
VISUAL AER-BASED PROCESSING WITH CONVOLUTIONS
FOR A PARALLEL SUPERCOMPUTER
Rafael J. Montero-Gonzalez, Arturo Morgado-Estevez, Fernando Perez-Peña
Applied Robotics Research Lab, Engineering School, University of Cadiz, C/Chile 1, 11002, Cadiz, Spain
Alejandro Linares-Barranco, Angel Jimenez-Fernandez
Robotic and Technology of Computers Lab, University of Sevilla, Av. Reina Mercedes s/n, 41012, Seville, Spain
Bernabe Linares-Barranco, Jose Antonio Perez-Carrasco
Institute of Microelectronics of Seville, IMSE-CNM-CSIC
Av. de los Descubrimientos, Pabellón Pza. de América, 41092, Seville, Spain
Keywords: AER, Convolution, Parallel processing, Cluster, Supercomputer, Bio-inspired, AER simulator.
Abstract: This paper is based on the simulation of a convolution model for multimedia applications using the neuro-
inspired Address-Event-Representation (AER) philosophy. AER is a communication mechanism between
chips gathering thousands of spiking neurons. These spiking neurons are able to process the visual
information in a frame-free style like the human brain do. All the spiking neurons are working in parallel
and each of them implement an operation when an input stimulus is received. The result of this operation
could be, or not, to produce an output event. There exist AER retinas and other sensors, AER processors
(convolvers, WTA filters), learning chips and robot actuators. In this paper we present the implementation
of an AER convolution processor for the supercomputer CRS (cluster research support) of the University of
Cadiz (UCA). This research involves a test cases design in which the optimal parameters are set to run the
AER convolution in parallel processors. These cases consist on running the convolution taking an image
divided in different number of parts, applying to each part a Sobel filter for edge detection, and based on the
AER-TOOL simulator. Runtimes are compared for all cases and the optimal configuration of the system is
discussed. In general, CRS obtain better performances when the image is subdivided than for the whole
image processing.
1 INTRODUCTION
Nowadays, multimedia systems seek to solve
problems more efficiently. The processing speed in
solving these problems becomes critical. Images and
video sequences are increasing the data volume so
high and fast that new algorithms are needed for
more efficient processing. Hardware
implementations are a solution to meet the
expectations of even the most demanding users.
Address-Event-Representation systems are
composed of sets of cells typically distributed in a
matrix that process the information spike by spike in
a continuous way. The information or results of each
cell is sent in a time multiplexed strategy using a
digital bus, indicating which position is producing
the event.
If we represent a black and white image as an
array of cells where each pixel value is in gray scale,
the white level would correspond to a frequency
value determined by allocating the largest amplitude
values, higher brightness values. The signal caused
by each pixel is transformed into a train of pulses
using PFM (pulse frequency modulation) showed by
Serrano-Gotarredona and Linares-Barranco (1999).
Based on the interconnection of neurons present
on human vision, the continuous state of
transmission in a chip is transformed into a sequence
of digital pulses (spikes) of a minimum size (in the
85
Montero-Gonzalez R., Morgado-Estevez A., Perez-Peña F., Linares-Barranco A., Jimenez-Fernandez A., Linares-Barranco B. and Perez-Carrasco J..
VISUAL AER-BASED PROCESSING WITH CONVOLUTIONS FOR A PARALLEL SUPERCOMPUTER.
DOI: 10.5220/0003519100850090
In Proceedings of the International Conference on Signal Processing and Multimedia Applications (SIGMAP-2011), pages 85-90
ISBN: 978-989-8425-72-0
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

order of ns) but with an interval between spikes of
the order of hundreds of microseconds (us) or even
milliseconds (ms). This interval allows time
multiplexing of all the pulses generated by neurons
into a common digital bus. Each neuron is identified
with an address related to its position into the array.
Every time a neuron emits a pulse, its address will
appear in the output bus, along with a request signal,
until acknowledge is received (handshake protocol).
