
Robust Descriptors Fusion for Pedestrians’ Re-identification and
Tracking Across a Camera Network
Ahmed Derbel
1
, Yousra Ben Jemaa
2
, Sylvie Treuillet
3
, Bruno Emile
3
, Raphael Canals
3
and Abdelmajid Ben Hamadou
1
1
MIRACL Laboratory, SFAX University, Sfax, Tunisia
2
Signal and System Research Unit, TUNIS University, Tunis, Tunisia
3
PRISME Laboratory, ORLEANS University, Orleans, France
Keywords:
People Identification and Tracking, Multi-camera, Cascade of Descriptors, AdaBoost, Cumulative Matching
Characteristic.
Abstract:
In this paper, we introduce a new approach to identify people in multi-camera based on AdaBoost descriptors
cascade. Given the complexity of this task, we propose a new regional color feature vector based on intra and
inter color histograms fusion to characterize a person in multi-camera. This descriptor is then integrated into
an extensive comparative study with several existing color, texture and shape feature vectors in order to choose
the best ones. We prove through a comparative study with the main existing approaches on the VIPeR dataset
and using Cumulative Matching Characteristic measurement that the proposed approach is very suitable to
identify a person and provides very satisfactory performances.
1 INTRODUCTION
People identification and tracking is an activeresearch
area that can be applied in video surveillance, be-
havioral analysis and blind guiding. This complex
recognition process needs the use of robust descrip-
tors allowing a good pedestrian labeling despite sev-
eral complex problems depending on the work con-
text.
In a mono-camera context, persons’ tracking con-
sists in periodically locating pedestrians who appear
in a single camera field of view. This task, although
intuitive for the human cognitive system, is very dif-
ficult to automate and requires good management of
the great shape silhouettes’ variations as well as par-
tial occlusions which significantly affect the pedes-
trian images.
In some cases, the installation of several non-
overlapping cameras is necessary to cover wide ar-
eas. So, to ensure robust multi-camera tracking, it
is necessary to solve the pedestrians’ re-identification
problem. In fact, pedestrians’ re-identification con-
sists in identifying persons who appear in a camera
field of view and deciding if they have previously
been observed. To address this challenging objective,
a robust identification process is required to manage
large pose variations, changes in lighting conditions,
intrinsic and extrinsic camera parameter variations in
the network, scale variations and finally partial occlu-
sions.
To ensure multi-camera people re-identification
and tracking, several approaches have been suggested
in the literature. In a mono-camera context, some
existing approaches use a motion model such as a
Kalman filter or a particle filter to predict the po-
sition of tracked persons. This type of approach
also requires appearance models like color histogram
(Tung and Matsuyama, 2008) or a fusion of color his-
tograms and histograms of oriented gradients (Yang
et al., 2005) to make the particles weight correc-
tion. In a multi-camera context, many works are
based on merging priori knowledge on the camera
network such as probabilities and inter-camera transi-
tion time with appearance models such as color his-
tograms (Nam et al., 2007) or (Gilbert and Bow-
den, 2006) to ensure multi-camera people tracking
and re-identification. Some others works use only ap-
pearance models such as color histogram (Cai et al.,
2008), regional histograms (Alahi et al., 2010) or spa-
tiogram (Truong Cong et al., 2010) to ensure proper
92
Derbel A., Jemaa Y., Treuillet S., Emile B., Canals R. and Ben Hamadou A..
Robust Descriptors Fusion for Pedestrians’ Re-identification and Tracking Across a Camera Network.
DOI: 10.5220/0004275500920097
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 92-97
ISBN: 978-989-8565-48-8
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

pedestrians’ identification. The fusion of color and
texture descriptors is also a strategy used in (Gray
and Tao, 2008) (Prosser et al., 2010). This last cat-
egory of approaches is the best suited for people
re-identification and mono or multi-camera persons’
tracking because of its simplicity and its similarity
to the human identification cognitive system. That’s
why we have adopted this strategy in our work.
