
Quantified Epistemic and Probabilistic ATL
Henning Schnoor
Institut f¨ur Informatik, Christian-Albrechts-Universit¨at zu Kiel, 24098 Kiel, Germany
Keywords:
ATL, Multi-agent systems, Epistemic Logic.
Abstract:
We introduce QAPI (quantified ATL with probabilism and incomplete information), which extends epistemic
and probabilistic ATL with a flexible mechanism to reason about strategies in the object language, allowing
very flexible treatment of the behavior of the “counter-coalition”. QAPI can express complex strategic proper-
ties such as equilibria. We show how related logics can be expressed in QAPI, provide bisimulation relations,
and study the issues arising from the interplay between quantifiers and both epistemic and temporal operators.
1 INTRODUCTION
ATL (Alternating-time temporal logic) (Alur et al.,
2002) is a logic to reason about strategic properties of
games. Its strategy operator hhAiiϕ expresses “there
is a strategy for coalition A to achieve ϕ.” We in-
troduce QAPI (quantified ATL with probabilism and
incomplete information), a powerful epistemic and
probabilistic extension of ATL with quantification of
and explicit reasoning about strategies. QAPI’s key
features are:
• Strategy Variables allow explicit reasoning about
strategies in the object language,
• A generalized Strategy Operator flexibly binds
the behavior of some coalitions to strategies,
while the remaining players exhibit standard ATL
“worst-case” behavior,
• Quantification of strategy variables expresses de-
pendence between strategies.
Existential quantification of strategies already ap-
pears as part of the hh.ii-operator of ATL, however
QAPI makes this more explicit and allows separat-
ing the quantification of a strategy and the reasoning
about it in the formulas. To this end, the logic can
reason directly about the effect of a coalition follow-
ing a strategy and express statements as “if coalition
A follows strategy s, then ϕ is true.”
QAPI properly includes e.g., ATL
∗
, strategy
logic (Chatterjee et al., 2007), ATLES (Walther et al.,
2007), (M)IATL (
˚
Agotnes et al., 2007), ATEL-R
∗
and
ATOL (Jamroga and van der Hoek, 2004). QAPI can
reason about equilibria and express that a coalition
knows a strategy to be successful. This requirement is
often useful, and is e.g., hard-coded into the strategy
definition in (Schobbens, 2004). In addition, QAPI
features probabilistic reasoning, i.e., can express that
events occur with a certain probability bound.
We illustrate QAPI’s advantages with an impor-
tant example. When evaluating hhAiiϕ in ATL, the
behavior of players not in A (we denote this “counter-
coalition” with A) is universally quantified: A must
succeed for every possible behavior of A. Hence A
has a strategy for ϕ only if such a strategy works even
in the worst-case setting where
•
A’s only goal is to stop A from reaching the goal,
• the players in A know A’s goal,
• A’s actions may depend on unknown information.
These issues are particularly relevant when play-
ers have incomplete information about the game.
Variants of ATL for this case were suggested in
e.g., (Jamroga, 2004; Schobbens, 2004; Jamroga and
van der Hoek, 2004; Herzig and Troquard, 2006;
Schnoor, 2010b). These logics restrict agents to
strategies that can be implemented with the available
information, but still require them to be successful
for every possible behavior of the counter-coalition.
Hence the above limitations still apply—for example,
“A can achieve ϕ against every strategy of A that uses
only information available to A” cannot be expressed.
QAPI’s direct reasoning about strategies provides
a flexible way to specify the behavior of all play-
ers, and in particular addresses the above-mentioned
shortcomings with a fine-grained specification of the
behavior of the “counter-coalition” A. For example,
the following behaviors of A can be specified:
•
A continues a strategy for their own goal—i.e., A
14
Schnoor H..
Quantified Epistemic and Probabilistic ATL.
DOI: 10.5220/0004189300140023
In Proceedings of the 5th International Conference on Agents and Artificial Intelligence (ICAART-2013), pages 14-23
ISBN: 978-989-8565-39-6
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

is unaware of (or not interested in) what A does,
• A follows a strategy tailor-made to counteract the
goal ϕ, but that can be implemented with informa-
tion available to A—here A reacts to A with “real-
istic” capabilities, i.e., strategies based on infor-
mation actually available to A,
• A plays an arbitrary sequence of actions, which
does not have to correspond to an implementable
strategy—this is the pessimistic view of the logics
mentioned above: A must be successful against
every possible behavior of the players in A.
As we will show, detailed reasoning about the
counter-coalition is only one advantage of QAPI. Our
results are as follows:
1. We prove that QAPI has a natural notion of bisim-
ulation which is more widely applicable than the
one in (Schnoor, 2010b), even though QAPI is
considerably more expressive. In particular, our
definition can establish strategic and epistemic
equivalence between finite and infinite structures.
2. We discuss the effects of combining quantifica-
tion, epistemic, and temporal operators in detail.
The combination of these operators can lead to
unnatural situations, which motivate the restric-
tion of QAPI to infix quantification.
3. We prove complexity and decidability results for
model checking QAPI. In the memoryless case
QAPI’s added expressiveness compared to ATL
∗
comes without significant cost: The complexity
ranges from PSPACE to 3EXPTIME for games
that are deterministic or probabilistic. Hence the
deterministic case matches the known PSPACE-
completeness for ATL
∗
with memoryless strate-
gies (Schobbens, 2004). As expected, the prob-
lem is undecidable in the perfect-recall case.
Related Work. We only mention the most closely
related work (in addition to the papers mentioned
above) from the rich literature. QAPI is an exten-
sion of the ATL
∗
-semantics introduced in (Schnoor,
2010b), and utilizes the notion of a strategy choice
introduced there. In this paper, we extend the seman-
tics and the results of (Schnoor, 2010b) by the use of
strategy variables, quantification, and explicit strategy
assignment, which lead to a much richer language.
In particular, the semantics in (Schnoor, 2010b) does
not handle negation of the strategy operator in a sat-
isfactory way in the incomplete-information setting.
Further, our notion of a bisimulation is much more
general than the one suggested in (Schnoor, 2010b).
QAPI’s approach of allowing first-order like quan-
tification of strategies is very similar to the treat-
ment of strategies in strategy logic (Chatterjee et al.,
2007). However, the combination of epistemic as-
pects and quantification reveals some surprising sub-
tleties, which we discuss in Section 4, and to the best
of our knowledge, there are no results on bisimula-
tions for strategy logic.
Relaxations of ATL’s universal quantification
over the counter-coalition’s behavior were studied
in (
˚
Agotnes et al., 2007; Walther et al., 2007) for
the complete-information case. In (Schnoor, 2012),
QAPI is used to specify strategic and epistemic prop-
erties of cryptographic protocols, the bisimulation re-
sults from the present paper are used to obtain a pro-
tocol verification algorithm.
