
USING RELATIONS TO INTERPRET ANAPHORA
Parma Nand and Wai Yeap
School of Computer and Mathematical Sciences, Auckland University of Technology, Auckland, New Zealand
Keywords:
Anaphora resolution, Noun phrase anaphora, Discourse structure, Noun compounds, Noun phrases.
Abstract:
In this paper we present a novel framework for resolving bridging anaphora. The new framework is based on
the core set of relations that have been used to describe an entirely different linguistic process, the process of
generating a compound noun from two different nouns. We argue that the linguistic processes of compound
noun generation and the use of NP anaphora are alike hence have to use the same relational framework. We
validated this hypothesis by using human annotators to interpret indirect anaphora from naturally occurring
discourses. The annotators were asked to classify the relations between anaphor-antecedent pairs into relation
types that have been previously used to describe the relations between a modifier and the head noun of a
compound noun. We obtained very encouraging results with a Fleiss’s κ value of 0.66 for inter-annotation
agreement.
1 INTRODUCTION
The term anaphora resolution refers to identification
of the real world entity that an anaphor co-refers to.
This is true in the case of pronouns where the pro-
noun has a one-to-one relation with the antecedent.
It is also true in the case of some NPs where the
anaphoric NP directly co-refers to the antecedent (eg.
James Smith/Mr Smith), however in a case such as
window/house, table/tablecloth or even car/vehicle,
there is an indirect relation, different to a one-to-one
co-reference type relation between the anaphor and
the antecedent. NP anaphora resolution studies (e.g.
(Poesio et al., 1997; Fraurud, 1990; Vieira and Poe-
sio, 2000)) treat these indirect relations as a single
category and refer to them as associative or bridging
anaphora, however they are still interpreted as a form
co-reference. In this study we propose a relational
framework that distinguishes between the different
types of semantic relations that can exist between two
nouns, one of which is used anaphorically in a dis-
course. Hence anaphora interpretation involves iden-
tifying the antecedent as well as the type of relation
to the antecedent noun. Since we are now identifying
the type of relation, it is now possible for an anaphor
to have multiple antecedents, related by the same or
a different relation. This is a significant departure
from the conventional notion of anaphora resolution
where an anaphor is resolved to a single previously
mentioned entity, and in the case in which it is also an
anaphor, it is assumed to be already resolved form-
ing a chain of relations. For some NP anaphora this
is inadequate. As an illustration, consider the excerpt
below:
The robber jumped out of the window
1
.
The house
2
belonged to Mr Smith.
The window
3
is thought to have been un-
locked.
If we allow a single resolution relation for an
anaphoric NP, then window
3
would have to be re-
solved to either house
2
or window
1
. In either case, a
part ofthe informationwould not be captured. A com-
mon strategy in most studies (eg. (Poesio et al., 1997;
Fraurud, 1990)) is to resolve to the most recent an-
tecedent. In the case of the above excerpt, this would
mean that we resolve window
3
to house
2
which can
be assumed to be already resolved to window
1
. There
are two inadequacies in this strategy; firstly the se-
mantic difference between the relation of window
3
to
window
1
and window
3
to house
2
is approximated by
a single co-reference relation, and secondly as a con-
sequence, the direct relation between window
3
to win-
dow
1
is not captured. In the proposed framework, we
will identify both house
2
and window
1
as antecedents
and interpret each of them with a different relation. It
can be argued that this can be overwhelming since we
can form a relation between even a pair of very remote
entities. However the constraint in our case is that
we are only interested in relations that give rise to
anaphoric use of NPs. The interpretation framework
involves specifying a relation between an anaphor
92
Nand P. and Yeap W..
USING RELATIONS TO INTERPRET ANAPHORA.
DOI: 10.5220/0003740700920099
In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART-2012), pages 92-99
ISBN: 978-989-8425-95-9
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

and the antecedent hence a consequence of this is that
an NP can form relations with more than one an-
tecedent. This allows us to interpret and represent the
multiple relations between a simple anaphoric noun
such as window to house and another occurrence of
window. However, more importantly, it allows us to a
richer interpretation of compound nouns by interpret-
ing the modifier/s in addition to the head noun. As
a simple example, the compound noun battle fatigue,
appearing after the clause “The battle caused fatigue”
has a co-referential relation to the noun fatigue, but in
addition it also has some interpretation relation (iden-
tified later as CAUSE ) to the noun battle.