The receiver chip reads and decodes the direction of
incoming events and issues pulses for the receiving
neurons.
One of the operations performed by AER
systems, applied to artificial vision and multimedia
systems, is the convolution. The first operation in
the brain cortex consists of convolution for object
edges detection, based on calculations of brightness
gradients. In the design presented by Camunas-
Mesa, Acosta-Jimenez, Serrano-Gotarredona and
Linares-Barranco (2008), a system is described
where a single convolution processor performs all
operations for the whole image.
Based on this idea, and the divide and conquer
premise presented in Montero-Gonzalez, Morgado-
Estevez, Linares-Barranco, et al. (2011), this paper
is arguing that the division of the image into smaller
parts before AER convolution processing in parallel
will reduce the runtime. With this new design a
convolution could be proposed where a
multiprocessor system may perform operations in
less time.
2 METHODOLOGY AND TEST
CASES
The process of experimentation is to verify, through
an exhaustive analysis, which would be the different
runtimes of the convolution of an image. Each
runtime will correspond to different divisions. All
division convolutions are performed in parallel,
instead of performing the convolution of the whole
image.
We have used the Cluster of Research Support
(CRS), part of the infrastructure of the UCA, for
improving Runtimes of the simulation tool AER
TOOL. In order to run this simulator on CRS we
propose a new simulation model parameterized and
adapted to running tests in parallel processors.
2.1 Supercomputer CRS (Cluster of
Research Support)
The CRS is composed of 80 nodes. Each node has 2
Intel Xeon 5160 processors at 3 GHz with 1.33GHz
Front Side Bus. Each processor is Dual Core, so we
have 320 cores available. A total of 640GB of RAM
memory, 2.4TB of scratch and Gigabit Ethernet
communication architecture with HP Procurve
switches allow to obtain a peak performance of 3.75
TFLOPS, information extracted from Technical
support in supercomputing, University of Cadiz,
http://supercomputacion.uca.es/.
In terms of software features, to manage
distributed work, Condor tool is used. Condor is a
job manager system that specializes in calculation-
intensive tasks. The coding for the simulation was
done using MATLAB and AER TOOL simulator for
MATLAB described by Perez-Carrasco, Serrano-
Gotarredona and Acha-Piñero (2009).
Developing this set of tests on a real physical
implementation would be highly expensive. The
supercomputer CRS provides the possibility of an
AER simulation model implementation in parallel
with acceptable runtimes, using the software
installed and existing libraries.
2.2 Test Image and Successive
Divisions
For this simulation we have designed an image in
Adobe Photoshop CS, using gray scale, where the
pixel having the darkest value will have a value
close to 0 and the brightest will be close to 255. The
GIF image size is 128x128 pixel of 256 gray levels.
The idea of dividing the original image and
perform parallel convolution arises from trying to
take advantage of distributed processing systems to
expedite the process. This involves running a series
of tests with different numbers of divisions.
Firstly, we have obtained the process runtimes of
the convolution of the original image without
divisions. Secondly the image has been divided into
4 parts (64x64 pixel each), performing the
convolution in a different processor. Then, the
sequence has been repeated by 16 divisions (32x32
pixel each). Next, using 256 divisions (8x8 pixel
each), and finally we have concluded with 1024
divisions (4x4 pixel each). Conceptually, the
operation would be as shown in Figure 1.
2.3 Topology Diagram Implementation
For this research, parametric model simulation
software has been developed, whose test cases are
specified by variable assignment.
Once the simulation variables are set, the system
runs following the block diagram shown in Figure 2.