All proofs can be found in the technical re-
port (Schnoor, 2010a).
2 Syntax and Semantics of QAPI
2.1 Concurrent Game Structures
We use the definition of concurrent game struc-
tures from (Schnoor, 2010b), which extends the
one from (Alur et al., 2002) with probabilistic (see
also (Chen and Lu, 2007)) and epistemic aspects (see
also (Jamroga and van der Hoek, 2004)):
Definition 1. A concurrent game structure (CGS) is a
tuple C = (Σ, Q, P, π, ∆,δ, eq), where
• Σ and P arefinite sets of players and propositional
variables, Q is a (finite or infinite) set of states,
• π: P → 2
Q
is a propositional assignment,
• ∆ is a move function such that ∆(q, a) is the set
of moves available at state q ∈ Q to player a ∈ Σ.
For A ⊆ Σ and q ∈ Q, an (A, q)-move is a function
c such that c(a) ∈ ∆(q, a) for all a ∈ A.
• δ is a probabilistic transition function which for
each state q and (Σ, q)-move c, returns a discrete
1
probability distribution δ(q, c) on Q (the state ob-
tained when in q, all players perform their move
as specified by c),
• eq is an information function eq : {1, . .. , n} ×
Σ → P (Q× Q), where n ∈ N and for each i ∈
{1, . .. , n} and a ∈ Σ, eq(i, a) is an equivalence
relation on Q. We also call each i ∈ {1, . . . , n} a
degree of information.
Moves are merely “names for actions” and only
havemeaning in combination with the transition func-
tion δ. A subset A ⊆ Σ is a coalition of C . We
leave out “of C ” when C is clear from the context,
omit set brackets for singletons, etc. The coalition
Σ\ A is denoted with A. We write Pr(δ(q, c) = q
′
) for
1
A probability distribution Pr on Q is discrete, if there is
a countable set Q
′
⊆ Q such that
∑
q∈Q
′ Pr(q) = 1.
QuantifiedEpistemicandProbabilisticATL
15

(δ(q, c)) (q
′
), i.e., consider δ(q, c) as a random vari-
able on Q. The function eq expresses incomplete in-
formation: It specifies pairs of states that a player
cannot distinguish. By specifying several relations
eq(1, a), . . . , eq(n, a) for each player, we can specify
how much information a player may use to reach a
certain goal. This is useful e.g., in security defini-
tions (Cortier et al., 2007; Schnoor, 2012).
C is deterministic if all distributions δ(q, c) assign
1 to one state and 0 to all others, C has complete in-
formation if eq(i, a) is always the equality relation.
2.2 Strategies, Strategy Choices,
and Formulas
The core operator of QAPI is the strategy operator:
hhA : S
1
, B : S
2
ii
≥α
i
ϕ expresses “if coalition A fol-
lows S
1
and B follows S
2
, where both coalitions base
their decisions only on information available to them
in information degree i, the run of the game satisfies
ϕ with probability ≥ α, no matter what players from
A∪ B do.” Here, S
1
and S
2
are variables for strat-
egy choices which generalize strategies (see below).
While similar to the ATL-operator hh.ii, the strategy
operator is much more powerful: It allows to flexibly
find a strategy to a coalition. This allows, for exam-
ple, to model that a coalition commits to a strategy (in
ATL
∗
, a strategy is revoked when the hh.ii-operator is
nested) and much more (see examples below).
Definition 2. Let C be a CGS with n degrees of in-
formation. Then the set of strategy formulas for C is
defined as follows:
• A propositional variable of C is a state formula,
• conjunctions and negations of state (path) formu-
las are state (path) formulas,
• every state formula is a path formula,
• if A
1
, . .., A
m
are coalitions, 1 ≤ i ≤ n, 0 ≤ α ≤
1, and ◭ is one of ≤, <, >, ≥, and ψ is a path
formula, and S
i
is an A
i
-strategy choice variable
for each i, then hhA
1
: S
1
, . . . , A
m
: S
m
ii
◭α
i
ψ is a
state formula,
• if A is a coalition, 1 ≤ i ≤ n, ψ is a state formula,
and k ∈ {D, E,C} then K
k
A,i
ψ is a state formula,
• If ϕ
1
and ϕ
2
are path formulas, then Xϕ
1
, Pϕ
1
,
X
−1
ϕ
1
, and ϕ
1
Uϕ
2
are path formulas.
The values D, E, and C indicate different notions
of knowledge, namely distributed knowledge, every-
body knows, and common knowledge. We use stan-
dard abbreviations like ϕ ∨ ψ = ¬(¬ϕ ∧ ¬ψ), ♦ϕ =
true Uϕ, and ϕ = ¬♦¬ϕ. A hh.ii-formula is one
whose outmost operator is the strategy operator. In
a CGS with only one degree of information, we omit
the i subscript of the strategy operator; in a determin-
q
0
q
0
1
q
0
2
q
0
ok
q
0
ok
q
1
1
q
1
2
q
1
ok
q
1
ok
ok
ok
ok
ok
b:0
a:0
a:1
b:1
a:1
a:0
Figure 1: Strategy choices.
istic CGS we omit the probability bound ◭ α (and
understand it to be read as ≥ 1). Quantified strategy
formulas are strategy formulas in which the appearing
strategy choice variables are quantified:
Definition 3. Let C be a CGS, let ϕ be a strategy
formula for C such that every strategy choice variable
appearing in ϕ is one of S
1
, ..., S
n
. Then
∀S
1
∃S
2
∀S
3
. . . ∃S
n
ϕ
is a quantified strategy formula for C .
Requiring a strict ∀∃. . . -alternation is without loss
of generality and can be obtained via dummy vari-
ables. On the other hand, allowing quantification only
in the prefix is a deliberate restriction of QAPI, the
reasons for which we discuss in detail in Section 4.
Definition 4. For a player a, an a-strategy in a CGS
C = (Σ, Q, P, π, ∆, δ, eq) is a function s
a
with s
a
(q) ∈
∆(q, a) for each q ∈ Q. For an information degree i,
s
a
is i-uniform if q
1
∼
eq
i
(a)
q
2
implies s
a
(q
1
) = s
a
(q
2
).
For A ⊆ Σ, an A-strategy is a family (s
a
)
a∈A
, where
each s
a
is an a-strategy.
Our strategies are memoryless: A move only de-
pends on the current state, not on the history of the
game. With incomplete information, the question
how players can identify suitable strategies is relevant.
