
A Simulation-based Scheduling Strategy for Scientific Workflows
Sergio Hern´andez, Javier Fabra, Pedro
´
Alvarez and Joaqu´ın Ezpeleta
Arag´on Institute of Engineering Research (I3A), Department of Computer Science and Systems Engineering,
University of Zaragoza, Zaragoza, Spain
Keywords:
Scientific Workflows, Grid Modelling and Simulation, Workloads, Performance Analysis.
Abstract:
Grid computing infrastructures have recently come up as computing environments able to manage hetero-
geneous and geographically distributed resources, being very suitable for the deployment and execution of
scientific workflows. An emerging topic in this discipline is the improvement of the scheduling process and
the overall execution requirements by means of simulation environments. In this work, a simulation compo-
nent based on realistic workload usage is presented and integrated into a framework for the flexible deployment
of scientific workflows in Grid environments. This framework allows researchers to simultaneously work with
different and heterogeneous Grid middlewares in a transparent way and also provides a high level of abstrac-
tion when developing their workflows. The approach presented here allows to model and simulate different
computing infrastructures, helping in the scheduling process and improving the deployment and execution
requirements in terms of performance, resource usage, cost, etc. As a use case, the Inspiral analysis workflow
is executed on two different computing infrastructures, reducing the overall execution cost.
1 INTRODUCTION
Grid computing emerged as a paradigm for the devel-
opment of computing infrastructures able to share het-
erogeneous and geographically distributed resources
(Foster and Kesselman, 2003). Due to their compu-
tational and networking capabilities, this type of in-
frastructure has turned into execution environments
suitable for scientific workflows, which require inten-
sive computations as well as complex data manage-
ment. Nevertheless, the comparison of existing Grid
workflow systems has shown relevant differences in
the building and execution of workflows that causes
experiments programmed by scientists and engineers
to be strongly coupled to the underlying system re-
sponsible for their execution (Rahman et al., 2011; Yu
and Buyya, 2005). Therefore, two of the most inter-
esting open challenges in the field of scientific com-
puting are the ability to program scientific workflows
independently of the execution environment and the
flexible integration of heterogeneous execution envi-
ronments to create more powerful computing infras-
tructures for their execution.
This new generation of computing infrastructures
requires new strategies of resource brokering and
scheduling to facilitate the utilization of multiple-
domain resources and the allocation and binding of
workflow activities to them. An emerging topic in
this discipline is the use of simulation environments
to help in the scheduling process, improving the over-
all execution requirements in terms of resource us-
age, time and costs. Some approaches such as GMBS
(Kert´esz and Kacsuk, 2010) or SCI-BUS
1
, for in-
stance, propose the use of simulation tools to evaluate
the best meta-scheduling strategy. Different schedul-
ing policies can be evaluated to decide the most suit-
able allocation of workflow activities to resources. On
the other hand, another research focus on the devel-
opment of a novel scheduling algorithm and its ex-
ecution over a simulated environment. The results
are then compared with other similar algorithms in
order to classify the algorithm with respect to some
predefined criteria. Strategies are normally compared
in terms of makespan (Hamscher et al., 2000; Abra-
ham et al., 2006; Yu and Shi, 2007), simulation times
(Ludwig and Moallem, 2011) or queue times (Yu and
Shi, 2007; Ludwig and Moallem, 2011).
Regardless of the problem to be solved, simula-
tion environments may consider execution environ-
ment models and workloads with the purpose of im-
proving scheduling decisions. The first provide a
complete specification of architectures and configura-
tions of the execution environment. Flexible mecha-
nisms for the specification of these models should be
1
http://www.sci-bus.eu/
61
Hernández S., Fabra J., Álvarez P. and Ezpeleta J..
A Simulation-based Scheduling Strategy for Scientific Workflows.
DOI: 10.5220/0004061200610070
In Proceedings of the 2nd International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH-2012),
pages 61-70
ISBN: 978-989-8565-20-4
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

provided, specially to model evolving and heteroge-
neous computing infrastructures. Meanwhile, work-
loads are logs of job sets based on historical data or
statistical models representing jobs to be executed in
the environment. The relation between workloads and
scheduling policies turns around the necessity of us-
ing a workload fitting the characteristics of jobs ex-
ecuted in the infrastructure in order to evaluate the
suitability of a concrete scheduling algorithm in real
terms. In (Feitelson, 2002), the benefits of using
workloads as well as how to use them to evaluate a
system are discussed. However, their use is still rather
limited, due mainly to the complexity of its creation,
being the process automation a difficult task. There-
fore, workloads are mainly used just for the analysis
of Grid systems (Iosup and Epema, 2011; Li et al.,
2004). Understanding these real workloads is a must
for the tuning of existing Grids and also for the design
of future Grids and Cloud infrastructures.
In (Fabra et al., 2012), a framework for the deploy-
ment and execution of scientific workflows whose
main features are described in Section 2 was pre-
sented. This framework facilitates the flexible in-
tegration of heterogeneous Grid computing environ-
ments, addressing the challenge of creating more
powerful infrastructures. Besides, its architectural de-
sign guarantees that workflow programmers do not
need to be aware of this heterogeneity. In this paper,
we integrate new components into our framework for
the simulation of scientific workflows using realistic
workloads, allowing the improvement and flexibility
of job allocation by means of a meta-scheduler. Un-
like other approaches which are focused on assisting
the researcher, in our proposal simulation results are
internally used to make scheduling decisions transpar-
ently to researchers and their workflows. Obviously,
the complexity of this simulation-based scheduling is
increased by the evolving nature of the underlying
computing infrastructure.
The information obtained from the simulator com-
ponent can also be used by the meta-scheduler in or-
der to carry out some optimization process depend-
ing on the parameters to be optimized. For instance,
it is possible to provide a better-execution-time algo-
rithm which schedules the execution of jobs on the
most suitable computing infrastructure depending on
the workload provided at the execution time. It is also
possible to easily minimize resource costs while keep-
ing a defined relation between execution time and in-
volved costs, for instance.
The remainder of this paper is organized as fol-
lows. The main features of the developed framework
in which the presented simulation approach is inte-
grated are described in Section 2. The design and im-
plementation of the simulator is sketched by means of
the application to a real cluster which uses Condor in
Section 3. The flexibility and reuse capabilities of the
component are then depicted in Section 4 by means of
the integration of another real Grid managed by gLite.
Then, the simulation approach integration is applied
to the development of a real case study, the LIGO In-
spiral analysis workflow in Section 5. Finally, Section
6 concludes the paper and addresses future research
directions.
