
ON PRACTICAL ISSUES OF MEASUREMENT DECISION THEORY
An Experimental Study
Jiri Dvorak
Scio, s.r.o., Pobrezni 34, Prague, Czech Republic
Keywords:
Educational Measurement, Test Evaluation, Decision Theory, Simulation, Calibration.
Abstract:
In Educational Measurement field Item Response Theory is a dominant test evaluation method. A few years
ago Lawrence Rudner has introduced an alternative method providing better results than IRT in some cases
of measurement. However, his method called Measurement Decision Theory did not get much of interest
in the community. In this article we would like to give MDT some of the focus we believe it deserves. In
particular we are focusing on the practical issues necessary to successfully implement MDT into a daily life
of Educational Measurement. We will summarize classification abilities. After that in the main part of this
paper we will explain in depth calibration process which is a crucial part of MDT implementation. A basic
calibration process will be described as well as its characteristics. Then, as a main result, an improvement of
this basic process will be introduced.
1 INTRODUCTION
The most widely used test evaluation method at this
time is the Item Response Theory (IRT). IRT pro-
vides great results in estimating the ability level of
a tested person. Unfortunately such outcomes are
not always applicable. Lots of testing problems are
pass/fail problems: HR services, professional certifi-
cations, high school or university entrance exams etc.
Other tests have to compare person’s skills to a given
standard defining a set of groups (categories/grades)
an examinee could belong to (e.g. CEFRL certifica-
tion, school grades or state assessments in some coun-
tries). These kinds of tests are intended to classify ex-
aminees into given (and defined in advance) groups -
categories. The purpose of many of today’s tests is
rather classification than ability estimation. This ap-
proach is not new. Even Cronbach and Gleser in their
book (Cronbach and Gleser, 1957) argue that the ul-
timate purpose of testing is to arrive at classification
decisions.
Rudner in (Rudner, 2002; Rudner, 2009; Rudner,
2010) discusses main features of IRT usage in solving
classification problems. He argues that since classifi-
cation is a different (and in many ways simpler) task
than ability estimation and IRT is fairly complex and
relies on a several restrictive assumptions, we should
find a more suitable evaluation method intended di-
rectly for classification. Rudner then presents educa-
tional testing based on the classification named Mea-
surement Decision Theory (MDT). We would like to
recall main principles of MDT in the next section (2).
Although MDT has been known for about ten
years and even its background was discussed as soon
as 1970s (Hambleton and M, 1973; van der Linden
and Mellenbergh, 1978), it remains out of the main
focus of measurement community. In this paper we
would like to give MDT some of the attention we
think it deserves. We present a brief overview of ef-
ficiency of MDT (section 4) and especially a kind of
guideline (an application-ready process) of item pa-
rameters estimation in section 5. We recognize lack
of research in both topics as one of the main reasons
why MDT is used so rarely.
2 BACKGROUND
(MEASUREMENT DECISION
THEORY)
Measurement Decision Theory (MDT) is a test eval-
uation method intended to classify examinees. MDT
was introduced by Rudner in (Rudner, 2002) and re-
vised in (Rudner, 2009). In his papers Rudner has
proven that MDT issimpler and more efficient in clas-
sifying examinees than cut-point based IRT classifica-
tion.
94
Dvorak J..
ON PRACTICAL ISSUES OF MEASUREMENT DECISION THEORY - An Experimental Study.
DOI: 10.5220/0003901300940099
In Proceedings of the 4th International Conference on Computer Supported Education (CSEDU-2012), pages 94-99
ISBN: 978-989-8565-07-5
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

MDT is nothing more than Naive Bayes Clas-
sifier (NBC), a well-known classifier from Arti-
ficial Intelligence. Classifiers are algorithms in-
tended to classify objects (examinees in our case
of Educational Measurement) according to their at-
tributes (responses to test items) into a pre-defined
set of classes/groups/categories. NBC overcomes
most of the prerequisites of IRT (especially uni-
dimensionality of tested domain) assuming only a lo-
cal independence of items similarly to both IRT and
CTT.