In this paper, we propose a new regional color de-
scriptor which will be subsequently integrated into an
extensive comparative study with different existing
descriptors based on color, texture and shape infor-
mation applied to people identification. This compar-
ative study will allow us to select the most robust of
them which will be merged using Adaboost algorithm
to ensure optimal performances.
This paper is organized as follows: Section 2 de-
scribes the different descriptors including the one we
propose. In order to select the best descriptors, we
present in Sections 3 and 4 two performed tests used
to evaluate the representative power of these feature
vectors in terms of people re-identification and track-
ing. Section 5 illustrates the proposed approach con-
sisting in merging descriptors already selected and
presents a comparative study with several existing
works. Conclusions and future works end the paper.
2 FEATURE VECTORS
In this section, we introduce our new descriptor and
several existing color, texture and shape descriptors
used to represent a pedestrian in multi-camera.
2.1 Proposed Descriptor
Regional color histograms are frequently applied in
multi-camera people identification according to their
robustness against large pose variations and partial
occlusions (Alahi et al., 2010). Despite the applica-
tion of the colors normalization step, the most color
descriptors remain very sensitive to lighting condi-
tions changes that affect pedestrians’ silhouettes in
multi-camera. For this reason, we propose a new
color descriptor that integrates intra-people regional
histograms to ameliorate the pedestrian characteriza-
tion and reduce the impact of lighting conditions vari-
ations across any network of camera.
The first step in implementing this descriptor con-
sists in quantizing the persons’ images to reduce the
effect of large color variation and then dividing hor-
izontally each quantized image into four blocks in
order to calcule a regional histogram for each block
(Figure 1). This division allows considering the ar-
ticulated nature and color differences between human
body parts. For each person matching, two types of
feature vectors are calculated. The first feature vector
type of size 6 contains Bhattacharyya distances be-
tween the four bands color histograms existing in a
person’s image: it characterizes the intra-class simi-
larity (Figure 1.a). A second feature vector type of
size 4 contains the Bhattacharyya distances between
each two color histograms of the same band existing
in two different persons’ images (Figure 1.b): it char-
acterizes the inter-class similarity. Before performing
the persons’ matching, intra and inter feature vectors
are normalized by dividing each element by the sum
of the corresponding vector.
Figure 1: Intra-class (a) and inter-class (b) vector of two
people.
The similarity measure between two persons’ im-
ages depends on intra and inter feature vectors accord-
ing to Equation 1:
similarity = w
1
[1− std(V
ter
)]+
w
2
[1− (std(V1
tra
−V2
tra
))]
(1)
where V1
tra
, V2
tra
are the feature vectors for both
intra-persons, V
ter
is the inter-person characteristic
vector, std is the standard deviation which represents
the difference whatsoever intra or inter people, and w
1
and w
2
are the weights assigned respectively to intra
and inter-person similarity. According to an experi-
mental study, parameters w
1
and w
2
are fixed to 0.5 to
ensure optimal performances.
2.2 Existing Descriptors
To represent persons in multi-camera context, we
have tested as color descriptors, the color histogram
and the spatiogram which is a color histogram exten-
sion incorporating spatial intensity distribution. As
texture descriptor, we have used the co-occurrence
matrix and the Schmid and Gabor filters. Also, we
have tested the most popular shape descriptors used
in literature like the histogram of oriented gradients
(HOG) and the Zernike and Hu moments. All already
introduced descriptors are more explained in (Derbel
et al., 2012).
RobustDescriptorsFusionforPedestrians'Re-identificationandTrackingAcrossaCameraNetwork
93
3 PEOPLE RE-IDENTIFICATION
3.1 VIPeR Dataset
To evaluate the performance of each descriptor in
terms of re-identifying a person in a camera network,
we have used the VIPeR image database (Gray and
Tao, 2008) that contains 632 pedestrians’ image pairs
taken from different points of view with large lighting
conditions variations. All images are spatially nor-
malized as 128× 48 pixels.
