
Sparse Motion Segmentation using Propagation of Feature Labels
Pekka Sangi, Jari Hannuksela, Janne Heikkil¨a and Olli Silv´en
Center for Machine Vision Research, Department of Computer Science and Engineering, University of Oulu, Oulu, Finland
Keywords:
Motion Segmentation, Block Matching, Confidence Analysis.
Abstract:
The paper considers the problem of extracting background and foreground motions from image sequences
based on the estimated displacements of a small set of image blocks. As a novelty, the uncertainty of local
motion estimates is analyzed and exploited in the fitting of parametric object motion models which is done
within a competitive framework. Prediction of patch labels is based on the temporal propagation of labeling
information from seed points in spatial proximity. Estimates of local displacements are then used to predict
the object motions which provide a starting point for iterative refinement. Experiments with both synthe-
sized and real image sequences show the potential of the approach as a tool for tracking based online motion
segmentation.
1 INTRODUCTION
Detection, segmentation, and tracking of moving ob-
jects is a basic task in many applications of computer
vision such as visual surveillance and vision-based in-
terfaces. In absence of a priori appearance models,
solutions must be based on observed image changes
or apparent motions. In the case of a moving cam-
era, one approach is to perform motion segmentation
where scene objects are detected based on their mo-
tion differences (Tekalp, 2000).
One particular approach to motion-based segmen-
tation is to estimate or track the motion of a set of
feature points whose association provides the approx-
imate segmentation of regions of interest and corre-
sponding parametric motions (Wong and Spetsakis,
2004; Fradet et al., 2009). Due to the potential unre-
liability of local motion estimation, such approaches
either use point detectors to find regions with suit-
able texture, and/or incorporate various mechanisms
for detecting or analyzing unreliability (Wills et al.,
2003; Wong and Spetsakis, 2004; Kalal et al., 2010;
Hannuksela et al., 2011).
When processing is done for long image se-
quences mechanisms are needed for maintaining the
coherence of the motions, segmentations, and appear-
ances of the objects (Tao et al., 2002). One approach
here is to use dynamics based filtering such as Kalman
filter (Tao et al., 2002). (Tsai et al., 2010) optimize
energy functions which model the coherence within
and across frames. (Karavasilis et al., 2011) main-
tain temporal coherence by performing the clustering
of feature trajectories. In (Lim et al., 2012), back-
ground/foregroundsegmentations which are based on
a regular block grid are linked according to displace-
ments obtained by block matching. (Odobez and
Bouthemy, 1995b) propagate dense segmentation in-
formation using the parametric motion estimates of
the segmented regions.
Various principles have been used to imple-
ment motion segmentation algorithms as discussed
in (Tekalp, 2000; Zappella et al., 2009), for exam-
ple. The competitive approach, implemented typi-
cally with the Expectation Maximisation (EM) algo-
rithm to find a maximum likelihood solution, has been
widely used (see (Karavasilis et al., 2011; Pundlik
and Birchfield, 2008; Tekalp, 2000; Wong and Spet-
sakis, 2004)). In our first contribution, we consider
a method based on this approach, and derive a tech-
nique where the temporal propagation of feature seg-
mentation information is integrated into competitive
refinement. Prediction is based on the segmentation
of the previous frame and estimated block displace-
ments. The approach is reminiscent to propagation
in (Odobez and Bouthemy, 1995b) and (Lim et al.,
2012) who also use motion estimates in some form
for temporal propagation; in our case, coarse feature-
based segmentation is considered. As a second con-
tribution, we use the results of directional uncertainty
analysis of block matching and show experimentally
that use of such uncertainty information can improve
the performance of online sparse segmentation.
396
Sangi P., Hannuksela J., Heikkilä J. and Silvén O..
Sparse Motion Segmentation using Propagation of Feature Labels.
DOI: 10.5220/0004281203960401
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 396-401
ISBN: 978-989-8565-48-8
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2 PROPOSED METHOD
In motion estimation, correspondencesfor regions ob-
served in the anchor frame are sought for in the tar-
get frame which correspond to temporally earlier and
later frames in forward estimation. Based on track-
ing and assumptions on spatial coherence, the predic-
tion of segmentation can be based on the alternation
of temporal and spatial propagation. This idea pro-
vides the basis of the proposed method.