Hence, there are two novel aspects to this frame-
work for interpreting anaphora; firstly it identifies
a specific relation between the anaphor and its an-
tecedent. Secondly, it also interprets modifiers be-
yond using them to merely identify the antecedent for
the head noun, ie. interprets them in the same way as
the head noun. A consequential effect of this is that
an NP can have more then one antecedent. Thus this
framework enables us to determine the relational de-
pendence of an anaphoric NP to all other NPs in the
discourse.
2 RELATED WORKS
NP anaphora resolution has received considerably
less attention from computational linguists compared
to pronominal anaphora even though the proportion
of NP anaphora in natural discourses is either com-
parable or more then the proportion of pronominal
anaphora. The reason for this seems to be because
the problem of pronoun resolution much better de-
fined compared to NP anaphora. This complexity
of the problem also explains why whatever published
work is available on NP anaphora resolution, is pre-
dominantly focussed on NPs that are definite descrip-
tions (eg. (Poesio et al., 1997; Fraurud, 1990; Bean
and Riloff, 1999; Bunescu, 2003)) with the accom-
panying task of identifying whether a definite NP
is anaphoric or not. NP resolution in these stud-
ies involves identifying a single previously mentioned
noun that the anaphoric NP refers to. There are two
categories of anaphora; direct and associative. The
direct category includes cases in which an NP di-
rectly co-refers to another entity such as the case of
he/John. The associative category includes cases such
as window/house. Some of the studies such as (Poesio
et al., 1997) have gone a step further to specify the
actual associative relation in terms of synonymy
1
, hy-
1
same meaning relation
ponymy
2
and meronymy
3
. The motivation for these
relations seems to have risen from organization of the
lexicon, WordNet (Fellbaum, 1998) which is used to
bridge the meanings between the anaphor and the an-
tecedent.
This paper argues that the noun compound gener-
ation process and the anaphoric use of NPs are similar
linguistic processes, hence they have to be based on a
common relational framework.
A compound NP of the form noun + noun (N +
N) consists of two nouns which have some underly-
ing semantic relation ((Levi, 1973; Downing, 1977;
Li, 1971)). According to these studies use of com-
pound NPs is highly productive rather then lexical.
In this productive process, compound NPs are formed
by a producer on the fly as a discourse is being pro-
duced rather then recalled and used from a lexicon.
This formation of NPs is not totally unconstrained, in
other words, a compound NP cannot be formed with
any two random nouns. For example, war man can
not be formed on the basis of the relation “man who
hates war” or similarly house tree can not be formed
from “tree between two houses” (Zimmer, 1971). In
both the examples there does exist a relation between
the nouns, however it is of the type that can be used
to form a compound NP. With the exception of (Zim-
mer, 1971), the other mentioned studies on compound
NPs have assumed that the set of generic relations are
finite and characterizable, although the set is not nec-
essarily common among all the studies. Studies such
as (Levi, 1973) and (Downing, 1977) have attempted
to identify these relations, and even though the exact
set of relations proposed by the different studies are
slightly different, a core set is very similar. An addi-
tional aspect highlighted in (Downing, 1977) is that
compound nouns can also be formed from “tempo-
rary or fortuitous” relations, hence it presents a case
for an existence of unbounded number of relations al-
though the vast majority of noun compounds fit into
a relatively small set of categories (Tratz and Hovy,
2010).
The relational frameworks used in computational
linguistics vary along similar lines as those proposed
by linguists. Some works in the computational lin-
guistics (eg. (Butnariu and Veale, 2008; Nakov,
2008)) assume the existence an unbounded number
of relations while others (eg. (Lauer, 1995; Kim and
Nakov, 2011)) use categories similar to Levi’s finite
set. Yet others (eg. (Nastase and Szpakowicz, 2003;
Kim and Baldwin, 2005)) are somewhat similar to
(Warren, 1978). Most of the research to date has been
domain independent done on generic corpus such as
2
same subset/superset relation
3
part/whole relation
USING RELATIONS TO INTERPRET ANAPHORA
93

Penn Tree Bank, British National Corpus or the web.
The later works on noun compounds have fol-
lowed on from either (Levi, 1978) or (Warren, 1978)
with some of them coming up with a slightly differ-
ent variation while others have defined a finer grained
set of relations dictated by the data sets used for the
study. For example, (Tratz and Hovy, 2010) reports
a set of 43 relations grouped into 10 upper level cat-
egories. Most of the relations from different studies
can be mapped to an equivalent relation in other stud-
ies.
