
Context Modeling and Context Transition Detection
in Software Development
Bruno Antunes, Joel Cordeiro and Paulo Gomes
Centre for Informatics and Systems, University of Coimbra, Coimbra, Portugal
Keywords:
Context Modeling, Context Capture, Software Development, IDE.
Abstract:
As software development projects increase in size and complexity, developers are becoming overloaded and
need to cope with a growing amount of contextual information. This information can be captured and pro-
cessed in order to improve some of the tasks performed by developers during their work. We propose a context
model that represents the focus of attention of the developer at each moment. This context model adapts to
changes in the focus of attention of the developer through the automatic detection of context transitions. We
have developed a prototype that was submitted to an experiment with a group of developers, to collect statisti-
cal information about the context modeling process and to manually validate the context transition mechanism.
1 INTRODUCTION
The interest in the many roles of context comes from
different fields such as literature, philosophy, linguis-
tics and computer science, with each field propos-
ing its own view of context (Mostefaoui et al., 2004).
The term context typically refers to the set of circum-
stances and facts that surround the center of interest,
providing additional information and increasing un-
derstanding. The context-aware computing concept
was first introduced by Schilit and Theimer (Schilit
and Theimer, 1994), where they refer to context as
“location of use, the collection of nearby people and
objects, as well as the changes to those objects over
time”. In a similar way, Brown et al. (Brown et al.,
1997) define context as location, identities of the peo-
ple around the user, the time of day, season, tem-
perature, etc. In a more generic definition, Dey and
Abowd (Dey and Abowd, 2000) define context as
“any information that can be used to characterize the
situation of an entity. An entity is a person, place,
or object that is considered relevant to the interaction
between a user and an application, including the user
and applications themselves”.
With the increasing dimension of software sys-
tems, software development projects have grown in
complexity and size, as well as in the number of fea-
tures and technologies involved. During their work,
software developers need to cope with a large amount
of contextual information that is typically not cap-
tured and processed in order to enrich their work envi-
ronment. Especially, in the IDE, developers deal with
dozens of different artifacts at the same time. The so-
ftware development process requires that developers
repeatedly switch between different artifacts, which
often depends on searching for these artifacts in the
source code structure. The workspace of developers
frequently comprises hundreds, if not thousands, of
artifacts, which makes the task of searching for rele-
vant artifacts very time consuming, especially when
repeated very often. The contextual information as-
sociated to the work of a developer can be used to
identify the source code artifacts that are more rele-
vant at a specific point in time. Although the work
of a developer is typically task oriented, it is too com-
plex and dynamic to be easily sliced into simple tasks.
The developer often addresses more than one task in
a short period of time, or even at the same time, and
the switches between these tasks are not explicit. This
behaviour makes it difficult to identify the context of
a task and to know when the developer switches be-
tween tasks. We believe that more important than
identifying the context for each one of the tasks the
developer has at hands, is to understand what is the
focus of attention of the developer at each moment
and adapt as it changes.
We propose a context model that represents the fo-
cus of attention of the developer at each moment. This
context model comprises a structural and a lexical di-
mensions. The structural context focus on the source
code artifacts and their structural relations, while the
lexical context focus on the terms used to represent
these artifacts. This context model adapts to changes
in the focus of attention of the developer, automat-
ically detecting context transitions, either to a new
context or a previous one. We have implemented
477
Antunes B., Cordeiro J. and Gomes P..
Context Modeling and Context Transition Detection in Software Development.
DOI: 10.5220/0004084204770484
In Proceedings of the 7th International Conference on Software Paradigm Trends (ICSOFT-2012), pages 477-484
ISBN: 978-989-8565-19-8
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

a prototype, named SDiC
1
(Software Development
in Context), in the form of a plugin that integrates
the context modeling and transition mechanisms in
Eclipse
2
. The prototype was submitted to an exper-
iment with a group of developers, in order to col-
lect statistical information about the context modeling
process and to manually validate the context transi-
tion mechanism.
The remaining of the paper starts with an overview
of related work. Then we introduce the developer
context model and section 4 explains how the con-
text transition is processed. The prototype developed
is described in section 5. The experimentation and
results discussion is presented in section 6. Finally,
section 7 concludes the work with some final remarks
and future work.