2.1 Motion Features
Our approach analyzes the observation of interframe
motion encoded as so-called motion features which
are triplets (p
n
, d
n
, C
n
) where p
n
= [x
n
, y
n
]
T
is the lo-
cation of a block in the anchor frame, d
n
= [u
n
, v
n
]
T
denotes an estimate of its displacement in the target
frame, and C
n
is a 2×2 covariancematrix which mea-
sures directional uncertainty related to the displace-
ment estimate, that is, it quantifies the aperture prob-
lem associated with the block and its neighborhood.
The image area is divided into N
feat
rectangular
subregions, and location for a block, p
n
, is selected
from each region n. The minimum eigenvalue of the
second moment matrix of local image gradients (2D
structure tensor) is used as the basic criterion here.
To reduce the amount of computations, this image-
based selection technique is complemented with fea-
ture tracking which generates points from the motion
features of the previous frame pair.
In our experiments, the estimation of the displace-
ments d
n
is based on the evaluation of the sum of
squared differences (SSD) or some related measure
over the block pixels. The fittings of quadratic poly-
nomials to SSD surface at the minimum are used
to obtain an estimate with subpixel accuracy. The
match surface is also used as a basis for computing
the covariance matrix C
n
as is done in (Nickels and
Hutchinson, 2001). For this purpose, we use the gra-
dient based method detailed in (Sangi et al., 2007).
2.2 Estimating Parametric Motions
Linear parametric models are used to approximate 2-
D motion of background and foreground areas (called
objects in the following). With such models, the in-
duced displacement d at image point p is computed
by multiplication d = H[p]θ where H[p] is the map-
ping matrix, and θ is the parameter vector.
Weighted least squares (WLS) regression is used
to both predict and refine object motion models.
Due to the aperture problem, the estimates of local
displacements carry varying amount of information
about the local motion. In addition, if the patch is not
associated with the object of interest there is no infor-
mation about the object motion. These notions about
informativeness are combined in 2 × 2 observation
weight matrices W
(i)
n,o
which are derived from the ma-
trices C
n
and object association weights w
(i)
n,o
∈ (0, 1)
(o = 1, 2). Particularly, we use the formulation
W
(i)
n,o
= [w
(i)
n,o
]
a
C
−1
n
(1)
where a is a positive parameter. The superscript (i)
refers here to ith iteration in refinement; i = 0 corre-
sponds to the prediction step.
Let G
(i)
o
= {(p
n
, d
n
, W
(i)
n,o
)}
N
feat
n=1
be the weighted
motion feature set obtained for the object o. Then,
the associated estimate of θ is
ˆ
θ
(i)
o
= (H
T
W
(i)
o
H)
−1
H
T
W
(i)
o
z (2)
where z is a vector composed of feature displace-
ments d
n
, H is a vertical concatenation of matrices
H
n
= H[p
n
], and W
(i)
o
is a block diagonal matrix com-
posed of W
(i)
n,o
. Moreover, interpreting W
(i)
o
as in-
verse error covariance matrices we estimate the mo-
tion model error covariance as
P
(i)
o
= (H
T
W
(i)
o
H)
−1
(3)
and use it for error propagation in computations.
2.3 Association Weights in Prediction
Based on the estimated displacements d
n
of fea-
ture points, we can propagate association information
from the anchor to the target frame. In addition, the
target frame of the previous frame pair is the anchor
frame of the current frame pair which provides an ap-
proach to propagate association information between
frame pairs based on spatial proximity. We expect that
if two patches are close to each other then it is likely
that they have the same association. This principle is
illustrated in Fig. 1.
