
Fence
A Context-free Grammar Parser with Constraints
for Model-driven Language Specification
Luis Quesada, Fernando Berzal and Francisco J. Cortijo
Department of Computer Science and Artificial Intelligence, CITIC, University of Granada, Granada 18071, Spain
Keywords:
Parser, Context-free Grammars, Constraints, Ambiguities.
Abstract:
Traditional language processing tools constrain language designers to specific kinds of grammars. In contrast,
model-based language specification decouples language design from language processing. As a consequence,
model-based language specification tools need general parsers able to parse unrestricted context-free gram-
mars. As languages specified following this approach may be ambiguous, parsers must deal with ambiguities.
Model-based language specification also allows the definition of associativity, precedence, and custom con-
straints. Therefore parsers generated by model-driven language specification tools need to enforce constraints.
In this paper, we propose Fence, an efficient bottom-up chart parser with lexical and syntactic ambiguity
support that allows the specification of constraints and, therefore, enables the use of model-based language
specification in practice.
1 INTRODUCTION
Traditional language specification techniques (Aho
and Ullman, 1972) require the developer to provide
a textual specification of the language grammar.
In contrast, model-based language specification
techniques (Quesada et al., 2011c) allow the speci-
fication of languages by means of data models anno-
tated with constraints.
Model-based language specification has direct
applications in the following fields: programming
tools (Aho et al., 2006), domain-specific languages
(Fowler, 2010; Hudak, 1996; Mernik et al., 2005),
model-driven software development (Schmidt, 2006),
data integration (Tan et al., 2006), text mining (Turmo
et al., 2006; Crescenzi and Mecca, 2004), natural lan-
guage processing (Jurafsky and Martin, 2009), and
the corpus-based induction of models (Klein, 2004).
Due to the nature of the aforementioned applica-
tion fields, the specification of separate language el-
ements may cause lexical and syntactic ambiguities.
Lexical ambiguities occur when an input string si-
multaneously corresponds to several token sequences
(Nawrocki, 1991), which may also overlap. Syntac-
tic ambiguities occur when a token sequence can be
parsed in several ways.
The formal grammars of languages specified using
model-based techniques may contain epsilon produc-
tions (such as E := ε), infinitely recursive production
sets (such as A := c, A := B, and B := A), and associa-
tivity, precedence, and custom constraints. Therefore,
a parser that supports such specification is needed.
Our proposed algorithm, Fence, is a bottom-up
chart parser that accepts a lexical analysis graph as
input, performs an efficient syntactic analysis taking
constraints into account, and produces a parse graph
that represents all the possible parse trees. The pars-
ing process discards any sequence of tokens that does
not provide a valid syntactic sentence conforming to
the language specification, which consists of a pro-
duction set and a set of constraints. Fence implicitly
performs a context-sensitive lexical analysis, as the
parsing process determines which token sequences
end up in the parse graph. Fence supports everypossi-
ble construction in a context-free language with con-
straints, including epsilon productions and infinitely
recursive production sets.
The combined use of the Lamb lexical analyzer
(Quesada et al., 2011a) and Fence allows the gen-
eration of processors for languages with ambiguities
and constraints, and it renders model-based language
specification techniques feasible. Indeed, ModelCC
(Quesada et al., 2011c; Quesada et al., 2011b) is a
model-based language specification tool that relies on
Lamb and Fence to generate language processors.
Section 2 exposes the background to this paper.
5
Quesada L., Berzal F. and J. Cortijo F..
Fence - A Context-free Grammar Parser with Constraints for Model-driven Language Specification.
DOI: 10.5220/0003949800050013
In Proceedings of the 7th International Conference on Software Paradigm Trends (ICSOFT-2012), pages 5-13
ISBN: 978-989-8565-19-8
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

Section 3 introduces Fence, our parser with ambiguity
and constraint support. Section 4 presents our conclu-
sions and future work.
2 BACKGROUND
Language processing tools traditionally divide the
analysis into two separate phases; namely, scanning
(or lexical analysis), which is performed by lexers,
and parsing (or syntax analysis), which is performed
by parsers. However, language processing tools based
on scannerless parsers also exist.