Consider the CGS in Figure 1. The players are a and
b, the game starts in q
0
. The first move by b controls
whether the next state is q
0
1
or q
1
1
. For x ∈ {0, 1}, q
x
1
is always followed by q
x
2
. In q
x
2
, the move 0 leads to
a state satisfying ok iff x = 0; move 1 is successful iff
x = 1. Player a cannot distinguish q
0
2
and q
1
2
. We ask
whether he has a strategy leading to ok that is suc-
cessful started in both q
0
1
and q
1
1
. If a can only use
strategies, he must play the same move in q
0
2
and in
q
1
2
, and thus fails in one of them. However, if a can
decide on a strategy and remember this decision, the
player can choose in q
0
1
(q
1
1
) a strategy playing 0 (1)
in every state, and be successful.
ICAART2013-InternationalConferenceonAgentsandArtificialIntelligence
16

Strategy choices (Schnoor, 2010b) formalize how
a player chooses a strategy, and distinguish between
states where a strategy is identified and where it is ex-
ecuted: In state q
0
1
or q
1
1
, player a uses his information
to choose the strategy that he follows from then on.
When using only strategies, the knowledge has to be
present at the time of performing a move. Hence strat-
egy choices give players additional capabilities over
the pure memoryless setting, by allowing to remem-
ber decisions. In contrast to the perfect recall case,
where players remember the entire run of a game,
there is no significant computational price, whereas
perfect recall makes the model checking problem un-
decidable (cp. Section 6).
Definition 5. A strategy choice for a coalition A in a
CGS C = (Σ, Q, P, π, ∆, δ, eq) is a function S such that
for each a ∈ A, q ∈ Q, each hh.ii
i
-formula ϕ, S(a, q, ϕ)
is an i-uniform a-strategy in C , and if q
1
∼
eq
i
(a)
q
2
,
then S(a, q
1
, ϕ) = S(a, q
2
, ϕ).
In the definition of a strategy choice, syntax and
semantics meet, since one input to a strategy choice
is the goal a coalition is supposed to achieve—such a
goal is best specified with a formula. The formula also
specifies the coalition working together to achieve the
goal. For a coalition A, and a strategy choice S for A,
the strategy chosen for A by S in a state q to reach the
goal ϕ is the A-strategy (s
a
)
a∈A
with s
a
= S(a, q, ϕ)
for each a. We denote this strategy with S(A, q, ϕ).
Strategy choices model the decision of a single player
to use a certain strategy. For coalitions, they model
strategies agreed upon before the game for possible
goals. This allows their members to predict the each
other’s behavior without in-game communication. As
mentioned above, the crucial point is that strategy
choices distinguish between states where a strategy
is identified and where it is executed: In state q
0
1
or q
1
1
of the above example, player a uses his information to
choose a strategy which he then follows. When using
only strategies, the knowledge has to be present at the
time of playing a move. A strategy choice hence al-
lows players to “remember” previous decisions. For
coalitions, it models prior agreement helpful in e.g.,
coordination games.
The strategy operator binds the behavior of the
players in the appearing coalitions to the strategies
specified by the assigned strategy choices (see below).
The remaining players (the “counter-coalition”) are
treated as “free agents” in QAPI: Every possible be-
havior of these players is taken into account. Such a
behavior may not even follow any strategy, for exam-
ple they may perform different moves when encoun-
tering the same state twice during the game. This is
formalized as a response (cp. (Schnoor, 2010b)) to a
coalition A, which is a function r such that r(t, q) is
a (A, q)-move for each t ∈ N and each q ∈ Q. This
models an arbitrary reaction to the outcomes of an A-
strategy: In the i-th step of a game, A performs the
move r(i, q), if the current state is q.
When a coalition A follows the strategy s
A
, and the
behavior of A is defined by the response r, the moves
of all players are fixed; the game is a Markov pro-
cess. This leads to the following definition of “suc-
cess probability.” A path in a CGS C is a sequence
λ = λ[0]λ[1] . . . of states of C .
Definition 6. Let C be a CGS, let s
A
be an A-strategy,
let r be a response to A. For a set M of paths over C ,
and a state q ∈ Q, Pr(q → M | s
A
+ r) is the proba-
bility that in the Markov process resulting from C , s
A
,
and r with initial state q, the resulting path is in M.
A key feature of QAPI is the flexible binding of
strategies to coalitions, which is done using the strat-
egy operator. As a technical tool to resolve possi-
ble ambiguities, we introduce a “join” operation on
strategy choices: If the coalitions A
1
, ..., A
n
follow
strategy choices S
1
, ..., S
n
, the resulting “joint strat-
egy choice” for A
1
∪ · ·· ∪ A
n
is S
1
◦ ·· · ◦ S
n
. This is a
“union” of the S
i
with a tie-breaking rule for players
appearing in several of the coalitions: These always
follow the “left-most” applicable strategy choice. We
define the (associative) operator ◦ as follows:
S
1
◦ S
2
(a, q, ϕ) =
(
S
1
(a, q, ϕ), if a ∈ A
1
,
S
2
(a, q, ϕ), if a ∈ A
2
\ A
1
.
This definition ensures that if a coalition A
1
∪·· ·∪
A
n
is instructed to follow the strategy choice S
1
◦ ··· ◦
S
n
, then evenif A
i
∩A
j
6=
/
0, for each agent the strategy
choice to follow is well-defined.
2.3 Evaluating Formulas
In the same manner as the syntax, we also define
QAPI’s semantics in two stages: We first handle strat-
egy formulas, where instantiations for the appearing
strategy choice variables are given. This naturally
leads to the semantics definition for quantified for-
mulas. Our semantics is very natural: Propositional
variables and operators are handled as usual, tempo-
ral operators behave as in linear-time temporal logic,
and hhA
1
: S
1
, . . . , A
n
: S
n
ii
≥α
i
ψ expresses that when
coalitions A
1
, . .., A
n
follow the strategy choices S
1
,
.. ., S
n
with information degree i available, the for-
mula ψ is satisfied with probability ≥ α. The knowl-
edge operator K models group knowledge, see below.
