
DITEC
Experimental Analysis of an Image Characterization Method
based on the Trace Transform
Igor G. Olaizola
1
, I˜nigo Barandiaran
1
, Basilio Sierra
2
and Manuel Gra˜na
2
1
Vicomtech-IK4 Research Alliance, Donostia, Spain
2
Dpto. CCIA, UPV-EHU, Donostia, Spain
Keywords:
Feature Descriptor, Trace Transform, Image Matching, Image Characterization.
Abstract:
Global and local image feature extraction is one of the most common tasks in computer vision since they
provide the basic information for further processes, and can be employed on several applications such as
image search & retrieval, object recognition, 3D reconstruction, augmented reality, etc. The main parameters
to evaluate a feature extraction algorithm are its discriminant capability, robustness and invariance behavior to
certain transformations. However, other aspects such as computational performance or provided feature length
can be crucial for domain specific applications with specific constraints (real-time, massive datasets, etc.). In
this paper, we analyze the main characteristics of the DITEC method used both as global and local descriptor
method. Our results show that DITEC can be effectively applied in both contexts.
1 INTRODUCTION
Image analysis and characterization tasks used for ap-
plications like image search & retrieval, 3D recon-
struction, or augmented reality are mainly based on
the extraction of low-level features as primary infor-
mation units for its further processes. These features
can be obtained either by analyzing specific charac-
teristics of the whole image (global features) or by
processing points or areas with relevant information
(local features). While image characterization can be
performed by using both types of features, some other
tasks such as stereo disparity estimation, image stitch-
ing, or camera tracking require the detection, descrip-
tion and matching of interesting points. Key point ex-
traction and description mechanisms play a key role
during image matching process, where several image
points must be accurately identified to robustly esti-
mate a transformation or recognize an object.
In this paper we analyze the behavior as
both a global and a local descriptor of a novel
method (DITEC) which has been already successfully
tested as global approach in image characterization
tasks(Olaizola et al., 2012). The very promising re-
sults obtained in the evaluation phase suggest its po-
tential as a highly discriminative local descriptor.
The paper is structured as follows: section 2 gives
a brief description on previous work related with im-
age description or characterization. Section 3 de-
scribes our DITEC approach and the methodology
used for the evaluation of DITEC, performing as both
global and local descriptor. Section 4 describes re-
sults obtained by DITEC approach compared with
similar approaches, both globally(Section 4.1) and lo-
cally (Section 4.2). Finally, Section 5 gives final re-
marks and future work.
2 RELATED WORK
2.1 Image Descriptors
There is a vast literature regarding different global
features. Histograms of several local features (Bouker
and Hervet, 2011), texture features (Manjunath et al.,
1998) or self similarity (Shechtman and Irani, 2007)
havebeen broadly used as low levelfeatures for image
characterization. Watanabe et al. (Watanabe et al.,
2002) proposed a global descriptor based on the code-
words provided by Lempel-Ziv (Ahmed et al., 2011;
Cerra et al., 2010) entropy coders assuming that the
codification of the complexity of data can character-
ize the content represented within it. Among all these
global descriptors, DITEC has proven to be a very
promising method for robust image domain catego-
344
Olaizola I., Barandiaran I., Sierra B. and Graña M..
DITEC - Experimental Analysis of an Image Characterization Method based on the Trace Transform.
DOI: 10.5220/0004292303440352
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 344-352
ISBN: 978-989-8565-47-1
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

rization, producing short codewords with a high dis-
criminant value.
In addition to globally describing images, local
approaches are also becoming an active topic in re-
search community. Local descriptors are nowadays
widely used by computer vision community (Snoek
and Smeulders, 2010). Some approaches such as
SIFT (Lowe, 1999) are extensively used in many
computer vision based applications because of their
robustness. However, the application of such ap-
proaches in contexts like real-time image processing,
are not suitable due to its computation requirements.
Some other approaches such as SURF (Bay et al.,
2006a) or BRIEF (Calonder et al., 2010a) overcome
this computational requirements, being some of the
most popular approaches when near real-time perfor-
mance is required. Usually, a trade-off between ro-
bustness and performance needs to be tackled.
2.2 Trace Transform
The trace transform has been already used for several
computer vision applications. MPEG-7 (Mart´ınez,
2004) standard specification for image fingerprinting
contains a method based on the trace transform to cre-
ate hash codes (Bober and Oami, 2007; O’Callaghan
et al., 2008). Other applications such as face recogni-
tion (Fahmy, 2006; Srisuk et al., 2003; Liu and Wang,
2007; Liu and Wang, 2009), character recognition
(Nasrudin et al., 2010) and sign recognition (Turan
et al., 2005) are other examples where the trace trans-
form was successfully applied.
The data transformation process is carried out
through the trace transform, a generalization of the
Radon transform (1) where the integral of the func-
tion is substituted for any other functional Ξ (Kadyrov
and Petrou, 1998; Kadyrov and Petrou, 2001; Petrou
and Kadyrov, 2004; Turan et al., 2005; Brasnett and
Bober, 2008).
R(φ,ρ) =
ZZ
f(x,y)δ(xcosφ+ysinφ− ρ)dx dy (1)
The trace transform consists in applying a func-
tional Ξ along a straight line (L in Figure 1). This
line is moved tangentially to a circle of radius ρ cov-
ering the set of all tangential lines defined by φ. The
Radon transform has been used to characterize images
(Peyrin and Goutte, 1992) in well defined domains
(Lin et al., 2010), in image fingerprinting (Seo et al.,
2004) and as a primitive feature for general image
description. The trace transform extends the Radon
transform by enabling the definition of the functional
and thus enhancing the control on the feature space.
These features can be set up to show scale, rotation,
Figure 1: Trace transform, geometrical representation
(Olaizola et al., 2012).
affine transformation invariance or high discrimina-
tive capacity for specific content domains.
3 METHODS
DITEC method proposed in (Olaizola et al., 2012)
consists of a method based on the trace transform to
extract efficient global descriptors for domain catego-
rization. The results of DITEC tested with Corel 1000
dataset
1
and a subset of Geoeye
2
show its potential as
global feature for image characterization.
