
Low-cost Automatic Inpainting for Artifact Suppression in Facial Images
Andr
´
e Sobiecki
1
, Alexandru Telea
1
, Gilson Giraldi
2
, Luiz Antonio Pereira Neves
3
and Carlos Eduardo Thomaz
4
1
Scientific Visualization and Computer Graphics, University of Groningen, Nijenborgh 9, Groningen, The Netherlands
2
Department of Computing, National Laboratory of Scientific Computation, Petr
´
opolis, Brazil
3
Department of Computing, Paran
´
a Federal University, Curitiba, Brazil
4
Department of Artificial Intelligence Applied on Automation, University Center of FEI, S
˜
ao Bernardo do Campo, Brazil
Keywords:
Image Inpainting, Face Reconstruction, Statistical Decision, Image Quality Index.
Abstract:
Facial images are often used in applications that need to recognize or identify persons. Many existing facial
recognition tools have limitations with respect to facial image quality attributes such as resolution, face posi-
tion, and artifacts present in the image. In this paper we describe a new low-cost framework for preprocessing
low-quality facial images in order to render them suitable for automatic recognition. For this, we first detect
artifacts based on the statistical difference between the target image and a set of pre-processed images in the
database. Next, we eliminate artifacts by an inpainting method which combines information from the target
image and similar images in our database. Our method has low computational cost and is simple to implement,
which makes it attractive for usage in low-budget environments. We illustrate our method on several images
taken from public surveillance databases, and compare our results with existing inpainting techniques.
1 INTRODUCTION
Facial recognition is the process of obtaining the iden-
tity of a person based on information obtained from
facial appearance (Ayinde and Yang, 2002). Com-
pared to other person identification methods such as
biometric fingerprints, retina scans, and voice recog-
nition, facial recognition has the advantage that it can
be used in contexts where the collaboration of the
person to be identified is not possible (Zhao et al.,
2003; Hjelmas and Low, 2001). One such context is
the identification of missing people based on existing
photographs thereof.
In the last decades, automatic face recognition has
received considerable attention from the scientific and
commercial communities. However, several open is-
sues still remain in this area. One such issue is that
facial recognition tools are in general not efficient for
poor quality facial images, e.g. in the presence of
shadows, artifacts, and blurring (Zamani et al., 2008;
Zhao et al., 2003; Castillo, 2006).
In some contexts, facial protographs are the only
key to person identification. For example, the sites
of Australian Federal Police (AFP, 2012), Federal
Brazilian Government (FGB, 2012), and UK Miss-
ing People Centre (MPO, 2012) publish facial pho-
tographs of missing people. Often, such photographs
are old, poorly digitized, and have artifacts such as
folds, scratches, irregular luminance, molds, stamps,
and written text, all of various sizes, shapes, texture,
and color. Since the effectiveness of facial recognition
methods depends on the quality of input images, it is
of high importance that such images present the dis-
criminant facial features (eyes, mouth, and nose) with
minimal artifacts. Moreover, it is desirable that they
all have a standard look, e.g. avoid outlier elements
such as glasses, hair locks, highlights, and smiles.
We present here a computational framework for
segmentation and automatic restoration of poor-
quality facial images, based on a statistical model
built from frontal facial images and inpainting tech-
niques. The location of facial features is obtained
by a mean image generated from a sample popula-
tion of conforming facial images that provides priv-
ileged information about spatial location of the fea-
tures. Salient outliers are found by statistically com-
paring the input image with this mean image. These
outliers are next eliminated by using a modified in-
painting technique which uses information from both
the input image itself and the closest high-quality im-
age in our image database. This produces images of
sufficient quality for typical face recognition tasks. In
41
Sobiecki A., Telea A., Giraldi G., Neves L. and Thomaz C..
Low-cost Automatic Inpainting for Artifact Suppression in Facial Images.
DOI: 10.5220/0004212300410050
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 41-50
ISBN: 978-989-8565-47-1
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

contrast to most existing digital restoration methods,
we require no user input to mark regions in the im-
age which has to be restored. Our method is simple
to implement and can be run in real-time on low-cost
PCs, which makes it attractive for utilization by gov-
ernment agencies in least developed countries.
2 RELATED WORKS
Many image inpainting techniques have been pro-
posed in the last decade. Oliveira et al. (Oliveira
et al., 2001) present a simple inpainting method
which repeatedly convolves a 3 ×3 filter over the re-
gions to inpaint. Although fast, this method yields
significant blurring. Bertalmio et al. (Bertalmio
et al., 2000; Bertalmio et al., 2001) estimate the lo-
cal image smoothness, using the image Laplacian,
and propagate this along isophote directions, esti-
mated by the image gradient rotated 90 degrees and
by Navier-Stokes equation. The Total Variational
(TV) model (Chan and Shen, 2000a) uses an Euler-
Lagrange equation coupled with anisotropic diffusion
to keep the isophotes directions. Telea (Telea, 2004)
inpaints an image by propagating the image informa-
tion from the boundary towards the interior of the
damaged area following a fast marching approach
and a linear extrapolation of the image field outside
the missing region. These methods give good results
when the regions to restore are small.