2 RELATED WORK
Kersten and Murphy (Kersten and Murphy, 2006)
have been working on a model for representing tasks
and their context. The task context is derived from an
interaction history that comprises a sequence of inter-
action events, representing operations performed on
a software program’s artifact. They then use the in-
formation in a task context either to help focus the
information displayed in the IDE, or to automate the
retrieval of relevant information for completing a task.
We do not attach the context of the developer to tasks,
we see the context model as a continuous and dy-
namic structure that adapts to the behaviour of the
developer. Instead of requiring developers to explic-
itly define where a task starts and ends, our approach
automatically adapts to the changes in the focus of
attention of the developer, identifying which artifacts
are more relevant for the activities of the developer in
each moment.
In the same line of task management and recov-
ery, Parnin and Gorg (Parnin and Gorg, 2006) propose
an approach for capturing the context relevant for a
task from a programmer’s interactions with an IDE,
which is then used to aid the programmer recovering
the mental state associated with a task and to facili-
tate the exploration of source code using recommen-
dation systems. The work is essentially focused on
methods, while our approach also covers classes and
interfaces, and they do not take into consideration the
structural relations that exist between these elements.
They interpret moves between methods as transitions,
differing from our broader interpretation of a context
1
http://sdic.dei.uc.pt
2
http://eclipse.org
transition, which represents a change in the focus of
attention of the developer.
With the belief that customized information re-
trieval facilities can be used to support the reuse of
software components, Henrich and Morgenroth (Hen-
rich and Morgenroth, 2003) propose a framework that
enables the search for potentially useful artifacts dur-
ing software development. Their approach exploits
both the relationships between the artifacts and the
working context of the developer. The context infor-
mation is used to refine the search for similar artifacts,
as well as to trigger the search process itself. Only
a small part of the interaction of the developer with
the IDE is considered in the context model, while our
approach is fully based on the source code artifacts
manipulated by the developer in the IDE.
Holmes and Murphy (Holmes and Murphy, 2005)
proposes Strathcona, an Eclipse plugin that allows to
search for source code examples. The process con-
sists of extracting the structural context of the code on
which a developer is working, when the developer re-
quests for examples. The search is based in different
heuristics, such as inheritance relations and method
calls, by matching the structural context with the code
in the repository. The contextual information is ex-
plicitly provided by the developer when searching for
source code examples, while our context model is au-
tomatically built from the interactions of the devel-
oper in the IDE.
Ye and Fischer in (Ye and Fischer, 2002), propose
a process called information delivery, which consists
in proactively suggesting useful software engineer’s
needs for components. The process is performed
by running continuously as a background process in
Emacs, extracting reuse queries by monitoring devel-
opment activities. They use the JavaDoc comments as
context to create a query for retrieving relevant com-
ponents, while our approach makes use of context to
improve the ranking of search results. With the idea
that code fragments using similar terms in the identi-
fiers also use similar methods, Heinemann and Hum-
mel (Heinemann and Hummel, 2011) proposes the
use of the knowledge embodied in the identifiers as
a basis for recommendation of methods. They use the
identifiers of a few source lines preceding a method
call as context. These approaches focus on the iden-
tifiers and comments used in the source code to com-
plement a query used to retrieve relevant artifacts.
They do not take into consideration the focus of at-
tention of the developer or the relative relevance of a
specific artifact manipulated by the developer.
Warr and Robillard (Warr and Robillard, 2007)
developed a plugin for the Eclipse IDE to provide pro-
gram navigation, by suggesting potentially relevant
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
478

elements for the current context. The context is cre-
ated by the user by dragging and dropping elements
of interest into a view. It retrieves and ranks all the el-
ements in the project’s source code by taking into ac-
count their structural relations to any of the elements
in the context. The contextual information is provided
by the developer through a set of elements of interest,
while our approach automatically identifies these ele-
ments of interest and how their interest evolves over
time.
3 CONTEXT MODELING
The context model we have defined aims to represent
the context of the developer in relation to the source
code artifacts that are more relevant to the work of the
developer at each moment. The model is built from
the interactions of the developer with the source code
artifacts and evolves over time, as the focus of atten-
tion of the developer changes. It comprises a struc-
tural and a lexical dimensions, which are described in
more detail on the following sections (see figure 1).
3.1 Structural Context
The structural context focus on the source code ar-
tifacts and structural relations that are more relevant
for the developer in a specific moment. It comprises a
list of structural elements and relations with an asso-
ciated DOI (Degree of Interest), a concept introduced
in (Kersten and Murphy, 2006), that represents their
relevance in the context of the developer. Next, we
describe the structural context in more detail, includ-
ing the structural elements and structural relations.