Subsection 2.1 analyzes existing scanning algo-
rithms with ambiguity support. Subsection 2.2 des-
cribes existing parsing algorithms.
2.1 Lexical Analysis Algorithms with
Ambiguity Support
Given a language specification describing the tokens
listed in Figure 1, the string “&5.2& /25.20/” can cor-
respond to the four different lexical analysis alterna-
tives shown in Figure 2, depending on whether the se-
quences of digits separated by points are considered
real numbers or integer numbers separated by points.
The productions shown in Figure 3 illustrate a sce-
nario of lexical ambiguity sensitivity. Sequences of
digits separated by points should be considered either
Real tokens or Integer Point Integer token sequences
depending on the surrounding tokens, which may be
either Ampersand tokens or Slash tokens. The desired
result of analyzing the input string “&5.2& /25.20/” is
shown in Figure 4.
The further application of a parser supporting lexi-
cal ambiguities would produce the only possible valid
sentence, which, in turn, would be based on the only
valid lexical analysis for our example. The intended
results are shown in Figure 6.
The Lamb lexical analyzer (Quesada et al., 2011a)
captures all possible sequences of tokens within a
given input string and it generates a lexical analysis
graph that describes them all, as shown in Figure 5. In
these graphs, each token is linked to its preceding and
following tokens. There may also be several starting
tokens. Each path in these graphs describes a possible
(-|\+)?[0-9]+ Integer
(-|\+)?[0-9]+\.[0-9]+ Real
\. Point
\/ Slash
\& Ampersand
Figure 1: Specification of token types as regular expressions
for a lexically-ambiguous language.
•
Ampersand Integer Point Integer Ampersand
Slash Integer Point Integer Slash
•
Ampersand Integer Point Integer Ampersand
Slash Real Slash
•
Ampersand Real Ampersand Slash Integer Point
Integer Slash
•
Ampersand Real Ampersand Slash Real Slash
Figure 2: Different possible token sequences in the input
string “&5.2& /25.20/” due to the lexically-ambiguous lan-
guage specification shown in Figure 1.
E ::= A B
A ::= Ampersand Real Ampersand
B ::= Slash Integer Point Integer Slash
Figure 3: Context-sensitive productions that resolve the am-
biguities in Figure 2.
sequence of tokens that can be found within the input
string.
To the best of our knowledge, the only way to pro-
cess lexical analysis graphs consists of extracting the
different paths from the graph and parse each of them.
This process is inefficient, as partial parsing trees that
are shared among different token sequences have to
be created several times.
2.2 Syntactic Analysis Algorithms
Traditional efficient parsers for restricted context-
free grammars, such as the LL (Oettinger, 1961),
LR (Knuth, 1965), LALR (DeRemer, 1969; DeRe-
mer and Pennello, 1982), and SLR (DeRemer, 1971)
parsers, do not consider ambiguities in syntactic anal-
ysis, so they cannot be used to parse ambiguous lan-
guages. The efficiency of these parsers is O(n), being
n the token sequence length.
Generalized LR (GLR) parsers (Lang, 1974) parse
in linear to cubic time, depending on how closely
the grammar conforms to the underlying LR strat-
egy. The time required to run the algorithm is propor-
tional to the degree of nondeterminism in the gram-
mar. The Universal parser (Tomita and Carbonell,
1987) is a GLR parser used for natural language pro-
cessing. However, it fails for grammars with epsilon
productions and infinitely recursive production sets.
Existing chart parsers for unrestricted context-free
grammar parsing, as the CYK parser (Younger, 1967;
Kasami and Torii, 1969) and the Earley parser (Ear-
ley, 1983), can consider syntactic ambiguities but not
lexical ambiguities. The efficiency of these general
context-free grammar parsers is O(n
3
), being n the
token sequence length.
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
6
Point
.
