
REFA3D: ROBUST SPATIO-TEMPORAL ANALYSIS
OF VIDEO SEQUENCES
Manuel Grand-Brochier, Christophe Tilmant and Michel Dhome
Laboratoire des Sciences et Matriaux pour l’Electronique et d’Automatique (LASMEA), UMR 6602 UBP-CNRS,
24 Avenue des Landais, 63177 Aubi
`
ere, France
Keywords:
Ellipsoid-HOG, Local Descriptor, Space-time Robustness.
Abstract:
This article proposes a generalization of our approach REFA (Grand-brochier et al., 2011) to spatio-temporal
domain. Our new method REFA3D, is based mainly on hes-STIP detector and E-HOG3D. SIFT3D and
HOG/HOF are the two must used methods for space-time analysis and give good results. So their studies allow
us to understand their construction and to extract some components to improve our approach. The mask of
analysis used by REFA is modified and therefore relies on the use of ellipsoids. The validation tests are based
on video clips from synthetic transformations as well as real sequences from a simulator or an onboard camera.
Our system (detection, description and matching) must be as invariant as possible for the image transformation
(rotations, scales, time-scaling). We also study the performance obtained for registration of subsequence, a
process often used for the location, for example. All the parameters (analysis shape, thresholds) and changes
to the space-time generalization will be detailed in this article.
1 INTRODUCTION
Today, digital imaging is becoming more prevalent in
current applications of life. It is used for example to
track, to localize, or to recognize. Scientists search
and propose methods to acquire or create images, to
edit content, or to extract all the information neces-
sary for various applications. To give some exam-
ples, we can cite the 3D reconstruction, object track-
ing and the face recognition. These applications need
data usually extracted with two tools: the detections
of interest points and the local description. For 2D ap-
plications, we can cite methods such as SIFT (Scale
Invariant Feature Transform) (Lowe, 1999; Lowe,
2004) and SURF (Speed Up Robust Features) (Bay
et al., 2006), offering a complete system for the detec-
tion and local description of points. We proposed in
2011 the method REFA (Grand-brochier et al., 2011),
to extract and characterize interest points with greater
precision and a higher matching rate. The addition of
temporal information is used to complete the analy-
sis to study the mouvement of points in a video se-
quence. Processes such as localization or tracking re-
quired to use this type of data. Several methods offers
this type of study, we can cite SIFT3D (Scovanner
et al., 2007; Klaser et al., 2008) which is the general-
ization of SIFT, SURF generalized (Willems et al.,
2008) or the coupling HOG/HOF (Laptev and Lin-
deberg, 2006; Laptev et al., 2007). To provide the
best possible characteristic points of video for differ-
ent space-time applications, we propose to generalize
our approach REFA, making sure to remain as robust
as possible against the various transformations exist-
ing between two video sequences (translations, rota-
tions, scale changes, timescaling changes). We must
also retain the various constraints that we set for our
spatial method (robustness, matching rate and preci-
sion). All parameters of our new method REFA3D
will be detailed in this article.
Section 2 presents briefly two space-time de-
tectors and three characterizations of points, the
method SIFT3D, SURF generalized and the couplig
HOG/HOF. Additions, changes and parameters used
for the construction of our new approach REFA3D
are detailed in Section 3. To validate our method, we
compare it with the SIFT3D and HOG/HOF, through
various tests by implementing a number of transfor-
mations of data in section 4. We also propose results
for the registration of subsequence.
2 RELATED WORK
Many approaches provide tools to extract and charac-
352
Grand-Brochier M., Tilmant C. and Dhome M..
REFA3D: ROBUST SPATIO-TEMPORAL ANALYSIS OF VIDEO SEQUENCES.
DOI: 10.5220/0003857203520357
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2012), pages 352-357
ISBN: 978-989-8565-03-7
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

terize the interest points moving in time. For detec-
tion, we can cite Laptev and Lindberg (Laptev and
Lindeberg, 2003), Dollar and al (Dollar et al., 2005)
and Willems and al (Willems et al., 2008). The spatio-
temporal description is generally based on the cou-
pling, or the extension 2D+t, of existing methods
such as SIFT (Lowe, 1999; Lowe, 2004) or SURF
(Bay et al., 2006). A listing of these generaliza-
tion was published by Wang and al (Wang et al.,
2009). We limit our analysis to the SIFT3D (Sco-
vanner et al., 2007; Klaser et al., 2008) and to the
coupling HOG/HOF (Laptev and Lindeberg, 2006;
Laptev et al., 2007)
Introduced by Laptev and Lindberg (Laptev and
Lindeberg, 2003), Harris3D proposes a temporal gen-
eralization of the matrix of Harris, to obtain the tensor
of structure:
M = g
σ,τ
∗
I
2
x
I
x
I
y
I
x
I
t
I
x
I
y
I
2
y
I
y
I
t
I
x
I
t
I
y
I
t
I
2
t
. (1)
where g
σ,τ
is the spacetime Gaussian function, de-
fined by a spatial scale σ and by a temporal scale τ.
