
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
Andr
´
e Lourenc¸o
1,2
, Liliana Medina
3
, Ana Fred
2
and Joaquim Filipe
3,4
1
Instituto Superior de Engenharia de Lisboa, Lisbon, Portugal
2
Instituto de Telecomunicac¸
˜
oes, Instituto Superior T
´
ecnico, Lisbon, Portugal
3
Institute for Systems and Technologies of Information, Control and Communication, Lisbon, Portugal
4
School of Technology of Set
´
ubal, Polytechnic Institute of Set
´
ubal, Set
´
ubal, Portugal
Keywords:
Unsupervised learning, Clustering, Clustering combination, Clustering ensembles, Text mining, Feature
selection, Concept induction, Metaterm.
Abstract:
Unsupervised organisation of documents, and in particular research papers, into meaningful groups is a diffi-
cult problem. Using the typical vector-space-model representation (Bag-of-words paradigm), difficulties arise
due to its intrinsic high dimensionality, high redundancy of features, and the lack of semantic information. In
this work we propose a document representation relying on a statistical feature reduction step, and an enrich-
ment phase based on the introduction of higher abstraction terms, designated as metaterms, derived from text,
using as prior knowledge papers topics and keywords. The proposed representation, combined with a cluster-
ing ensemble approach, leads to a novel document organization strategy. We evaluate the proposed approach
taking as application domain conference papers, topic information being extracted from conference topics or
areas. Performance evaluation on data sets from NIPS and INSTICC conferences show that the proposed
approach leads to interesting and encouraging results.
1 INTRODUCTION
The increase in the volume of scientific literature and
its dissemination using the Web is leading to an infor-
mation overload. Scientific literature comprises dif-
ferent kinds of publications, as scientific articles pub-
lished in journals, book chapters, papers in confer-
ences, technical reports, etc. This kind of literature
has a standardized structure (title, abstract, introduc-
tion, methods, results, conclusions), and typical writ-
ing style, resulting in very similar documents. One of
the key problems is that it is poorly categorized, being
difficult to retrieve all the main articles of a specific
topic.
Autonomous citation indexing (ACI) (Lawrence
et al., 1999) has been proposed to help the organi-
zation of scientific literature by automating the con-
struction of citation indices. A citation index cata-
logues the citations that an article makes, linking the
articles with the cited works. These mechanisms help
scientists to find work that cites their own work or is
relevant to their research, but does not solve the prob-
lem of documents organization.
Machine learning methods have been used
proposing several approaches for the problem. Docu-
ment clustering provides a possible solution, grouping
articles into categories, based on different informa-
tion extracted from them, using only the textual con-
tent of the article (Janssens et al., 2006)(Aljaber et al.,
2010), and/or the citation graph analysis (Ahlgren and
Jarneving, 2008; Boyack and Klavans, 2010).
The representation of the textual content of docu-
ments using the standard bag-of-words model is only
effective for grouping related documents when shar-
ing a large proportion of lexically equivalent terms.
This standard approach ignores synonymies and other
relations between words, which reduces the effective-
ness of this document representation scheme.
In this work we propose a methodology to clus-
ter scientific literature based on its textual content and
on a priori categorization of each document on broad
classes according to a classification system provided
to the authors. We propose an extension of the typical
bag-of-words representation introducing metaterms,
concepts derived from the text that try to go beyond
the syntax, forming a conceptualization that connects
related terms.
We follow a recent and promising trend in un-
supervised learning, namelly clustering combination
techniques (Fred, 2001; Fred and Jain, 2005; Strehl
557
Lourenço A., Medina L., Fred A. and Filipe J..
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS.
DOI: 10.5220/0003722905490560
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (SSTM-2011), pages 549-560
ISBN: 978-989-8425-79-9
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

and Ghosh, 2002; Hanan and Mohamed, 2008),
which typically outperform the results of single clus-
tering algorithms, achieving better and more robust
partitioning of the data, combining the information
provided by a clustering ensemble (CE). Moreover
this class of algorithms further enables the combina-
tion of several sources of information (e.g. citations)
for the clustering of scientific documents.
The remainder of the paper is organized as fol-
lows. Section 2 describes related work. Section 3
presents the proposed methodology, dividing the so-
lution in the following phases: stop-word removal (in
section 3.1); meta-terms creation (in section 3.2); and
clustering strategy (in section 3.3). Section 4 presents
the data sets used for evaluation and section 5 the
main results. Finally, in section 6 we draw the main
conclusions and future work.
2 RELATED WORK
Document categorization can be divided in two
stages: a) transforming the documents into a suitable
and useful data representation; b) organizing the data
into meaningful groups.
Consider a set of D documents X =
{
d
1
,...,d
D
}
to be clustered. Commonly, document information
is represented using a vector space model or bag-
of-words (Manning et al., 2008) where each docu-
ment, d
i
, is represented by document tokens aggre-
gated in a feature vector with F dimensions, d
i
=
{
w
1
,...,w
F
}
; w
j
, represents the relative importance
of each token in the document. Typically w
j
is com-
puted using the Term Frequency-Inverse Document
Frequency weighting (TF-IDF) (Sebastiani, 2005).
The most simple form of a token is a word, but com-
pound terms can also be used such as bigrams, tri-
grams and noun phrases.
Recent work (Hotho et al., 2003; Sedding and
Kazakov, 2004; Reforgiato Recupero, 2007), con-
siders not only syntactic information, obtained from
the terms present in a document, but also semantic
relationships between terms. These approaches are
mostly based on WordNet (Fellbaum, 1998), which
is a lexical database that groups English words into
sets of synonyms, called synsets. Most synsets are
connected to other synsets via several semantic rela-
tions, such as: synonymy, hypernymy, meronymy and
holonymy.
In (Hotho et al., 2003), the standard representa-
tion of a document is enriched with concepts derived
from WordNet, using several strategies: (a) replac-
ing terms by concepts; (b) using concepts only; (c)
or extending the term vector with WordNet concepts.
These strategies lead to a new document represen-
tation, d
0
i
, which includes a concept subspace, d
0
i
=
{
w
1
,...,w
F
,c
1
,...c
C
}
, where c
i
represents a concept.
These concepts correspond to hypernyms of ex-
tracted terms, that is to more generic words than the
extracted term. In (Hotho et al., 2003), the analysis
relied on single-term analysis, while in (Zheng et al.,
2009b) a more complete phrase-based analysis was
performed.
Concerning the clustering algorithm several ap-
proaches are followed in the literature. In (Hotho
et al., 2003; Sedding and Kazakov, 2004; Refor-
giato Recupero, 2007) a variant of the K-means, the
Bi-Section-K-means is used, stating that this method
frequently outperforms the standard K-means. In
(Boyack et al., 2011) a more complex partitioning of
the document collection is proposed. They start by
obtaining a graph of related documents, based on sev-
eral document similarity measures; after employing a
pruning step over the obtained graph, an average-link
algorithm is used to assign each document to a cluster
based on proximity of remaining edges. This process
is run 10 separate times with different starting points,
and the results are re-clustered, or combined, using
only those document pairs that are clustered together
in at least 4 of 10 preliminary solutions. The method
was evaluated on more than two million biomedical
publications.
3 PROPOSED APPROACH
The motivation behind the proposed methodology
consists on the unsupervised organization of scien-
tific papers into meaningful subsets, accomplished
through the derivation of a conceptualization relat-
ing terms that describe the categories used by authors
to classify their articles using a scientific classifica-
tion system, such as the ACM Computing Classifica-
tion System (ACM, 1998). This conceptualization is
created using a bottom-up approach, based on docu-
ments’ textual content. This information can be inter-
preted as a priori knowledge, and allows a more accu-
rate representation of documents content, improving
the typical bag-of-words representation.