Integer
20
Slash
/
Real
5.2
Ampersand
&
Slash
/
Ampersand
&
Integer
25
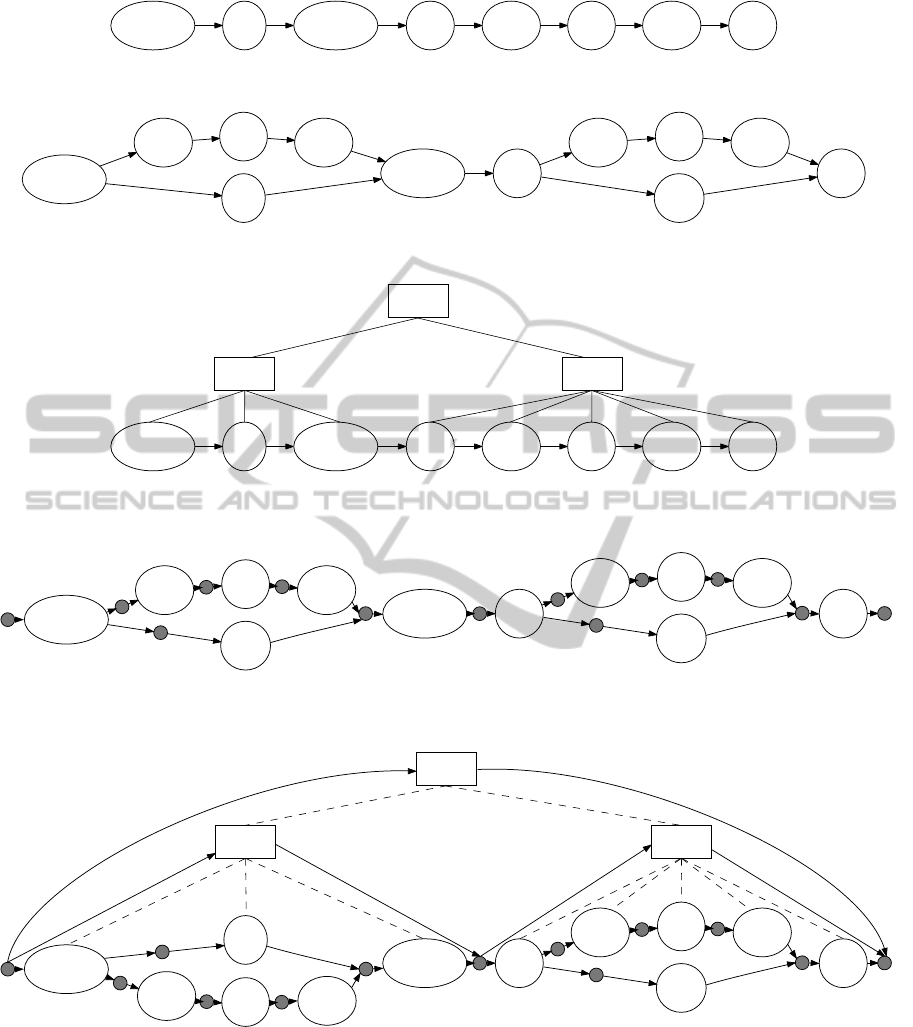
Figure 4: Desired lexical analysis of the lexically ambiguous “&5.2& /25.20/” input string.
Point
.
Integer
20
Slash
/
Real
5.2
Ampersand
&
Slash
/
Ampersand
&
Integer
5
Point
.
Real
25.20
Integer
25
Integer
2
Figure 5: Lexical analysis graph, as produced by the Lamb lexer.
Point
.
Integer
20
Slash
/
Real
5.2
Ampersand
&
Slash
/
Ampersand
&
Integer
25
E
B
A
Figure 6: Syntactic analysis graph, as produced by applying a parser that supports lexical ambiguities to the lexical analysis
graph shown in Figure 5. Squares represent nonterminal symbols found during the parsing process.
Point
.
Integer
20
Slash
/
Ampersand
&
Slash
/
Ampersand
&
Real
25.20
Integer
25
Point
.
Integer
5
Integer
2
Real
5.2
Figure 7: Extended lexical analysis graph corresponding to the lexical analysis graph shown in Figure 5. Gray nodes represent
cores.
Point
.
Integer
20
Slash
/
Real
5.2
Ampersand
&
Slash
/
Ampersand
&
Integer
5
Point
.