To inpaint thicker regions, the Curvature-Driven
Diffusion (CCD) method (Chan and Shen, 2000b)
enhances the TV method to drive diffusion along
isophote directions. Diffusion-based texture synthe-
sis techniques have been proposed to achieve higher
quality inpainting results (Bugeau and Bertalmio,
2009; Bugeau et al., 2009). Closer to our proposal,
Li et al. (Li et al., 2010) present semantic inpaint-
ing, where the damaged image is restored based on
texture synthesis using a most similar image from a
given database. Perez et al. (P
´
erez et al., 2003) and
Jeschke et al. (Jeschke et al., 2009) present seamless
image cloning that uses a Poisson process to compute
the seamless filling as well as a guidance vector field
that incorporates prior knowledge of the damaged do-
main.
Image cloning gives very good results, but is rela-
tively expensive in CPU and memory terms. Joshi et
al. use example images, taken from a person’s photo
collection, to improve the luminance, blur, contrast,
and shadows of that person’s photograph (Joshi et al.,
2010). Chou et al. also use the seamless image
cloning of Perez et al. for the editing of facial features
in digital photographs (Chou et al., 2012). However,
in contrast to our goal of automatic removal of facial
outlier artifacts, their goal was to assist users in pre-
viewing the results of explicitly chosen image modi-
fications.
To achieve our goal of facial image preprocessing
for supporting automatic missing persons identifica-
tion in low-cost contexts, we need a method which is
able to
• automatically detect the most salient artifacts in a
low-quality facial photograph;
• remove these artifacts in a plausible way;
• work (nearly) automatically;
• require very low computational costs.
Next, we present our proposal in order to address
these requirements.
3 PROPOSED METHOD
Figure 1 illustrates our computational pipeline for fa-
cial image restoration. We start by computing an im-
age quality index, which classifies the input image
as potentially benefiting from artifact removal or not
(Sec. 3.1). If the image can be improved, we next
identify, or segment, its artifacts using a statistical
decision method where the image is compared to an
existing database of facial images of various ethnici-
ties (Sec. 3.2). The detected artifacts are next slightly
enlarged using morphological dilation (Aptoula and
Lef
`
evre, 2008) to remove small-scale spatial noise
such as artifact boundary jaggies. Finally, we elim-
inate the artifacts by using a semantic inpainting, a
variation of the method presented in (Li et al., 2010),
which combines information from the input image
and the image database (Sec. 3.3).
All our images (input and database) are nor-
malized and equalized by the framework proposed
in (Amaral and Thomaz, 2008). This is needed since
existing facial image databases around the world con-
tain images with several sizes, resolutions, and con-
trasts. The steps of our pipeline are explained next.
3.1 Image Quality Index
Objective image quality measures have an important
role in image processing applications, such as com-
pression, analysis, registration, restoration and en-
hancement. One such simple measure is the image
quality index (Wang et al., 2004), which compares
two images x and y based on luminance l(x, y), con-
trast c(x, y) and structure s(x, y) comparison mea-
sures
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
42

Figure 1: Pipeline of proposed method.
l(x,y) =
2µ
x
µ
y
µ
2
x
+ µ
2
y
, (1)
c(x, y) =
2σ
x
σ
y
σ
2
x
+ σ
2
y
, (2)
s(x, y) =
σ
xy
σ
x
σ
y
. (3)
where x = {x
i
|1 ≤ i ≤ n} and y = {y
i
|1 ≤ i ≤ n} are
the two n-pixel images to compare. Here, µ
x
, µ
y
, σ
2
x
,
σ
2
y
and σ
xy
are the mean, variance, and covariance of
x and y, respectively (Sellahewa and Jassim, 2010),
i.e.
µ
x
=
1
n
n
∑
i=1
x
i
, µ
y
=
1
n
n
∑
i=1
y
i
σ
2
x
=
1
n −1
n
∑
i=1
(x
i
−µ
x
)
2
, σ
2
y
=
1
n −1
n
∑
i=1
(y
i
−µ
y
)
2
σ
xy
=
1
n −1
n
∑
i=1
(x
i
−µ
x
)(y
i
−µ
y
)
The quantities l(x,y) and c(x, y) range between 0
and 1, while s(x, y) is between -1 and 1. For nor-
malized and equalized (NEQ) images, as in our case,
l(x,y) and c(x, y) have a maximum of 1 since NEQ
images have very similar standard deviation and mean
values. In contrast, covariance values σ
xy
are distinct
in NEQ images. Hence, s(x, y) (Eqn. 3) is a good
candidate for assessing the similarity of two NEQ im-
ages. Note that s(x, y) does not give a direct descrip-
tive representation of the image structures: It reflects
the similarity between two image structures, where
s(x, y) equals one if and only if the structures of the
two images x and y are exactly the same.