2 EVOLVING TOWARDS THE
ADAPTABLE DEPLOYMENT
OF SCIENTIFIC WORKFLOWS
The proposed Grid-based framework for program-
ming and executing scientific workflows is able to
tackle some of the open challenges in the field of Grid
computing. From the programmer’s point of view,
workflows can be programmed independently of the
execution environment where the related tasks will be
executed. Different standard languages, widely ac-
cepted by the scientific community (e.g. Taverna),
can be used for programming this type of abstract
workflows. On the other hand, the proposed frame-
work is open and flexible from the computing re-
source integration’s point of view. First, and in ac-
cordance with this feature, it is able to simultaneously
work with different Grid middlewares or middlewares
implemented using other alternatives (e.g. Web ser-
vices). And, secondly, heterogeneous execution en-
vironments can be added, modified or even removed
without previous announcement and in a flexible and
transparent way. Therefore, the combination of these
features turns our solution into a novel and suitable
proposal in the field of scientific workflows (Yu and
Buyya, 2005).
Figure 1 shows the high-level architecture of the
proposed framework. A more detailed description is
outside the scope of this paper. Let us concentrate on
the process of executing workflow tasks and the ar-
chitectural components involved in it.
Once a workflow has been deployed, the work-
flow execution environment is responsible for control-
ling its execution and submitting tasks to the resource
broker by means of its interface as they must be exe-
cuted. Submitted tasks are then stored into the mes-
sage repository as messages that encapsulate the in-
formation needed for the execution of a task, includ-
ing the application to be executed, the references to
input and output data, a description of the resources
required for its execution (operating system, CPU ar-
SIMULTECH2012-2ndInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
62
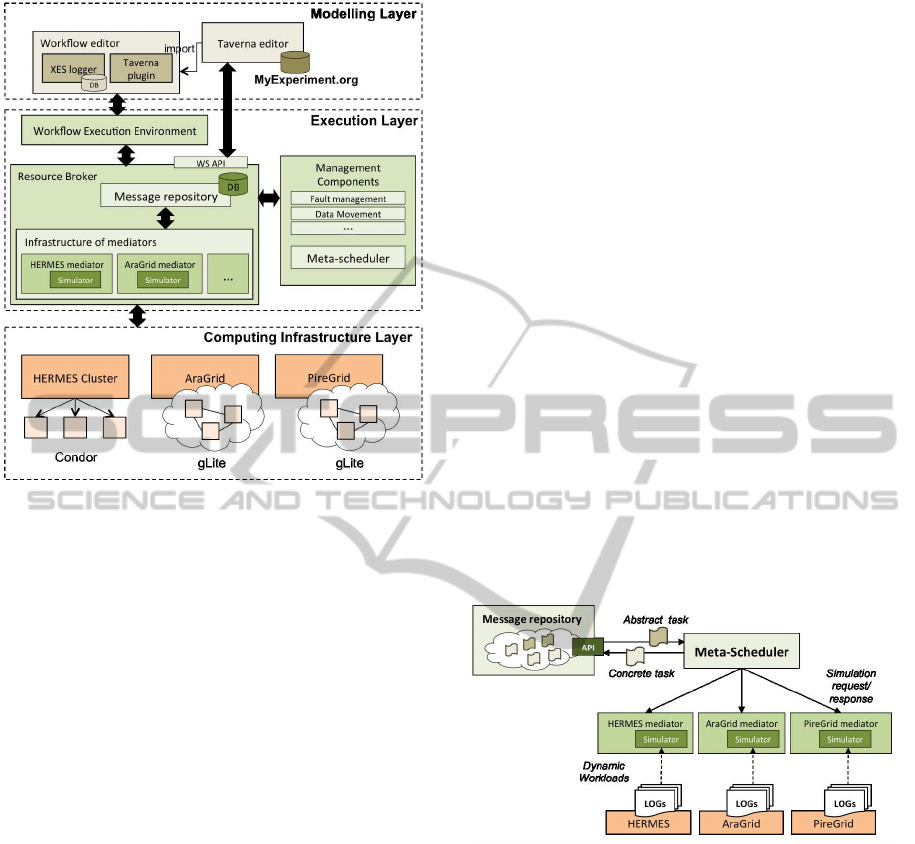
Figure 1: Architecture of the execution environment.
chitecture and features, memory, network bandwidth,
etc.) and QoS parameters. These messages are de-
scribed using the JSDL standard. Optionally, the tar-
get computing environment responsible for the task
execution can be also included into the message. This
type of tasks is called concrete tasks. Nevertheless,
workflowswill be usually programmed independently
of the execution environmentwhere their tasks will be
executed (abstract tasks). This decision tries to take
full advantage of the integration capabilities of rid-
based framework.
An infrastructure of mediators uncouples the re-
source broker from the specific and technological de-
tails about the Grid-based computing environments
where tasks will be executed. Each computing en-
vironment is represented by a mediator. Internally,
a mediator handles a complete information about the
Grid infrastructure it represents. Subsequently, this
knowledge will be used by the mediator to interact
with the message repository and to find at run-time
abstract tasks that could be executed by its middle-
ware. Therefore, mediators are responsible for mak-
ing dispatching decisions related to the execution of
tasks. Obviously, in this dispatching model more
than one mediator could compete for the execution
of a specific task (the criterion would be that their
corresponding middlewares were able to execute it).
This proposal is an alternative to traditional solutions
based on the use of a centralized task scheduler re-
sponsible for deciding where tasks will be executed.
Finally, each mediator dispatches its tasks to the
middleware managing the infrastructure it represents
for their execution and stores the results of the exe-
cuted tasks into the message repository, as well as the
resulting execution log, which can be used for moni-
toring or analysis purposes. These results will be sub-
sequently recovered by the workflow execution envi-
ronment for controlling the execution of the deployed
workflow.
2.1 Improving the Scheduling
Capabilities of the Framework
The dispatching strategy of our proposal presents a
set of drawbacks: 1) performance issues related to the
execution of tasks are not considered by mediators
(therefore, a task could be executed by an inappro-
priate computing environment degrading the perfor-
mance of the whole workflow); 2) dispatching deci-
sions are locally adopted by each mediator and, con-
sequently, one of them could monopolize the execu-
tion of pending tasks (this could cause unnecessary
overloads on its corresponding computing environ-
ment); and, finally, 3) the real behaviour of the ex-
isting computing environments and the state of their
resources is also ignored by the mediators.
