a bag of maximal substrings after reducing the variety of maximal substrings by
a simple frequency-based selection. This extraction can be done in an unsupervised manner. Our experiment
aims to compare bag of maximal substrings representation with bag of words representation in document
clustering. For clustering documents, we utilize Dirichlet compound multinomials, a Bayesian version of
multinomial mixtures, and measure the results by F-score. Our experiment showed that maximal substrings
were as effective as words extracted by a dictionary-based morphological analysis for Korean documents. For
Chinese documents, maximal substrings were not so effective as words extracted by a supervised segmentation
based on conditional random fields. However, one fourth of the clustering results given by bag of maximal
substrings representation achieved F-scores better than the mean F-score given by bag of words representation.
It can be said that the use of maximal substrings achieved an acceptable performance in document clustering.
1 INTRODUCTION
Recently, researchers propose a wide variety of
methods envisioning large scale data mining, where
documents originating from SNS environments or
DNA/RNA sequences providedby next generationse-
quencing are a typical target of their proposals. Many
of the methods adopt an unsupervised approach, be-
cause it is difficult to prepare a sufficient amount of
hand-maintained training data for a supervised learn-
ing when test data is of quite large scale.
This paper focuses on text mining, where we
can use various unsupervised methods, e.g. docu-
ment clustering (Nigam et al., 2000), topic extrac-
tion (Blei et al., 2003), topical trend analysis (Wang
and McCallum, 2006), etc, each based on an elabo-
rated document modeling. However, these unsuper-
vised methods assume that each document is repre-
sented as a bag of words, i.e., as an unordered col-
lection of words. Therefore, we should first extract
elementary features that can be called words.
For some languages, e.g. English, French, Ger-
man, etc, we can obtain words by a simple heuristics
called stemming. However, for many languages, e.g.
Japanese, Chinese, Korean, etc, it is far from a trivial
task to extract words. Japanese and Chinese sentences
contain no white spaces and thus give no boundaries
between the words. While Korean sentences contain
white spaces, each string separated by a white space
often consists of multiple words (Choi et al., 2009).
Many of the existing word extraction methods
require a well-maintained dictionary and/or a well-
trained data model of character sequences. Further,
such extraction methods often presuppose the avail-
ability of a sufficient amount of training data to which
supervised signals (e.g. 0/1 labels giving word bound-
aries, grammatical categories of words, etc) are as-
signed by hand. Therefore, any mining method sitting
on such supervised feature extraction methods may
show difficulty in scaling up to larger datasets even
when the mining method itself is an unsupervised one.
This paper shows how we can use maximal sub-
strings (Okanohara and Tsujii, 2009) as elementary
features of documents. One important characteristic
of maximal substrings is that they can be obtained in
a totally unsupervised manner.
In this paper, we compare bag of maximal sub-
strings representation with bag of words representa-
tion in document clustering. To be precise, we com-
pare the quality of document clusters obtained by us-
5
Masada T., Shibata Y. and Oguri K..
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS - An Unsupervised Feature Extraction for Document Clustering.
DOI: 10.5220/0003403300050013
In Proceedings of the 13th International Conference on Enterprise Information Systems (ICEIS-2011), pages 5-13
ISBN: 978-989-8425-53-9
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

ing maximal substrings as document features with the
quality of document clusters obtained by using words
as document features. We compute document clusters
by applying the same clustering method to the same
document set. In our comparison, only the document
representation is different.
As far as we know, this paper is the first one that
gives a quantitative comparison of bag of maximal
substrings representation with bag of words represen-
tation in document clustering. While Chumwatana et
al. conduct a similar experiment with respect to Thai
documents (Chumwatana et al., 2010), they fail to
give reliable evaluation, because their datasets consist
of only tens of documents. Further, they do not com-
pare bag of maximal substrings representation with
bag of words representation.
We conducted document clustering on tens of
thousands of Korean and Chinese newswire articles.
To compare with maximal substrings, we extracted
words by applying a dictionary-based morphological
analyzer (Gang, 2009) to Korean documents and by
applying a word segmenter implemented by us based
on linear conditional random fields (CRF) (Sutton and
McCallum, 2007) to Chinese documents. The former
extraction method presupposes that we have a well-
maintained dictionary, and the latter presupposes that
we have a sufficient amount of training data.
Our experiment will provide the following impor-
tant observations:
• For Korean documents, maximal substrings are
as effective as words extracted by the dictionary-
based morphological analyzer.
• For Chinese documents, maximal substrings are
not so effective as words extracted by the CRF-
based word segmenter. However, the performance
achieved with maximal substrings is acceptable.
The rest of the paper is organized as follows. Sec-
tion 2 gives previous works related to the extraction
of elementary features from documents. Section 3 de-
scribes how we use maximal substrings as elementary
features in Bayesian document clustering. Section 4
includes the procedure and the results of our evalua-
tion experiment. Section 5 concludes the paper with
discussions and future work.
2 PREVIOUS WORKS
Most text mining methods require word extraction
as a preprocessing of documents. We have a rela-
tively simple heuristics called stemming for English,
French, German, etc. However, it is far from a trivial
task to extract elementary linguistic features that can
be called words for many languages, e.g. Japanese,
Chinese, Korean, etc.
Word extraction can be conducted, for example,
by analyzing language-specific grammatical struc-
tures with a well-maintained dictionary (Gang, 2009),
or by labeling sequences with an elaborated prob-
abilistic model whose parameters are in advance
optimized with respect to hand-prepared training
data (Tseng et al., 2005). However, recent research
trends point to increasing need for large scale data
mining. Therefore, intensive use of supervised word
extraction becomes less realistic, because it is difficult
to prepare training data of sufficient size and quality.
