
Text Recognition in Natural Images using
Multiclass Hough Forests
G
¨
okhan Yildirim, Radhakrishna Achanta and Sabine S
¨
usstrunk
School of Computer and Communication Sciences,
´
Ecole Polytechnique F
´
ed
´
erale de Lausanne, Lausanne, Switzerland
Keywords:
Text Detection and Recognition, Hough Forests, Feature Selection, Natural Images.
Abstract:
Text detection and recognition in natural images are popular yet unsolved problems in computer vision. In
this paper, we propose a technique that attempts to detect and recognize text in a unified manner by searching
for words directly without reducing the image into text regions or individual characters. We present three
contributions. First, we modify an object detection framework called Hough Forests (Gall et al., 2011) by
introducing “Cross-Scale Binary Features” that compares the information between the same image patch at
different scales. We use this modified technique to produce likelihood maps for every text character. Second,
our word-formation cost function and computed likelihood maps are used to detect and recognize the text
in natural images. We test our technique with the Street View House Numbers
∗
(Netzer et al., 2011) and
the ICDAR 2003
†
(Lucas et al., 2003) datasets. For the SVHN dataset, our algorithm outperforms recent
methods and has comparable performance using fewer training samples. We also exceed the state-of-the-art
word recognition performance for ICDAR 2003 dataset by 4%. Our final contribution is a realistic dataset
generation code for text characters.
1 INTRODUCTION
Text detection and recognition are popular and chal-
lenging problems in the computer vision community.
State-of-the-art Optical Character Recognition (OCR)
softwares robustly convert scanned documents into
text. However, they do not perform well on text in nat-
ural images (de Campos et al., 2009). In natural im-
ages, text regions might have complex backgrounds
and in general have no structure. In order to overcome
these issues, previous research has mostly addressed
text detection and recognition separately.
Text detection describes methods that isolate text
regions from background clutter. In order to separate
text and background, various methods have been pro-
posed that can be summarized under two categories:
connected-component based and texture-based.
In connected-component based methods, the color
or intensity of text is assumed to be consistent. In or-
der to find these consistent areas, mathematical mor-
phology operations (Ezaki et al., 2004) and maxi-
mally stable extremal regions (Neumann and Matas,
∗
http://ufldl.stanford.edu/housenumbers
†
http://algoval.essex.ac.uk/icdar/Datasets.html
This work was supported by the Swiss National Sci-
ence Foundation under grant number 200021 143406 / 1
2011) can be used. Connected-component based
methods perform well if the consistency assumptions
are met. However, they might not work on images
with complex background and/or non-standard font
styles.
In texture-based methods, text and non-text re-
gions are distinguished by classification, such as Sup-
port Vector Machines (SVM) (Kim et al., 2003) and
adaptive boosting with Haar-like structures (Chen and
Yuille, 2004). Texture-based methods are robust in
the presence of image clutter. However, they still have
difficulty in detecting small, low contrast, or blurred
text.
Text recognition in natural images is challeng-
ing due to practical difficulties, such as non-uniform
backgrounds, geometric transformations, and the va-
riety of font types and sizes. In the literature, we
find structural and statistical approaches for solving
the text recognition problem. In (Netzer et al., 2011),
features are selected by clustering using K-means
and other unsupervised techniques, and the characters
(digits) are classified with SVM. In (de Campos et al.,
2009), individual characters that are cut from natu-
ral images are recognized using a variety of different
features and classified with nearest neighbours, SVM
and multiple kernel learning. In (Newell and Griffin,
737
Yildirim G., Achanta R. and Süsstrunk S..
Text Recognition in Natural Images using Multiclass Hough Forests.
DOI: 10.5220/0004197407370741
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 737-741
ISBN: 978-989-8565-47-1
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2011), multi-scale histograms of oriented gradients
followed by a nearest neighbor-classifier are used to
recognize characters. In (Neumann and Matas, 2011),
directional Gaussian filters are applied to generate
features for a character; these features are then used
to train an SVM for recognizing a character. In (Neu-
mann and Matas, 2011; Wang et al., 2011; Mishra
et al., 2012), in addition to individual character recog-
nition, lexicon priors for English language are em-
ployed for robust word recognition. As the recogni-
tion operation is not perfect, in practice it is required
to utilize other information, such as word formation,
lingual statistics, and size limitations to correct for
false positives and negatives and to form a word.