Figure 2: Architectural components for the simulation-
based scheduling.
In order to solve the previous drawbacks and also
to improve and enhance our infrastructure, a meta-
scheduler based on simulation techniques will be in-
tegrated into the Grid-based framework in this paper.
Figure 2 represents the alternative process of execut-
ing workflow tasks using a meta-scheduler. Initially,
pending (abstract) tasks are stored into the message
repository. The meta-scheduler retrieves this type of
tasks for determining where they will be finally ex-
ecuted. Scheduling decisions are made by simulat-
ing the execution of each task in the existing com-
puting environments and analysing the simulation re-
sults. With these results, the task is made concrete
and then submitted to the message repository, allow-
ing the task to be executed by the selected mediator.
ASimulation-basedSchedulingStrategyforScientificWorkflows
63

The interface of mediators has been extended to
support this process. Now, each mediator exposes
a set of operations able to simulate the execution of
a task. Internally, a simulator has been integrated
into each mediator for providing the required func-
tionality. More specifically, the simulator is able
to: 1) model the corresponding computing environ-
ment managed by the mediator (computing resources,
memory, network bandwidth, user and scheduling in-
ternal policies, etc.); 2) select the most suitable work-
load for representing the real behaviour of the com-
puting environment and the state of its resources (ex-
ecution logs are used for creating these workloads);
and, finally, 3) simulate the execution of tasks mea-
suring parameters such as the execution time, the data
transfer time, the queuing time, the consumed mem-
ory, etc.
In the following, the design and implementation
of the simulator component is depicted. As it will be
shown, this component is flexible enough as to allow
an easy adaptation for different computing infrastruc-
tures with different scheduling policies.
3 SIMULATING WORKFLOW’S
EXECUTION
As stated, the simulator component has been inte-
grated as an internal component in each mediator.
Therefore, each computing infrastructure can han-
dle different and customized simulation capabilities.
Anyway, simulators are accessed through a well de-
fined API, so adding new simulators to the framework
is a guided and easy process. Also, coupling simu-
lation components with mediators allows developers
to introduce new computing infrastructures without
needing to implement them. Obly the corresponding
scheduling policy and the associated simulator must
be considered.
The simulation component receives the Grid
model and the workload as an input, which are stored
as files accessible from the corresponding mediator.
Then, after a processing cycle, it generates as a re-
sult the execution estimation in terms of time and re-
source usage with respect to the input provided. The
simulator also provides some metrics for analysis pur-
poses such as the average system utilization of each
resource, for instance, which can be used to improve
the process.
In the following, the design and implementation
of the simulation component is sketched by means of
the description of two real use cases: the HERMES
cluster and the AraGrid multi-cluster Grid.
3.1 Overview of the HERMES Cluster
HERMES is a cluster hosted by the Arag´on Institute
of Engineering Research (I3A)
2
. In general terms,
HERMES consists of 1308 cores and 2.56 TB of
RAM. More specifically, it consists of 126 heteroge-
neous computing nodes, including 52 nodes with two
2.33 GHz 4-core Intel Nehalem CPUs and 24 GB of
RAM per node, 48 nodes with two 2.00 GHz 8-core
AMD Magny-Cours CPUs and 16 GB of RAM per
node, 12 nodes with a 3.00 GHz 4-core Intel Wood-
creest quadcore CPUs and 8 GB of RAM per node,
11 nodes with two 2.33 GHz 2-core Intel Woodcreest
CPUs and 4 GB of RAM per node, and 4 nodes with
two 2.66 GHz 4-core Intel Woodcrest CPUs and 16
GB of RAM per node. The computing nodes in HER-
MES are connected by Gigabit links, allowing high-
speed data transfers.
At the moment of this writing, the cluster is man-
aged by the Condor
3
middleware version 7.6.3.
The cluster is used by a vast variety of researchers,
mainly focused on inductive and physical systems,
automotive systems, discrete event system analysis
and complex semantic workflow analysis. System uti-
lization is usually focused on the use of CPUs rather
than memory consumption. Data inputs are usually
small sized, although there is a group handling com-
plex experiments with files of more than 20TB. The
analysis of relevant workloads shown that the aver-
age user is not aware of load peaks or advanced con-
figuration issues, which normally produces that ex-
periments last extremely long, require oversized re-
sources or even are queued for long times. In this
scenario, our proposal for a framework which would
optimize such situations is extremely useful from both
the researcher and also the system usage perspectives.
3.2 Implementation Details of the
HERMES Simulator
Alea (Klus´aˇcek and Rudov´a, 2010) has been used to
implement the internal simulator in the HERMES me-
diator component. Alea is an event-based simulator
built upon the GridSim toolkit (Sulistio et al., 2008).
Alea extends GridSim and provides a central sched-
uler, extending some functionalities and improving
scalability and simulation speed. Alea has been de-
signed to allow an easy incorporation of new schedul-
ing policies and to easily extend its functionalities.
Also, Alea provides an experimentation environment
easy to configure and use, which helps in the quick
2
http://i3a.unizar.es
3
http://research.cs.wisc.edu/condor/
SIMULTECH2012-2ndInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
64
and rapid development of simulators when a new in-
frastructure is going to be added to the system.
The original implementation of Alea has been ex-
tended to allow some Condor features such as user
priorities, RAM requirements and preemptions. Fig-
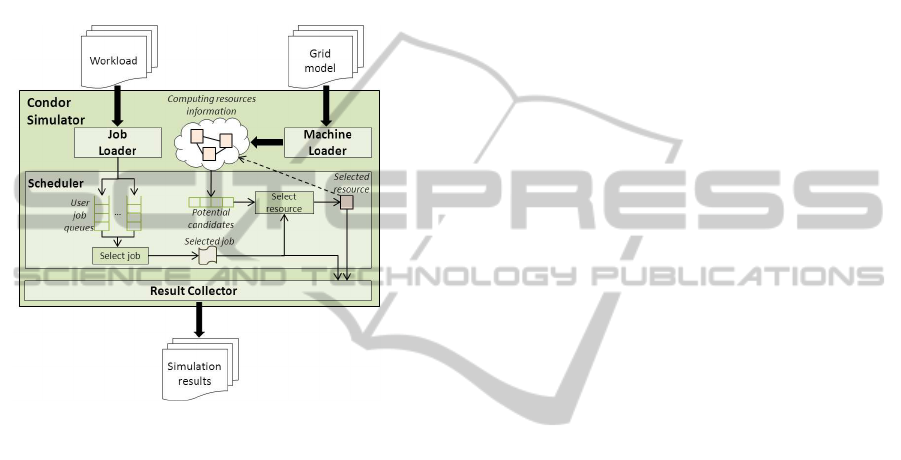
ure 3 depicts the structure of the simulator. As shown,
it consists of two input files, the workload and the
Grid model, and four main modules, the Job Loader,
the Machine Loader, the Scheduler and the Result
Collector, respectively.