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
86
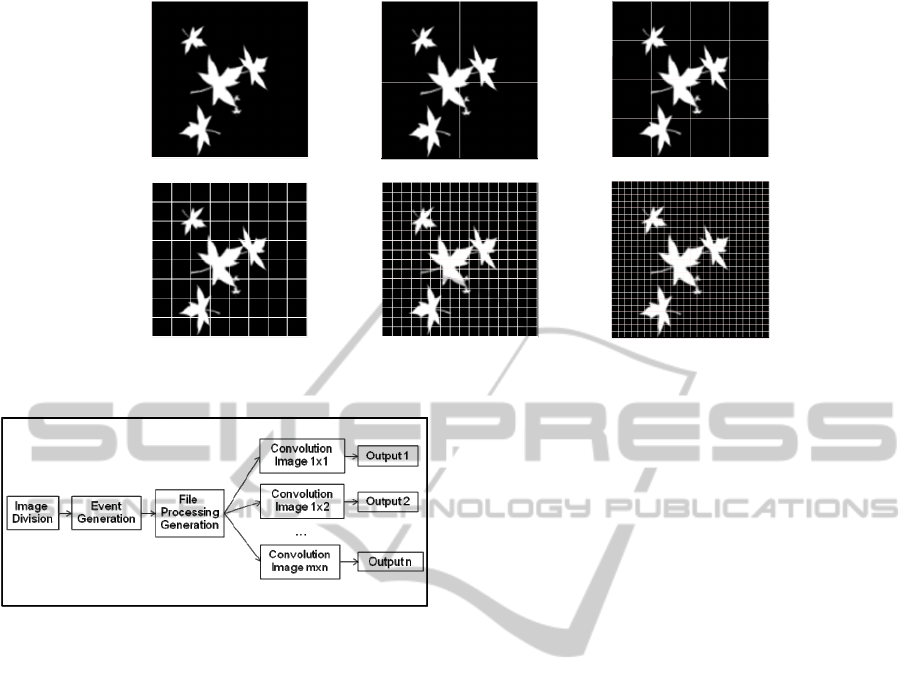
1 Division
4 Divisions
16 Divisions
64 Divisions
256 Divisions
1024 Divisions
Figure 1: Divisions of the original image to simulate.
Figure 2: Simulation block diagram.
First, the division of the image is performed
using specified parameters. Then, the Uniform
method showed in Linares-Barranco, Jimenez-
Moreno, and Civit-Balcells (2006), was used for
events generation algorithm. When applying this
algorithm, a minimum time interval between
consecutive events of 0.2 ms and a maximum of
400K events per frame are specified. The next step
generates all files necessary for processing the AER
TOOL in the CSR cluster. Then, the convolution
filter is performed for each division on a different
node. Finally, we got as many outputs as image
divisions were generated, with the result of applying
the operation.
For the convolution filter Sobel edge detection
was used in horizontal averaging the diagonal values
of a 3x3 size.
⎟
⎟
⎟
⎠
⎞
⎜
⎜
⎜
⎝
⎛
−−−
=
121
000
121
S
(1)
Parameters that have been considered for the
study are:
Number of cores: 4, 8, 16 and 32.
Number of divisions of the image:
o 1 image of 128x128 pixel.
o 4 divisions of 64x64 pixel.
o 16 divisions of 32x32 pixel.
o 64 divisions of 16x16 pixel.
o 256 divisions of 8x8 pixel.
o 1024 divisions of 4x4 pixel.
Convolution matrix: Sobel of 3x3.
Once we have recorded the runtimes of each
stage, analyzed the graph generated and detected the
highest peak on the surface, we can indicate the
optimal design for the system.
3 RESULTS AND DISCUSSION
CSR cluster is a shared computational resource at
UCA. Runtimes may depend on the cluster workload
and users. A variation in the order of milliseconds
has been detected. In order to minimize these
undesirable situations we have selected a low
workload day (Saturday) and a reduced number of
nodes respect to the maximum available number of
nodes in the cluster. Tests were performed 3 times
and the averaged Runtimes are represented in tables
1- 4 and their respective figures.
The test took place on 9/10/2010 with a
workload of 30% consumed by other 9 users running
their own independent application of this test.
Processing time for each stage and the total can
be seen in the following tables, expressing all the
time in seconds for each number of nodes.
