
A Distributionally Robust Formulation for Stochastic Quadratic Bi-level
Programming
Pablo Adasme
1
, Abdel Lisser
2
and Chen Wang
2
1
Departamento de Ingenieria Electrica, Universidad de Santiago de Chile, Avenida Ecuador 3519, Santiago, Chile
2
Laboratoire de Recherche en Informatique, Universite Paris-Sud XI, Batiment 650, 91405 Orsay Cedex, France
Keywords:
Distributionally Robust Optimization, Stochastic Programming, Binary Quadratic Bi-level Programming,
Mixed Integer Programming.
Abstract:
In this paper, we propose a distributionally robust model for a (0-1) stochastic quadratic bi-level programming
problem. To this purpose, we first transform the stochastic bi-level problem into an equivalent deterministic
formulation. Then, we use this formulation to derive a bi-level distributionally robust model (Liao, 2011).
The latter is accomplished while taking into account the set of all possible distributions for the input random
parameters. Finally, we transform both, the deterministic and the distributionally robust models into single
level optimization problems (Audet et al., 1997). This allows comparing the optimal solutions of the proposed
models. Our preliminary numerical results indicate that slight conservative solutions can be obtained when the
number of binary variables in the upper level problem is larger than the number of variables in the follower.
1 INTRODUCTION
Bi-level programming(BP) is a hierarchical optimiza-
tion framework. It consists in optimizing an objective
function subject to a constrained set where another
optimization problem is embedded. The first level op-
timization problem is referred to as the leader prob-
lem while the lower level, as the follower problem.
Formally, a BP problem can be written as follows
min
{x∈X,y}
F(x, y)
s.t. G(x, y) ≤ 0
min
{y}
f(x, y)
s.t. g(x, y) ≤ 0
where x ∈ R
n
1
, y ∈ R
n
2
, F : R
n
1
×R
n
2
→ R and f :
R
n
1
×R
n
2
→ R are the decision variables and the ob-
jective functions for the upper and lower level prob-
lems, respectively. The functions G : R
n
1
×R
n
2
→R
m
1
and g : R
n
1
×R
n
2
→R
m
2
denote upper and lower level
constraints. The goal is to find an optimal point such
that the leader and the follower minimizes their re-
spective objective functions subject to their respec-
tive linking constraints (Audet et al., 1997). Ap-
plications of BP include transportation, network de-
sign, management and planning among others. For
more application domains, see for instance (Floudas
and Pardalos, 2001). It has been shown that bi-level
problems are strongly NP-Hard, even for the simplest
case where all the involved functions are affine (Au-
det et al., 1997).
As far as we know, robust optimization ap-
proaches have not yet been reported in the literature
for bi-level programming. Some preliminary works
concerning pure stochastic programming approaches
can be found, for instance, in (Audestad et al., 2006;
¨
Ozaltin et al., 2010; Carrion et al., 2009; Kalashnikov
et al., 2010; Wynter, 2009). In (Carrion et al., 2009),
an application for retailer futures market trading is
considered whereas a natural gas cash-out problem is
studied in (Kalashnikov et al., 2010).
Stochastic programming (SP) as well as robust op-
timization (RO) are well known optimization tech-
niques to deal with mathematical problems involving
uncertainty in the input parameters. In SP, it is usually
assumed that the probability distributions are discrete
and known or that they can be estimated (Shapiro
et al., 2009). There are two well known scenario ap-
proachesin SP, the recourse model and the probabilis-
tic constrained approach. See for instance (Schultz
et al., 1996; Birge and Louveaux, 1997). Different
from the SP approach, the RO framework assumes
that the input random parameters lie within a convex
uncertainty set and that the robust solutions must re-
main feasible for all possible realizations of the in-
222
Adasme P., Lisser A. and Wang C..
A Distributionally Robust Formulation for Stochastic Quadratic Bi-level Programming.
DOI: 10.5220/0004207100240031
In Proceedings of the 2nd International Conference on Operations Research and Enterprise Systems (ICORES-2013), pages 24-31
ISBN: 978-989-8565-40-2
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

put parameters. Thus, the optimization is performed
over the worst case realization of the input param-
eters. In compensation, we obtain robust solutions
which are protected from undesired fluctuations in the
input parameters. In this case, the objective function
provides more conservative solutions. We refer the
reader to (Bertsimas and Sim, 2004) and (Bertsimas
et al., 2010) for a more general understanding on RO.
In this paper, we propose a distributionally RO
model for a (0-1) stochastic quadratic bi-level prob-
lem with expectation in the objective and probabilis-
tic knapsack constraints in the leader. To this pur-
pose, we first transform the stochastic problem into an
equivalent deterministic problem (Gaivoronski et al.,
2011). Subsequently, we apply a novel and simple
distributionally robust approach proposed by (Liao,
2011) to derive a distributionally robust formulation
for our stochastic bi-level problem. The latter allows
optimizing the objective function over the set of all
possible distributions in the input random parameters.
