
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT
OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
Andrés Cancer
1
, Cristina del Campo
2
and Carlos Gascón
1
1
Telecom NGOSS, Indra, Madrid, Spain
2
Department of Estadística e Investigación Operativa II, Universidad Complutense de Madrid, Madrid, Spain
Keywords: Severe Network Faults, Customer Care, Service Management, Impact Evaluation.
Abstract: Despite the effort that has been carried out in the last two decades, there is still a huge gap between the
information that network management systems can provide to identify and solve network problems, and the
information they offer to determine the actual impact of these problems on basic telecommunication
services. This paper presents a new method (called SICAEN) to identify and characterize service impact
incidents using network resource unavailability information as an input. Most of the previously done work
tries to identify the root cause of a failure, while SICAEN is concerned with the actual impact of the failure,
from a user (service) perspective. The method performs impact evaluation in a per-service basis and has
been successfully applied in real world in the context of Telefonica’s IMPACTA project, whose goal is to
determine the impact of severe network faults on mobile basic services for the Spanish biggest mobile
operator.
1 INTRODUCTION
A big effort has been carried out in the last two
decades in order to define the structure of
telecommunication network faults and their
treatment by a network fault management system. In
fact, during these last two decades
telecommunication service providers, network
equipment providers, software vendors and system
integrators have tried to define and standardize the
structure and the management of network faults.
Some of the most widely accepted proposals in this
area are:
ITU-T X733 Alarm Reporting Function
(ISO/IEC 10164-4).
3GPP Alarm Integration Reference Point
(3GPP) .
OSS/J Quality of Service API (Åberg, 2002)
and Fault Management API (Raymer and
Flauw, 2007).
Multi-Technology Operation System Interface
(MTOSI) Release 1.0 (TMFORUM-MTOSI).
These proposals define management solution
sets, but each of them has a different background
since they evolve from working groups related to
specific network technologies. This is the case of
3GPP, focused on mobile networks, and MTOSI, on
transport technologies, while others evolve from
solutions for fixed networks from the 90’s as is the
case of ITU-T, the former CCITT, and OSS/J who
tries to define a J2EE standard for network
management. All of these proposals are roughly
equivalent and recently some efforts have been made
to integrate them (Raymer, 2004).
Nowadays, there is a wide range of commercial
operation support systems that implement, to a
certain extent, some of the aforementioned
proposals. This adoption has made it easy to achieve
system interoperability and, what is more, to
improve network oriented management processes
whose goal is to identify and solve network issues
and events.
Nevertheless, there is still a wide gap between
the information operation support systems provide to
identify and solve network problems, and the
information they can offer to determine the actual
impact of these problems on basic
telecommunication services. In fact most of service
impact analysis is done manually, based on the
knowledge of the network topology provided by the
maintenance experts. It must be also noticed that,
154
Cancer A., del Campo C. and Gascón C..
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC TELECOMMUNICATION SERVICES.
DOI: 10.5220/0003726601540163
In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART-2012), pages 154-163
ISBN: 978-989-8425-96-6
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

although the information related to a service impact
is based on network data, it has an independent life-
cycle and scope, so the raw network data must be
processed to obtain service impact information. This
detailed service impact knowledge is essential to
prioritize repairing actions on severe network faults,
to take new network planning decisions and, more
generally, to achieve higher levels of service and, by
extent, of customer satisfaction. It must be noted that
the TeleManagement Forum (TM Forum) clearly
states (see TMFORUM-eTOM and TMFORUM-
TAM) that the billing/invoice service must be feed
with information about service impacts in order to
trigger the appropriate customer care actions if
appropriated (v.g. SLA violation treatment). This is
also enforced by law in some EU countries, like
Spain (see Real Decreto 424/2005).
In order to fill this gap, the first issue to be dealt
with is the lack of a clear and widely accepted
definition for service impact incidents. These
incidents have a complete life-cycle with a well
defined start and end point but, in opposition to
standard network faults, their nature and their scope
can vary meaningfully over time, presenting
different intermediate states. Therefore, to be able to
capture all the data needed to track and to record the
service impact incident life-cycle, a more complex
definition and structure for service faults is needed.
The TeleManagement Forum has recently launched
a working group (TMFORUM-NGOSS) to define all
these items.
This paper presents a new method that has been
developed to identify and characterize service
impacting incidents using network resource
unavailability information as an input. The method
performs impact evaluation in a per-service basis
and has been identified with the name SICAEN. The
method has been successfully applied in the context
of Telefonica’s IMPACTA project whose main goal
was to determine the impact of severe network faults
on mobile basic services (GMS voice, GPRS data,
UMTS voice, UMTS data, etc).
The rest of the paper is organised as follows:
Section 2 provides some basic definitions and
architectural assumptions. Then Section 3 presents
the different stages of the SICAEN method.
Implementation results indicating the effectiveness
of the approach are presented in Section 4, and
finally future work and conclusions are drawn in
Section 5.
