
BUILDING BRIEF ONTOLOGIES
A Case Study for Floods Management
Juli
´
an Garrido, Ignacio Requena
Department of Computer Science and Artificial Intelligence, Universidad de Granada
C/ Daniel Saucedo Aranda, 18071 Granada, Spain
Stefano Mambretti
Wessex Institute of Technology, Ashurst, Southampton, U.K.
Keywords:
Hazards, Floods, Risk management, Knowledge representation, Brief ontology.
Abstract:
This paper introduces the generation of brief ontologies as a mechanism to obtain a reduced version of the
original ontology. The new ontology includes the relevant knowledge for a given context and thus reduces
reasoning time in applications. In order to do so, an automatic selection of the concepts that are included in
the brief ontology is done. A case of study for flood management is also presented, creating a brief ontology
that contains only knowledge related to floods from a generic ontology of environmental assessment.
1 INTRODUCTION
There have been different attempts of summarizing
monolithic semantic networks and ontologies i.e. a
methodology for partitioning a vocabulary hierarchy
into trees (Gu et al., 1999). This methodology re-
fines a IS-A hierarchy of medical entities according
to prescribed rules in a process carried out by a user
in conjunction with the computer. In order to reach
more simplicity, the methodology aims to create a set
of very small trees where each concept has only one
parent. However, this simplification makes the model
unrealistic. Moreover, they use human evaluation to
study how comprehensive are the resulting trees.
A comparison and description of pruning methods
for bio-ontologies is done in (Kim et al., 2007). They
describe whether a pruning method is more suitable
and whether they should be avoided by showing their
benefits and drawbacks for the different cases. In gen-
eral, these methods include two phases: i) the selec-
tion phase identifies relevant elements according to
the user’s goals. ii) The pruning phase uses the selec-
tion to remove irrelevant elements. In particular, they
describe for each method: the ontology base that the
method uses, whether it supports integrity constraints,
the level of automation, the type of selection strategy
and the size of the final ontology. Although they plan
to use metrics to assess the effectiveness of the meth-
ods, they also assess the methods showing the results
to a group of experts.
Another different approach divides large ontolo-
gies into modules using partitioning based on struc-
tural properties (Stuckenschmidt and Schlicht, 2009).
Its criterion consists of building modules where the
semantic connection between concepts in a module is
maximized whereas the dependencies with concepts
belonging to other modules are minimized. Firstly, it
creates a weighted dependency graph, it does a parti-
tioning and finally it optimizes the modules by isolat-
ing concepts, merging or duplicating concepts (even-
tually).
According to (Noy and Musen, 2009), an ontol-
ogy view is a portion of an ontology that is specified
as a query in some ontology-query language (analo-
gously to databases). However, they extend this def-
inition to ontologies that are defined by a traversal
specification (concepts, relationships and the maxi-
mum distance to traverse along each relationship) or
by meta-information. They also present a tool able
to accomplish management tasks such as comparing
ontologies, merging them together, maintaining and
comparing different versions. However, they declare
as an open issue pruning the definitions of the con-
cepts.
The concept of brief ontology was firstly intro-
duced in (Delgado et al., 2005). They define a
28
Garrido J., Requena I. and Mambretti S..
BUILDING BRIEF ONTOLOGIES - A Case Study for Floods Management.
DOI: 10.5220/0003630900280036
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development (KEOD-2011), pages 28-36
ISBN: 978-989-8425-80-5
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

brief ontology as the ontology which includes a small
amount of knowledge referring to concepts existing in
more generic ontologies. They introduce this concept
to provide relevant access to information in databases
for a web services-based and multi-agent architecture.
Nonetheless, a formal definition of brief ontology is
included in Section 2.
Methodologies like Methontology (Fern
´
andez
et al., 1999) point out the convenience of reusing other
existing ontologies whenever is possible. However,
the whole ontology has to be imported even if only
a small fraction is relevant for the problem. For this
reason, the size of the new ontology may grow with
useless conceptualizations from other ontology. This
problem worsens increasingly as more ontologies are
imported to the new one.
