
ANOMALY DETECTION IN PRODUCTION PLANTS
USING TIMED AUTOMATA
Automated Learning of Models from Observations
Alexander Maier, Oliver Niggemann, Roman Just, Michael J¨ager
Institut Industrial IT, OWL Universitiy of Applied Sciences, Lemgo, Germany
Asmir Vodenˇcarevi´c
Knowledge-Based Systems Research Group, University of Paderborn, Paderborn, Germany
Keywords:
Parallelism structure, Behavior model, Timed automata, Anomaly detection, Model-based diagnosis.
Abstract:
Model-based approaches are used for testing and diagnosis of automation systems (e.g. (Struss and Ertl,
2009)). Usually the models are created manually by experts. This is a troublesome and protracted procedure.
In this paper we present an approach to overcome these problems: Models are not created manually but
learned automatically by observing the plant behavior. This approach is divided into two steps: First we learn
the topology of automation components, the signals and logical submodules and the knowledge about parallel
components. In a second step, a behavior model is learned for each component. Later on, anomalies are
detected by comparing the observed system behavior with the behavior predicted by the learned model.
1 INTRODUCTION
Model-based diagnosis uses a model of a production
plant to compare the predictions of the model to ob-
servations of the running plant. If there arises a dif-
ference between the simulation of the model and the
running plant, an anomaly is signaled.
The bottleneck in model-based diagnosis is the
modeling aspect. Usually, this is done manually by
experts who know the plant in detail. After each plant
modification, this work has to be repeated.
In this paper, we present a method for the anomaly
detection (part of model-based diagnosis) for produc-
tion plants using probabilistic deterministic timed au-
tomata (PDTA) as behavior models. But in contrast
to usual approaches, these automata are not created
manually but are learned automatically based on ob-
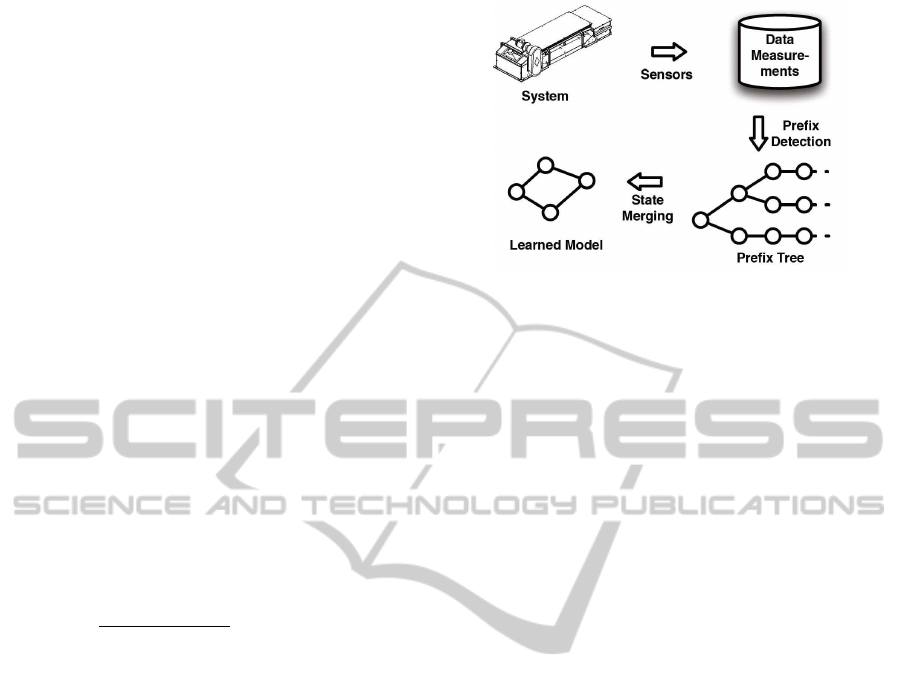
servations from the plant. Figure 1 shows our 3-step
toolchain for the anomaly detection:
The first step is learning the topology of the au-
tomation system: Learning the behavior of parallel,
asynchronous components is hard unless this paral-
lelism structure is known beforehand. E.g. learning
the timing behavior of 2 asynchronous components,
each comprising 1000 states, is hard when the paral-
lelism structure is unknown; obviously up to 1000000
1. Learning
parallelism
structure
2. Learning
behavior
model
3. Anomaly
detection
Local neighbor
information for
each device
observations observations
Figure 1: Our toolchain for the anomaly detection.
states may be learned.