We formulate this by measuring the proximity of
image points with their Euclidean distance. Let w
′
m,o
(m = 1, . . . , M) be the given probabilistic weights for
the association of the seed points p
′
m
with the object o
(
∑
o
w
′
m,o
= 1). The predicted association weight, w
n,o
,
for a point p
n
is computed as a weighted average
w
(0)
n,o
=
∑
M
m=1
u(p
n
, p
′
m
)w
′
m,o
∑
M
m=1
u(p
n
, p
′
m
)
(4)
where u(·) is the weighting function. Exponential
mapping of the Euclidean distance is used to derive
the weights: u(p, p
′
) = exp ( r kp
′
−pk
2
2
) where k·k
2
denotes the L2 norm, and r is a scaling parameter.
SparseMotionSegmentationusingPropagationofFeatureLabels
397

Figure 1: Propagation of feature labeling: motion features
of the previous frame pair (k − 1, k) provide seed points for
frame k which are then used to predict labeling of features
A, B, C. Based on seed points, B and C are predicted to be
associated with the same object. However, based on the ob-
served motion of these features and refined object motions,
the labeling of C changes here.
Using these weights, the prediction of object mo-
tions is based on Eq. 2 where small random values are
added to the components of
ˆ
θ
(0)
o
in order to have dis-
tinct motion models as a starting point for refinement.
2.4 Competitive Refinement
Refinement of predicted motion estimates is based
on the competitive paradigm where estimation is per-
formed by iterating two steps, reweighting of data and
updating of parametric models. As described above,
we use WLS estimation to implement motion model
refinement. Bayesian formulation for updating local
association weights is used during refinement as fol-
lows.
Let the current estimates of object motions and as-
sociated covariances be θ
(i)
o
and P
(i)
o
, and let the cor-
responding association weights be w
(i)
n,o
. New associ-
ation weights, w
(i+1)
n,o
, are obtained by weighting old
values according to differences between the observed
local displacements and displacements induced by
object motion models. The estimated errors of motion
features and object motion estimates are used to form
Gaussian likelihood functions q
(i)
n,o
(d) whose mean is
H
n
θ
(i)
o
and covariance H
n
P
(i)
o
H
T
n
. The Bayes rule is
then used to update the association weights according
to (
∑
o
w
(i+1)
n,o
= 1)
w
(i+1)
n,o
∝ q
(i)
n,o
(d
n
)w
(i)
n,o
. (5)
It should be noted that if there is no independent
foreground motion the motion estimates are close
to each other q
(i)
n,1
(d
n
) ≈ q
(i)
n,2
(d
n
), and the algorithm
tends to keep the association weights equal to predic-
tion. This supports maintaining object location infor-
mation if the independent object motion stops for a
moment, and therefore provides a mechanism for han-
dling the temporary stopping problem (Zappella et al.,
2009).
2.5 Computational Cost
The derived algorithm is summarized in Fig. 2. Itera-
tion of Step 4 may also stop after Step 4(a) has been
evaluated. In Step 5, sparse segmentation for the tar-
get frame is produced using the current feature points
p
n
and their displacements d
n
. The segmentation is
soft and uses the association weights computed in the
last iteration. Only one weight, w
(N
iter
)
n,1
, is saved as
the sum of object weights is one. These points are
also used as the seed points in processing of the next
frame pair.
Considering the computational cost with M =
N
feat
seed points, Step 1 takes time O(N
2
feat
) whereas
the cost of other steps is O(N
feat
). However, in evalu-
ation of predicted associations it is necessary to con-
sider only seeds in the 3 × 3 neighborhood of subre-
gions, and then then the cost of Step 1 is too O(N
feat
).
1
Inputs: a set of motion features, a set of seed points
Outputs: object motion estimates, sparse segmentation of the
target frame
1. Predict associations w
(0)
n,o
of each motion feature using
(4) and given seed points.
2. Compute the weight matrices W
(0)
n,o
using (1).
3. Make the predictions of object motions,
ˆ
θ
(0)
o
, using (2)
with added perturbation. Compute error covariances
P
(0)
o
using (3).
4. Iteratively refine estimates (i = 1, . . . , N
iter
):
(a) Compute new estimates of association weights, w
(i)
n,o
,
using (5).
(b) Compute weight matrices W
(i)
n,o
using (1).