In addition to global image descriptors, an image
can also be categorized or described by extracting lo-
cal information in several positions along its dimen-
sions. This local information is usually represented
in form of local descriptors. A local image descriptor
can be seen as a vector of values representing a region
of size s around a detected key point p, as shown in
figure 2. The type of data and vector dimensions de-
pends on the nature of the local description algorithm.
Figure 2: Local image patch and corresponding local de-
scriptor.
1
Corel Gallery Magic 65000 (1999), www.corel.com
2
http://www.geoeye.com
DITEC-ExperimentalAnalysisofanImageCharacterizationMethodbasedontheTraceTransform
345

For example, one of the most successful descriptor to
date, SIFT (Lowe, 1999), is represented as a vector
of 128 floating point values. Our local image descrip-
tor approach works on single channel images, thus no
color information is used. Many of the most popular
local image descriptors, such as SIFT (Lowe, 1999),
SURF (Bay et al., 2006b) or BRIEF (Calonder et al.,
2010b) use also intensity information only. As men-
tioned before, DITEC algorithm is an approach for
image description, thus an additional mechanism for
interest point detection or segmentation is needed, in
order to apply it locally. In order for DITEC to ob-
tain high robustness to scale transformation, a detec-
tor with key point scale s estimation is needed. In the
current evaluation, we used as interest point extrac-
tion, the detection of local maxima in scale-space of
Laplacian of Gaussian (LoG), approximated by dif-
ference of Gaussians (Lowe, 1999).
Once keypoints are detected, we apply DITEC ap-
proach locally to every detected points. In this way, n
image patches of size s, proportional to the scale esti-
mated by the point detector, are extracted around each
key point x
i
. These patches are reduced bi-linearly to
a predefined size n. Then, for every patch, a trace
transform g(φ, ρ) with a given functional F is com-
puted. g(φ,ρ) is then normalized between 0 and 1 in
order to reduce the influence of signal intensity and
make DITEC robust against light intensity variations.
Once the trance transform is normalized, the frequen-
cial coefficients of the patch are obtained.
4 EVALUATION
4.1 Behavior as Global Descriptor
The analysis of DITEC as global feature extraction
method for image domain characterization has been
performed using three different datasets. The exper-
iments with the first two datasets (Geoeye and Corel
1000) are described in (Olaizola et al., 2012) while
a more detailed analysis of the results is presented
here. The third experiment has been performed on a
new dataset composed by a subset of Caltec 101 (de-
scribed in Section 4.1.3). These three datasets allow
the evaluation of the method under different condi-
tions in terms of type of content domains, variations
in resolution, etc.
4.1.1 Corel 1000
Corel 1000 dataset is composed of 10 different classes
with 1000 instances per class where some classes rep-
resent scenes while some other represent specific ob-
jects within a scene and few of them are more related
to specific objects contained within a scene. The best
precision results for this datasets are shown in Table
1. The general precision achieved for Corel 1000 is
84.8%. A non square resolution of n
φ
and n
ρ
has been
used in this case. The low angular resolution reduces
the rotational invariance of the descriptor, a constraint
that is not required for this dataset. In this case the
average value has been applied as functional and the
SVM implementation of Weka 3.6.4 (SMO) has been
used for training and classification.
Table 1: Corel 1000 dataset confusion matrix. The closest
classes attending the misclassification rates are represented
in bold.
tion is needed, in order to apply it locally. In order
for DITEC to obtain high robustness to scale transfor-
estimation is
needed. In the current evaluation, we used as inter-
est point extraction, the detection of local maxima in
scale-space of Laplacian of Gaussian (LoG), approx-
Once key points are detected, we apply DITEC ap-
, proportional to the scale esti-
mated by the point detector, are extracted around each
. These patches are reduced bi-linearly to
. Then, for every patch, a trace
is com-
is then normalized between 0 and 1 in
order to reduce the influence of signal intensity and
a b c d e f g h i j
a) Africans
75 2 6 0 2 5 0 2 1 7
b) Beach
5 79 6 1 0 6 0 0 2 1
c) Architecture
3 4 78 1 0 3 1 0 8 2
d) Buses
3 3 3 81 0 0 1 0 4 5
e) Dinosaurs
0 0 0 0 100 0 0 0 0 0