No data analysis can reveal this parallelism struc-
ture. But for the special case of plant signals, the plant
structure often mirrors the components’ parallelism.
And this resembles the topology of the automation
system, i.e. the topology of IO devices. So in order to
learn the parallelism structure, learning the topology
of the automation system is often a good approxima-
tion. Further details are given in section 2.1.
In the second step, for each component, a behavior
model is learned automatically on basis of recorded
plant observations. Section 2.2 gives more details to
the model formalism and the learning algorithm.
In the third step anomalies are detected: During
runtime of the production plant, we compare the out-
put of the model simulation with observations of the
production plant. Typical anomalies in this paper are
363
Maier A., Niggemann O., Just R., Jäger M. and Voden
ˇ
carevi
´
c A..
ANOMALY DETECTION IN PRODUCTION PLANTS USING TIMED AUTOMATA - Automated Learning of Models from Observations.
DOI: 10.5220/0003538903630369
In Proceedings of the 8th International Conference on Informatics in Control, Automation and Robotics (ICINCO-2011), pages 363-369
ISBN: 978-989-8425-74-4
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

timing deteriorations or changed signal values. This
is discussed in section 3 in detail.
2 LEARNING BEHAVIOR AND
PARALLELISM STRUCTURE
In order to learn the overall model, we first have to
identify the parallelism structure and finally learn the
behavior model for each component individually.
2.1 Learning Parallelism Structure
As mentioned above, the topology of the automation
system is used to approximate the parallelism struc-
ture. This parallelism structure decomposes the over-
all model into parallel components—for which se-
quential behavior models can be learned.
We use AutomationML (AutomationML, 2010)
as an exchange format to store the topology of the
automation system—and therefore of the parallelism
structure. This parallelism structure includes infor-
mation like the IO devices, Programmable Logical
Controllers (PLCs) and communication networks.
For some types of communication networks, the
topology of the automation system can be identified
automatically. In this paper, the PROFINET standard
is used as an example.
123.11…
123.11…
123.11…
Step 1: IP addresses are
collected (using DCP)
Step 2: Local neighborhoods are
found (using LLDP and SNMP)
Step 3: Identical
nodes are merged,
forming the
topology
Figure 2: Topology Learning Principle.
The learning procedure is organized in three steps
(see figure 2): (i) First we collect all IP addresses
in the network, using the DCP standard. As result
we’ve got an unsorted collection of all participants
in the network. (ii) In the next step we look for lo-
cal neighborhoods for each node. In a PROFINET
network each device offers network related data, like
local and neighbor information in its own database,
called LLDP-MIB. This information is accessible via
the SNMP protocol, by addressing each device in the
network directly. Collecting local and neighbor infor-
mation of each network participant leads to raw data,
describing single autonomous nodes. (iii) Based on
these gathered data sets, a topology map can be cre-
ated, by merging each individual node based on the
assignment of neighbor information to local data of
other nodes.
In the following, a parallelism structure and its
components are defined formally; the definition here
is especially tailored for the purpose of model learn-
ing.
Definition 1 (Component). A component C is de-
fined by a behavior function b
C
: R × {0,1}
m
→
{0,1}
n
,n,m ∈ N is a function over m input variables
and over time and it returns n output variables.
The reader may note that we assume a global time
base and a deterministic, discrete system; from this it
follows that the order of all value changes are prede-
fined, i.e. a component behaves sequentially.
So far, we do not distinguish between components
describing plant modules, PLCs, or network devices.
While such classifications are necessary from a do-
main point of view, a general formalism for learning
models should abstract from such classifications.