Table 1 presents both the event generation and
the convolution Runtimes for selected image
divisions and using 4 nodes (16 cores) of the CRs. It
can be observed that there is no significant
difference for 1 or 4 divisions. Nevertheless, for 64
VISUAL AER-BASED PROCESSING WITH CONVOLUTIONS FOR A PARALLEL SUPERCOMPUTER
87
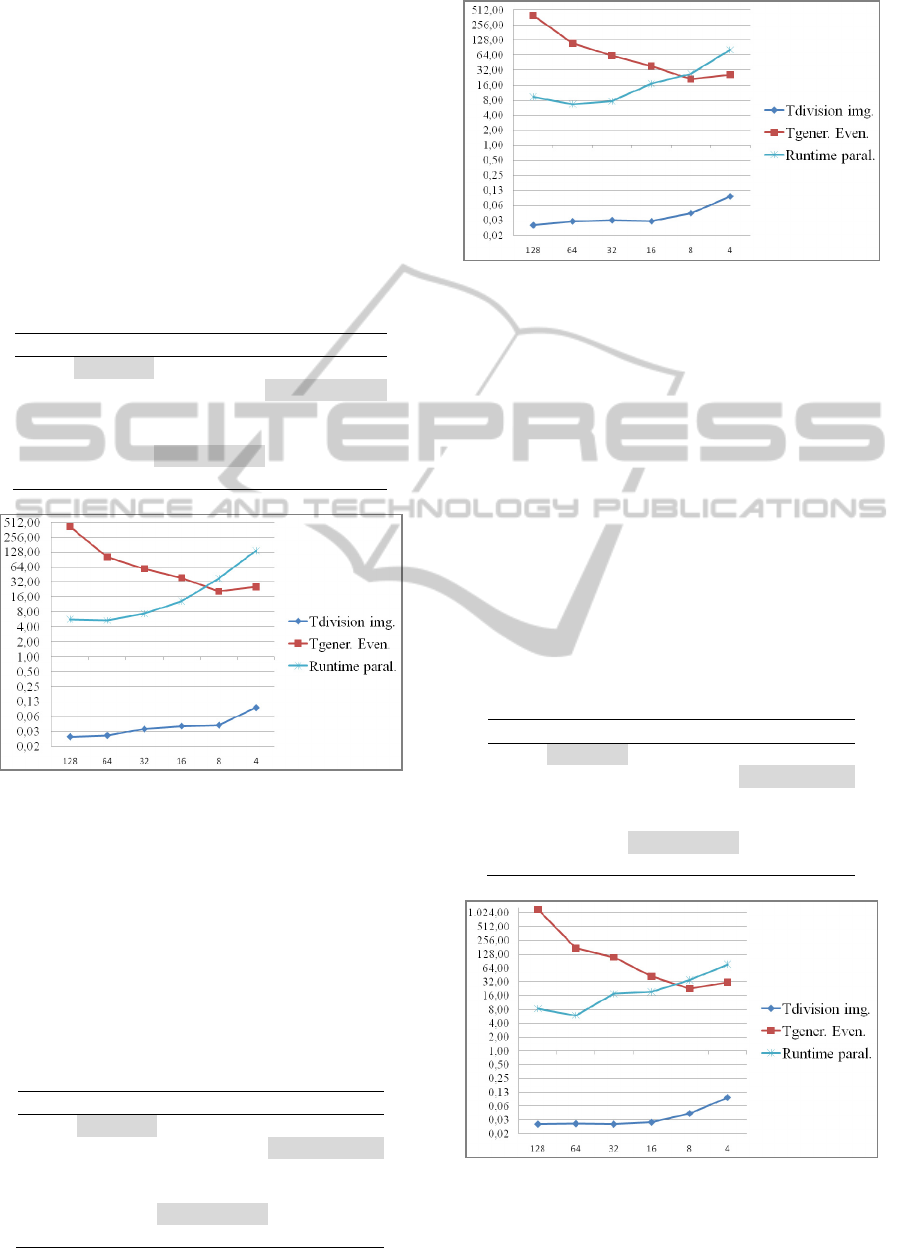
or 256 divisions, runtimes are doubled and a
significant difference for 1024 divisions can be seen.