In this paper, we present three contributions. First,
we replace binary features in multiclass Hough forests
with cross-scale binary features and to achieve bet-
ter recognition rates. Multiclass Hough forests show
promising results in object detection and recognition
in (Gall et al., 2011; Razavi et al., 2011) but they
have not yet been employed for text detection and
recognition. Second, we propose a word formation
method, which is more suitable and accurate for like-
lihood maps. Using our features and word forma-
tion method, we exceed the best performance for the
SVHN dataset and outperform state-of-the-art word
recognition performance of the ICDAR 2003 dataset
by 4%. Finally, we present a realistic dataset genera-
tor for text characters.
The rest of the paper is as follows: In Section 2,
we summarize the multiclass Hough forests and in-
troduce cross-scale binary features. In Section 3, we
describe our word-formation cost function, which at-
tempts to jointly solve detection and recognition prob-
lems. In Section 4, we introduce our synthetic dataset
and the performance of cross-scale binary features.
In Section 5, we present and discuss our results for
text detection and recognition on different datasets.
In Section 6, we summarize our algorithm and related
observations.
2 HOUGH FORESTS
The generalized Hough transform (Ballard, 1981) is
a technique for finding the position and parameters
of arbitrary shaped objects using local information in
a voting scheme. In this paper, we use multiclass
Hough forests (Gall et al., 2011), which is an effi-
cient method to compute the generalized Hough trans-
form for multiple types of objects by adopting random
forests.
A Hough forest consists of binary random trees.
In a random tree, a randomly selected portion of im-
age patches are recursively split into smaller sub-
sets by using binary features as separation criteria.
One contribution of our paper is a new feature set
called “Cross-Scale Binary Features” (see Section
2.2), which gives better recognition performance than
the binary features from (Gall et al., 2011). We use
our features to train and test the Hough forests.
2.1 Binary Features
In (Gall et al., 2011), the binary features are the
comparison results of two randomly selected pixels.
These pixels can be selected from different represen-
tations (intensity, gradient, blurred etc.) of the same
image. The general structure to represent a binary fea-
ture is as follows:
f =
(
1, if P
l
(x
1
) > P
l
(x
2
) + τ
0, otherwise
(1)
Here, f is the binary feature, P
l
is image patch P in l
th
representation type, x
1
and x
2
are image coordinates
and τ is an offset value.
2.2 Cross-Scale Binary Features
In our work, we modify the structure in (1) by intro-
ducing cross-scale feature comparison. We generalize
the feature set by allowing the comparison among two
representations l
1
and l
2
as follows:
f =
(
1, if P
l
1
(x
1
) > P
l
2
(x
2
) + τ
0, otherwise
(2)
In our method, each representation corresponds to
a blurred version of the image processed with aver-
aging filters with different kernel sizes. Thus, every
feature effectively compares the mean values of two
randomly positioned rectangles with random dimen-
sions. A representation of a cross-scale feature on an
image patch is shown in Figure 1.
Cross-scale binary features defined in (2) are the
superset of the features in (1). Cross-scale features
help us to exploit potential local structural informa-
tion and to compactly group similar patches of differ-
ent objects. Performance comparison of binary and
cross-scale binary features can be found in Section 4.
2.3 Training and Testing Hough Forests
In the training step, we use 24 × 24 pixel images and
densely sample them with 8 × 8 pixel patches. We
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
738

Classes
0
1
A
G
a
Instances
G!
G"
G"
G
G
G
€
P
l
1
x
1
( )
=
µ
Image Patch
€
P
l
2
x
2
( )
=
µ
Figure 1: Representation of a cross-scale binary feature, µ
represents the average pixel value for a given rectangular
region.
then recursively split the image patches using a cross-
scale binary feature that is selected from a pool of
features by minimizing metric functions described in
(Gall et al., 2011). Feature selection and splitting op-
erations eventually lead to compact clusters of image
patches. The separation procedure terminates when
one of the two criteria is met: the maximum allowed
tree depth is achieved or the total number of patches
is less than a certain value. A leaf is then declared
and the number of image patches for each class label
and relative patch position is stored for testing as a
“Hough vote”.
In the testing step, multiclass Hough forests trans-
form a test image into likelihood maps for each
text character by computing and accumulating Hough
votes of each test image patch. An example for the
letter “a” is illustrated in Figure 2.