Actually, we already have important results for
unsupervised feature extraction from documents.
Poon et al. (Poon et al., 2009) propose an unsu-
pervised word segmentation by using log-linear mod-
els, often adopted for supervised word segmentation,
in an unsupervised learning framework. However,
when computing the expected count that is required
in learning process, the authors exhaustively enumer-
ate all segmentation patterns. Consequently, this ap-
proach is only applicable to the languages whose sen-
tences are given as a sequence of short strings sepa-
rated by white spaces (e.g. Arabic and Hebrew), be-
cause the total number of segmentation patterns are
not so large for each short strings. That is, this ap-
proach will show an extreme inefficiency in execution
time for the languages whose sentences are given with
no white spaces (e.g. Chinese and Japanese).
Mochihashi et al. (Mochihashi et al., 2009) pro-
vide a sophisticated Bayesian probabilistic model for
segmenting given sentences into words in a totally un-
supervised manner. The authors improve the genera-
tive model of Teh (Teh, 2006) and utilize it for mod-
eling both character n-grams and word n-grams. The
proposed model can cope with the data containing so-
called out-of-vocabulary words, because the genera-
tive model of character n-grams serves as a new word
generator for that of word n-grams. However, highly
complicated sampling procedure, including MCMC
for the nested n-gram models and segmentation sam-
pling by an extended forward-backward algorithm,
may encounter an efficiency problem when we try to
implement this procedure, though the proposed model
is well designed enough to prevent any exhaustive
enumeration of segmentation candidates.
Okanohara et al. (Okanohara and Tsujii, 2009)
propose an unsupervised method from a completely
different angle. The authors extract maximal sub-
strings, i.e., the substrings each giving a smaller
number of occurrences even after adding only one
character at its head or tail, as elementary features.
This extraction can be efficiently implemented based
ICEIS 2011 - 13th International Conference on Enterprise Information Systems
6

on the works related to suffix array and Burrows-
Wheeler transform (Kasai et al., 2001; Abouelhoda
et al., 2002; Navarro and Makinen, 2007; Nong et al.,
2008). While Zhang et al. (Zhang and Lee, 2006) also
provide a method for extracting a special set of sub-
strings, this is not the set of maximal substrings. Fur-
ther, their method has many control parameters and
thus seems based on a more heuristic intuition when
compared with the extraction of maximal substrings.
In this paper, we adopt maximal substrings as
elementary features of documents by following the
line of Okanohara et al. and check the effective-
ness in document clustering, because both previous
works (Okanohara and Tsujii, 2009; Zhang and Lee,
2006) try to prove the effectiveness of extracted sub-
strings in document classification.
We can also find previous works using maximal-
ity of substrings for document clustering. Zhang et
al. (Zhang and Dong, 2004) present a Chinese docu-
ment clustering method by using maximal substrings
as elementary features. However, the authors give
no quantitative evaluation. Especially, maximal sub-
strings are not compared with elementary features ex-
tracted by an elaborated supervised method. While
Li et al. (Li et al., 2008) also propose a document
clustering based on the maximality of subsequences,
the authors focus not on character sequences, but on
word sequences. Further, the proposed method uti-
lizes WordNet, i.e., an external knowledge base, for
reducing the variety of maximal subsequences and
thus is not an unsupervised method.
In this paper, we would like to show what kind
of effectiveness maximal substrings can provide in
document clustering when we only use a frequency-
based selection method for reducing the variety of
substrings and use no external knowledge base.
3 DOCUMENT CLUSTERING
WITH MAXIMAL SUBSTRINGS
3.1 Extracting Maximal Substrings
Maximal substrings are defined to be a substring
whose number of occurrences is reduced even by
adding only one character to its head or tail. We dis-
cuss more formally below.
We assume that we have a string S of length l(S)
over a lexicographically ordered character set Σ. In
addition, we assume that a special character $, called
sentinel, is attached at the tail of S, i.e., S[l(S)] = $.
The sentinel $ does not appear in the given original
string and is smaller than all other characters in lexi-
cographical order.
For a pair of strings S and T over Σ, we de-
fine Pos(S,T) by Pos(S,T) ≡ {i : S[i + j − 1] =
T[ j] for j = 1,..., l(T) }, i.e., the set of all occur-
rence positions of T in S. We denote the nth small-
est element in Pos(S, T) by pos
n
(S,T). Further,
we define Rel(S,T) by Rel(S,T) ≡ {(n, pos
n
(S,T) −
pos
1
(S,T)) : n = 1,.. .,|Pos(S, T)|}. Rel(S,T) is the
set of all occurrence positions relative to the first
smallest occurrence position. Then, T is a maximal
substring of S when the following conditions hold:
1. |Pos(S,T)| > 1 ;
2. Rel(S,T) 6= Rel(S, T
′
) for any T
′
s.t. l(T
′
) =
l(T) + 1 and T[ j] = T
′
[ j], j = 1,... ,l(T) ; and
3. Rel(S,T) 6= Rel(S, T
′
) for any T
′
s.t. l(T
′
) =
l(T) + 1 and T[ j] = T
′
[ j + 1], j = 1,. .., l(T) .
The last condition corresponds to “left expansion”
discussed by Okanohara et al. (Okanohara and Tsu-
jii, 2009).