3.1.1 Structural Elements
The structural elements represent the source code ar-
tifacts with which the developer is interacting. Asso-
ciated to each artifact is a DOI that is derived from
the analysis of the interactions of the developer with
that artifact. When the developer opens, closes, ac-
tivates or edits an artifact, that artifact is considered
relevant for the structural context. The DOI of an ar-
tifact changes according to the different interactions
that affect that artifact. The impact of each interac-
tion in the DOI of an artifact has been defined based
on our experience and some empirical tests. When
the artifact is opened, it is added to the structural con-
text and its DOI is increased by 0.4. When the artifact
gains focus or is edited, its DOI is increased by 0.2
and 0.1, respectively. When an artifact is closed, its
DOI is decreased by −0.4.
As time passes, the DOI of the artifacts is decayed,
so that the relevance of an artifact to the context of the
developer decreases if it is not used over time. The de-
cay is executed every five minutes. To prevent loosing
the context if the developer is distracted or away for
some reason, the decay is only executed if the devel-
oper has been active during that time interval. When
the DOI of an artifact reaches zero, the artifact is re-
moved from the structural context. The DOI of each
artifact is represented in the interval [0, 1], by normal-
izing the original value using (1).
1 −
1
e
x
(1)
As shown in figure 1, the structural ele-
ments ContextModel, ContextElement and Contex-
tElement.setDOI(int) were added to the structural
context because they were manipulated by the devel-
oper at some point in time. The relevance of these el-
ements to the developer is given by their DOI values,
which evolved according to the different interactions
of the developer with that elements over time.
3.1.2 Structural Relations
The structural relations represent the relevance of the
relations that exist between the source code artifacts
that are manipulated by the developer. These rela-
tions represent the structural relations that exist in the
Java programming language, but are common to most
of the object oriented programming languages, and
can be categorized in three groups: inheritance (ex-
tensionOf and implementationOf ), composition (at-
tributeOf and methodOf ) and behaviour (calledBy,
usedBy, parameterOf and returnOf ). The relevance
of the structural relations can be used to measure the
relevance of source code artifacts that are not being
used by the developer, but are structurally related with
the artifacts that are in the context model.
Because the structural relations are not directly af-
fected by the interactions of the developer, their rele-
vance is derived from the structural elements that exist
in the structural context. When two, or more, struc-
tural elements are bound by one of these relations,
that relation is added to the structural context. Asso-
ciated with each relation is a DOI that represents the
relevance of that relation in the context of the devel-
oper. The DOI of a relation is computed as an average
of the DOI of all structural elements that are bound by
that relation. The DOI of a structural relations is up-
dated according to the changes in the elements that
are bound by that relation. When no more structural
elements are bound by a relation, it is removed from
the structural context.
ContextModelingandContextTransitionDetectioninSoftwareDevelopment
479

ContextModel
ContextElement
ContextElement.setDOI(int)
0.8
0.6
0.4
STRUCTURAL ELEMENTS DOI
attributeOf
methodOf
0.7
0.5
STRUCTURAL RELATIONS DOI
STRUCTURAL CONTEXT
model
context
element
...
0.8
0.6
0.5
LEXICAL ELEMENTS DOI
LEXICAL CONTEXT
INTERACTION
TIMELINE
INTERACTION
Figure 1: A representation of the context capture and modeling processes.
The structural relations represented in figure 1,
attributeOf and methodOf, were added to the struc-
tural context because there are structural elements
bound by these relations. The structural element Con-
textElement is an attribute of the structural element
ContextModel, and ContextElement.setDOI(int) is a
method of ContextElement. The DOI associated with
these relations represents the average DOI of the ele-
ments that are bound by them.
3.2 Lexical Context
The lexical context focus on the terms that are more
relevant in the context of the developer. It com-
prises a list of terms that are extracted from the names
of the source code artifacts that are manipulated by
the developer. The name of source code artifacts in
the Java programming language typically follow the
Camel Case
3
naming standard, resulting in one or
more terms joined without spaces and with the first
letter of each element capitalized. We use this char-
acteristic to extract the different terms associated with
an artifact. The lexical context comprises all the terms
extracted from the structural elements in the structural
context. Similarly to the elements and relations in the
structural context, the relevance of each term is given
by its DOI. The DOI of a term is computed as an aver-
age of the DOI of the structural elements from which
the term was extracted. When the structural elements
change, the lexical context is updated accordingly.