We use the image quality index s for two purposes.
First, given an input image x, we compare it with the
average image x of our pre-computed image database
(see Sec. 3.2), using s(x, x). If x is too far away from
x, then x is either not a face image, or an image we
cannot improve; and so, we stop our pipeline. This
is further detailed in the quality index discussion in
Sec. 4. Otherwise, we determine the so-called outlier
artifacts which differentiate x from x, and suppress
them, as shown next.
3.2 Statistical Artifact Segmentation
Once we have chosen to improve the quality of an in-
put image, we aim to segment those image parts, or
artifacts, which deviate significantly from typical av-
erage images. These will be the target of our inpaint-
ing (Sec. 3.3).
For artifact segmentation, we use statistical deci-
sion methods based on inference theory (Spiegel and
Stephens, 2008; Bussab and Morrettin, 2002), where
samples in a database can generate privileged infor-
mation. This makes it possible to discriminate arti-
facts which we next want to remove from regular im-
age pixels. Given a database of N of NEQ-normalized
facial frontal images x
i
, the mean image is given by:
x =
1
N
N
∑
i=1
x
i
. (4)
We compute mean images x
DS
, x
LS
, and x
JP
sepa-
rately for images of people of three ethnicities (dark
skin (DS), light skin (LS), and japanese (JP)). This
avoids mixing up too different facial traits. Fig-
ure 2 shows the mean and standard deviation images
for these three groups. For dark skin people, we
use the FERRET database, (65 images) (P.J. Phillips
and Rauss, 2000) and 14 images taken from the
FEI database (Thomaz and Giraldi, 2010). For light
skin people, we consider 100 images from the FEI
database. For japanese people, we use the JAFFE
database (100 images) (M.J. Lyons and Gyoba, 1998).
These databases contain a variety of images for peo-
ple of different races, ages, and appearances. Al-
though all images are equalized, facial structure dif-
ferences exist, e.g. larger nose and lips (DS images),
shadows around the eyes (LS images), and significant
mouth position variations (JP images).
We next determine the ethnicity of the input im-
age x by finding its closest mean image x
min
∈
{x
DS
, x
LS
, x
JP
}, in terms of Euclidean distance.
Low-costAutomaticInpaintingforArtifactSuppressioninFacialImages
43

Finally, we use statistical segmentation to find the
artifact regions to be removed. To illustrate this, let
us suppose that the face samples are represented by a
random field x that follows a normal distribution with
mean x
min
and standard deviation σ.
Thus the distribution of the standardized variable
is given by:
z =
x −x
min
σ
. (5)
Here, σ is the standardized normal distribution of x
with mean 0 and variance 1, computed similariy to
x, i.e. separately for the white skin, dark skin, and
japanese face databases.
Table 1 shows the values of per-pixel z scores and
significance levels α. The set of z scores outside the
(a) x
JP
, japanese (b) σ
JP
, japanese
(c) x
DS
, dark skin (d) σ
DS
, dark skin
(e) x
LS
, light skin (f) σ
LS
, light skin
Figure 2: Mean images x and color-coded standard devia-
tion σ images for japanese, black skin, and light skin eth-
nicities.
range [−2.58, 2.58] is called the critical region of the
hypothesis or region of significance. This is the re-
gion of rejection of the hypothesis. The set of z scores
inside the range[−2.58, 2.58] is called the region of
hypothesis acceptance or the non-significance region.
Table 1: Statistical Significance.
Level of significance α Values of z
10% - 1.645 .. 1.645
5% -1.96 .. 1.96
1% - 2.58 .. 2.58
0.1% -3.291 .. 3.291
In practice, we observed that a value of α ' 10%
gives a good selection of atypical face features. In
other words, for each pixel z of the image z, computed
by Eqn. ( 5), we decide if it is an artifact pixel or not,
based on the value of z and our threshold α (Tab. 1).
The set of artifact pixels Ω are removed as described
next.
3.3 Semantic Inpainting
Now that we know which pixels of our input image
are likely to be artifacts, we show a way to remove
them by using inpainting. As our approach combines
the fast marching based inpainting (Telea, 2004) and
Poisson image editing (P
´
erez et al., 2003) techniques,
we first briefly outline relevant aspects of these tech-
niques.