Definition 7. Let C = (Σ, Q, P, π, ∆, δ, eq) be a CGS,
let
−→
S = (S
1
, ..., S
n
) be a sequence of strategy choices
QuantifiedEpistemicandProbabilisticATL
17

instantiating
2
the strategy choice variables S
1
, ...,
S
n
. Let ϕ be a state formula, let ψ
1
, ψ
2
be path for-
mulas, let λ be a path over Q, let t ∈ N. We define
• C ,
−→
S , q |= p iff q ∈ π(p) for p ∈ P,
• conjunction and negation are handled as usual,
• (λ, t),
−→
S |= ϕ iff C ,
−→
S , λ[t] |= ϕ,
• (λ, t),
−→
S |= Xψ
1
iff (λ,t + 1),
−→
S |= ψ
1
,
• (λ, t),
−→
S |= Pψ
1
iff there is some t
′
≤ t and
(λ,t
′
),
−→
S |= ψ
1
,
• (λ, t),
−→
S |= X
−1
ψ
1
iff t ≥ 1 and (λ,t − 1),
−→
S |=
ψ
1
,
• (λ, t),
−→
S |= ψ
1
Uψ
2
iff there is some i ≥ t such that
(λ, i),
−→
S |= ψ
2
and (λ, j),
−→
S |= ψ
1
for all t ≤ j < i,
• If k ∈ {D, E,C}, then C ,
−→
S , q |= K
k
A,i
ϕ iff
C ,
−→
S , q
′
|= ϕ for all q
′
∈ Q with q ∼
k
A,i
q
′
(see be-
low),
• C ,
−→
S , q |= hhA
i
1
: S
i
1
, . . . , A
i
m
: S
i
m
ii
◭α
i
ψ
1
| {z }
=:ϕ
1
iff for
every response r to A
i
1
∪ · ·· ∪ A
i
m
, we have
Pr
q →
n
λ | (λ, 0),
−→
S |= ψ
1
o
|
S
i
1
◦ ·· · ◦ S
i
m
(A
i
1
∪ · ·· ∪ A
i
m
, q, ϕ
1
) + r) ◭ α.
The relations ∼
D
A,i
, ∼
E
A,i
, and ∼
C
A,i
referenced in
Definition 7 represent different possibilities to model
group knowledge. For a coalition A and an informa-
tion degree i, they are defined as follows:
• ∼
D
A,i
= ∩
a∈A
eq(i, a) expresses distributed knowl-
edge: K
D
A,i
ϕ is true if ϕ can be deduced from the
combined knowledge of every member of A (with
respect to information degree i),
• ∼
E
A,i
= ∪
a∈A
eq(i, a) models everybody knows:
K
E
A,i
ϕ is true if every agent in A on his own has
enough information to deduce that ϕ holds (with
respect to information degree i),
• ∼
C
A,i
is the reflexive, transitive closure of ∼
E
A,i
.
This models common knowledge: K
C
A,i
ϕ expresses
that (in A, with information degree i), everybody
knows that ϕ is true, and everybody knows that
everybody knows that ϕ is true, ..., etc.
These concepts have proven useful to express the
knowledge of a group. See (Halpern and Moses,
1990) for detailed discussion.
For quantified formulas, we define:
Definition 8. Let C be a CGS, let ψ =
∀S
1
∃S
2
∀S
3
. . . ∃S
n
ϕ be a quantified strategy for-
mula for C , let q be a state of C . Then ψ is satisfied
2
I.e., if S
i
is an A-strategy choice variable for some
coalition A, then S
i
is a strategy choice for A.
in C at q, written C , q |= ψ, if for each i ∈ {2, 4, . . . n},
there is a function s
i
such that for all strategy choices
S
1
, S
3
, ..., S
n−1
, if S
i
is defined as s
i
(S
1
, . . . , S
i−1
)
for even i, then C , (S
1
, . . . , S
n
), q |= ϕ.
Constant strategy choices (which only depend on
the player, not on the state or the formula) are essen-
tially strategies. We introduce quantifiers ∃
c
and ∀
c
quantifying over constant strategy choices.
2.4 MQAPI
MQAPI (Memory-enabled QAPI), is QAPI with per-
fect recall. The semantics can be defined in the
straight-forward way by encoding history in the states
of a system, see, e.g.,(Schnoor, 2010b).
3 Examples
3.1 Restricted Adversaries
The following expresses “A can achieve ϕ against ev-
ery uniform strategy of A:”
∃S
1
∀S
2
A : S
1
, A : S
2
1
ϕ.
This is weaker than ∃S
1
hhA : S
1
ii
1
ϕ: In the latter,
A is not restricted to any strategy at all, while in the
former, A has to follow a uniform strategy.
3.2 Sub-coalitions Changing Strategy
Often, when a coalition A
′
( A changes the strategy,
they rely on A\ A
′
to continue the current one. As-
sume that A works together to reach a state where
A
′
( A has strategies for ϕ
1
and ϕ
2
, if players in A\A
′
continue their earlier strategy. We express this as
∃
c
S
A
∃S
A
′
hhA : S
A
ii
1
♦( hhA
′
: S
A
′
, A : S
A
ii
1
♦ϕ
1
∧ hhA
′
: S
A
′
, A : S
A
ii
1
♦ϕ
2
).
This expresses that A uses a fixed strategy and
does not change behavior depending on whether A
′
attempts to achieve ϕ
1
or ϕ
2
. In particular, A\ A
′
does
not need to know which of these goals A
′
attempts to
achieve. We use the same strategy choice for ϕ
1
and
ϕ
2
to require A
′
to identify the correct strategy with
the available information.
3.3 Knowing whether a Strategy is
Successful
The following expresses “there is an A-strategy such
that there is no B-strategy such that the coalitionC can
know that its application successfully achieves ϕ:”
∃
c
S
A
∀
c
S
B
¬K
C
hhA : S
A
, B : S
B
ii
1
ϕ.
ICAART2013-InternationalConferenceonAgentsandArtificialIntelligence
18
This is very different from expressing that A has
a strategy preventing ϕ, i.e., ∃S
A
hhA : S
A
ii
1
¬ϕ, since
(i) There may be a successful strategy for B, but not
enough information for C to determine that it is suc-
cessful, (ii) the goal ϕ may still be reachable if B does
not follow a (uniform) strategy.
3.4 Winning Secure Equilibria (WSE)
If player a (b) has goal ϕ
a
(ϕ
b
), a WSE (Chatterjee
et al., 2006) is a pair of strategies (s
a
, s
b
) such that
both goals are achieved when a and b play s
a
and s
b
,
and if b plays such that ϕ
a
is not reached anymore, but
a still follows s
a
, then b’s goal ϕ
b
is also not satisfied
anymore (same for player a). QAPI can express this
as follows: Both goals are reached if (s
a
, s
b
) is played,
and neither player can reach his goal without reaching
that of the other player as well, if the latter follows the
WSE strategy.
∃
c
S
a
∃
c
S
b
hha : S
A
, b : S
B
ii
1
(ϕ
a
∧ ϕ
b
)
∧ hha : S
A
ii
1
(ϕ
b
→ ϕ
a
)
∧ hhb : S
B
ii
1
(ϕ
a
→ ϕ
b
).
3.5 Expressing ATEL-R
∗
and ATOL
ATOL (Jamroga and van der Hoek, 2004) requires
identifying strategies with the agent’s knowledge.
