
TOWARDS DATA AND DATA QUALITY MANAGEMENT
FOR LARGE SCALE HEALTHCARE SIMULATIONS
∗
Position Paper
Philipp Baumg
¨
artel and Richard Lenz
Chair for Computer Science 6 (Data Management), Friedrich-Alexander University of Erlangen-Nuremberg,
Erlangen and Nuremberg, Germany
Keywords:
Simulation data management, Knowledge management, Ontologies, Healthcare.
Abstract:
The approach of ProHTA (Prospective Health Technology Assessment) is to understand the impact of medical
processes and technologies as early as possible. Therefore, simulation techniques are utilized to estimate the
effects of innovative health technologies and find potentials of efficiency enhancement within the supply chain
of healthcare. Data management for healthcare simulations is required as heterogeneous data is needed both
as simulation input data and for validation purposes. The main problem is the heterogeneity of the data and the
initially unknown and continuously changing demands of the simulation. Also, data quality considerations are
necessary to quantify the reliability of simulation output. A solution has to consider all of these aspects and
must be extensible to cope with changing requirements. As the structure of the data is not known in advance,
a generic database schema is required. This paper proposes an approach to store heterogeneous statistical
data in an RDF-triplestore. Semantic annotations based on conceptual models are utilized to describe the
datasets. Additionally, a special query language helps loading the data into the simulation. The feasibility of
the approach has been demonstrated in a prototype implementation. We discuss the benefits of this approach
as well as remaining challenges and issues.
1 INTRODUCTION
The main goal of ProHTA (Prospective Health Tech-
nology Assessment) is to simulate medical processes
to gain information about the impact of diverse new
health technologies on healthcare. Therefore, a mod-
ular simulation framework has to be designed to an-
swer questions about different new medical products.
Besides the problems of simulation modeling, val-
idation and optimization, simulation data manage-
ment is required. Skoogh et al. (Skoogh et al., 2010)
claim that the input data management process con-
sumes about 31% of the time of a simulation study.
They argue that in most cases the data is collected
manually for each simulation study. Robertson and
Perera (Robertson and Perera, 2002) conducted a sur-
vey showing that 60% of the polled simulation prac-
titioners manually input the data to the simulation
model.
ProHTA shall become a framework to be used to
answer different questions in the same domain.
∗
On behalf of the ProHTA Research Group.
Hence, the reusability of simulation model compo-
nents and input data is important. The main data
management problem is to store heterogeneous data
in such a way as to ensure its reusability. Typi-
cal data sources contain preaggegated data, like e.g.
demographic data, healthcare statistics, geographic
data etc. These data are to be provided, both to
feed the heathcare simulation with realistic parame-
ters and to validate the simulation. To be able to cope
with rapidly growing data sets and new unknown data
sources, we propose an approach to store arbitrary sta-
tistical data without previously fixing its semantics in
a database schema. By semantically annotating the
stored data, we are able to search for already inte-
grated datasets for reuse.
Another major problem is data quality. Because
decisions may be based on the simulation output, its
reliability is important. Therefore, the simulation
models have to be validated and the quality of the
input data has to be quantified. Data provenance is
important for simulation studies to be repeatable and
to determine data quality (Stonebraker et al., 2009).
Additionally, storing the inherent uncertainty of sci-
275
Baumgärtel P. and Lenz R..
TOWARDS DATA AND DATA QUALITY MANAGEMENT FOR LARGE SCALE HEALTHCARE SIMULATIONS - Position Paper.
DOI: 10.5220/0003871602750280
In Proceedings of the International Conference on Health Informatics (HEALTHINF-2012), pages 275-280
ISBN: 978-989-8425-88-1
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

entific data is important to quantify the quality of sim-
ulation output (Stonebraker et al., 2009).
There are two main questions regarding simula-
tion input data management:
1. How can heterogeneous statistical data be stored
and queried to be reusable in many different sim-
ulation studies?
2. How can data quality be quantified to estimate the
reliability of the simulation output?
In this paper, we present our approach to store
simulation input data in an RDF-triplestore. Addi-
tionally, we outline a simple query language for sta-
tistical simulation input data. After the discussion of
data quality issues and related work on simulation in-
put data management, we will conclude with a sum-
mary and a perspective on future work on this subject.