2.1 Method
2.1.1 Basic Definitions
Def.: Let M be a set of categories and m
k
∈ M the
k-th category. Let U be a set of items and u
i
∈ U the
i-th item. Let Z be a set of examinees and z
j
∈ Z the
j-th examinee.
Def.: Let P(m
k
) be a probability of randomly se-
lected examinee belonging to a category m
k
∈ M and
let ~p = (P(m
1
), P(m
2
), . . . , P(m
k
)).
Def.: Let P(u
i
|m
k
) be a probability of
correct response of an examinee of cate-
gory m
k
∈ M to the item u
i
∈ U and let
~p
i
= (P(u
i
|m
1
), P(u
i
|m
2
), . . ., P(u
i
|m
k
)) be a
vector of parameters of item u
i
∈ U (i.e. calibration
of item u
i
∈ U).
2.1.2 Method Description
Priors. MDT requires us to know in advance sets
M and U and two other priors. The first one is a
vector of distribution of categories in population ~p
and the second one is a set of parameters of items
P = {~p
i
|u
i
∈ U}.
Observations. Observations obtained from a test
for a single examinee are represented by a vec-
tor of his/her responses ~z
j
= (z
j1
, z
j2,
..., z
ji
) where
z
ji
∈ {0, 1} for incorrect/correct response. Let R =
~z
j
|z
j
∈ Z
.
Classification. Let’s describe the classification pro-
cess by a function F : (~p, P,R) → ~c where ~c =
(c
1
,c
2,
...,c
j
) is vector of categories c
j
∈ M
such as c
j
= m
k
⇐⇒ examinee z
j
belongs to
category m
k
. Function F could be rewritten
into a vector of simpler functions F (~p, P, R) =
( f (~p, P,~z
1
), f (~p,P,~z
2
), . . . , f (~p, P,~z
j
)) defined in
equation 1 and subsequent equations 2, 3 and 4.
f (~p, P,~z) = m ∈ M; P(m|~z) = max
m
k
∈M
(P(m
k
|~z)) (1)
P(m
k
|~z) = n
c
P(~z|m
k
)P(m
k
) (2)
n
c
=
1
∑
m
k
∈M
P(~z|m
k
)P(m
k
)
(3)
P(~z|m
k
) =
∏
{i|z
i
=1}
P(u
i
|m
k
) ·
∏
{i|z
i
=0}
(1− P(u
i
|m
k
))
(4)
Note that function F is application of Bayes’ The-
orem. Equation 4 implies the “naive“ assumption of
local independence of responses to items. n
c
used in
equation 2 and defined in equation 3 is a normalizing
constant ensuring
∑
m
k
∈M
P(m
k
|~z) = 1.
3 METHODOLOGY
Our study is based on results of experimental appli-
cations of MDT performed in simulated environment.
In this section we summarize essential parts of simu-
lation.
Def.: Since simulation often uses randomness we
define a random function RAN : (S,~v) → s ∈ S
such as s is selected randomly from S with re-
spect to the probability distribution vector ~v =
v
1
, v
2
, . . . , v
|S|
,
∑
v
i
= 1.
3.1 Test and Item Generator
A test is a set of randomly generated items. There-
fore, an item generator is an essential part of a sim-
ulation engine. Our model represented by func-
tion GI :
/
0 → ~p
i
is based on two main assumptions.
At first it assumes that categories represent sequen-
tial grades: for each item u
i
and each m
k
stands
P(u
i
|m
k−1
) < P(u
i
|m
k
) < P(u
i
|m
k+1
). At second that
items are quite good: max(P(u
i
|m
k+1
) − P(u
i
|m
k
)) ∈
h0.2, 0.6i. Function GI ()generates ~p
i
of random ele-
ments P(u
i
|m
k
) with respect to this assumptions.