For this study we chose the set of relations pro-
posed by in (Levi, 1978) for two reasons. Firstly, our
analysis of corpus for anaphor-antecedent relations
seemed to map better to Levi’s set of nine relations
for noun compounds and secondly more of these rela-
tions can be computationally determined from exist-
ing lexicons such as WordNet and the Web. In terms
of natural language processing, a linguistic theory is
only useful if it can be reasonable implemented in a
computational system.
(Levi, 1978) proposes that compound NPs are de-
rived from underlying clause or complement struc-
tures by the two processes of predicate deletion and
normalization. Her work is based on similar frame-
work as (Lees, 1966) except Less’ transformational
process is based on verb classifications. Levi pro-
poses that, in the case of normalization, ‘the underly-
ing predicate survives overtly in the head noun, with
the modifier deriving from either the subject or the
object of the underlying S’, giving rise to subjective
(eg. industrial production) or objective (eg. heart
massage) normalization. For the case of predicate
deletion, Levi maintains that the number or deletable
predicates is limited to only nine primitive relations.
They are CAUSE, HAVE, MAKE, USE, BE, IN,
FROM, ABOUT and FOR. In the next section we ar-
gue that these relations also describe anaphoric use of
NPs.
3 ANAPHORA RESOLUTION
FRAMEWORK
In the Introduction we stated that anaphora interpreta-
tion and noun compound generation are two indicants
of the same underlying relational framework between
entities. Hence, a framework describing compound
noun generation has to apply to anaphora usage as
well. In the proposed framework we extend the re-
lations proposed for compound noun generation by
predicate deletion from (Levi, 1978) for interpretation
of NP as well as pronominal anaphora.
An indirect reference such as window referring to
house and diesel referring to truck is based on the
predicates “house has windows” and “a truck uses
diesel”. In the case of noun compound generation,
the predicate is deleted and the two entities are jux-
taposed to form the noun compounds house window
and diesel truck. For interpretation of the compound
noun the consumer is expected to reconstruct the rela-
tion between the modifier and the head noun ((Down-
ing, 1977; Levi, 1978)). We propose that the com-
pound noun generation process is very similar to NP
anaphora, except in the latter case the modifier is not
necessarily bound to the head noun as part of a noun
compound. That is, it may exist in another clause,
however the same relation is still expected to be re-
constructed for a full interpretation of the anaphor.
Hence, for the example for the predicate “house has
window”, we could have the full NP, house window
produced by predicate deletion. However in addition,
the same predicate coulc also be expressed anaphori-
cally as in the following example:
John bought a house in Glen Eden.
The windows are wooden.
In the example above the related entities from the
predicate “house has windows” are separated into two
different sentences, however the consumer is still ex-
pected to reconstruct the semantic relation as in the
case of noun compound generation. Hence, with the
proposed anaphora interpretation framework, the only
difference between noun compound generation and
anaphoric use of NPs is that in the former the two
nouns are used together as a compound noun while
in the latter the nouns are used separately as anaphor-
antecedent pairs, however they are both governed by
the same semantic framework.
Semantic relations between certain entities exit
by default and can be assumed as part of the lexical
knowledge by a producer. For example, the HAVE
relation between car and tyre is part of lexicon so
the noun compound car tyre and the noun tyre used
anaphorically to refer to car is readily understood.
However, in addition, a semantic relation can also be
formed between two between two entities which are
not usually related by the relation. In this case the re-
lation is explicitly expressed by a predicate as context
before the predicate is deleted to form a noun com-
pound or used anaphorically. For example, after spec-
ifying the relation “the box has tyres”, the noun tyres
can be used to indirectly refer to box in the same way
as the reference of tyres to car. However, the former
can only be used in the context of the discourse in
which the relation was expressed. This corresponds
to Downing’s (Downing, 1977) fortuitous relations.
We distinguish between these two type of relations
as persistent or contextual. Persistent relations are
ICAART 2012 - International Conference on Agents and Artificial Intelligence
94

those that form part of the lexical knowledge which
are valid within the context of an individual discourse
as well as all other discourses. On the other hand con-
textual relations are transient and may be valid only
for the duration of a single discourse, for example, “a
cup on a table” or “John has a knife”. The contex-
tual relations can be expressed as either a verb or a
preposition relating two entities in the discourse be-
ing processed.
As argued earlier, the semantic relations used by
NP anaphora are same as those used for noun com-
pound generation, hence for this study we adopted the
set proposed in (Levi, 1978) consisting of the rela-
tions CAUSE, HAVE, MAKE, USE, BE, IN, FOR,
FROM and ABOUT. In order to define a complete
framework for anaphora interpretation, we needed to
do two modifications to the nine relations from (Levi,
1978). Both of these modifications were done in or-
der to be able to better interpret and represent plural
anaphoric NPs. This was done by introducing a new
relation named ACTION, and by splitting the existing
BE relation into BE-INST and BE-OCCR. These are
explained next.