Finally, we compute optimal solutions by transform-
ing both problems, the deterministic as well as the
distributionally models into single level optimization
problems (Audet et al., 1997). Preliminary numeri-
cal comparisons are given. The paper is organized
as follows. Section 2, presents the stochastic model
under study and the equivalent deterministic formula-
tion. In section 3, we derive the distributionally robust
formulation. In section 4, we transform the determin-
istic and robust models into single level optimization
problems. Then, in section 5, we provide preliminary
numerical comparisons. Finally, section 6 concludes
the paper.
2 PROBLEM FORMULATION
We consider the following (0-1) stochastic quadratic
bi-level problem we denote hereby Q
0
as follows
max
{x}
E
(
n
1
∑
i=1
n
1
∑
j=1
D
i, j
(ξ)x
i
x
j
)
(1)
s.t. P
(
n
1
∑
j=1
a
j
(ξ)x
j
+
n
2
∑
j=1
b
j
(ξ)y
j
≤ c(ξ)
)
≥
(1−α) (2)
x
j
∈{0, 1}, j = 1 : n
1
(3)
y ∈ argmax
{y}
{
n
2
∑
j=1
d
j
y
j
} (4)
s.t.
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
(5)
0 ≤ y
j
≤ 1, j = 1 : n
2
(6)
where x ∈ {0, 1}
n
1
and y ∈ [0, 1]
n
2
are the leader and
the follower decision variables respectively. In Q
0
,
(1)-(3) correspond to the leader problem while (4)-
(6) represent the follower problem. The term E{·}
denotes mathematical expectation while P{·} repre-
sents a probability imposed on the upper level knap-
sack constraint. This probability should be satisfied
at least for (1−α)% of the cases where α ∈ (0, 0.5]
represents the risk. The matrices D, F,G and vectors
a, b, d, h, c are input nonnegative real matrices/vectors
defined accordingly. We assume that the matrix
D = D(ξ), vectors a = a(ξ), b = b(ξ) and c = c(ξ)
are random variables distributed according to a dis-
crete probability distribution Ω. As such, one may
suppose that a
j
(ξ), b
j
(ξ) and c(ξ) are concentrated
on a finite set of scenarios as a
j
(ξ) = {a
1
j
, .., a
K
j
},
b
j
(ξ) = {b
1
j
, .., b
K
j
} and c(ξ) = {c
1
, .., c
K
} respec-
tively, with probability vector q
T
= (q
1
, .., q
K
) such
that
∑
K
k=1
q
k
= 1 and q
k
≥ 0. In (Gaivoronski et al.,
2011), the authors propose a deterministic equivalent
formulation for Q
0
by replacing the probabilistic con-
straint (2) with the following deterministic constraints
n
1
∑
j=1
a
k
j
x
j
+
n
2
∑
j=1
b
k
j
y
j
≤ c
k
+ M
k
z
k
, z
k
∈ {0, 1}∀k
K
∑
k=1
q
k
z
k
≤ α (7)
where M
k
is defined for each k = 1 : K by M
k
=
∑
n
1
j=1
a
k
j
+
∑
n
2
j=1
b
k
j
−c
k
. The variable z
k
for each k is
a binary variable used to decide whether a particular
constraint is discarded. This is handled by taking the
risk α in constraint (7).
Analogously, the random variables D
i, j
(ξ) are dis-
cretely distributed, i.e. D
i, j
(ξ) = (D
1
i, j
, ..., D
K
i, j
), ∀i, j
such that
∑
K
k=1
ρ
k
= 1 and ρ
k
≥0 where ρ is the prob-
ability vector. Thus, the expectation in the objective
function (1) can be written as
max
{x}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
This yields the following deterministic equivalent
problem we denote by Q
D
as follows
max
{x,z}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
s.t.
n
1
∑
j=1
a
k
j
x
j
+
n
2
∑
j=1
b
k
j
y
j
≤ c
k
+ M
k
z
k
, ∀k
ADistributionallyRobustFormulationforStochasticQuadraticBi-levelProgramming
223

K
∑
k=1
q
k
z
k
≤ α
z
k
∈ {0, 1}∀k
x
j
∈ {0, 1}, j = 1 : n
1
y ∈ argmax
{y}
{
n
2
∑
j=1
d
j
y
j
}
s.t.
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
0 ≤ y
j
≤ 1, j = 1 : n
2
This model is a deterministic equivalent formulation
for Q
0
provided the assumption on the discrete prob-
ability space Ω holds.
3 THE DISTRIBUTIONALLY
ROBUST FORMULATION
In this section, we derive a distributionally RO model
for Q
D
. For this, we assume that the probability dis-
tribution of the random vectors ρ
T
= (ρ
1
, .., ρ
K
) and
q
T
= (q
1
, .., q
K
) are not known and that they can be
estimated by some statistical mean from some avail-
able historical data. Thus, we consider the maximum
likelihood estimator of the probability vectors ρ
T
and
q
T
to be the observed frequency vectors.