Because terms are not explicitly related as the
source code artifacts, the terms used in the names of
all the source code artifacts that exist in the workspace
of the developer are analyzed in order to identify
3
http://en.wikipedia.org/wiki/CamelCase
terms that are related by co-occurrence. The co-
occurrence relation is created when two terms are
found in the name of an artifact. In a linguistic
sense, co-occurrence can be interpreted as an indi-
cator of semantic proximity (Harris, 1954). We use
co-occurrence as a measure of proximity between two
terms, assuming that if the terms are used together to
represent the same entity, that means they are related.
These relations are then used to understand how the
source code artifacts are related with each other from
a lexical point of view. We also identify terms that
are very frequent, such as get, set, etc. These very
frequent terms co-occur with a variety of other terms
and end up connecting almost every term in a distance
of three relations. To avoid this, we chose to ignore
all the terms that would fall in the top 30% of all term
occurrences.
The terms in the lexical context of figure 1, model,
context, element, etc, were extracted from the ele-
ments in the structural context. Their DOI represents
the average DOI of the structural elements referenced
by them.
4 CONTEXT TRANSITION
As the focus of attention of the developer changes,
the notion of what is relevant to the work of the de-
veloper also changes and the context model must be
adapted accordingly. The context model described
was designed to represent the focus of attention of
the developer at each moment, but does not provide,
by itself, the mechanisms needed to adapt as the fo-
cus of attention changes, which sometimes happens
very fast. Because the developer commonly addresses
more than one task in a short period of time, or even
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
480

CONTEXT TRANSITION
WINDOW
HARD TRANSITIVE
ELEMENT
SOFT TRANSITIVE
ELEMENT
INTERACTION
TIMELINE
INTERACTION
Figure 2: A representation of the context transition window applied to the interaction timeline.
at the same time, the focus of attention is dispersed
through different parts of the source code structure.
This means that, in fact, more than one context model
exist in parallel, and they must be activated and deac-
tivated as the focus of attention changes. This issue
has been addressed with a mechanism to deal with
context transitions, as the focus of attention of the
developer changes. This way we may have several
context models, that are stored in a context model
pool, with only one context model active at each mo-
ment. The system automatically detects the changes
in the focus of attention of the developer and decides
whether a new context should be created or an exist-
ing one should be activated.
To detect changes in the focus of attention of the
developer, we rely on the way source code artifacts
added to the context model are related with those that
are already in the context model. When the atten-
tion of the developer shifts to a different part of the
source code structure, it is expected to see, in a short
period of time, a reasonable number of interactions
with source code artifacts that have no relation with
those in the current context model. We assume that in
such a situation, the system must adapt to the change
that is occurring in the behaviour of the developer and
make a transition to a new context, or an existing one.
To detect these situations we have defined a mecha-
nism based on a fixed time window and a set of tran-
sitive elements (see figure 2). The time window is
used to represent the time span within which a cer-
tain number of elements having no relation with the
current context will start a context transition. We call
these elements of transitive elements, and they can be
either hard or soft transitive. The hard transitive ele-
ments are those that have absolutely no relation with
the elements in the current context. The soft transitive
elements are those that are are related only with hard
transitive, or other soft transitive, elements. The time
window moves along the interaction timeline as time
passes. The hard or soft transitive elements that reach
the limit of the time window are no longer marked as
transitive elements. When the number of hard transi-
tive elements reaches a threshold of 3, or the num-
ber of soft transitive elements reach a threshold of
6, within a context transition window of 3 minutes,
a context transition is initiated.
When a context transition is detected, the system
must remove the transitive elements from the cur-
rent context, deactivate it and decide if a new context
should be created or an existing one should be acti-
vated. To activate an existing context, one must assure
that the developer is changing the focus of attention to
a part of the source code structure that originated the
existing context. The system decides if an existing
context should be activated by comparing its elements
with the transitive elements, those that were used to
detect the context transition in the first place. The
similarity between the two sets of elements is com-
puted using the Jaccard index (Jaccard, 1901), also
known as the Jaccard similarity coefficient, which is a
statistic measure used for comparing the similarity be-
tween sample sets. When the similarity between the
two sets is greater than a threshold of 0.5, the existing
context is activated. If the threshold is not reached,
a new context is created, the transitive elements are
added to this new context and then it is activated.