2 DATA MANAGEMENT FOR
LARGE SCALE HEALTHCARE
SIMULATIONS
Figure 1 depicts our basic data management concept
for healthcare simulations. One of the main problems
is the heterogeneity of the data sources. Therefore, a
manual ETL process has to be applied to integrate the
data in a central storage. Also, knowledge manage-
ment is important to organize the different datasets.
To be independent from simulation languages and
tools, our data management concept uses a preproces-
sor. A simulation template containing the regular sim-
ulation program and queries is processed. The queries
in the simulation templates are replaced by real data.
Then the resulting simulation containing the data can
be processed by the simulation tool.
The preprocessor also checks data quality con-
straints and provides feedback to the user. It also en-
courages the user to improve the quality of the simu-
lation’s input data.
At the core of our concept is the storage com-
ponent for data and knowledge. Basically, three ap-
proaches exist to store heterogeneous data with un-
known or changing semantic constraints. One possi-
ble solution is a schema-free approach. However, data
in a schema-free storage can not be reused or even
be queried or processed easily. An adaptable schema
would solve this problem. However, when the schema
is adapted, we will need to adapt the applications
using the data as well. Our proposed solution is a
generic schema flexible enough to cope with changing
requirements and heterogeneity but also structured
enough to support querying and reusing the data.
Knowledge-
& Database
Knowledge
Engineering
Simulation-
Template
…
Query
…
Preprocessor
Simulation-
Model
…
Data
…
Input
& Annotation
SQL Word Excel HTML
table
ETL
Data Quality
Frontend
Missing data
Contradictions
Too small samples
Knowledge
Query
Figure 1: Data management concept for healthcare simula-
tions.
A generic relational approach like EAV (Nadkarni
et al., 1999) can be utilized to store information about
entities with an arbitrary number of attributes. This
technique has been adapted for various purposes in-
cluding the storage of structured document contents
(Lenz et al., 2002). The price for flexibility is a loss
of semantic control at the database level. In addition,
queries on an EAV-schema tend to be more complex
than traditional queries. Attempts to regain semantic
control by the use of additional user defined metadata
tables even aggravate the problem of query complex-
ity (Nadkarni et al., 1999). Despite these trade offs,
the usefulness of the EAV approach for certain pur-
poses is out of question.
In our context, the statistical input data is typi-
cally multidimensional rather than document based.
However, because of the heterogeneity of the data, a
conventional data warehouse approach is not suitable.
Also, at the current state of ProHTA, the requirements
for the multidimensional storage are not predictable.
Our attempts to design a relational schema to store
multidimensional data with arbitrary dimensions and
a flexible number of attributes resulted in EAV-like re-
lations containing triples. Because of the drawbacks
of EAV, we decided to choose RDF (Lassila et al.,
1999), being inherently triple-based, to store the sim-
ulation input data and additional metadata.
2.1 Storing Heterogeneous
Multdimensional Data in RDF
We compared the most prominent approaches to de-
scribe multidimensional data in RDF in Table 1.
Modeling dimensions as properties instead of
classes results in less triples than storing dimensions
as separate instances, but is also less flexible. Because
of the need to annotate dimensions with further in-
HEALTHINF 2012 - International Conference on Health Informatics
276

Table 1: Comparison of different ontologies for multidimensional data.
Ontology Class Hierarchies Summarizability Unit Multi-measure
based observations
dimensions
(Cyganiak et al., 2010) No No No Yes Yes
(Hausenblas et al., 2009) Yes No No No No
(Niemi et al., 2007) No No No No Yes
(Niemi and Niinim
¨
aki, 2010) No No Yes Yes Yes
(Kurze et al., 2010) Yes Yes No No Yes
Requirements of Yes Yes Yes Yes Yes
ProHTA
formation, a class based approach is required in our
scenario.
Only the approach of Kurze et al. (Kurze et al.,
2010) supports classification hierarchies in the dimen-
sions. Unfortunately they do not describe their ap-
proach in sufficient detail.
Summarizability information (Lenz and Shoshani,
1997) is only considered by Niemi and Niinim
¨
aki
(Niemi and Niinim
¨
aki, 2010). This is important for
automatic aggregation. Other important aspects are
the unit of the measured data and the support for
multi-measure observations.
To our knowledge, no well documented approach
to store multidimensional data in RDF fulfilling all
our requirements exists. Therefore, we developed our
own RDF-schema.
Figure 2: RDF-schema to store multidimensional data.