When two or more entities in a discourse are par-
ticipating in the same or similar event, they can be
referred to as a unit by a collective NP in the context
of the discourse. Two entities in the same or simi-
lar action can be expressed by the conjunction and
or described by two different clauses. For instance
in the sentence “The coastguard and Lion Foundation
Rescue helicopter were called out.”, the entities coast-
guard and Lion Foundation Rescue helicopter are re-
lated to each other by the virtue of participating in the
same action. Similarly, the clauses “the truck rolled
down the hill” and “the ball rolled down the hill”
would enforce the same relation between truck and
ball since they are both engaged in the same action
(roll). This relation between truck and ball is only
valid for the context of the discourse, hence the re-
lation is contextual. We describe this contextual re-
lation as the ACTION relation which relates entities
participating in events which are identified to be same
or similar. The ACTION is used to describe an NP
such as runners used to refer to fox and Peter from
the context clause “The fox and Peter were running”.
The second modification involved defining a finer
grained BE relation in order to interpret existence of
plurals in a different form. We split Levi’s BE re-
lation into BE-OCCR and BE-INST to distinguish
between direct co-reference or identity relation and
an instance relation. In a BE-OCCR relation an
NP directly forms a one-to-one co-reference to an-
other NP, eg. John/he and John/the driver. The
BE-INST relation represents cases where an anaphor
refers to a plural antecedent, in a partial capacity,
for example, both trucks/northbound truck. In this
case the NP northbound truck is an instance of both
trucks which is distinct from a co-reference relation.
It can be argued that all subset/ superset relations
such as John/driver(John is an instance of driver) and
car/vehicle (car is and instance of vehicle) is an in-
stance relation. However we consider these as BE-
OCCR relation since they function to identify the en-
tity. Hence in the framework, the BE-INST relation
only relates a plural NP and an NP representing a sub-
set of the plural NP.
With this discussion we can now define and
exemplify the eleven relation types was used for the
purpose of anaphora interpretation. They are:
CAUSE - Includes all causal relations. For example,
battle/fatigue, earthquake/tsunami
HAVE - Includes notions of possession. This
includes diverse examples such as snake/poison,
house/window and cake/apple.
MAKE - Includes examples such as concrete house,
tar/road and lead/pencil.
USE - Some examples are drill/electricity and
steam/ship.
BE-INST - Includes plural cases such as both
trucks/southbound truck, John/teachers.
BE-OCCR - Describes the same instance participat-
ing in multiple events. For example John Smith/Mr
Smith/he and John Smith/the driver.
IN - This relation captures grouping of things that
share physical or temporal properties. For example
lamp/table and Auckland/New Zealand.
FOR - This includes purpose of one entity for an-
other. For example pen/writing and soccer ball/play.
FROM - This includes cases where one entity is
derived from another. For example olive/oil and
wheat/flour.
ABOUT - Describes cases where one entity is a topic
of the other. For example travel/story and loan/terms.
ACTION - This is only a contextual relation meant
to capture entities engaged in same or similar action
either with the same object/s or a null object.
The next section describes the annotation experi-
ment done in order to validate the that anaphora usage
is based on the above relation types.
4 ANNOTATION EXPERIMENT
4.1 Annotators
For the purpose of human validation of all relations in
USING RELATIONS TO INTERPRET ANAPHORA
95

the framework we used second and third year stu-
dents enrolled in computer related degrees. The anno-
tation experiments were done overa period of 4 weeks
at the beginning of their usual classes. Four different
streams were used each consisting of approximately
30 students. The students in each stream were given
a basic training on the requirements of the annotation
and they were given a single annotation task at the
beginning of their class over a 4 week period. The
whole annotation experiment was broken down into
session based tasks involving 25 anaphoric NPs per
task. This was done to ensure that each task was com-
pleted in about 10 minutes with minimal impact on
the students class time. In addition, the annotators
were not identified in any of the tasks. We only en-
sured that an annotator did not annotate the same task
twice.