When we extract maximal substrings from a doc-
ument set, we first concatenate all documents by in-
serting a special character, which does not appear in
the given document set, between the documents. The
concatenation order is irrelevant to our discussion.
We put a sentinel at the tail of the resulting string and
obtain a string S from which we extract maximal sub-
strings. We can efficiently extract all maximal sub-
strings from S in time proportional to l(S) (Okanohara
and Tsujii, 2009).
The number of different maximal substrings is in
general far larger than that of different words obtained
by morphological analysis or by word segmentation.
Therefore, we remove maximal substrings containing
special characters put between the documents. Fur-
ther, when the target language provides its sentences
with white spaces, delimiters (e.g. comma, period,
question mark, etc), and other functional characters
(e.g. parentheses, hyphen, center dot, etc), we remove
maximal substrings containing such characters.
Even after the above reduction, we still have a
large number of different maximal substrings. There-
fore, we propose a simple frequency-based strategy
for reducing the variety of maximal substrings. We
only use the following two parameters: the lowest and
the highest frequencies of maximal substrings.
To be precise, we remove all maximal substrings
whose frequencies are less than the threshold n
L
and
also remove all maximal substrings whose frequen-
cies are more than the threshold n
H
. We directly spec-
ify n
L
as 10, 20, 50, etc. On the other hand, we specify
n
H
through the equation n
H
= c
H
×n
1
, where n
1
is the
frequencyof the most frequent maximal substring and
c
H
is a real value. We feel difficulty in specifying n
H
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS - An Unsupervised Feature Extraction for Document
Clustering
7

100
1,000
10,000
100,000
m
aximal substrings
1
10
1 10 100 1,000 10,000 100,000 1,000,000
#
m
maximal substring frequency
100
1,000
10,000
100,000
m
aximal substrings
1
10
1 10 100 1,000 10,000 100,000 1,000,000
#
m
maximal substring frequency
Figure 1: Plot of the number of maximal substrings for each
different frequency. The top panel (resp. bottom panel)
shows the statistics of maximal substrings extracted from
Korean (resp. Chinese) newswire articles used in our evalu-
ation experiment. For example, when we have 800 different
maximal substrings each occurring 100 times in the docu-
ment set, a marker is placed at (100,800) in the chart.
directly, because the choice of n
H
heavily depends on
the size of the dataset. However, it can be regarded
that n
1
scales with the size of the dataset. Therefore,
we specify n
H
by multiplying a factor c
H
to n
1
.
Figure 1 shows how many different maximal sub-
strings we have at each frequency for the two datasets
used in our experiment. The top panel gives the statis-
tics of maximal substrings for the Korean newswire
article set, and the bottom panel gives the statistics
for the Chinese article set. The horizontal axis rep-
resents the frequency of maximal substrings, and the
vertical axis represents the number of different maxi-
mal substrings having the same frequency. For exam-
ple, when we have 800 different maximal substrings
each occurring at 100 positions in the document set, a
marker is placed at (100,800) in the chart. The data
plot range starts from five on the horizontal axis, be-
cause the maximal substrings of frequency less than
five were noisy strings and were thus removed. We
can observe that the distribution of the number of dif-
ferent maximal substrings roughly follows Zipf’s law.
The two shaded areas of each chart in Figure 1
show the frequency intervals where the correspond-
ing maximal substrings are removed by our selection
method. In other words, the unshaded area of each
chart ranges from n
L
to n
H
on the horizontal axis and
thus shows the frequency interval where the corre-
sponding maximal substrings are used in document
clustering. Figure 1 displays the frequency interval
giving the best evaluation result for each dataset. For
the chart in the top panel, n
L
is set to 100 and n
H
to
97,879, where n
H
is determined by setting c
H
to 0.1
with respect to n
1
= 978,789. For the chart in the
bottom panel, n
L
is set to 20 and n
H
to 53,051, where
n
H
is determined by setting c
H
to 0.2 with respect to
n
1
= 265,254. Each setting gave the best result as we
will discuss in Section 4.
3.2 Bayesian Document Clustering
When documents are represented as a bag of elemen-
tary features, multinomial distribution (Nigam et al.,
2000) is a natural choice for document modeling, be-
cause we can represent each document as a frequency
histogram of elementary features.
However, it is often discussed from a Bayesian
view point that multinomial distributions are likely
to overfit to sparse data. The term “sparse” means
that the number of differentfeatures appearing in each
document is far less than the total number of differ-
ent features observable in the entire document set.
This tendency becomes more apparent when we use
maximal substrings as document features, because the
number of maximal substrings extracted from a docu-
ment set is in general far larger than that of words ex-
tracted by an elaborated word segmentation method.
Therefore, we use Dirichlet compound multino-
mials (DCM) (Madsen et al., 2005) as our document
model to avoid overfitting. We assume that the num-
ber of clusters is K. DCM has K multinomial distribu-
tions, each of which models a word frequency distri-
bution for a different document cluster. Further, DCM
applies a Dirichlet prior distribution to each of the K
multinomials. DCM can effectively avoid overfitting
with these K Dirichlet prior distributions.
Here we prepare notations for discussions. We as-
sume that the given document set contains J docu-
ments and that W different words (or maximal sub-
strings) can be observed in the document set. Let
c
jw
be the number of occurrences of the wth word
(or maximal substring) in the jth document. Let α
kw
,
k = 1,... ,K, w = 1,... ,W be the hyperparameters of
the Dirichlet priors. The posterior probability that the
jth document belongs to the kth cluster is denoted by
p
jk
. Note that
∑
k
p
jk
= 1. We define α
k
≡
∑
w
α
kw
and
c
j
≡
∑
w
c
jw
.