3.3.1 Inpainting using Fast Marching
Inpainting technique based on fast marching method
(FMM) considers a first order approximation I
q
(p) of
the image at a point p situated on the boundary ∂Ω of
the region to inpaint Ω
I
q
(p) = I(q) + ∇I(q) ·(p −q), (6)
where q is a neighbor pixel of p located within a ball
B
ε
(p) of small radius ε centered at p and I(q) is the
image value at q. Each point p is inpainted as func-
tion of all points q ∈ B
ε
(p), by summing the esti-
mates of all points q, weighted by a weighting func-
tion w(p, q):
I(p) =
∑
q∈B
ε
(p)
w(p, q)I
q
(p)
∑
q∈B
ε
(p)
w(p, q)
(7)
where the application-dependent weights w(p, q) are
normalized, i.e.
∑
q∈B
w(p, q) = 1.
The boundary ∂Ω is advanced towards the interior
of Ω using the FMM (Sethian, 1999). While doing
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
44

this, FMM implicitly computes the so-called distance
transform DT : Ω → R
+
DT (p ∈ Ω) = argmin
q∈∂Ω
kp −qk. (8)
As the FMM algorithm visits all pixels of the dam-
aged region the method gradually propagates gray-
value information from outside Ω inwards by com-
puting expression (7).
This inpainting method is fast and simple. How-
ever, for regions thicker than roughly 10..25 pixels, it
creates an increased amount of blurring as we go far-
ther from ∂Ω into Ω, given the smoothing nature of
Eqn. 7. Since our facial artifacts are not guaranteed to
be thin, this method is not optimal.
3.3.2 Poisson Image Editing
This image restoration method allows to achieve
seamless filling of the damaged domain by using a
source image data. It renders remarkably good re-
sults, even for thick target regions. The method is
based on solving the equation:
∆I = div v on Ω (9)
with I known over the boundary ∂Ω and constrained
to the values of v, the so-called guidance field, that
is derived from a source image. For instance, if we
desires to seamlessly clone a source image I
src
onto
Ω, we can set v = ∇I
src
, which effectively reduces
Eqn. 9 to ∆I = ∆I
src
on Ω (Eqn. 10 in (P
´
erez et al.,
2003)). Solving the Poisson problem (Eqn. 9), how-
ever, is expensive in terms of memory requirements,
which is critical in our low-cost scenario (Farbman
et al., 2009).
3.3.3 Proposed Inpainting Method
Both the FMM inpainting method and Poisson image
editing basically use only the non-artifact areas of the
input and near image to restore its artifacts.
However, we have additional information coming
from our high-quality image database. Hence, our
proposal is to combine the fast-and-simple inpainting
method of (Telea, 2004) with the Poisson image edit-
ing (P
´
erez et al., 2003) augmented with information
extracted from our image database (Fig. 3).
We start by applying FMM inpainting (Sec. 3.3.1)
on the artifact region Ω ⊂x of our input image x. We
denote the result of this step, i.e. the image x where
Ω has been inpainted, by I
inp
. Next, we search in our
face image database DB for the closest facial image
I
near
, i.e.
I
near
= arg min
y∈DB
kx −yk. (10)
As outlined in Sec. 3.3.1, when Ω is thick, FMM in-
painting produces a blurred result I
inp
. We correct this
by mixing I
inp
and I
near
to yield:
I
2
= (1 −DT )I
inp
+ DT ·I
near
(11)
where DT is the distance transform of ∂Ω (Eqn. 8).
This progressively mixes the inpainting result I
inp
with the nearest image I
near
in a progressive way. At
the border ∂Ω, we see the inpainted image, which
smoothly extrapolates the non-artifact area out of the
damaged region in the input image. In the middle of
Ω the blurred effects observed in I
inp
are attenuated
by the high-quality image I
near
.
Next, we calculate Laplacian ∆I
near
=
∂
2
I
near
∂x
2
+
∂
2
I
near
∂y
2
of the closest image I
near
, using central differ-
ences, and add this component to our restoration, i.e.
compute
I
3
= I
2
+ ∆I
near
. (12)
This is a simplified form of the ‘seamless cloning’
presented in (P
´
erez et al., 2003) which just adds high-
frequency features to I
2
through the Laplacian oper-
ation ∆I
near
.” In contrast to (P
´
erez et al., 2003), our
approach is much cheaper, as it does not require solv-
ing a Poisson equation on Ω.
As a final step, we apply a 3-by-3 median filter on
I
3
to yield the final reconstruction result. This further
removes small-scale noise elements created by using
the finite-difference Laplacian (Eqn. 12).