Figure 3: Architecture of the Condor simulator based on
Alea.
Multiple workload have been composed using the
cluster execution logs from the last year and identi-
fying common situations of resource utilization and
job submission. The workload is represented using
the Grid Workload Format (GWF format) proposed
by the Grid Workload Archive (GWA) (Iosup et al.,
2008a). For each job, the job execution time, the num-
ber of CPUs required, the memory requirements, the
user and group who executes the job and the job de-
pendencies (if exists) are provided. More details on
the creation of workloads is provided in subsection
5.1.
The Grid model is a text file that contains the in-
formation of each computing node. The representa-
tion of each node includes a node identifier, the num-
ber of machines, the number of CPUs per machine,
the total amount of memory per machine, the sys-
tem architecture, its operating system and the network
characteristics. Also, a failure model can be detailed
to reflect dynamic changes in the infrastructure during
the simulation.
The Job Loader component reads the job descrip-
tions and sends them to the scheduler. This module
has been extended to allow RAM requirements and
user and group details of the submitted jobs.
The Machine Loader component is responsible for
reading the resource description from a file containing
the Grid model. This module has been extended to be
able to parse and save the information provided.
The Scheduler component is the more complex
one. It has been extended with a new scheduling
policy considering the schema for user priorities that
Condor applies in HERMES. This scheduling policy
works as follows: when a job sent by the Job Loader
reaches the scheduler, the job is queued in the right
user queue. This queue is ordered by the job prior-
ity and the job arrival time. When the scheduler re-
quests a new job to be executed, jobs are ordered by
their user priority and the job with the highest prior-
ity is chosen. Then, the machines with available re-
sources (CPUs and RAM) and also the machines that
could have available resources (if some running jobs
are evicted) are selected as potential candidates to ex-
ecute the job. The list of all potential candidates is or-
dered by multiple criteria (job preferences, machine
preferences, etc.) to get the most suitable resource. If
there is no resource available to execute the job, this
is queued again and the scheduler looks for the next
job. Finally, when a job and a resource have been
chosen, the job is sent to the resource and its state is
updated. In addition, some of the current running jobs
are evicted from the selected resource if necessary to
execute the new job. These evicted jobs are requeued
and will be reexecuted later.
Finally, the Result Collector component is respon-
sible for storing the simulation results and provide
them as output. When a job is sent to a resource,
evicted or a machine fails, the Result Collector stores
this information. When a job ends, the Result Collec-
tor stores the job information in an output file. For
each job, the arrival time, the time the job has spent
queued, the execution time of the resource, the re-
source where the job was executed and the number
of evictions suffered by the job are stored in the file.
3.3 Validation of the HERMES
Simulator
The aim of the developed simulator is to be used as
a decision tool at meta-scheduling level. In terms of
simulation accuracy, its validation is a key issue to
verify its feasibility and usefulness for this purpose
(Sargent, 2010). Figure 4 shows a comparison of the
actual cluster utilization, extracted from the logs, and
the simulated utilization, obtained from the simula-
tion of the tasks described in the workload. The com-
parison is presented as a daily cycle in which the hor-
izontal axis indicates the time (in hours) and the ver-
ASimulation-basedSchedulingStrategyforScientificWorkflows
65
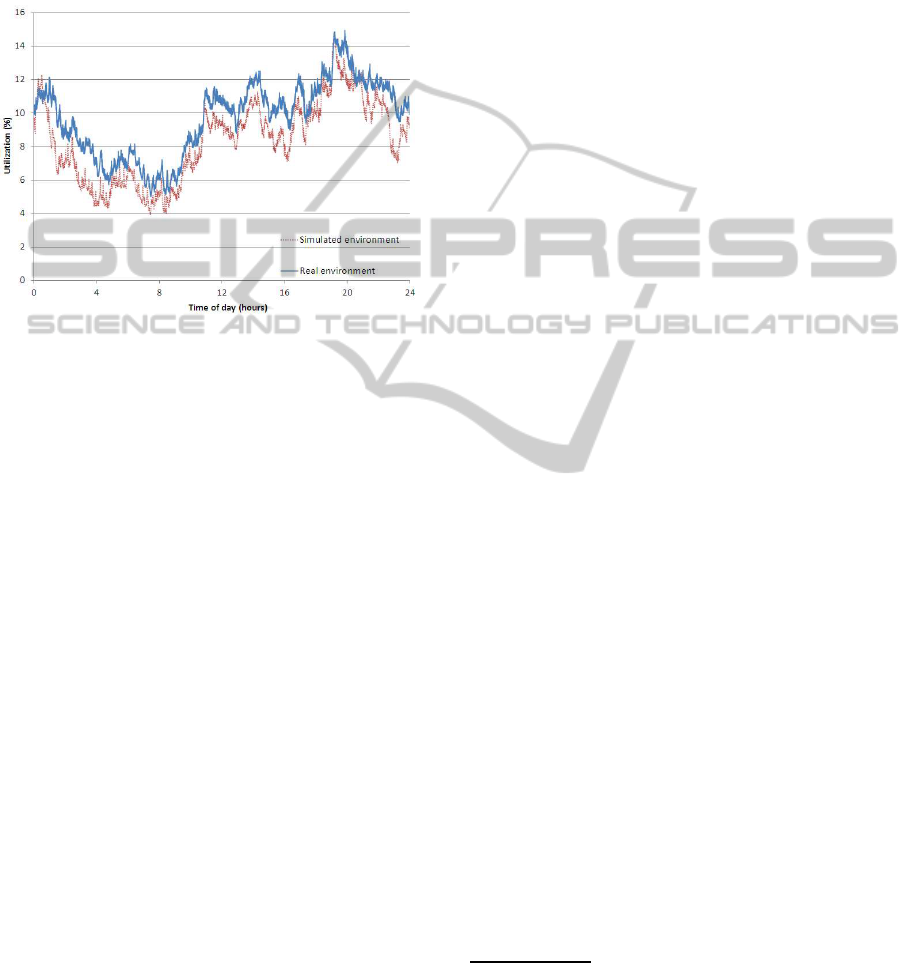
tical axis shows the CPU utilization rate (in percent-
age). As it can be observed, the simulation results are
very similar to real results. Both plots follow the same
trend, being the simulation utilization slightly lower.