2 PREVIOUS DEFINITIONS
Most of the concepts that are going to be used in the
development of this paper are well known and their
definitions can be found in the references (see for
example Jakobson and Weissman, 1993), but,
although SICAEN will be presented in the following
sections, there are certain definitions and
architectural assumptions that must be introduced in
order to fully understand the scope and mechanisms
employed.
The formerly mentioned proposals use a basic
fault definition (see ISO/IEC 10164-4, 3GPP, Åberg
2002, Raymer and Flauw 2007 and TMFORUM-
MTOSI) as a basis for their fault management
processes and interfaces. As it has already been
stated, this definition is clearly insufficient to handle
service impact incidents, so new concepts and new
structures must be defined to manage them. Along
this paper, “Service Incident” stands for a
telecommunication service unavailability affecting a
geographical area and/or a defined group of
customers. Service Incidents may evolve
dynamically, featuring a complete life-cycle, during
which they may change their affection scope, may
disappear once the affection scope is void, may be
aggregated with another Service Incident, may be
divided in two or more independent parts, etc.
Regarding the architecture, SICAEN does not
define and implement a complete OSS, but it
complements the concept of OSS with service
impact generation. Therefore SICAEN assumes the
existence an OSS solution which provides network
management facilities (i.e Fault and Configuration).
This implies that SICAEN can be deployed as an
independent module of the OSS or as a completely
independent system, accessing to the underlying
OSSs. This last configuration would be typical on a
multivendor environment since the SICAEN method
needs access to the different network events
provided by the underlying network managers.
Also, SICAEN follows the recommendations of
the TM Forum about data stewardships so it requires
the existence of a corporate repository and unified
resource identifiers. A corporate repository of the
network resources is needed in order to complete the
information provided by the underlying OSS. Also,
since the SICAEN method will integrate different
sources of events and will make use of the corporate
network repository, a unified network resource
identifier (UNRI) for every element must be
provided to be able to correlate all these sources.
This unified identifier, UNRI, will be used to
retrieve information from the corporate repository.
Finally, as it will be shown in following sections,
SICAEN method requires a rich detailed knowledge
of the role and characteristics of each element, so it
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
155

can integrate the events originated by each element
in the appropriated service impact incident.
3 SICAEN METHOD
SICAEN is an acronym formed by the initial letter
of each of the five Spanish-named stages which
constitute the method: SI for “Selección de
Indisponibilidades” (Unavailability Selection), C for
“Consolidación” (Consolidation), A for
“Agregación” (Aggregation), E for “Estabilización”
(Stabilization) and N for “Notificación”
(Notification).
In the following sections the different stages of
the method will be presented along with the
concepts that emerge from them.
3.1 First Stage: Unavailability
Selection
The first stage (see Figure 1), named “Unavailability
Selection (SI)”, collects unavailability data from
network elements and network element managers
and selects any alarm, state change event or operator
action record representing a total unavailability of a
network resource or the end of the unavailability
condition. As an example, in the context of
IMPACTA project, aimed to identify the impact of
severe network faults on mobile basic services, the
method selects and catalogues unavailability
network resource conditions and restorations.
Although the list is not exhaustive, some of the most
relevant conditions are:
GSM cell service unavailable.
GSM cell service available.
GSM cell manually locked.
GSM cell manually unlocked.
BSC function unavailable.
BSC function available.
MSC function unavailable.
MSC function available.
UMTS cell service unavailable.
UMTS cell service available.
UMTS cell manually locked.
UMTS cell manually unlocked.
HLR function unavailable.
HLR function available.
SGSN function unavailable.
SGSN function available.
Each of these un/availability conditions can be
generated by a variable range of alarms, events or
manual actions extracted from log records. This
range differs from one network technology to
another. SICAEN method first stage (SI) transforms
(see Figure 1) alarms, state change events and
records into catalogued un/availability conditions
and forwards them to the next stage as a new kind of
notification called Service Potential Incidents (SPI).
These notifications can be firing notifications (SPI-
F) or clearing ones (SPI-C) and they convey
information regarding the un/availability condition
such as its type, the starting and/or ending time and
the affected network resource identity using the
aforementioned unified network resource identifier
UNRI (see Section 2).
This transformation process may be a simple
mapping of the received events. That is to say, just
an event acquisition from some kind of event source
followed by a network resource identity resolution.
This kind of schema can be implemented in a quite
straight forward way, although the SPI can be
defined as a complex combination of simple events
and a more sophisticated approach may be needed
using techniques such as correlation engines as
described in (Forgy, 1979 and 1982) in order to
produce the SPI.
Figure 1: SICAEN First Stage: Unavailability Selection.
It must be noted that multiple “Unavailability
Selectors”, each of them using different sources, can
be employed simultaneously to feed the next stage.
This may lead to duplicated SPIs for a given
network resource, but it may provide a simpler way
to integrate different sources or even to provide
some resilience to failures on the fault reporting
functions. This event redundancy must be dealt by
A
larms
State Change Events
Operator Action
Records
SICAEN Method
Second Stage: Consolidation (C)
Service Potential Incidents (SPI)
{
Firing (SPI-F)/Clearing (SPI-C),
Incident Type,
Starting Date-Time,
Ending Date-time,
A
ffected Network Resource Id,
….