f) Elephants
7 1 3 0 0 83 0 2 3 1
g) Flowers
1 1 0 0 0 0 95 2 0 1
h) Horses
1 0 1 1 0 0 0 97 0 0
i) Mountains
0 14 4 1 0 3 0 0 78 0
j) Food
5 1 0 5 0 3 4 0 0 82
Table 1: Corel 1000 dataset confusion matrix. The closest
A deeper analysis of Corel 1000 has been per-
formed by analyzing the 224 attributes obtained dur-
ing an evolutionary feature selection process. These
remaining 224 attributes have been analyzed and
ranked with a Support Vector Machine (SVM) clas-
sifier. The ranking criteria has been the square of the
weight assigned by the SVM classifier (Guyon et al.,
2002). Then an iterative test has been performedstart-
ing from the five most important values and increas-
ing the number of attributes according to the rank ob-
tained previously. The obtained results can be ob-
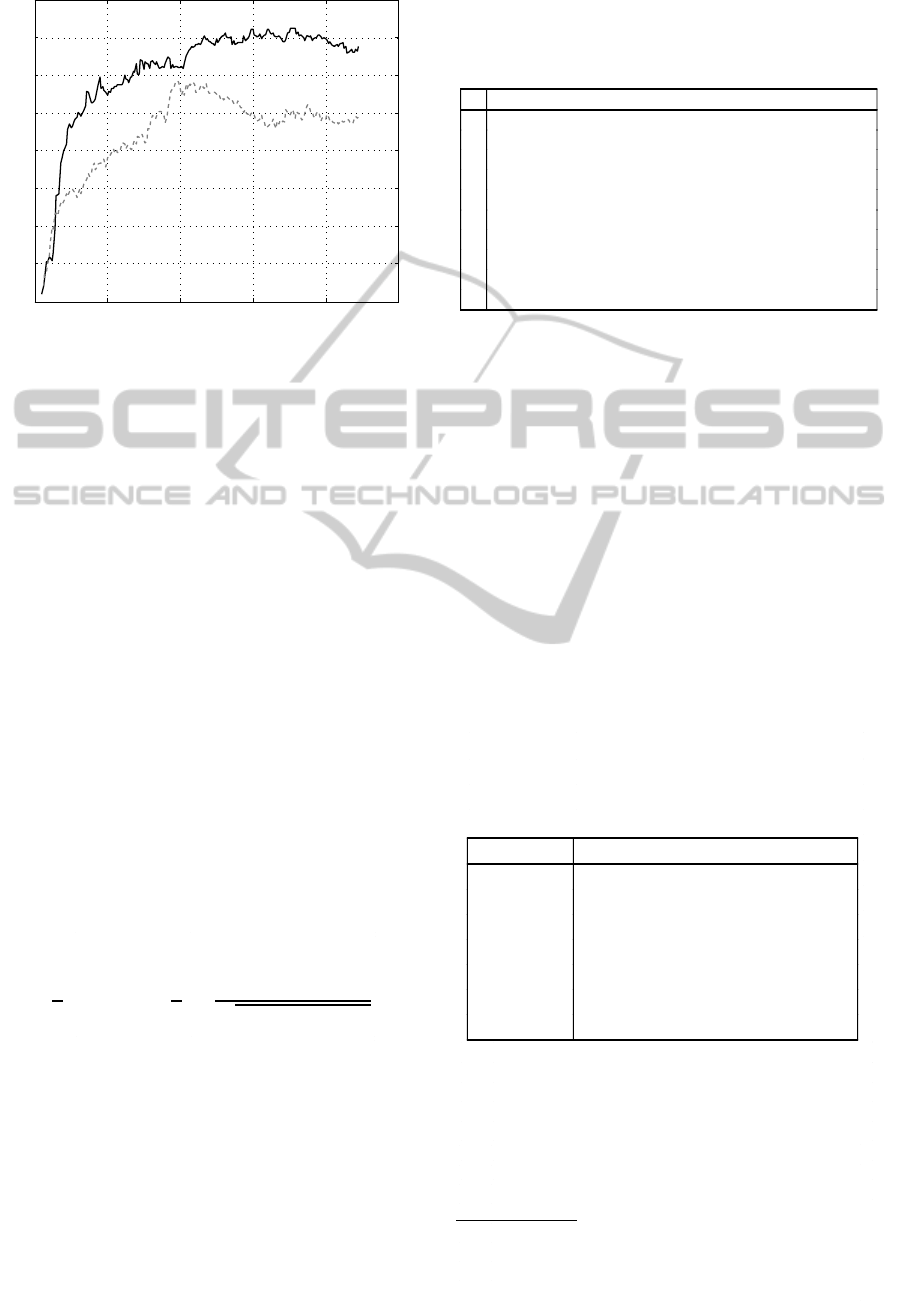
served in Figure 3. This evaluation shows that there
are few attributes with strong discriminative power.
When the number of attributes reaches around 180,
the precision starts decreasing.
SVM based attribute selection has some draw-
backs in terms of computationalperformance and data
sensitivity. A more robustapproachfor feature extrac-
tion can be provided by Principal Component Analy-
sis (PCA), also known as Karhunen-Lo`eve transform
(Bishop, 2006). The goal of this approach is to project
data onto a space with a lower dimensionality, while
maximizing the variance of the projected data.
As it can be seen in Figure 3, PCA method im-
proves the precision for dimensionalities below 14,
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
346
0 50 100 150 200 250
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
Number of attributes
Precision
Figure 3: Attribute selection applied in Corel 1000 dataset.
Black line: Attributed ranked according to a generic SVM
classifier (WEKA(Hall et al., ) SMO implementation with
standard parameters). Discontinuous line: Features trans-
formed with PCA.
but SVM ranking provides considerably better results
for a higher number of attributes. The best results of
SVM ranking are 7% higher than those obtained by
PCA. However, it is important to note that PCA is a
much faster method than SVM ranking. This makes
PCA appropriate for applications where time or com-
putational performance is more critical than precision
or where very short descriptors are needed (e.g. Very
fast distance evaluations in massive datasets).
For a better understanding of the obtained fea-
ture space, the Bhattacharyya distance can provide a
good overview related to the distances among differ-
ent classes. Bhattacharyya distance for Gaussian mul-
tivariate distribution is given by (2). Assuming such
distribution in the analyzed feature spaces, we can ob-
tain an approximation about the distances among the
different classes. The study of the relative distances
provides significant information about their distribu-
tion and thus the discriminantpotential when different
classifiers are applied. As it can be observed in Table
2, the evaluated relative distance among classes fits
with the errors shown in the confusion matrix.
D
B
=
1
8
∆µ
t
C
−1
∆µ+
1
2
log
det(C)
p
det(C
1
) · det(C
2
)
(2)
where C = (C
1
+C
2
)/2
4.1.2 Geoeye subset
Geoeye subset contains 1003 multi resolution satel-
lite image patches categorized in 7 classes). All the
Geoeye classes belong to geographical locations and
include different cities as well as natural spaces. For
this dataset, a precision of 94.51% has been obtained
Table 2: Bhattacharyya distance matrix for Corel 1000
dataset. Distance values corresponding to the two most sim-
ilar classes according to the misclassification rates of the
classification process are represented in bold.
a b c d e f g h i j
a 0 7.48 6.69 10.38 15.38 6.96 9.33 8.23 8.72 5.99
b 7.48 0 7.45 12.02 14.76 6.63 11.73 9.74 6.27 9.10
c 6.69 7.45 0 9.94 18.47 7.07 11.85 10.05 7.29 7.86
d 10.38 12.02 9.94 0 27.98 13.18 13.97 11.82 13.50 8.13
e 15.38 14.76 18.47 27.98 0 12.29 36.17 32.03 15.07 17.93
f 6.96 6.63 7.07 13.18 12.29 0 12.95 8.91 6.59 8.67
g 9.33 11.73 11.85 13.97 36.17 12.95 0 9.94 13.25 8.91
h 8.23 9.74 10.05 11.82 32.03 8.91 9.94 0 12.60 8.12
i 8.72 6.27 7.29 13.50 15.07 6.59 13.25 12.60 0 11.22
j 5.99 9.10 7.86 8.13 17.93 8.67 8.91 8.12 11.22 0
Table 2: Bhattacharyya distance matrix for Corel 1000
with the following parameter values: n
φ
= n
ρ
71,·
functional: mean. Comparing to the parameters em-
ployed in Corel 1000, the higher angular resolution
has improved the rotational invariance of the descrip-
tor adapting its behavior to the constraints of the
dataset.