Real
25.20
Integer
25
Integer
2
E
B
A
Figure 8: Parse graph corresponding to the extended lexical analysis graph shown in Figure 7. Squares represent nonterminal
symbols found during the parsing process. Dotted lines represent the explicit parse graph node.
3 FENCE
In this section, we introduce Fence, an efficient
bottom-up chart parser that produces a parse graph
that contains as many root nodes as different parse
trees exist for a given ambiguous input string.
In contrast to the parsing techniques mentioned in
the previous section, Fence is able to process lexical
analysis graphs and, therefore, it efficiently considers
Fence-AContext-freeGrammarParserwithConstraintsforModel-drivenLanguageSpecification
7

lexical ambiguities.
Fence also considers syntactic ambiguities, allows
the specification of constraints, and supports every
possible context-free language construction, particu-
larly epsilon productions and infinitely recursive pro-
duction sets.
The Fence parsing algorithm consists of three con-
secutive phases: the extended lexical analysis graph
construction phase, the chart parsing phase, and the
constraint enforcement phase.
Subsection 3.1 introduces the terminology used in
this section. Subsection 3.2 describes the extended
lexical analysis graph construction phase. Subsection
3.3 describes the chart parsing phase. Subsection 3.4
describes the constraint enforcement phase.
3.1 Terminology
A context-free grammar is formally defined (Chom-
sky, 1956) as the tuple (N, Σ, P, S), where:
• N is the finite set of nonterminal symbols of the
language, sometimes called syntactic variables,
none of which appear in the language strings.
• Σ is the finite set of terminal symbols of the lan-
guage, also called tokens, which constitute the
language alphabet (i.e. they appear in the lan-
guage strings). Therefore, Σ is disjoint from N.
• P is a finite set of productions, each one of the
form N → (Σ ∪ N)
∗
, where ∗ is the Kleene star
operator, ∪ denotes set union, the part before the
arrowis called the left-hand side (LHS) of the pro-
duction, and the part after the arrow is called the
right-hand side (RHS) of the production.
• S is a distinguished nonterminal symbol, S ∈ N:
the grammar start symbol.
A dotted production is of the form N → (Σ ∪
N)
∗
.(Σ ∪ N)
∗
, where the dot indicates that the RHS
symbols before the dot have already been matched
with a substring of the input string.
A handle is a tuple (dottedproduction,
[start, end]), where start and end identify the
substring of the input string that matched the dotted
production RHS symbols before the dot. Each handle
can be used during the parsing process to match a
rule RHS symbol with a node representing either
a token or a nonterminal symbol (namely, SHIFT
actions in LR-like parsers) or perform a reduction
(namely, REDUCE actions in LR-like parsers).
A core is a set of handles.
3.2 Extended Lexical Analysis Graph
Construction Phase
In order to efficiently perform the parsing process,
Fence converts the input lexical analysis graph (LA
graph) into an extended lexical analysis graph (ELA
graph) that stores information about partially ap-
plied productions (namely, handles) in data structures
(namely, cores).
In an ELA graph, tokens are not linked to their
preceding and following tokens, but to their preceding
and following cores. Cores are, in turn, linked to their
preceding and following token sets. For example, the
ELA graph corresponding to the LA graph in Figure
5 is shown in Figure 7.
The conversion from the LA graph to the ELA
graph is performed by completing the LA graph with
cores. A starting core is linked to the tokens with an
empty preceding token set. A last core is linked from
the tokens with an empty following token set. Finally,
for each one of the other tokens in the LA graph, a
preceding core is linked to it. Links between tokens
in the LA graph are converted into links from tokens
to the cores preceding each token of their following
token set in the ELA graph.
3.3 Chart Parsing Phase
The Fence chart parsing phase processes the ELA
graph and generates an implicit parse graph (I-
graph). Nodes in the I-graph are described as
(start, end, symbol) tuples, where start and end iden-
tify the substring of the input string, and symbol iden-
tifies the production LHS. It should be noted that am-
biguities, both lexical and syntactic, are implicit in the
I-graph nodes, as they contain no information about
their contents. The I-graph contains a set of start-
ing nodes, each of which may represent several parse
tree roots. The parsing itself is performed by pro-
gressively applying productions and storing handles
in cores.