}
SICAEN Method First Stage:
Unavailability Selection (SI)
ICAART 2012 - International Conference on Agents and Artificial Intelligence
156
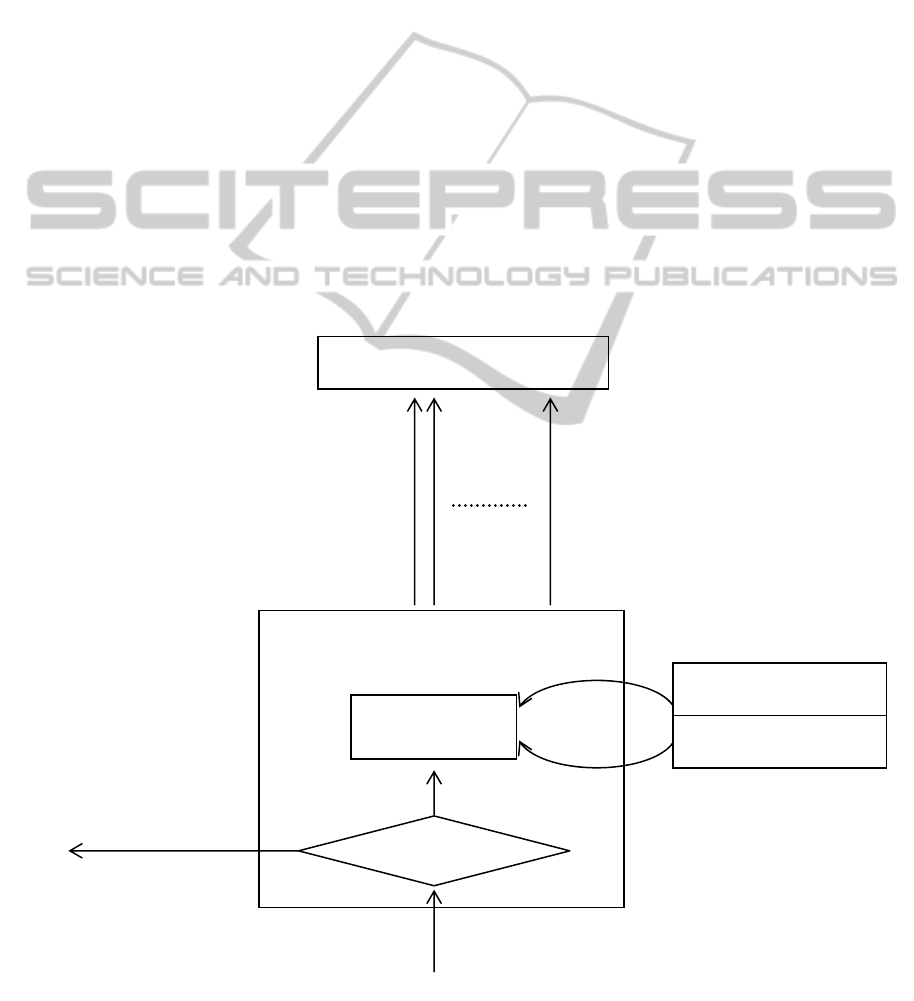
the second stage “Consolidation”.
3.2 Second Stage: Consolidation
In the second stage (see Figure 2), named
“Consolidation (C)”, the system checks the recorded
state of the network resource referenced by the
incoming SPI against the state reported by this SPI.
If there is no change in the state of the network
resource, then the SPI may be discarded since the
received SPI will not affect the state of the network
resource. This discard process works as follows:
If an SPI-C is received for a non faulty
network resource, the SPI-C is discarded and
regarded as an internal error (In fact, the error
is: There is not an existing SPI active in the
network resource).
If an SPI-F is received and is not already
attached to the network resource, then it is
attached and the “life-count” of the network
resource is increased. The existence of
multiple “Unavailability Selector” from the
previous stage can lead to multiple path
detection for SPI.
An SPI-C can still be not treated, even when the
referenced network resource is in a faulty state, if
the “life-count” for the network resource is bigger
than one. This represents that the SPI-C is just
deleting a path, but there are still other SPI for the
network resource.
This “life-count” mechanism allows to
coordinate multiple “Unavailability Selector” in a
very simple and straightforward way, although it
should be noted that some sort of synchronising
protocols between this second Consolidation stage
and all the instances of the previous stage
(Unavailability Selection) must be implemented.
Once it has been stated that the received SPI is
relevant and that it must be treated, the method
updates the network resource state, recording the
date and the time of the state change. Then, it
searches through the Network Inventory and the
Service Inventory to identify the basic services
affected by the network resource referenced by the
SPI. As soon as these services have been identified,
this stage forwards them to the next stage
(Aggregation), generating as many Service-Specific
Potential Incidents (S-SPI) as basic services have
Figure 2: SICAEN Second Stage: Consolidation.