ICEIS 2011 - 13th International Conference on Enterprise Information Systems
8

We update cluster assignment probabilities and
hyperparameters of Dirichlet priors with the EM al-
gorithm described below.
E step: Update p
jk
by
p
jk
←
∑
j
p
jk
∑
j
∑
k
p
jk
·
Γ(α
k
)
Γ(c
j
+ α
k
)
∏
w
Γ(c
jw
+ α
kw
)
Γ(α
kw
)
and then normalize p
jk
by p
jk
← p
jk
/
∑
k
p
jk
.
M step: Update α
kw
by
α
kw
← α
kw
·
∑
j
p
jk
{Ψ(c
jw
+ α
kw
) − Ψ(α
kw
)}
∑
j
p
jk
{Ψ(c
j
+ α
k
) − Ψ(α
k
)}
where Γ(·) is gamma function, and Ψ(·) is digamma
function. The update formula for α
kw
is based on
Minka’s discussion (Minka, 2000). We terminate the
iteration of E and M steps when the log likelihood in-
creases by less than 0.001%.
Before entering into the loop of E and M steps,
we initialize α
jk
to 1, because this makes Dirichlet
priors uniform distributions. Further, we initialize p
jk
not randomly but by the EM algorithm for multino-
mial mixtures (Nigam et al., 2000). In the EM for
multinomial mixtures, we use a random initialization
for p
jk
. The execution of EM for multinomial mix-
tures is repeated 30 times each from a random ini-
tialization. Each of the 30 executions of the EM for
multinomial mixtures gives a different estimation of
p
jk
. Therefore, we choose the estimation giving the
largest likelihood as the initial setting of p
jk
in the EM
algorithm for DCM. We conduct this entire procedure
three times. Then, among the three clustering results,
we select the result giving the largest likelihood as the
final output of our document clustering.
The time complexity of our EM algorithm is
O(IKM), where I is the number of iterations and M is
the number of different pairs of document and word.
In general, M is far smaller than J × W due to the
sparseness discussed above.
4 EVALUATION EXPERIMENT
4.1 Procedure
The following two document sets were used in our
evaluation experiment:
• The one is the set of Korean newswire articles
downloaded from the Web site of Seoul Newspa-
per
1
. We denote this dataset as SEOUL. This set
consists of 52,730 articles whose dates range from
1
http://www.seoul.co.kr/
January 1st, 2008 to September 30th, 2009. Each
article belongs to one among the following four
categories: Economy, Local issues, Politics, and
Sports. Therefore, we set K = 4 in DCM.
• The other is the set of Chinese newswire articles
dowloaded from Xinhua Net
2
. We denote this
dataset as XINHUA. This set consists of 20,127
articles whose dates range from May 8th to De-
cember 17th in 2009. All articles are written in
simplified Chinese. Each article belongs to one
among the three categories: Economy, Interna-
tional, and Politics. Therefore, we set K = 3.
We regarded article categories as the ground truth
when we evaluated document clusters.
To compare with maximal substrings, we ex-
tracted words by applying KLT morphological ana-
lyzer (Gang, 2009) to Korean articles. On the other
hand, we applied a word segmenter, implemented by
using L1-regularized linear conditional random fields
(CRF) (Sutton and McCallum, 2007), to Chinese ar-
ticles. Our algorithm for parameter optimization in
training this Chinese word segmenter is based on
stochastic gradient descent algorithm with exponen-
tial decay scheduling (Tsuruoka et al., 2009). This
segmenter achieved the following F-scores for the
four datasets of SIGHAN Bakeoff 2005 (Tseng et al.,
2005): 0.943 (AS), 0.941 (HK), 0.929 (PK) and
0.960 (MSR). In our experiment, we used the seg-
menter trained with MSR dataset, because this dataset
gave the highest F-score. For Korean language, we
could not find any training data comparable with the
SIGHAN training data in its size and quality. There-
fore, we used KLT for Korean word segmentation.
The wall clock time required for extracting all
maximal substrings was only a few minutes for both
datasets on a PC equipped with Intel Core 2 Quad
9650 CPU. This wall clock time is comparable with
the time required for word extraction by our Chinese
segmenter, though the time required for training the
segmenter is not included. Further, it is much less
than the time required for Korean morphologicalanal-
ysis, because KLT achieves its excellence by dictio-
nary lookups. While KLT can provide part-of-speech
tags, they are not required for our experiment.
The running time of document clustering is pro-
portional to M, i.e., the number of different pairs
of document and word (or of document and maxi-
mal substring). When we extracted words by KLT
morphological analyzer from SEOUL dataset, M was
equal to 8,208,591 after removing the words whose
frequencies are less than five. When we used max-
imal substrings, M was 37,079,130 after removing
2
http://www.xinhuanet.com/
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS - An Unsupervised Feature Extraction for Document
Clustering
9

the maximal substrings whose frequencies are less
than five. Further, when we extracted words by the
CRF-based segmenter from XINHUA dataset, M was
3,244,859 after removing the words whose frequen-
cies are less than five. When we used maximal sub-
strings, M was 17,561,135 after removing the maxi-
mal substrings whose frequencies are less than five.