A simplified version of our data model is depicted
in Figure 2. This schema was designed to support
efficient querying and to avoid redundancy. There
are facts linked to different observations, although
in Figure 2 there is only one value (rdf:value) de-
picted. Facts can be grouped together and one dataset
can contain multiple groups of facts. There are di-
mensions like age, time or gender. A specific fact
group has different dimensions in a specific granular-
ity like day, month or year. Also, the information how
to aggregate along a given dimension is stored for
each group of facts. At the moment, this is the only
summarizability information we store. These infor-
mations are stored using the artificial class :SetDim.
Facts are identified by the instances of one dimension
like a specific day in the time dimension. The hierar-
chy of dimension instances is stored using the :partOf
property. Additionally, the hierarchy of granularities
is stored using the :partOfGranularity property. This is
not redundant, because the hierarchical dependencies
between granularities have to be stored even if no di-
mension instances in these granularities exist. Addi-
tionally, the connection between dimension instances
in different granularities can not be derived from the
hierarchy of granularities. However, inconsistencies
between these two hierarchies are possible and have
to be prevented.
We also store information about the unit of obser-
vations in one group of facts. Each unit is linked to
a base unit and the conversion factors between a unit
and it’s base unit are stored. However, this is not de-
picted in Figure 2.
2.2 Knowledge Management
Currently, the different datasets are only identified by
their name. When the simulation models grow in
size and detail, the problem of finding the appropri-
ate dataset in the RDF-triplestore will arise. There-
fore, it is necessary to store context information about
datasets. Hence, detailed semantic descriptions of
datasets are required.
In our simulation project, we are developing con-
ceptual models as a first step towards executable sim-
ulation models. These conceptual models can be for-
malized using the RDF ontology we are currently de-
veloping. Then, data and simulation models are able
to reference the formalized conceptual models and
data sets can be queried using terms from the con-
ceptual models.
The main problem is that many different concep-
tual models are needed for our simulation project.
There are, for example, high level models represent-
ing stocks and flows and more detailed models repre-
TOWARDS DATA AND DATA QUALITY MANAGEMENT FOR LARGE SCALE HEALTHCARE SIMULATIONS -
Position Paper
277
senting individuals and decisions.
Figure 3: Describing conceptual models in RDF.
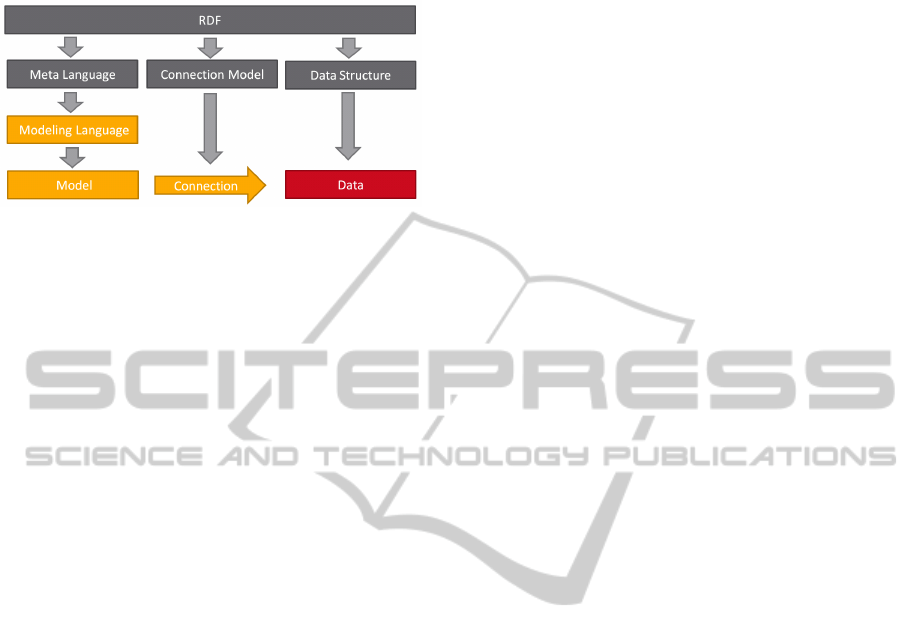
Figure 3 depicts our idea to solve this problem.
A fixed meta language is used to describe different
modeling languages. For example, we can describe a
language to describe stock and flow models.
These modeling languages are then used to de-
scribe individual conceptual models. The data needed
to execute our simulations can be described using a
connection model to create links between data and
conceptual models. The structure to actually store the
data has been explained in Section 2.1.
This approach is currently under development.