Network-Resource
State Checking
Service Searching
Service Inventory
Service Potential Incident (SPI)
Network Inventory
SPI Discarding
SICAEN Method Third Stage:
Aggregation (A)
SICAEN Method
Second Stage: Consolidation (C)
Service-Specific Potential Incidents (S-SPI)
{
Firing (S-SPI-F)/Clearing (S-SPI-C),
Incident Type,
Affected Service Identity,
Starting Date-Time,
Ending Date-time,
Affected Network Resource Id,
….
}
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
157
been found. Together with the information conveyed
by the SPI, each of the S-SPI generated by the
second stage holds the affected service identity.
Therefore, this second stage performs a first
unification of the network data, in a more complete
approach than the pre-processing proposed in Li and
Li (2011). It also provides more flexibility when the
method is deployed, since the existence of several
“Unavailability Selection (SI)” stages may be
necessary in order to simplify their internal
architecture or to provide redundancy.
3.3 Third Stage: Aggregation
The third stage, named “Aggregation (A)”, is the
key stage in the SICAEN Method. This stage
determines whether each of the S-SPI generated by
the second stage should indeed be tailored as a
Service Incident (SI). This analysis is performed in a
per-service basis (see Figure 3).
3.3.1 Definitions
SIs are the final output generated by the method,
and, as it was stated before, they represent actual
service unavailability situations affecting a
geographical area and/or a defined group of
customers, where each SI concerns a specific basic
telecommunication service. However, SIs are not
static entities: they feature a complete life-cycle,
with a starting point, an ending point and an
indefinite number of changes (mutations) in
between. The authors have chosen the term
“mutation” as the changes can be very slight or
transient or lead, on some occasions, to evolutionary
leaps in the SI, mimicking the mutations on life
organisms. These mutations will be filtered on the
consolidation phase in order to provide an ordered
view of the SI evolution.
A Service Incident Mutation (SIM) may concern
the incident type (for example, an incident that was
originally perceived and catalogued as a “GSM cell
unavailability”, may be later perceived and
catalogued as a “BSC function unavailability”) or it
may concern the incident scope, i.e. the collection
of network resources affected by the incident
(throughout its life cycle, the incident may involve
different collections of network resources).
SICAEN identifies outgoing SI by a unique
Figure 3: SICAEN Third Stage: Aggregation.
Aggregation analysis
Service “A”
Aggregation analysis
Service “B”
Aggregation analysis
Service “S”
Service-Specific Potential Incidents
(S-SPI)
{
….
A
ffected Service ID = “A”
….
}
Service-Specific Potential Incidents
(S-SPI)
{
….
A
ffected Service ID = “B”
….
}
Service-Specific Potential Incidents
(S-SPI)
{
….
A
ffected Service ID = “S”
….
}
SICAEN Method Fourth Stage:
Stabilization (E)
Service Incident Mutations (SIM)
{
GFID-SFID
Firing/Clearing
Incident Type
Affected Service ID = “B”
Starting Date-Time
Ending Date-Time
Affected Network Resource List
….
}
SICAEN Method
Third Stage: Aggregation (A)
ICAART 2012 - International Conference on Agents and Artificial Intelligence
158
numerical identifier, named “Global Fault Identifier”
(GFID), and each of the comprising SIMs by the
concatenation of GFID and a second mutation-
specific numerical identifier named “Specific Fault
Identifier” (SFID). Like SPI and S-SPI, SIMs may
be firing notification (SIM-F) or clearing ones (SIM-
C). Firing notifications denote that a new SI state
has been reached while clearing notifications
indicate the SI is no longer at the state notified by
the mutation.
Each SIM captures relevant aspects of the
change suffered by the SI it belongs to. Those
aspects include the type of the incident (it may be
different from one mutation to the following one),
the collection of network resources affected by the
incident just after the mutation took place, and the
time and date of the mutation. The affected service
identity does not change throughout the service
incident life-cycle.