5 PROTOTYPE
We have implemented a prototype in the form of a
plugin, that integrates the context modeling and con-
text transition mechanisms in Eclipse. The activity of
the developer is monitored in the background in order
to build the context model and detect context transi-
tions.
The prototype provides an interface where all the
information related with the context modeling and
context transition processes can be consulted (see fig-
ure 3). The interface shows a list of all the context
models that have been created (see 1 in figure 3).
When one of these context models is selected, all the
information related with the selected context model
is presented, including information about the struc-
ContextModelingandContextTransitionDetectioninSoftwareDevelopment
481
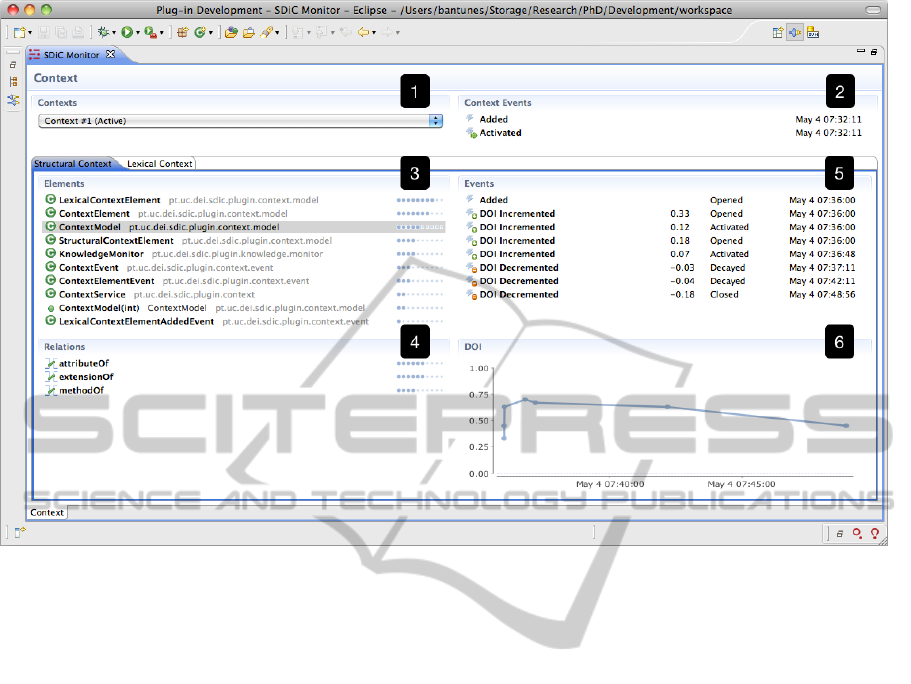
Figure 3: A screenshot of the prototype, showing information about the structural context.
tural and lexical contexts. A list of events (Added,
Removed, Activated and Deactivated) associated with
the context model is presented (see 2 in figure 3).
Concerning the structural context, we can see the
structural elements (see 3 in figure 3) and structural
relations (see 4 in figure 3) that exist in the selected
context model, as well as a visual representation of
their current DOI. The hard and soft transitive ele-
ments are shown in gray, with the soft transitive ele-
ments having a lighter grey than the others. When one
of the elements or relations is selected, a list of the
events (Added, Removed, DOI Incremented and DOI
Decremented) that affected that element are presented
(see 5 in figure 3) and a chart representing the evolu-
tion of its DOI over time is shown (see 6 in figure 3).
Concerning the lexical context model, we can see the
terms that exist in the current context model. Simi-
larly to the structural context interface, when a term
is selected, the list of events that affected the term is
presented and a chart representing the evolution of its
DOI over time is shown.
6 EXPERIMENTATION
We have created an experiment to validate our ap-
proach in the field, with developers using the pro-
totype during their work. The experiment was con-
ducted during a period of about two weeks, with
a group of four developers from different software
houses and four students from a computer science
graduation, all of them using Eclipse to develop
source code in the Java programming language. The
objective of the experimentation was to collect statis-
tical data about the context modeling and transition
mechanisms, as well as to manually validate the con-
text transitions processed by the system.