The final classification results have been tested us-
ing stratified 10-fold cross validation. Experimental
text have demonstrated that Bayesian networks of-
fer better precision rates than SVM for this specific
dataset.
The results of the classification process are rep-
resented in Table 3 while Table 4 shows the Bhat-
tacharyya distances among Geoeye dataset classes.
As described in the previous case, there is a strong
correspondence between the relative Bhattacharyya
distance and the results obtained by using supervised
classifiers (Bayesian networks in this case).
Table 3: Geoeye dataset confusion matrix. The closest
classes attending the misclassification rates are represented
in bold.
tain an approximation about the distances among the
different classes. The study of the relative distances
provides significant information about their distribu-
tion and thus the discriminant potential when different
classifiers are applied. As it can be observed in Table
2, the evaluated relative distance among classes fits
(2)
a b c d e f g
(a) Athens 74 0 1 0 2 0 0
(b) Davis 0 183 0 0 2 7 2
(c) Manama 1 0 193 0 0 0 0
(d) Midway 2 0 0 62 1 0 0
(e) Nyragongo 0 0 4 0 77 2 2
(f) Risalpur 0 0 0 0 0 177 17
(g) Rome 0 0 1 0 0 11 182
Table 3: Geoeye dataset confusion matrix. The closest
4.1.3 Subset of Caltech 101
A new test has been performed based on a subset of
Caltech 101
3
. The classes contained in this subset
and one sample per class are depicted in Figure 4. The
dataset contains a different number of samples per
3
http://www.vision.caltech.edu/archive.html
DITEC-ExperimentalAnalysisofanImageCharacterizationMethodbasedontheTraceTransform
347

(a) Accordion (b) Airplanes (c) Bonsai (d) Brain (e) Budha
(f) Butterfly (g) Dollar bill (h) Faces easy (i) Grand Piano (j) Hawksbill
(k) Ketch (l) Leopards (m) Motorbikes (n) Watch
Figure 4: Samples of Caltech101 subset. The dataset includes an heterogeneous set of images at different resolutions and
photogrametric conditions.
class and there is a high inter and intra class varia-
tion in many aspects such as resolution, image qual-
ity, color space, angle/perspective, scale etc. Fig-
ure 5 shows some samples of one of the Caltech 101
classes.
Table 4: Bhattacharyya distance matrix for Geoeye dataset.
Distance values corresponding to the two most similar
classes according to the misclassification rates of the classi-
fication process are represented in bold.
Geoeye subset contains 1003 multi resolution satel-
lite image patches categorized in 7 classes). All the
Geoeye classes belong to geographical locations and
include different cities as well as natural spaces. For
this dataset, a precision of 94.51% has been obtained
71,
. Comparing to the parameters em-
a b c d e f g
a 0 26.29 14.66 21.67 15.86 16.75 21.25
b 26.29 0 15.71 24.76 17.06 7.17 11.19
c 14.66 15.71 0 20.34 13.33 12.19 12.77
d 21.67 24.76 20.34 0 22.39 15.82 17.59
e 15.86 17.05 13.32 22.38 0 12.45 15.42
f 16.75 7.16 12.19 15.81 12.44 0 5.15
g 21.25 11.19 12.76 17.59 15.42 5.15 0
Table 4: Bhattacharyya distance matrix for Geoeye dataset.
During this evaluation, we used DITEC method
with the following parameters: functional=average
value, n
phi
= 100, n
rho
= 100, n
ξ
= 251. The num-
Figure 5: Some samples of images belonging to leopards
class.
ber of DCT coefficients per channel was reduced to
the first 80 positions, thus obtaining 480 descriptors
per channel. Using the standard configuration of the
Weka SMO classifier a precision of 79.8 % was ob-
tained and reducing the number of dimensions to 75
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
348
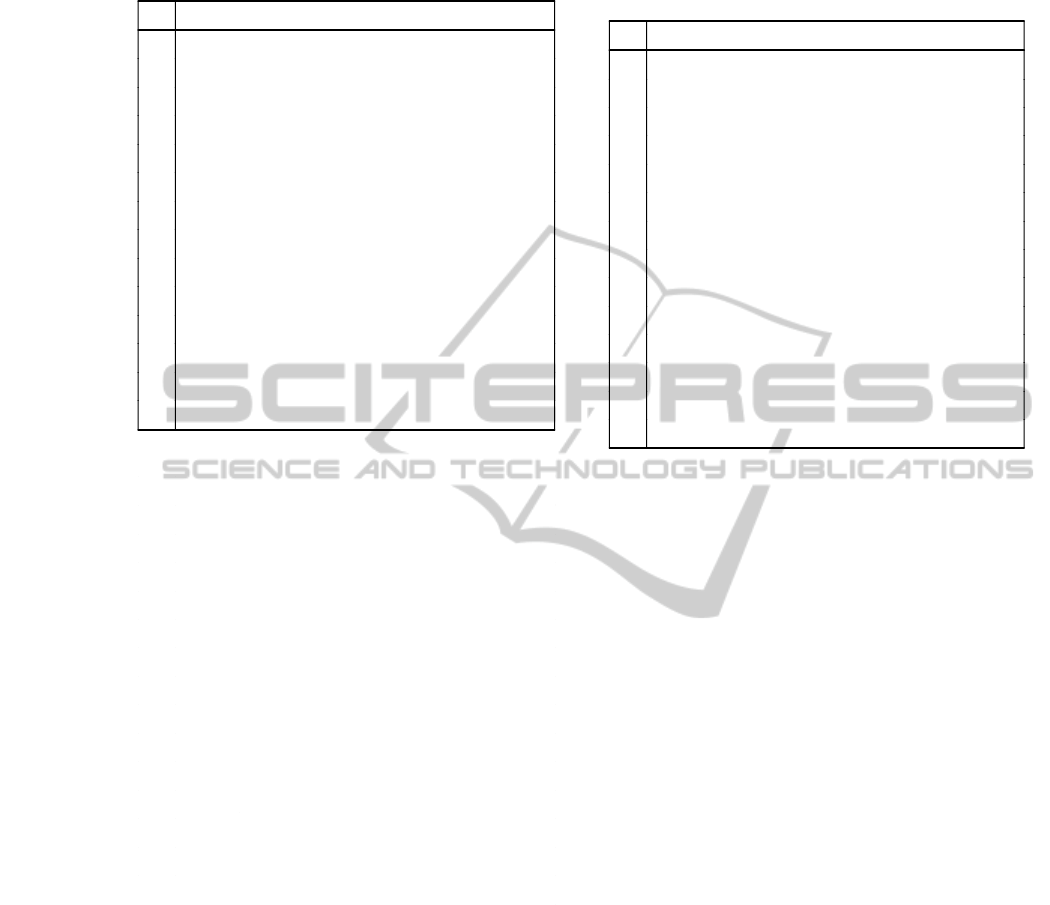
Table 5: Caltech 101 subset confusion matrix.