Our approach differs from previous work, in two
perspectives: (a) the analysis of text relies on com-
pound terms; (b) we add hypernyms to the base rep-
resentation, which are not imposed by Wordnet, but
are instead extracted from the data textual content.
Figure 1 presents a general overview of the pro-
posed methodology.
We start by the extraction of single words, w
i
, and
compound terms, ct
j
(bigrams, trigrams and/or noun
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
558
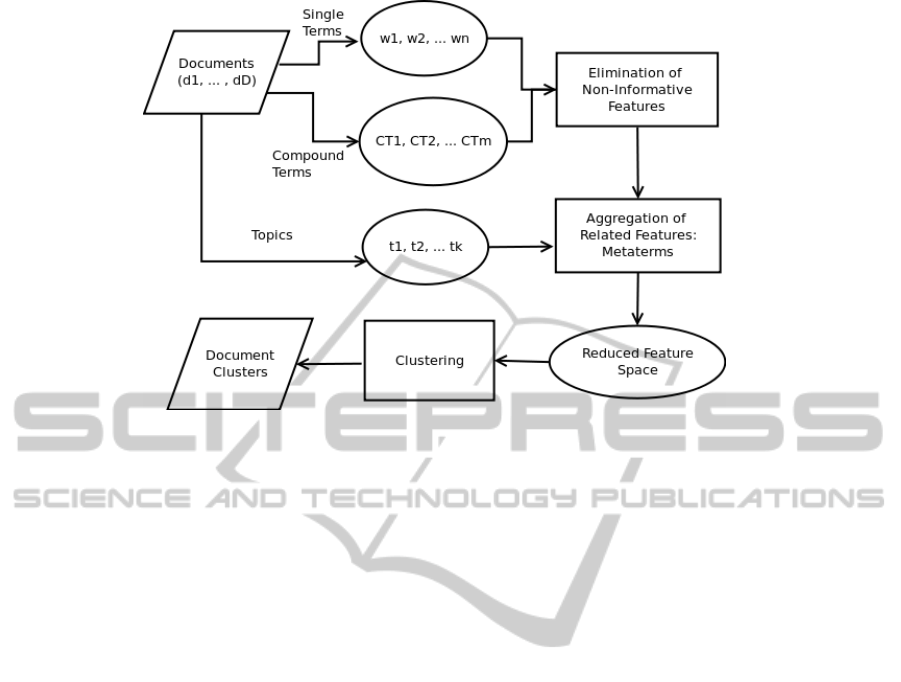
Figure 1: Proposed Methodology: (1) Document Representation; (2) Elimination of Non-Informative Features; (3) Aggrega-
tion of Related Features; (4) Clustering.
phrases) from the text; this takes place after removing
all the punctuation from the text, as well as mathe-
matical formulas. These features are extracted from
the documents using a natural language processing
(NLP) tool specifically built for this purpose. Each
document is represented by a feature space, composed
by, d
00
i
=
{
w
1
,...,w
M
,ct
1
,...ct
M
}
.
This representation has the following challenges:
• The dimensionality (w + m) is very high.
• Existence of redundant or irrelevant features.
• This representation does not take into account
the possible, semantic, relationships between fea-
tures.
In order to reduce the feature space, we pro-
pose two independent steps: (1) Removal of non-
informative words in the context of the document
collection; (2) Aggregation of related features (both
words and compound terms) into a more general
and more meaningful feature, which we refer to as
metaterm.
Our hypothesis is that the feature space reduction
by aggregating terms into metaterms will provide a
better, more accurate text representation.
Using this alternative representation, we finally
organize the documents using a clustering combina-
tion algorithm.
3.1 Context-dependent Stop-Word
Removal
Stop word removal is one of the most common ap-
proaches to non-informative feature removal. Stop-
words are terms that appear too frequently in doc-
uments and thus provide low discriminative power
(Van Rijsbergen, 1979). In this work, we go one
step further, assuming that this problem is context-
dependent. We address this problem applying a sta-
tistical criterion to the document collection in analy-
sis, trying to remove redundant or irrelevant features
of the type word: the percentage of documents where
the word occurs.
We consider that if a word occurs in a very high
percentage of documents, then it must not be very
meaningful in the context of the data set. The same
hypothesis is applied for the case when the term oc-
curs in a very small percentage of documents.
After applying this step over a data set, we expect
to obtain a reduced feature space comprised of the
most meaningful words and compound terms present
in the text.
3.2 Aggregation of Related Features:
MetaTerm Creation
In (Zheng et al., 2009a), concept induction is per-
formed using Latent Semantic Analysis (LSA) tech-
niques, based on single terms and common phrases
extracted from the documents. Relations between
concepts are constructed using WordNet, extracting
hypernyms for each detected concept. The draw-
back of this approach is the dependance on WordNet,
which is a general and context-independent resource.
We define a metaterm as the entity representing a
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
559
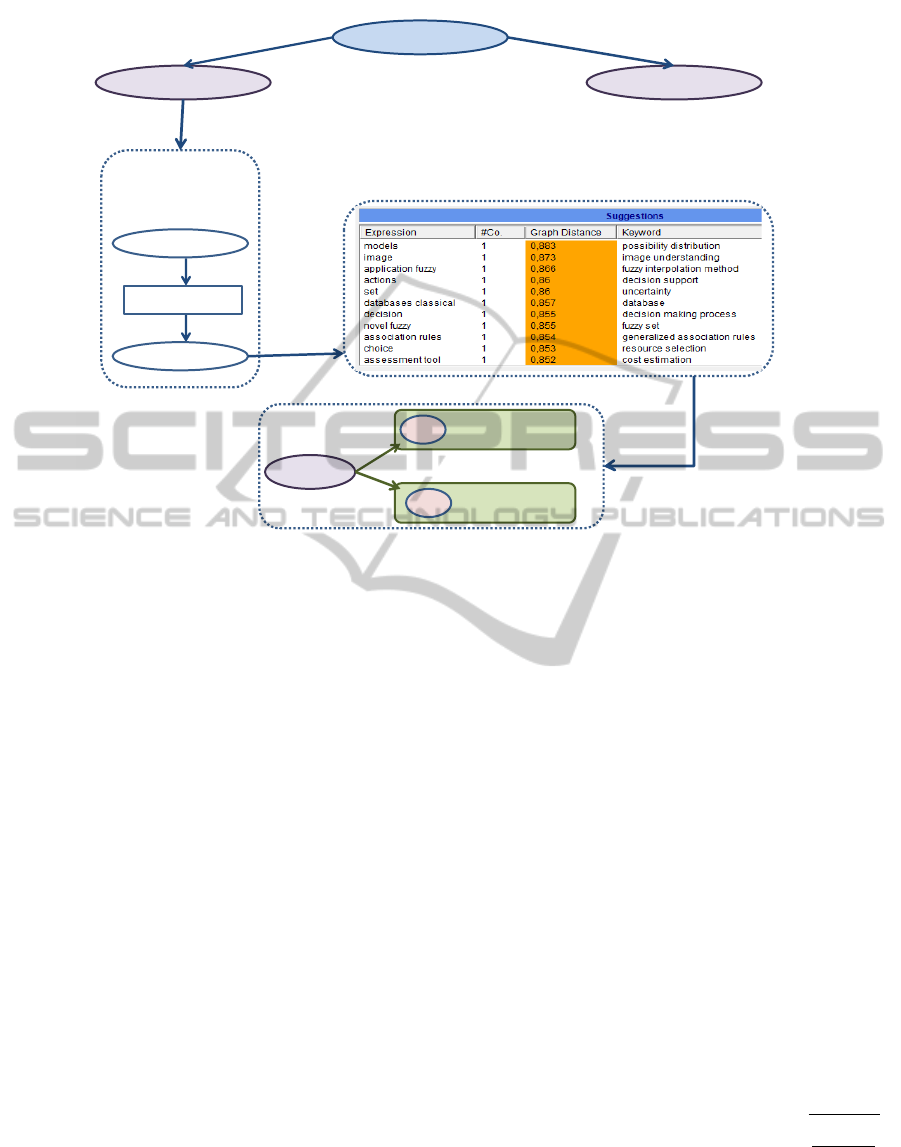
AREA 1
TOPIC 1 TOPIC N
. . . . . . .