The grammar productions with an empty RHS
(i.e. epsilon productions) are removed from the gram-
mar and their LHS symbol is stored in the epsilon-
Symbols set. This set allows these parse symbols be-
ing skipped when found in a production, as if a reduc-
tion using the epsilon production were applied.
The agenda is a stack of (handle, node) in which
the node can match the symbol after the dot in the
dotted rule of the handle. It is initially empty.
The alreadyGenerated handle set contains all the
agenda entries ever generated and inhibits the gener-
ation of duplicate entries.
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
8

The parser is initialized by generating a handle for
each production and adding them to every core, as
shown in Figure 10.
The addHandle procedure in Figure 9 is respon-
sible for adding a handle to a core. It also adds the
corresponding agenda entries for that handle with the
nodes that follow the core and match the symbol af-
ter the dot in the dotted production of the handle. It
should be noted that the addHandle procedure consid-
ers epsilon productions: if a production RHS symbol
is in the epsilonSymbols set, both the possibilities of
it being reduced or not by that production are consid-
ered; that is, a new handle that skips that element is
added to the same core. It should also be noted that
element are skipped iteratively, as many consecutive
RHS symbols of a production could be in the epsilon-
Symbols set.
The parsing process consists in iteratively extract-
ing entries consisting of handles and nodes from the
agenda and matching the next symbol of the RHS
of the handle production with the node. The han-
dles whose productions are successfully matched are
added to the cores following the node and the agenda
is updated with the entries that contain any of the
newly generated handles. In case all the symbols of
a production RHS match a sequence of nodes, a new
node is generated by reducing them. The new node
start index is obtained from the handle, its end posi-
tion is obtained from the last node matched, and its
symbol is the LHS symbol of the production. When
a newly generated node only has the starting core in
its preceding core set and the final core in its follow-
ing core set, and its symbol corresponds to the initial
symbol of the grammar, it is added to the parse graph
starting node set, which means that that node repre-
sents a valid parse. The pseudocode for this process
is shown in Figure 11.
The result of the chart parsing phase is an I-graph,
which the constraint enforcement phase accepts as in-
put.
The Fence chart parsing phase order of efficiency
is theoretically equivalent to existing Earley chart
parsers. That is, O(n
3
) in the general case, O(n
2
)
for unambiguous grammars, and O(n) for almost all
LR(k) grammars, being n the length of the input
string.
3.4 Constraint Enforcement Phase
The Fence constraint enforcement phase processes
the I-graph and generates an explicit parse graph (E-
graph, or just parse graph) by enforcing the con-
straints defined for the language. Nodes in the
E-graph that represent tokens are still defined as
(start, end, symbol) tuples. Nodes in the E-graph that
represent nonterminal symbols reference the list of
nodes that matched the production used to generate
those nodes. It should be noted that ambiguities, both
lexical and syntactic, are explicit in the E-graph, as
it represents several parse trees corresponding to all
the possible interpretations of the input string. The E-
graph contains a set of starting nodes, each of which
represents a parse tree root. Constraint enforcement is
performed by converting each implicit node into ev-
ery possible explicit node sequence that can be de-
rived from the implicit node and satisfies the speci-
fied constraints; that is, by expanding the each im-
plicit node.
Only the nodes that conform valid parse trees
are needed in the parse graph. In order to generate
only these nodes, each one of the implicit nodes in
the starting node set of the I-graph is recursively ex-
panded using memoization. Each possible resulting
explicit node is the root of a parse tree in the E-graph.
3.4.1 Algorithm Description
The expansion of an implicit node is performed by
finding every possible reduction of a sequence of ex-
plicit nodes that generates that node. Each one of
these reductions produces an explicit node. Whenever
an implicit node is found and needed in order to make
the reductions progress, it is expanded recursively. It
should be noted that this procedure is different from
parsing itself in that the actual bounds of the reduc-
tions for every node are known.
The expand procedure in Figure 12 expands an
implicit node by applying every possible production
that could generate it and produces a set of explicit
nodes. The use of the history set inhibits entering an
infinite loop when processing infinitely recursive pro-
duction sets, as it avoids the expansion of a node as
an indirect requirement of expanding the same node.