A new test has been performed based on a subset of
a b c d e f g h i j k l m n
a
37 0 1 4 0 3 0 1 1 1 0 0 0 7
b
0 766 4 0 1 4 0 0 1 2 4 0 10 8
c
2 17 53 2 6 4 0 4 3 2 6 3 3 23
d
0 7 2 43 3 10 2 1 3 1 2 2 7 15
e
0 5 13 2 33 6 0 3 2 1 12 0 1 7
f
12 9 5 6 5 26 0 2 1 5 5 1 5 9
g
0 7 0 1 0 0 23 0 0 1 2 2 10 6
h
1 0 2 2 4 1 0 419 1 1 0 1 1 2
i
1 6 5 3 5 1 0 3 51 3 0 0 1 20
j
0 24 5 2 3 3 2 2 0 49 3 0 2 5
k
1 10 4 3 5 2 0 3 2 1 68 3 2 10
l
0 0 1 0 0 0 0 0 0 1 0 198 0 0
m
0 20 4 3 1 3 0 0 0 0 0 0 746 21
n
2 16 13 13 8 3 4 1 10 3 6 0 27 133
Table 5: Caltech 101 subset confusion matrix
attributes by using a PCA decomposition, the preci-
sion was 76.4%. Both experiments were performed
following a k-fold 10 cross-validation method. Table
5 shows the corresponding confusion matrix for SVM
algorithm.
The Bhattacharyya distance of Caltech subset
classes 6 cannot be directly calculated due to the sin-
gularity of the covariance matrix in some classes.
Therefore, low variance attributes have been removed
before the calculation. The obtained classification re-
sults are in general coherent to the Bhattacharyya dis-
tance specially for highest distances but the lower sig-
nificance of this distance can be observed in some
other cases. For example, the two classes with high-
est misclassification results (classes m and n) show a
relatively high Bhattacharyya distance.
4.2 Behaviour as Local Descriptor
In addition to the evaluation of our DITEC approach
runningas global image descriptor, we also conducted
an evaluation to measure how well this approach can
be applied as a local image descriptor. We used our
own framework based on the original work of (Miko-
lajczyk and Schmid, 2005) to evaluate our DITEC ap-
proach acting as a local descriptor. This framework
is able to generate precision-recall curves as Mikola-
jczyk’s framework but is also able to generate more
informative curves that represent the number or per-
centage of correct matches against specific values of
a given transformation. We also used a set of images
proposed by (Mikolajczyk and Schmid, 2005) and the
image generator proposed in our framework. These
Table 6: Caltech 101 subset Bhattacharyya distance matrix
(rounded values).
A new test has been performed based on a subset of
. The classes contained in this sub-
set and one sample per class are depicted in Figure
4. The dataset contains a different number of sam-
ples per class and there is a high inter and intra class
variation in many aspects such as resolution, image
quality, color space, angle/perspective, scale etc. Fig-
ure 5 shows some samples of one of the Caltech 101
During this evaluation, we used DITEC method
with the following parameters: functional=average
251. The num-
ber of DCT coefficients per channel was reduced to
the first 80 positions, thus obtaining 480 descriptors
per channel. Using the standard configuration of the
Weka SMO classifier a precision of 79.8 % was ob-
tained and reducing the number of dimensions to 75
attributes by using a PCA decomposition, the preci-
sion was 76.4%. Both experiments were performed
following a k-fold 10 cross-validation method. Table
a b c d e f g h i j k l m n
a
0 31 27 16 17 16 35 28 29 18 29 29 16 26
b
31 0 10 24 23 24 29 14 12 19 10 7 18 7
c
27 10 0 21 22 22 35 8 10 20 10 10 19 7
d
16 24 21 0 10 10 29 23 25 11 23 25 9 20
e
17 23 22 10 0 11 27 23 25 10 24 23 9 20
f
16 24 22 10 11 0 29 24 26 11 22 24 9 21
g
35 29 35 29 27 29 0 36 35 24 35 33 23 30
h
28 14 8 23 23 24 36 0 11 22 11 12 22 8
i
29 12 10 25 25 26 35 11 0 22 14 13 20 8
j
18 19 20 11 10 11 24 22 22 0 21 20 8 17
k
29 10 10 23 24 22 35 11 14 21 0 8 21 9
l
29 7 10 25 23 24 33 12 13 20 8 0 22 9
m
16 18 19 9 9 9 23 22 20 8 21 22 0 17
n
26 7 7 20 20 21 30 8 8 17 9 9 17 0
Table 6: Caltech 101 subset Bhattacharyya distance matrix
sets of images show different geometric transforma-
tions such as in-plane rotation, scale similarity, and
affine or projective transformations. All these sets of
images allowed us to evaluate the robustness of our
proposed descriptor against those types of transfor-
mations. Geometric transformations are related with
the spatial transformations that occurs between differ-
ent coordinate systems involved during image forma-
tion. Those transformation are mainly the Euclidean
transformations, i.e. rotation and translation from
word coordinate system to camera coordinate system,
the projection of world points to camera coordinate
system, and finally the points transformation to image
coordinate system.
IF
2
=
Z
|ξ(x)|
q
dt
r
(3)
As described in Section 3, DITEC is based on
the generalization of the trace transform, and there-
fore a functional Ξ must be applied to every image
to be transformed. In this case, we used IF
2
func-
tional (Equation 3) as defined in (Petrou and Kadyrov,
2004). All tests were carried out by comparing results
obtained with DITEC approach with results obtained
by the popular SURF (Bay et al., 2006b) descriptor in
the same framework and datasets. The parameters of
SURF descriptor were set as the default values imple-
mented in OpenCV version (2.4).