We evaluated the quality of clusters as follows:
1. We calculated precision and recall for each clus-
ter. Precision is defined as
#(true positive)
#(true positive) + #(false positive)
,
and recall is defined as
#(true positive)
#(true positive) + #(false negative)
,
where “#” means the number;
2. We calculated F-score as the harmonic mean of
precision and recall for each cluster; and
3. The F-score was averaged over all clusters.
We used the resulting averaged F-score as our evalu-
ation measure.
We executed document clustering 64 times for
each setting of n
L
and n
H
. Consequently, we obtained
64 F-scores for each setting. The effectivenessof each
setting of n
L
and n
H
was represented by the mean and
the standard deviation of these 64 F-scores.
We reduced the variety of maximal substrings as
follows. We removed the maximal substrings whose
frequency was less than n
L
. We tested the following
six settings for n
L
: 10, 20, 50, 100, 200, and 500. We
present the evaluation result for each setting of n
L
in
Table 1, where the mean and the standard deviation
are computed over the 64 F-scores for each case.
With respect to the best setting of n
L
, we tested
the following five settings for c
H
to specify n
H
: 0.2,
0.1, 0.05, 0.02, and 0.01. For example, when c
H
was
set to 0.02, n
H
was set to 0.02n
1
. The result for each
setting of c
H
is given in Table 2 also with the mean
and the corresponding standard deviation.
The same reduction method was applied not only
to maximal substrings but also to words extracted by
the morphological analyzer from SEOUL dataset and
to words extracted by our segmenter from XINHUA
dataset. The evaluation results for these supervised
word extraction methods are also given in Table 1 and
Table 2.
4.2 Analysis of Results
We can analyze the results presented in Table 1 and
Table 2 as follows.
In Table 1, the top panel gives the results for
SEOUL dataset, and the bottom panel for XINHUA
dataset. The column labeled as “n
L
” includes the set-
tings for n
L
, and the column labeled as “# words” in-
cludes the numbers of words or the numbers of maxi-
mal substrings after removing low frequency features.
We regard the boldfaced cases as the best setting for
n
L
, because each of these cases leads to the F-score
larger than the other settings. We can obtain the fol-
lowing observations from Table 1:
• For SEOUL dataset, the F-scores achieved with
maximal substrings were quite close to those
achieved with words extracted by the morpholog-
ical analyzer. It can be said that the results prove
the effectiveness of maximal substrings.
• For XINHUA dataset, maximal substrings gave
weaker results than words obtained by the CRF-
based segmenter. Further, bag of maximal sub-
strings representation led to larger standard devia-
tions of F-scores. These large standard deviations
suggest that there is a room for improvement re-
garding with selection of maximal substrings or
with clustering method so as to utilize maximal
substrings more effectively.
• By removing more low frequency words or max-
imal substrings, a smaller standard deviation was
achieved. A large standard deviation means that
the quality of document clusters is quite different
trial by trial. Therefore, it is desirable to reduce as
many low frequency words as possible. However,
the reductionof too many lowfrequency words re-
sulted in a large drop of F-scores. Table 1 shows
that the range n
L
≤ 200 is recommended.
• We may expect that low frequency words will be
sharply related to a specific topic and thus will
have a discriminative power. However, in our
case, by using more low frequency words, we ob-
tained larger standard deviations. This may tell
that most low frequency words misled clustering
process maybe by occasionally focusing on a mi-
nor aspect of the document content.
We further check if we can achieve an improve-
ment by reducing also high frequency features. Es-
pecially for XINHUA dataset, we could not obtain
any good F-scores only with the reduction of low fre-
quency maximal substrings. Therefore, we next dis-
cuss about the results presented in Table 2.
In Table 2, the top panel gives the results for
SEOUL dataset, and the bottom panel for XINHUA
dataset. Each of the boldfaced cases corresponds to
the best F-score among the various settings of c
H
.
For ease of comparison, Table 2 also presents the best
cases from Table 1 in the rows that have the value 1.0
ICEIS 2011 - 13th International Conference on Enterprise Information Systems
10
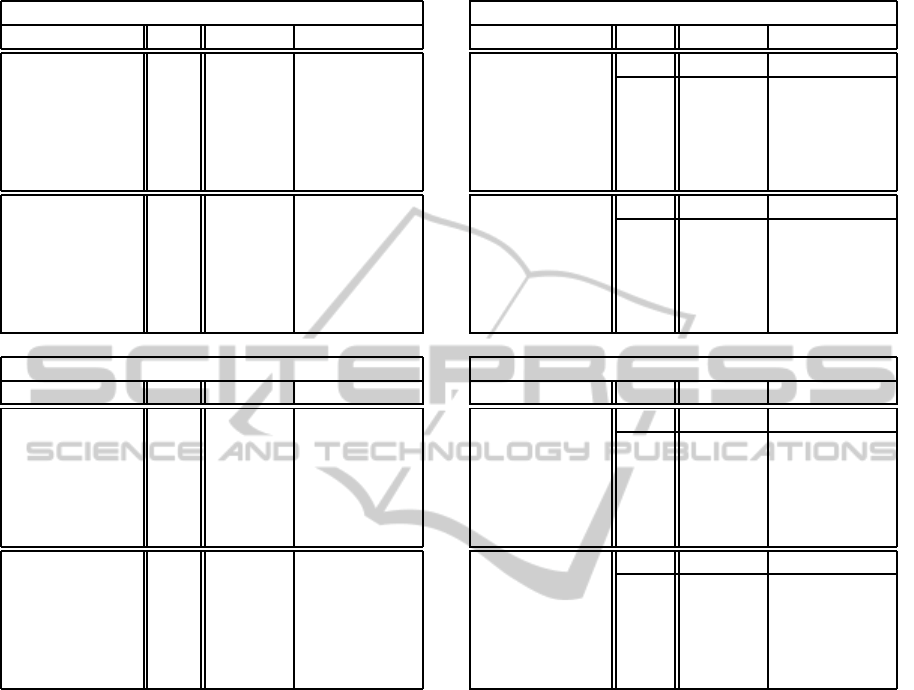
Table 1: Evaluation of clusters obtained after removing only
low frequency features.