ATOL’s key operator is defined as follows (right-hand
side in our notation)—in the following, A is the coali-
tion playing, and Γ the one identifying the strategy:
C , q |= hhAii
K (Γ)
ϕ iff there is a constant strat-
egy choice S
A
such that for all q
′
∈ C with
q
′
∼
Γ
q, we have that C , q
′
|= hhA : S
A
ii
1
ϕ.
The above can be translated into QAPI by writing
C , q
′
|= K
Γ
hhA : S
A
ii
1
ϕ,
where S
A
’s quantification depends on the par-
ity of negation and is restricted to constant strategy
choices.
3
In (Jamroga and van der Hoek, 2004), it is
stated that requiring “Γ knows that A has a strategy
to achieve ϕ” is insufficient to express hhAii
K (Γ)
ϕ. It
suffices in QAPI since we quantify S
A
before the K -
operator, hence Γ knows that the fixed A-strategy is
successful. ATEL-R
∗
would quantify the strategy af-
ter the K -operator in a formula like K
Γ
hhAiiϕ: A
could choose a different strategy in each state. ATEL-
R
∗
(ATOL with recall) can be expressed in MQAPI
analogously. The above highlights the usefulness
3
It is not sufficient to rely on the uniformity of strat-
egy choices (the same strategy must be chosen in A-
indistinguishable states), since there must be a single strat-
egy that is successful in all Γ-indistinguishable states, and
Γ might have less information than A.
q
0
q
2
q
1
q
4
q
3
p
p
1
0
0
1
Figure 2: Infix quantification example.
of QAPI’s ability to directly reason about strategy
choices. Strategy logic (Chatterjee et al., 2007),
ATLES (Walther et al., 2007), and (M)IATL (
˚
Agotnes
et al., 2007) can be expressed similarly.
4 QUANTIFICATION AND
EPISTEMIC/TEMPORAL
OPERATORS
We now study the interplay between quantifiers and
temporal or epistemic operators: Applying quantifiers
in the scope of epistemic or temporal operators often
leads to highly counter-intuitive behavior. This be-
havior is the reason why QAPI only allows quantifi-
cation in a quantifier block prefixing the formula. The
issues we demonstrate here are not specific to QAPI
or the concept of strategy choices, but are general ef-
fects that arise in any formalism combining the oper-
ators we discuss here with some mechanism of forc-
ing agents to “know” which strategy to apply. The
core issue is that an unrestricted ∃-quantifier adds a
high degree of non-uniformity to the agent’s choices,
which is incompatible with the epistemic setting.
To demonstrate these issues, in this section, we
consider QAPI
infix
, which is QAPI with arbitrary nest-
ing of quantifiers and other operators. The semantics
is defined by applying quantification in every state in
the obvious way. Clearly, quantification can always
be pulled outside of the scope of propositional and
♦-operators. The remaining temporal and epistemic
operators cannot be handled so easily.
QuantifiedEpistemicandProbabilisticATL
19

4.1 Quantification in the Scope of
Temporal Operators
Consider the following QAPI
infix
-formula:
A∃S
A
hhA : S
A
ii
≥1
1
ψ.
The quantifier A abbreviates ∃S
/
0
hh
/
0 : S
/
0
ii
≥1
1
and
expresses quantification over all reachable paths (es-
sentially A is CTL’s A-operator). The formula ex-
presses that in all reachable states, there is a strategy
choice for A that accomplishes ψ. There are no uni-
formity or epistemic constraints on the ∃-quantifier:
Even in states that look identical for all members of A,
completely different strategy choices can be applied.
This is problematic in an epistemic setting: Consider
the CGS with two players a and b in Figure 2. We
only indicate the moves of player a. The game is turn-
based, where it is b’s turn in the state q
0
and a’s turn
in the remaining states. The first action of b chooses
whether the next state is q
1
or q
2
, these two states are
indistinguishable for a. In q
1
, player a must play 0 to
reach a state where p holds, in state q
2
, a must play 1
to achieve this. Now consider the following formula
(we consider the coalition A = {a}):
AX∃S
A
hhA : S
A
ii
≥1
1
p.
This formula is true in q
0
: In both possible follow-
up states, there is a strategy choice that allows player
a to enforce that p is true in the next state: In q
1
(q
2
),
we choose a strategy choice S
1
that for every possi-
ble goal and in every state always plays the move 0
(1). Individually, these strategy choices satisfy every
imaginable uniformity condition, since they fix one
move forever. However, intuitively in q
1
, player a
cannot achieve Xp, since a cannot identify the cor-
rect strategy choice to apply. This shows that having
an existential quantifier in the scope of a temporal op-
erator yields counter-intuitive results.
A natural way to address this problem is to re-
strict quantification to be “uniform” and demand that
the quantifier chooses the same strategy choice in the
states indistinguishable for A. We can express this
in QAPI
infix
by requiring that the strategy choice “re-
turned” by the quantifier is successful in all indistin-
guishable states—in other words, requiring A to know
that the strategy choice is successful. In this case, the
same strategy choice can be used in all indistinguish-
able states as intended. In the above example, we
therefore would consider the following formula (for
singleton-coalitions, all notions of knowledge coin-
cide, we use common knowledge in the example):
AX∃S
A
K
C
A,1
hhA : S
A
ii
≥1
1
p.
If we follow the above suggestion and always
combine existential quantification with requiring the
knowledge that the introduced strategy choice accom-
plishes its goal, the behavior is much more natural—
however, as we now demonstrate, these are exactly
the cases which already can be expressed in QAPI.
To do this, we need to decide on a suitable no-
tion of group knowledge to apply in formulas of the
above structure. If we use distributed knowledge, we
essentially allow coordination inside the coalition A
as part of the existential quantifier. This is similar to
the behavior of ATL/ATL
∗
, where the hh.ii-operator
also allows coordination. Hence distributed knowl-
edge does not achieve the desired effect. However,
everyone knows and common knowledge do not suf-
fer from these issues: In both cases, each agent on
his own can determine whether the current strategy
“works.” We now show that this intuition is supported
by formal arguments: In the case of everyone knows
or common knowledge, the existential quantifier can
indeed be exchanged with the operator, the same
does not hold for distributed knowledge.