(c) Compute estimates of object motions,
ˆ
θ
(i)
o
, using (2).
Compute also P
(i)
o
if needed.
5. Derive sparse segmentation for the target frame as the
set of pairs(p
n
+ d
n
, w
(N
iter
)
n,1
).
Figure 2: Derived algorithm for two-motion extraction.
3 EXPERIMENTS
Experimental work concentrates on showing the effi-
cacy of algorithmic solutions. To make quantitative
comparisons, synthesized image sequences were gen-
erated and ground truth information about object mo-
1
Computation of a Matlab implementation takes 29 ms
for motion features (implemented partly in C) and 10 ms for
the motion extraction (64 8× 8 blocks, AMD Opteron 2.4
GHz Linux server).
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
398
tion models is used as a basis for quantitative mea-
sures of performance. Emphasis in the performance
analysis here is on the precision of motion estimates.
In practice, we match estimated motions with the
groundtruth motions, and then compute the root mean
square error (RMSE) over the ground truth support
regions. It can be shown that the RMSE measure
is related to performance in motion content analysis:
RMSE should stay below about 1 pixel, and on aver-
age it should be at the level of 0.1 − 0.2 pixels with
synthetic sequences.
Synthesized sequences were generated by sim-
ulating the background motion for eight different
scenes, and pasting moving textured objects of var-
ious size to those sequences. In addition, we stud-
ied the performance of the motion extraction with
real sequences visually by checking the association
of features to moving objects, and performing post-
segmentation using available motion estimates.
3.1 Efficacy of Feature-based Prediction
In the first experiment, performance of the proposed
WLS based prediction-refinement method (denoted
WLSPR) is evaluated against two variants which use
Kalman filtering to implement motion estimation.
Both variants perform the propagation of segmenta-
tion as described in Sec. 2.3. In the first variant, de-
noted W-KP-KF, the stages of Kalman filtering are
substituted for both prediction (Step 3 in Fig. 2) and
estimation (Step 4c) of motions. In the second variant,
denoted WLSP-KF, prediction uses WLS and only fi-
nal estimate is computed using Kalman filtering (Step
4c). Motion dynamics in W-KP-KF is based on an
assumption about the constant motion of objects.
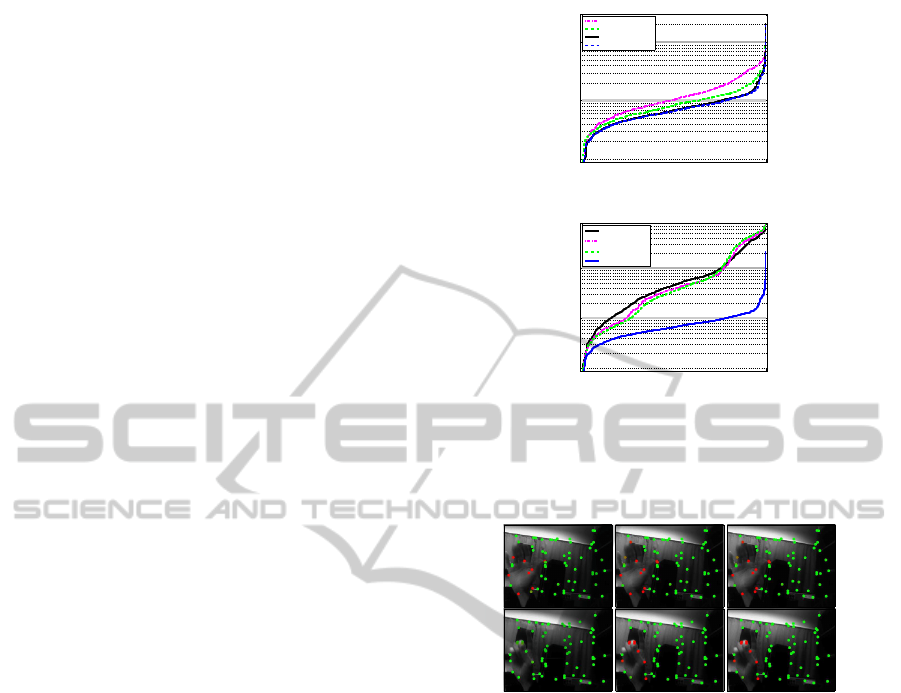
The RMSE precision of the estimates, sorted in
ascending order, is shown in Fig. 3(a). It can be
seen that the proposed approach provides more pre-
cise estimates than its variants on average. The me-
dian RMSE value with WLSPR is 0.07 pixels whereas
it is 0.10 for W-KP-KF and 0.08 for WLSP-KF. In
addition, we note that single iteration can already be
sufficient for refinement.