4 RESULTS
Our method can produce good artifact removal even
in large and thick regions, due to the mix of inpaint-
ing (which preserves information specific to the in-
put image) and prior information (which introduces
information from a similar high-quality image from
our image database). A key element is that our image
database is composed by high quality images. There-
fore, they are considered to be good for facial recogni-
tion purposes. Besides this information is suitable for
both to extract the artifacts (Sec. 3.2) and to restore
the corresponding damaged areas.
We tested our method on 79 frontal facial im-
ages provided by several public organizations: the
Federal Brazilian Government (FGB, 2012), the Aus-
tralian Federal Police (AFP, 2012), and the UK Miss-
ing People Organization (MPO, 2012). These images
contain various levels of artifacts, e.g. annotations,
scratches, glasses, obscuring facial hair, folds, and ex-
posure problems. All input images were normalized
and equalized as outlined in Sec. 3.
Low-costAutomaticInpaintingforArtifactSuppressioninFacialImages
45

Figure 3: Diagram of the proposed inpainting method (see Sec. 3.3).
Segmentation. The Fig. 4 shows the results when
applying our segmentation approach for the im-
ages of collum (a) using the light-skin mean image
(Fig. 4.(b)), dark-skin mean image (Fig. 4.(c)) and
japanese mean image (Fig. 4.(d)). We observe that
if significance level α ≤ 1.0% we can extract the ar-
tifacts (glasses) when using the light and dark-skin
mean image images. Segmentation of artifacts works
best and has similar perceived quality results for dark-
skin and light-skin images (see Fig. 4). For several
images, the mean of japanese people presents very
good results. Although segmentation cannot select
all details where an input image differs from its eth-
nic group’s statistical average, it does a good job in
selecting details deemed to be unsuitable for official
person recognition photographs.
Figure 4: Segmentation comparison, with α = 0.1% (red),
α = 1% (dark blue), and α = 10% (light blue). (a) original
image; (b) light skin mean image x
LS
; (c) dark skin mean
image x
DS
; (d) japanese mean image x
JP
.
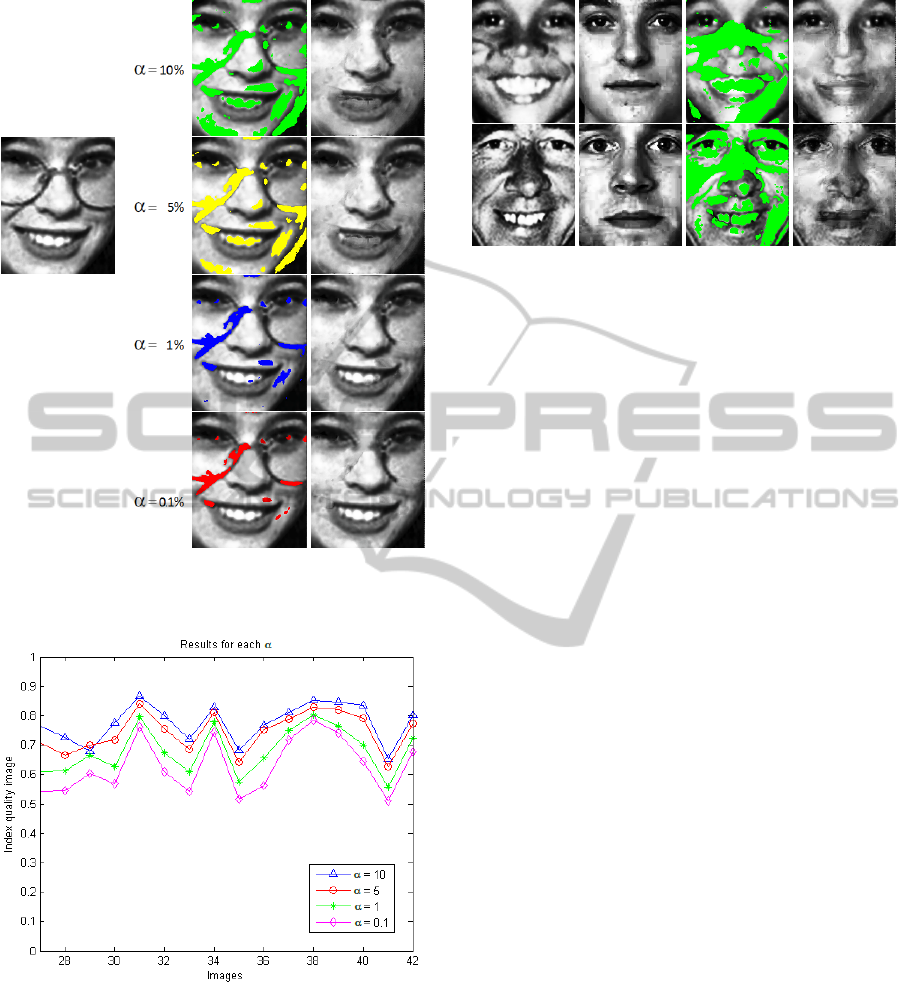
Significance Level. Figure 5 shows results when
changing the significance level α (Sec. 3.2). If we
choose high values for α the method extracts the ar-
tifacts as well as other regions, as we can see on Fig-
ure 5 . Conversely, the choice of low α values, like
in Figure 5, prevent such problem but is not efficient
to segment the region of interest. The optimum value
for α is application dependent and it depends on man-
ual fine-tuning in general. For the test performed, the
value α = 10% has given good results in all cases.