3.2 Evaluation Protocol and Results
Before extracting color and texture feature vectors, a
Greyworld normalization is applied to all the pedes-
trians’ images. This normalization reduces the effect
of large color variations caused by lighting condition
changes between cameras.
The descriptors extraction phase is performed on
each image according to different settings. For each
category of descriptors, different configurations are
tested by varying the color space, the quantization
step (number of bins) for color descriptors, only the
quantization step for texture descriptors and the block
size for the Histogram of oriented gradients which is
the only local shape descriptor used in this work.
Taking into account all configurations, a set of 41
feature vectors are extracted from each image. To
minimize the computation time, we have used only
the first half of the VIPeR dataset (that is to say
N=316 pedestrians’ images pairs). Next, we calculate
the inter-images similarity by computing the Bhat-
tacharyya distance between each descriptor variant:
41 × N
2
distance measurements. To have distance
measurements between 0 and 1, all extracted feature
vectors are normalised by dividing each element by
the sum of the corresponding vector.
The comparison is based on the CMC precision
measurement (Alahi et al., 2010) (Gray and Tao,
2008) (Prosser et al., 2010) that represents the cor-
rect identification rate according to a rank. To do this,
each descriptor’s distance measurements are stored in
a matrix of size N × N. The diagonal contains the
similarity of the same pedestrian pair that should be
the maximum in each matrix line. For each matrix
row noted i, d(i) represents the number of matches
showing greater similarity compared to the diagonal.
For a given rank n, the recognition rate (normalized
between 0 and 1) cumulates the results of all lines
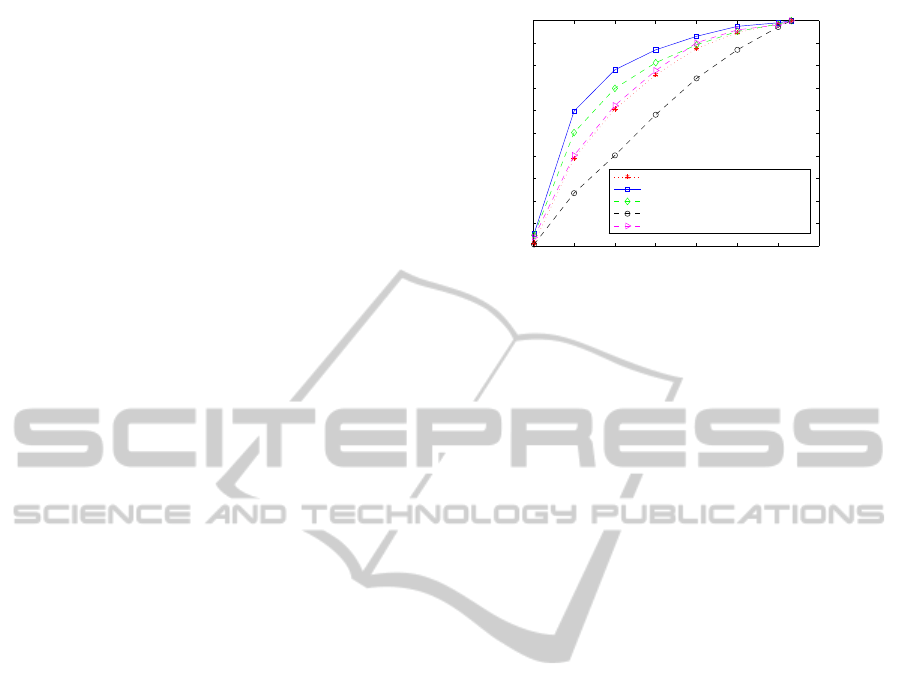
boolean test (when d(i) ≤ n). Figure 2 shows the per-
formance of the best descriptors of each category.
0 50 100 150 200 250 300 350
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Rang
Recognition Rate
Color Histogram(YCBCR,8 bins)
Spatiogram(HSV,16 and 32 bins)
Regional histograms(RGB,16 and 32 bins)
HOG (16 cells)
Co−occurrence Matrix(32 bins)
Figure 2: Best descriptors of each category.