Weakness of dynamics-based motion prediction is
observed in situations where the direction of motion
changes. This fact is illustrated using real video in
Fig. 4 where W-KP-KF does not assign any features
with the foreground object after motion change oc-
curring in the video whereas feature-based prediction
is not so sensitive. In effect, WLSP-KF and WL-
SPR produce the same soft segmentation as can be
seen from Fig. 4 but weighted combination in filter-
ing tends to increase the error in the final object mo-
tion estimates, and therefore WLS also in refinement
1 800
10
−2
10
−1
10
0
Analyzed frame pair instance (sorted)
RMSE [pixels]
W−KP−KF
WLSP−KF
WLSPR (Niter=1)
WLSPR (Niter=2)
(a)
1 800
10
−2
10
−1
10
0
Analyzed frame pair instance (sorted)
RMSE [pixels]
No UA, σ
2
=4
No UA, σ
2
=1
No UA, σ
2
=0.25
With UA
(b)
Figure 3: (a) Comparison of the method against Kalman
filter configurations. (b) Comparison to estimation which
does not exploit uncertainty analysis.
#65
W−KP−KF WLSP−KF WLSPR
#71
Figure 4: Example of failure of dynamics-based prediction
(Hand sequence).
is preferred.
3.2 Utility of Uncertainty Information
The second experiment checks whether the compu-
tation of uncertainty estimates, covariances C
n
, done
according to the gradient-based analysis (Sangi et al.,
2007), is useful in the proposed method. To do this,
the weight matrices (see Eq. 1) are set alternatively
as W
(i)
n,o
= [w
n,o
]
a
σ
2
I where I denotes a 2 × 2 iden-
tity matrix, and σ
2
is a constant variance parameter.
In Fig. 3(b), the results with synthesized sequences,
computed with different choices of σ
2
, are illustrated
and compared against the result obtained with WL-
SPR (2 refinement iterations used in each case). It
can be seen that the precision of estimates is improved
significantly with uncertainty analysis, and large er-
rors are avoided.
In the experiment with real sequences, the qual-
ity of sparse segmentation was evaluated visually by
the comparison of feature assignments provided by