Hough&Forests&
Figure 2: Generalized Hough transform for character “a” by
using Hough forests (the image is taken from the ICDAR
2003 dataset).
For detection and recognition, we calculate Hough
images for all 62 characters (digits, capital and small
letters) and downsize images to achieve 10 different
scales. We use integral images for efficient feature
computation and distribute different scales to differ-
ent processing cores.
3 WORD FORMATION
Letters can resemble each other either locally or glob-
ally. For example, the upper part of the letter “P”
could be detected as a letter “D” within a smaller
scale. Depending on the font style, the letter “W” can
be confused with two successive “V”s or “U”s and
vice versa. Therefore, instead of recognizing char-
acters individually, we use a pictorial structure model
(Felzenszwalb and Huttenlocher, 2005), which is sim-
ilar to the one in (Wang et al., 2011) and produces
lexicon priors with the help of an English word list
3
.
These priors help us to reduce the search space and
to robustly recognize the actual word. We recognize
a word when the following function is locally mini-
mized in the image:
w = argmin
n,∀c
i
−
n
∑
i=1
V(L
i
) +
n−1
∑
i=1
C(L
i
, L
i+1
)
(3)
Here, w is the recognized word, L
i
is the coordinate
quadruplet (scale, character, 2-D position), V is the
likelihood value of having that character at that scale
and position, and C is the cost function for two ad-
jacent letters. The cost function includes consistency
terms for position, scale, capitalization, and lexicon
priors. In order to find the most likely word hypoth-
esis that minimizes the cost function, we perform a
grid-like search on Hough maps. An example search
is illustrated in Figure 3. The word search is initial-
ized with a grid over all likelihood maps (red crosses).
The word with minimum cost and part of the dictio-
nary is the recognition output. The red circles depict
V(L
1
), V(L
2
), and V(L
3
) and the red connections are
C(L
1
, L
2
) and C(L
2
, L
3
).
Figure 3: From left to right: word image, likelihood maps
for “W”, “A”, and “Y”. The first row shows the beginning
of the word search and the second row shows the minimized
path between likelihood maps.
4 EXPERIMENTS
Training Dataset. We create a dataset by using a
subset of 200 computer fonts under random affine
transformations
4
. In addition, we put other characters
around the main character using the probabilities of
occurrence in an English word (the word list of Sec-
tion 3 is used). Finally, we blend these images with
random non-text background to simulate a character
3
http://www.mieliestronk.com/wordlist.html
4
http://ivrg.epfl.ch/research/text detection recognition
TextRecognitioninNaturalImagesusingMulticlassHoughForests
739
in a natural scene.
We train our recognizer using over 1000 training
images per class (10 trees in total with a maximum
depth of 20). As the trees are independent from each
other, they are trained in parallel. The same property
is used when we compute the likelihood maps for text
characters.
Feature Evaluation. We conduct five experiments
for different number of features to compare the per-
formance of cross-scale and normal binary features.
If the number of features is equal to one, it means that
there is no intelligent feature selection, thus totally
random features and trees. The recognition results
and error bars for each case in Figure 4 show that
our features yield a better recognition performance.
In addition, as the number of features increases, the
differences between our features and binary features
tend to increase. This is an expected result because
our features are actually a superset of the binary fea-
tures in (Gall et al., 2011).
0 1 2 4 8 16 32 64 128 256 512
0.65
0.66
0.67
0.68
0.69
0.7
0.71
0.72
0.73
0.74
Number of Features
Recognition Performance
Recognition Performance of Different Features
Cross−Scale Features
Gall et al. 2011
Figure 4: Recognition performance of two different types
of features using our synthetically generated dataset.