However, when generating events it can be seen that
the lower is the number of divisions, the higher is
the Runtime, except for 1024 divisions. In the case
of parallel execution it can be seen that leaving the
image on its original size and dividing it into 4
pieces of 64x64 has a significant time difference too.
It can be also observed that there is a runtime
increment for 64 image divisions. For the total
runtime (Table 5, 4 nodes column), the best
Runtimes correspond to 64 divisions.
Table 1: Runtimes summary for 4 nodes.
N. div Tdiv img Tgener. Even Runtime. Paral
1 24 ms 413,9 s 5,6 s
4 26 ms 101,1 s 5,3 s
16 35 ms 59,1 s 7,3 s
64 40 ms 38,8 s 13,1 s
256 42 ms
20,7 s 37,6 s
1024 94 ms 25,7 s 135,5 s
Figure 3: Runtimes for 4 nodes.
Table 2 presents corresponding runtime results
when tasks are scheduled for 8 nodes of the cluster.
Now, it can be seen that runtimes are improved in
general terms, but these results do not imply
significant changes. For the image division task, the
lowest Runtime remains for 1 division. For the event
generation task, the lowest result is obtained for 256
divisions. And for the convolution task, runtime is
also the lowest for 4 divisions, like for 4 nodes.
Table 2: Runtimes summary for 8 nodes.
N. div Tdiv img Tgener. Even Runtime paral
1 25 ms 395,6 s 9,3 s
4 30 ms 109,8 s 6,6 s
16 31 ms 62,8 s 7,6 s
64 30 ms 38,8 s 17,0 s
256 43 ms
20,9 s 27,2 s
1024 95 ms 25,8 s 81,5 s
Figure 4: Runtimes for 8 nodes.
In Table 3 runtime results correspond to the use
of 16 nodes of the cluster. Image division task has
similar results than for lower number of nodes.
Event generation task runtime offers significant
changes for 8x8 pixel blocks (when divided into a
total of 256 images), but their convolution runtimes
do not produce improvements. In the parallel
execution of convolutions, it is found that 64x64
divisions have reduced runtime. For 32x32 and
16x16 images runtime is very similar, but when you
have 8x8 images runtime increases. This increment
is due to the coordination of a large number of
processors in the cluster that requires more data
traffic between them, resulting in an overall
implementation delay.
Table 3: Runtimes summary for 16 nodes.
N. div Tdiv img Tgener. Even Runtime paral
1 26 ms 1199,2 s 8,3 s
4 26 ms 171,9 s 5,9 s
16 26 ms 108,9 s 17,4 s
64 28 ms 41,9 s 19,3 s
256 43 ms
22,7 s 34,8 s
1024 96 ms 31,3 s 76,8 s
Figure 5: Runtimes for 16 nodes.