Concerning the context modeling mechanism, we
have collected statistical data about new elements
added to the context model and how they were re-
lated with the elements that were already in the con-
text model. This information would allow us to better
understand how the source code artifacts manipulated
by developers are related with each other and how this
could be used to improve the context modeling and
transition processes. We have analyzed a total of 9210
elements added to the context model. To evaluate how
these elements were related with existing elements,
we have verified if they were related within a distance
of 3 relations with the top 15 elements with higher
DOI of both the structural and the lexical contexts.
About 88% of the elements were structurally related
with at least one structural element, with an average
distance of 2.5 relations, and about 90% were lexi-
cally related with at least one lexical element, with an
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
482

Table 1: Average number of structural and lexical elements.
Average Structural Elements 16.0
Average Structural Related Elements 5.8
Average Structural Unrelated Elements 5.9
Average Lexical Elements 18.4
Average Lexical Related Elements 26.8
Average Lexical Unrelated Elements 2.3
average distance of 2 relations. These numbers show
that most of the source code artifacts needed by de-
velopers were related with at least one of the artifacts
manipulated before, within a distance of about two re-
lations. Based on this, we believe that the use of our
context model to rank, elicit and filter relevant source
code artifacts for the developer is very promising. As-
suming that a source code artifact needed by the de-
veloper is likely to be related with the artifacts being
manipulated, we can use the proximity between this
artifact and the context model to assess its relevance
to the developer.
In table 1 we present the average number of struc-
tural and lexical elements, as well as the average num-
ber of elements related and unrelated with the added
element. The lexical related elements have an higher
average due to the fact that a source code artifact name
typically comprises more than one term, and each
match between one of these terms and the terms in the
lexical context was considered. The results show that
the source code artifacts added to the context model
were structurally related with a an average of about
30% of the elements that were already in the context
model. The results of the lexical elements are even
more expressive. This reinforces the idea that the
source code artifacts manipulated by developers are
highly correlated. We have also analyzed the types
of relations that are more common between the added
elements and the existing elements. The percentage
of times each relation appeared is shown in table 2.
The composition and behavior relations are by far the
most common, as expected.
With respect to the context transition process, we
have collected statistical information about 55 con-
text transitions, presented in table 3. All the context
transitions led to the creation of a new context. We
could conclude that a transition to a previous context
is something very uncommon, but we have to collect
more data in order to understand if improvements can
be made in the identification of similar contexts. The
use of the Jaccard similarity coefficient between the
set of all elements in the existing context and the set of
transitive elements may be the cause for this behavior.
Because the existing context most of the times con-
Table 2: Percentage of times each relation appeared in the
relations between added and existing context elements.
extensionOf 5.5%
implementationOf 1.0%
attributeOf 42.3%
methodOf 90.3%
calledBy 69.7%
usedBy 30.5%
parameterOf 9.3%
returnOf 2.3%
Table 3: Statistical information collected about the context
transition process.
Context Transition (New Context) 100%
Context Transition (Existing Context) 0%
Context Transition (Hard Transition) 67%
Context Transition (Soft Transition) 33%
tains many more elements than the number of tran-
sitive elements, which makes it very difficult to reach
the similarity threshold of 0.5. We plan to improve the
process by focusing only in the transition elements.
Because the transition elements are more relevant for
the context transition process than the others, we may
assume that if an existing context contains most of
the transition elements, then this context model is a
good candidate to be activated. Also, we could con-
clude that context transitions are more often caused by
reaching the hard transitive elements threshold than
by reaching the soft transitive elements threshold.
Finally, we asked the developers to evaluate how
each context transition detected by the system could
be identified as change in their focus of attention.
They were presented with the structural elements that
were in the context model before the transition and
the elements that were used to detect the transition
(both hard and soft transitive). They were asked to
rate how the context transition would be related with
a change in their focus of attention in a scale from 1
(Poorly Related) to 5 (Highly Related). The average
score for the 55 context transitions evaluated was 3.0.
The average score obtained is not conclusive, but is
encouraging, at least. One of the problems we have
faced is that developers have some difficulties under-
standing the concepts of context transition and focus
of attention, which can have lead to misjudgment in
the evaluation process.