A parallelism structure is now created by connect-
ing several components:
Definition 2 (Parallelism Structure). A parallelism
structure M is defined as a tuple < C ,z > where
C = {C
0
,.. .,C
p−1
} is the set of components and z :
C ×N →C ×N maps an output variables of one com-
ponent onto the input variable of another component.
I.e. z(C
i
,k) = (C
j
,l) connects the k’s output vari-
able of C
i
with the l’s input variable of C
j
.
Finally we have to learn the behavior model for
each component. The following section gives more
details about the used formalism and the learning al-
gorithm.
2.2 Learning Behavior Model
In general, model-based diagnosis can use any kind
of behavior models. However, the quality of diagno-
sis depends on the used modeling formalism and the
prediction abilities of the models. In the following,
we give some requirements to this formalism for the
use case of anomaly detection for production plants.
State based Systems. Production plants mainly show
a state based behavior, i.e. the system’s state is pre-
cisely defined by its current and previous discrete IO
signals.
Usage of Time. Since actions in automation plants
are mostly depending on time, the formalism has to
consider it as well.
Probabilistic Information. Here, the behavior mod-
els describe the previous, recorded plant behavior. So
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
364
unlike in specification models, behavior probabilities
must be modeled.
Timed Automata are well suited for the require-
ments from above. A large number of variants of au-
tomata exist. Here we use a timed, probabilistic au-
tomaton where the timing is expressed as a relative
time span.
In contrast to traditional automata, the formalism
here is simplified to ease the learning task: First of
all, we allow only for relative timing, e.g. transitions
may not refer to a global time base.
Definition 3 (Timed, Probabilistic Automaton). An
automaton is a tuple A = (S, S
0
,F,Σ, T,δ,Num),
where
• S is a finite set of states, S
0
∈ S is the initial state,
and F ⊆S is a distinguished set of accepted states,
• Σ is the alphabet. For a component, Σ equals the
set of events.
• T ⊆ S ×Σ×S gives the set of transitions. E.g. for
a transition hs,a,s
′
i, s,s
′
∈ S are the source and
destination state and, a ∈ Σ is the trigger event.
• A function Num : T →N counts the number of ob-
servations in which a transition has been used in
the system’s past. Num can be used to compute a
transition probability p for a transition (v,w) ∈T:
p(v, w) =
Num(v,w)
∑
((v,w
′
)∈T)
Num(v,w
′
)
.
• A transition timing constraint δ : T →I, where I is
a set of intervals. δ always refers to the time spent
since the last event occurred. It is expressed as
a time range or as a probability density function
(PDF), i.e. as probability over time.
Learning Probabilistic Deterministic Timed Au-
tomata
Learning behavior models–i.e. automata–for se-
quential components follows the methodology from
figure 3: First of all, all relevant data is measured
from the system. For this, the system is observed dur-
ing several production cycles. The resulting observa-
tion sequences (recorded events and time stamps) are
stored in a database.
In a next step, common prefixes of such data se-
quences are identified. I.e. for the first cycle, the se-
quence of events is stored in form of an event list.
Then for each following cycle, common prefixes with
a previous event sequence are identified; if the actual
sequence derives at some point, the result is an event
tree. The final result is a prefix tree (prefix tree accep-
tor, PTA) which models all observation sequences in
a dense form—dense because common sequences are
stored only once.
Now, similar states of the prefix tree are merged.
The result is an automaton which models the system.
Figure 3: The general learning methodology.
Our algorithm (Bottom Up Timing Learning Al-
gorithm, BUTLA) for learning the behavior models
differs to the existing algorithms in two points:
1. Bottom-up merging order: We use a bottom-up
merging strategy, i.e. we start with the final (leaf)
states and go up to the starting state in a breadth-first-
like manner. This eliminates the need for recursive
compatibility checks of the sub-trees. This has two
advantages: (i) the algorithm shows a better runtime
behavior and (ii) the resulting automaton resembles
better the real plant behavior.
This bottom-up strategy works best if all leafs of
the prefix trees correspond to final states or to the
same states in a cyclic process. Here, the new algo-
rithm applies domain specific knowledge: For mea-
surements of plants, it is normally no problem guar-
anteeing this constraint.