4 ACCURACY OF
CLASSIFICATION
Instead of recalling Rudner’s experiments comparing
IRT and MDT we are focusing on practical issues of
ONPRACTICALISSUESOFMEASUREMENTDECISIONTHEORY-AnExperimentalStudy
95

MDT. At first we wouldlike to showa relationship be-
tween classification accuracyand the number of items
or categories respectively. In both cases we are inter-
ested in theoretical limits (given quality of items) of
accuracy. The classification is performed on actual
parameters of items not on the estimated parameters.
Following experiments share commonframework.
A single experiment is repeated a few hundred times
and then statistical characteristics of results of the set
of experiments are evaluated. Overall results are pre-
sented as a so-called box-graph where around a hori-
zontal line representing median is a box showing first
and third quartile with whiskers as extreme values.
Box-graphs show both the most likely results (me-
dians) and the stability of results (quartiles and ex-
tremes).
4.1 Experiments
In this section we present a framework common to
experiments following in section 4.2.
Def.: Let’s have a given number of categories m,
number of items u and number of examinees z = 200
defining sets M, U and Z.
Step 1. Let’s have a set of parameters of items P
U
=
S
u
i
∈U
GI() of actual parameters of items in U, vector
of categories~c
Z
such as c
Z
j
= RAN ({1, 2, .. . , m}, ~p)
where ~p =
1
m
,
1
m
, . . . ,
1
m
(note we are assuming
equal distribution of ~p), where examinees z
j
∈ Z
belong to and a set R of responses such as z
ji
=
RAN
{0, 1} ,
n
1− P
U
u
i
|c
Z
j
, P
U
u
i
|c
Z
j
o
.
Step 2. Let~c = F
~p, P
U
, R
.
Step 3. Let classification error rate e = E
~c,~c
Z
where function E = (~v, ~w) is defined by equation 5.
E (~v, ~w) =
j| v
j
6= w
j
|~w|
(5)
4.2 Results
Here we show results of two sets of experi-
ments. The first one with setting m = 5 and u =
(10, 20, 30, 40, 50, 60, 70, 80, 90, 100) is shown in
Figure 1-left . We can see that the error rate falls with
the number of items not only in the sense of the most
likely result but also in the sense of stability. The
same effect could be seen in Figure 1-right where a
similar set of experiments with m = 8 is presented.
10 20 30 40 50 60 70 80 90 100
0.0 0.1 0.2 0.3 0.4
items (5 groups)
error rate
10 20 30 40 50 60 70 80 90 100
0.0 0.1 0.2 0.3 0.4 0.5 0.6
items (8 groups)
error rate
Figure 1: Accuracy of classification vs. number of items
(5(left)/8(right) categories, ideal parameters = theoretical
limits).
2 3 4 5 6 7 8 9 10
0.00 0.05 0.10 0.15 0.20 0.25
categories
error rate
Figure 2: Accuracy of classification vs. number of cate-
gories (ideal parameters = theoretical limits).
Figure 2 shows results of an experiment of setting
u = 50 and m = (2, 3, 4, 5, 6, 7, 8, 9, 10). The accu-
racy of classification significantly decreases with the
increasing number of categories.
In Figure 3 we are presenting an overview of the-
oretical limits of calibration. We can see how many
items we need for a given number of categories to ob-
tain e < 0.1. More precisely, the figure shows mini-
mal number of items for a given number of categories
when median of error rates was below 0.1.
2 4 6 8 10
10 20 30 40 50 60
categories
items
Figure 3: Number of items needed to get median of classi-
fication errors below 0.1 for given number of categories.
CSEDU2012-4thInternationalConferenceonComputerSupportedEducation
96

5 CALIBRATION
In (Rudner, 2002; Rudner, 2009; Rudner, 2010) Rud-
ner spends only a few words talking about MDT cali-
bration (estimation of priors - vector ~p and set P). But
for practical purposes calibration process is essential.