In order to avoid this problem, brief ontologies
may be used to obtain reduced versions of the ontol-
ogy that the user wants to import. If these ontologies
contain only the portion of knowledge that the user
really needs then the size of the ontology will not in-
crease unnecessarily. By contrast, the objective might
be just isolating a portion of the knowledge modelled
on the ontology in order to use only the brief ontol-
ogy without unnecessary knowledge. Our approach
presents a traversal method to build brief ontologies
using not only concepts but also instances of concepts
(individuals) as starter point. Moreover, the method is
also fully compatible with pruning definitions of the
concepts.
As an example, a case of study for floods manage-
ment is presented because of the European normative
(Directive 2007/60/CE, 2004) that encourages to the
assessment of flood risks in order to do an adequate
management of the problem. The starting point is
an ontology for environmental assessment and a brief
ontology for flood management is created as a base of
a future knowledge-based system.
The paper is organized as follows, Section 2 in-
troduces the concept of brief ontology, Section 3 de-
scribes the procedure for generation of brief ontolo-
gies taking into account two different scenarios i.e.
the generation based on concepts and the generation
based on individuals, Section 4 describe the case of
study where a brief ontology for flood management is
created. The final sections give the conclusions and
list bibliography.
2 BRIEF ONTOLOGIES
According to (Baader et al., 2003), a typical DL (De-
scription Logic) knowledge base comprises the TBox
and the ABox. The TBox describes the intensional
knowledge (terminology) and it is represented with
declarations in order to describe general properties of
the concepts.
Operators of the DL knowledge base allow build-
ing the terminology and providing meaning to its dec-
larations. For instance, a concept may be defined as
the intersection of other concepts. This type of sim-
ple definition allows defining a concept in terms of
other previously defined concepts. However, the set
of operators depends on the type of description logics
that the language implements (OWL-DL). This sub-
language implements the S H OI N (D) logic and it
has less expressivity than OWL in order to reduce the
computational complexity of reasoning and inferring
(Staab and Studer, 2009). It involves operators such
as: union, intersection, complement, one of, existen-
tial restriction, universal restriction and cardinality re-
striction.
The ABox contains the extensional knowledge
which is the knowledge that is specific to the indi-
viduals of the domain. It includes assertions about
individuals for example using properties or roles to
establish a relationship between individuals.
If an ontology is defined as the union of its TBox
and ABox, a brief ontology is another ontology where
the extensional and intensional knowledge have been
restricted and modified in order to include only the
relevant knowledge for a given context. This is for-
mally described in the following definition where the
TBox is represented as O = (K
T
and the ABox is rep-
resented as K
A
). However, it is important to clarify
before that if two concepts have the same name in O
and O
B
, then they are referred as equivalent with inde-
pendence of their definitions. The concept of equiva-
lence has the same consideration for individuals and
roles.
Definition 1. For ontology O = (K
T
, K
A
), a brief
ontology is an ontology O
B
= (K
B
T
, K
B
A
) such that
K
B
T
v K
T
∧ K
B
A
v K
A
, and for every concept C ∈ K
T
and its equivalent C
B
∈ K
B
T
, the definition of C ex-
actly matches the definition of C
B
or the definition of
C
B
is a generalization of the definition of C. Analo-
gously, for every individual v ∈ K
T
and its equivalent
v
B
∈ K
B
T
, every assertion of v
B
exactly matches the as-
sertion of v or it is a generalization of the original as-
sertion of v.
In other words, the brief ontology is a pseudo-
copy of the original ontology that includes only a por-
tion of the knowledge base (a subset of the intensional
and extensional knowledge). It is referred as a portion
because not all the concepts, individuals and roles of
the original ontology are in the brief ontology. More-
over, it is considered a pseudo-copy because the defi-
BUILDING BRIEF ONTOLOGIES - A Case Study for Floods Management
29

nition of the concepts may be modified or generalized,
and because some assertions of the individuals may
be also ignored or generalized (Garrido and Requena,
2011b).
The exclusion of elements of the original ontol-
ogy and the pseudo-copy are accomplished in order to
match with the restrictions for the brief ontology and
because of the brief ontology pretends to be a simpli-
fied version of the original ontology.
3 PROCEDURE OF GENERATION
This section describes the extraction procedure of the
brief ontologies. However, some considerations must
be taken into account before describing the algorithm.