2. Different time learning operation: Here, we use a
different heuristic to learn the correct timing informa-
tion at the transitions:
(i) First of all, timing is expressed by means of
probability density functions instead of time interval;
this allows for a much preciser model of the timing.
(ii) At the core of transition timing learning lies
one decision: Should a transition with an event e be
split into two transitions with different timing infor-
mation? Unlike other approaches, we base our deci-
sion on the timing information itself, not on the sub-
tree resemblance; figure 4 shows an example:
s
0
and s
1
are two states in an automaton, the transi-
tion timing is a statistic for the transition occurrences
in the past and is expressed as a probability density
function (shown next to the transition).
Using Verwer’s approach, the transition would
only be split (new states s
′
1
and s
′′
1
) if the new result-
ing sub-trees are different. The motivation is that dif-
ferent states should define different successive behav-
iors, i.e. sub-trees.
But looking at figure 4, a split could be justified
just on the basis of probability density functions: Ob-
ANOMALY DETECTION IN PRODUCTION PLANTS USING TIMED AUTOMATA - Automated Learning of Models
from Observations
365

P
t
5
s'
1
s''
1
Subtree
Subtree
incompatible
[0,2]
(2,9]
s
0
s
1
s
0
Subtree
Subtree
s'
1
s''
1
[0,5]
(5,9]
s
0
Traditional
Approach
New
Approach
Subtree
Figure 4: A different timing learning approach.
viously the density function is created by two overlap-
ping Gaussian distribution. So it can be presumed that
two different technical processes have created the cor-
responding event—i.e. here again we apply domain
specific knowledge. And different processes must be
modeled as different states, because only then can the
learning algorithm associate transitions with the cor-
rect timing. And only such a precise timing associ-
ation allows for a correct separation between correct
and erroneous behavior (anomaly detection).
Our algorithm BUTLA is shown in figure 5 and can
be described as follows: First of all, a prefix tree is
created (step 1). Then, compatible states are merged
in a bottom-up order (steps 2); how state compatibil-
ity is defined will be explained later on. If the PDF
describing a transition timing is multi-modal (i.e. is
the sum of several independent processes, see also
figure 4), the transition is split (step 3). Each of the
new states created by the split gets a copy of the orig-
inal sub-automaton (the function Num must be re-
computed).
BUTLA uses a function compatible to check
whether two states can be merged (see figure 6): The
idea is similar to ALERGIA’s approach (see section
4), only that we compare in-going and not out-going
transitions and that no recursive sub-tree comparisons
are needed.
First of all, several additional variables are needed
in figure 6: The number of occurrences of an out-
going transition for a specific state and a specific event
(f (a,v), step 1), the number of occurrences of in-
going and out-going transitions for a specific state
(f
in/out
, step 2-3) and the number of measurement se-
quences which end in a specific state (f
end
, step 4).
If the f
end
s for two states (in relation to f
in
) are too
different (see function compatible below), they are
not merged (step 6). Similarly, if for any event a the
corresponding f(a,∗)s are too different (in relation to
f
in
), the states are also not merged (step 7).
In step 8, it is checked whether two transitions,
that might be merged, have too different timing con-
straint PDFs. This is done to prevent later unneces-
Given:
(1) Discrete componentC, its function b
C
, its events E
(2) Measurements S = {S
0
,...,S
n−1
} where S
i
= (E ×
R)
p
, p ∈ N is one sequence of p events over time (i.e. one
measurement or one scenario).
Result: C’s function b
C
defined by an automaton
(1) Build prefix tree A = (S, S
0
,F,Σ,T, δ, Num) based on S .
A is a timed, probabilistic automaton according to definition 3
(2) for all v, w ∈ S in a bottom-up order do
(2.1) if compatible(v, w) then
(2.1.2) merge(v, w)
end for
(3) for all v in a top-down order do
(3.1) for all out-going transitions e of v do
(3.1.1) if transition timing δ(e) is multi-modal then
(3.1.1.1) split(e)
end for
end for
Figure 5: Automata learning algorithm BUTLA.