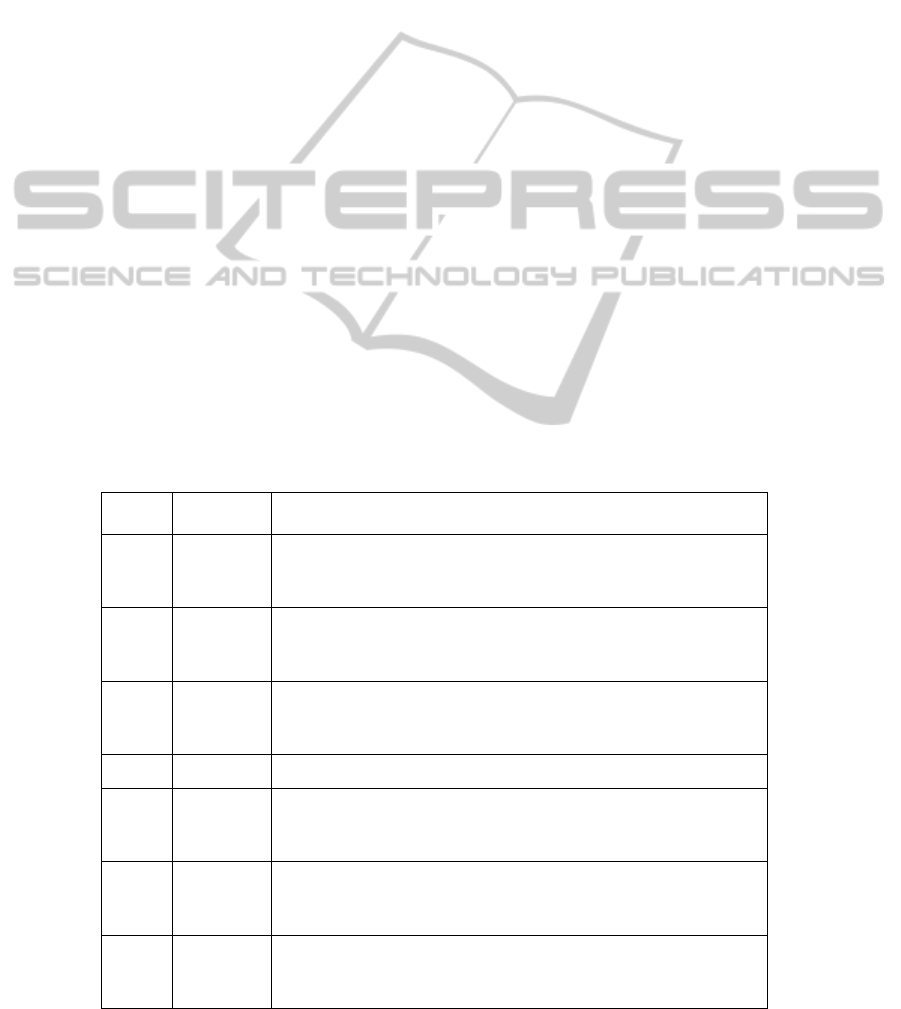
The SI life-cycle is composed by the complete
sequence of SIM from its rise to its demise. As an
example, some of the SIMs generated by SICAEN
method for a SI with GFID=214 are shown in the
table below. Table 1 shows some of the thirty six
mutations throughout its life-cycle, affecting service
S7, where R1, R2, R3…, Rn are network resources.
As it can be seen in Table 1, SIM with SFID = 0
is a special mutation: it flags the start and the end of
the whole SI.
3.3.2 Functional Behaviour
To compute the net effect of each incoming S-SPI
on an ongoing SI, SICAEN Aggregation stage uses
correlation techniques based on network topology,
i.e. based on functional dependencies between
network resources, or, failing these (when network
topology information is not enough, inaccurate or
non-existent), based on spatial-temporal proximity
criteria. Liu et al. (2008) presents a similar proposal.
An incoming firing Service-Specific Potential
Incident (S-SPI-F) may produce different results
after being processed by the Aggregation stage:
A new SI is generated.
A new SIM for ongoing SI is created.
Two or more SIs are aggregated into only one
SI encompassing all of the network resources
from the aggregated SI.
In this case, the resultant SI retains the identity
(GFID) of the oldest one being aggregated.
The remaining aggregated SIs are closed.
No effect on ongoing SIs.
Similarly, an incoming clearing Service-Specific
Potential Incident (S-SPI-C) may also produce
different results:
Table 1: Service Incident life-cycle example.
Time
Stamp
Mutation
Type
Service Incident Mutation
T0
Firing
Firing
[
GFID=214; SFID=0; {R7, R19, R24}; Firing:
1
7:45:03 04/04/2008; Clearing: -]
[
GFID=214; SFID=1; {R7, R19, R24}; Firing:
1
7:45:03 04/04/2008; Clearing: -]
T1
Clearing
Firing
[GFID=214; SFID=1; {R7, R19, R24}; Firing:
17:45:03 04/04/2008; Clearing: 17:46:07 04/04/08]
[GFID=214; SFID=2; {R7, R19, R24; R51}; Firing:
17:46:07 04/04/08; Clearing: -]
T2
Clearing
Firing
[GFID=214; SFID=2; {R7, R19, R24; R51}; Firing:
17:46:07 04/04/08; Clearing: 17:46:46 04/04/08]
[GFID=214; SFID=3; {R7, R19, R24; R51; R55};
Firing: 17:46:46 04/04/08; Clearing: -]
… … …
T34
Clearing
Firing
[GFID=214; SFID=34; {R19, R51; R63}; Firing:
18:06:41 04/04/08; Clearing: 18:07:39 04/04/08]
[GFID=214; SFID=35; { R19, R51}; Firing: 18:07:39
04/04/08; Clearing: -]
T35
Clearing
Firing
[GFID=214; SFID=35; { R19, R51}; Firing: 18:07:39
04/04/08; Clearing: 18:08:22 04/04/08]
[GFID=214; SFID=36; { R19}; Firing: 18:08:22
04/04/08; Clearing: -]
T36
Clearing
Clearing
[GFID=214; SFID=36; {R19}; Firing: 18:08:22
04/04/08; Clearing: 18:10:11 04/04/08]
[GFID=214; SFID=0; {}; Firing: 18:10:11 04/04/08;
Clearing: 18:10:11 04/04/08]
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
159
An ongoing SI is closed.