4.2 Annotation Data
Our base input data used for content analysis for all
aspects of NP usage consisted of 120 articles (of
mixed genre) from The New Zealand Herald, The Do-
minion Post and The Press which are three major on-
line newspapers from three different cities in New
Zealand. The choice of the articles were not com-
pletely random. This corpora was developed to serve
as the input data for the anaphora resolution system
which is the parent project of this study. Hence, the
corpora was developed from the articles which were
not too short (had more then 20 sentences), exhibited
use of a variety of anaphoric uses (including pronom-
inal anaphora) and had been written by different writ-
ers.
An inherent challenge in most NLP tasks is what
is referred to as data sparseness. The term is used
to describe a characteristic when a single chosen cor-
pus cannot be used for consistent empirical validation
of all aspects of a theory. This is because the preva-
lence of the different characteristics of an NLP theory
can be unevenly distributed in a fixed corpus. Hence,
we searched an extended corpus in order to make the
lower threshold of 15 relations from each category.
For this we used The Corpus of Contemporary Amer-
ican English (Davies, 2010). This freely available
corpora consisting of some 410 million words from
a variety of genre and has an online web interface
which can be used to do fairly complex searches for
words and phrases hence forms an excellent resource
for manual content analysis for NLP tasks.
We excluded validating the BE-OCCR relation
since this is a non-ambiguous co-reference relation.
For the annotation experiment we used 3 streams
of approximately 30 students giving us a total of 90
different annotators. Each annotator took 4 differ-
ent tasks, one per week for a period of 4 weeks.
Each task consisted of 25 antecedent-anaphor pairs
and was annotated by 2 streams, ie. approx. 60
annotators. We randomly discarded some annota-
tion task sheets in order to have a consistent number
of annotations for each pair resulting in 25 annota-
tors for each task. Each relation type from (CAUSE,
HAVE, MAKE, USE, BE-INST, IN, FOR, FROM,
ABOUT, ACTION) as classified by the author was
represented by 15 anaphor-antecedent pairs. The
pairs from each of the 10 relation types were ran-
domly selected to make up 6 task sheets, each con-
sisting of 25 pairs. The total number of classifications
for all relations amounted to 3750 with 375 classifica-
tions for each relation type consisting of 15 different
anaphor-antecedent pairs.
Each of the streams were given a basic training
on on semantic interpretation of the relation types us-
ing the examples in section section 3. These exam-
ples were also given as a separate sheet with each an-
notation task. Each task sheet consisted of anaphor-
antecedent pairs and a tick box for each of the rela-
tions. The annotators were asked to choose the re-
lation which best describes the anaphor-antecedent
pair. Two additional options, OTHER and NONE
were also given. The OTHER was to be used if the
annotator thought that a relation does exist but is not
present in the given list and option NONE to be used
if the annotator thought that the pair were not related
at all.
Table 1 shows the confusion matrix of the rela-
tion types as identified by the annotators against the
author’s classification. Table 2 shows the correspond-
ing confusion indices between the relation types. The
confusion indices indicate the likelihood of a relation
type to be interpreted as another type.
5 ANNOTATION RESULTS
The first observation of the annotation results from
table 1 is that only 2 annotations out of a total of
3750 were classified as NONE indicating that the
annotators by and large thought that the pairs given
had some relation. In addition a total of 43 (approx.
1.1%) annotations were classified as OTHER, indi-
cating the relations were described by a relation not in
the list of 10 that were given. The main categories that
were interpreted as having some other relation were
CAUSE and ACTION, however these were still a very
small percentage with indices of 0.04 and 0.05 respec-
tively. The bolded entries in table 2 give the percent-
age agreement of the relation types agreeing with that
ICAART 2012 - International Conference on Agents and Artificial Intelligence
96
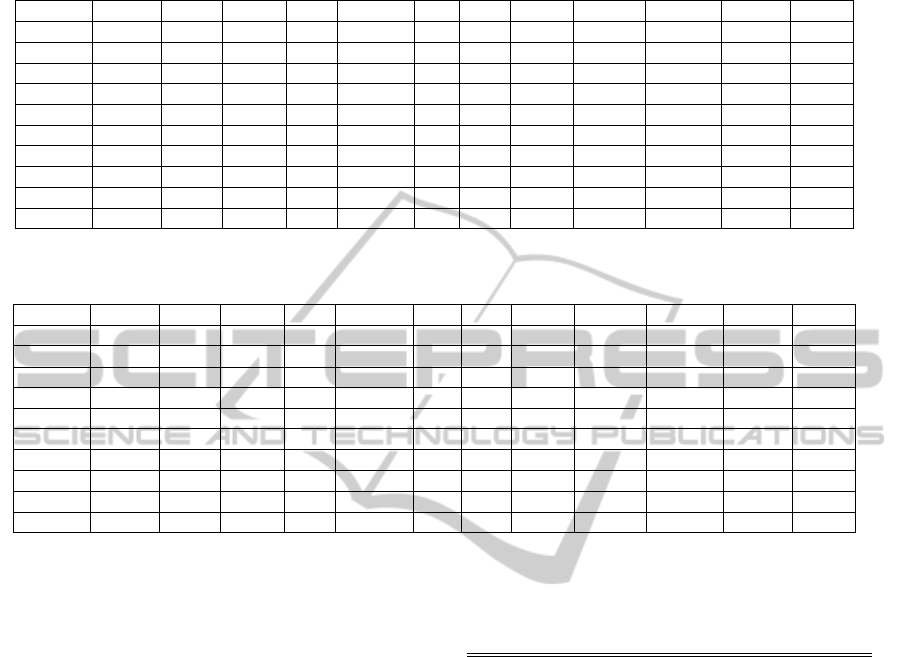
Table 1: Confusion Matrix for the non-normalized NPs. The columns give the annotations by annotators against the author’s
annotations on the rows. Each relation category had a total of 375 annotations done by 50 different annotators. The bolded
entries indicate number of annotations agreeing with author’s annotations.