The brief ontology is built making a selective copy
of the original ontology. The goal is to obtain a
context-centered ontology where the context is con-
sidered the specification of the user for the relevant
knowledge.
The extraction procedure is parametrized by this
user specification because it is used as criteria to
spread a traversal exploration on the original ontol-
ogy and therefore it is used to decide whether an ele-
ment of the original ontology is relevant and must be
included in the brief ontology.
Traversal algorithms (Aho et al., 1983) are usu-
ally used in graphs theory to implement depth first
or breadth first searches. These algorithms start at
some node and then visit all the nodes that are reach-
able from the start node. If the graph is weighted
then the strength of the relationships between nodes
are usually defined with matrix. Therefore, traversal
algorithms assist in the task of creating a sub-graph
because they establish an order to visit nodes in the
graph. Moreover, a threshold is useful to visit only
nodes that are strongly connected and thus restricting
the concept of reachable node.
Although an ontology is not a graph (Bizer and
Seaborne, 2004), a traversal exploration of an on-
tology implies analogously to consider two types of
nodes i.e. concepts and individuals. Moreover, these
elements are considered reachable whether there is
some kind of relationship between them. It may be
a parenthood relationship between concepts or a con-
cept and its individuals, relationships of a concept
with the concepts and individuals that are used in
its definition and relationships between individuals
that are represented in its assertions. Primitive val-
ues and datatype properties are not considered nodes
and connections between nodes, therefore, those data
are components of the node.
Whereas a threshold may be used to limit the
nodes that are going to be visited in a weighted graph,
other different mechanisms are used in ontologies. In
particular, a set of properties are specified to restrict
individuals and concepts that are visited during the
traversal exploration of the ontology (this set of prop-
erties is named relevant properties). If two nodes are
related with a property which is not a relevant prop-
erty then the second node will not be reachable by this
connection but it may be by another one.
If a property is relevant then the information that
it gives is interpreted as significant for the purpose
of the user. For the same reason, if a property is not
in this set then all the information or semantic that it
provides must be ignored and not included in the brief
ontology.
The following subsections describe two different
methods to build the brief ontologies. The genera-
tion based on concepts should be considered if there
is more interest on extracting the taxonomy of con-
cepts rather than the individuals of the ontology. De-
pending on how the ontology is built, a brief ontology
where all the individuals have been rejected is pos-
sible. However, if there is special interest in these
individuals then the generation based on individuals
should be used.
3.1 Generation based on Concepts
Algorithm 1 describes the generic procedure to build
a brief ontology when the start set is compound of
concepts. Its inputs are the original ontology, the set
of main concepts (MC) where the traversal copy starts
and the set of relevant properties (RR) to restrict the
traversal exploration. The output is a new ontology
that contains the relevant knowledge of the original
ontology.
First of all, only the relevant properties (RR) will
be created in the brief ontology and the rest of prop-
erties of the original ontology are ignored. After this,
the traversal copy of concepts must be accomplished.
This task is done for every concept that belongs to the
set MC (first loop).
The traversal exploration of concepts involves
spreading the algorithm to all the reachable nodes.
In this case, it spreads to concepts and individuals
by concept-concept, individual-individual, concept-
individual and individual-concept connections. How-
ever, only concepts are labeled with positive evalua-
tion to be created at this point. The reason is that the
complete taxonomy of concepts for the brief ontology
must be created before the creation of individuals, as-
sertions or concept definitions.
In the second loop, a traversal exploration of con-
cepts is started for each concept in MC. The next
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
30

nested loop starts a traversal exploration of individ-
uals for the ones that were reachable in the previous
exploration. The traversal exploration of individuals
is done following only individual-individual connec-
tions. All the individuals that are reached with the
set of relevant properties RR are created in the brief
ontology at this point.
All the concepts and individuals that have been in-
cluded in the brief ontology are visited in the third
loop. Firstly, a traversal exploration over the concepts
is done in order to create the definition of concepts.
Secondly, a traversal exploration over the individuals
allows defining their assertions.