4 PEOPLE TRACKING AND
RE-IDENTIFICATION
4.1 PETS 2009 and CVLAB Databases
To evaluate simultaneously the descriptors perfor-
mances in terms of multi-camera people tracking
and re-identification, we have used the two pedes-
trians’ images databases PETS 2009 (Sharma et al.,
2009) and CVLAB (Fleuret et al., 2008). These two
databases contain many peoples’ sequences filmed by
different cameras and including large pose and light-
ing conditions changes, scale variation and partial oc-
clusions.
We have selected 606 person’s images from the
PETS 2009 database representing four pedestrians
and 900 person’s images from the CVLAB database
representing three pedestrians taken from three dif-
ferent cameras. For each person filmed by a camera,
all the extracted images are temporally successive al-
lowing us to evaluate the multi-camera pedestrians’
tracking and re-identification performances.
Preprocessing includes the following steps: (1)
background subtraction, (2) morphological filtering,
(3) people detection and bounding box tracing and fi-
nally (4) spatial and color image normalization. In
both databases, all persons are in standing position.
For this reason, a foreground detected region is con-
sidered a pedestrian when its height is twice greater
than its width.
4.2 Evaluation Protocol and Results
This second test consists in evaluating the perfor-
mance of the best descriptors for each category se-
lected from the previous comparative study (Figure
2) simultaneously in terms of people tracking and re-
identification. In fact, the representative power of
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
94

each descriptor can be measured by the average sim-
ilarity for the same person
ˆ
SP, the average similar-
ity for different persons
ˆ
DP, and the number of false
alarms that represents the number of times where the
same person’s similarity is less than the different per-
sons’ similarity (S
m,i|m, j
< S
m,i|n, j
). All these parame-
ters are clarified by Equation 2.
ˆ
SP
m,i|n, j
=
1
Zp
∑
S
m,i|n, j
if m = n (2)
ˆ
DP
m,i|n, j
=
1
Zn
∑
S
m,i|n, j
if m 6= n
S
m,i|n, j
=
1
T
∑
T
t=1
d
B
(V
m,i,t
,V
n, j,t+1
)
T = min(nb
m,i
, nb
n, j
)
where m and n represent the person’s identities, i and j
represent the different cameras used, Z
p
and Z
m
repre-
sent respectively the number of same-person’s (when
m=n) and different-persons’(when m6=n) matching, S
represents the average similarity between two pedes-
trians’ sequences, t is the chronological order of the
person’s image in the sequence, T is the number of
matches made to compare two persons’ sequences,
d
B
is the Bhattacharyya distance between two feature
vectors, V represent the feature vector and nb is the
number of frames in a sequence.
For each descriptor,
ˆ
SP and
ˆ
DP are calculated by
making temporally successive matches between the
same camera pedestrians’ images (tracking case) and
between the different cameras pedestrians’ images
(re-identification case). A robust descriptor must ac-
centuate the gap between
ˆ
SP and
ˆ
DP and minimize
the number of false alarms. Table 1 summarizes all
the obtained results.
4.3 Performances Analysis and
Interpretation
The results presented in Table 1 confirm those ob-
tained from the first comparative study (Figure 2). In
fact, it is very clear that the descriptor ranking accord-
ing to the people representation power is as follows:
1) Spatiogram (HSV 16 bins), 2) Proposed descriptor
(RGB, 16 bins), 3) Co-occurrence matrix (32 bins),
4) Color histogram (YCbCr, 8 bins) and 5) HOG (16
cells).
Since color and texture descriptors are the best
feature vectors, we propose to combine them using
the AdaBoost algorithm in order to find the best con-
figuration that ensures good performances in terms of
pedestrians’ re-identification in multi-camera.
5 PROPOSED APPROACH AND
COMPARATIVE STUDY
In this section, we introduce firstly the proposed ap-
proach intended to ensure a proper multi-camera peo-
ple identification and secondly a comparative study
with the main existing works in literature.