The apply procedure in Figure 13 applies a pro-
duction by matching the RHS symbol given by the
matched + 1 index of it with the n node, expanding
the nodes that follows it, and recursively applying the
next RHS symbols of the production.
The checkConstraints procedure is the responsible
for the enforcement of the constraints specified by the
developer.
3.4.2 Supported Constraints
Fence supports associativity constraints, selection
precedence constraints, composition precedence con-
straints, and custom-designed constraints.
The fact that the constraint check is per-
formed during the graph expansion improves the
Fence-AContext-freeGrammarParserwithConstraintsforModel-drivenLanguageSpecification
9

procedure addHandle(Production p, int matched, ImplicitNode first,
ImplicitNode n, Stack<[Handle,ImplicitNode]> agenda):
offset = 0
do:
next = matched+offset
nextSymbol = p.right[next].symbol
h = new Handle(p,next,first,first.startIndex)
if !n.core.contains(h):
n.core.add(h)
if n.symbol == nextSymbol:
if !alreadyGenerated.contains([h,n]):
agenda.push([h,n])
alreadyGenerated.add(]h,n])
offset++
while epsilonSymbols.contains(nextSymbol) && next<r.right.size
Figure 9: Pseudocode of the ancillary addHandle procedure.
agenda = {}
for each Production p in productionSet:
for each ImplicitNode n in nodeSet:
addHandle(p,0,n,n,agenda)
Figure 10: Pseudocode of the chart parser initialization.
parser performance, as the sooner constraints are
applied, the more interpretations are discarded.
For example, in the case of a binary expression
with left-to-right associative operators, the string
“2+5+3+5+6+2+1+5+6+3” can be expanded in 10!
possible ways when not considering the associativity
constraint, and in just 1 possible way when consider-
ing it.
• Associativity constraints allow the specification
of the associative property for binary operators.
The application of a production is inhibited when
any of the nodes that matches its RHS symbols
has an associativity constraint and is followed (for
left-to-right associativity constraints), preceded
(for right-to-left associativity constraints), or ei-
ther followed or preceded (for non-associative as-
sociativity constraints) by a node that was derived
using the same production.
• Selection precedence constraints allow the reso-
lution of syntactic ambiguities caused by different
explicit nodes (i.e. interpretations) resulting from
a single implicit node. For example, a Statement
can be either an OutputStatement or a Function-
Call. Both OutputStatement and FunctionCall
can match the input string “output(var);”, there-
fore OutputStatement can be set to precede Func-
tionCall, which will inhibit that string from being
considered a function call. The application of a
production is inhibited when it is preceded by a
different production and both of them match the
same node sequence.
• Composition precedence constraints allow the
resolution of syntactic ambiguities when a node
derived using a production cannot be derived us-
ing another production. For example, one of the
productions ConditionalStatement ::= “if” Ex-
pression Sentence and ConditionalStatement ::=
“if” Expression Sentence “else” Sentence can be
set to precede the other one in order to resolve the
ambiguity in “if expr1 if expr2 sent1 else sent2”,
in which “else sent2” could be assigned to either
the inside or outside conditional sentence. The ap-
plication of a production is inhibited when it pre-
cedes any of the productions used to derive the
nodes that matched its RHS symbols.
• Custom-designed constraints allow the specifi-
cation of any other constraints (e.g. semantic con-
straints). In order to enforce custom-designed
constraints, an evaluator can be assigned to any
production. Whenever a node is generated, the
evaluator of the production used to derive it gets
executed and determines whether the node satis-
fies the constraint or not. In the later case, its gen-
eration is inhibited. Custom-designed constraints
provide a very extensible framework which allows
developers to design complex syntactic or se-
mantic constraints (e.g. probabilistic constraints,
corpus-based constraints) that effectively limit the
possible interpretations of an input string and, as a
side effect, improve the performance of the parser,
as pruned partial interpretations are discarded as
soon as they do not fulfill the constraints.