We evaluated the DITEC performance as local im-
age descriptor by measuring the matching ratio, i.e.
percentage of correct matches of key points detected
between the first image (reference image) and the rest
of images in the dataset.
DITEC-ExperimentalAnalysisofanImageCharacterizationMethodbasedontheTraceTransform
349
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
0 45 90 135 180 225 270 315 360
% of Correct Correspondences
Angle of Rotation
SURF
DITEC
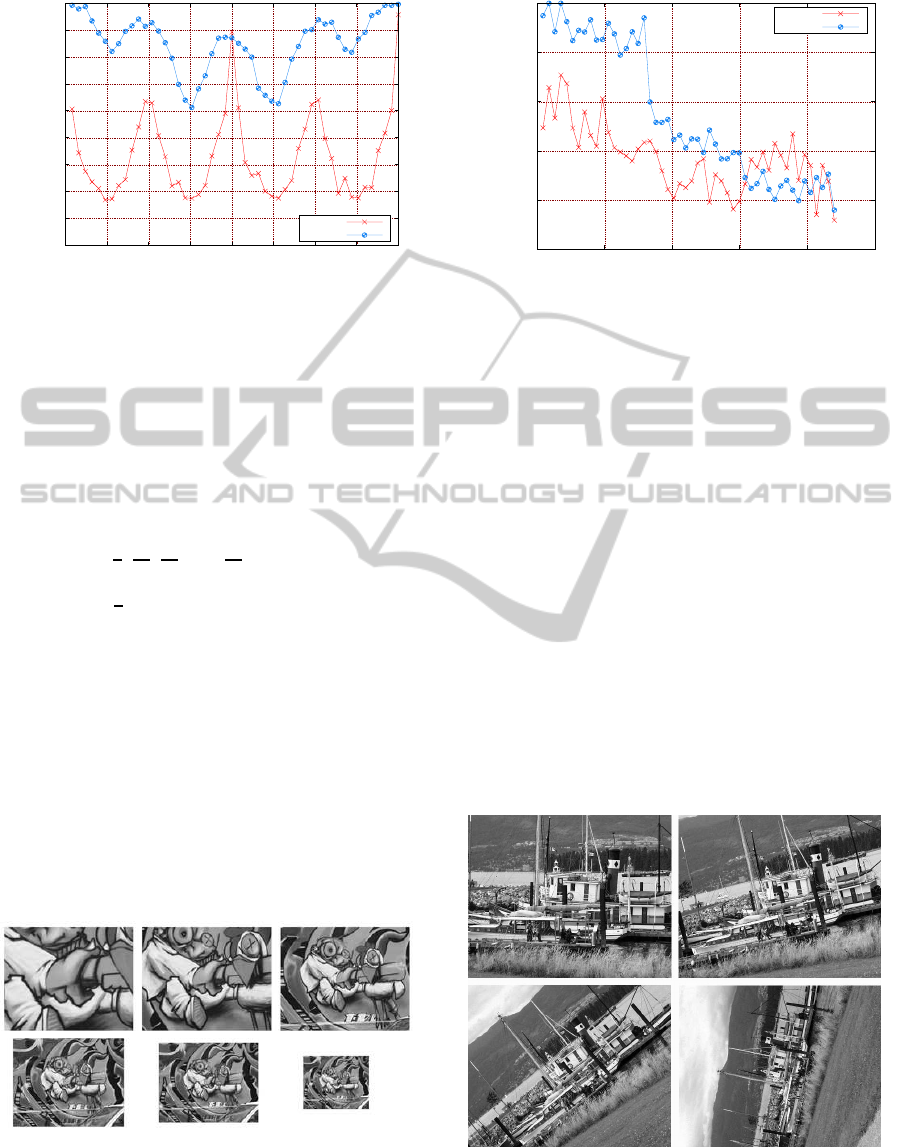
Figure 6: Results of in-plane rotation transformation test.
In order to evaluate the robustness of DITEC ap-
proach against rotation similarity transformation, we
generated 50 in-plane rotated images, with 7,2 de-
grees of difference between consecutive images.
Figure 6 shows normalized correct matching ratio
between source image with 0 degrees of rotation and
the rest of images in the generated dataset. Both ap-
proaches show different responses given different an-
gles. In the case of DITEC there are 4 local minimum
points at α =
π
4
,
3π
4
,
5π
2
and
7π
4
which are the points
with highest distance to the reference values (consid-
ering that α =
π
2
is closed to the reference). The cho-
sen functional and the use of frequencial coefficients
to represent the trace transform results provide a high
rotational invariance. DITEC approach outperforms
SURF by obtaining higher matching ratios along the
transformation range, being always over an 80% of
accuracy.
Next test shows the results of a similar evaluation
process, but changing the rotation similarity transfor-
mation by a scale transformation. Similarly to the
rotation transformation test, we generated 25 scale
transformed images, with a scale range from 2 times
the original size to a reduction of 2.5 times, as shown
in Figure 7.
Figure 7: Scale transformed images of image 1 of Graffiti
(Mikolajczyk and Schmid, 2005) dataset.
Figure 8 shows normalized results of scale trans-
formation test. Both approaches show high robust-
0.75
0.8
0.85
0.9
0.95
1
0 0.5 1 1.5 2 2.5
% of Correct Correspondences
Scale Factor
SURF
DITEC
Figure 8: Normalized results of isotropic scale transforma-
tion test.
ness to scale transformation and DITEC obtains over-
all better results than SURF. Clearly, generalized trace
transform with applied functional IF
2
(3) shows great
invariance capabilities against isotropic scale trans-
formation.
In addition to previous test, where images were
generated synthetically, the following tests use real
images proposed in (Mikolajczyk and Schmid, 2005).
These datasets are widely used by related community
since its publication, and are composed of several sets
of images performing different geometric and photo-
metric transformations. Figure 9 shows images 1 to 4
of one of those dataset called Boat. Original dataset
provides 2 more images, but in those images both
SIFT and SURF detectors extract a very low num-
ber of points. Thus, normalized results are somehow
distorted, therefore we decided to remove them from
the evaluation. Images of Boat dataset show rotation,
scale and projective transformations altogether.