Dollar and al. coupling in 2005 this approach with the
impulsives responses of the temporal filters define by:
h
ev
(t;τ) = −cos(8πt)e
−t
2
/τ
2
and h
od
(t;τ) = −sin(8πt)e
−t
2
/τ
2
,
(2)
Willems and al. resume in 2008 the general idea of
Laptev and Lindeberg to apply it to the hessian matrix
and to create the hes-STIP (hessian spatio-temporal
interest point) detector. Their goal is to propose a gen-
eralization of the SURF method, usually used for the
images analysis.
To generalize the SIFT descriptor, Scovanner and
al then Klaser and al, add it a 3D analysis model. Fig-
ure 1 illustrates their histograms HOG3D (Klaser and
al.), by detailing the steps of construction.
Figure 1: Various steps of the HOG3D construction: sam-
pling of the mask of analysis (a et b), determination of the
gradient orientation (d) in every sub-block with an icosahe-
dron (c). (Klaser et al., 2008).
This approach consists to determine a region of 3D
analysis, centred on the interest point. The mask is
divided into M × M × N blocks which is divided in
turn into S
3
sub-blocks (Figure 1.a and 1.b). The ori-
entation is determined with a regular polyhedron (Fig-
ure 1.c). Finally an histogram of oriented gradients is
built on each b
j
.
A spatio-temporal extension of the SURF is pro-
posed by Willems and al. The principle is to extend
the Haar warvelet to a cuboid of size sσ × sσ × sτ,
where σ and τ are respectively the spatial scale and
the temporal scale and s is a factor defined by the
user. The descriptor is made up of the Harr wavelets
responses x, y and t.
Laptev et al. (Laptev and Lindeberg, 2006; Laptev
et al., 2007) combine different histograms to define
the spatial and the temporal aspects. Their idea is to
build a HOG with a spatial analysis ’classic’ and pair
it with a histogram of oriented optical flow (HOF) in
order to have a temporal concept.
We presented various approaches of detection and
local description, integrating a temporal analysis. The
study of these methods allows us to extract the main
advantages from it (stability, performances and invari-
ances). We propose a generalization of our approach
REFA (Grand-brochier et al., 2011) based on these
diffrents tools and based on an ellipsoidal local ex-
ploration. So we detail in the next section, the mod-
ifications, the new parameters and the optimizations
used.
3 METHOD
We propose a generalization of our method, to include
space-time data to process video. To remain as invari-
ant as possible to the various image transformations,
our approach is divided into three parts: a hes-STIP
detector (hessian spatio-temporal interest point), a lo-
cal E-HOG3D (ellipsoid histogram of oriented gra-
dients 3D) and an optimized matching. This section
describes the different steps of our method and pa-
rameters used.
3.1 Detection
Proposed by Willems and al. (Willems et al., 2008),
the hes-STIP is a generalization of the fast-hessian
method (Bay et al., 2006), to include temporal data.
This addition provides the following equation:
H(x;σ, τ) =
L
xx
(x;σ, τ) L
xy
(x;σ, τ) L
xt
(x;σ, τ)
L
xy
(x;σ, τ) L
yy
(x;σ, τ) L
yt
(x;σ, τ)
L
xt
(x;σ, τ) L
yt
(x;σ, τ) L
tt
(x;σ, τ)
(3)
Its construction is based on the interpretation of the
hessienne matrix (equation 3) and particularly on two
local scales: σ and τ. The first corresponds to the
space exploration defined by the fast-hessien and the
REFA3D: ROBUST SPATIO-TEMPORAL ANALYSIS OF VIDEO SEQUENCES
353

second allows us to add a temporal analysis of the lo-
cal information. To optimize this detector, we observe
the influence of these two scales on the repeatability
rate of our method. The results show that this rate is
optimal for a spatial analysis following two octaves
and a temporal exploration following four scales. The
number of points is not the most significant for ap-
plications such as the homography estimation or ob-
jects recognition for exemple. On the contrary, good
matchings precision increase strongly the quality and
the performances, due to a lower number of outliers
(false matchings). So we choose these criteria in spite
of 7% loss of matched points.