------------------------------------------------
Algorithm 1
Input: Ontology O, main concepts MC,
relevant properties RR
Output: brief ontology OB Begin
Create RR properties
Foreach concept C in MC Begin
Traversal exploration of concepts (RR,C)
Create concepts with positive evaluation
End For
Foreach concept C in MC Begin
Traversal exploration of concepts (RR,C)
Foreach individual v in the exploration
Traversal exploration of individuals (RR,v)
Create individuals with positive evaluation
End For
End For
Foreach concept C in MC Begin
Traversal exploration of concepts (RR,C)
Foreach concept with positive evaluation
Create relevant definitions
End For
Foreach individual v in the exploration
Traversal exploration of individuals (RR,v)
Create relevant assertions in individuals
with positive evaluation
End For
End For
End
------------------------------------------------
Concepts and individuals may be reachable from
different concepts and individuals and it may im-
ply several traversal explorations in the same steps.
Moreover, cycles may appear depending on the orig-
inal ontology. In order to solve this problems, if a
concept or individual has been computed in a itera-
tion of the traversal algorithm then it does not have to
be computed a second time in subsequent iterations.
For this reason, the complexity of a traversal ex-
ploration is lineal O(n) if the number of relevant prop-
erties and main concepts are limited by constants.
Hence, the efficiency of the algorithm corresponds to
O(n*m), being n the number of concepts and m the
number of individuals.
3.2 Generation based on Individuals
Algorithm 2 describes the generic procedure to build
a brief ontology when the start set is compound of
individuals. Its inputs are the original ontology, the
set of individuals (MI) to start the traversal copy and
the relevant properties (RR). The output is the brief
ontology with the relevant knowledge.
This algorithm also starts creating the relevant
properties in the brief ontology. Then, it continues
with a traversal exploration of individuals for each in-
dividual in MI (first loop). The individuals cannot be
created until the class they belong exists in the brief
ontology. For this reason, the class of every individ-
ual found in the exploration is created in a nested loop
immediately before its respective individual. At this
point all the direct connections between individuals
that start in the MI are created. The next logical step
is to spread the algorithm with a traversal exploration
of all the concepts that were classes of the individu-
als. Hence, the complete taxonomy of concepts is in
the brief ontology once finished this step.
Although the major part of individuals is already
in the brief ontology, the individuals that are con-
nected to concepts by its definition may not have been
included. This requires a second loop where all the
concepts that are classes of the individuals (which
were found in the first loop of the algorithm) are again
the starting point of a traversal exploration. Conse-
quently, new individuals may be found in the con-
cepts definition as a result of this exploration of con-
cepts. These individuals are also starting point of a
new traversal exploration of individuals and the new
ones will be created in the brief ontology.
After finishing this second loop the complete tax-
onomy of concepts and individuals is in the brief on-
tology. However, individuals and classes are created
empty at first attempt and it requires a second step
to include its definitions and assertions. As a gen-
eral rule, concepts must be created before individuals,
these before definitions or assertions, and definitions
before assertions.
In the third step, the algorithm consists of two
nested traversal explorations of individuals (starting
in the set MI) and its concepts. The definitions of
the concepts are created at this moment. Nonetheless,
it is important to remark that the original definition
may be modified according to (Garrido and Requena,
2011b) due to some of the concepts or individuals of
the definition may no longer exist in the brief ontol-
ogy.
In the last step, a traversal exploration starts for
BUILDING BRIEF ONTOLOGIES - A Case Study for Floods Management
31

every individual of MI and the assertions are created
for every individual that is found during the explo-
ration. Exploring the classes of these concepts, new
individuals may be found and the algorithm ends cre-
ating the assertions for these individuals.
Although this algorithm increases the order of
complexity compared to the case that is based on con-
cepts, it has still polynomial efficiency.