3 A QUERY LANGUAGE FOR
HEALTHCARE SIMULATIONS
Another benefit from simulation data management is
the independence between data collection and model
building. Once the data is stored, the simulation mod-
eler is exempt from the task to manually input the data
to the simulation model. The task of the simulation
modeler is now to query the data from the data stor-
age component. To load data into the simulation two
kinds of information are necessary:
1. What dataset should be loaded?
2. In which form should the data be loaded? (E.g.
dimensions, granularity, unit, ...)
The data is semantically annotated in RDF uti-
lizing conceptual models and our schema for mul-
tidimensional data. Therefore, both the first and
second question could be answered in SPARQL
(Prud’hommeaux and Seaborne, 2008). However,
SPARQL queries selecting appropriate data items
would be very complex because our RDF schema
contains additional meta data. Another problem is
that aggregation is not part of the SPARQL standard.
It would be much more convenient and powerful to
use a query language for multidimensional data like
MDX (Multidimensional Expressions). We are cur-
rently developing a simple query language specifi-
cally designed for statistical simulation input data .
That way, the queries are independent from the actual
multidimensional RDF structure.
For example, a query to get the number of men
aged between 50 and 60 years in a population depend-
ing on age and time could be expressed as:
select cube<One> (Time<Year>,
Age<Year> = [50-60],
Gender<MW> = "M")
from Population;
One additional information contained in this query
is the desired unit of the observations. In this exam-
ple, the unit is simply “One”.
At the moment datasets are selected by name. In
the future the connection to conceptual models will
be utilized to find datasets.
If more information than just one value per fact is
stored, it can be queried by adding arbitrary SPARQL
statements to our query language. That way arbitrary
information with multidimensional structure can be
stored and queried. For example, the time of diag-
nosis and treatment steps in a hospital depending on
age and gender could be stored in one data cube.
select ?ci cube<One> (Time<Year>,
Age<Year> = [50-60],
Gender<MW> = "M")
from Population
with {
?fact data:confidence_interval ?ci .
};
Because our query language adds unit conversion
and automatic aggregation to SPARQL, we can not
simply translate queries. To process a query in our
language, it is checked whether an appropriate dataset
with sufficient data quality exists in the data stor-
age. The factor to convert the observations to the
desired unit is calculated. Then, the dataset is ag-
gregated to the desired dimensions and granularities
and the resulting dataset is stored as a new group of
facts for provenance reasons. After that, the remain-
ing query processing is done by translating the query
to an equivalent SPARQL query.
4 DATA QUALITY
CONSIDERATIONS
As previously mentioned, measurability of data qual-
ity contributes to the success of ProHTA. Only simu-
lation results with quantifiable reliability are useful.
Accuracy is the most prominent data quality di-
mension, however Wang and Strong (Wang and
Strong, 1996) listed other types of data quality as
HEALTHINF 2012 - International Conference on Health Informatics
278

well. Besides the quality of the input data, other
aspects influence the quality of the simulation out-
put. High accuracy and appropriate granularity of
the simulation model are required for precise results.
Also, the characteristics of the simulation model’s er-
ror propagation have influence on the output’s quality.
For example, Cheng and Holland (Cheng and Hol-
land, 2004) developed an approach to calculate confi-
dence intervals for simulation output. This method is
concerned with the variability arising from the use of
random numbers in the simulation and the uncertainty
of the parameters.
In order to continuously improve data quality we
need a methodological approach to data quality man-
agement (Batini et al., 2009). Firstly, the necessary
data quality dimensions have to be identified. Then,
the data quality has to be converted to a statistical
measure (e.g. a confidence interval). The simulation
model’s error propagation characteristics have to be
evaluated. Additionally, the accuracy of the simula-
tion model itself has to be estimated by a validation
procedure. Finally, the statistical measure has to be
propagated through the simulation model. That way
the accuracy of the simulation output can be calcu-
lated.
Knowledge engineering is applied to annotate the
stored data. This can also be useful for data quality
considerations. F
¨
urber and Hepp (F
¨
urber and Hepp,
2010) proposed an approach to correct wrong values
using semantically annotated reference data. They
provided SPARQL queries for identifying missing or
illegal values. Another example in our context would
be data from a medical study conducted only in some
hospitals. Then, an ontology describing hospitals,
cities and populations could be utilized to estimate the
generality of this data.
5 RELATED WORK
There are different technical approaches to support
reusability of simulation data. Gowri (Gowri, 2001)
presented EnerXML, an XML schema to enable in-
teroperability between different energy simulations.