Find the D documents
assigned to Topic 1.
d1, d2, .... , dD
k1, k2, .... , kK
f1, f2, .... , fF
Find the K keywords
assigned to the D
and find the F features
that occur in the subset.
Find semantic/syntactic relationships between keywords
and features.
TOPIC 1
mM
m1
k1
f1 f5 .... fF-2
kM
f4 f7 .... fF
. . . . . . .
Produce metaterms by
aggregating features that
satisfy one or more criteria.
docs
Figure 2: Aggregation of related features.
subset of words and/or compound terms which are ei-
ther synonyms or have some kind of semantic relation
(with variable degrees of ‘closeness’). These concepts
have a direct analogy to Wordnet hypernyms, since
they represent also higher-level expressions, but are
obtained using different sources.
Our approach uses as external source of a pri-
ori information the conference topics, assigned by
authors when submitting their work to conferences.
These topics are considered the roots of the metaterms
to be created. For each topic we analyse the keywords
provided for each document.
We propose as criterion for the extraction of
metaterms based on the keywords an adaptation of
the Lesk Algorithm (Dao and Simpson, 2005) (Baner-
jee and Pedersen, 2003). The Lesk Algorithm (Lesk,
1986) disambiguates words in short phrases, compar-
ing the dictionary definition or gloss of a given word
to the glosses of every other word in the phrase. A
word is assigned the sense whose gloss shares the
largest number of words with the glosses of the other
words. The used adaption consists of using WordNet
as dictionary, with senses arranged in a hierarchical
order. This criterion was chosen based on the assump-
tion that words in a given neighborhood will tend to
share a common topic.
Figure 2 presents these procedures, showing for
a given topic an example of terms/compound terms
related with keywords that will produce a metaterm.
The minimum number of co-occurrences/ Lesk Dis-
tance is specified by the user.
An example of three metaterms obtained for the
topic ”‘Datamining”’ may be observed in Figure 3.
Each metaterm was based on a particular keyword,
assigned to documents that belong to the chosen topic
(circled purple).
The reduced feature space represents each doc-
ument as d
new
i
=
{
m
1
,...,m
R
,w
1
,...,w
T
,ct
1
,...ct
L
}
,
where m
i
represents a metaterm, and w
j
and ct
j
single
terms and compound terms that were not aggregated.
We used the TF-IDF weighting scheme. Let’s de-
note t f
t
i
, j
as the frequency of the feature t
i
on the doc-
ument d
j
, when t
i
is either a word or a compound
term; and id f
t
i
as the the inverse frequency of t
i
.
The TF-IDF weight for a metaterm, m
i
is a combi-
nation of the frequency values of its components. Let
T be the number of components of m
i
. The number of
occurrences of this metaterm in a document d
j
, #m
i, j
is given by #m
i, j
=
∑
t∈T
#
t, j
where #
t, j
is the number
of occurrences of each term t ∈ T within d
j
. Let M
be the subset of metaterms that occur in d
j
: thus, the
frequency of m
i
in the document is t f
m
i
, j
=
#m
i, j
∑
q∈M
#m
q, j
The inverse frequency of m
i
is id f
m
i
= log
D
{d:m
i
∈D}
,
and finally
t f id f
m
i
, j
= t f
m
i
, j
× id f
m
i
(1)
The feature space may be further (or alternatively)
reduced by applying techniques such as Latent Se-
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
560
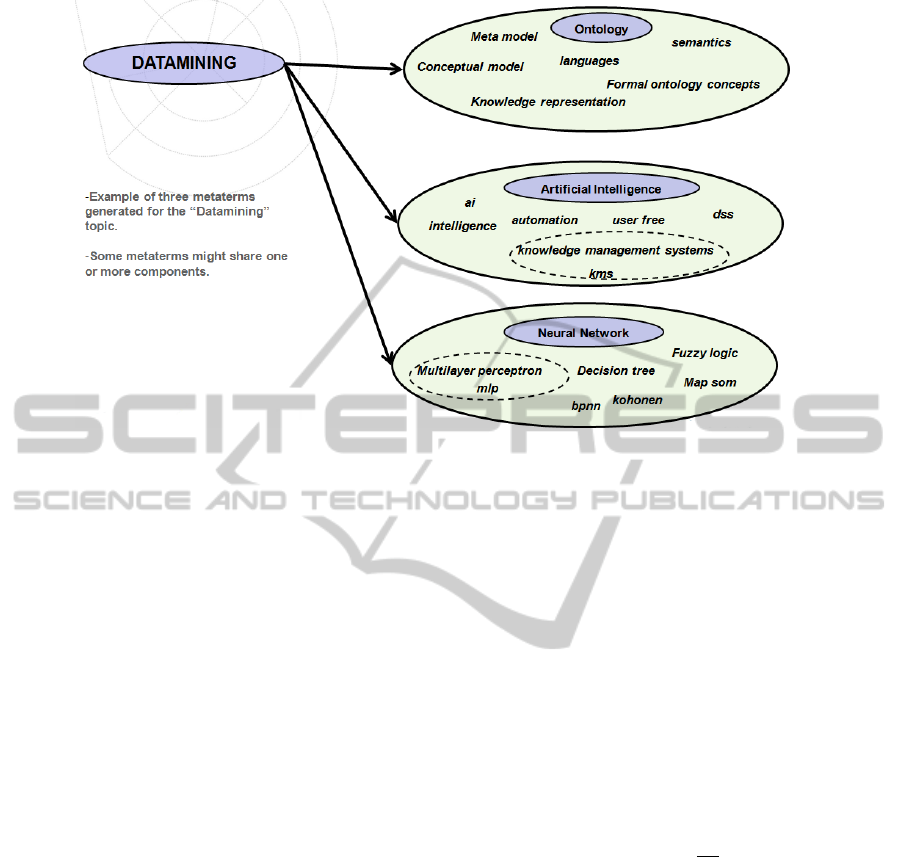
Figure 3: Three metaterms obtained for the topic ”‘Datamining”’, based on the keywords ”Ontology”, ”Artificial intelligence”
and ”Neural network”.
mantic Indexing (LSI), which reduces the number of
features by generating a new feature space that would
capture, ideally, the true (semantic) relationships be-
tween documents(Sevillano et al., 2009). It uses Sin-
gle Value Decomposition (SVD) to decompose the
TF-IDF matrix into a subset set of k orthogonal vec-
tors:
M = UΣV
T
, (2)
where M is a term-by-document matrix, U and V
T
are the left and right singular vectors matrices, and σ
is the singular values matrix. Dimensionality reduc-
tion is accomplished by retaining the first z columns
of matrix V (Sevillano et al., 2009). Therefore, the
dimensionality of the reduced feature space, z, must
be carefully chosen.