-----------------------------------------------
Algorithm 2
Input: Ontology O, main individuals MI,
relevant properties RR
Output: brief ontology OB
Begin
Create RR properties
Foreach individual v in MI Begin
Traversal exploration of individuals (RR,v)
Foreach individual p with positive evaluation
Create concept C that is class of p
Create individual p
Traversal exploration of concepts (RR,C)
Foreach concept with positive evaluation
create concept
End
End
End
Foreach individual v in MI Begin
Traversal exploration of individuals (RR,v)
Foreach individual p with positive evaluation
Select C that is class of p
Traversal exploration of concepts (RR,C)
Foreach individual u in the exploration
Traversal exploration of individual(RR,u)
Create individuals with positive evaluation
End
End
End
Foreach individual v in MI Begin
Traversal exploration of individuals (RR,v)
Foreach individual p with positive evaluation
Select C that is class of p
Traversal exploration of concepts (RR,C)
Foreach concept with positive evaluation
Create definition
End
End
End
Foreach individual v in MI Begin
Traversal exploration of individuals (RR,v)
Foreach individual p with positive evaluation
Create assertions of p
Select C that is class of p
Traversal exploration of concepts (RR,C)
Foreach individual v in the exploration
Create assertions of v
End
End
End
End
-----------------------------------------------
4 CASE OF STUDY: FLOOD
MANAGEMENT
First of all, building a brief ontology from a detailed
one according to our needs is done by the genera-
tion process described in Section 3. Nonetheless, the
complete semi-automatic procedure to obtain a brief
model is detailed below.
1. Establish the aim and scope for the brief ontology.
2. Selection of a detailed ontology with knowledge
about the aim and scope.
3. Analysis and study of the detailed ontology.
4. Selection of the best type of extraction algorithm
for this ontology.
5. Selection of the starter point and relevant proper-
ties.
6. Generation of the brief ontology.
7. Evaluation of the resulting model.
4.1 Aim and Scope
Flood is a body of water which overflows its usual
boundaries over a land area with other land use, re-
sulting in adverse impacts. The socioeconomic devel-
opment in the floodplains and the reduction of the nat-
ural water retention by the land use increase the con-
sequences of floods. For this reason, a European Di-
rective (Directive 2007/60/CE, 2004) encourages the
flood management and risk assessment. This manage-
ment requires in general prevention, protection and
mitigation actions (De Wrachien et al., 2011).
The main goal for this case of study is to build a
model for flood management.
4.2 Detailed Ontology
The detailed ontology will be the environmental im-
pact assessment ontology that is originally described
in (Garrido and Requena, 2011a). This ontology was
built with two purposes. Firstly, in order to provide
and establish the conceptual framework of environ-
mental assessment (EA) and secondly, to facilitate the
development of methodologies and applications (Gar-
rido and Requena, 2010). Indeed, the ontology was
also born to be the knowledge base of an EA system.
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
32

Table 1: Set of relevant object properties.
ByMeansOf characterizeRainfall
characterizeRainfall dischargeAffectedBy
dischargeProducedBy floodProducedBy
hasCharacterizingIndicator hasDataSource
hasMitigatingAction hasPreventiveAction
hasRecoveryAction isCharacterizingIndicatorOf
isDataSourceOf isObteinedWith
isParameterOf isParametrizedBy
manageedBy produce
produceDischarge produceFlood
rainfallCharacterizedBy use&Need
4.3 Analysis of the Ontology
The EA ontology describes in essence the relation-
ships between industrial activities and environmen-
tal impacts considering for instance the environmental
indicators that should be controlled for every impact.
Although the ontology is focused on industrial ac-
tivities and human actions, it is also taking under con-
sideration natural processes and natural events as im-
pacting actions. A natural process or event is consid-
ered an impacting action whether they interact with
human activities and this interaction implies an incre-
ment of its environmental impact.
As a result of the inclusion of natural events, the
EA ontology contains knowledge about floods and it
allows using this detailed ontology as a base to extract
the relevant knowledge about our case of study.
A deeper description of the EA ontology is found
in (Garrido and Requena, 2011a). It contains a de-
scription for the taxonomy of concepts, the properties
and its justification.
4.4 Selection of the Algorithm
The selection of the algorithm may depend on the type
of ontology and the portion of the ontology that the
user is interested in.
Some ontologies are built only as semantic mod-
els where no instances of concepts are stored. In this
case, the application of the generation based on con-
cepts is mandatory.
By contrast, other ontologies are used as knowl-
edge base with a high number of instances. In this
case, the user may be interested only in the seman-
tic model represented by the taxonomy of concepts
or the factual knowledge represented by the instances
of concepts. The first case implies the utilization of
the generation based on concepts whereas the second
case requires the generation of brief ontologies based
on individuals.