5.1 Proposed Approach
In the first stage, we have divided randomly the
VIPeR dataset into two equivalents portions (the first
one is for learning and the second one is for testing).
Both portions contain N=316 pairs of pedestrians,
each taken from two different cameras. During the
learning phase, we have calculated an N × N matrix
”D” containing Bhattacharyya distances between two
cameras learning images for the most robust descrip-
tors that are shown in Figure 3. Each matrix contains
N positive training examples (positive distribution in
diagonal) and N × (N − 1) negative training examples
(negative distribution otherwise). Three distributions
can be applied on each matrix ”D” such as Gaus-
sian, Exponential or Gamma distribution (Gray and
Tao, 2008). According to an experimental study, we
choose the Exponential distribution that maximizes
the number of 1 in the diagonal and the number of
-1 otherwise for all selected descriptors.
In fact, an Exponential matrix ”E” is obtained
from each descriptor’s matrix ”D” as follows (Equa-
tion 3).
E(i, j) =
1 if a× D(i, j) + b ≻ 0
−1 otherwise
(3)
The coefficients a and b can be expressed in term
of the estimated parameters of positive distribution
(in diagonal) and negative distribution (otherwise)
calculated from each matrix ”D” as Equation 4.
a = λ
n
− λ
p
, b = ln(λ
p
) − ln(λ
n
) (4)
λ
n
=
1
µ
n
, λ
p
=
1
µ
p
where µ
p
and µ
n
are respectively the mean of positive
and negative distributions in matrix ”D”.
In the second stage, the Adaboost algorithm is ap-
plied for selected descriptors on matrices ”E” in order
to calculate a weight for each one. In this work, we
have performed two experiments: (a) cascade of color
descriptors and (b) cascade of color and texture de-
scriptors. We do not use shape descriptors in the pro-
posed cascade because they give poor performances
(Figure 2). Figure 3 shows all selected feature vectors
and their respective weights for each experiment.
RobustDescriptorsFusionforPedestrians'Re-identificationandTrackingAcrossaCameraNetwork
95
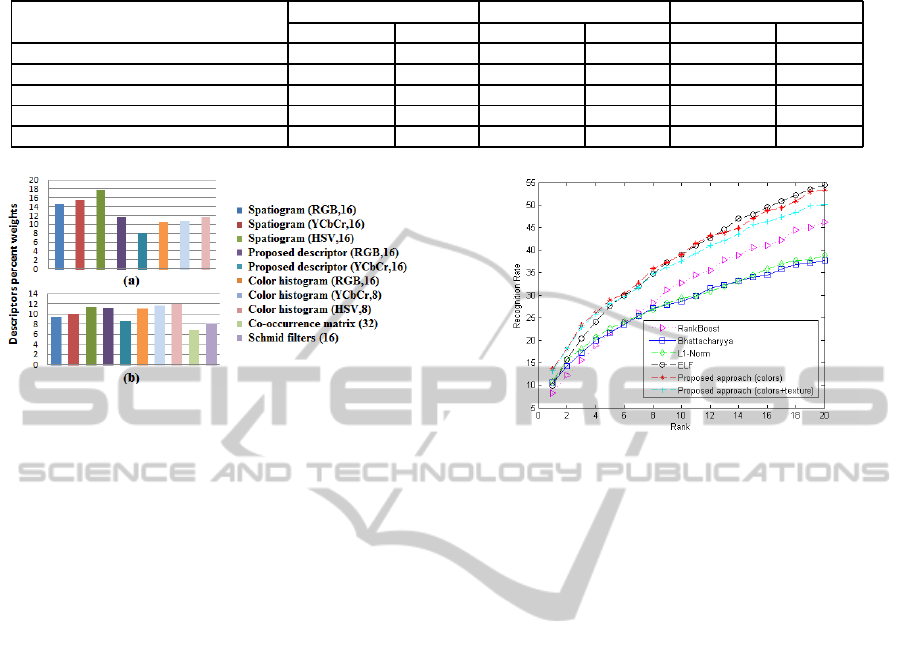
Table 1: People re-identification and tracking performances analysis.