This fact can be verified in Figure 6 which shows the
results using some values of α.
Artifacts. Smile is considered an artifact, as it
does not comply with official standards for fa-
cial images concerning expression, illumination, and
background (ANSI, 2004; ISO, 2004; Thakare and
Thakare, 2012). Figure 7 presents an example of
smile suppression. The bottom row shows a case
where the smile has been well segmented and sup-
pressed. The top row shows a less successful case:
Part of the large smile (see Fig. 7 a, top) has not been
captured by the segmentation, and as such, it leaked
in the final reconstruction (Fig. 7 d, top). Also, note
that our method can produce changes in facial expres-
sions. For example, Fig. 7 (bottom row, d) shows a
face where the eyes are a mix between the input im-
age and nearest image, whereas the nose, and cheeks
follow more closely the input image.
Figure 8 shows further results, and also compares
them with three known inpainting techniques. In the
top row, we see an image with a hair lock artifact.
Segmenting this artifact is easy, as it is much darker
than the mean light-skin image x
LS
. Inpainting this ar-
tifact is also relatively easy, as it is not thick. The sec-
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
46
(a) (b) (c)
Figure 5: Segmentation results: (a) original image; (b) seg-
mentation; (c) reconstruction.
Figure 6: Results at each value of α.
ond row shows a face image which has a highlight, as
well as a thin horizontal crease (most probably due to
a photograph damage) on the cheeks. This artifact is
more complicated to capture since its grayvalue field
is similar with the mean image pixels nearby. How-
ever, the result (column g) shows that this artifact is
also largely eliminated from the input image.
The third row of Figure 8 shows an image with
glasses as an outlier artifact. Existing inpainting
(a) (b) (c) (d)
Figure 7: Smile elimination: (a) input image; (b) nearest
image; (c) segmentation; (d) proposed inpainting.
methods (columns d-f) succeed in eliminating this ar-
tifact less than our method (column g), because the
eyes are reconstructed. The fifth row of Figure 8
shows a similar case. Here, the artifact region is thin,
so all four tested inpainting methods produce elimi-
nate the glasses equally well.
In the fourth row Figure 8 it is shown an image
where a large shadow artifact appears under the nose,
on the cheeks, and the mouth. As expected, standard
inpainting cannot easily remove this problem, since
the shadow slightly extends outside of the segmented
region, on the base of the nose (dark area under the
nose, Fig. 8 c, fourth row). By using the nearest im-
age our method can be more efficient to remove the
shadow while generating less spurious details. A sim-
ilar effect is observed in Figure 8 (bottom row), where
our method performs better for both to remove the
cheek highlights and to reconstruct the opened eyes
better than existing methods.
Quality Index. Figure 9 shows the average structural
image quality index (Equation 3) for the three eth-
nicities present in our face image database, the origi-
nal input images for inpainting, and the results of the
studied inpainting methods. Several observations fol-
low. First, as expected, the face database images have
a relatively high quality index (average s ∈[0.6, 0.8]).
Secondly, input images which are faces have a lower
quality (average s ∼ 0.49). This motivates our pro-
posal to adjust such images to bring them in line with
the quality level of the face database. In contrast, in-
put images which are not faces have a much lower
quality index (average s ∼ 0). This allows us to de-
cide whether an input image should be improved or
deemed not improvable (because it is not a face): We
choose a suitable threshold τ, in this case, τ = 0.1.
Input images with s > τ are likely faces, so they are
further improved; images with s < τ are likely non-
faces, and thus skipped from the process. Thirdly, we
notice that the nearest image I
near
used in our inpaint-
Low-costAutomaticInpaintingforArtifactSuppressioninFacialImages
47

(a) (b) (c) (d) (e) (f) (g)
Figure 8: Method results: (a) original image; (b) nearest image (not the same person, just similar); (c) segmentation, where
green color indicates significance level α = 10%, yellow is 5%, blue is 1% and red is 0.1%; (d) inpainting (Oliveira et al.,
2001); (e) inpainting (Bertalmio et al., 2001); (f) inpainting (Telea, 2004); (g) our method.