The result of the constraint enforcement step is an
E-graph or parse graph, such as the one shown in Fig-
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
10

while !agenda.empty:
[h,n] = agenda.pop()
if h.dotposition == h.production.right.size-1:
// Production matched all its elements. i.e. Reduction
nn = new ImplicitNode(h.startIndex,n.endIndex,p.left.symbol)
h.first.core.following.add(nn)
nn.preceding.add(h.first.core)
for each Core c in n.following:
c.preceding.add(nn)
nn.following.add(c)
for each Handle hn in h.first.core.waitingFor(nn.symbol):
hadd = new Handle(hn.production,hn.next,hn.first,hn.startIndex)
agenda.push([hadd,n])
else:
// i.e. Shift
for each Core c in n.following:
for each ImplicitNode nnext in c.following:
addHandle(h.production,h.next+1,h.first,h.startIndex,agenda)
Figure 11: Pseudocode of the Fence parsing phase.
procedure expand(ImplicitNode n, Set<ImplicitNode> history,
Map<ImplicitNode,Set<Node>> alreadyExpanded)
returns Set<Symbol>:
if alreadyExpanded.contains(n): // memoization
return alreadyExpanded.get(n)
else:
// the history set avoids infinite loop in recursive production sets
if !history.contains(n):
history.add(n);
// try to apply every production
for each Production p with LHS symbol == n.symbol:
for every ImplicitNode pn with startIndex == n.startIndex:
if pn != n && pn.endIndex<=n.endIndex:
if p.mayMatch(pn.symbol):
// apply production p to each expanded symbol of pn
pn.expandeds = expand(pn,history,alreadyExpanded)
for each Node nn in pn.expandeds:
out += apply(p,nn,0,{},alreadyExpanded,history)
alreadyExpanded.put(n,out)
return out
Figure 12: Pseudocode of the expand procedure that obtains every possible derivation of a given node in the parse graph.
ure 8.
The Fence constraint enforcement phase improves
the performance of traditional techniques phases in
practice, as all constraints are applied at the earliest
possible time, thus discarding possibilities that would
otherwise be processed later.
4 CONCLUSIONS AND FUTURE
WORK
We havepresented Fence, an efficient bottom-up chart
parsing algorithm with lexical and syntactic ambigu-
ity support. Its constraint-based ambiguity resolution
mechanism enables the use of model-based language
specification in practice. In fact, the ModelCC model-
based language specification tool (Quesada et al.,
2011c) generates Fence parsers.
Fence accepts a lexical analysis graph as input,
performs syntactic analysis conforming to a formal
context-free grammar specification and a set of con-
straints, and produces as output a compact representa-
tion of the set of parse trees accepted by the language.
Fence applies constraints while expanding the
parse graph. Thus, it improves the performance of
traditional techniques in practice, as the sooner con-
straints are applied, the less processing time and
memory the parser will require.
In the future, we plan to extend Fence to support
probabilistic grammars and we also plan to apply it to
natural language processing.
Fence-AContext-freeGrammarParserwithConstraintsforModel-drivenLanguageSpecification
11

procedure apply(Production p, Node n, int matched, List<Node> content,
Map<ImplicitNode,Set<Node>> alreadyExpanded,
Set<ImplicitNode> history) returns Set<Node>:
if matched == p.right.size:
n = new Node(p.symbol,p,content)
if checkConstraints(n):
return {n}
else:
offset = 0
next = matched+offset
do:
if p.right[next].symbol == n.symbol:
for each ImplicitNode pn in n.followingNodes():
if pn is the next symbol to match in the production:
// keep applying production to each expanded symbol of pn
expandeds = expand(pn,history,alreadyExpanded)
for each Node nn in expandeds:
out += apply(p,nn,next+1,content+n,alreadyExpanded,history)
offset++
next = matched+offset
while epsilonSymbols.contains(nextSymbol) && next<r.right.size &&
p.right[next].symbol == n.symbol
return out
Figure 13: Pseudocode of the ancillary apply procedure that applies a production.
ACKNOWLEDGEMENTS
Work partially supported by research project
TIN2009-08296.
REFERENCES
Aho, A. V., Lam, M. S., Sethi, R., and Ullman, J. D. (2006).
Compilers: Principles, Techniques, and Tools. Addi-
son Wesley, 2nd edition.