A new SIM for an ongoing SI is created.
A new SI is created after a SIM has been
emitted for an ongoing SI.
No effect on ongoing SIs.
The process to determine the effect of each
incoming Service-Specific Potential Incident (S-SPI)
on ongoing SIs is named “Aggregation Analysis”
and, as it has been noted before, it is performed in a
“per-service” basis. Therefore, both the incoming S-
SPI and the ongoing SI taken into consideration in
this analysis must reference the same basic service.
3.3.3 Details of the Aggregation Analysis
The Aggregation Analysis is based on a correlation
process that uses inference techniques as the basic
tool, and network topology (functional dependencies
between network resources for the service
concerned) as the main source of knowledge. In
short, the behaviour of this analysis for incoming
firing Service-Specific Potential Incident (S-SPI) is
as follows:
1. If the network resource referenced by the
incoming S-SPI-F is functionally dependent
on some of the network resources
encompassed by one of the ongoing SIs, then
that resource, and any other that is
functionally dependent on it, is aggregated to
the concerned SI.
2. If any of the network resources included in
the ongoing SIs are related to the network
resource referenced by the incoming S-SPI-F,
then these Incidents are changed to
accommodate the network resource included
in the S-SPI-F. It has to be noted that
functional dependency is one type of relation
but not the only one, spatial-temporal
relations can also be defined.
Should there be more than one SI, they will
be unified. In this unification process the
oldest SI will prevail, while the rest will be
closed if all of theirs resources have been
subsumed in the prevailing SI. Not all the
relations must be of type functional
dependent and although the relations are
symmetric they may be not transitive
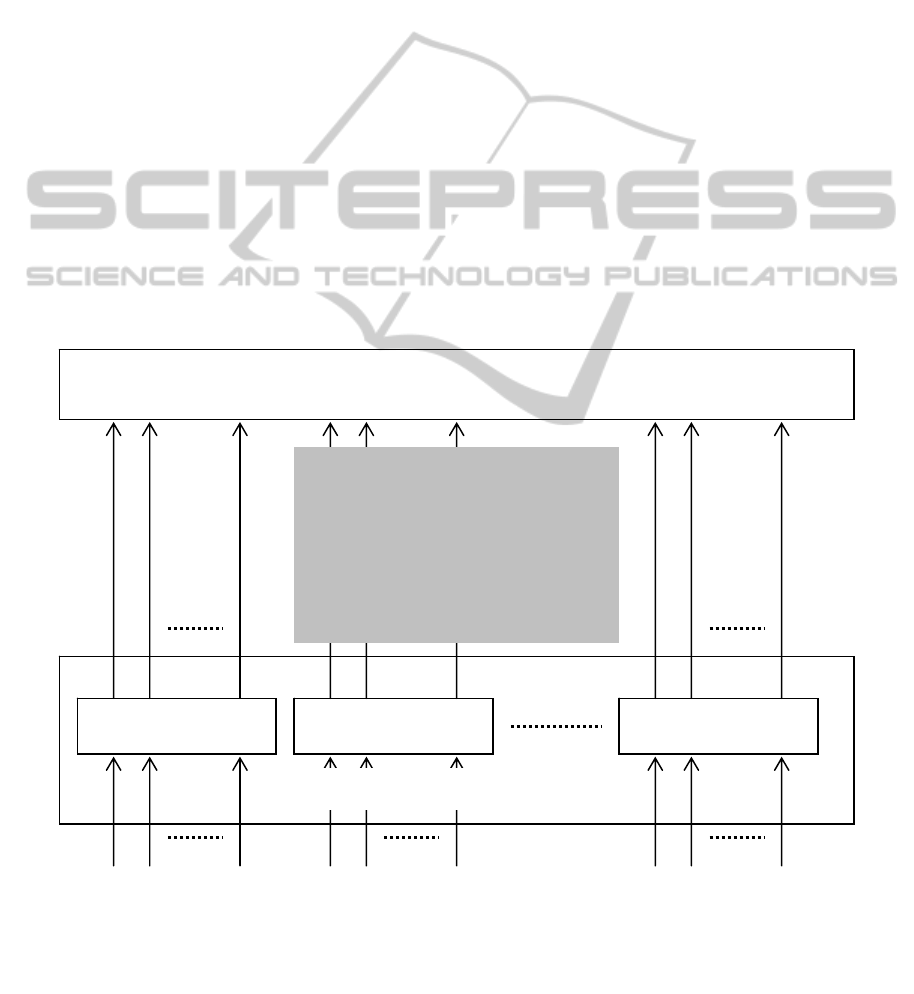
Figure 4: SICAEN Fourth Stage: Stabilization.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
160

3. If the network resource referenced by the
incoming S-SPI-F is not functionally
dependent on any of the network resources
encompassed by the ongoing SIs, then a new
SI, encompassing that resource and any other
that is functional dependent on it, is created.
There is an analogous correlation process for S-
SPI-C.
In all the cases, the type of the resultant SI is re-
evaluated. Every change on any ongoing SIs or the
rise of a SI is notified to the next stage
(Stabilization) by means of the corresponding SIMs.