3.0.1 The Distributionally Robust Model
In order to formulate a robust model for Q
D
, we write
its objective function as follows
min
{x}
max
{π∈H
β
}
K
∑
k=1
π
k
n
1
∑
i=1
n
1
∑
j=1
−D
k
i, j
x
i
x
j
!
(8)
and the left hand side of constraint (7) as the maxi-
mization problem
max
{p∈H
γ
}
K
∑
k=1
p
k
z
k
(9)
where the sets H
β
and H
γ
are defined respectively as
H
β
=
(
π
k
≥ 0, ∀k :
K
∑
k=1
π
k
= 1,
K
∑
k=1
|π
k
−ρ
k
|
√
ρ
k
≤ β
)
and
H
γ
=
(
p
k
≥ 0, ∀k :
K
∑
k=1
p
k
= 1,
K
∑
k=1
|p
k
−q
k
|
√
q
k
≤ γ
)
where β, γ ∈ [0, ∞). Now, let δ
k
= π
k
−ρ
k
, then the
inner max problem in (8) can be written as
max
{δ}
K
∑
k=1
(δ
k
+ ρ
k
)
n
1
∑
i=1
n
1
∑
j=1
−D
k
i, j
x
i
x
j
!
s.t.
K
∑
k=1
|δ
k
|
√
ρ
k
≤ β (10)
K
∑
k=1
δ
k
= 0 (11)
δ
k
≥ −ρ
k
, k = 1 : K (12)
The associated dual problem is
min
{w
1
,ϕ
1
,v
1
}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
−D
k
i, j
x
i
x
j
!
+
K
∑
k=1
ρ
k
w
1
k
+ βϕ
1
s.t. ϕ
1
≥
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
, ∀k
ϕ
1
≥ −
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
, ∀k
w
1
k
≥ 0, ∀k
and ϕ
1
, v
1
, w
1
are Lagrangian multipliers for con-
straints (10)-(12), respectively. Similarly, we obtain
a dual formulation for (9) as follows
min
{w
2
,ϕ
2
,v
2
}
K
∑
k=1
q
k
z
k
+
K
∑
k=1
q
k
w
2
k
+ γϕ
2
s.t. ϕ
2
≥
√
q
k
v
2
+ w
2
k
+ z
k
, ∀k
ϕ
2
≥ −
√
q
k
v
2
+ w
2
k
+ z
k
, ∀k
w
2
k
≥ 0, ∀k
where ϕ
2
, v
2
, w
2
are Lagrangian multipliers associ-
ated with its primal constraints. Now, replacing these
dual problems in Q
D
gives rise to the following distri-
butionally robust formulation we denote by Q
R
D
max
{w
1
,ϕ
1
,v
1
,w
2
,ϕ
2
,v
2
,x,z}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
−
K
∑
k=1
ρ
k
w
1
k
−βϕ
1
s.t.ϕ
1
≥
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
, ∀k
ϕ
1
≥ −
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
x
i
x
j
!
, ∀k
w
1
k
≥ 0, ∀k (13)
ICORES2013-InternationalConferenceonOperationsResearchandEnterpriseSystems
224

n
1
∑
j=1
a
k
j
x
j
+
n
2
∑
j=1
b
k
j
y
j
≤ c
k
+ M
k
z
k
, k = 1 : K
z
k
∈ {0, 1} k = 1 : K
K
∑
k=1
q
k
z
k
+
K
∑
k=1
q
k
w
2
k
+ γϕ
2
≤α
ϕ
2
≥
√
q
k
(z
k
+ v
2
+ w
2
k
), ∀k
ϕ
2
≥ −
√
q
k
(z
k
+ v
2
+ w
2
k
), ∀k
w
2
k
≥ 0, ∀k (14)
x
j
∈ {0, 1}, j = 1 : n
1
y ∈ argmax
{y}
{
n
2
∑
j=1
d
j
y
j
}
s.t.
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
0 ≤ y
j
≤ 1, j = 1 : n
2
In the next section we transform both models: Q
D
and
Q
R
D
into single level optimization problems. More
precisely, we obtain Mixed Integer Linear program-
ming problems (MILP) (Audet et al., 1997).
4 EQUIVALENT MILP
FORMULATIONS
Since the follower problem is the same for both Q
D
and Q
R
D
, we derive equivalent MILPs by replacing the
follower problem with its primal, dual and comple-
mentarity slackness conditions. These conditions can
be written as
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
(15)
0 ≤ y
j
≤ 1, j = 1 : n
2
(16)
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
≥ d
j
, j = 1 : n
2
(17)
λ
i
≥ 0, i = 1 : m
2
(18)
µ
j
≥ 0, j = 1 : n
2
(19)
λ
i
h
i
−
n
1
∑
j=1
F
i, j
x
j
−
n
2
∑
j=1
G
i, j
y
j
!