SEOUL (52,730 docs, 4 clusters)
n
L
# words F-score
10 186,032 0.826±0.049
20 126,619 0.854±0.036
Maximal 50 72,104 0.867±0.029
Substrings 100 45,360 0.872±0.004
200 26,923 0.869±0.002
500 12,590 0.856±0.001
10 61,416 0.859±0.043
20 37,800 0.883±0.025
Morphological 50 20,068 0.892±0.002
Analysis 100 12,411 0.890±0.001
200 7,620 0.886±0.000
500 3,798 0.879±0.002
XINHUA (20,127 docs, 3 clusters)
n
L
# words F-score
10 285,438 0.650±0.051
20 140,690 0.690±0.051
Maximal 50 53,239 0.672±0.039
Substrings 100 25,344 0.649±0.014
200 12,351 0.642±0.002
500 5,049 0.619±0.002
10 23,234 0.753±0.021
20 15,347 0.750±0.021
Word 50 8,783 0.755±0.012
Segmentation 100 5,709 0.760±0.007
200 3,596 0.762±0.007
500 1,752 0.741±0.011
at the column labeled as c
H
. The case c
H
= 1.0 corre-
sponds to the case where we reduce no high frequency
features, i.e., the case considered in Table 1.
Table 2 provides the following observations:
• For bag of words representation, the reduction of
high frequency features did not lead to any im-
provement on both SEOUL dataset and XINHUA
dataset. The reduction of high frequency features
just worked as a reduction of working space for
document clustering.
• For bag of maximal substrings representation, the
reduction of high frequency features led to a small
improvement. However,the improvementwas not
statistically significant. Therefore, also for max-
imal substrings, the reduction only worked as a
reduction of working space. Of course, the same
observation can be restated as follows: we could
reduce the number of elementary features without
harming cluster quality.
Table 2: Evaluation of clusters obtained after removing both
high and low frequency features.
SEOUL (52,730 docs, 4 clusters)
c
H
# words F-score
1.0 45,360 0.872±0.004
Maximal 0.2 45,320 0.873±0.008
Substrings 0.1 45,260 0.875±0.007
(n
L
= 100) 0.05 45,159 0.875±0.008
0.02 44,918 0.873±0.011
0.01 44,589 0.874±0.011
1.0 20,068 0.892±0.002
Morphological 0.2 20,056 0.890±0.007
Analysis 0.1 20,040 0.890±0.008
(n
L
= 50) 0.05 19,975 0.888±0.009
0.02 19,721 0.887±0.009
0.01 19,179 0.887±0.009
XINHUA (20,127 docs, 3 clusters)
c
H
# words F-score
1.0 140,690 0.690±0.051
Maximal 0.2 140,672 0.701±0.059
Substrings 0.1 140,611 0.693±0.056
(n
L
= 20) 0.05 140,466 0.696±0.051
0.02 140,069 0.685±0.051
0.01 139,515 0.698±0.047
1.0 3,596 0.762±0.007
Word 0.2 3,593 0.762±0.001
Segmentation 0.1 3,587 0.762±0.001
(n
L
= 200) 0.05 3,559 0.762±0.001
0.02 3,468 0.718±0.000
0.01 3,261 0.754±0.001
• For XINHUA dataset, even after the reduction
of high frequency features, bag of maximal sub-
strings representation provided weaker results
than bag of words representation. This means that
we should use a supervised segmenter for Chinese
documents as long as we can prepare a sufficient
amount of training data.
We can conclude that maximal substrings are
as effective as words extracted by the dictionary-
based morphological analysis for Korean documents.
This may be partly because Korean sentences con-
tain white spaces and thus maximal substring extrac-
tion works as a fine improvement of this intrinsic seg-
mentation. In contrast, for Chinese documents, we
need some more sophistication to make maximal sub-
strings equally effective.
However, we think that the difference of effective-
ness between bag of words representation and bag of
maximal substrings representation is not so large to
make the latter inapplicable in document clustering.