In terms of the deviation of the simulation results, an
average error of 15.09% and a standard deviation of
8.03% is observed.
Figure 4: Condor cluster utilization for the real and simu-
lated environment.
In order to validate the job performance indicator,
two metrics are provided: the execution time and the
queue time. Figure 5 shows the cumulative distribu-
tion function for the execution time (Figure 5-a) and
the queue time (Figure 5-b). For the sake of clarity,
the horizontal axis is shown on a log scale. Figure 5-a
illustrates that job execution time is almost the same
in the simulation and the real environment. In con-
trast, there is an important difference between queue
time in both environments, which can be explained
because the simulator is able to schedule a job without
delay when there are available resources to execute a
job. However, Condor middleware suffers for several
delays due to different reasons such as delay notifi-
cations between distributed components, scheduling
cycle duration or status update. To fix this error and
reduce its influence on the results, two techniques are
proposed: the first one adds a synthetic delay to the
job execution time, whereas the second one adds the
synthetic delay to the job queue time results. Also,
how this feature can be incorporated in the simulator
to get more accurate simulations is being studied for
the meantime.
4 EXPERIENCE REUSE FOR THE
SIMULATION OF A GLITE
GRID
In this section, how a simulator for a multi-cluster
Grid can be easily implemented replacing some parts
of the previously developed simulator is shown. Also,
we illustrate the usefulness of the methodology pre-
sented to validate the simulator results.
4.1 Overview of the AraGrid Grid
AraGrid
4
is a research and production Grid hosted by
the Institute for Biocomputation and Physics of Com-
plex Systems (BIFI)
5
and it is part of the European
Grid Initiative (EGI)
6
. AraGrid consists of four ho-
mogeneous sites located at four different faculties in
different geolocated cities. Every site is formed by 36
nodes with two 2.67 GHz 6-core Intel Xeon X5650
CPUs and 24 GB of RAM per node, making a total
amount of 1728 cores and 4 TB of RAM. Both sites
and nodes are interconnected by Gigabit links.
The Grid is managed by the gLite
7
middleware
version 3.2.0 and every site use openPBS
8
version 2.5
as local batch system.
The AraGrid infrastructure is oriented to long-
term experiment in the fields of physics, biochemistry,
social behaviour analysis, astronomy, etc. Users are
more conscious of loads and resource usage, although
they deploy experiments similarly to the HERMES
case, getting long waiting times.
4.2 Implementation and Validation of
the AraGrid Simulator
Starting from the simulator structure, the design and
implementation of the Condor simulator has been
reused to develop a gLite simulator valid for the Ara-
Grid computing infrastructure. This is an easy and
quick implementation process, and the resulting sim-
ulator can be easily adapted to another gLite infras-
tructure. The reasons to implement these two simu-
lators is twofold. On the one hand, HERMES (man-
aged using Condor), AraGrid (gLite) and also Pire-
Grid (gLite) are connected using high speed Gigabit
links, which enhances data movement performance
(which is left out of the scope of this paper). On
the other hand, Condor and gLite are well known and
4
http://www.araGrid.es/
5
http://bifi.es/es/
6
http://www.egi.eu/
7
http://glite.cern.ch/
8
http://www.mcs.anl.gov/research/projects/openpbs/
SIMULTECH2012-2ndInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
66
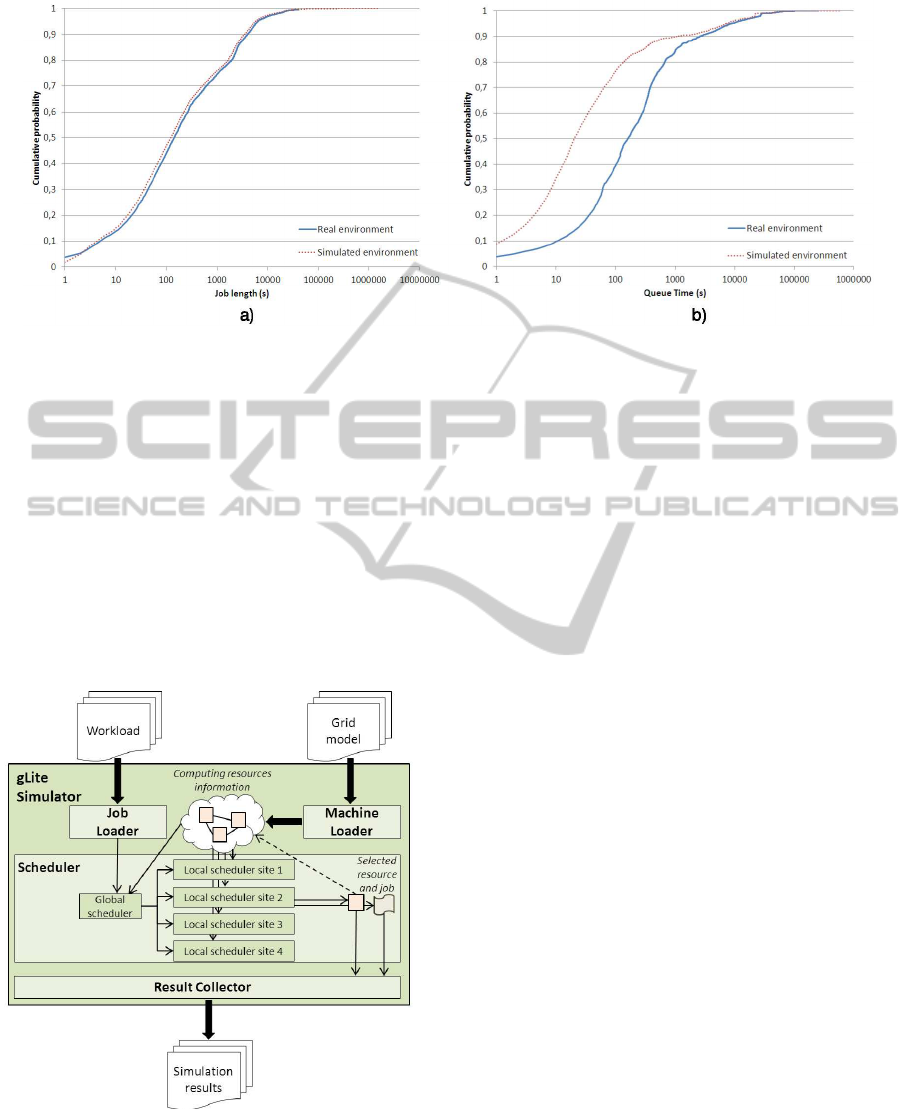
Figure 5: Job performance comparison between real data and simulation results in terms of: (a) job execution time, (b) job
queue time.
widespread cluster/Grid middlewares in the research
community.