Aho, A. V. and Ullman, J. D. (1972). The Theory of Parsing,
Translation, and Compiling, Volume I: Parsing & Vol-
ume II: Compiling. Prentice Hall, Englewood Cliffs,
N.J.
Chomsky, N. (1956.). Three models for the description of
language. IRE Transactions on Information Theory,
2:113–123.
Crescenzi, V. and Mecca, G. (2004). Automatic information
extraction from large websites. Journal of the ACM,
51:731–779.
DeRemer, F. L. (1969). Practical translators for LR(k) lan-
guages. Technical report, Cambridge, MA, USA.
DeRemer, F. L. (1971). Simple LR(k) grammars. Commu-
nications of the ACM, 14(7):453–460.
DeRemer, F. L. and Pennello, T. (1982). Efficient computa-
tion of LALR(1) look-ahead sets. ACM Transactions
on Programming Languages and Systems, 4(4):615–
649.
Earley, J. (1983). An efficient context-free parsing algo-
rithm. Communications of the ACM, 26:57–61.
Fowler, M. (2010). Domain-Specific Languages. Addison-
Wesley.
Hudak, P. (1996). Building domain-specific embedded lan-
guages. ACM Computing Surveys, vol. 28, no. 4es, art.
196.
Jurafsky, D. and Martin, J. H. (2009). Speech and Language
Processing: An Introduction to Natural Language
Processing, Computational Linguistics and Speech
Recognition. Prentice Hall, 2nd edition.
Kasami, T. and Torii, K. (1969). A syntax-analysis proce-
dure for unambiguous context-free grammars. Journal
of the ACM, 16:423–431.
Klein, D. (2004). Christopher d. manning. In Proceedings
of the 42nd Annual Meeting on Association for Com-
putational Linguistics (ACL ’04), pages 478–485.
Knuth, D. E. (1965). On the translation of languages from
left to right. Information and Control, 8:607–639.
Lang, B. (1974). Deterministic techniques for efficient non-
deterministic parsers. In Loeckx, J., editor, Automata,
Languages and Programming, volume 14 of Lecture
Notes in Computer Science, pages 255–269. Springer
Berlin / Heidelberg.
Mernik, M., Heering, J., and Sloane, A. M. (2005). When
and how to develop domain-specific languages. ACM
Computing Surveys, 37:316–344.
Nawrocki, J. R. (1991). Conflict detection and resolution in
a lexical analyzer generator. Information Processing
Letters, 38:323–328.
Oettinger, A. (1961). Automatic syntactic analysis and the
pushdown store. In Proc. of the Symposia in Applied
Math, volume 12, pages 104–129.
Quesada, L., Berzal, F., and Cortijo, F. J. (2011a). Lamb —
a lexical analyzer with ambiguity support. In Proceed-
ings of the 6th International Conference on Software
and Data Technologies, volume 1, pages 297–300.
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
12

Quesada, L., Berzal, F., and Cortijo, F. J. (2011b). A tool for
model-based language specification. ArXiv e-prints.
http://arxiv.org/abs/1111.3970.
Quesada, L., Berzal, F., and Cubero, J.-C. (2011c). A lan-
guage specification tool for model-based parsing. In
Proceedings of the 12th International Conference on
Intelligent Data Engineering and Automated Learn-
ing. Lecture Notes in Computer Science, volume 6936,
pages 50–57.
Schmidt, D. C. (2006). Model-driven engineering. IEEE
Computer, 39:25–31.
Tan, P.-N., Steinbach, M., and Kumar, V. (2006). Introduc-
tion to Data Mining. Addison Wesley.
Tomita, M. and Carbonell, J. G. (1987). The univer-
sal parser architecture for knowledge-based machine
translation. In Proceedings of the 10th International
Joint Conference on Artificial Intelligence, volume 2,
pages 718–721.
Turmo, J., Ageno, A., and Cata`a, N. (2006). Adaptive in-
formation extraction. ACM Computing Surveys, vol.
38, no. 2, art. 4.
Younger, D. H. (1967). Recognition and parsing of context-
free languages in time n
3
. Information and Control,
10:189–208.
Fence-AContext-freeGrammarParserwithConstraintsforModel-drivenLanguageSpecification
13