SparseMotionSegmentationusingPropagationofFeatureLabels
399
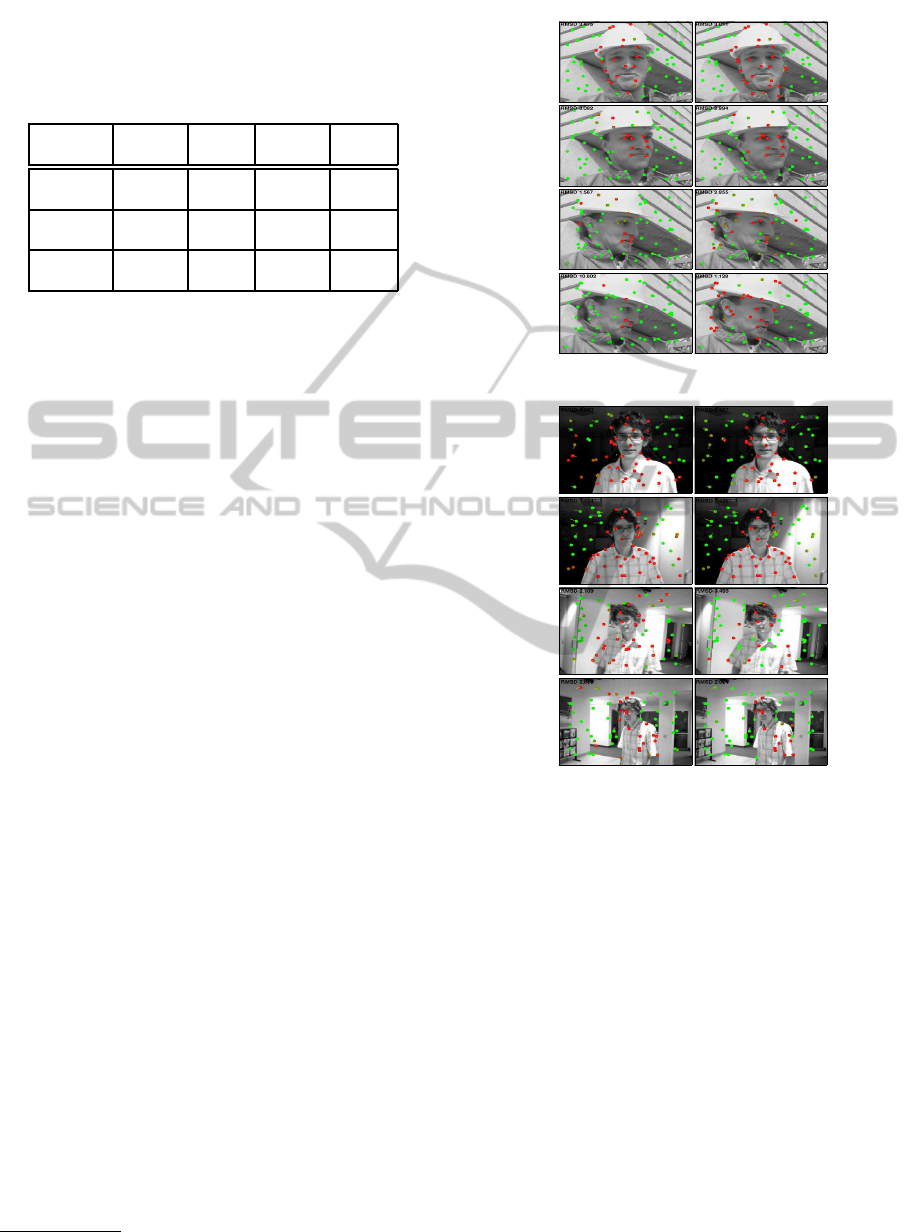
Table 1: Result with real videos based on visual check of
quality of feature assignments when motion uncertainty in-
formation is used (w/UA) and not used (wo/UA). The 2nd
and 3rd column consider absolute quality of assignments
whereas 4th and 5th column evaluate their relative quality.
Sequence # wo/UA # w/UA # wo/UA # w/UA
[# frames] good good better better
Hand
104 177 12 131
[201]
Foreman
148 148 37 60
[185]
David
102 156 21 124
[201]
the alternatives (σ
2
was set to 1.0 when uncertainty
information was not used). When the number of mis-
labellings (64 features used) was observed to be less
than three, the segmentation was considered a good
one in this experiment. In addition, we compared
the segmentation qualities. The figures obtained in
this way are given in Table 1, and it can be seen that
segmentations obtained using uncertainty information
were better on average.
Examples of related segmentations are given in
Fig. 5.
2
In the case of the Foreman sequence,
Fig. 5(a), segmentation of the face area does not typi-
cally extend to the area of the helmet and shirt due to
the absence of texture and similarity with the back-
ground motion, respectively (see Frame 122). In
the frames 155-158, there is a moving hand in the
view which disturbs segmentation (see Frames 160
and 166). The solution which exploits uncertainty
analysis recovers from this situation already in the
Frame 161 whereas without uncertainty analysis seg-
mentation is poor until Frame 171.
In the experiment with the David sequence, the
background tends to get mislabellings more often
when uncertainty analysis is not used as illustrated in
Fig. 5(b). With uncertainty analysis, the largest errors
occur at the beginning of the sequence (Frames 2-7)
and when the person turns sideways(Frames 135-160,
check Frame 140). However, there are long periods
(Frames 64-103, 115-135, 170-200) where the seg-
mentation is very good (see Frame 80).