ContextModelingandContextTransitionDetectioninSoftwareDevelopment
483

7 CONCLUSIONS
We have presented an approach to context modeling
and context transition detection in software develop-
ment. The context model combines a structural and a
lexical dimensions, to represent the source code ar-
tifacts, structural relations and terms that are more
relevant for the developer in a specific moment in
time. The context transition detection mechanism al-
lows the context model to automatically adapt to the
changes in the focus of attention of the developer. We
have implemented a prototype that integrates our ap-
proach in Eclipse. This prototype was submitted to
an experiment with a group of developers to collect
statistical information about the context modelling
process and to manually validate the context transi-
tion mechanism. The statistical information collected
shows that the source code artifacts manipulated by
the developer are highly correlated, leading us to be-
lieve that the use of a context model to assess the rel-
evancy of a source code artifact to the developer is
very promising. The human evaluation of the con-
text transition mechanism was not conclusive, but the
results are nevertheless encouraging, considering the
fact that developers have some difficulties in under-
standing the concept of context transition.
As future work we plan to improve the context
modeling and context transition processes, taking into
consideration some of the issues that were identified.
Also, we want to evaluate if the lexical context can
be used to detect context transitions and how it would
impact the the current context transition mechanism.
Next, we want to apply the context model developed
to improve the context-based retrieval of source code
artifacts in the IDE. The context model can be used
to rank, elicit and filter source code artifacts based on
their proximity to the context model.
ACKNOWLEDGEMENTS
Bruno Antunes is supported by the FCT scholarship
grant SFRH/BD/43336/2008, co-funded by ESF (Eu-
ropean Social Fund).
REFERENCES
Brown, P. J., Bovey, J. D., and Chen, X. (1997). Context-
aware applications: From the laboratory to the mar-
ketplace. Personal Communications, IEEE, 4:58–64.
Dey, A. K. and Abowd, G. D. (2000). Towards a better un-
derstanding of context and context-awareness. In CHI
2000 Workshop on the What, Who, Where, When, and
How of Context-Awareness, The Hague, The Nether-
lands.
Harris, Z. (1954). Distributional structure. Word,
10(23):146–162.
Heinemann, L. and Hummel, B. (2011). Recommending api
methods based on identifier contexts. In Proceedings
of the 3rd International Workshop on Search-Driven
Development: Users, Infrastructure, Tools, and Eval-
uation, SUITE ’11, pages 1–4, New York, NY, USA.
ACM.
Henrich, A. and Morgenroth, K. (2003). Supporting collab-
orative software development by context-aware infor-
mation retrieval facilities. In 14th International Work-
shop on Database and Expert Systems Applications,
2003. Proceedings., pages 249 – 253.
Holmes, R. and Murphy, G. C. (2005). Using structural con-
text to recommend source code examples. In Proceed-
ings of the 27th international conference on Software
engineering, ICSE ’05, pages 117–125, New York,
NY, USA. ACM.
Jaccard, P. (1901).
´
Etude comparative de la distribution
florale dans une portion des Alpes et des Jura. Bul-
letin del la Soci
´
et
´
e Vaudoise des Sciences Naturelles,
37:547–579.
Kersten, M. and Murphy, G. C. (2006). Using task context
to improve programmer productivity. In Proceedings
of the 14th ACM SIGSOFT International Symposium
on Foundations of Software Engineering, pages 1–11,
Portland, Oregon, USA. ACM.
Mostefaoui, G. K., Pasquier-Rocha, J., and Brezillon, P.
(2004). Context-aware computing: A guide for the
pervasive computing community. In Proceedings of
the IEEE/ACS International Conference on Pervasive
Services, ICPS 2004, pages 39–48.
Parnin, C. and Gorg, C. (2006). Building usage contexts
during program comprehension. In Proceedings of
the 14th IEEE International Conference on Program
Comprehension (ICPC’06), pages 13–22.
Schilit, B. and Theimer, M. (1994). Disseminating ac-
tive map information to mobile hosts. IEEE Network,
pages 22–32.
Warr, F. W. and Robillard, M. P. (2007). Suade: Topology-
based searches for software investigation. In Proceed-
ings of the 29th international conference on Software
Engineering, ICSE ’07, pages 780–783, Washington,
DC, USA. IEEE Computer Society.
Ye, Y. and Fischer, G. (2002). Supporting reuse by de-
livering task-relevant and personalized information.
In Proceedings of the 24th International Conference
on Software Engineering, ICSE ’02, pages 513–523,
New York, NY, USA. ACM.
ICSOFT2012-7thInternationalConferenceonSoftwareParadigmTrends
484