Given: v, w ∈S
Result: decision yes or no
(1) f(a, v) :=
∑
e=(∗,a,v)∈T
Num(e), v ∈ S, a ∈Σ where
∗ is an arbitrary element
(2) f
in
(w) :=
∑
e=(∗,∗,w)∈T
Num(e), w ∈ S
(3) f
out
(v) :=
∑
e=(v,∗,∗)∈T
Num(e), v ∈ S
(4) f
end
(v) := f
in
(v) − f
out
(v), v ∈ S
(5) d(a,v) :=
∑
e=(∗,a,v)∈T
δ(e) where the sum denotes the
adding of two PDFs
(6) if fractions-different( f
in
(v), f
end
(v), f
in
(w), f
end
(w))
(6.1) then return false
(7) for all a ∈Σ do
(7.1) if fractions-different( f
in
(v), f (a,v), f
in
(w), f (a,w))
(7.1.1) then return false
(8.1) if PDFs-different(d(a, v),d(a, w)) then
(8.1.1) return false
end for
(10) return true
Figure 6: Comparison algorithm compatible.
sary splits; the function PDF-different can be imple-
mented using the well-known R
2
test.
To compare whether two fractions
f
0
n
0
and
f
1
n
1
are
significantly different (function fractions-different),
we use the Hoeffding Bound:
different(n
0
, f
0
,n
1
, f
1
) :=
f
0
n
0
−
f
1
n
1
>
r
1
2
log
2
α
1
√
n
o
+
1
√
n
1
where 1−α,α ∈ R is the probability of the decision.
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
366

3 ANOMALY DETECTION
For diagnosis, we use the discrete probabilis-
tic deterministic timed automaton (PDTA) A =
(S,S
0
,F,Σ, T,δ,Num) as defined in definition 3.
Therefore, the behavior can be defined as a path
through the automaton as follows.
Definition 4 (Path through Automaton). Let A =
(S,S
0
,F,Σ, T,δ,Num) be an automaton. A path P
through the automaton is defined as a list of sequen-
tial transitions P ⊆ T
∗
.
Definition 5 (Observation). An observation of the
plant is defined as o = (a,t), where
• a ∈ Σ is the trigger event in the plant and
• t is a relative time value (relative to the last signal
change).
The learned automaton is now used to detect
an unusual behavior (an anomaly) in an automation
plant. During runtime we observe the running au-
tomation plant and simulate the identified model in
parallel. Then we compare the simulation outputs
with the observations from the running system. If
there arises any difference, an anomaly (error) has oc-
curred.
Figure 7 shows the algorithm for detecting an
anomaly. Following types of anomalies can be de-
tected using this procedure:
Functional Errors. In a current state exits no event
(i.e. changing signal value) for a certain signal (sen-
sor/actuator). E.g. while filling a bottle the next event
should be ”bottle full” but for some reason the filling
stops (event: ”stop filling”).
For every observed event it is checked whether-
its symbol corresponds to one of the possible outgo-
ing events in the current state (line 2.2a). An error
is found when no transition with the observed event
exists, i.e. if the observed path is not equal to one
possible simulated path in the automaton.
Timing Errors. A timing error occurs when the sig-
nal changes correctly, but the timing range doesn’t fit.
E.g. if the filling of the bottle should take between
four and five seconds, an anomaly would be found,
when this takes less than four or more than five sec-
onds. Since we often don’t have hard time limits, it’s
useful to work with distribution functions. In this case
we can return the probability of the failure.
For every observed event it is checked whetherthe
time of the observed event fits into the time range or
doesn’t differ more than a predefined deviation from
the expected value. This is done in line 2.2b.