CAUSE HAVE MAKE USE BE-INST IN FOR FROM ABOUT ACTION OTHER NONE
CAUSE 208 45 87 4 14 15 2
HAVE 196 113 7 13 46
MAKE 45 206 120 4
USE 45 26 242 59 3
BE-INST 347 19 9
IN 64 37 241 33
FOR 18 5 132 216 4
FROM 9 17 35 87 227
ABOUT 48 11 56 7 253
ACTION 5 351 19
Table 2: Confusion Index Matrix between the relation types corresponding to table 1. The bolded entries indicate the index
of annotations which were the same as that of the author’s.
CAUSE HAVE MAKE USE BE-INST IN FOR FROM ABOUT ACTION OTHER NONE
CAUSE 0.55 0.12 0.23 0.01 0.04 0.04 0.01
HAVE 0.52 0.30 0.02 0.03 0.12
MAKE 0.12 0.55 0.32 0.01
USE 0.12 0.07 0.65 0.16 0.01
BE-INST 0.93 0.05 0.02
IN 0.17 0.10 0.64 0.09
FOR 0.05 0.01 0.35 0.58 0.01
FROM 0.02 0.05 0.09 0.23 0.61
ABOUT 0.13 0.03 0.15 0.02 0.67
ACTION 0.00 0.01 0.94 0.05
of the author. The relation types BE-INST and AC-
TION have the highest conformance indicating they
are the least ambiguous. The other types vary from
a low figure of 0.52 for HAVE to 0.67 for ABOUT
with an overall agreement value of 0.66. The rela-
tion types that were easily confused and hence can
be interpreted as semantically close were HAVE and
MAKE USE. Conflating these 3 categories gives us
an agreement index of 0.89. Another crucial observa-
tion is for the FROM relation. Although not by large
amounts, this relation type seems to be confused with
all other categories. This prompted us to closely ex-
amine the task sheets to see if there were consistent
misclassifications by the author, however no such pat-
terns were found. Some of the classifications seemed
to use the FROM type as a “fall back” category.
In order to compare the inter-annotator agree-
ment with other similar studies we also computed the
Fleiss’ κ measure. The κ index for the overall anno-
tation tasks was computed to be 0.64 and the value
with HAVE, MAKE and USE conflated was 0.86.
The overall κ value 0.64 compares well the inter-
annotator figures from other annotation experiments
dealing with identification of relations. For compari-
son some of the results are summarized in table 3.
Table 3: Inter-annotator agreement comparison between
studies dealing with relations between composite nouns of
noun compounds.