= 0,
i = 1 : m
2
(20)
µ
j
(1−y
j
) = 0, j = 1 : n
2
(21)
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
−d
j
!
y
j
= 0,
j = 1 : n
2
(22)
where (15)-(16) and (17)-(19) are the primal and dual
follower constraints, respectively. Note that con-
straints (20)-(22) are quadratic constraints. In (Audet
et al., 1997), the authors propose a splitting scheme
to linearize these complementarity constraints. The
approach introduces binary variables as follows
h
i
−
n
1
∑
j=1
F
i, j
x
j
−
n
2
∑
j=1
G
i, j
y
j
+ ν
1
i
L ≤L,
i = 1 : m
2
(23)
λ
i
≤ν
1
i
L, i = 1 : m
2
(24)
ν
1
i
∈ {0, 1}, i = 1 : m
2
(25)
1−y
j
+ ν
2
j
L ≤L, j = 1 : n
2
(26)
µ
j
≤ ν
2
j
L, j = 1 : n
2
(27)
ν
2
j
∈ {0, 1}, j = 1 : n
2
(28)
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
−d
j
+ ν
3
j
L ≤L,
j = 1 : n
2
(29)
y
j
≤ ν
3
j
L, j = 1 : n
2
(30)
ν
3
j
∈ {0, 1}, j = 1 : n
2
(31)
where constraints (23)-(25), (26)-(28) and (29)-(31)
replace the single constraints (20), (21) and (22), re-
spectively. The parameter L is a large positive num-
ber.
Finally, let ψ
i, j
= x
i
x
j
be a linearization variable
for each quadratic term in Q
D
and Q
R
D
(Fortet, 1960).
Thus, a MILP formulation for Q
D
can be written as
max
{x,y,z,ψ,λ,µ,ν
1
,ν
2
,ν
3
}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
ψ
i, j
!
s.t.
n
1
∑
j=1
a
k
j
x
j
+
n
2
∑
j=1
b
k
j
y
j
≤c
k
+ M
k
z
k
, ∀k
K
∑
k=1
q
k
z
k
≤ α
z
k
∈{0, 1}∀k
ψ
i, j
≤ x
i
, i, j = 1 : n
1
(32)
ψ
i, j
≤ x
j
, i, j = 1 : n
1
(33)
ψ
i, j
≥ x
j
+ x
i
−1, i, j = 1 : n
1
(34)
ψ
i, j
∈ {0, 1}, i, j = 1 : n
1
(35)
x
j
∈{0, 1}, j = 1 : n
1
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
0 ≤ y
j
≤ 1, j = 1 : n
2
ADistributionallyRobustFormulationforStochasticQuadraticBi-levelProgramming
225

m
2
∑
i=1
λ
i
G
i, j
+ µ
j
≥ d
j
, j = 1 : n
2
λ
i
≥ 0, i = 1 : m
2
µ
j
≥ 0, j = 1 : n
2
h
i
−
n
1
∑
j=1
F
i, j
x
j
−
n
2
∑
j=1
G
i, j
y
j
+ ν
1
i
L ≤L,
i = 1 : m
2
λ
i
≤ ν
1
i
L, i = 1 : m
2
ν
1
i
∈ {0, 1}, i = 1 : m
2
1−y
j
+ ν
2
j
L ≤L, j = 1 : n
2
µ
j
≤ ν
2
j
L, j = 1 : n
2
ν
2
j
∈ {0, 1}, j = 1 : n
2
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
−d
j
+ ν
3
j
L ≤L,
j = 1 : n
2
y
j
≤ ν
3
j
L, j = 1 : n
2
ν
3
j
∈ {0, 1}, j = 1 : n
2
where constraints (32)-(35) are Fortet linearization
constraints. We denote this model by MIP
D
. Con-
sequently, a MILP distributionally robust model for
Q
R
D
can be written as follows
max
{ϒ}
K
∑
k=1
ρ
k
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
ψ
i, j
!
−
K
∑
k=1
ρ
k
w
1
k
−βϕ
1
s.t.ϕ
1
≥
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
ψ
i, j
!
, ∀k
ϕ
1
≥ −
√
ρ
k
v
1
+ w
1
k
−
n
1
∑
i=1
n
1
∑
j=1
D
k
i, j
ψ
i, j
!