The only component that needed a custom adap-
tation to fit the behaviour of AraGrid with respect
to the HERMES simulator component is the sched-
uler. The scheduler’s policy follows a hierarchical ap-
proach, as shown in Figure 6. Jobs sent by the Job
Loader are managed by the global scheduler compo-
nent that sends them to the right local scheduler con-
sidering job requirements, job rank and site occupa-
tion are taken. Meanwhile, every local scheduler uses
a custom First Come First Serve (FCFS) policy.
Figure 6: Architecture of the gLite simulator and detail of
the local scheduler of a site.
It is important to consider a special case. As some
sites are shared with other Grid initiatives such as
EGI, the workload used as input contains jobs that
can only be executed in shared sites. Sites where a
job can be executed depends on the Virtual Organi-
zation (VO). Since this information is included in the
workload, this special case can be properly treated by
the scheduler when this kind of job reaches the global
scheduler.
The resulting simulator component has been inte-
grated into the AraGrid gLite mediator. The valida-
tion of the component has been carried out following
the same approach depicted in subsection 3.3. In this
case, the results are more accurate than in the HER-
MES case. That is because AraGrid scheduling policy
is easier to replicate. The average error is of 1.19%
with a standard deviation of 0.85%.
5 A CASE STUDY: INSPIRAL
ANALYSIS WORKFLOW
In this section, the proposed simulation-based ap-
proach is applied in order to improve the performance
of the Inspiral analysis scientific workflow. The ex-
periment setup is detailed, with particular attention
to the workload creation method used for modelling
other users jobs that are executed in HERMES and
AraGrid at the same time. Finally, performance re-
sults showing the benefits of our infrastructure are
presented and discussed.
One of the main research lines of the Laser Inter-
ferometer Gravitational Wave Observatory (LIGO) is
the detection of gravitational waves produced by var-
ious events in the universe (based on Einstein’s the-
ory of general relativity). The LIGO Inspiral Anal-
ysis Workflow is a scientific workflow which ana-
lyzes and tries to detect gravitational waves produced
by various events in the universe using data obtained
from the coalescing of compact binary systems such
ASimulation-basedSchedulingStrategyforScientificWorkflows
67
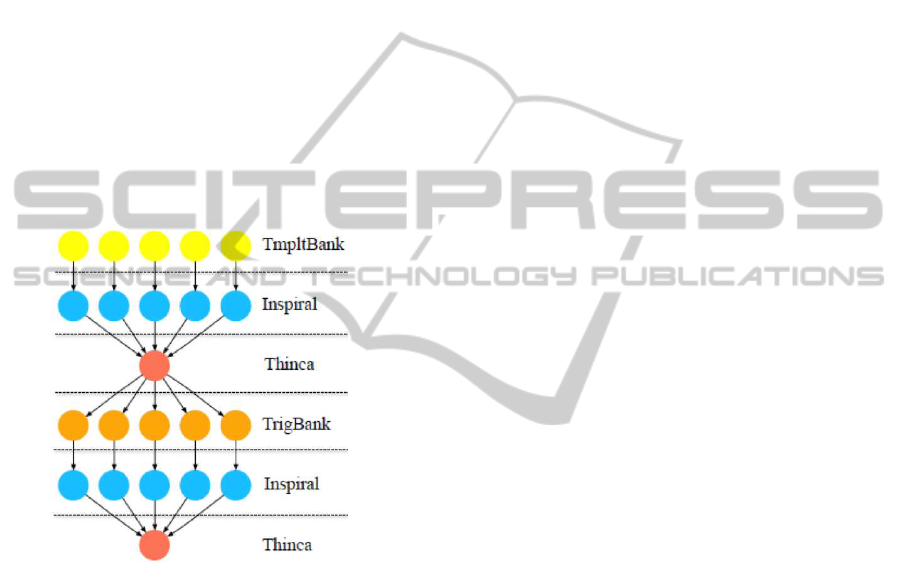
as binary neutron stars and black holes (Taylor et al.,
2006). Figure 7 depicts a simplified view of the main
structure of the workflow. Although the workflow
has a simple structure, it allows a high level of par-
allelism. As shown, the whole experiment is split
into several smaller stages or blocks for analysis. The
time-frequency data from any event for each of the
LIGO detectors is arranged into template banks and
used as an input for the workflow, which generates a
subset of waveforms belonging to the parameter space
and computes the matched filter output in each stage.
Inspiral jobs are the most computationally intensive
tasks in the workflow, generating most of the comput-
ing requirements. In case a true inspiral is detected,
the matched filter output is computed and a trigger
is generated and tested for consistency by the Thinca
jobs as a result from the experiment. Finally, template
banks are then generated from these trigger outputs
and the process repeats.
Figure 7: Workflow of the LIGO Inspiral analysis scientific
workflow.
Several scientific workflows management systems
could be used to develop the workflow. In our case, a
high level Petri nets implementation (Reference nets)
has been developed using the workflow editor pro-
vided by the framework depicted in Section 2. How-
ever, the workflow implementation details are out of
the scope of this paper.
5.1 Experiment Setup
The experiment setup is not specific for this experi-
ment or case study, but it is a general setup automati-
cally generated by the components of the framework.
This design simplifies the use of the infrastructure,
making the simulation-based meta-scheduling com-
pletely transparent to the user.
The process is as follows: first, when a mediator
retrieves a simulation request, it builds a workload de-
scribing the tasks to be simulated. Next, it gets infor-
mation about the state of the computing infrastructure
it represents. These data are used to adapt the pre-
defined Grid model to its current situation (introduc-
ing resource failures) and to build a second workload
representing the infrastructure state during the simu-
lation. Details about the creation of this second work-
load are shown below. Once both workloads have
been created, they are combined into one that is used
as the simulation input. Then, the simulation starts
its execution. Once it has finished, the simulation re-
sults are analysed by the mediator and only the infor-
mation concerning the target tasks is provided to the
meta-scheduler. Finally, the meta-scheduler chooses
the best computing infrastructure based on data ob-
tained from several simulations. For that purpose, the
meta-scheduling policy uses a better-execution-time
algorithm. Nevertheless, more complex policies in-
volving the information obtained in previous simula-
tions could be easily used.