Proposition 9. Let ϕ be a formula in which the vari-
able S
A
does not appear, and which does not use past-
time operators, and let k ∈ {E,C}. Then
∃S
A
K
k
A,i
hhA : S
A
ii
≥α
i
ϕ ≡ ∃S
A
K
k
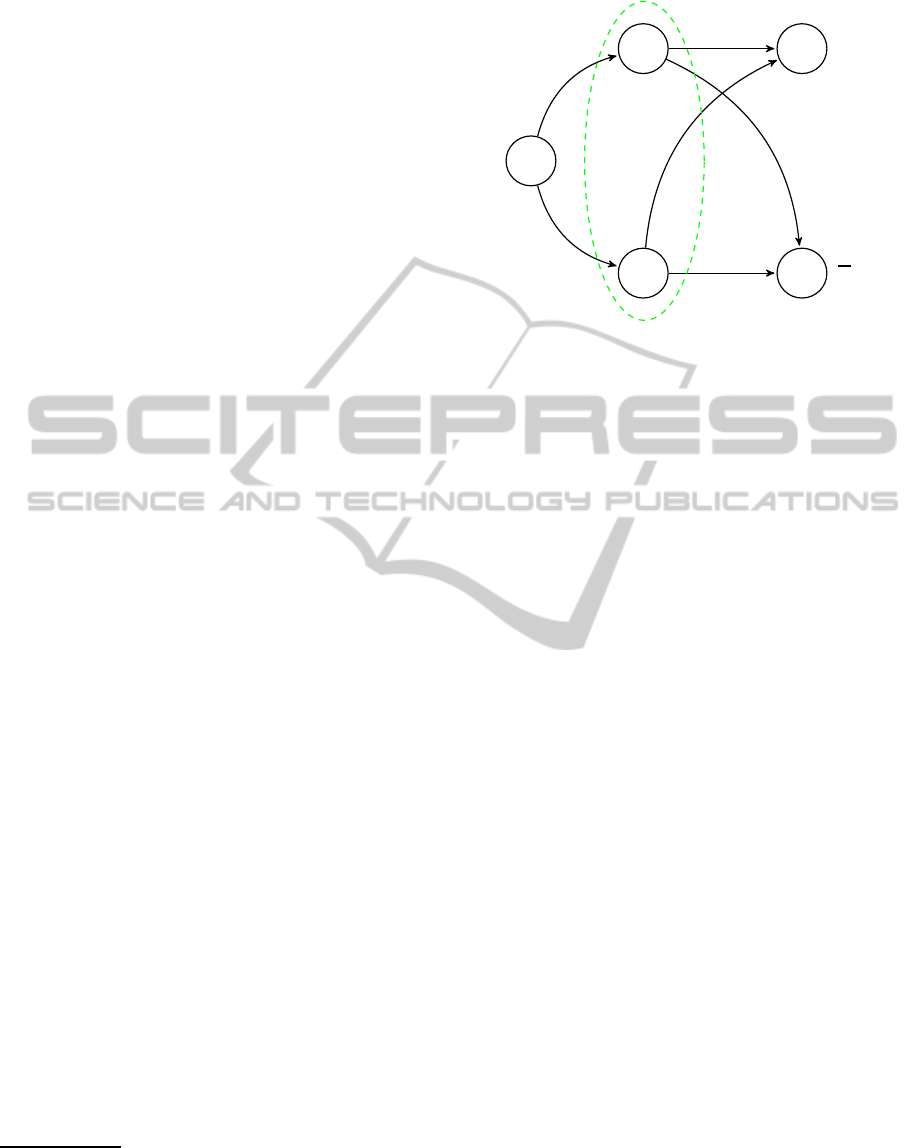
A,i
hhA : S
A
ii
≥α
i
ϕ.
We require that ϕ does not contain S
A
, since the
idea of the above discussion is the direct coupling
of the existential quantification of S
A
and the group
knowledge about the effects of its application. Re-
quiring that ϕ does not have past-time operators is
clearly crucial for memoryless strategies: If ϕ, e.g.,
requires to play a specific move if and only if that
move has been played previously, then the strategy
choice clearly must depend on the history and the
above equivalence does not hold. Proposition 9 does
not hold for distributed knowledge instead:
Example 10. Consider a CGS C with players a and
b and two Boolean variables x and y, where player a
(b) only sees the value of variable x (y) and the val-
ues of the variables change randomly in every tran-
sition. Each player always has the moves 0 and 1
available. Consider the coalition A = {a, b} and the
formula ϕ expressing “a moves according to y and b
moves according to x”
4
Since the distributed knowl-
edge of A allows to identify the values of both x
and y, in each state there is a strategy choice achiev-
ing ϕ, however clearly there is no single strategy
choice which works in all states. Hence, the formula
∃S
A
K
D
A,1
hhA : S
A
ii
≥1
1
ϕ is always true in C , while
∃S
A
K
D
A,1
hhA : S
A
ii
≥1
1
ϕ is always false.
4
To express this as a variable, the CGS needs to record
the last move of each player in the state in the obvious way.
ICAART2013-InternationalConferenceonAgentsandArtificialIntelligence
20

Proposition 9 can be generalized in several di-
rections. For ease of presentation we only present
the above simple form of Proposition 9 which sup-
ports the main argument of this section: “Intuitively
sensible” applications of quantifications inside -
operators can be eliminated.
4.2 Quantification in the Scope
of Epistemic Operators
We now show that quantification in the scope of epis-
temic operators leads to similar issues as the case of
temporal operators considered above. We again con-
sider the CGS in Figure 2. In q
0
, the formula
AXK
d
A,1
∃S
A
hhA : S
A
ii
≥1
1
Xp
is true: Agent a (who alone forms the coalition A)
knows that there is a successful strategy choice, since
there is one in both q
1
and in q
2
. However, as seen
above, he does not know this strategy choice.
We now present a similar result to Proposition 9,
for quantification in the scope of epistemic operators,
and identify cases in which these operators commute.
For this, we exhibit a “maximal” class of formulas for
which knowledge and quantification can always be
exchanged. When discussing whether quantification
of a variable S
i
commutes with an operator (epistemic
or otherwise), clearly we are only interested in formu-
las in which the variable S
i
actually plays a non-trivial
role. To formalize this, we extend the concept of a
“relevant” variable which is well-known in proposi-
tional logic, to the class of strategy variables:
Definition 11. Let ϕ be a formula with free strat-
egy variables among {S
1
, . . . , S
n
}. We say that
the variable S
i
is relevant for ϕ if there exists
a CGS C , a state q of C , and strategy choices
S
1
, . . . , S
n
, S
′
i
such that C , (S
1
, . . . , S
n
), q |= ϕ and
C , (S
1
, . . . , S
i−1
, S
′
i
, S
i+1
, . . . , S
n
), q 6|= ϕ.
This means that there exists a situation where it
matters which strategy choice is used to instantiate the
variable S
i
. Examples for an irrelevant variable S
A
are
hhA : S
A
ii
≥1
i
(♦x∨ ¬x) or hhA : S
A
ii
≥0
i
♦x.