, ∀k
w
1
k
≥ 0, ∀k
n
1
∑
j=1
a
k
j
x
j
+
n
2
∑
j=1
b
k
j
y
j
≤ c
k
+ M
k
z
k
, k = 1 : K
K
∑
k=1
q
k
z
k
+
K
∑
k=1
q
k
w
2
k
+ γϕ
2
≤ α
z
k
∈{0, 1} k = 1 : K
ϕ
2
≥
√
q
k
(z
k
+ v
2
+ w
2
k
), ∀k
ϕ
2
≥ −
√
q
k
(z
k
+ v
2
+ w
2
k
), ∀k
w
2
k
≥ 0, ∀k
ψ
i, j
≤ x
i
, i, j = 1 : n
1
ψ
i, j
≤ x
j
, i, j = 1 : n
1
ψ
i, j
≥ x
j
+ x
i
−1, i, j = 1 : n
1
ψ
i, j
∈ {0, 1}, i, j = 1 : n
1
x
j
∈{0, 1}, j = 1 : n
1
n
1
∑
j=1
F
i, j
x
j
+
n
2
∑
j=1
G
i, j
y
j
≤ h
i
, i = 1 : m
2
0 ≤ y
j
≤ 1, j = 1 : n
2
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
≥ d
j
, j = 1 : n
2
λ
i
≥ 0, i = 1 : m
2
µ
j
≥ 0, j = 1 : n
2
h
i
−
n
1
∑
j=1
F
i, j
x
j
−
n
2
∑
j=1
G
i, j
y
j
+ ν
1
i
L ≤L,
i = 1 : m
2
λ
i
≤ ν
1
i
L, i = 1 : m
2
ν
1
i
∈ {0, 1}, i = 1 : m
2
1−y
j
+ ν
2
j
L ≤L, j = 1 : n
2
µ
j
≤ ν
2
j
L, j = 1 : n
2
ν
2
j
∈ {0, 1}, j = 1 : n
2
m
2
∑
i=1
λ
i
G
i, j
+ µ
j
−d
j
+ ν
3
j
L ≤L,
j = 1 : n
2
y
j
≤ ν
3
j
L, j = 1 : n
2
ν
3
j
∈ {0, 1}, j = 1 : n
2
where ϒ = {w
1
, ϕ
1
, v
1
, w
2
, ϕ
2
, v
2
, x, y, z, ψ, λ, µ, ν
1
, ν
2
,
ν
3
}. We denote this model by MIP
R
D
.
In the next section, we provide numerical com-
parisons between MIP
D
and MIP
R
D
. This allows mea-
suring the conservatism level of MIP
R
D
with respect
to MIP
D
. The conservatism level can be measured by
the loss in optimality in exchange for a robust solution
which is more protected against uncertainty (Bertsi-
mas and Sim, 2004). This means, the less conser-
vative the robust solutions are, the better the RO ap-
proach.
5 NUMERICAL RESULTS
In this section, we present preliminary numerical re-
sults. A Matlab program is developed using Cplex
12.3 for solving MIP
D
and MIP
R
D
. The numerical ex-
periments have been carried out on a Pentium IV, 1.9
GHz with 2 GB of RAM under windows XP. The in-
put data is generated as follows. The probability vec-
tors ρ and q are uniformly distributed in [0, 1] such
that the sums are equal to one. The parameter α is
ICORES2013-InternationalConferenceonOperationsResearchandEnterpriseSystems
226
set to 0.1. Matrices F, G and vectors a
k
, b
k
, ∀k are
uniformly distributed in [0, 1]. The symmetric matri-
ces D
k
, ∀k and vector d are uniformly distributed in
[0, 10]. The scalars c
k
, ∀k and the vector h are gener-
ated respectively as
c
k
=
1
2
n
1
∑
j=1
a
k
j
+
n
2
∑
j=1
b
k
j
!
, ∀k
and
h
i
=
1
2
n
1
∑
j=1
F
i, j
+
n
2
∑
j=1
G
i, j
!
, ∀i = 1 : m
2
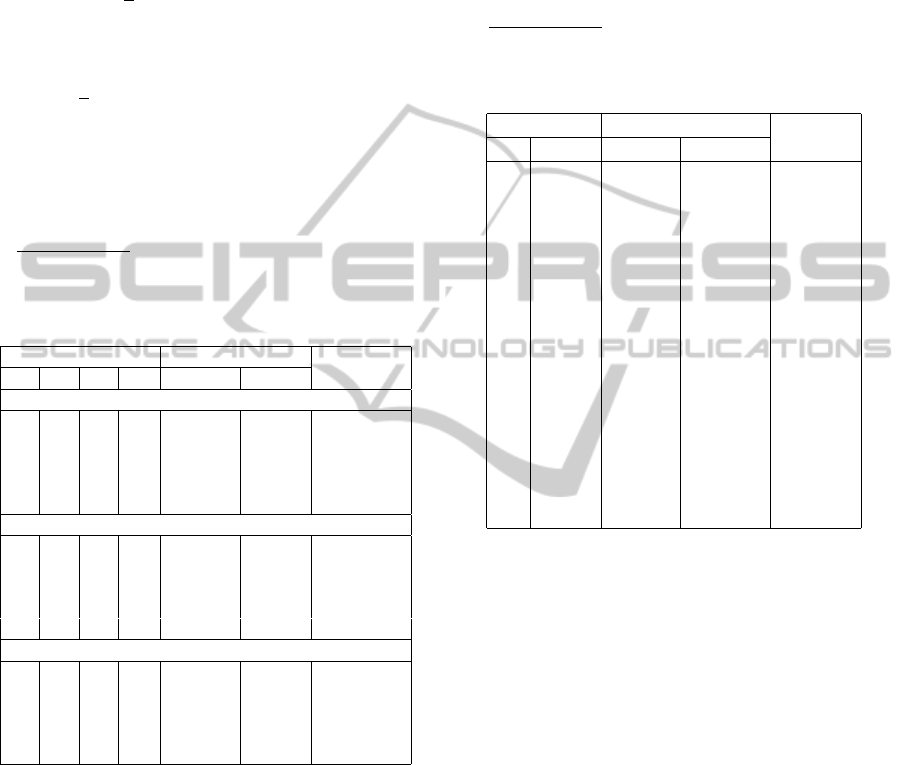
In table 1, columns 1-4 give the size of the instances.