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS - An Unsupervised Feature Extraction for Document
Clustering
11
2
3
4
5
6
7
8
9
# results
(64 results in total)
0
1
2
0.57
0.58
0.59
0.60
0.61
0.62
0.63
0.64
0.65
0.66
0.67
0.68
0.69
0.70
0.71
0.72
0.73
0.74
0.75
0.76
0.77
0.78
# results
F-score
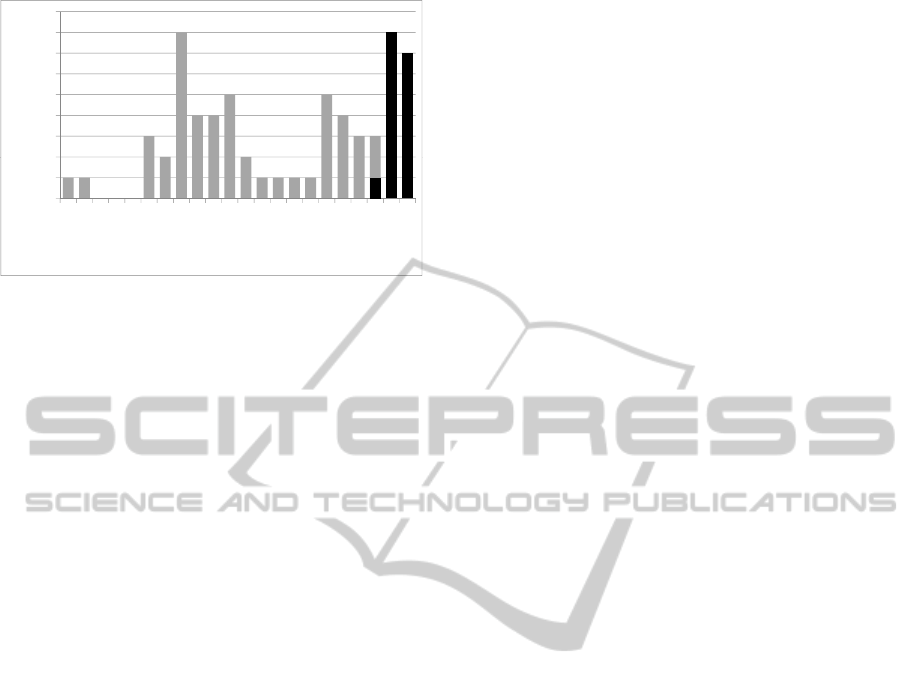
Figure 2: Distribution of F-scores achieved with maximal
substrings for XINHUA dataset. This histogram shows the
64 F-scores obtained by setting n
L
= 20 and c
H
= 0.2. F-
scores are rounded off to two decimal places. While the
mean of all 64 F-scores is 0.701, we have 16 F-scores (black
part of the histogram) that are larger than the best mean F-
score 0.762 achieved with CRF-based word segmentation
(cf. the bottom panel in Table 2).
Even with respect to XINHUA dataset, the cluster
quality obtained with bag of maximal substrings rep-
resentation is acceptable, as we discuss below.
When we set n
L
= 200, c
H
= 0.2 and reduce the
variety of words extracted by our CRF-based seg-
menter from XINHUA dataset, the best mean F-score
0.762 was achieved (cf. Table 2). However, when we
set n
L
= 20 and c
H
= 0.2 and reduce the variety of
maximal substrings, we could obtain F-scores larger
than 0.762 for 16 clustering results among all 64 clus-
tering results. That is, 25% of the clustering results
showed a quality better than the mean quality of doc-
ument clusters bag of words representation gave.
Figure 2 presents the detailed distribution of the F-
scores achieved with bag of maximal substrings repre-
sentation when we set n
L
= 20 and c
H
= 0.2 for XIN-
HUA dataset. In this histogram, F-scores are rounded
off to two decimal places. The black part of the his-
togram correspondsto the 16 F-scores that were larger
than the best mean F-score 0.762 achieved with bag of
words representation.
In addition, for the case where we achieved the
best mean F-score 0.762 with bag of words rep-
resentation, all 64 F-scores fell within the interval
[0.755, 0.765). Further, the best three F-scores were
0.764, 0.764, and 0.763. In contrast, the best three F-
scores were 0.782, 0.781, and 0.780 when we used
maximal substrings as elementary features and set
n
L
= 20, c
H
= 0.2.
Therefore, it is a promising work to introduce
some sophistication into selection of maximal sub-
strings and also into document clustering so as not to
occasionally give extremely poor clustering results.
5 CONCLUSIONS
As text data originating from SNS environmentscome
to show a wider divergence in the writing style or in
the used vocabularies, unsupervised extraction of el-
ementary features becomes more important as a pre-
processing for various text mining techniques than be-
fore. Therefore, in this paper, we provide experimen-
tal results where we compare bag of maximal sub-
strings representation with bag of words representa-
tion, because maximal substrings can be extracted in
a totally unsupervised manner.
Our results showed that maximal substrings were
not equally effective with words extracted by the elab-
orated supervised method for Chinese documents,
though we could obtain impressive results for Korean
documents. We need a more sophisticated selection
method to obtain a special subset of maximal sub-
strings for Chinese documents. We should also im-
prove document model for clustering to capture fre-
quency statistics of maximal substrings more cleverly
than DCM. We think that these future works are wor-
thy to do based on the reason discussed in the late part
of the previous section.
Further, if we use larger datasets, we can expect
that more reliable statistics of maximal substrings will
be obtained and thus that more convincing evaluation
results will be provided. It is an important future work
to acquire a more realistic insight with respect to the
trade-off between the following two types of cost:
• the cost to improve the effectiveness of maxi-
mal substrings with a more elaborated selection
method and/or with a more elaborated clustering
method; and
• the cost to prepare training data for supervised
feature extraction and then to train a segmentation
model by using the data.
We also have a plan to conduct experiments where
we use maximal substrings as elementary features for
a multi-topic analysis based on latent Dirichlet alloca-
tion (Blei et al., 2003) for text data or for DNA/RNA
sequence data (Chen et al., 2010).
ACKNOWLEDGEMENTS
This work was supported in part by Japan Society
for the Promotion of Science (JSPS) Grant-in-Aid
for Young Scientists (B) 60413928 and also by Na-
gasaki University Strategy for Fostering Young Scien-
tists with funding provided by Special Coordination
Funds for Promoting Science and Technology of the
ICEIS 2011 - 13th International Conference on Enterprise Information Systems
12

Ministry of Education, Culture, Sports, Science and
Technology (MEXT).