Probability Errors. Taking the probabilities into
consideration more complex and gradual errors can be
Given:
(1) Probabilistic Deterministic Timed Automaton (PDTA) A =
(S, S
0
,F,Σ,T, δ, Num) (according to definition 3)
(2) O = (o
1
,...,o
k
), o
i
is an observation according to definition
5
(3) α: a predefined value for the probability deviation
(4) Num
′
: T → N, ∀e ∈ T : Num
′
(e) = 0
Result: localized anomaly (if there exits one) otherwise ’OK’
Algorithm:
(1) s := S
0
// beginning with initial state
(2) for i := 1 to k do // iterate over all observations
(2.1) o
i
= (a,t) // observation with symbol and time
(2.2a) if exists e ∈ T with e = (s,a,s
′
) // check symbol
(2.2b) and t ∈ δ(e) then // check times
(2.2.1) Num
′
(e)++ // update observed occurrences
(2.2.2) if p
Num
′
(e) − p
Num
(e) > α then
(2.2.2.1) return anomaly
(2.2.3) s := s
′
// go to next state
(2.3) else
(2.3.1) return anomaly
(2.4) end if
(3) end for
(4) return OK
Figure 7: Algorithm for anomaly detection.
detected when the probabilities in the observed sys-
tem diverge from the probabilities in the model. E.g.
while checking the filling of a bottle, 95% of the bot-
tles are filled correct and 5% wrong. Here it would be
an anomaly, if the observed probability exceeds this
usual value.
In line 2.2.2 it is checked whetherthe probabil-
ity for taking the chosen transition doesn’t vary too
much. The occurrences of each event in the real plant
are counted and the probabilities are recalculated after
each occurrence (line 2.2.1). For the check we need
α as additional parameter for the allowed tolerance.
If the probability exceeds this tolerance, an error is
detected.
4 STATE OF THE ART
4.1 Parallelism Structure
From a model learning perspective, a parallelism
structure subdivides the overall system into parallely
working components. I.e. a parallelism structure
defines a (hierarchical) set of interconnected com-
ponents where components work in parallel (usu-
ally asynchronously) and each individual component
shows a sequential behavior only. In plants, such se-
quential components often correspond to one techni-
ANOMALY DETECTION IN PRODUCTION PLANTS USING TIMED AUTOMATA - Automated Learning of Models
from Observations
367
cal device such as a robot, a conveyor belt, a reactor,
or a PLC (programmable logic controller).
Currently there exists no algorithm to identify a
parallelism structure by only using observations in an
automation system.
4.2 Behavior Model
The Finite State Machine/ Automaton (FSM) is one
of the most established modeling formalism. Based
on the initial FSM different types for different cases
were developed(e.g. non-deterministic, timed, proba-
bilistic, hybrid). An overview to the main formalisms
can be found in (Kumar et al., 2010). Petri nets also
allow modeling discrete behavior and are used e.g. by
(Cabasino et al., 2007).
There exist already several algorithms for learning
an automaton by using observations. In general, there
is a distinction between online and offline algorithms.
Online algorithms allow to ask for new patterns dur-
ing runtime while offline algorithms have to deal with
a given set of examples. The best known and one of
the first online algorithm is Angluin’s L* (Angluin,
1987).
Offline algorithms use a prefix tree to collect and
combine all recorded observations. MDI (Thollard
et al., 2000) and ALERGIA (Carrasco and Oncina,
1999) are two offline algorithms which learn a PDFA.
They use only positive examples, i.e. no failure mea-
surements. MDI uses a global criterion to check the
compatibility of two states. After each merging step
the old automaton and the new one are compared. If
the similarity measure exceeds a predefined value, the
new automaton is kept, otherwise rejected. ALER-
GIA uses a local criterion to check the compatibility.
Before merging two states, the Hoeffding Bound is
used to measure the similarity of these states. If these
states are similar enough, they are merged.
Verwer already presented different algorithms for
identifying timed automata (Verwer, 2010). Some of
them use as well negative as positive examples. To
include timing information Verwer introduced a split-
ting operation which splits a transition if the resulting
subtrees are different enough.
4.3 Model-based Diagnosis
Model-based diagnosis using discrete automata was
firstly introduced by Sampath et al. (Sampath et al.,
1994). They use a discrete deterministic (untimed)
automaton. This approach was applied for diagnosis
e.g. in (Hashtrudi Zad et al., 2003). In some other
contributions this approach is extended to the usage
of timed automata (e.g. in (Tripakis, 2002)).