Columns 5-6 provide the average optimal solutions
over 25 different sample instances. Finally, column 7
gives the average gaps we compute for each instance
as
(MIP
D
−MIP
R
D
)
MIP
D
·100%. These results are calculated
for different values of β and γ. From table 1, we
Table 1: Average comparisons over 25 instances.
Instance size Avg. Opt. Sol.
Avg. Gap
R
n
1
n
2
K m
2
MIP
D
MIP
R
D
β = 50 and γ = 50
10 10 10 5 300.09 267.31 10.85 %
10 10 30 5 283.95 229.39 21.88 %
10 10 10 10 322.94 284.46 11.98 %
20 10 10 5 985.82 917.55 6.95 %
10 20 10 5 152.09 115.25 22.12 %
β = 100 and γ = 50
10 10 10 5 313.29 258.47 17.74 %
10 10 30 5 272.49 212.07 22.05 %
10 10 10 10 320.94 290.30 9.29 %
20 10 10 5 990.99 931.64 5.93 %
10 20 10 5 138.99 100.97 27.53 %
β = 50 and γ = 100
10 10 10 5 290.98 255.61 12.06 %
10 10 30 5 278.32 197.80 28.66 %
10 10 10 10 311.54 282.26 9.08 %
20 10 10 5 1013.41 958.89 5.23 %
10 20 10 5 169.78 89.12 47.33 %
mainly observe that the solutions tend to be more con-
servative when a) the number of scenarios K is larger
than n
1
, n
2
and m
2
and b) when the number of vari-
ables of the follower problem: n
2
is larger than n
1
, K
and m
2
. On the opposite, we see slight conservative
solutions when the number of binary variables: n
1
is
larger than n
2
, K and m
2
. The variations of β and γ do
not seem to affect these trends. However, they seem to
affect the conservatism level in each case. For exam-
ple, the average increases significantly up to 47.33%
when β < γ and n
2
is large. Same remarks when K is
large.
In order to see how the parameters β and γ af-
fect the conservatism levels, we solve one instance
for each row in table 1 while varying only β and γ.
These results are shown in tables, 2, 3, 4, 5 and 6,
respectively. All columns in these tables provide the
same information for each instance. In columns 1-2,
we give the values of β and γ. Columns 3-4 give the
optimal solutions for MIP
D
and MIP
R
D
, respectively.
Finally, in column 5, we give the gap we compute
as
(MIP
D
−MIP
R
D
)
MIP
D
·100%. In table 2, we observe that
Table 2: Instance # 1: n
1
= n
2
= 10, m
2
= 5, K = 10.
Robustness Optimal Solutions
Gap
R
β γ MIP
D
MIP
R
D
0 0
328.37
328.37 0 %
0 30 328.37 0 %
0 60 328.37 0 %
0 90 328.37 0 %
30 0 301.18 8.28 %
30 30 311.27 5.21 %
30 60 315.48 3.93 %
30 90 315.48 3.93 %
60 0 290.70 11.47 %
60 30 291.79 11.14 %
60 60 311.04 5.28 %
60 90 311.04 5.28 %
90 0 302.53 7.87 %
90 30 309.27 5.82 %
90 60 309.27 5.82 %
90 90 290.54 11.52 %
when β = 0, then augmenting the values of γ does not
affect the optimal solutions. This is not the case when
γ = 0 and β > 0. Next, when both β > 0 and γ > 0,
the optimal solutions are affected. In particular, we
observe that the parameter β affects more the optimal
solutions than γ does. For example, when β goes from
30 to 60, we observe an increment of 5.93% while
from 30 to 90, we observe an increment of 0.61%.
This is not the case when γ increases. In this partic-
ular case, we observe a decrement of 1.28% in each
case. The increase of γ seems to produce the opposite
effect than incrementing β. For example, we notice
that when β = 30, 60, 90 and γ goes from 0 to 30, 60
or 90, the gaps are decremented except in the worst
case when both, β = γ = 90.