3.2 Description
The local description of the method REFA is based
on the use of histograms of oriented gradients fol-
lowing an elliptical mask. The addition of temporal
data forces us to change our mask, transforming the
ellipses in ellipsoids. In order to analyze the entire
spatio-temporal information, we propose the mask
shown in Figure 2, based on a sampling of the ellip-
soidal neighborhood of the interest point. The latter
is determined according to five levels of description
(level -2 to level 2) combining 37 ellipsoids. For bet-
ter visibility of the spatio-temporal aspect of our de-
scriptor, we only display the centers of the ellipsoids
in the illustration.
Figure 2: Representation of our analysis ellipsoidal mask,
according to five levels of description.
The parameters of the ellipsoids are based on the
scales (spatial and temporal) of local interest points.
To increase the invariance to rotation, we adjust the
mask analysis in two angles. The analysis of the ma-
trix Harris3D (equation 1) introduced by Laptev and
Lindeberg (Laptev and Lindeberg, 2003) to retrieve
two angles θ and ϕ, shown in Figure 3.
The description of the method REFA is essen-
tially based on the use of histograms of oriented gra-
Figure 3: Illustration of spatial adjustement (left) and tem-
poral (right) of an ellipsoid.
dients (eight classes). So the addition of temporal data
forces us to change these histograms. Building on the
work of Klaser and al. (Klaser et al., 2008), providing
a generalization of HOG in space-time domain, we
construct the following twenty classes. To do this, our
histograms is based on an icosahedron (regular poly-
hedron) to optimize the distribution of such data. The
choice of the class of the histogram based on the de-
termination of the intersection of the gradient vector
with one of the twenty faces of the icosahedron. To
order our descriptor optimally, the face corresponding
the first class of our histograms are readjusted accord-
ing to the vector v. The latter corresponds to the com-
bination readjustments shown in Figure 3.
A final step is to saturate the values of the gradi-
ents, allowing us to increase the robustness to illumi-
nation changes. This process limits the influence of
outliers characterized by high gradient values.
3.3 Matching
The goal is to find the best similarity (corresponding
to the minimum distance) between descriptors des
I
1
and des
I
2
of two video sequences. Euclidean distance,
denoted d
e
, between two descriptors is defined by:
d
e
(des
I
1
(x
k
,y
k
,t
k
),des
I
2
(x
l
,y
l
,t
l
)) =
q
[des
I
1
(x
k
,y
k
,t
k
)]
T
· des
I
2
(x
l
,y
l
,t
l
),
(4)
where (x
k
,y
k
,t
k
) = x
k
and (x
l
,y
l
,t
l
) = x
l
represent the
interest points respectively in the first and in the sec-
ond sequence. The minimization of d
e
, denoted d
min
,
provides a pair of points {(x
k
,y
k
,t
k
);(x
˜
l
,y
˜
l
,t
˜
l
)}:
˜
l = argmin
l∈[[0;L−1]]
(d
e
(des
I
1
(x
k
,y
k
,t
k
),des
I
2
(x
l
,y
l
,t
l
))) (5)
and so
d
min
= d
e
(des
I
1
(x
k
,y
k
,t
k
),des
I
2
(x
˜
l
,y
˜
l
,t
˜
l
)). (6)
To reduce the computation time, we generalize the de-
cision tree used by the method REFA. The latter de-
pends on the size of the data provided, its size is there-
fore R
340
(seventeen histograms with twenty classes
each). Regarding the selection threshold and method
of removing duplicates, processes and parameters re-
main unchanged.