Bengtsson et al. (Bengtsson et al., 2009) proposed
the Generic Data Management Tool. It stores input
data for discrete event manufacturing simulations ac-
cording to the Core Manufacturing Simulation Data
(CMSD) specification. Boulonne et al. (Boulonne
et al., 2010) extended the Generic Data Management
Tool by a Resource Information Management compo-
nent. This component enables the reuse of resource
information by generating standard CMSD files.
Another approach to structured simulation data
management are simulation workflows. Reimann et
al. (Reimann et al., 2011) introduced SIMPL – a
framework for data provisioning for simulation work-
flows. This framework supports the ETL-process (ex-
tract, transform and load) for simulation data. Data
is stored as XML, which is flexible enough for het-
erogeneous data. However, the problem of designing
a schema to support reusability of input data remains
unsolved.
SciDB (Rogers et al., 2010) is a project aimed at
scientific data management. The main goal of this
project is to store large multidimensional array data
and to support efficient data processing. In contrast
to SciDB, our main problem is not to handle very
large array data, but to handle many small multidi-
mensional data sets in different granularities with po-
tentially complex datatypes.
A project by Ainsworth et al. (Ainsworth et al.,
2011) aims at simulating healthcare policy interven-
tions in a generic way. Their data management com-
ponent simply uses the NHibernate Framework to
store simulation input data. This approach does not
solve the problem of data heterogeneity. Additionally,
they do not concern data quality and data reusability
issues.
Zhang et al. (Zhang et al., 2011) introduced
SciQL, a query language for scientific applications.
Like SciDB’s query language, SciQL is designed to
query multidimensional arrays, but not for data ware-
houses with hierarchical dimensions.
6 CONCLUSIONS AND FUTURE
WORK
In this paper, we clarified the importance of data and
data quality management in simulation studies. Then,
we proposed a simulation data management approach
using an RDF-triplestore and described how to query
it. Afterwards we discussed data quality challenges
and issues for simulations. Finally, we discussed re-
lated work.
There are three main benefits from our approach.
Our RDF schema is flexible enough to cope with the
changing demands of the simulation. By semantic an-
notations utilizing conceptual models and metadata,
the datasets are also structured enough to be reusable.
The query language, we are developing, helps to load
data into the simulation independently from the ac-
tual multidimensional RDF data structure. Addition-
ally, the stored knowledge and metadata can be used
to control and improve data quality.
We validated our approach with a prototypical im-
plementation of our framework (Figure 1). In future
TOWARDS DATA AND DATA QUALITY MANAGEMENT FOR LARGE SCALE HEALTHCARE SIMULATIONS -
Position Paper
279

work, we will identify the data quality requirements
of a ProHTA simulation study in detail. Also, we will
study how to control and improve data quality by us-
ing stored knowledge. Additionally, we will refine
our approach to store conceptual models and to utilize
them to annotate stored datasets. Finally, the query
language for statistical simulation input data will be
improved.
ACKNOWLEDGEMENTS
This project is supported by the German Federal Min-
istry of Education and Research (BMBF), project
grant No. 01EX1013B.
REFERENCES
Ainsworth, J. D., Carruthers, E., Couch, P., Green, N.,
O’Flaherty, M., Sperrin, M., Williams, R., Asghar,
Z., Capewell, S., and Buchan, I. E. (2011). Impact:
A generic tool for modelling and simulating public
health policy. Methods of Information in Medicine,
5:454–463.
Batini, C., Cappiello, C., Francalanci, C., and Maurino, A.
(2009). Methodologies for data quality assessment
and improvement. ACM Comput. Surv., 41:16:1–
16:52.
Bengtsson, N., Shao, G., Johansson, B., Lee, Y., Leong, S.,
Skoogh, A., and Mclean, C. (2009). Input data man-
agement methodology for discrete event simulation.
In Winter Simulation Conference (WSC), Proceedings
of the 2009, pages 1335 –1344.
Boulonne, A., Johansson, B., Skoogh, A., and Aufenanger,
M. (2010). Simulation data architecture for sustain-
able development. In Proceedings of the 2010 Winter
Simulation Conference.
Cheng, R. C. H. and Holland, W. (2004). Calculation
of confidence intervals for simulation output. ACM
Trans. Model. Comput. Simul., 14:344–362.