3.3 Clustering
A clustering algorithm organizes a set of objects, in
this case documents, into k clusters by generating a
partition of the data into k groups, P = {C
1
,...,C
k
}.
The assignment of these patterns into different clus-
ters is based on a given similarity or dissimilarity met-
ric such that the similarity between patterns of the
same cluster is greater than the similarity between
patters belonging to different clusters.
Different clustering algorithms lead in general to
different organization of patterns. A recent approach
consists on the production of a more robust clustering
results by combining the results of different partitions,
called the clustering ensembles (CE). A CE is a set of
N different partitions of X, P = {P
1
,...,P
N
}, where
each partition P
i
= {C
i
1
,...,C
i
k
i
}, has k
i
clusters. This
partitions can be generated by the choice of clustering
algorithms or algorithmic parameters, or using differ-
ent feature representations, as described in (Fred and
Jain, 2005).
Evidence Accumulation (EAC) is one of the clus-
tering ensemble methods that enables the combina-
tion of several partitionings of the data set. The un-
derlying assumption is that patterns belonging to a
natural cluster are very likely to be assigned in the
same cluster in different partitions. Taking the co-
occurrences of pairs of patterns in the same cluster as
votes for their association, the N data partitions of n
patterns are mapped into a n × n co-association ma-
trix:
C (i, j) =
n
i j
N
(3)
where n
i j
is the number of times the pattern pair (i, j)
is assigned to the same cluster among the N partitions.
This matrix corresponds to an estimate of the proba-
bility of pairs of objects belonging to the same group,
as assessed by the N partitions of the ensemble.
A consensus partition can be extracted applying a
clustering algorithm, which typically induces a hard
partition, to the co-association matrix (Fred and Jain,
2005). The decision on the number of clusters of the
consensus partition, might be based on specific cri-
teria, such as the cluster lifetime criterion (Fred and
Jain, 2005), or based on ground truth information.
In this work, as source for the clustering algo-
rithms we used the different representations of docu-
ments described before. The construction of the clus-
tering ensemble (CE) is generated using the k-means
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
561
algorithm, taking as distance measure one minus the
cosine of the angle between the vectors representing
the documents. Each partition of the ensemble is pro-
duced with a varying number of clusters. The mini-
mum and the maximum number of clusters were de-
termined as a function of the number of samples, n
s
,as
given by the expression (Lourenc¸o et al., 2010):
{K
min
,K
max
} = {dn
s
/Ae,dn
s
/Be}, with A = 50 and
B = 20.
For the extraction of the consensus partition
we used several hierarchical agglomerative methods
(Single Link - SL, Complete Link - CL, Average
Link - AL, Ward’s Link - WL), and Metis algorithm
(Karypis et al., 1998). The number of extracted clus-
ters is equal to the number of topics of each confer-
ence.
(a) NIPS
(b) ICEIS
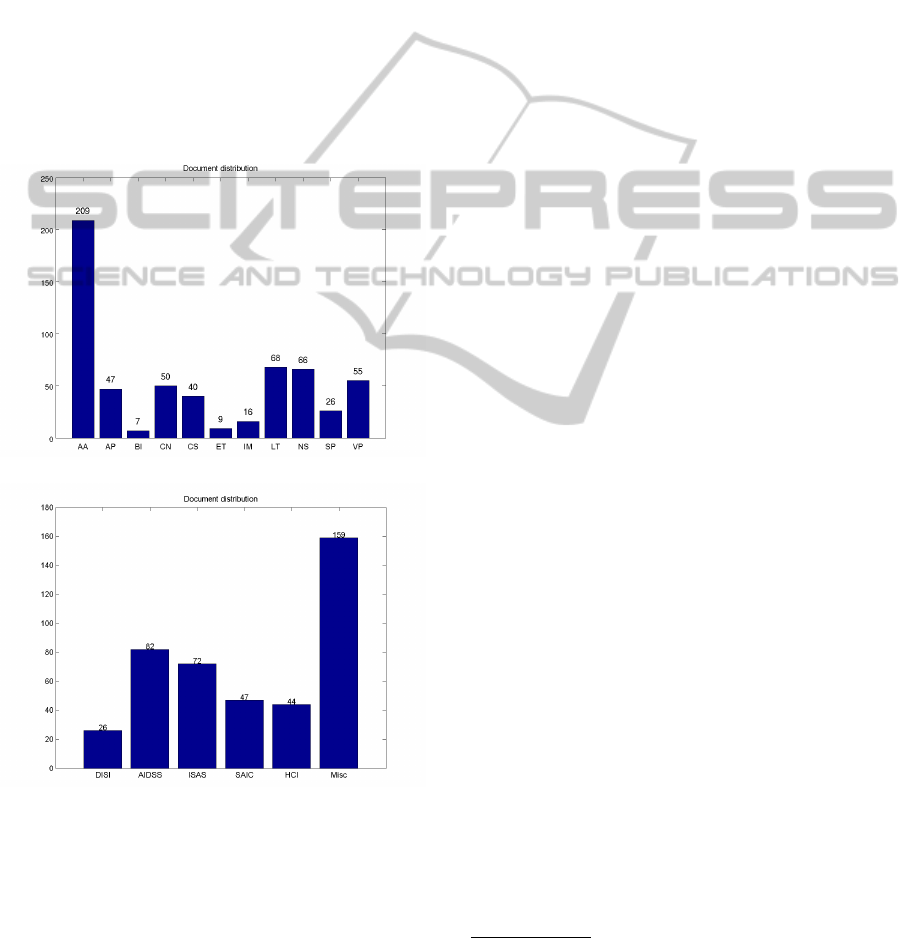
Figure 4: Documents distribution: 4(a) document-per-topic
distribution of the NIPS papers, and 4(b) document-per-area
distribution of the ICEIS papers.
4 EXPERIMENTAL SETUP
We applied the previously detailed methodology to
two data sets, referred to as NIPS and ICEIS.
The NIPS data set, built by (Globerson et al.,
2007), consists of 2484 documents from 17 NIPS
conferences held between 1987 and 2003. There
are 14036 distinct words occurring in this data set.
Given that the topic distribution for 593 documents
from years 2001 to 2003 is available, we applied our
methodology to this subset of papers. The original
feature space for this subset is comprised of 6881
words.
The ICEIS
1
data set consists of 430 documents
from one conference organized by INSTICC
2
in
2009. The ICEIS event is subdivided into 5 confer-
ence areas, and each area is further subdivided into
topics. Documents were grouped according to the
area / topic, in a total of 75 topics. This data set
contains 20460 distinct features (words, bigrams, tri-
grams, etc.).
Each NIPS topic has an associated set of ex-
pressions
3
, assigned by the conferences organizers.
Given that the papers submitted to NIPS conferences
do not have keywords assigned by the authors, we use
these expressions as keywords and search for docu-
ments where they occur in order to produce sugges-
tions for metaterms.
The ICEIS keywords-per-document assignment is
available, which allows us to combine this informa-
tion with the documents-per-topic information and
build specific metaterms.