Figure 9: Images 1-4 of boat dataset (Mikolajczyk and
Schmid, 2005).
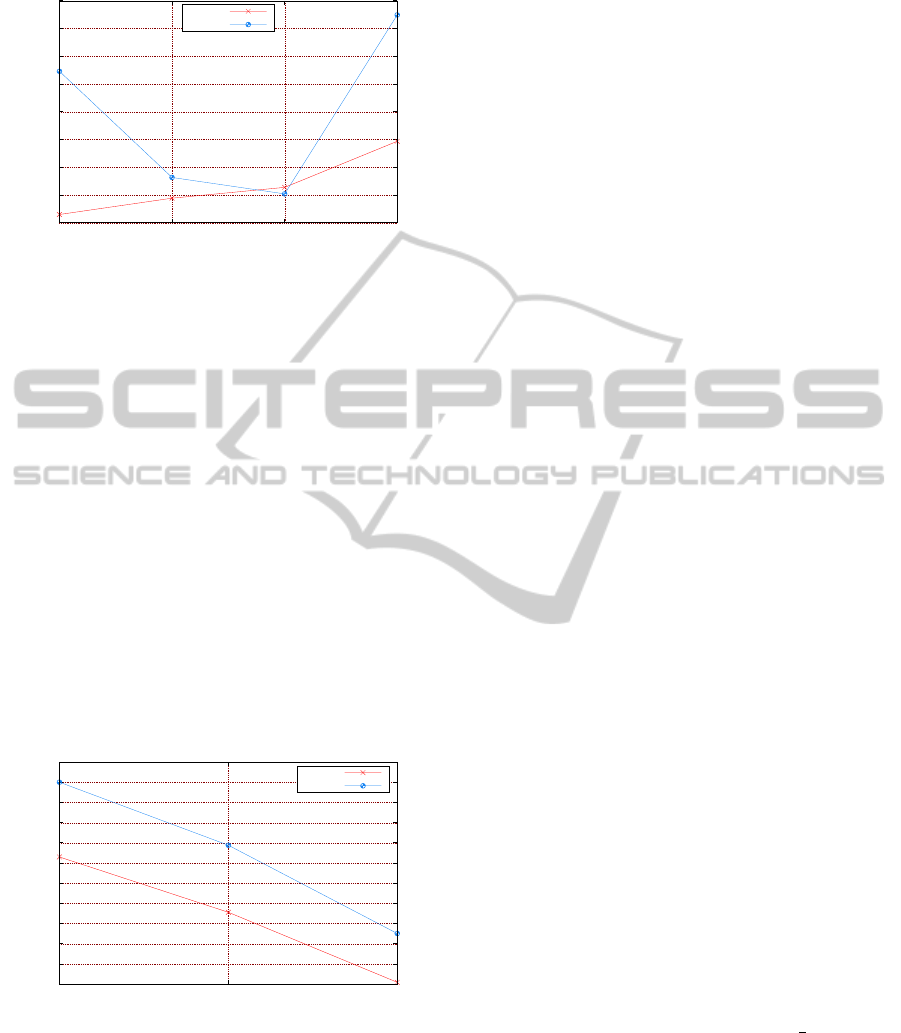
Results depicted in Figure 10 show how DITEC
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
350
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1 2 3 4
% Correct Correspondences
Image
Normalized Number of Correspondences
SURF
DITEC
Figure 10: Results of images 1-4 of Boat dataset.
obtains high accurate ratios in every image, outper-
forming SURF approach.
As with Boat dataset, we used only first 3 out of 5
images due to the significant reduction of the number
of extracted key points. This dataset shows mainly
projective transformations between images, where all
world points are on a same world plane. Results de-
picted in Figure 11 show that DITEC performs better
than SURF approach, achieving higher accuracy ra-
tios for every image. Even if DITEC is not projec-
tively invariant, it is able to obtain good results in im-
ages where projective distortion is not very high with
respect to reference image, such as in images 1 and
2, and thus can be locally approximated by an affin-
ity. As described in (Petrou and Kadyrov, 2004), trace
transform using specific functionals, such as IF
2
(3)
used in DITEC, can be robust against affine transfor-
mations.
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1 2 3
% Correct Correspondences
Image
Normalized Number of Correspondences
SURF
DITEC
Figure 11: Results of images 1-3 of Graffiti dataset (Miko-
lajczyk and Schmid, 2005).
5 CONCLUSIONS
We have presented a new approach for both global
and local image description. We have evaluated its
behavior with three domain characterization datasets
considering DITEC as a global descriptor. The ro-
bustness of DITEC has been also evaluated perform-
ing local image description against several geometric
transformations.
The discriminative power of the descriptor has
been successfully evaluated with these three differ-
ent datasets where complex objects and scenes have
been correctly classified without any segmentation
process or local description. Bhattacharyya distance
has shown a good measure to characterize the fea-
ture space before any classification process which can
be an efficient method for semi-supervised classifica-
tion tasks. Moreover, the quality of the distance can
be evaluated by analyzing the singularity of covari-
ance matrices. These results make DITEC a very suit-
able method as a initial analysis algorithm for datasets
where non a priori information exists.
DITEC performs well in in-plane rotation trans-
formation and is almost invariant to scale transforma-
tion. In almost every test, DITEC approach outper-
forms SURF approach. It is worth mentioning that
our current implementation of DITEC, acting as local
image descriptor, is not optimized thus is currently
slower than SURF descriptor. We think that current
implementation can be severely improved by paral-
lelizing the main loop of Radon transform because its
computation is inherently parallel. Overall, results
obtained with DITEC performing local description
are very promising. We are currently conducting an in
deep evaluation of DITEC local descriptor, by testing
several parameters such as angular and radial resolu-
tion, number of frequencial coefficients and different
functionals (instead of IF2), and comparing it with
state-of-the-art descriptors such as BRISK, FREAK,
or ORB among others.
REFERENCES
Ahmed, S., Khan, M., and Shahjahan, M. (2011). A fil-
ter based feature selection approach using lempel ziv
complexity. In Liu, D., Zhang, H., Polycarpou, M.,
Alippi, C., and He, H., editors, Advances in Neural
Networks ISNN 2011, volume 6676 of Lecture Notes
in Computer Science, pages 260–269. Springer Berlin
/ Heidelberg. 10.1007/978-3-642-21090-7 31.