In our case of study, the generation based on con-
cepts is chosen because of there is no special interest
on individuals and we are interested only in the se-
mantic model (taxonomy of concepts with their for-
mal definitions).
4.5 Parameters of the Algorithm
Because of the traversal algorithm based on concepts
has been chosen (Section 3.1), the parameters are a set
of starter concepts and a set of properties to traverse.
The selection of the starting point and the set of
relevant properties of the EA ontology require the
study and the analysis of the existing properties that
are used in the concept definitions, i.e. studying how
the concepts are related by these properties.
A property will be relevant in our domain depend-
ing on its semantics and its meaning. There are two
different cases: i) The property is specific for the tar-
geted domain. ii) The property has general use in dif-
ferent domains but it is used in concept definitions of
the targeted domain.
If the knowledge that the user have about the de-
tailed ontology is not enough to choose the set of rele-
vant properties, a heuristic for the selection of relevant
properties consist of the following steps. First, the set
of specific properties for the domain (floods) has to
be identified. Among them, a group of relevant prop-
erties is selected by studying its informal description,
domain or range in order to understand its semantics
and decide if it is relevant. Then, a temporary brief
ontology may be built with this set of relevant prop-
erties. The resulting ontology is studied to identify
new properties that are not specific in our domain but
they are considered also relevant for the concepts of
the brief ontology. Finally these properties are added
to the set of relevant properties.
For example, the property floodProducedBy has
its domain in the concept Flood and it allows defin-
ing the causes of a flood. This property is considered
relevant because it represents knowledge that we want
in our brief ontology for floods. The table 1 includes
the final set of relevant object properties for our case
of study.
Regarding to the starting points or main concepts,
the user should try to find some representative con-
cepts in the targeted domain that are not connected by
a traversal path with relevant properties. In our case
study, the selection of the concept FreshWaterFlood is
enough because of it is the best concept to represent
our targeted domain.
4.6 Generation of the Brief Ontology
The construction of the brief ontology for floods is
automatically carried out with the traversal algorithm
BUILDING BRIEF ONTOLOGIES - A Case Study for Floods Management
33
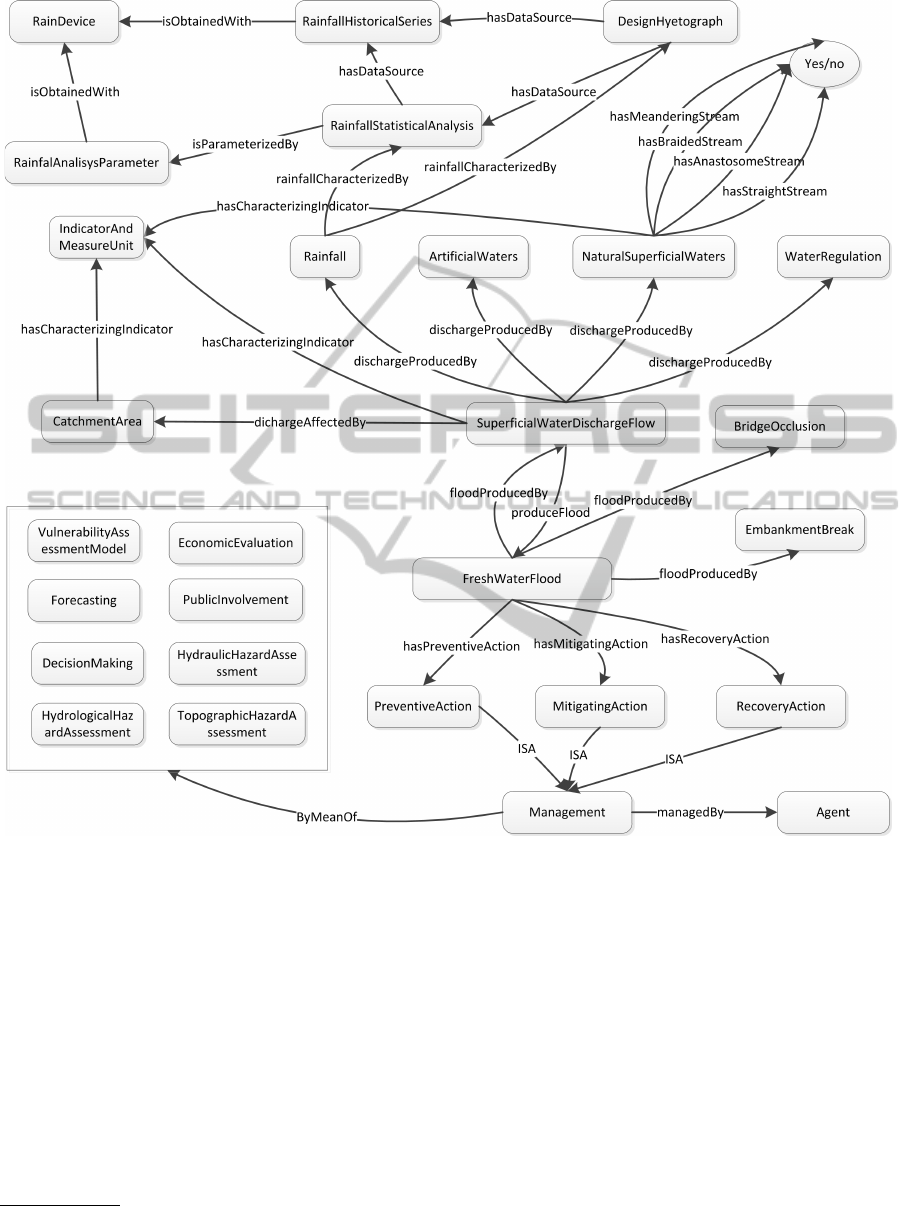
Figure 1: Schema of the brief ontology.
once it has the starting point for the algorithm and the
relevant properties.
As an example, the concept DDF