Figure 4 depicts the topic distribution for both
data sets is. The topics for the NIPS data are: Al-
gorithms & Architectures (AA); Applications (AP);
Brain Imaging (BI) ; Control and Reinforcement
Learning (CN); Cognitive Science (CS); Emerging
Technologies (ET); Implementation (IM); Learning
Theory (LT); Neuroscience (NS); Speech and Sig-
nal Processing (SP); Vision Processing (VP). The AA
category is the largest with 209 documents, represent-
ing almost half of the documents of the collection. For
the ICEIS data set the topics are: Databases and Infor-
mation Systems Integration (DISI); Artificial Intelli-
gence and Decision Support Systems (AIDSS); Infor-
mation Systems Analysis and Specification (ISAS);
Software Agents and Internet Computing (SAIC);
Human-Computer Interaction (HCI); Miscelaneous
topic, representing documents with more than one
topic (Misc). This last category is the largest with
159 documents.
These categorizations are not very clear and many
times very fuzzy. Due to this reason, the methodology
followed for the evaluation of the results is not based
1
International Conference on Enterprise Information
Systems: http://www.iceis.org/
2
http://insticc.org/
3
http://nips.cc
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
562
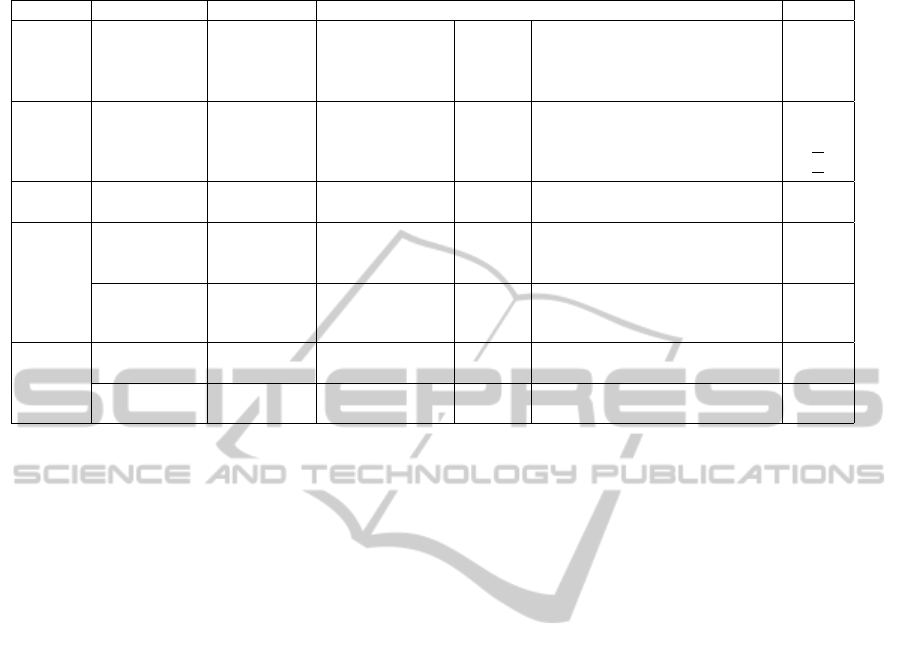
Table 1: Experimental framework: associated parameter values and description.
Experiment Data Set Task Algorithm/Parameter Description Value
1,2,3
NIPS and ICEIS Stopwords Re-
moval
Removal (%)
Max
SW
Maximum percentage of documents
where a word may occur.
12%
Min
SW
Minimum percentage of documents
where a word may occur.
0.5%
1,2,3
NIPS and ICEIS Clustering En-
semble K-Means
N
P
number of partitions 200
k
min
minimum number of clusters
N
s
50
k
max
maximum number of clusters
N
s
20
1,2,3 NIPS and ICEIS Extraction SL, CL, AL, WL,
metis
k lifetime Final partition’s cluster number 11 and 5
2
NIPS Feature space
reduction
LSI
M dimensionality of the new feature space 27
th threshold 0.4
ICEIS Feature space
reduction
LSI
M dimensionality of the new feature space 35
th threshold 0.5
3
NIPS
Aggregation
Lesk Algorithm L
th
minimum graph proximity between two
features for aggregation
0.9
ICEIS Aggregation Lesk Algorithm L
th
minimum graph proximity between two
features for aggregation
0.85
on accuracy calculation (based on this ground truth).
We analyse the clusters looking at the features of the
documents composing them, to the document distri-
bution, and to the pairwise similarity between the doc-
uments on each cluster (obtained from the application
of the EAC clustering algorithm).
To understand the impact of the metaterms, we
performed, over both data sets, the experiments de-
tailed below. The clustering is always performed us-
ing the EAC algorithm over a clustering ensemble of
200 partitions of the baseline representation, obtained
with the K-means algorithm.
Experiment 1. Our baseline experiment pertains
to the TF-IDF representation matrix obtained af-
ter applying the irrelevant feature removal step of
the methodology, with no aggregation of terms into
metaterms.
Experiment 2. The TF-IDF matrix is transformed
by applying LSI over the matrix obtained on Experi-
ment 1.
Experiment 3. Here, the feature aggregation step
for metaterm creation is performed in order to reduce
the dimensionality of the feature space. We explore
two criteria for term aggregation: Lesk algorithm and
co-occurrences, obtaining thus two different represen-
tations.
The different parameters associated with the ex-
periments are summarized in Table 1. For the Stop-
words removal we empirically verify that using as
minimum and maximum percentage of documents
having a token of 0.5% and 12%, respectively, we
conserved words that seemed important for distin-
guishing documents. For the aggregation of related
features step, we empirically chose 0.9 and 0.85 as
thresholds for the minimum graph proximity, for the
NIPS and ICEIS data set, respectively, trying to guar-
antee that only strong relations were chosen.
5 RESULTS AND DISCUSSION
Many studies compare cluster solutions based on pre-
defined document sets based on expert opinion. In the
present study we do not have such information, or the
available information is considered fuzzy. We chose
to evaluate the results based on the following: (1)
pairwise similarity between documents within clus-
ters, available in the co-association matrices obtained
by the EAC clustering algorithm; (2) distribution of
documents by topic; (3) Adaptation of within-cluster
textual coherence (Boyack and Klavans, 2010), based
on Jensen-Shannon divergence; (4) examples of most
relevant features of each cluster.
The co-association matrices obtained using EAC,
are represented by a color scheme ranging from blue
(C (i, j) = 0) to red (C (i, j) = 1), corresponding to
the magnitude of similarity, and the axis represent the
documents organized such that documents belonging
to the same cluster are displayed contiguously. This
information is also represented on the colorbar on top
of each figure, where each color represents the ob-
tained clusters. Well formed partitions have a pro-
nounced block-diagonal structure, revealing that the
similarity within clusters is very high when compared
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
563

to documents in different clusters.
Regarding the distribution of documents by topic,
we present histograms representing the number of
documents assigned to each topic on each of the ob-
tained clusters. Moreover, we present, at the top of
the histogram, a bar representing the confidence over
each cluster (ranging over the same color scheme as
before). This confidence is obtained based on the av-
erage similarity of pairwise associations within a clus-
ter.
The textual coherence (Boyack and Klavans,
2010), is computed based on Jensen-Shannon diver-
gence (JSD), which computes the distance between
two probability distributions, p and q:
JSD(p,q) = 1/2D
KL
(p,m) + 1/2D
KL
(q,m) (4)
where m = (p +q)/2, and D
KL
is the Kullback-Leiber
divergence
D
KL
(p,m) =
∑
(p
i
log(p
i
/m
i
)) (5)
We consider that p and q represent the probabilities of
words in two distinct documents. The JSD is calcu-
lated for each cluster as the average JSD value over all
documents in the cluster, represented as JSD
i
. JSD is
a divergence measure, meaning that if documents in a
cluster are very different from each other its value will
be very high; while if documents have very similar
words distributions, its value will be low. We obtain
the coherence of a partition, as a weighted average
over all clusters:
Coh =
∑
n
i
JSD
i
/
∑
n
i
, (6)
where n
i
is the number of documents per cluster.