Lunze et al. also work intensively with model-
based diagnosis based on timed discrete-event sys-
tems (e.g. (Lunze et al., 2001) (Supavatanakul et al.,
2006)). The main idea is to create a discrete-event
model which corresponds to the discrete-event sys-
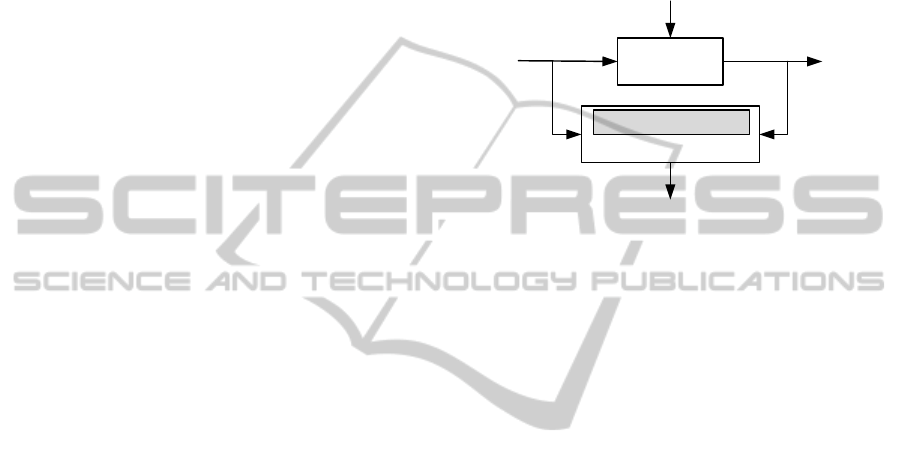
tem and afterwards compare their outputs (see figure
8). If a failure occurs in the system, the diagnostic al-
gorithm detects a difference and suggests the failure
which occurred in the system.
Discrete-event
system
Diagnostic Algorithm
V
W
Discrete-event model
f
f
Figure 8: Diagnosis of dynamic systems (Supavatanakul
et al., 2006).
5 CASE STUDY
This chapter includes an exemplary use case for the
formalisms described below. For this case we use an
exemplary plant which is used to transport and pro-
duce bulk material e.g. transport corn an produce pop-
corn. This model factory comprises several modules
to store, carry and produce the bulk material. The
model factory is controlled by a PLC and the mod-
ules are connected using PROFINET.
Using the methodology from chapter 2.1 we dis-
covered the plant topology and detected the two IO-
modules. These are used for the parallelism struc-
ture. Therefore in the following two automata were
learned; one for each module.
A datalogger observes the network traffic on a
mirrored port and analyses the profinet frames. For
further usage the extracted process data (recorded
events and the time stamps) is stored in a database.
Using these observations a prefix tree was created for
each component. The PTA of the first module con-
tains 26 states, the second one 3611 states.
Then we learned the behavior model as timed au-
tomaton (according to definition 3) for each compo-
nent using the algorithm described in figure 5. The
final automaton contains 17 states (8 states in mod-
ule 1, 9 states in module 2). This corresponds to a
compression rate of 99.5%.
Finally, to test the anomaly detection, we caused
some failures in the plant. Combining all signal out-
puts from the components we compared the signal
values observed in the running plant with the outputs
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
368

of the simulation. Here we used the datalogger in the
plant again, but in context of a real-time analysis. The
network traffic (profinet frames) are analyzed and af-
ter each change of a signal our anomaly detection tool
gets a message with the signal, its value and the times-
tamp.
In some first experiments we inserted 17 different
failures. Using the algorithm from figure 7, we were
able to detect 88% of the failures correctly. In the
remaining 12% we were able to detect the error, but
the error cause wasn’t identified correctly.
Although we were able to detect most of the er-
rors (at least the failures which were enforced by our-
selves), we encountered a problem: Sometimes a cor-
rect behavior was recognized as an error. This hap-
pens because we are not able to learn the completely
correct behavior model. For this we would need an
infinite number of recorded test samples. To prevent
this, it is possible to enrich the recorded observations
e.g. by using a normal distribution and create addi-
tional samples. Another possibility is to adapt the
model during runtime. For this we would need a su-
pervised learning algorithm which allows the plant
operator to add a path to the model. This issue is not
yet solved and should be addressed in future work.