5 RESULTS
Individual character recognition is done using the
SVHN dataset, which consists of over 600’000 im-
ages of the ten digits with a 32 × 32 pixel size
5
. The
performance is evaluated on the same test set as in
(Netzer et al., 2011), which consists of over 26000
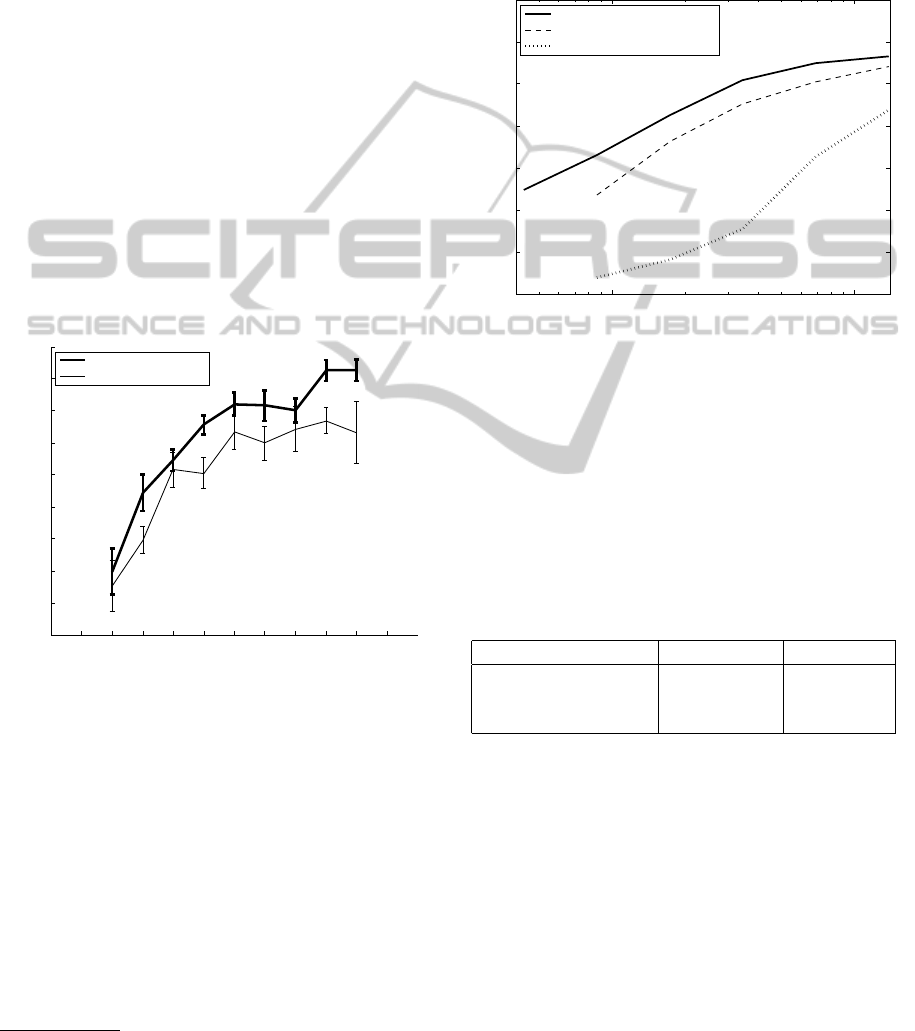
images of digits. As we can see from Figure 5, our
technique has better performance than the K-means
approach described in (Netzer et al., 2011). In ad-
dition, as the number of training samples decreases,
5
We downsized the images to 24×24 to reduce the com-
putational cost.
we achieve the same recognition performance using
approximately one-half of the training samples used
for K-means. The cross-scale features that we use
in training increase the distinction effectiveness of
the Hough trees and create an accurate classifier with
fewer training samples.
10
4
10
5
0.85
0.86
0.87
0.88
0.89
0.9
0.91
0.92
Number of Training Samples
Recognition Rate
Digit Recognition on SVHN Dataset
Hough Forest
K−means (Netzer et al., 2011)
NN (Netzer et al., 2011)
Figure 5: SHVN digit recognition dataset results.
We also test our algorithm on cropped words in
the ICDAR 2003 database. As in (Wang et al., 2011)
and (Mishra et al., 2012), we ignore words with non-
alphanumeric characters and words that are shorter
than three letters, giving us a total of 827 words. Note
that the proper nouns and brand names that appear in
the dataset are also in our search space. The recogni-
tion results are presented in Table 1.
Table 1: Cropped word recognition results (in %) from the
ICDAR 2003 database.
Method ICDAR2003 Time
Hough Forest 85.7 3 minutes
(Mishra et al., 2012) 81.78 -
(Wang et al., 2011) 76 15 seconds
Our framework is similar to that of (Mishra et al.,
2012). The performance increase, however, is due to
the exhaustive word search in the likelihood maps.
We also apply our algorithm to the full ICDAR
2003 images, some results are given in Figure 6.