REFERENCES
Abouelhoda, M., Ohlebusch, E., and Kurtz, S. (2002). Op-
timal exact string matching based on suffix arrays.
In SPIRE’02, the Ninth International Symposium on
String Processing and Information Retrieval, pages
31–43.
Blei, D., Ng, A., and Jordan, M. (2003). Latent Dirichlet
allocation. Journal of Machine Learning Research,
3:993–1022.
Chen, X., Hu, X., Shen, X., and Rosen, G. (2010). Prob-
abilistic topic modeling for genomic data interpreta-
tion. In BIBM’10, IEEE International Conference on
Bioinformatics & Biomedicine, pages 18–21.
Choi, K., Isahara, H., Kanzaki, K., Kim, H., Pak, S., and
Sun, M. (2009). Word segmentation standard in Chi-
nese, Japanese and Korean. In the 7th Workshop on
Asian Language Resources, pages 179–186.
Chumwatana, T., Wong, K., and Xie, H. (2010). A SOM-
based document clustering using frequent max sub-
strings for non-segmented texts. Journal of Intelligent
Learning Systems & Applications, 2:117–125.
Gang, S. (2009). Korean morphological analyzer KLT ver-
sion 2.10b. http://nlp.kookmin.ac.kr/HAM/kor/.
Kasai, T., Lee, G., Arimura, H., Arikawa, S., and Park, K.
(2001). Linear-time longest-common-prefix computa-
tion in suffix arrays and its applications. In CPM’01,
the 12th Annual Symposium on Combinatorial Pattern
Matching, pages 181–192.
Li, Y., Chung, S., and Holt, J. (2008). Text document
clustering based on frequent word meaning sequences.
Data & Knowledge Engineering, 64:381–404.
Madsen, R., Kauchak, D., and Elkan, C. (2005). Model-
ing word burstiness using the Dirichlet distribution. In
ICML’05, the 22nd International Conference on Ma-
chine Learning, pages 545–552.
Minka, T. (2000). Estimating a Dirichlet dis-
tribution. http://research.microsoft.com/en-
us/um/people/minka/papers/dirichlet/.
Mochihashi, D., Yamada, T., and Ueda, N. (2009). Bayesian
unsupervised word segmentation with nested Pitman-
Yor language modeling. In ACL/IJCNLP’09, Joint
Conference of the 47th Annual Meeting of the Asso-
ciation for Computational Linguistics and the Fourth
International Joint Conference on Natural Language
Processing of the Asian Federation of Natural Lan-
guage Processing, pages 100–108.
Navarro, G. and Makinen, V. (2007). Compressed full-text
indexes. ACM Computing Surveys (CSUR), 39(1).
Nigam, K., McCallum, A., Thrun, S., and Mitchell, T.
(2000). Text classification from labeled and un-
labeled documents using EM. Machine Learning,
39(2/3):103–134.
Nong, G., Zhang, S., and Chan, W. (2008). Two efficient
algorithms for linear time suffix array construction.
http://doi.ieeecomputersociety.org/10.1109/TC.2010.188.
Okanohara, D. and Tsujii, J. (2009). Text categorization
with all substring features. In SDM’09, 2009 SIAM
International Conference on Data Mining, pages 838–
846.
Poon, H., Cherry, C., and Toutanova, K. (2009). Unsu-
pervised morphological segmentation with log-linear
models. In NAACL/HLT’09, North American Chapter
of the Association for Computational Linguistics - Hu-
man Language Technologies 2009 Conference, pages
209–217.
Sutton, C. and McCallum, A. (2007). An introduction to
conditional random fields for relational learning. In
Introduction to Statistical Relational Learning, pages
93–128.
Teh, Y. (2006). A hierarchical Bayesian language model
based on Pitman-Yor processes. In COLING/ACL’06,
Joint Conference of the International Committee on
Computational Linguistics and the Association for
Computational Linguistics, pages 985–992.
Tseng, H., Chang, P., Andrew, G., Jurafsky, D., and Man-
ning, C. (2005). A conditional random field word
segmenter for SIGHAN bakeoff 2005. In the Fourth
SIGHAN Workshop, pages 168–171.
Tsuruoka, Y., Tsujii, J., and Ananiadou, S. (2009). Stochas-
tic gradient descent training for L1-regularized
log-linear models with cumulative penalty. In
ACL/IJCNLP’09, Joint Conference of the 47th Annual
Meeting of the Association for Computational Lin-
guistics and the fourth International Joint Conference
on Natural Language Processing of the Asian Federa-
tion of Natural Language Processing, pages 477–485.
Wang, X. and McCallum, A. (2006). Topics over time: a
non-Markov continuous-time model of topical trends.
In KDD’06, the 12th ACM SIGKDD International
Conference on Knowledge Discovery and Data Min-
ing, pages 424–433.
Zhang, D. and Dong, Y. (2004). Semantic, hierarchical,
online clustering of Web search results. In APWeb’04,
the Sixth Asia Pacific Web Conference, pages 69–78.
Zhang, D. and Lee, W. (2006). Extracting key-substring-
group features for text classification. In KDD’06, the
Twelfth ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, pages 474–
483.
DOCUMENTS AS A BAG OF MAXIMAL SUBSTRINGS - An Unsupervised Feature Extraction for Document
Clustering
13