Similar observations are obtained for instances 3
and 5 in tables 4 and 6, respectively. Instances 2 and
4 in tables 3 and 5 respectively, provide additional in-
formation. Table 3 corresponds to the case where the
number of scenarios K is larger compared to n
1
, n
2
and m
2
. In this case, increasing γ when β = 0 af-
fects the optimal solutions. In particular, when β = 0
and γ goes from 60 to 90, we have a large increase of
31.04% in the conservatism level. This is repeated for
ADistributionallyRobustFormulationforStochasticQuadraticBi-levelProgramming
227
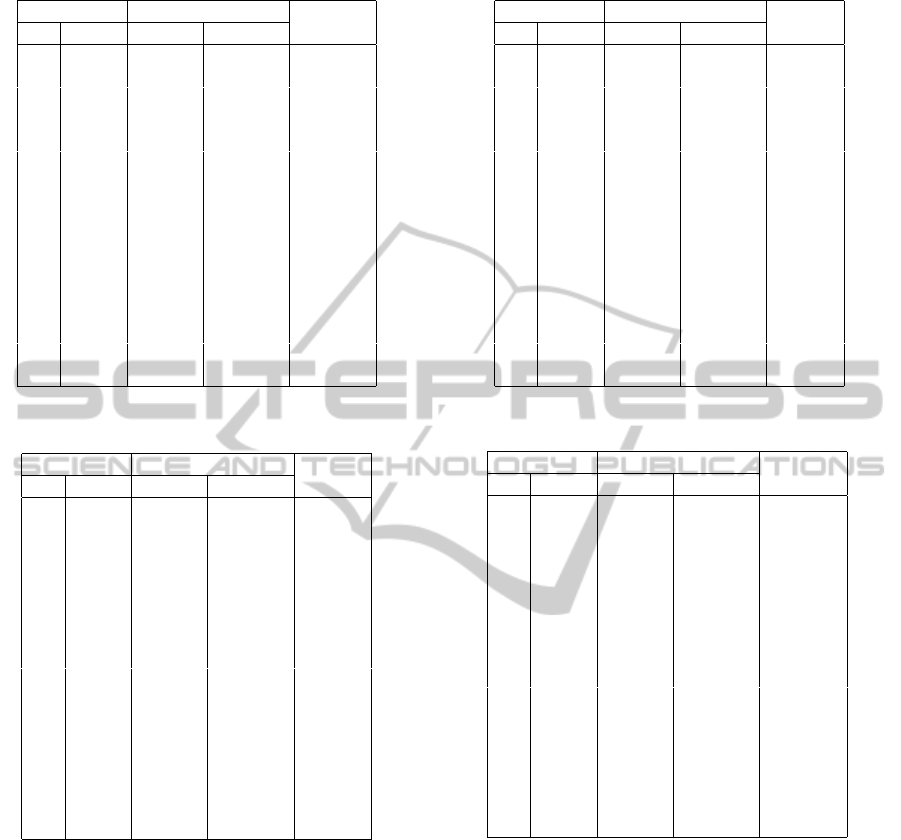
Table 3: Instance # 2: n
1
= n
2
= 10, m
2
= 5, K = 30.
Robustness Optimal Solutions
Gap
R
β γ MIP
D
MIP
R
D
0 0
181.14
181.14 0 %
0 30 181.03 0.06 %
0 60 179.85 0.71 %
0 90 123.63 31.75 %
30 0 178.82 1.28 %
30 30 177.12 2.22 %
30 60 177.12 2.22 %
30 90 123.67 31.73 %
60 0 176.63 2.49 %
60 30 176.63 2.49 %
60 60 175.07 3.35 %
60 90 123.08 32.05 %
90 0 174.60 3.61 %
90 30 173.15 4.41 %
90 60 173.15 4.41 %
90 90 121.96 32.67 %
Table 4: Instance # 3: n
1
= n
2
= 10, m
2
= 10, K = 10.
Robustness Optimal Solutions
Gap
R
β γ MIP
D
MIP
R
D
0 0
331.48
331.48 0 %
0 30 331.48 0 %
0 60 331.48 0 %
0 90 331.48 0 %
30 0 316.51 4.52 %
30 30 316.51 4.52 %
30 60 316.51 4.52 %
30 90 311.11 6.15 %
60 0 306.65 7.49 %
60 30 306.65 7.49 %
60 60 306.65 7.49 %
60 90 309.91 6.51 %
90 0 308.84 6.83 %
90 30 308.84 6.83 %
90 60 308.84 6.83 %
90 90 308.84 6.83 %
each value of β = 0, 30, 60, 90 when γ goes from 60 to
90. The worst gap occurs when β = γ = 90.
Finally, in table 5 we observe weak conservatism
levels in all cases. In fact, they are lower than 10%.
This instance corresponds to the case when the binary
variables of the leader problem, i.e. n
1
are largerwhen
compared to n
2
, m
2
and K. Notice that when β = 0
and γ grows, then the optimal solutions are slightly
affected.
6 CONCLUSIONS
In this paper, we proposed a distributionally robust
model for a (0-1) stochastic quadratic bi-level pro-
Table 5: Instance # 4: n
1
= 20, n
2
= 10, m
2
= 5, K = 10.