For the images in Figure 6(a),(b),(c), and (d), we
are able to recognize the words correctly despite the
non-standard font styles, distracting factors around
the characters and/or complex backgrounds. The oc-
cluded word “Park” in Figure 6(b) is recognized cor-
rectly, because of the patch-based voting operation in
Hough forests. In Figure 6(e), we incorrectly recog-
nized the words “for” and “our” as “colour”. This er-
ror might be due to the complex background, or to the
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
740

total word formation cost, which is lower for a com-
bined word than individual words. In Figure 6(f), the
word “Oxfam” was missed due to the resemblance of
the letter “f” to the letter “t”.
Computing Hough votes and searching for words
can require significant computational power. How-
ever, due to the nature of Hough forests and the local
word search operation in the image, the whole oper-
ation is highly parallelizable both in the training and
testing stages.
6 CONCLUSIONS
We present a new method for text detection and recog-
nition in natural images. We introduce cross-scale bi-
nary features and show that using these features im-
proves the recognition performance. We train Hough
forests using images generated by our realistic charac-
ter generator code. We recognize the words in natural
images using these features and our word-formation
cost function. We test our algorithm on two avail-
able datasets. In individual character recognition, we
show that our algorithm has a better recognition per-
formance and can operate at same performance using
fewer training samples. In cropped word recognition,
we exceed the recognition performance of the most
recent algorithm by 4%.
(a) australia (b) sports, centre, wivenhoe, partk,
conference, center, car, parks
(c) closeout, final, reductions,
closeout
(d) yamaha
(e) famous, COLOUR, fist, chips (f) OXFAM,bookshop
Figure 6: Some results of our algorithm on ICDAR 2003
dataset images (correctly and incorrectly recognized words
are written in small and capital letters, respectively).
REFERENCES
Ballard, D. H. (1981). Pattern Recognition, 13(2):111–122.
Chen, X. and Yuille, A. (2004). Detecting and reading text
in natural scenes. In Proc. of the IEEE Conference on
Computer Vision and Pattern Recognition, volume 2,
pages 366–373.
de Campos, T. E., Babu, B. R., and Varma, M. (2009). Char-
acter recognition in natural images. In Proc. of the
International Conference on Computer Vision Theory
and Applications, pages 273–280.
Ezaki, N., Bulacu, M., and Schomaker, L. (2004). Text de-
tection from natural scene images: towards a system
for visually impaired persons. In Proc. of the Interna-
tional Conference on Pattern Recognition, volume 2,
pages 683–686.
Felzenszwalb, P. F. and Huttenlocher, D. P. (2005). Pic-
torial structures for object recognition. International
Journal of Computer Vision, 61(1):55–79.
Gall, J., Yao, A., Razavi, N., Gool, L. V., and Lempitsky, V.
(2011). Hough forests for object detection, tracking,
and action recognition. IEEE Transactions on Pat-
tern Analysis and Machine Intelligence, 33(11):2188–
2202.
Kim, K. I., Jung, K., and Kim, J. H. (2003). Texture-based
approach for text detection in images using support
vector machines and continuously adaptive mean shift
algorithm. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 25(12):1631 – 1639.
Lucas, S., Panaretos, A., Sosa, L., Tang, A., Wong, S., and
Young, R. (2003). ICDAR 2003 robust reading com-
petitions. In Proc. of the International Conference on
Document Analysis and Recognition, pages 682–687.
Mishra, A., Alahari, K., and Jawahar, C. V. (2012). Top-
down and bottom-up cues for scene text recognition.
In Proc. of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 2687–2694.
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., and
Ng, A. Y. (2011). Reading digits in natural images
with unsupervised feature learning. In NIPS Workshop
on Deep Learning and Unsupervised Feature Learn-
ing.
Neumann, L. and Matas, J. (2011). A method for text lo-
calization and recognition in real-world images. In
Proc. of the Asian Conference on Computer Vision,
volume 3, pages 770–783.
Newell, A. J. and Griffin, L. D. (2011). Multiscale his-
togram of oriented gradient descriptors for robust
character recognition. In Proc. of the International
Conference on Document Analysis and Recognition,
pages 1085–1089.
Razavi, N., Gall, J., and Gool, L. J. V. (2011). Scalable
multi-class object detection. In Proc. of IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 1505–1512.
Wang, K., Babenko, B., and Belongie, S. (2011). End-to-
end scene text recognition. In Proc. of the Interna-
tional Conference on Computer Vision, pages 1457–
1464.
TextRecognitioninNaturalImagesusingMulticlassHoughForests
741