The creation of the workload used to represent
the state of the computing infrastructure is a key step
in the simulation process. The importance of using
an appropriate workload has been identified as a cru-
cial input in some previous work (Feitelson, 2002; Li
et al., 2004). Using a wrong workload can cause the
simulation results not to correspond to the actual be-
haviour of the involved Grids. These research papers
propose the generation of a single workload based on
historical information from a long period of time and
only considering representative periods (e.g. the peak
hours during weekdays in job-intensive months). It
is assumed that the longer the observation period is,
the more representative is the workload, which al-
lows tunning the Grid in extreme situations (Feitel-
son, 2002). Nevertheless, for simulation purposes
these approaches are not valid because the state of the
resources must be considered as the simulation starts.
If an average or extreme workload is used, it is very
likely to get very inaccurate results that lead to wrong
scheduling decisions. Our proposal is to build several
representative workloads with different situations de-
pending on the state of the infrastructure (e.g. low
load, average load and high load) and date. There-
fore, the current computing infrastructure state is ob-
tained before starting a simulation and used to select
the most suitable workload. Also, the recovered in-
frastructure information, including currently running
jobs and queued jobs, is added at the beginning of the
workload, obtaining this way a workload describing
the current infrastructure state and its evolution.
The model proposed in (Iosup et al., 2008b) has
been used for workload creation. This model incorpo-
SIMULTECH2012-2ndInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
68
rates the notions of different users and jobs in Bag-of-
Tasks (BoTs) to the Lublin-Feitelson model (Lublin
and Feitelson, 2003). Due to the fact that the HER-
MES and AraGrid analysis has shown that more than
90% of jobs belongs a BoT and a few users are re-
sponsible for the entire load, this model is suitable for
modelling jobs in our infrastructures.
5.2 Analysis of the Results
To prove the usefulness of the proposed approach,
the workflow has been executed for a whole day (24
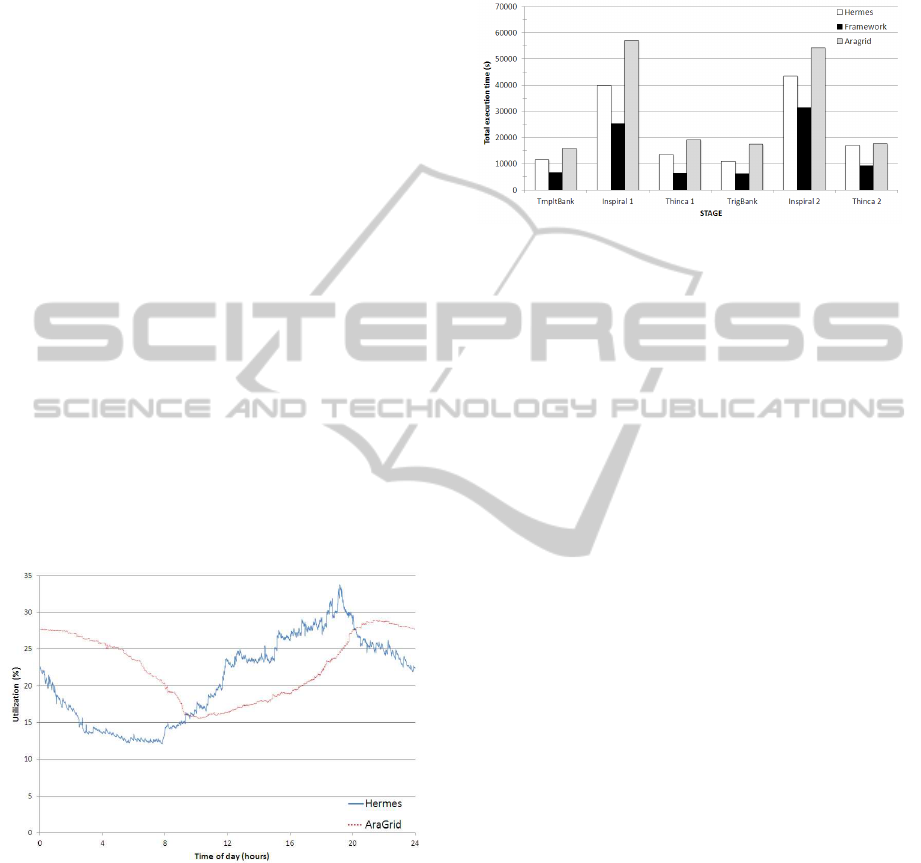
hours). Figure 8 depicts the CPU load observed in
HERMES and AraGrid during the experiment. Note
that HERMES load is different from the one sketched
in figure 4. That is because the load in Figure 4 is
an average load extracted from the execution log cor-
responding to the whole last year, whereas Figure 8
shows the cluster load on a particular day. As it can
be observed, both computing infrastructures have dif-
ferent load models. Throughout the day there are bet-
ter periods of time for submitting jobs to HERMES
(mostly at early morning and night), and times more
appropriate to submit jobs to AraGrid (in the after-
noon). However, this is not the only criterion to be
considered as the performance of a Grid infrastruc-
ture depends on many factors.
Figure 8: HERMES and AraGrid utilization (in percentage)
observed during workflow execution.
The use of the simulation as a decision tool for
meta-scheduling deals with this complexity and im-
proves the performance obtained in the execution of
the workflow as shown in Figure 9. The figure shows
the total execution time for each stage of the In-
spiral workflow entirely executed in each comput-
ing infrastructure (HERMES on the left bar and Ara-
Grid on the right bar ) and using the framework with
the simulation-based meta-scheduling strategy (cen-
ter bar) depicted previously. The results show that
the use of the proposed approach leads to an improve-
ment of 59% in HERMES execution time and a 111%
in AraGrid execution time.
Figure 9: Experimental results for LIGO Inspiral analysis
workflow.
Regarding the simulation overhead in terms of ex-
ecution time, the simulation process for HERMES is
more complex (more iterative structures) and can take
up to 3-4 minutes for a bag of 10000 tasks, whereas
for gLite it takes one minute approximately. There-
fore, simulation times are insignificant in comparison
to the execution time of each stage. Also, data move-
ment has been measured. For the sake of clarity, as
HERMES and AraGrid are connected by a Gigabit
link, these times are small and can be avoided in the
calculation of the overall execution time.