In this section we are presenting methods of calibra-
tion and results of our experiments showing charac-
teristics of calibration process important to implement
MDT in real-world testing. In this section we are fo-
cused entirely on an estimation of set P because in the
worst case, if we were unable to estimate ~p, we could
set it ~p =
1
|M|
,
1
|M|
, .. . ,
1
|M|
(equally distributed cat-
egories in population) without fatal consequences to
method precision (see (Rudner, 2009)).
5.1 Basic Calibration
As we have already mentioned MDT is an instance
of well-known Naive Bayes Classifier (NBC). NBC
is widely used in a scope of Artificial Intelligence
where calibration process (“classifier training“) is
well-developed. In AI there is a “training set“ of ob-
jects of known attributes as well as their classifica-
tion. Equivalent to training set in Educational Mea-
surement is pilot testing performed on a set of exami-
nees (“pre-testees“) of known classification (typically
obtained from external sources e.g. existing certifi-
cations). Once we have a set of objects (pre-testees),
their attributes (responses to items) and their classi-
fications we are able to compute parameters of at-
tributes (items).
More precisely: Let’s have a set of categories M,
set of items U , set of examinees Z, set of appropriate
responses R and a vector of appropriate classification
~c. Our task is to obtain an appropriate set P. Once
again we could describe the process as a function B :
(R,~c) → P. Since P is a set of P(u
i
|m
k
) elements
we could simplify the computation of function B to
a computation of each element. In equations 6, 7 and
8 there is a description of evaluation of P(u
i
|m
k
) in
three steps.
R
m
k
= {~z
j
|~z
j
∈ R∧ c
j
= m
k
} (6)
T
m
k
i
= {z
ji
|~z
j
∈ R
m
k
∧ z
ji
= 1} (7)
P(u
i
|m
k
) =
T
m
k
i
R
m
k
(8)
Crucial difference between usage of NBC in Ar-
tificial Intelligence and Educational Measurement is
the size of a training set. In AI we are typically op-
erating with large training sets even larger than the
set of objects we want to classify (see examples in
(Caruana and Niculescu-mizil, 2006)). In contrast in
Educational Measurement we are very limited in the
number of pre-testees. It is an expensiveprocess to re-
cruit persons of known classification especially if we
are developing a brand-new test. Therefore there is
a strong motivation to keep number of pre-testees as
small as possible. Two next sections are dedicated to
the analysis of required number of pre-testees (section
5.2) and to the description of a particular calibration
improvement technique (section 5.3).
5.2 Items or Categories
Two approaches are possible when describing suffi-
cient number of pre-testees: a per-item (used by Rud-
ner in (Rudner, 2010)) or per-group. In this section
we will show which approach is more appropriate.
To answer this question we have constructed two
sets of experiments. Experiments are repeated a few
times and share a common framework. Results of ex-
periments are again presented as box-graphs.
5.2.1 Framework
Let’s have a given number of categories m, number of
items u, number of pre-testees z
p
, number of exami-
nees z = 200 defining sets M, U, Z
p
, Z and number of
selected items u
s
≤ u.
Step 1. Let’s again have a set of parame-
ters of items P
U
=
S
u
i
∈U
GI(), vector of cat-
egories of pre-testees z
p
j
∈ Z
p
belong to ~c
Z
p
such as c
Z
p
j
= RAN ({1, 2, . . . , m}, ~p) where
~p =
1
m
,
1
m
, . . . ,
1
m
(again equal distribution of ~p),
a set R
p
of responses of pre-testees such as z
p
ji
=
RAN
{0, 1} ,
n
1− P
U
u
i
|c
Z
p
j
, P
U
u
i
|c
Z
p
j
o
,
U
s
⊆ U of u
s
i
randomly (equally distributed)
selected items u
i
∈ U, and a set of responses
of examinees to items of U
s
R
s
such as z
s
ji
=
RAN
{0, 1} ,
n
1− P
U
u
s
i
|c
Z
p
j
, P
U
u
s
i
|c
Z
p
j
o
.