Robustness Optimal Solutions
Gap
R
β γ MIP
D
MIP
R
D
0 0
982.24
982.24 0 %
0 30 965.06 1.75 %
0 60 973.95 0.84 %
0 90 982.24 0 %
30 0 923.13 6.02 %
30 30 934.96 4.81 %
30 60 940.78 4.22 %
30 90 940.78 4.22 %
60 0 940.38 4.26 %
60 30 943.63 3.93 %
60 60 931.84 5.13 %
60 90 902.04 8.16 %
90 0 936.32 4.67 %
90 30 926.40 5.68 %
90 60 929.28 5.39 %
90 90 895.58 8.82 %
Table 6: Instance # 5: n
1
= 10, n
2
= 20, m
2
= 5, K = 10.
Robustness Optimal Solutions
Gap
R
β γ MIP
D
MIP
R
D
0 0
257.00
257.00 0 %
0 30 257.00 0 %
0 60 257.00 0 %
0 90 257.00 0 %
30 0 241.17 6.16 %
30 30 241.17 6.16 %
30 60 241.17 6.16 %
30 90 241.17 6.16 %
60 0 230.29 10.39 %
60 30 230.29 10.39 %
60 60 230.29 10.39 %
60 90 230.29 10.39 %
90 0 223.45 13.06 %
90 30 223.45 13.06 %
90 60 223.45 13.06 %
90 90 223.45 13.06 %
gramming problem. To this end, we transformed the
stochastic bi-level problem into an equivalent deter-
ministic model. Afterward, we derived a bi-level dis-
tributionally robust model using the deterministic for-
mulation. In particular, we applied a distributionally
robust approach proposed in (Liao, 2011). This al-
lows optimizing the problem when taking into ac-
count the set of all possible distributions of the in-
put random parameters. Thus, we derived Mixed In-
teger Linear Programming formulations using Fortet
linearization method (Fortet, 1960) and the approach
proposed by (Audet et al., 1997). Finally, we com-
pared the optimal solutions of this model to measure
the conservatism level of the proposed robust model.
Our preliminary numerical results show that slight
conservative solutions are obtained for the case when
ICORES2013-InternationalConferenceonOperationsResearchandEnterpriseSystems
228

the numberof binary variables in the upper level prob-
lem is larger than the number of variables in the fol-
lower problem.
ACKNOWLEDGEMENTS
The first author is grateful for the financial support
given by Conicyt Chilean government through the In-
sertion project number: 79100020.
REFERENCES
Audestad, J., Gaivoronski, A., and Werner, A. (2006). Ex-
tending the stochastic programming framework for
the modeling of several decision makers: Pricing and
competition in the telecommunication sector. Annals
of Operations Research, 142:19–39.
Audet, C., Hansen, P., Jaumard, B., and Savard, G. (1997).
Links between linear bilevel and mixed 01 program-
ming problems. Journal of Optimization Theory and
Applications, 93(2):273–300.
Bertsimas, D., Brown, D., and Caramanis, C. (2010). The-
ory and applications of robust optimization. SIAM Re-
view, 53(3):464501.
Bertsimas, D. and Sim, M. (2004). The price of robustness.
Operations Research, 52(1):35–53.
Birge, J. and Louveaux, F. (1997). Introduction to stochas-
tic programming. Springer-Verlag, New York.
Carrion, M., Arroyo, J., and Conejo, A. (2009). A bilevel
stochastic programming approach for retailer futures
market trading. IEEE Transactions on Power Systems,
24(3):1446–1456.
¨
Ozaltin, O., Prokopyev, O., and Schaefer, A. (2010). The
bilevel knapsack problem with stochastic right-hand
sides. Operations Research Letters, 38(4):328–333.
Floudas, C. and Pardalos, P. (2001). Encyclopedia of Op-
timization. Kluwer Academic Publishers, Dordrecht.
The Netherlands.
Fortet, R. (1960). Applications de l
′
algebre de boole
en recherche operationelle. Revue Francaise de
Recherche Operationelle, 4:17–26.
Gaivoronski, A., Lisser, A., and Lopez, R. (2011). Knap-
sack problem with probability constraints. Journal of
Global Optimization, 49(3):397–413.
Kalashnikov, V., Perez-Valdes, G., Tomasgard, A., and
Kalashnykova, N. (2010). Natural gas cash-out prob-
lem: Bilevel stochastic optimization approach. Euro-
pean Journal of Operational Research, 206(1):18–33.
Liao, S. (2011). Staffing a call center with uncertain non-
stationary arrival rate and flexibility. To appear in OR
Spectrum.
Schultz, R., Leen, S., and Vlerk, M. V. D. (1996). Two-stage
stochastic integer programming: a survey. Statistica
Neerlandica, 50:404–416.
Shapiro, A., Dentcheva, D., and Ruszczy´nski, A. (2009).
Lectures on Stochastic Programming: Modeling and
Theory. SIAM Philadelphia, Series on Optimization,
9 of MPS/SIAM, Philadelphia, 436 edition.
Wynter, L. (2009). Encyclopedia of Optimization, chapter
Stochastic Bilevel Programs. Springer.
ADistributionallyRobustFormulationforStochasticQuadraticBi-levelProgramming
229