1
is subclass
of the concept RainfallStatisticalAnalysis and it has
three existential restrictions over the property is-
ParametrizedBy. When the concept DDF is added
to the brief ontology, its relationship with other con-
cepts and individuals is analysed. These connections
are represented in the definition below.
DDF
v RainfallStatisticalAnalysis
∃ isParametrizedBy.RainfallDepth
1
Rainfall statistical analysis whose acronym stands for
Depth, Duration and Frequency.
∃ isParametrizedBy.RainfallDuration
∃ isParametrizedBy.RainfallFrequency
According to the traversal algorithm, because of
the property isParametrizedBy is included in the set of
relevant properties, the concepts RainfallDepth, Rain-
fallDuration and RainfallFrequency will be added to
the brief ontology and the traversal algorithm will
continue through these concepts.
Figure 1 depicts a schema of the resulting model
for flood assessment and management. The schema
shows the main concepts and how they are related by
the properties.
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
34

4.7 Evaluation
The interpretation of the model is that floods are pro-
duced by a high level of water discharge or isolated
events like bridge occlusion and embankment breaks.
The discharge may be produced as well by rainfall, ar-
tificial water like canals, superficial waters like rivers
or bad water regulation but it also is affected by the
catchment area. The rainfall, which is usually the
main cause of high discharge, is usually character-
ized by statistical analysis and design hyetograph. Fi-
nally, flood management is the union of the preven-
tive, mitigating and recovery actions that must be ac-
complished. However, the management also involves
some processes like forecasting, economic evalua-
tion, etc. (different agents like the municipality are
in charge for each process).
The detailed ontology contains 2054 named
classes and this number has been reduced to 91 in
the brief ontology. Therefore, the brief ontology for
floods only includes the relevant knowledge for this
case of study.
As (Stuckenschmidt and Schlicht, 2009) says,
there is not golden standard to compare the results
with and the goodness of the brief ontology depends
on the application that will use the ontology. For this
reason, the resulting brief ontology has been posi-
tively evaluated by several experts in the targeted do-
main (floods). Nonetheless, the quality of the brief
ontology depends totally on the quality of the detailed
ontology.
5 CONCLUSIONS
In general, brief ontologies have a wide range of ad-
vantages when, for some reason, the user or applica-
tion does not wish to deal with the whole original on-
tology. Sometimes, the user is no interested in using
all the information or the application is not capable of
dealing with such a huge resources.