3.3 Comparison to a Reference Method
We also implemented two-motion extraction based on
the dominant motion principle (Tekalp, 2000). A ro-
bust multiresolution method for estimating paramet-
ric motion models (Odobez and Bouthemy, 1995a)
was applied sequntially, first to the whole image, and
then to that part of the image which did not support
2
See videos at http://www.ee.oulu.fi/research/imag/sms.
#50
wo/UA
w/UA
#122
#160
#166
(a) Foreman sequence.
#35
wo/UA
w/UA
#80
#140
#180
(b) David sequence.
Figure 5: Examples of sparse segmentation obtained with-
out and with uncertainty analysis.
the motion estimate obtained in the first step. In this
case, the method uses the whole image area as a ba-
sis for estimation which gives significant gain in per-
formance with synthetic sequences observable from
Fig. 6. To make the comparison with WLSPR more
fair, a fixed grid of blocks was also used as a reduced
estimation support, and the same set of blocks was
used to provide motion features for WLSPR. The ro-
bustness of WLSPR was better with the translational
motion model in this experiment (RMSE> 1 pixel in
5 versus 27 out of total of 800 frame pairs). In the
case of the four-parameter similarity motion model,
used for the results shown in Fig. 6, the robustness of
the methods was quite similar.
Finally, masks computed from motion compen-
sated frame differences are compared in Fig. 7 for the
Hand sequence. Small differences in the masks indi-
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
400
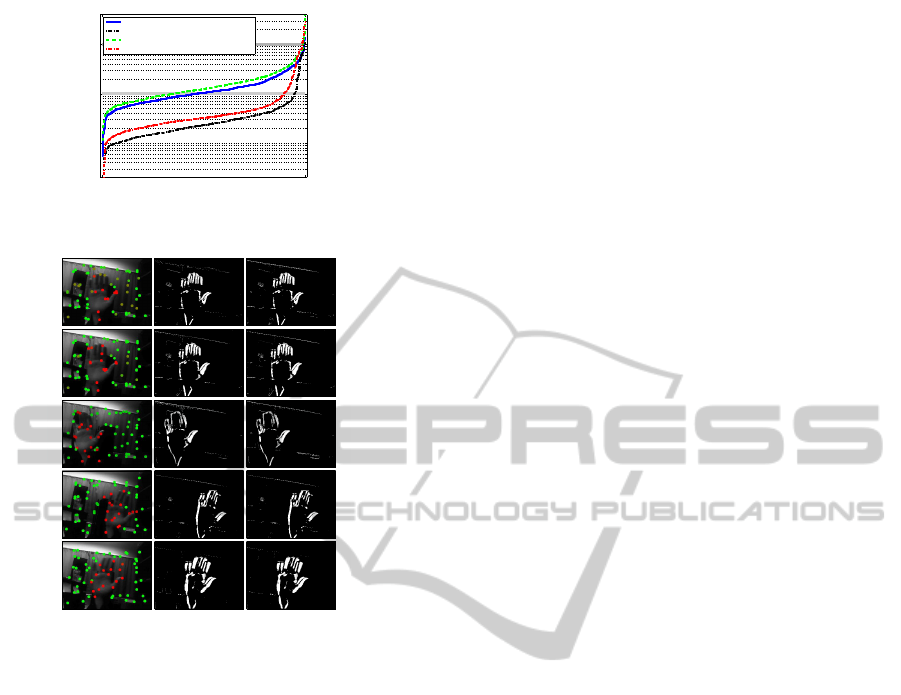
1 800
10
−2
10
−1
10
0
Analyzed frame pair instance (sorted)
RMSE [pixels]
WLSPR (64 features)
Ref. method (full support)
WLSPR (regular grid, 144 features)
Ref. method (regular grid, 12% support)
Figure 6: Comparison against the reference method.