Study Agreement Index No. of Relations
(Tratz and Hovy, 2010) 0.57 - 0.67 κ 43
(Girju, 2007) 0.61 κ 22
(
´
O S´eaghdha, 2007) 0.68 κ 6
(Kim and Baldwin, 2005) 52.31 % 20
(Girju et al., 2005) 0.58 κ 21
6 DISCUSSION
The annotation experiment results strongly indicates
that the the two natural language usage phenomena
of compound noun generation and anaphoric use of
nouns are based on the same underlying semantic
structure. Since they are two different processes they
have been studied as two separate nlp research areas
as well. The proposed framework for anaphora reso-
lution allows us to marry the two nlp areas so that we
can better share computational advances in the two
research areas. Recently there has been an increased
momentum (Kim and Nakov, 2011; Tratz and Hovy,
2010; Nakov, 2008; Butnariu and Veale, 2008; Kim
and Baldwin, 2006; Nastase et al., 2006; Barker and
Szpakowicz, 1998; Hendrickx et al., 2010) towards
USING RELATIONS TO INTERPRET ANAPHORA
97

automatic derivation of relations between composite
nouns in noun compounds, most of them based on re-
lations from (Levi, 1978). This will result in an in-
creasing amount of ontology describing the semantic
relations between compound nouns which will also
become useful for anaphora interpretation if there is
an existence of a common framework. The anaphora
interpretation framework proposed in this study is a
step towards this.
Another significant advantage of a common
framework is that it will be easier to integrate the full
meaning of a compound noun and the meaning as-
sociated with it being used anaphorically. Currently,
anaphora is described using a different set of relations
(eg. synonymy, hypernomy, meronomy etc.) and
compound nounswith adifferentset. Hence, when in-
terpreting a compound noun which is also anaphoric,
it becomes difficult to merge the two meanings. Com-
bining the processes within the same framework gives
us a much stronger interpretativepower enabling us to
interpret a modifier as well as the head noun. As an
illustration consider the excerpt below:
John’s car had an accident yesterday. Its
thought faulty car tyres played a major role
in the accident.
The compound noun faulty car tyres expresses the
relation HAVE between the modifier car and the head
noun tyres, defined by the compound noun genera-
tion framework. In terms of straight forward anaphora
resolution, the noun compound faulty car tyres is not
anaphoric since the head noun tyres does not co-refer
to anything in the previous sentence. However to be
able to fully interpret the meaning of the second sen-
tence, it is crucial that we know that the noun car in
the first sentence also has a HAVE relation to tyres
in the second sentence. This relation forms the basis
of the coherence between “car and accident” in the
first sentence and “tyres and accident” in the second
sentence. The proposed framework enables us to use
relations from the same set to describe the relations
between car and tyres in the compound noun faulty
car tyres and the anaphoric relations between faulty
car tyres and car. The resultant output from process-
ing a whole discourse using the proposed framework
would be a network of entity-to-entity relations con-
sisting of all freely existing nouns as well as nouns
participating as modifiers. This network can either be
used on its own or used as a building block towards
higher level discourse structures such as a coherence
structure.
7 CONCLUDING REMARKS
In this paper we presented a relational framework for
interpreting anaphoric NPs which goes beyond the
conventional co-reference relations. We argued that
anaphora usage and compound noun generation are
based on a common relational framework. To support
this we used an existing NP production framework
and validated it for anaphora usage using real world
discourses. We also argued that using this framework,
a more accurate level of discourse interpretation can
be achieved, both directly, as well as using it as a
building block for a higher level discourse structure
such as the coherence structure. We are in the process
of enthusiastically implementing the framework and
will be reporting the results in near future. It is antic-
ipated that successful computation of this framework
will help in numerousNLP tasks such as document vi-
sualization, summarization, archieving/retrieval and
search engine applications.
REFERENCES
Barker, K. and Szpakowicz, S. (1998). Semi-automatic
recognition of noun modifier relationships.
Bean, D. and Riloff, E. (1999). Corpus-based identifica-
tion of non-anaphoric noun phrases. In Proceedings of
the 37th annual meeting of the Association for Com-
putational Linguistics on Computational Linguistics,
pages 373–380. Association for Computational Lin-
guistics Morristown, NJ, USA.
Bunescu, R. (2003). Associative anaphora resolution:
A web-based approach. In In Proceedings of the
EACL2003 Workshop on the Computational Treat-
ment of Anaphora, pages 47–52.
Butnariu, C. and Veale, T. (2008). A concept-centered ap-
proach to noun-compound interpretation. In Proceed-
ings of the 22nd International Conference on Compu-
tational Linguistics - Volume 1, COLING ’08, pages
81–88, Stroudsburg, PA, USA. Association for Com-
putational Linguistics.
Davies, M. (2010). Corpus of contemporary american en-
glish. http://www.americancorpus.org/.
Downing, P. (1977). On the creation and use of english
compound nouns. Language, 53(4):810–842.
Fellbaum, C. (1998). WordNet: An Electronic Lexical
Database. Bradford Books.
Fraurud, K. (1990). Definiteness and the processing of noun
phrases in natural discourse. Journal of Semantics,
7(4):395–433.