As it has been formerly stated, network topology
information for the concerned service may be
detailed enough, inaccurate or, even, non-existent. In
any of these cases, the “Aggregation Analysis” uses
the concept of “spatial-temporal proximity” as a
basic mechanism for its correlation process.
The spatial proximity relationship between
network resources is defined as a function of both
network resource typology and network resource
location. As an example, in the context of
IMPACTA project, aimed to identify the impact of
severe network faults on mobile basic services, the
method uses as spatial proximity criteria the distance
between cells defined as a function of cell location
(rural, urban, sub-urban, etc) and cell type (macro-
cell, micro-cell, pico-cell, etc).
The temporal proximity relationship between
events is simply defined as a function of elapsed
time between events.
3.4 Fourth Stage: Stabilization
The fourth stage, named “Stabilization (E)”, is
aimed at reducing the amount of information the
method delivers, in line with the proposal in Sterritt
and Bustard 2002. This stage forwards to the next
one only those SIMs which convey relevant
information.
A severe network incident can cause hundreds,
or even thousands, of alarms and events to be raised
and to be cleared throughout its life-cycle. Each of
them may provoke several SIMs to be issued by the
Aggregation Stage. Most of those mutations report
only very small changes regarding the collection of
network resources affected by the incident
concerned and do not alter by any means the type of
the incident.
In order to select the incident mutations that must
be forwarded to the following stage, Stabilization
Stage makes use of a sliding time-limited watching
window in a per-incident basis (see Figure 4). For
each incident, this technique allows only relevant
mutations to be relayed to final stage. The mutations
are evaluated and since each of them represents a
particular state associated to the Service Incident,
the mutation located at the end of the window
summarizes the previous mutations.
3.5 Fifth Stage: Notification
The fifth and last stage, named “Notification (N)”, is
responsible for issuing SIMs for those clients
wishing to receive them. These clients can be part of
any assurance process that needs to know the impact
of severe network faults on basic telecommunication
services.
This stage shows the typical behaviour of a
standard notification service, such as OMG
Notification Service (OMG, 2004) or OASIS Web
Service Notification (Graham et al. 2006), although
any other type of notification schema may be used.
4 IMPLEMENTATION RESULTS
The SICAEN method has been implemented on top
of the proprietary OSS used by Telefónica (Spanish
biggest mobile operator) to manage its mobile
network which consists of several thousands of cells.
It also takes on account the full network topology,
BSC/RNC, MSC, SGSN, GSSN, HLR... It has
provided for the last few years and still does, impact
analysis on the two basic telecommunications
services, voice and data over GSM and UMTS
networks. It manages over a hundred thousand
different event origins, compromising cells,
BSC/RNCs, MSCs... It generates, on a daily basis,
over thirty thousand service mutation incidents
which in turn generate after the Stabilization Stage
about five thousands unique Service Specific
Identifiers grouped in four thousand Global Fault
Identifiers, for the four basic telecommunication
services managed. This information is used to
prioritise network faults and evaluate their actual
impact.
SICAEN is implemented and is coded in C++
and Java as a multiagent system making use of a
Rete correlation engine in the Unavailability
Selection stage and OASIS Web Service
Notification in the Notification Stage.
The method is integrated in a wider multiagent
architecture (IMPACTA) with specialised agents
complementing SICAEN to provide real time maps
of Service Unavailability zones to the Network
Operator Centre and the Customer Care Personnel.
These maps take in account the fact that in a mobile
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
161

network there is a certain degree of overlap between
cells so the scope of the failure reported by SICAEN
is lessened using this overlap information.
5 CONCLUSIONS AND FUTURE
WORK
A complete description of the SICAEN method has
been presented in the previous sections. Stages SI
and C provide a normalised annotated input to the
Aggregation phase. These first two stages make a
heavy use of the facilities provided by the
underlying OSS and corporate repositories to obtain
normalised Service-Specific Potential Incidents,
taking into account not only network faults, but also
operator actions. The later are not usually analyzed
by other methods since its root cause is already
known, but nevertheless they create a measurable
Service Impact to the user.
The Aggregation stage computes, using
topological and functional relationships among the
network elements, the net effect for each Service
Specific Potential Incidence (S-SPI). The last two
stages, E and N, provide the means to reduce the
volume of information generated by the Aggregation
stage and to relay the information to external clients.
SICAEN method has proven to be a powerful
tool to determine the impact of severe network faults
on mobile basic services in the context of
Telefonica’s IMPACTA project, which is used to
provide automated reports, textual and graphical, on
severe network failures as requested by the Spanish
Law (Real Decreto 424/2005). Nevertheless, some
enhancements have been identified during its daily
use.
The first enhancement regards the ability to
disaggregate a long life Service Incident into several
separate Service Incidents when it is suspected to
have been wrongly aggregated. In this situation, a
re-evaluation of correlation criteria for every
concerned Service-Specific Potential Incident (S-
SPI) should be performed.
Another enhancement concerns the use of
network resource partial unavailability information
as input. A network resource may be only partially
affected by a fault and, as a result, it may be only
able to preserve part of the services it usually
supports operating under regular conditions.