Performances
ˆ
SP
ˆ
DP Number of false alarms
Descriptors PETS 2009 CVLAB PETS 2009 CVLAB PETS 2009 CVLAB
Color histogram (YCbCr,8 bins) 98.91 99.54 97.73 98.24 2 2
Spatiogram (HSV,16 bins) 87.42 93.87 76.54 87.37 2 2
Proposed descriptor (RGB,16 bins) 97.38 95.67 91.94 91.33 0 1
Co-occurrence matrix (32 bins) 98.00 99.05 93.23 96.65 3 2
HOG (16 cells) 73.49 80.11 69.97 70.65 11 4
Figure 3: Descriptors percent weights: (a) color descriptors
cascade (b) color and texture descriptors cascade.
To reduce the search space and more separate dif-
ferent people, these relative descriptors weights will
be applied on matrix E
T
where E
T
is the Exponential
matrix calculated from testing images (Equation 5).
CSM =
n
∑
i=1
α
i
× E
Ti
(5)
where CSM is the Cascade Similarity Matrix, E
Ti
and
α
i
represent respectively the Exponential testing ma-
trix and the relative weight for the i
th
selected descrip-
tor.
Ambiguity cases (two different matching with the
same rank) are managed by Spatiogram (HSV, 16
bins) Bhattacharyya matrix chosen because it is the
strongest descriptor (Figure 2). Experimental results
are presented in the next section.
5.2 Comparative Study with Existing
Works
Here, we compare the two variants of our proposed
approach (cascade of color descriptors and cascade of
color and texture descriptors) with two categories of
approaches which are tested in (Prosser et al., 2010):
(i) non-learning methods (Bhattacharyya (Prosser
et al., 2010), L1-norm (Prosser et al., 2010)) and (ii)
learning methods using AdaBoost (ELF (Gray and
Tao, 2008), RankBoost (Freund et al., 2003)).
Since we have been interested in evaluating the
impact of the descriptors choice on the recognition
rate, we have used the Ababoost classifier which is
widely applied in literature. In fact all introduced ex-
isting approaches use color histograms and Gabor and
Figure 4: CMC curve for different approaches.
Schmid filters to represent pedestrians. However our
proposed color approach uses the color histograms,
the spatiograms and the proposed descriptors. The
proposed color/texture one retain all feature vectors
used in the color proposed approach and add the co-
occurrence matrix and Schmid filters as explained in
Figure 3. Experimental results are shown in Figure
4 representing the performance for lower rank-orders
(up to 20) which are the most significant in CMC
measure.
Figure 4 indicates that non-learning approaches
(Bhattacharyya or L1-norm) are not efficient to iden-
tify a person in a multi-camera context. This is due
to the high number of possible matches and also to
the large variation in poses and lighting conditions in
the VIPeR dataset that cannot be bypassed by a sim-
ple distance and without using a learning phase. Fig-
ure 4 shows too that our two proposed approaches are
more efficient compared to ELF since the recognition
rate has increased about 3% (up to rank 8) and Rank-
Boost approaches even if they all use the same clas-
sifier. This proves that the used descriptors are more
representative in terms of multi-camera people iden-
tification. The slight superiority of the ELF approach
for (rank ≻ 12) can be explained by using the absolute
difference which has a great separation power com-
pared to the Bhattacharyya distance used in our work.
Looking at the performances of the two proposed
approaches, we can conclude that the integration of
texture descriptors slightly deteriorates the perfor-
mance proving that the fusion of only robust color de-
scriptors (color histogram, spatiogram and proposed
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
96

regional histograms) represents the best strategy to
identify pedestrians in a multi-camera context.