In Experiment 1 - the baseline experiment, using
only the feature removal step, - the NIPS original fea-
ture space is reduced to 5660 words, and the ICEIS
feature space to 14987 distinct features.
Figure 5 presents the co-association matrices ob-
tained using EAC. When comparing figures 5(a) and
5(b), corresponding to co-association matrices from
the NIPS and ICEIS conferences, we see that the first
has a more pronounced block-diagonal structure, hav-
ing clusters apparently more separated. The distribu-
tion of documents by topics is represented in figure
6. For the NIPS data set, the majority of the clusters
joins several topics (except for clusters 3 and 4); for
the ICEIS data set the same happens.
With Experiment 2, we obtained a smaller fea-
ture space, applying LSI over the TFIDF matrix ob-
tained in the previous experiment. The obtained co-
association matrix, for the NIPS data set, has a less
obvious block-diagonal structure, with several micro-
structures representing small clusters; for the ICEIS
data set the cluster structure is more evident.
Figure 7 presents the distribution of documents by
topics. In the case of NIPS data set, the clusters ap-
pear to be more confused, apparently resulting from
the grouping of small clusters. In the case of ICEIS,
the clusters are better defined than those of experi-
ment 1, with cluster 3 being composed almost entirely
by topic 2; nevertheless this partitioning is still very
mixed in terms of the distribution of topics per clus-
ters.
Finally, in Experiment 3, we summarize the re-
sults obtained using metaterms using an adapted ver-
sion of the Lesk Algorithm. We chose as mini-
mum threshold for aggregating terms normalized dis-
tances above 0.9 (ie, normalized distance in the Word-
Net graph from the keyword that ”generates” the
metaterm). From this, 24 metaterms were created
for the NIPS data set, and 694 for the ICEIS data
set. The reason why ICEIS has a much larger num-
ber of metaterms is because information about which
keywords were assigned to which papers was made
available, unlike the NIPS case. Figure 8 presents the
cluster distribution for this experiment. For the NIPS
data set, there are several clusters (3,4,5,11) that are
composed mainly by one topic. In the case of ICEIS
data set, the clusters are better defined than before,
with cluster 3,4, and 6, being composed by almost
only one topic.
As final note for the graphics of the documents
by topics, we observe little correlation between the
clusters obtained and the original document-per-topic
distribution. This is expected for NIPS data set, due
to the fact that some of the conference topics are
quite broad (such as ”Algorithms and Applications”
or ”Emerging Technologies”); the same is also ex-
pected for ICEIS data set given that about 160 docu-
ments are assigned to more than one area, which sug-
gests that these are sometimes transversal.
The textual coherences of the different experi-
ments are depicted in figure 9. As one can observe,
the lower values of textual coherence are obtained for
Experiment 3, using the Lesk criteria (Exp3-Lesk).
Regarding other experiments, the presented values
follow the conclusions already drawn, showing that
employing feature aggregation into metaterms pro-
duces better results than the original TF-IDF feature
spaces, and than when using the feature space reduc-
tion obtained using LSI.
Finally, we show a few examples of the most
relevant features within each of the extracted clus-
ters in Table 2. For experiment 1, we show some
of the single features which have the highest TF
within the cluster, and for experiment 3 we display the
metaterms with the highest values. We observe that
there are still some features that do not add relevant
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
564
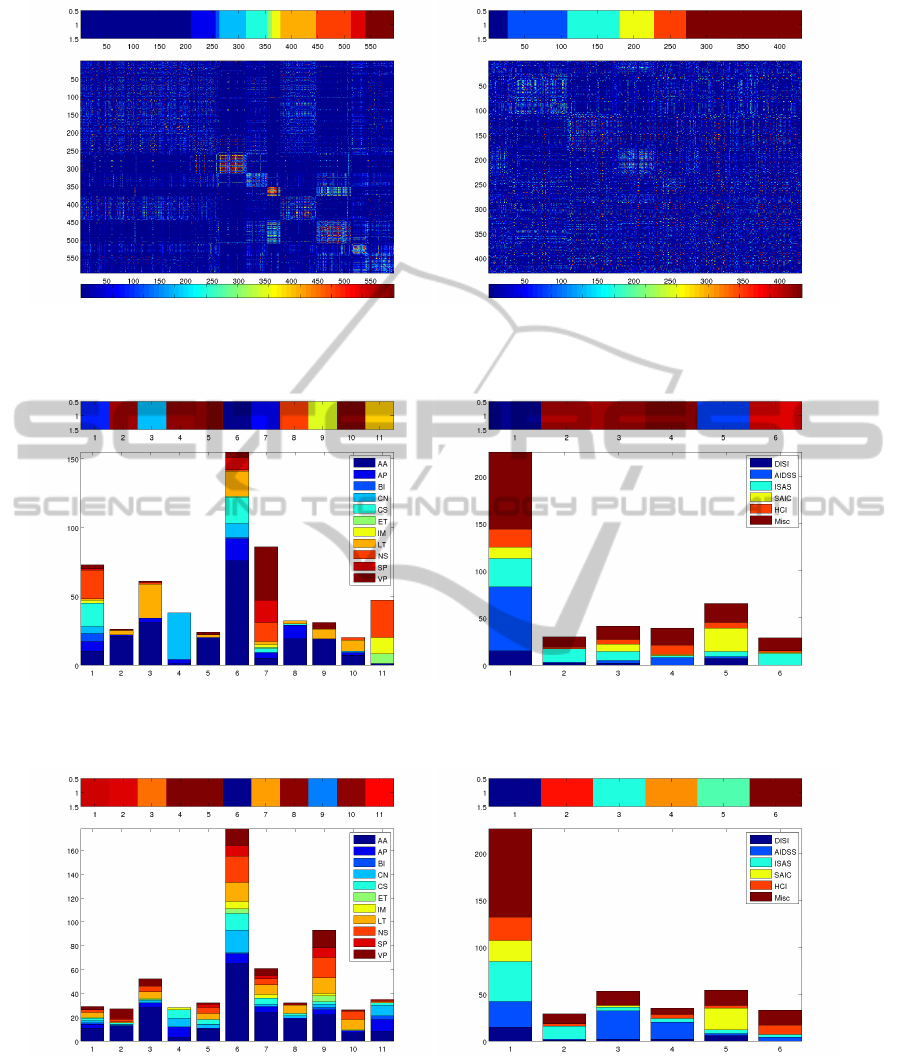
(a) NIPS (b) ICEIS
Figure 5: Graphical representation of the co-association matrices obtained for experiment 1 over the NIPS and ICEIS data set
(with document distribution).
(a) NIPS (b) ICEIS
Figure 6: Experiment 1 Results - clustering of documents based on TFIDF - for each cluster we show the distribution of
documents by topics (different colors). At the top is represented the confidence of each clustering.
(a) NIPS (b) ICEIS
Figure 7: Experiment 2 Results - clustering of documents based on TFIDF - for each cluster we show the distribution of
documents by topics (different colors). At the top is represented the confidence of each clustering.
information to the documents’ characterization, such
as ”summary” or ”notable”. This suggests that the
contextual stopwords-removal step might still be fur-
ther improved. Regarding the metaterms, in some sit-
uations the number of aggregated terms is high (>30),
joining terms that can have multiple meanings, intro-
ducing errors in the representation.