#2
#3
#10
#30
#50
Figure 7: Snapshots from the experiment with the Hand
sequence, Left: patch/object assignment, Middle: segmen-
tation masks computed from the WLSPR output, Right:
masks computed from the reference output.
cate that the object motion estimates provide the same
level of performance in post-processing.
4 CONCLUSIONS
In this paper, we have proposed an approach to extrac-
tion of background and foregroundmotions where the
temporal propagation of probabilistic feature associa-
tions is done. This is based on estimated displace-
ments which provides labeled seed points. Spatial
proximity of the new feature patches to those points
is then used to predict the labelling of features. This
propagation technique was integrated with iterative
refinement under the WLS estimation framework.
Experiments show that feature-based prediction of
motion provides a better starting point for segmen-
tation than the approach using dynamics. In addi-
tion, experiments show importance of using direc-
tional uncertainty information about the block motion
estimates in improving the precision and robustness
of the feature-based approach.
REFERENCES
Fradet, M., Robert, P., and P´erez, P. (2009). Clustering point
trajectories with various life-spans. In Proc. Conf. on
Visual Media Production, pages 7–13.
Hannuksela, J., Barnard, M., Sangi, P., and Heikkil¨a, J.
(2011). Camera-based motion recognition for mobile
interaction. ISRN Signal Processing, Art. Id 425621.
Kalal, Z., Mikolajczyk, K., and Matas, J. (2010). Forward-
backward error: automatic detection of tracking fail-
ures. In Proc. Int. Conf. on Pattern Recognition, pages
2756–2759.
Karavasilis, V., Blekas, K., and Nikou, C. (2011). Mo-
tion segmentation by model-based clustering of in-
complete trajectories. In ECML PKDD, volume 6912
of LNAI, pages 146–161. Springer-Verlag.
Lim, T., Han, B., and Han, J. H. (2012). Modeling and
segmentation of floating foreground and background
in videos. Pattern Recognition, 45(4):1696 – 1706.
Nickels, K. and Hutchinson, S. (2001). Estimating uncer-
tainty in SSD-based feature tracking. Image and Vi-
sion Computing, 20:47–58.
Odobez, J. and Bouthemy, P. (1995a). Robust multiresolu-
tion estimation of parametric motion models. J. Vi-
sual. Comm. Image Repr., 6(4):348–365.
Odobez, J.-M. and Bouthemy, P. (1995b). Direct model-
based image motion segmentation for dynamic scene
analysis. In Proc. Asian Conf. on Computer Vision,
pages 306–310.
Pundlik, S. J. and Birchfield, S. (2008). Real-time motion
segmentation of sparse feature points at any speed.
IEEE Trans. SMC-B, 38(3):731–742.
Sangi, P., Hannuksela, J., and Heikkil¨a, J. (2007). Global
motion estimation using block matching with uncer-
tainty analysis. In Proc. European Signal Processing
Conf., pages 1823–1827.
Tao, H., Sawhney, H. S., and Kumar, R. (2002). Object
tracking with Bayesian estimation of dynamic layer
representations. IEEE Trans. PAMI, 24(1):75–89.
Tekalp, A. M. (2000). Video segmentation. In Bovik, A.,
editor, Handbook of Image & Video Processing, chap-
ter 4.9. Academic Press, San Diego.
Tsai, D., Flagg, M., and Rehg, J. M. (2010). Motion coher-
ent tracking with multi-label MRF optimization. In
Proc. British Machine Vision Conf.
Wills, J., Agarwal, S., and Belongie, S. (2003). What went
where. In Proc. IEEE Conf. on Computer Vision and
Pattern Recognition, volume 1, pages 37–45.
Wong, K. Y. and Spetsakis, M. E. (2004). Motion segmen-
tation by EM clustering of good features. In Proc.
CVPR Workshop, pages 166–173.
Zappella, L., Llad´o, X., and Salvi, J. (2009). New trends
in motion segmentation. In Yin, P.-Y., editor, Pattern
Recognition, pages 31–46. INTECH.
SparseMotionSegmentationusingPropagationofFeatureLabels
401