Bay, H., Tuytelaars, T., and Gool, L. V. (2006a). Surf:
Speeded up robust features. In In ECCV, pages 404–
417.
Bay, H., Tuytelaars, T., and Van Gool, L. (2006b). Surf:
Speeded up robust features. Computer Vision–ECCV
2006, pages 404–417.
Bishop, C. M. (2006). Pattern recognition and machine
learning. Springer, 1st ed. 2006. corr. 2nd printing
edition.
DITEC-ExperimentalAnalysisofanImageCharacterizationMethodbasedontheTraceTransform
351

Bober, M. and Oami, R. (2007). Description of mpeg-7
visual core experiments. Technical report, ISO/IEC
JTC1/SC29/WG11.
Bouker, M. A. and Hervet, E. (2011). Retrieval of im-
ages using mean-shift and gaussian mixtures based
on weighted color histograms. In Proc. Seventh Int
Signal-Image Technology and Internet-Based Systems
(SITIS) Conf, pages 218–222.
Brasnett, P. and Bober, M. (2008). Fast and robust image
identification. In Proc. 19th Int. Conf. Pattern Recog-
nition ICPR 2008, pages 1–5.
Calonder, M., Lepetit, V., Strecha, C., and Fua, P. (2010a).
Brief: binary robust independent elementary features.
In Proceedings of the 11th European conference on
Computer vision: Part IV, ECCV’10, pages 778–792,
Berlin, Heidelberg. Springer-Verlag.
Calonder, M., Lepetit, V., Strecha, C., and Fua, P. (2010b).
Brief: Binary robust independent elementary features.
Computer Vision–ECCV 2010, pages 778–792.
Cerra, D., Mallet, A., Gueguen, L., and Datcu, M.
(2010). Algorithmic information theory-based anal-
ysis of earth observation images: An assessment.
IEEE J GRSL, 7(1):8–12.
Fahmy, S. A. (2006). Investigating trace transform archi-
tectures for face authentication. In Proc. Int. Conf.
Field Programmable Logic and Applications FPL ’06,
pages 1–2.
Guyon, I., Weston, J., Barnhill, S., and Vapnik, V. (2002).
Gene selection for cancer classification using support
vector machines. Mach. Learn., 46:389–422.
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann,
P., and Witten, I. H. SIGKDD Explor. Newsl., (1).
Kadyrov, A. and Petrou, M. (1998). The trace transform
as a tool to invariant feature construction. In Proc.
Fourteenth Int Pattern Recognition Conf, volume 2,
pages 1037–1039.
Kadyrov, A. and Petrou, M. (2001). The trace transform
and its applications. IEEE J PAMI, 23(8):811–828.
Lin, S., Li, S., and Li, C. (2010). A fast electronic compo-
nents orientation and identify method via radon trans-
form. In Proc. IEEE Int Systems Man and Cybernetics
(SMC) Conf, pages 3902–3908.
Liu, N. and Wang, H. (2007). Recognition of human faces
using siscrete cosine transform filtered trace features.
In Proc. 6th Int Information, Communications & Sig-
nal Processing Conf, pages 1–5.
Liu, N. and Wang, H. (2009). Modeling images with multi-
ple trace transforms for pattern analysis. IEEE J SPL,
16(5):394–397.
Lowe, D. G. (1999). Object recognition from local Scale-
Invariant features. Computer Vision, IEEE Interna-
tional Conference on, 2:1150–1157 vol.2.
Manjunath, B. S., rainer Ohm, J., Vasudevan, V. V., and Ya-
mada, A. (1998). Color and texture descriptors. IEEE
Transactions on Circuits and Systems for Video Tech-
nology, 11:703–715.
Mart´ınez, J. M. (2004). Mpeg-7 overview, iso/iec jtc1/sc29/
wg11 http://mpeg.chiariglione.org/standards/mpeg-7/
mpeg-7.htm.
Mikolajczyk, K. and Schmid, C. (2005). A perfor-
mance evaluation of local descriptors. Pattern Analy-
sis and Machine Intelligence, IEEE Transactions on,
27(10):1615–1630.
Nasrudin, M. F., Petrou, M., and Kotoulas, L. (2010). Jawi
character recognition using the trace transform. In
Proc. Seventh Int Computer Graphics, Imaging and
Visualization (CGIV) Conf, pages 151–156.
O’Callaghan, R., Bober, M., and Oami, R. and. Brasnett, P.
(2008). Information technology - multimedia content
description interface - part 3: Visual, amendment 3:
Image signature tools.
Olaizola, I. G., Quartulli, M., Fl´orez, J., and Sierra, B.
(2012). Trace transform based method for color im-
age domain identification. arXiv.
Petrou, M. and Kadyrov, A. (2004). Affine invariant
features from the trace transform. IEEE J PAMI,
26(1):30–44.
Peyrin, F. and Goutte, R. (1992). Image invariant via the
radon transform. In Proc. Int Image Processing and
its Applications Conf, pages 458–461.
Seo, J. S., Haitsma, J., Kalker, T., and Yoo, C. D. (2004).
A robust image fingerprinting system using the radon
transform. Sig. Proc.: Image Comm., 19(4):325–339.
Shechtman, E. and Irani, M. (2007). Matching local
self-similarities across images and videos. In Proc.
IEEE Conf. Computer Vision and Pattern Recognition
CVPR ’07, pages 1–8.
Snoek, C. G. M. and Smeulders, A. W. M. (2010). Visual-
concept search solved? Computer, 43(6):76–78.
Srisuk, S., Petrou, M., Kurutach, W., and Kadyrov, A.
(2003). Face authentication using the trace transform.
In Proc. IEEE Computer Society Conf. Computer Vi-
sion and Pattern Recognition, volume 1.
Turan, J., Bojkovic, Z., Filo, P., and Ovsenik, L. (2005). In-
variant image recognition experiment with trace trans-
form. In Proc. 7th Int Telecommunications in Modern
Satellite, Cable and Broadcasting Services Conf, vol-
ume 1, pages 189–192.
Watanabe, T., Sugawara, K., and Sugihara, H. (2002). A
new pattern representation scheme using data com-
pression. IEEE J PAMI, 24(5):579–590.
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
352