Step 2. Let P = B
R
p
,~c
Z
p
and than let ~c =
F (~p, P, R
s
).
Step 3. Let again classification error rate e =
E
~c,~c
Z
. And let difference of calibration to real pa-
rameters d = D
P, P
U
where function D is defined
by equation 9.
ONPRACTICALISSUESOFMEASUREMENTDECISIONTHEORY-AnExperimentalStudy
97
10 20 30 40 50 60 70 80 90 100
0.00 0.05 0.10 0.15 0.20 0.25
items
error rate
10 20 30 40 50 60 70 80 90 100
0.010 0.015 0.020 0.025 0.030 0.035
items
difference
Figure 4: Accuracy of classification(left)/calibration(right)
vs. number of items.
D
P
1
, P
2
=
∑
u
i
∈U, m
k
∈M
P
1
(u
i
|m
k
) − P
2
(u
i
|m
k
)
2
m· u
(9)
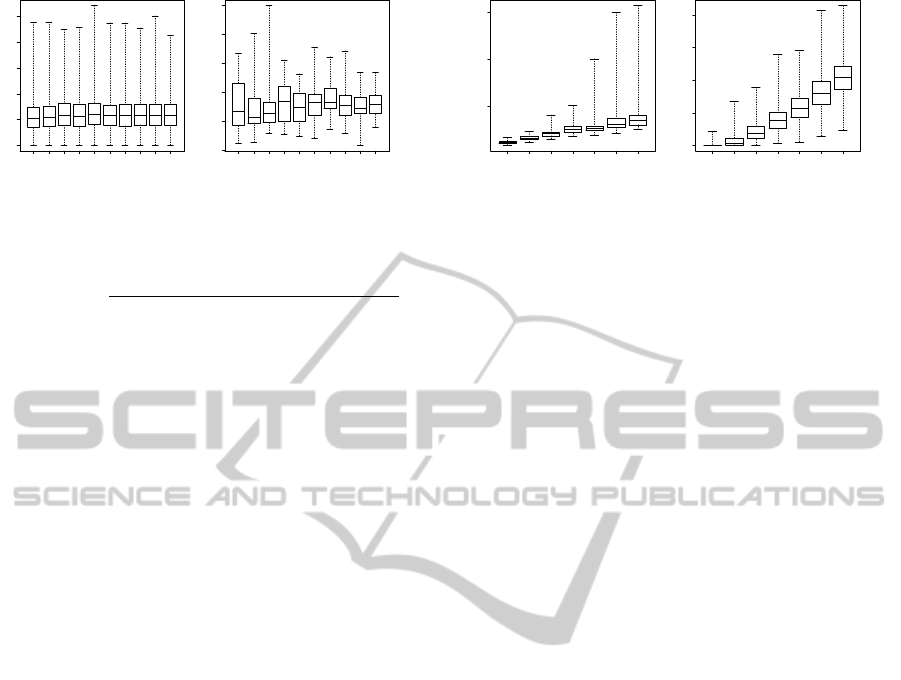
5.2.2 Experiment 1
The first experiment focuses on the per-item ap-
proach. This approach suggests that given a
fixed number of categories and pre-testees the ac-
curacy of calibration and classification should de-
crease while the number of items to calibrate in-
creases. We have constructed set of experiments
with setting m = 2, z
p
= 20, u
s
= 20 and u =
(10, 20, 30, 40, 50, 60, 70, 80, 90, 100). Note that we
are selecting a subset of items from a whole pool to
ensure relevant comparison of classification results
between experiments with different number of cali-
brated items with respect to the dependency of classi-
fication accuracy to the number of items discussed in
section 4. Figure 4-left shows how value of e changes
with respect to number of calibrated items. Figure 4-
right shows results of d instead of e. As we can see
both the accuracy of calibration and the accuracy of
classification remain constant.