Moreover, reusing a large ontology when only a
small portion is useful and relevant for our applica-
tions may involve unfavourable consequences i.e. the
reasoning time increases with the size of the knowl-
edge base and this issue may be essential in real-time
applications. For this reason, the efficiency of our
knowledge base is improved by isolating portions of
knowledge from large ontologies in form of brief on-
tologies.
As an example, a case of study in flood manage-
ment has been presented. A brief ontology is created
specifying the initiator concept (flood) for the traver-
sal algorithm and the set of relevant properties to de-
cide which concepts on the ontology are relevant. The
result has been an ontology where the number of con-
cepts has been dramatically reduced and thus it con-
tains only concepts related to flood.
As future work, it is planned to develop metrics to
compare the detailed and brief ontologies. For exam-
ple, the abstraction degree of equivalent concepts in
both ontologies or the representativeness of the brief
ontology.
ACKNOWLEDGEMENTS
This work has been partially supported by re-
search projects (CICE) P07-TIC-02913 and P08-
RNM-03584 funded by the Andalusian Regional
Governments.
REFERENCES
Aho, A. V., Ullman, J. D., and Hopcroft, J. E. (1983). Data
Structures and Algorithms. Addison Wesley.
Baader, F., Calvanese, D., McGuiness, D., Nardi, D., and
Patel-Schneider, P. (2003). The Description Logic
Handbook: Theory, Implementation and Applications.
Cambridge University Press.
Bizer, C. and Seaborne, A. (2004). D2rq - treating non-
rdf databases as virtual rdf graphs (poster). In The
Semantic Web-ISWC.
De Wrachien, D., Mambretti, S., and Schultz, B. (2011).
Flood management and risk assessment in flood-
prone areas: Measures and solutions. Irrigation and
Drainage, 60(2):229–240.
Delgado, M., P
´
erez-P
´
erez, R., and Requena, I. (2005).
Knowledge mobilization through re-addressable on-
tologies. In EUSFLAT Conf., pages 154–158.
Directive 2007/60/CE (2004). Directive 2007/60/CE of the
European Parliament and of the Council of 23 Octo-
ber 2007 on the assessment and management of flood
risks (OJ L 288, 6.11.2007, p. 2734).
Fern
´
andez, M., G
´
omez, A., Pazos, J., and Pazos, A. (1999).
Ontology of tasks and methods. IEEE Intelligent Sys-
tems and Their Applications, 14(1):37–46.
Garrido, J. and Requena, I. (2010). Knowledge mobiliza-
tion to support environmental impact assessment. a
model and an application. In Proceedings - inter-
national Conference on Knowledge Engineering and
Ontology Development, KEOD, pages 193–199.
Garrido, J. and Requena, I. (2011a). Proposal of ontology
for environmental impact assessment. an application
with knowledge mobilization. Expert System with Ap-
plications, 38(3):2462–2472.
Garrido, J. and Requena, I. (2011b). Towards summaris-
ing knowledge: Brief ontologies. Submited to Expert
System with Applications.
BUILDING BRIEF ONTOLOGIES - A Case Study for Floods Management
35

Gu, H., Perl, Y., Geller, J., Halper, M., and Singh, M.
(1999). A methodology for partitioning a vocabu-
lary hierarchy into trees. Artificial Intelligence in
Medicine, 15(1):77–98.
Kim, J., Caralt, J., and Hilliard, J. (2007). Pruning bio-
ontologies. In Proceedings of the Annual Hawaii In-
ternational Conference on System Sciences.
Noy, N. and Musen, M. (2009). Traversing ontologies to
extract views. Lecture Notes in Computer Science
(including subseries Lecture Notes in Artificial Intel-
ligence and Lecture Notes in Bioinformatics), 5445
LNCS:245–260.
Staab, S. and Studer, R., editors (2009). Handbook on
Ontologies (International Handbooks on Information
Systems). Springer.
Stuckenschmidt, H. and Schlicht, A. (2009). Structure-
based partitioning of large ontologies. Lecture Notes
in Computer Science (including subseries Lecture
Notes in Artificial Intelligence and Lecture Notes in
Bioinformatics), 5445 LNCS:187–210.
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
36