Definition 12. For a coalition A and a degree of in-
formation i, k ∈ {D, E,C}, a formula ϕ is k-i-simple
in S
A
, if one of the following conditions is true:
• S
A
is an irrelevant variable of ϕ, or
• ϕ is equivalent to a formula of the form K
k
A,i
ψ.
Formulas that are k-i-simple give a “natural” se-
mantics when prefixed with an existential quantifier,
since in the same way as there, the non-uniformity
of the existential quantifier is reduced using the epis-
temic operator. We now show that in these cases, infix
quantification again is not necessary, as here, the ex-
istential and the epistemic operators commute:
Lemma 13. If ϕ is k-i-simple and has a single free
strategy variable, then for all CGS C and states q,
C , q |= K
k
A,i
∃s
A
ϕ if and only if C , q |= ∃s
A
K
k
A,i
ϕ.
This class of formulas is maximal—as soon as we
have a formula that depends on the variables S
A
and
of which A’s knowledge does not suffice to determine
the truth, we cannot swap the above operators.
Proposition 14. Let ϕ be a formula such that ϕ is not
k-i-simple in S
A
and the coalition A is bound to S
A
in
the entire formula, then ∃S
A
K
k
A,i
ϕ 6≡ K
k
A,i
∃S
A
ϕ.
The prerequisite that A is bound to S
A
in the en-
tire formula is necessary to e.g., preclude cases where
S
A
is only used in a non-meaningful way. It is not
a strong requirement, as (with infix quantification)
usually the subformula directly succeeding the exis-
tential quantifier will be the one “talking about” the
quantified strategy choice. It is possible to strengthen
Proposition 14, howeveragain the simple form here is
suffices to show that in the cases where quantification
in the scope of an epistemic operator gives a satis-
factory semantics, the quantifier can be moved out of
scope of that operator, and hence QAPI suffices.
4.3 Discussion
Nesting of quantification and epistemic or temporal
operators leads to counter-intuitive behavior, since
quantification introduces a degree of non-uniformity,
whereas a core issue in the epistemic setting is to en-
force sufficient uniformity to ensure that agents have
enough knowledge to decide on the “correct” move to
play in every situation. Although we did not give a
complete characterization of the cases in which tem-
poral/epistemic operators and quantifiers commute
and it is notoriously difficult to give a good defini-
tion of a “natural” semantics, our results give strong
evidence for our claim: In the cases where infix quan-
tification leads to a natural semantics, the quantifiers
can be swapped with the temporal/epistemic opera-
tors, hence infix quantification is unneeded.
Another reason why QAPI only allows quantifiers
in the prefix of a formula is that in the presence of
strategy choices, infix quantification does not seem
to be particularly useful: Quantification of strategies
that may be different in any state can be handled by
strategy choices in a way that is compatible with the
epistemic setting, since strategy choices may return
different strategies in states that are distinguishable
for an agent. On the other hand, infix quantification
of strategy choices is very unnatural: Strategy choices
QuantifiedEpistemicandProbabilisticATL
21
express “global behavior” of coalitions allowing prior
agreement, but during the game only rely on commu-
nication that is part of the game itself. Quantification
inside formulas would express “prior agreement” dur-
ing the game, which defeats its purpose.
There may be interesting properties that can only
be expressed using QAPI
infix
, but usuallyz QAPI is
sufficient and avoids the above problems.
5 SIMULATIONS
Bisimulations relate structures in a truth-preserving
way. They allow to obtain decidability results for
game structures with infinite state spaces (if a bisimi-
lar finite structure exists), or can reduce the state space
of a finite system. In (Schnoor, 2012), our bisimula-
tion results are used to obtain a model-checking al-
gorithm on an infinite structure by utilizing a bisim-
ulation between this structure and a finite one. We
give the following definition, which is significantly
less strict than the one in (Schnoor, 2010b): For ex-
ample, our definition can establish bisimulations be-
tween structures with different numbers of states (see
example below). This is not possible in the defini-
tion from (Schnoor, 2010b), since there a bisimula-
tion is essentially a relation Z which is a simulation
in both directions simultaneously. Since a simulation
in the sense of (Schnoor, 2010b) is a function be-
tween state spaces, this implies that Z must contain,
for every state in one CGS, exactly one related state
in the other. Hence such a Z induces a bijection be-
tween state spaces, and is essentially an isomorphism.
The following definition is somewhat simplified to in-
crease readability, it only treats game structures that
have a single degree of information, which is there-
fore omitted here.
Definition 15. Let C
1
and C
2
be CGSs with state sets
Q
1
and Q
2
, the same set of players, and the same set
of propositional variables. A probabilistic bisimula-
tion between C
1
and C
2
is a pair of functions (Z
1
, Z
2
)
where Z
1
: Q
1
→ Q
2
and Z
2
: Q
2
→ Q
1
such that there
are move transfer functions ∆
1
and ∆
2
such that for
{i,
¯
i} = {1, 2} and all q
i
∈ Q
i
, q
¯
i
= Z
i
(q
i
), and all
coalitions A:
• q
i
and q
¯
i
satisfy the same propositional variables,
• if c
i
is a (A, q
i
) move, the (A, q
¯
i
)-move
c
¯
i
(a) = ∆
i
(a, q
i
, c
i
(a)) for all a ∈ A satis-
fies that for { j,
¯
j} = {1, 2} and all (A, q
j
)-
moves c
A
j
, there is a (A, q
¯
j
)-move c
A
¯
j
such that
for all q
′
i
∈ Q
i
, Pr
Z
¯
i
(δ(q
¯
i
, c
¯
i
∪ c
A
′
¯
i
)) = q
′
i
=
Pr
δ(q
i
, c
i
∪ c
A
i
) = q
′
i
.
• if q
i
∼
a
q
′
i
, then ∆
i
(a, q
i
, c) = ∆
i
(a, q
′
i
, c) for all c
• if q
i
∼
a
q
′
i
, then Z
i
(q
i
) ∼
a
Z
i
(q
′
i
)
• if q
¯
i
∼
A
q
′
¯
i
, there is q
′
i
with Z
i
(q
′
i
) = q
′
¯
i
and q
i
∼
A
q
′
i
.
• Z
1
◦ Z
2
and Z
2
◦ Z
1
are idempotent.
r
0
r
1
r
2
r
3
ok
ok
a:1
b:1
b:0
q
0
q
1
q
5
q
6
q
2
q
7
q
8
q
3
q
10
q
9
q
4
q
12
q
11
ok
ok
ok
ok
ok
ok
ok
ok
a:1
a:2
a:3
a:4
b:1
b:0
b:1
b:0
b:0
b:1
b:1
b:0
Figure 3: Game Structures C
1
and C
2
Theorem 16. Let C
1
and C
2
be concurrent game
structures, let (Z
1
, Z
2
) be a probabilistic bisimulation
between C
1
and C
2
, let q
1
and q
2
be states of C
1
and
C
2
with Z
1
(q
2
) = q
1
and Z
2
(q
1
) = q
2
. Let ϕ be a
quantified strategy state formula. Then C
1
, q
1
|= ϕ if
and only if C
2
, q
2
|= ϕ.