Cyganiak, R., Reynolds, D., and Tennison, J. (2010). The
rdf data cube vocabulary. http://publishing-statistical-
data.googlecode.com/svn/trunk/specs/src/main/html/
cube.html.
F
¨
urber, C. and Hepp, M. (2010). Using semantic web re-
sources for data quality management. In Proceedings
of the 17th international conference on Knowledge en-
gineering and management by the masses, EKAW’10,
pages 211–225, Berlin, Heidelberg. Springer-Verlag.
Gowri, K. (2001). Enerxml - a schema for representing en-
ergy simulation data. In Proceedings of the Seventh
International IBPSA Conference.
Hausenblas, M., Halb, W., Raimond, Y., Feigenbaum, L.,
and Ayers, D. (2009). Scovo: Using statistics on the
web of data. In The Semantic Web: Research and Ap-
plications, volume 5554 of Lecture Notes in Computer
Science, pages 708–722. Springer Berlin / Heidelberg.
Kurze, C., Gluchowski, P., and Bohringer, M. (2010). To-
wards an ontology of multidimensional data structures
for analytical purposes. In System Sciences (HICSS),
2010 43rd Hawaii International Conference on, pages
1 –10.
Lassila, O., Swick, R. R., Wide, W., and Consor-
tium, W. (1999). Resource description frame-
work (rdf) model and syntax specification.
http://www.w3.org/TR/1999/REC-rdf-syntax-
19990222.
Lenz, H.-J. and Shoshani, A. (1997). Summarizability in
olap and statistical data bases. In Scientific and Sta-
tistical Database Management, 1997. Proceedings.,
Ninth International Conference on, pages 132 –143.
Lenz, R., Elstner, T., Siegele, H., and Kuhn, K. A. (2002).
A practical approach to process support in health in-
formation systems. Journal of the American Medical
Informatics Association, 9(6):571–585.
Nadkarni, P. M., Marenco, L., Chen, R., Skoufos, E., Shep-
herd, G., and Miller, P. (1999). Organization of het-
erogeneous scientific data using the eav/cr represen-
tation. Journal of the American Medical Informatics
Association, 6(6):478–493.
Niemi, T. and Niinim
¨
aki, M. (2010). Ontologies and sum-
marizability in olap. In Proceedings of the 2010 ACM
Symposium on Applied Computing, SAC ’10, pages
1349–1353, New York, NY, USA. ACM.
Niemi, T., Toivonen, S., Niinimaki, M., and Nummenmaa,
J. (2007). Ontologies with semantic web/grid in data
integration for olap. International Journal on Seman-
tic Web and Information Systems (IJSWIS), 3:25–49.
Prud’hommeaux, E. and Seaborne, A. (2008). Sparql query
language for rdf. http://www.w3.org/TR/2008/REC-
rdf-sparql-query-20080115/.
Reimann, P., Reiter, M., Schwarz, H., Karastoyanova, D.,
and Leymann, F. (2011). Simpl - a framework for
accessing external data in simulation workflows. In
Datenbanksysteme fr Business, Technologie und Web.
Robertson, N. and Perera, T. (2002). Automated data collec-
tion for simulation? Simulation Practice and Theory,
9(6-8):349 – 364.
Rogers, J., Simakov, R., Soroush, E., Velikhov, P., Balazin-
ska, M., DeWitt, D., Heath, B., Maier, D., Madden,
S., Patel, J., Stonebraker, M., Zdonik, S., Smirnov, A.,
Knizhnik, K., and Brown, P. G. (2010). Overview of
scidb, large scale array storage, processing and analy-
sis. In Proceedings of the SIGMOD’10.
Skoogh, A., Michaloski, J., and Bengtsson, N. (2010).
Towards continuously updated simulation models:
Combingin automated raw data collection and auto-
mated data processing. In Proceedings of the 2010
Winter Simulation Conference.
Stonebraker, M., Becla, J., DeWitt, D., Lim, K.-T., Maier,
D., Ratzesberger, O., and Zdonik, S. (2009). Require-
ments for science data bases and scidb. In Proceedings
of the CIDR 2009 Conference.
Wang, R. Y. and Strong, D. M. (1996). Beyond accuracy:
what data quality means to data consumers. J. Man-
age. Inf. Syst., 12:5–33.
Zhang, Y., Kersten, M., Ivanova, M., and Nes, N. (2011).
Sciql, bridging the gap between science and relational
dbms. In Proceedings of the IDEAS11.
HEALTHINF 2012 - International Conference on Health Informatics
280