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
354
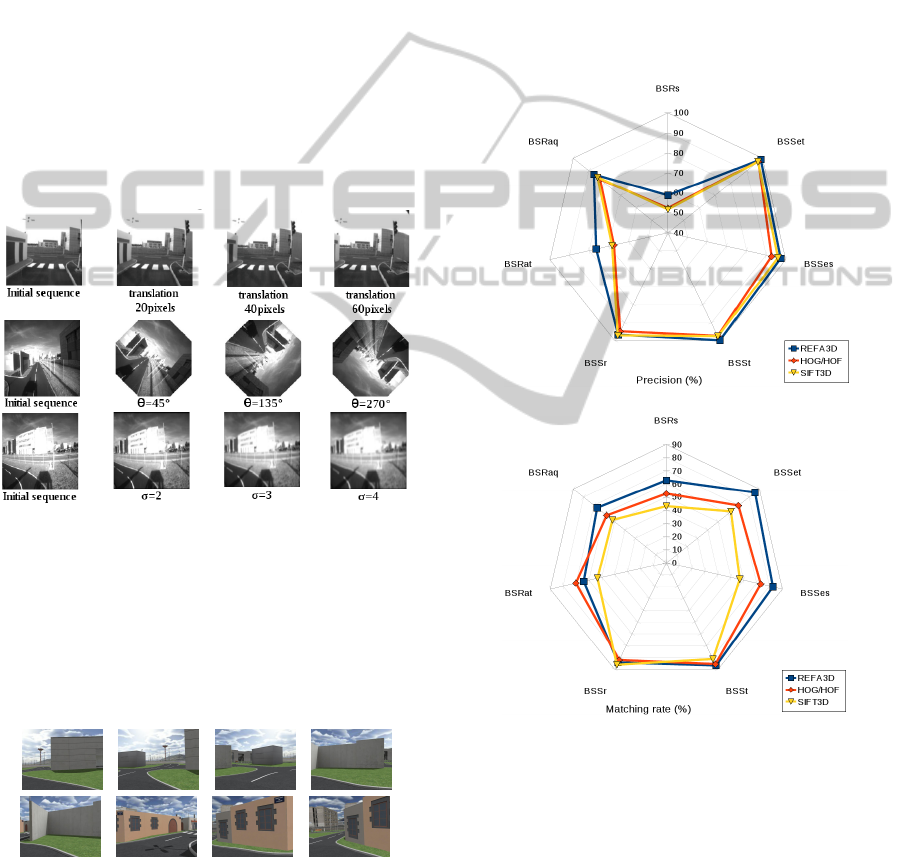
4 RESULTS
We are going to compare our method REFA3D
with SIFT3D (Klaser et al., 2008) and the coupling
HOG/HOF (Laptev and Lindeberg, 2006; Laptev
et al., 2007). These two methods give good results
for video analysis. We propose to study the matching
rate and the precision of each of them. We will also
study the subsequences registration.
4.1 Databases
The first database, noted BSS, is based on video ex-
tracted from an onboard camera. We then apply syn-
thetic transformations such as translations (BSS
t
), ro-
tations (BSS
r
), scale changes (BSS
es
) or timescaling
changes (BSS
et
). Figure 4 illustrates these transfor-
mations.
Figure 4: Examples of transformations (translations, rota-
tionsby an angle θ and scale changes σ).
The second database, noted BSR, comes from
the simulator ASROCAM (Malartre, 2011; Delmas,
2011), to create trajectories (BRSs, BSRaq, BSRat) in
a virtual environment. Figure 5 shows an example of
this database.
Figure 5: Example of an image sequence created by simu-
lator ASROCAM.
4.2 Evaluation Tests and Results
4.2.1 Matching Rate and Precision
We propose to compare the matching rate as well
as the precision of method REFA3D (blue), SIFT3D
(yellow) and HOG/HOF (red). The matching rate
is defined by the number of matches divided by the
number of possible matches. The precision is defined
by the number of correct matches divided by the num-
ber of matches performed. Figure 6 shows a synthesis
of the results obtained.
Figure 6: Summary of results for the spatio-temporal preci-
sion (left) and matching rate (right).
Given the different results, it appears that our ap-
proach has the best results in most cases. Its precision
decreases for real changes, but remains higher than
the HOG/HOF and SIFT3D. Our approach also pro-
vides a better overall matching rate, characterizing a
description more relevant in the neighborhood. Fi-
nally our method REFA3D is more robust and stable
for the various transformations considered. To detail
the precision curves of different methods, we propose
Figures 7 and 8.