6 CONCLUSIONS
In this paper, a simulation component based on realis-
tic workload usage has been presented. This compo-
nent allows modelling and simulating different com-
puting infrastructures in terms of performance, re-
source usage, cost, etc. We have also described a
framework developed for the flexible deployment of
scientific workflows in Grid environments, and which
allows researchers to transparently work simultane-
ously with different and heterogeneous Grid middle-
wares.
The integration of the simulation component into
the framework allows improving the meta-scheduling
process. Not only a simulation process can be carried
out to find the best computing infrastructure to exe-
cute a task (or a bag of tasks) in terms of performance
or costs, but also the process may vary depending on
the used workload. The use of realistic workloads
provides very suitable and reliable results.
The flexible design and implementation of the
simulation component also allows an easy adaptation
for being used with different computing infrastruc-
tures, as it was shown by means of the reuse of the
ASimulation-basedSchedulingStrategyforScientificWorkflows
69

HERMES simulator component (Condor) to develop
the AraGrid one (gLite). Both Condor and gLite are
two of the most used cluster/Grid middlewares in the
research community. Thus, an additional advantage
is that the developed components can be easily reused
for simulating other existing computing infrastruc-
tures.
Finally, the integration of the presented approach
into the framework has been applied to the develop-
ment and execution of the Inspiral analysis over two
different computing infrastructures, HERMES and
AraGrid. As a result, the overall execution cost was
significantly reduced.
Currently, the proposed simulation component is
being extended to support the dynamic building of
workloads. The use of dynamic workloads will mini-
mize the effort required to build a new simulator and
allow to obtain more accurate simulations. Also, the
addition of new features in the simulator is being ad-
dressed in order to get more accurate queue times in
simulations. Finally, the incorporation of complex
meta-scheduling approaches that can use the informa-
tion provided by the simulation process will be stud-
ied.
ACKNOWLEDGEMENTS
This work has been supported by the research project
TIN2010-17905, granted by the Spanish Ministry of
Science and Innovation.
REFERENCES
Abraham, A., Liu, H., Zhang, W., and Chang, T.-G. (2006).
Scheduling Jobs on Computational Grids Using Fuzzy
Particle Swarm Algorithm. In Proceedings of the 10th
International Conference in Knowledge-Based Intel-
ligent Information and Engineering Systems – KES
2006, volume 4252, pages 500–507.
Fabra, J., Hern´andez, S.,
´
Alvarez, P., and Ezpeleta, J.
(2012). A framework for the flexible deployment of
scientific workflows in grid environments. In Proceed-
ings of the Third International Conference on Cloud
Computing, GRIDs, and Virtualizations – CLOUD
COMPUTING 2012.
Feitelson, D. G. (2002). Workload Modeling for Perfor-
mance Evaluation. In Proceedings of Performance
Evaluation of Complex Systems: Techniques and
Tools – Performance 2002, volume 2459, pages 114–
141.
Foster, I. and Kesselman, C. (2003). The Grid 2: Blueprint
for a New Computing Infrastructure. Morgan Kauf-
mann Publishers Inc., San Francisco, CA, USA.
Hamscher, V., Schwiegelshohn, U., Streit, A., and
Yahyapour, R. (2000). Evaluation of Job-Scheduling
Strategies for Grid Computing. In Proceedings of
the First IEEE/ACM International Workshop on Grid
Computing – GRID 2000, pages 191–202.
Iosup, A. and Epema, D. H. J. (2011). Grid Computing
Workloads. IEEE Internet Computing, 15(2):19–26.
Iosup, A., Li, H., Jan, M., Anoep, S., Dumitrescu, C.,
Wolters, L., and Epema, D. H. J. (2008a). The Grid
Workloads Archive. Future Genereration Computer
Systems, 24(7):672–686.
Iosup, A., Sonmez, O., Anoep, S., and Epema, D. (2008b).
The performance of bags-of-tasks in large-scale dis-
tributed systems. In Proceedings of the 17th inter-
national symposium on High performance distributed
computing – HPDC 2008, pages 97–108.
Kert´esz, A. and Kacsuk, P. (2010). GMBS: A new middle-
ware service for making grids interoperable. Future
Generation Computer Systems, 26(4):542–553.
Klus´aˇcek, D. and Rudov´a, H. (2010). Alea 2 – Job Schedul-
ing Simulator. In Proceedings of the 3rd International
ICST Conference on Simulation Tools and Techniques
– SIMUTools 2010.
Li, H., Groep, D., and Wolters, L. (2004). Workload char-
acteristics of a multi-cluster supercomputer. In Pro-
ceedings of the 10th International Conference on Job
Scheduling Strategies for Parallel Processing – JSSPP
2004, pages 176–193.
Lublin, U. and Feitelson, D. G. (2003). The workload
on parallel supercomputers: modeling the characteris-
tics of rigid jobs. Journal of Parallel and Distributed
Computing, 63(11):1105–1122.
Ludwig, S. A. and Moallem, A. (2011). Swarm Intelligence
Approaches for Grid Load Balancing. Journal of Grid
Computing, 9(3):279–301.
Rahman, M., Ranjan, R., Buyya, R., and Benatallah, B.
(2011). A taxonomy and survey on autonomic man-
agement of applications in grid computing environ-
ments. Concurrency and Computation: Practice and
Experience, 23(16):1990–2019.
Sargent, R. G. (2010). Verification and validation of sim-
ulation models. In Proceedings of the 2010 Winter
Simulation Conference – WSC 2010, pages 166–183.
Sulistio, A., Cibej, U., Venugopal, S., Robic, B., and Buyya,
R. (2008). A toolkit for modelling and simulating data
Grids: an extension to GridSim. Concurrency and
Computation: Practice and Experience, 20(13):1591–
1609.
Taylor, I. J., Deelman, E., Gannon, D. B., and Shields, M.
(2006). Workflows for e-Science: Scientific Workflows
for Grids. Springer-Verlag New York, Inc., Secaucus,
NJ, USA.
Yu, J. and Buyya, R.(2005). A taxonomy of scientific work-
flow systems for grid computing. SIGMOD Record,
34(3):44–49.
Yu, Z. and Shi, W. (2007). An Adaptive Rescheduling Strat-
egy for Grid Workflow Applications. In IEEE Inter-
national Parallel and Distributed Processing Sympo-
sium, 2007 – IPDPS 2007, pages 1–8.
SIMULTECH2012-2ndInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
70