Additionally, the effect of the fault over each
individual service may vary meaningfully. To handle
this kind of partial unavailability information the use
of fuzzy logic and fuzzy reasoning techniques
(Zadeh, 1988 and Baldwin, 1981)) shall be explored.
REFERENCES
3GPP. Telecommunication management; Fault Manage-
ment; Part 2: Alarm Integration Reference Point
(IRP): Information Service (IS), TS 32.111-2. Retrie-
ved from http://www.3gpp.org/ftp/Specs/html-info/32
111-2.htm. Last visited 28-07-2011.
Åberg, S. 2002. OSS Quality of Service API (JSR-000090),
OSS through Java Initiative (OSS/J), November 2002.
Retrieved from http://jcp.org/en/jsr/detail?id=090.
Baldwin, J. F. 1981. Fuzzy Logic and Fuzzy Reasoning, in
E. H. Mamdani and B. R. Gaines (eds.) Fuzzy
Reasoning and its Applications, N. Y., Academic
Press, pp. 133-148.
Forgy, C. L. 1979. On the Efficient Implementation of
Production Systems. PhD thesis, Computer Science
Department, Carnegie Mellon University.
Forgy, C. L. 1982. Rete: A Fast Algorithm for the Many
Pattern/Many Object Pattern Match Problem, Artificial
Intelligence, Vol. 19, No. 1, pp. 17-37.
Graham, S., Hull, D. and Murray, B. (eds.). 2006. Web
Services Base Notification (WSN), Oasis Standard,
October. Retrieved from http://www.oasis-open.org/
specs/index.php#wsnv1.3. Last visited 01-07-2011.
ISO/IEC International Standard 10164-4. 1992. Also
published as X.733: Information Technology - Open
Systems Interconnection - Systems Management:
Alarm Reporting Function. International
Communication Union, Geneva. Retrieved from http://
www.itu.int/rec/T-REC-X.733/en.
Jakobson, G. and Weissman, M. D. 1993. Alarm
Correlation, IEEE Network, pp. 52-59, November.
Li, T. Y and Li, X. M. 2011. Preprocessing expert system
for mining association rules in telecommunication
networks, Expert Systems with Applications, 38, pp.
1709–1715.
Liu, Y., Zhang, J., Meng, X. and Strassner, J. 2008
Sequential Proximity-Based Clustering for
Telecommunication Netwok Alarm Correlation,
Lecture Notes In Computer Science, Vol. 5264, pp.
30-39.
OMG. 2004. OMG Notification Service, Version 1.1.
Retrieved from: http://www.omg.org/technology/do-
cuments/formal/notification_service.htm. Last visited
05-11-2009.
Raymer, D. 2004. Statement of alignment between OSS
through Java™ Initiative and 3GPP. Motorola.
Raymer, D. and Flauw, M. 2007. OSS Fault Management
API (JSR-000263), OSS through Java Initiative
(OSS/J), September. Retrieved from http://jcp.org/
en/jsr/detail?id=263. Last visited 05-11-2009.
Real Decreto 424/2005 “Reglamento sobre las condiciones
para la prestación de servicios de comunicaciones
electrónicas, el servicio universal y la protección de
los usuarios” (Regulation on the conditions to provide
electronic communication services, universal service
and customer data protection) Boletín Oficial del
Estado, No 102, pp 14545-14588, 15 April 2005 (In
Spanish).
ICAART 2012 - International Conference on Agents and Artificial Intelligence
162

Sterritt, R. and. Bustard, D. W. 2002. Fusing Hard and
Soft Computing for Fault Management in
Telecommunications Systems, IEEE Transactions on
Systems, Man, and Cybernetics—Part c: Applications
and Reviews, Vol. 32, No. 2, pp. 92-98.
TMFORUM-eTOM. GB921-Concepts and Principles -
Main eTOM document. Retrieved from http://www.
tmforum.org/BusinessProcessFramework/1647/home.
html (membership needed). Last visited 05-11-2009.
TMFORUM-MTOSI.Multi-Technology Operation System
Interface (MTOSI) Release 1.0. Retrieved from http://
www.tmforum.org/browse.aspx?catID=2320&linkID=
30792 (membership needed). Last visited 05-11-2009.
TMFORUM-NGOSS. NGOSS Service Assurance Charter.
http://www.tmforum.org/NGOSSServiceAssurance/48
26/home.html (membership needed). Last visited 05-
11-2009.
TMFORUM-TAM. 2006. Telecom Applications Map, The
BSS/OSS Systems Landscape. Release 2.0. Retrieved
from http://www.tmforum.org/ (membership needed).
Last visited 05-11-2009.
Zadeh, L.A. 1988. Fuzzy Logic, IEEE Computer, Vol. 21,
Issue 4, pp. 83-93.
APPENDIX
Patent pending. Reference number: P200803548
SICAEN: A NEW METHOD TO DETERMINE THE IMPACT OF SEVERE NETWORK FAULTS ON BASIC
TELECOMMUNICATION SERVICES
163