REFA3D: ROBUST SPATIO-TEMPORAL ANALYSIS OF VIDEO SEQUENCES
355
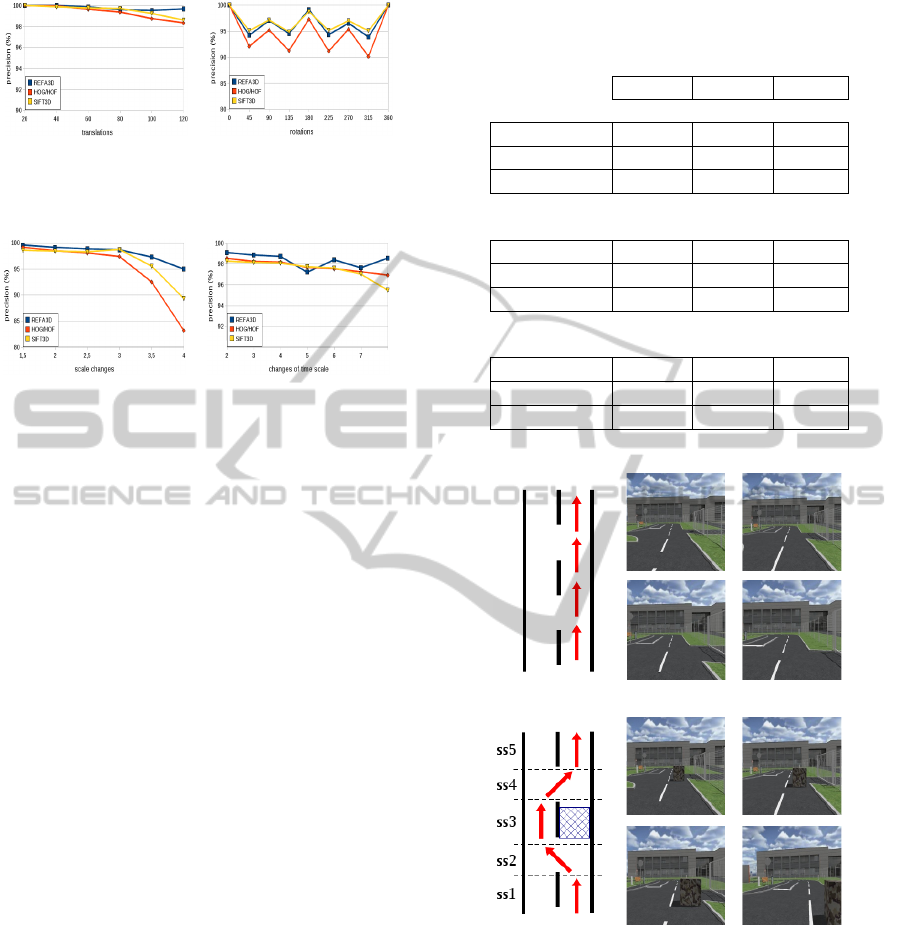
(a) (b)
Figure 7: (a) Precision rate for translation (in pixels) and (b)
precision rate for rotations (in degrees).
(a) (b)
Figure 8: (a) Precision rate for scale changes and (b) preci-
sion rate for timescaling changes.
Concerning transformations studied, our method
has generally a higher precision than other methods
or similar to SIFT3D in the case of rotations. The
stability also enables us to conclude that a better ro-
bustness of our approach. Nevertheless, these results
are based on various tools (optimization, threshold)
involving a slight decrease in the number of matched
points.
4.2.2 Subsequences Registration
We propose a study of the subsequence registration.
First we analyze three trajectories: a straight line, a
curve and a subsequence simulation. Table 1 show
the precision “P”, the number of matches “Nm” and
the frame rates are registrated “Fr”, for three methods
compared. It appears that our approach has a registra-
tion generally with a better precision of matches and
the rate of registered images is greater. Our approach
therefore presents a more relevant description of the
scene. The only disadvantage is the decrease in the
number of matching.
We propose a final test by implementing readjust-
ments of five subsequences in an obstacle avoidance.
Figure 9 illustrates the five stages of obstacle avoid-
ance, and subsequences associated. Table 2 shows the
results (“P” for the precision in percent and “Fr” for
the frame rates are registrated in percent) of REFA3D
methods, SIFT3D and HOG/HOF. The analysis of
these results shows that our approach gives a precision
rate and registered images generally higher than those
of the methods compared. Only SIFT3D presents, for
the subsequence ss5, a higher precision. Our method
Table 1: Results for the registration of subsequences for our
method REFA3D, the coupling HOG/HOF and the method
SIFT3D.
P Nm Fr
REFA3D
Straight line 99.8% 204 100%
Curve 97.6% 155 97.6%
Simulator 97.4% 237 98.3%
HOG/HOF
Straight line 99.2% 212 99.6%
Curve 96.9% 178 95.3%
Simulator 94.8% 256 92.5%
SIFT3D
Straight line 98.7% 284 98.1%
Curve 97.2% 247 97.8%
Simulator 95.4% 294 93.2%
Figure 9: Samples of the initial sequence and those with an
obstacle avoidance (split into five subsequence).
also has better stability, represented by decreases low-
est observation criteria. With the performances ob-
tained by our method, it would be interesting to con-
sider the use of these data in a different process of
realignment of the vehicle on its nominal trajectory.