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
88
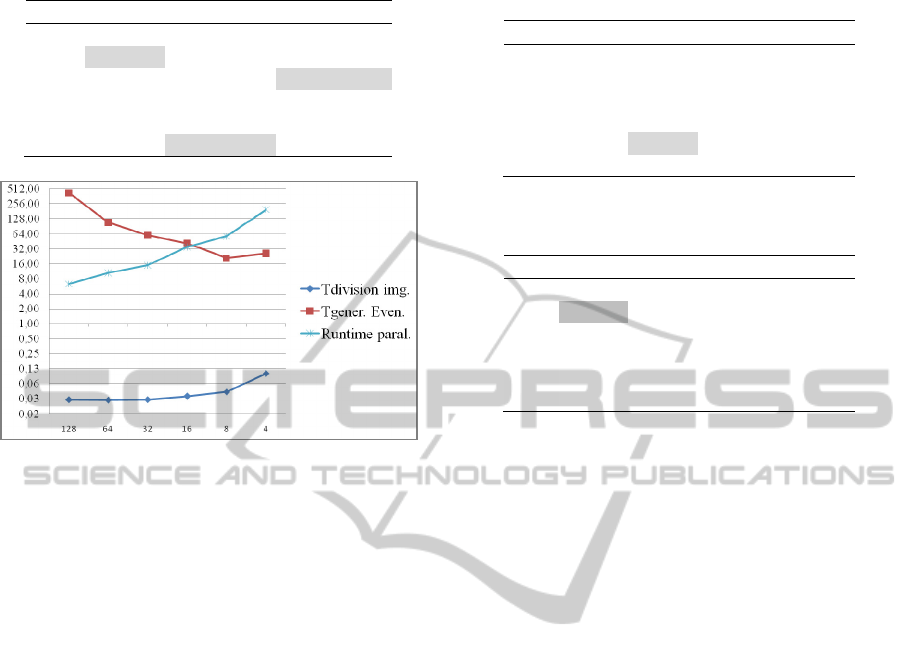
Table 4: Runtimes summary for 32 nodes.
N. div Tdiv img Tgener. Even Runtime paral
1 30 ms 423,7 s 6,3 s
4 30 ms 107,7 s 10,5 s
16 30 ms 59,9 s 14,9 s
64 35 ms 41,0 s 34,8 s
256 43 ms 20,8 s 57,0 s
1024 100 ms
25,8 s 195,6 s
Figure 6: Runtimes for 32 nodes.
In Table 4 results are presented when 32 nodes
of the cluster are used. Image division task runtime
and event generation runtime show similar results to
those presented for 16 nodes. Parallel convolution
task runtimes are improved for 4, 8 and 16 divisions.
Therefore increasing the number of nodes working
in parallel does not imply runtimes reduction, but for
larger number of divisions, runtimes also increase,
starting at dawn when they are 64 divisions of
blocks of 16x16 pixel and shooting when divisions
reach the 1024 block of 4x4 pixel.
If we represent the total runtime with respect to
the maximum number of nodes and the number of
divisions, we get Table 5, noting the lowest total
runtime shaded.
If instead of using the total runtime, we take the
parallel runtime and we represent it in the same
domain as Table 5, we obtain Table 6, noting the
minimum runtime shaded.
It can be highlighted the case of 4 nodes and 4
divisions of 64x64 pixel blocks which have a faster
execution, but not much different block sizes with
the 32 or 128.
In all cases, total runtime for 1024 divisions is
not the least due to coordination job between all
nodes in parallel. Job Manager of CRS takes more
time to handle all tasks in parallel.
Table 5: Summary of total runtime as the number of
divisions and the number of nodes.
N div 4 nodes 8 nodes 16 nodes 32 nodes
1 420 s 405 s 1213 s 430 s
4 107 s 117 s 178 s 118 s
16 67 s 71 s 127 s 75 s
64 52 s 56 s 62 s 76 s
256 59 s 49 s 59 s 79 s
1024 165 s 111 s 113 s 225 s
Table 6: Summary of parallel runtime depending on the
number of divisions and the number of nodes.
N div 4 nodes 8 nodes 16 nodes 32 nodes
1 5,6 s 9,3 s 8,3 s 6,3 s
4 5,3 s 6,6 s 5,9 s 10,5 s
16 7,3 s 7,6 s 17,4 s 14,9 s
64 13,1 s 17,0 s 19,3 s 34,8 s
256 37,6 s 27,2 s 34,8 s 57,0 s
1024 135,5 s 81,5 s 76,8 s 195,6 s
4 CONCLUSIONS
In this work we have designed a test case set for
AER convolution processing on a supercomputer,
the CRS cluster of UCA, Cadiz, SPAIN. We have
executed and compared all the test cases. If we rely
on the data obtained we obtain the following
conclusions:
Referring to the data in Table 5, we can see that
the total runtime minor by running a maximum
of 8 nodes in parallel and 256 divisions of the
image into blocks of 8x8 pixel. This case is
very similar to the case of a maximum of 8
nodes in parallel and 64 divisions of the image
into blocks of 16x16 pixel. Then, the two
implementations would be valid for our system.