5.2.3 Experiment 2
The second experiment checks the influence of the
number of categories to the accuracy of calibra-
tion and classification. The setting of the experi-
ment is now u = 50, z
p
= 30, u
s
= 50 and m =
(2, 3, 4, 5, 6, 7, 8). Figures 5-left and 5-right show
the results. Now we can see a very different picture
to one seen in the previous figures. The accuracy of
calibration as well as the accuracy of classification de-
creases with the increasing number of groups.
5.2.4 Conclusion
Our experiments have proven that describing number
of pre-testees on per-group basis is more appropriate.
2 3 4 5 6 7 8
0.05 0.10 0.15
categories
difference
2 3 4 5 6 7 8
0.00 0.05 0.10 0.15 0.20
categories
error rate
Figure 5: Accuracy of calibration(left)/classification(right)
vs. number of categories.
5.3 Unknown Objects
Although we have shown that good calibration could
be obtained from a relatively small number of pre-
testees, the calibration process could be still very ex-
pensive and further improvements of the original cali-
bration process are needed. The method we are going
to explain was developed experimentally by us inde-
pendently from the mentioned references.
NBC is used also in document classification. Clas-
sification of documents is in many ways similar to
testing. In document classification as well as in test-
ing there is a huge amount of objects (documents, ex-
aminees) to be classified but it is difficult to obtain
a training set. Therefore the training set is typically
very small. Nigam et al. (Nigam et al., 2000) took
inspiration from (Dempster et al., 1977) and used un-
classified objects to improve calibration of NBC. We
can use the same approach summarized in the follow-
ing algorithm:
1. Let’s have sets M, U, Z
p
, Z, R
p
and R and vectors
~p and~c
Z
p
(in the notation of previous sections).
2. Let P
0
= B
R
p
,~c
Z
p
.
3. Let P
t+1
= B(R, F (~p, P
t
, R)).
4. Repeat iterative step 3 until terminal condition
P
t+1
= P
t
(i.e. P
t+1
(u
i
|m
k
) = P
t
(u
i
|m
k
) ∀u
i
∈
U, m
k
∈ M) is reached.
5. As a side effect of this calibration classification of
examinees we obtain: ~c = F (~p, P
t
, R).
Improvement of both calibration and classification
accuracy performed by this iterative calibration algo-
rithm could be seen in Figures 6 and 7 for m = 5,
u = 50, z
p
= 20 and z = (100, 200, 300, 400, 500).
6 CONCLUSIONS
Measurement decision theory is a powerful test eval-
uation method in cases where we want to classify
examinees into a set of pre-defined categories. In
this paper we have presented results of a couple of
CSEDU2012-4thInternationalConferenceonComputerSupportedEducation
98
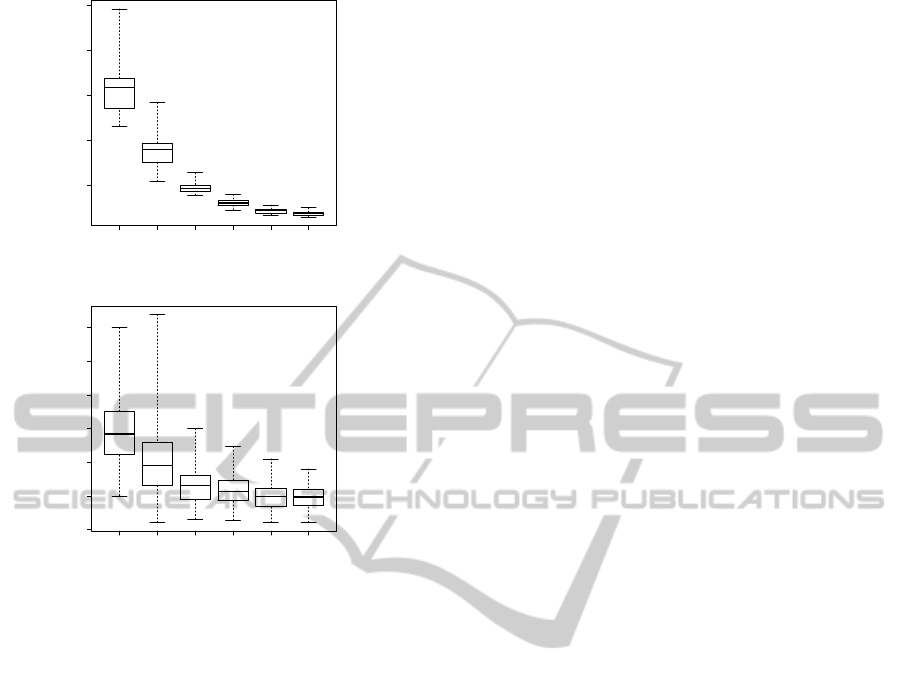
0 100 200 300 400 500
0.005 0.010 0.015 0.020 0.025
Figure 6: Improvement of calibration accuracy.