6 CONCLUSIONS AND FUTURE
WORK
In this paper we presented an efficient method for
anomaly detection based on behavior models avail-
able as finite state machines/ timed automata. In con-
trast to usual approaches these models are learned
automatically by observing the running plant. We
presented an appropriate algorithm for learning this
model as timed automaton. Our learning process
comprises the learning of the parallelism structure (in-
cluding the plant topology). Finally we learn the be-
havior model in the formalism of timed automata for
each component.
The overall model is used for anomaly detection.
We showedthe differenttypes of anomalies which can
be detected using this approach and validated the us-
ability of this approach by giving some first experi-
mental results.
During the experiments we encountered the prob-
lem, that a model cannot be learned with accuracy
of 100%. To reach this, we would need an infinite
number of test samples. This means that in practice
sometimes a regular behavior is diagnosed as a fail-
ure. In future work the learned model should be en-
riched with empirical data or adapted during runtime.
In further work hybrid automata should be taken
into consideration. This will expand the expressive-
ness and the ability of finding an error reliably. Until
now there exists no appropriate learning algorithm for
the learning of hybrid automata.
REFERENCES
Angluin, D. (1987). Learning regular sets from queries and
counterexamples. Inf. Comp., pages 75(2):87–106.
AutomationML (2010). www.automationml.org.
Cabasino, M. P., Giua, A., and Seatzu, C. (2007). Identifi-
cation of petri nets from knowledge of their language.
Discrete Event Dynamic Systems, 17:447–474.
Carrasco, R. C. and Oncina, J. (1999). Learning determinis-
tic regular grammars from stochastic samples in poly-
nomial time. In RAIRO (Theoretical Informatics and
Applications), page 33(1):120.
Hashtrudi Zad, S., Kwong, R., and Wonham, W. (2003).
Fault diagnosis in discrete-event systems: framework
and model reduction. Automatic Control, IEEE Trans-
actions on, 48(7):1199 – 1212.
Kumar, B., Niggemann, O., and Jasperneite, J. (2010). Sta-
tistical models of network traffic. In International
Conference on Computer, Electrical and Systems Sci-
ence,. Cape Town, South Africa.
Lunze, J., Schr¨oder, J., and Supavatanakul, P. (2001). Di-
agnosis of discrete event systems: the method and an
example. In Proceedings of the Workshop on Princi-
ples of Diagnosis, DX’01, pages 111–118, Via Lattea,
Italy.
Sampath, M., Sengupta, R., Lafortune, S., Sinnamohideen,
K., and Teneketzis, D. (1994). Diagnosability of dis-
crete event systems. In 11th International Confer-
ence on Analysis and Optimization of Systems Dis-
crete Event Systems, volume 199 of Lecture Notes
in Control and Information Sciences, pages 73–79.
Springer Berlin / Heidelberg.
Struss, P. and Ertl, B. (2009). Diagnosis of bottling
plants - first success and challenges. In 20th Inter-
national Workshop on Principles of Diagnosis, Stock-
holm, Stockholm, Sweden.
Supavatanakul, P., Lunze, J., Puig, V., and Quevedo, J.
(2006). Diagnosis of timed automata: Theory and
application to the damadics actuator benchmark prob-
lem. Control Engineering Practice, 14(6):609–619.
Thollard, F., Dupont, P., and de la Higuera, C. (2000).
Probabilistic dfa inference using kullback-leibler di-
vergence and minimality. In Proc. 17th International
Conf. on Machine Learning, pages 975–982. Morgan
Kaufmann.
Tripakis, S. (2002). Fault diagnosis for timed automata. In
FTRTFT, pages 205–224.
Verwer, S. (2010). Efficient Identification of Timed Au-
tomata: Theory and Practice. PhD thesis, Delft Uni-
versity of Technology.
ANOMALY DETECTION IN PRODUCTION PLANTS USING TIMED AUTOMATA - Automated Learning of Models
from Observations
369