If we look at the data in Table 6, in which only
the parallel runtimes are shown, we see that the
test case for a maximum of 4 nodes with 4
divisions of 64x64 pixel of the image, obtained
lower runtimes.
If we consider that in a hardware
implementation generation times of events
disappear when taking images directly from an
acquisition system events and we are left with
only 4 nodes in parallel with 4 divisions of
64x64 pixel.
This work represents the first steps on the
execution of more complex AER system simulations
on the cluster, which will improve considerably the
performance of parameters adjustment of
hierarchical AER systems where several convolution
VISUAL AER-BASED PROCESSING WITH CONVOLUTIONS FOR A PARALLEL SUPERCOMPUTER
89

kernels work together in a multilayer system for
more complex tasks as face or patron recognition.
ACKNOWLEDGEMENTS
This work has been partially supported by the
Spanish grant VULCANO (TEC2009-10639-C04-
02).
Andrés Yañez Escolano, member of Languages
and Computing Systems Department at University
of Cádiz, Spain, and Abelardo Belaustegui
González, member of Computing System Area at
University of Cádiz, Spain and main manager CRS.
REFERENCES
Serrano-Gotarredona, T., Linares-Barranco, B., (1999).
AER image filtering architecture for vision-processing
systems. Circuits and Systems I: Fundamental Theory
and Applications, IEEE Transactions., 46, 1064-1071.
Linares-Barranco, A., Jimenez-Moreno, G., Linares-
Barranco, B., Civit-Balcells, A., (2006) On
algorithmic rate-coded AER generation. Neural
Networks, IEEE Transactions., 17, 771-788.
Montero-Gonzalez, R.J., Morgado-Estevez, A., Linares-
Barranco, A., Linares-Barranco, B., Perez-Peña, F.,
Perez-Carrasco, J. A., Jimenez-Fernandez, A. (2011)
Performance study of software AER-based
convolutions on a parallel supercomputer. Proceedings
presented at International Work Conference on
Artificial Neural Networks (IWANN‘11).
Technical support in supercomputing, University of Cadiz,
http://supercomputacion.uca.es/
Perez-Carrasco, J.A., Serrano-Gotarredona, C., Acha-
Piñero, B., Serrano-Gotarredona, T., Linares-
Barranco, B. (2009). Advanced Vision Processing
Systems: Spike-Based Simulation and Processing.,
Lecture Notes in Computer Science, Advanced
Concepts for Intelligent Vision Systems, 5807, 640-
651.
Lujan-Martinez, C., Linares-Barranco, A., Rivas-Perez,
M., Jimenez-Fernandez, A., Jimenez-Moreno, G.,
Civit-Balcells, A. (2007). Spike processing on an
embedded multi-task computer: Image reconstruction.
Intelligent Solutions in Embedded Systems 2007 Fifth
Workshop. 15-26.
Camunas-Mesa, L., Acosta-Jimenez, A., Serrano-
Gotarredona, T., Linares-Barranco, B. (2008). Fully
digital AER convolution chip for vision processing.
Circuits and Systems, 2008. ISCAS 2008. IEEE
International Symposium. 652-655.
Perez-Carrasco, J. A., Acha, B., Serrano, C., Camunas-
Mesa, L., Serrano-Gotarredona, T., Linares-Barranco,
B.(2010). Fast Vision Through Frameless Event-Based
Sensing and Convolutional Processing: Application to
Texture Recognition. Neural Networks, IEEE
Transactions, 21, 609-620.
SIGMAP 2011 - International Conference on Signal Processing and Multimedia Applications
90