0 100 200 300 400 500
0.00 0.05 0.10 0.15 0.20 0.25 0.30
Figure 7: Improvement of classification.
experiments showing some interesting characteristics
of MDT. These experiments have followed and ex-
panded on the work (Rudner, 2002; Rudner, 2009;
Rudner, 2010) of Rudner. We were focused on prac-
tical issues of MDT to give a solid base for future
applications of MDT.
We have shown an overview of theoretical limits
of classification via MDT in section 4 and a depen-
dency of classification accuracy to number of items
and number of categories was discussed. As a main
result of this section we have summarized our find-
ings to a direct suggestion of how many items should
be chosen to obtain good classification (error rate less
than 0.1) results for different number of categories.
In the next section we have focused on the most
important obstacle on the path to real-life usage of
MDT - the process of calibration of items. We
have explained in depth the whole process of simple
straightforward calibration of items. Finally we have
introduced an improvement to the calibration process
which significantly reduces the number of required
pre-testees. Experimental results showing the reduc-
tion were presented as well.
Based on the results presented in this paper MDT
becomes a ready-to-use method.
ACKNOWLEDGEMENTS
This paper was written in the colaboration with my
colleagues from Scio (www.scio.cz).
REFERENCES
Caruana, R. and Niculescu-mizil, A. (2006). An empirical
comparison of supervised learning algorithms. In In
Proc. 23 rd Intl. Conf. Machine learning (ICML`06),
pages 161–168.
Cronbach, L. J. and Gleser, G. C. (1957). Psychological
tests and personnel decisions. Urbana: University of
Illinois Press.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977).
Maximum likelihood from incomplete data via the em
algorithm. In Journal of the Royal Statistical Society,
Series B, 39 (1), pages 1–38.
Hambleton, R. and M, M. N. (1973). Toward an integration
of theory and method for criterion-referenced tests. In
Journal of Educational Measurement, 10, pages 159–
170.
Nigam, K., Mccallum, A. K., Thrun, S., and Mitchell, T.
(2000). Text classification from labeled and unlabeled
documents using em. In Machine Learning, 39 (2/3),
pages 103–134.
Rudner, L. M. (2002). An examination of decision-theory
adaptive testing procedures. In Paper presented at
the annual meeting of the American Educational Re-
search Association, April 2002.
Rudner, L. M. (2009). Scoring and classifying examinees
using measurement decision theory. In Practical As-
sessment Research & Evaluation, 14(8).
Rudner, L. M. (2010). Measurement decision the-
ory (a measurement decision theory tutorial). In
http://echo.edres.org:8080/mdt/.
van der Linden, W. J. and Mellenbergh, G. J. (1978). Coeffi-
cients for tests from a decision-theoretic point of view.
In Applied Psychological Measurement, 2, pages 119–
134.
ONPRACTICALISSUESOFMEASUREMENTDECISIONTHEORY-AnExperimentalStudy
99