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
48

Image quality index
light skin (LS)
dark skin (DS)
japanese (JP)
nearest
images
non-faces
inpainting result
(Bertalmio et al.)
inpainting result
(Oliveira et al.)
inpainting result
(Telea)
inpainting result
(our method)
input images
(to be restored)
Figure 9: Structural image quality for the input images, face
database, and result images.
ing (Sec. 3.3.3) has an average high quality index,
which justifies its explicit usage during inpainting. Fi-
nally, we see that our method yields, on average, re-
sults with a higher structural quality than the others
studied inpainting methods.
Limitations. Despite of its capabilities, our method
cannot handle facial images which deviate too much
from the information provided by the predefined im-
age database. Figure 10 shows such an example,
which is the worst case we found in our tests: The
input image (a) is too far away from both the aver-
age black-skin image (Fig. 2 c) and the nearest image
(Fig. 10 b) to successfully remove the facial hair, nose
pin, and large opaque glasses. However, we note that
this type of outlier can be easily detectable by our ap-
proach: When the input image is too far away from
the mean image, as mentioned above, our method
reports that it cannot likely improve this image and
stops.
Database. Selecting images that has good quality for
the face database serves two purposes. First, this al-
lows specifying what one considers to be an accept-
able facial image in a given context (e.g. open eyes,
no smiles, shadows, adorns, or imprints). Statistical
characteristics of this collection are used to implic-
itly determine what are outliers, thus what has to be
suppressed in a given input image. Secondly, features
of the nearest image in this database are used in the
restoration. Hence, if one wants to allow certain spe-
cific feature to persist in the restored images, this can
be done by inserting images containing such features
in the database.
Computational Aspects. The proposed method
is simple to implement. For an image of n
pixels, its memory and computational complexi-
ties are O(n log
√
n) (Sethian, 1999) respectively,
(a) (b)
(c) (d)
Figure 10: Challenging case for our method: (a) input im-
age; (b) nearest image; (c) segmentation; (d) inpainting.
in contrast to more sophisticated inpainting algo-
rithms (Bertalmio et al., 2001; Chan and Shen, 2000a;
Chan and Shen, 2000b; P
´
erez et al., 2003; Joshi et al.,
2010). This makes our method suitable for computers
that have low capacity of memory.
Validation. Although we have not validated the
added value of our artifact suppresion method in a full
face recognition pipeline, feedback from S
˜
ao Paulo
law enforcement confirmed that artifact removal is in-
deed helpful in recognition tasks. Future work should
be done to quantify the improvement in automatic
face recognition tasks.
5 CONCLUSIONS
We have presented a computational framework for au-
tomatic inpainting of facial images. Given a database
of facial images which are deemed to be of good qual-
ity for recognition tasks, our method automatically
identifies outlier (artifact) regions, and reconstructs
these by using a mix of information present in the in-
put image and information from the provided image
database. The proposed method is simple to imple-
ment and has low computational requirements, which
makes it attractive for low-cost usage contexts such as
government agencies in least developed countries. We
Low-costAutomaticInpaintingforArtifactSuppressioninFacialImages
49

have tested our method using three real-world public
image databases of missing people, and compared our
restoration results with three popular methods used in
image inpainting.
Potential improvements lie in the areas of more ro-
bust segmentation using artifact-specific quality met-
rics and using the k nearest images (k ≥1) for inpaint-
ing and actual evaluation of inpainting in a real-world
face recognition set-up.
REFERENCES
AFP (2012). Australian Federal Police, National
Missing Persons Coordination Centre. http://
www.missingpersons.gov.au.
Amaral, V. and Thomaz, C. (2008). Normalizac¸
˜
ao es-
pacial de imagens frontais de face. Dept. of Elec-
trical Engineering, Univ. Center of FEI, Brazil.
http://fei.edu.br∼cet/relatorio tecnico 012008.pdf.
ANSI (2004). US standard for digital image formats for use
with the facial biometric (INCITS 385).
Aptoula, E. and Lef
`
evre, S. (2008). A comparative study
on multivariate mathematical morphology. Pattern
Recogn. Lett., 29(2):109–118.
Ayinde, O. and Yang, Y. (2002). Face recognition approach
based on rank correlation of Gabor-filtered images.
Pattern Recogn., 35(6):1275–1289.
Bertalmio, M., Sapiro, G., and Bertozzi, A. (2001). Navier-
stokes, fluid dynamics, and image and video inpaint-
ing. In Proc. CVPR, pages 355–362.
Bertalmio, M., Sapiro, G., Caselles, V., and Ballester, C.