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
565
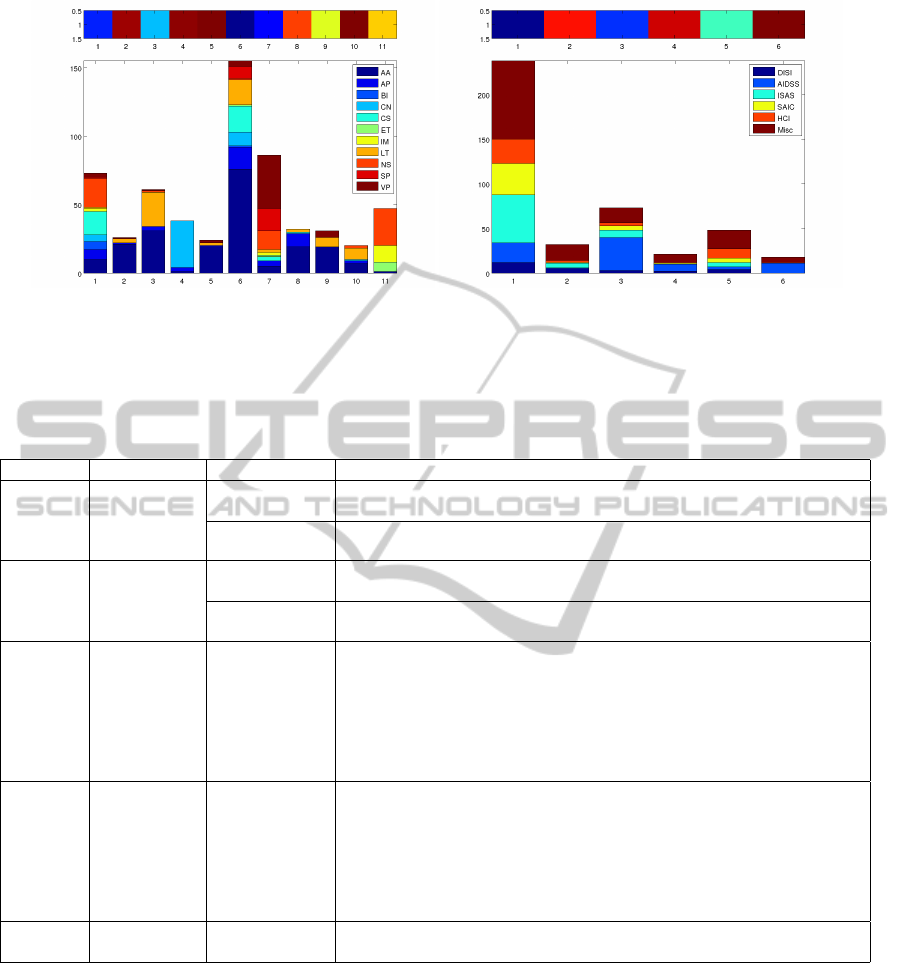
(a) NIPS (b) ICEIS
Figure 8: Experiment 3 Results (using Lesk Algorithm) - clustering of documents based on TFIDF - for each cluster we show
the distribution of documents by topics (different colors). At the top is represented the confidence of each clustering.
Table 2: Examples of the most relevant features found for some of the extracted clusters. The keywords that serve as root for
the metaterms are bolded. Notice how the two aggregation criteria generate aggregate different features based on the same
keyword (image processing).
Data Set Exp. Cluster Index Relevant Features
NIPS
1
2 frey; epochs; demonstrates; fischer; decoupled; freedman; dependency;
cal; eter; book
10 calls; centre; dec; extreme; broomhead; avg; disturbance; corporation;
affine; colinear
ICEIS
1
3 information;design; systems; paper;location; information systems; con-
text; architecture; method
4 data; spatial; information; schema; warehouse; mining; query; emer-
gency
NIPS 3 (Lesk) 6 image processing; res shape; res shape; images required; ground roc;
operation stereo; treat; treats; ground images; images shape; ring; es-
timates stereo; estimates stereo; proposed shape; sets; experts images;
forms model; shape variation; images material; performance shape; im-
ages truth; double profiles; implement res; sorts; effect textures; im-
ages occlusion; imaging; captures shape; direct shape; variation; model
truth; shape stereo; occlusions res; map shape; images texture
NIPS 3 (CoOccur.) 3 image processing; instances; temporally; chance; effort; consid-
ered; aligned; interface; kernels; multiplied; cropped ;include ;items
;shape shape ;sorted ;specifications ;formalize ;identically ;improved
;kai ;probabilistic ;math ;post ;contaminated ;rows ;consumption ;den-
dritic ;extend ;joachims ;recipes shape ;arguments ;complexity ;corner
;defer ;designer ;failed ;mika ;notable ;presynaptic ;states ;summary
;terrence ;tradeoff ;tuning
ICEIS 3 queries ;query rewriting ;query ; coresparql; sparql; queries; opti-
mization; optimization query; query optimization; query;
6 CONCLUSIONS AND FUTURE
WORK
We proposed a methodology for unsupervised organ-
isation of documents, and in particular research pa-
pers, into meaningful groups. The clustering was
based on a ensemble approach - Evidence Accumu-
lation Clustering (EAC) - which combines the re-
sults of different clusterings, the clustering ensem-
ble. We compared two different documents repre-
sentations: the typical vector-space-model, and an al-
ternative representation based on metaterms - which
are a subset of words and compound terms that are
either synonyms or have some kind of semantic re-
lation. Both representations relied on a first step of
statistical feature reduction. For the metaterm extrac-
tion we devised a criterion based on an adaptation
of the Lesk Algorithm which, from keywords or top-
ics assigned to the documents, aggregates words and
compound terms (bigrams and trigrams) extracted
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
566
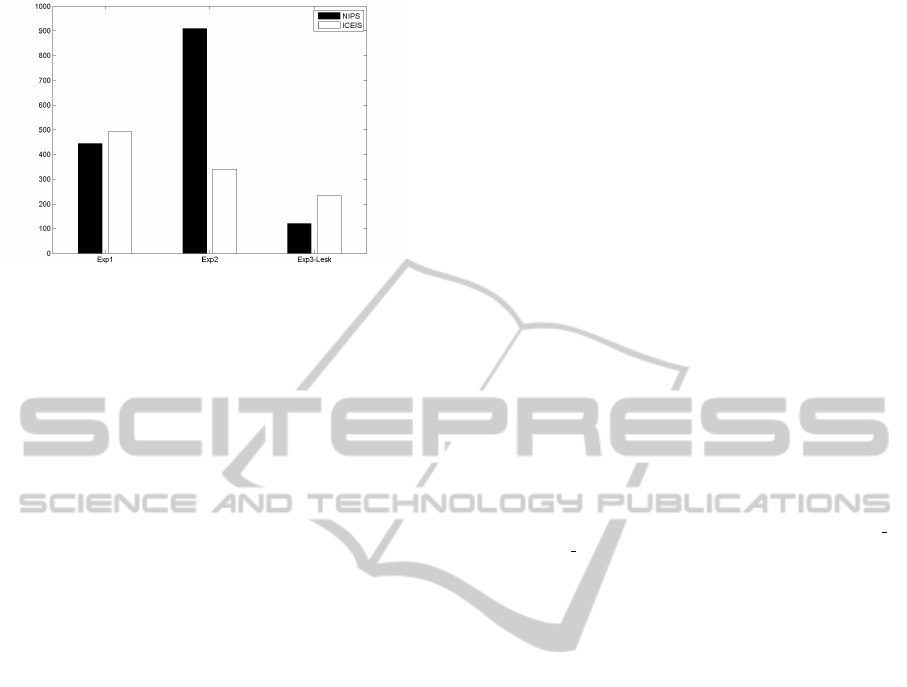
Figure 9: Textual Coherence over different experiments.
from the text. To evaluate the proposed methodol-
ogy we used two real-word data sets from conferences
NIPS and ICEIS. We also evaluated this methodology
against results obtained by applying LSI to the origi-
nal feature space.