Consider the games C
1
and C
2
in Figure 3. In
both, player a starts, he has a single choice in C
1
and 4 choices in C
2
. The move by b then determines
whether ok holds in the final state. In states r
1
of C
1
and q
1
, q
2
, and q
3
of C
2
, a must play 1 to make ok
true, in state q
4
of C
2
, he must play 0. States q
2
and
q
3
are indistinguishable for a in C
2
. CGSs C
1
and C
2
ICAART2013-InternationalConferenceonAgentsandArtificialIntelligence
22

with state sets Q
1
and Q
2
are bisimilar via (Z
1
, Z
2
),
where Z
2
: Q
2
→ Q
1
is defined as follows:
• Z
2
(q
0
) = r
0
,
• Z
2
(q
1
) = Z
2
(q
2
) = Z
2
(q
3
) = Z
2
(q
4
) = r
1
,
• Z
2
(q
5
) = Z
2
(q
7
) = Z
2
(q
9
) = Z
2
(q
11
) = r
2
,
• Z
2
(q
6
) = Z
2
(q
8
) = Z
2
(q
10
) = Z
2
(q
12
) = r
3
.
The move transfer function swaps moves 0 and 1
when transferring from r
1
to q
4
. Z
1
: Q
1
→ Q
2
maps
r
0
to q
0
, r
1
to q
1
, r
2
to q
5
and r
3
to q
6
, the move trans-
fer functions map all of a’s possible moves in q
0
to
the move 1, the moves of b are mapped to themselves
(note that q
4
is not used in this direction). It is easy to
check that (Z
1
, Z
2
) is a bisimulation.
Theorem 16 states that state related via both Z
2
and Z
1
satisfy the same formulas. This applies to
(r
0
, q
0
), (r
1
, q
1
), (r
2
, q
5
), and (r
3
, q
6
). The example
shows a bisimulation between structures with com-
plete and incomplete information, and with different
cardinalities.
6 MODEL CHECKING
COMPLEXITY
Model checking is the problem to determine, for a
CGS C , a quantified strategy formula ϕ, and a state q,
whether C , q |= ϕ. We state the following results for
completeness, the proofs are straight-forward using
results and techniques from the literature (Alur et al.,
2002; Br´azdil et al., 2006; Chatterjee et al., 2007;
Schnoor, 2010b). We note that the model-checking
problem for MQAPI is undecidable except for restric-
tions that reduce QAPI to strategy logic.
Theorem 17. The QAPI model-checking problem is
1. PSPACE-complete for deterministic CGSs,
2. solvable in 3EXPTIME and 2EXPTIME-hard for
probabilistic structures.
REFERENCES
˚
Agotnes, T., Goranko, V., and Jamroga, W. (2007).
Alternating-time temporal logics with irrevocable
strategies. In (Samet, 2007), pages 15–24.
Alur, R., Henzinger, T. A., and Kupferman, O. (2002).
Alternating-time temporal logic. Journal of the ACM,
49(5):672–713.
Br´azdil, T., Brozek, V., Forejt, V., and Kucera, A. (2006).
Stochastic games with branching-time winning objec-
tives. In LICS, pages 349–358. IEEE Computer Soci-
ety.
Chatterjee, K., Henzinger, T. A., and Jurdzinski, M. (2006).
Games with secure equilibria. Theor. Comput. Sci.,
365(1-2):67–82.
Chatterjee, K., Henzinger, T. A., and Piterman, N. (2007).
Strategy logic. In Caires, L. and Vasconcelos, V. T.,
editors, CONCUR, volume 4703 of Lecture Notes in
Computer Science, pages 59–73. Springer.
Chen, T. and Lu, J. (2007). Probabilistic alternating-time
temporal logic and model checking algorithm. In Lei,
J., editor, FSKD (2), pages 35–39. IEEE Computer So-
ciety.
Cortier, V., K¨usters, R., and Warinschi, B. (2007). A crypto-
graphic model for branching time security properties
- the case of contract signing protocols. In Biskup,
J. and Lopez, J., editors, ESORICS, volume 4734 of
Lecture Notes in Computer Science, pages 422–437.
Springer.
Halpern, J. Y. and Moses, Y. (1990). Knowledge and com-
mon knowledge in a distributed environment. Journal
of the ACM, 37:549–587.
Herzig, A. and Troquard, N. (2006). Knowing how to play:
uniform choices in logics of agency. In Nakashima,
H., Wellman, M. P., Weiss, G., and Stone, P., editors,
AAMAS, pages 209–216. ACM.
Jamroga, W. (2004). Some remarks on alternating tem-
poral epistemic logic. In Proceedings of Formal Ap-
proaches to Multi-Agent Systems (FAMAS 2003, pages
133–140.
Jamroga, W. and van der Hoek, W. (2004). Agents that
know how to play. Fundamenta Informaticae, 63(2-
3):185–219.
Samet, D., editor (2007). Proceedings of the 11th Confer-
ence on Theoretical Aspects of Rationality and Knowl-
edge (TARK-2007), Brussels, Belgium, June 25-27,
2007.
Schnoor, H. (2010a). Explicit strategies and quantification
for ATL with incomplete information and probabilis-
tic games. Technical Report 1008, Institut f¨ur Infor-
matik, Christian-Albrechts-Universit¨at zu Kiel.
Schnoor, H. (2010b). Strategic planning for probabilistic
games with incomplete information. In van der Hoek,
W., Kaminka, G. A., Lesp´erance, Y., Luck, M., and
Sen, S., editors, AAMAS, pages 1057–1064. IFAA-
MAS.
Schnoor, H. (2012). Deciding epistemic and strategic prop-
erties of cryptographic protocols. In Foresti, S., Yung,
M., and Martinelli, F., editors, ESORICS, volume
7459 of Lecture Notes in Computer Science, pages
91–108. Springer.
Schobbens, P.-Y. (2004). Alternating-time logic with imper-
fect recall. Electronis Notes in Theoretical Computer
Science, 85(2):82–93.
Walther, D., van der Hoek, W., and Wooldridge, M. (2007).
Alternating-time temporal logic with explicit strate-
gies. In (Samet, 2007), pages 269–278.
QuantifiedEpistemicandProbabilisticATL
23