(2000). Image inpainting. In Proc. ACM SIGGRAPH,
pages 417—424.
Bugeau, A. and Bertalmio, M. (2009). Combining texture
synthesis and diffusion for image inpainting. In Proc.
VISAPP, pages 26–33.
Bugeau, A., Bertalmio, M., Caselles, V., and Sapiro, G.
(2009). A unifying framework for image inpainting.
Technical report, Intitute for Math. and Applications
(IMA). http://www.ima.umn.edu.
Bussab, W. and Morrettin, P. (2002). Est
´
atistica B
´
asica.
Editora Saraiva, S
˜
ao Paulo, Brazil.
Castillo, O. (2006). Survey about facial image quality.
Technical report, Fraunhofer IGD, TU Darmstadt.
Chan, T. and Shen, J. (2000a). Mathematical model for
local deterministic inpaintings. In Tech. Report CAM
00-11. Image Processing Group, UCLA.
Chan, T. and Shen, J. (2000b). Non-texture inpainting by
curvature driven diffusions. In Tech. Report CAM 00-
35. Image Processing Group, UCLA.
Chou, J., Yang, C., and Gong, S. (2012). Face-off: Auto-
matic alteration of facial features. Multimedia Tools
and Applications, 56(3):569–596.
Farbman, Z., Hoffer, G., Lipman, Y., CohenOr, D., and
Lischinski, D. (2009). Coordinates for instant image
cloning. In Proc. ACM SIGGRAPH, pages 342–450.
FGB (2012). Federal Goverment of Brazil, Jus-
tice Ministry - Missing Persons. http://
www.desaparecidos.mj.gov.br.
Hjelmas, E. and Low, B. (2001). Face detection: A survey.
CVIU, 83(3):236–274.
ISO (2004). Final draft international standard of biomet-
ric data interchange formats (part 5, face image data,
ISO–19794-5 FDIS).
Jeschke, S., Cline, D., and Wonka, P. (2009). A GPU lapla-
cian solver for diffusion curves and poisson image
editing. In Proc. ACM SIGGRAPH Asia, pages 1–8.
Joshi, N., Matusik, W., Adelson, E., Csail, M., and Krieg-
man, D. (2010). Personal photo enhancement using
example images. In Proc. ACM SIGGRAPH, pages
1–15.
Li, H., Wang, S., Zhang, W., and Wu, M. (2010). Image in-
painting based on scene transform and color transfer.
Pattern. Recogn. Lett., 31(7):582–592.
M.J. Lyons, S. Akamatsu, M. K. and Gyoba, J. (1998). Cod-
ing facial expressions with gabor wavelets. In Proc.
FG, pages 200–204. IEEE.
MPO (2012). Missing People from United Kingdom.
http://www.missingpeople.org.uk.
Oliveira, M. M., Bowen, B., Mckenna, R., and Chang, Y.
(2001). Fast digital image inpainting. In Proc. VIIP,
pages 261–266.
P
´
erez, P., Gangnet, M., and Blake, A. (2003). Poisson im-
age editing. In Proc. ACM SIGGRAPH, pages 313–
318.
P.J. Phillips, M. Hyeonjoon, S. R. and Rauss, P. (2000). The
FERET evaluation methodology for face-recognition
algorithms. IEEE TPAMI, 22(10):1090–1104.
Sellahewa, H. and Jassim, S. (2010). Image-quality-based
adaptive face recognition. IEEE TIM, 59(4):805–813.
Sethian, J. (1999). Level Set Methods and Fast Marching
Methods. Cambridge Univ. Press, 2nd edition.
Spiegel, M. and Stephens, L. (2008). Statistics. Schaum’s
Outlines.
Telea, A. (2004). An image inpainting technique based
on the fast marching method. J. Graphics. Tools,
9(1):23–34.
Thakare, N. and Thakare, V. (2012). Biometrics standards
and face image format for data interchange - a review.
Int. J. of Advances in Engineering and Technology,
2(1):385–392.
Thomaz, C. and Giraldi, G. (2010). A new ranking method
for principal components analysis and its applica-
tion to face image analysis. Image Vision Comput.,
28(6):902–913.
Wang, Z., Lu, L., and Bovik, A. (2004). Video quality as-
sessment based on structural distortion measurement.
Sig. Proc.: Image Comm., 19(2):121–132.
Zamani, A., Awang, M., Omar, N., and Nazeer, S. (2008).
Image quality assessments and restoration for face de-
tection and recognition system images. In Proc. AMS,
pages 505–510.
Zhao, W., Chellappa, R., Phillips, P., and Rosenfeld, A.
(2003). Face recognition: A literature survey. ACM
Computing Surveys, 35(4):399–458.
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
50