The matches extracted by our approach would esti-
mate, frame by frame, the homography and thus to
calculate the various parameters of registration to pro-
vide the localization system.
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
356

Table 2: Results for the registration of subsequences in an
obstacle avoidance.
REFA3D HOG/HOF SIFT3D
P Fr P Fr P Fr
ss1 99.4 100 98.7 99.5 99.2 100
ss2 91.3 95.6 89.2 90.3 86.7 93.3
ss3 79.1 87.6 67.3 72.3 71.2 81.3
ss4 85.4 92.2 79.6 84.4 81.3 88.4
ss5 94.7 97.3 91.3 91.5 95.1 95.6
5 CONCLUSIONS
We propose in this article a space-time generalization
of our method REFA. To do this, we use the detec-
tor hes-STIP, which has the highest repeatability rate
for this type of analysis. The optimization that we
bring on the limitation of exploration scales (spatial
and temporal). The mask of analysis is also modified
to add the time component in the histograms. The
ellipses are converted into ellipsoids and we use five
levels of description (Figure 2). Adding a temporal
adjustment results a stable three-dimensional explo-
ration of the sequence. To validate this space-time
generalization, we first propose several tests based on
sequences from a real camera and a simulator. The
results show that our approach generally gets the best
precision. We also observe a better stability and a
higher matching rate. In a second step, we study the
registration of subsequences. This type of process is
used to provide space-time informations of the object
(localization, trajectory for example). Our method
performs best for the precision and the rate of reg-
istered images.
Our future prospects is the integration of our ap-
proach REFA3D in intelligent vehicles. Our goal is to
improve again and again the precision of our method,
for the vehicules to be more reliable and secure. An
other prospect is to export our descriptor to three-
dimensional field to use it in medical imaging.
REFERENCES
Bay, H., Tuylelaars, T., and Gool, L. V. (2006). Surf :
Speeded up robust features. European Conference on
Computer Vision, pages 404–417.
Delmas, P. (2011). Gnration active des dplacements d’un
vhicule agricole dans son environnement. PhD thesis,
University Blaise Pascal - Clermont II.
Dollar, P., Rabaud, V., Cottrell, G., and Belongie, S. (2005).
Behavior recognition via sparse spatio-temporal fea-
tures. IEEE International Conference on Computer
Vision.
Grand-brochier, M., Tilmant, C., and Dhome, M. (2011).
Method of extracting interest points based on multi-
scale detector and local e-hog descriptor. Interna-
tional Conference on Computer Vision Theory and
Applications.
Klaser, A., Marszalek, M., and Schmid, C. (2008). A spatio-
temporal descriptor based on 3d-gradients. British
Machine Vision Conference, pages 995–1004.
Laptev, I., Caputo, B., Schuldt, C., and Lindeberg, T.
(2007). Local velocity-adapted motion events for
spatio-temporal recognition. Computer Vision and Im-
age Understanding, 108(3):207–229.
Laptev, I. and Lindeberg, T. (2003). Space-time interest
points. IEEE International Conference on Computer
Vision, 1:432–439.
Laptev, I. and Lindeberg, T. (2006). Local descriptors for
spatio-temporal recognition. Computer and Informa-
tion Science, 3667:91–103.
Lowe, D. (1999). Object recognition from local scale-
invariant features. IEEE International Conference on
Computer Vision, pages 1150–1157.
Lowe, D. (2004). Distinctive image features from scale-
invariant keypoints. International Journal of Com-
puter Vision, 60(2):91–110.
Malartre, F. (2011). Perception intelligente pour la navi-
gation rapide de robots mobiles en environnement na-
turel. PhD thesis, University Blaise Pascal - Clermont
II.
Scovanner, P., Ali, S., and Shah, M. (2007). A 3-
dimensional sift descriptor and its application to ac-
tion recognition. ACM Multimedia.
Wang, H., Ullah, M., Klaser, A., Laptev, I., and Schmid, C.
(2009). Evaluation of local spatio-temporal features
for action recognition. British Machine Vision Con-
ference.
Willems, G., Tuytelaars, T., and Gool, L. V. (2008). An effi-
cient dense and scale-invariant spatio-temporal inter-
est point detector. European Conference on Computer
Vision, 5303(2):650–663.
REFA3D: ROBUST SPATIO-TEMPORAL ANALYSIS OF VIDEO SEQUENCES
357