To evaluate the results, we followed an unsuper-
vised approach, based on the observation of the ob-
tained co-association matrices, and on the within clus-
ter textual coherence. Based on both, we conclude
that feature reduction by employing feature aggrega-
tion into metaterms produces better results than both
the original TF-IDF feature spaces and the one using
the feature space reduction obtained by LSI.
As future work we want to improve the criteria
for feature aggregation, including a supervised step
of user annotation, and combining different criteria
(statistical and string comparison). Additionally, we
will use the EAC clustering combination algorithm
to combine the information already in use (titles and
abstracts) with citation information. Another of the
possible approaches is the usage of other ontologies
(besides WordNet) for the discovery of semantic rela-
tionships between features and documents, enabling
better aggregation of features.
ACKNOWLEDGEMENTS
This work was partially developed under the grants
SFRH/PROTEC/49512/2009 and PTDC/EIACCO/
103230/2008 (project EvaClue) from Fundac¸
˜
ao para
a Ci
ˆ
encia e Tecnologia(FCT), and project RETE, ref-
erence 3-CP-IPS-3-2009, from IPS/INSTICC, whose
support the authors gratefully acknowledge.
REFERENCES
(1998). Acm computing classification system. http://
www.acm.org/about/class/1998.
Ahlgren, P. and Jarneving, B. (2008). Bibliographic cou-
pling, common abstract stems and clustering: A
comparison of two document-document similarity ap-
proaches in the context of science mapping. Sciento-
metrics, 76:273–290. 10.1007/s11192-007-1935-1.
Aljaber, B., Stokes, N., Bailey, J., and Pei, J. (2010). Doc-
ument clustering of scientific texts using citation con-
texts. Inf. Retr., 13:101–131.
Banerjee, S. and Pedersen, T. (2003). Extended gloss over-
laps as a measure of semantic relatedness. In In Pro-
ceedings of the Eighteenth International Joint Confer-
ence on Artificial Intelligence, pages 805–810.
Boyack, K. W. and Klavans, R. (2010). Co-citation analy-
sis, bibliographic coupling, and direct citation: Which
citation approach represents the research front most
accurately? Journal of the American Society for Infor-
mation Science and Technology, 61(12):2389–2404.
Boyack, K. W., Newman, D., Duhon, R. J., Klavans, R.,
Patek, M., Biberstine, J. R., Schijvenaars, B., Skupin,
A., Ma, N., and Brner, K. (2011). Clustering more
than two million biomedical publications: Compar-
ing the accuracies of nine text-based similarity ap-
proaches. PLoS ONE, 6(3):e18029.
Dao, T. N. and Simpson, T. (2005). Measuring similarity
between sentences. http://opensvn.csie.org/WordNet
DotNet/trunk/Projects/Thanh/Paper/WordNetDotNet
Semantic Similarity.pdf.
Fellbaum, C. (1998). WordNet: An Electronical Lexical
Database. The MIT Press, Cambridge, MA.
Fred, A. (2001). Finding consistent clusters in data parti-
tions. In Kittler, J. and Roli, F., editors, Multiple Clas-
sifier Systems, volume 2096, pages 309–318. Springer.
Fred, A. and Jain, A. K. (2005). Combining multiple clus-
tering using evidence accumulation. IEEE Trans Pat-
tern Analysis and Machine Intelligence, 27(6):835–
850.
Globerson, A., Chechik, G., Pereira, F., and Tishby, N.
(2007). Euclidean Embedding of Co-occurrence Data.
The Journal of Machine Learning Research, 8:2265–
2295.
Hanan, G. A. and Mohamed, S. K. (2008). Cumulative
voting consensus method for partitions with variable
number of clusters. IEEE Trans. Pattern Anal. Mach.
Intell., 30(1):160–173.
Hotho, A., Staab, S., and Stumme, G. (2003). Wordnet im-
proves text document clustering. In In Proc. of the
SIGIR 2003 Semantic Web Workshop, pages 541–544.
Janssens, F., Leta, J., Glanzel, W., and De Moor, B. (2006).
Towards mapping library and information science. Inf.
Process. Manage., 42:1614–1642.
Karypis, G., Kumar, V., and Kumar, V. (1998). Multilevel k-
way partitioning scheme for irregular graphs. Journal
of Parallel and Distributed Computing, 48:96–129.
Lawrence, S., Giles, C. L., and Bollacker, K. (1999). Digi-
tal libraries and autonomous citation indexing. Com-
puter, 32:67–71.
Lesk, M. (1986). Automatic sense disambiguation using
machine readable dictionaries: how to tell a pine cone
from an ice cream cone. In Proceedings of the 5th
annual international conference on Systems documen-
UNSUPERVISED ORGANISATION OF SCIENTIFIC DOCUMENTS
567

tation, SIGDOC ’86, pages 24–26, New York, NY,
USA. ACM.
Lourenc¸o, A., Fred, A., and Jain, A. K. (2010). On the scal-
ability of evidence accumulation clustering. In ICPR,
Istanbul Turkey.
Manning, C. D., Raghavan, P., and Schtze, H. (2008). In-
troduction to Information Retrieval. Cambridge Uni-
versity Press.
Reforgiato Recupero, D. (2007). A new unsupervised
method for document clustering by using wordnet lex-
ical and conceptual relations. Information Retrieval,
10:563–579. 10.1007/s10791-007-9035-7.
Sebastiani, F. (2005). Text categorization. In Text Mining
and its Applications to Intelligence, CRM and Knowl-
edge Management, pages 109–129. WIT Press.
Sedding, J. and Kazakov, D. (2004). Wordnet-based text
document clustering. In Proceedings of the 3rd Work-
shop on RObust Methods in Analysis of Natural Lan-
guage Data, ROMAND ’04, pages 104–113, Strouds-
burg, PA, USA. Association for Computational Lin-
guistics.
Sevillano, X., Cobo, G., Al?as, F., Socor?, J. C., Arqui-
tectura, E., and Salle, L. (2009). Robust document
clustering by exploiting feature diversity in cluster en-
sembles.
Strehl, A. and Ghosh, J. (2002). Cluster ensembles - a
knowledge reuse framework for combining multiple
partitions. J. of Machine Learning Research 3.
Van Rijsbergen, C. J. (1979). Information Retrieval. But-
terworth, London.
Zheng, H.-T., Borchert, C., and Kim, H.-G. (2009a). Ex-
ploiting corpus-related ontologies for conceptualizing
document corpora. J. Am. Soc. Inf. Sci. Technol.,
60:2287–2299.
Zheng, H.-T., Kang, B.-Y., and Kim, H.-G. (2009b).
Exploiting noun phrases and semantic relationships
for text document clustering. Information Sciences,
179(13):2249 – 2262. Special Section on High Order
Fuzzy Sets.
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
568