6 CONCLUSIONS AND FUTURE
WORKS
In this paper, we have introduced a new regional
color histograms feature vector to characterize a per-
son which is integrated into an extensive comparative
study between different existing descriptors based on
color, texture and shape information applied to peo-
ple re-identification and tracking in multi-camera. To
ensure this objective, two separate tests have been
performed. The first one consists in evaluating the
performances of already introduced feature vectors in
terms of people re-identification as CMC curves on
VIPER pedestrians dataset. The second test, that is
more generic, allows us to evaluate simultaneously
the discriminatory power of these descriptors in terms
of persons tracking and re-identification.
Given the complexity of the multi-camera pedes-
trians re-identification and the number of constraints
to manage, a new approach based on a fusion of de-
scriptors selected from two performed comparative
studies is presented in this paper. Two variants of the
proposed approach (cascade of color descriptors and
cascade of color and texture descriptors) are tested
and compared with several existing approaches. Ex-
perimental results show that the proposed color-based
approach provides very satisfactory performances de-
spite the highly articulated human body, lighting con-
ditions changes and large pose variations.
Future work will focus on developing a robust
behavioral analysis module and merging it with the
proposed cascade of color descriptors to improve the
multi-camera people tracking and identification per-
formances.
REFERENCES
Alahi, A., Vandergheynst, P., and Bierlaire, M. (2010). Cas-
cade of descriptors to detect and track objects across
any network of cameras. Computer Vision and Image
Understanding, 114(6):624–640.
Cai, Y., Huang, K., and Tan, T. (2008). Matching tracking
sequences across widely separated cameras. Interna-
tional Conference on Image Processing, pages 765–
768.
Derbel, A., Ben Jemaa, Y., Canals, R., Emile, B., Treuillet,
S., and Ben Hamadou, A. (2012). Comparative study
between color texture and shape descriptors for multi-
camera pedestrians identification. IEEE International
Conference on Image Processing Theory Tools and
Applications, pages 313–318.
Fleuret, F., Berclaz, J., Lengagne, R., and Fua, P. (2008).
Multi-camera people tracking with a probabilistic oc-
cupancy map. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 30(2):267–282.
Freund, Y., Iyer, R., Schapire, R. E., and Singer, Y. (2003).
An efficient boosting algorithm for combining prefer-
ences. Journal ofMachine Learning Research, 4:933–
969.
Gilbert, A. and Bowden, R. (2006). Tracking ob-
jects across cameras by incrementally learning inter-
camera colour calibration and patterns of activity. Eu-
ropean Conference on Computer Vision, pages 125–
136.
Gray, D. and Tao, H. (2008). Viewpoint invariant pedes-
trian recognition with an ensemble of localized fea-
tures. European Conference on Computer Vision,
pages 262–275.
Nam, Y., Ryu, J., Choi, Y., and Cho, W. (2007). Learning
spatio-temporal topology of a multi-camera network
by tracking multiple people. World Academy of Sci-
ence Engineering and Technology, 24:175–180.
Prosser, B., Zheng, W. S., Gong, S., and Xiang, T. (2010).
Person re-identification by support vector ranking.
British Machine Vision Conference, pages 1–11.
Sharma, P. K., Huang, C., and Nevatia, R. (2009). Evalua-
tion of people tracking, counting and density estima-
tion in crowded environments. IEEE Int’l Workshop
Perf. Eval. of Tracking and Surveillance, pages 39–46.
Truong Cong, D. N., Meurie, C., Khoudour, L., Achard, C.,
and Lezoray, O. (2010). People re-identification by
spectral classification of silhouettes. Signal Process-
ing, 90(8):2362–2374.
Tung, T. and Matsuyama, T. (2008). Human motion track-
ing using a color-based particle filter driven by optical
flow. InternationalWorkshop on Machine Learning for
Vision-based Motion Analysis.
Yang, C., Duraiswami, R., and Davis, L. (2005). Fast mul-
tiple object tracking via a hierarchical particle filter.
IEEE International Conference on Computer Vision,
pages 212–219.
RobustDescriptorsFusionforPedestrians'Re-identificationandTrackingAcrossaCameraNetwork
97