Girju, R. (2007). Improving the interpretation of noun
phrases with crosslinguistic information. In in Pro-
ceedings of the 45th Annual Meeting of the Associa-
tion of Computational Linguistics, pages 568–575.
Girju, R., Moldovan, D., Tatu, M., and Antohe, D. (2005).
On the semantics of noun compounds. Computer
Speech and Language, 19(4):479–496.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
98

Hendrickx, I., Kim, S. N., Kozareva, Z., Nakov, P.,
S´eaghdha, D. O., Pad´o, S., Pennacchiotti, M., Ro-
mano, L., and Szpakowicz, S. (2010). Semeval-2010
task 8: Multi-way classification of semantic relations
between pairs of nominals. In Proceedings of the 5th
International Workshop on Semantic Evaluation, Se-
mEval ’10, pages 33–38, Stroudsburg, PA, USA. As-
sociation for Computational Linguistics.
Kim, S. N. and Baldwin, T. (2005). Automatic interpre-
tation of noun compounds using wordnet similarity.
In In Proceedings of the 2nd International Joint Con-
ference on Natural Language Processing, Jeju Island,
South Korea, 1113, pages 945–956.
Kim, S. N. and Baldwin, T. (2006). Interpreting seman-
tic relations in noun compounds via verb semantics.
In Proceedings of the COLING/ACL on Main confer-
ence poster sessions, COLING-ACL ’06, pages 491–
498, Stroudsburg, PA, USA. Association for Compu-
tational Linguistics.
Kim, S. N. and Nakov, P. (2011). Large-scale noun com-
pound interpretation using bootstrapping and the web
as a corpus. In The Proceeding of Conference on
Empirical Methods in Natural Language Processing,
EMNLP., Edinburgh, UK.
Lauer, M. (1995). Corpus statistics meet the noun com-
pound: some empirical results. In Proceedings of
the 33rd annual meeting on Association for Compu-
tational Linguistics, ACL ’95, pages 47–54, Strouds-
burg, PA, USA. Association for Computational Lin-
guistics.
Lees, Robert, B. (1966). On a transformational analysis of
compounds: A reply to hans marchand. Indogerman-
ische Forschungen, pages 1–13.
Levi, J. (1973). Where do all those other adjectives come
from. In Chicago Linguistic Society, volume 9, pages
332–354.
Levi, J. N. (1978). The syntax and semantics of complex
nominals / Judith N. Levi. Academic Press, New York
:.
Li, C. N. (1971). Semantics and the Structure of Com-
pounds in Chinese. PhD thesis, University of Carli-
fornia dissertation.
Nakov, P. (2008). Noun compound interpretation using
paraphrasing verbs: Feasibility study.
Nastase, V. and Szpakowicz, S. (2003). Exploring noun-
modifier semantic relations. In Proceedings of the 5th
International Workshop on Computational Semantics.
Nastase, V. S.-S., Sokolova, J., and M. Szpakowicz, S.
(2006). Learning noun-modifier semantic relations
with corpus-based and wordnet-based features. Pro-
ceedings of the National Conference on Aritficial In-
telligence., 21(Part 1):781–787.
´
O S´eaghdha, D. (2007). Annotating and learning com-
pound noun semantics. In Proceedings of the 45th
Annual Meeting of the ACL: Student Research Work-
shop, ACL ’07, pages 73–78, Stroudsburg, PA, USA.
Association for Computational Linguistics.
Poesio, M., Vieira, R., and Teufel, S. (1997). Resolving
bridging references in unrestricted text. In Proceed-
ings of a Workshop on Operational Factors in Prac-
tical, Robust Anaphora Resolution for Unrestricted
Texts, pages 1–6, Morristown, NJ, USA. Association
for Computational Linguistics.
Tratz, S. and Hovy, E. (2010). A taxonomy, dataset, and
classifier for automatic noun compound interpretation.
In Proceedings of the 48th Annual Meeting of the
Association for Computational Linguistics, ACL ’10,
pages 678–687, Stroudsburg, PA, USA. Association
for Computational Linguistics.
Vieira, R. and Poesio, M. (2000). An empirically based
system for processing definite descriptions. Computa-
tional Linguistics, 26(4):539–593.
Warren, B. (1978). Semantic patterns of noun-noun com-
pounds. Gothenburg studies in English. Acta Univer-
sitatis thoburgensis.
Zimmer, K. E. (1971). Some general observations about
nominal compounds. Working Papers on Language
Universals, pages C1–21.
USING RELATIONS TO INTERPRET ANAPHORA
99
