
Compressed Domain Moving Object Detection
based on H.264/AVC Macroblock Types
Marcus Laumer
1,2
, Peter Amon
2
, Andreas Hutter
2
and Andr
´
e Kaup
1
1
Multimedia Communications and Signal Processing, University of Erlangen-Nuremberg, Erlangen, Germany
2
Imaging and Computer Vision, Siemens Corporate Technology, Munich, Germany
Keywords:
H.264/AVC, Compressed Domain, Object Detection, Macroblock Type.
Abstract:
This paper introduces a low complexity frame-based object detection algorithm for H.264/AVC video streams.
The method solely parses and evaluates H.264/AVC macroblock types extracted from the video stream, which
requires only partial decoding. Different macroblock types indicate different properties of the video content.
This fact is used to segment a scene in fore- and background or, more precisely, to detect moving objects
within the scene. The main advantage of this algorithm is that it is most suitable for massively parallel pro-
cessing, because it is very fast and combinable with several other pre- and post-processing algorithms, without
decreasing their performance. The actual algorithm is able to process about 3600 frames per second of video
streams in CIF resolution, measured on an Intel
R
Core
TM
i5-2520M CPU @ 2.5 GHz with 4 GB RAM.
1 INTRODUCTION
Moving object detection is probably one of the most
widely used video analysis procedures in many dif-
ferent applications. Video surveillance systems need
to detect moving persons or vehicles, trackers have
to be initialized with the objects they should track,
and recognition algorithms require the regions within
the scene where they should identify objects. For this
reason, several proposals for efficient object detec-
tion have been published. Most of them operate in
the pixel domain, i.e., on the actual pixel data of each
frame. This usually leads to a very high accuracy, but
at the expense of computational complexity.
As most video data is stored or transferred in com-
pressed representation, the bit stream has to be com-
pletely decoded beforehand in such scenarios. There-
fore, attempts have been made to eliminate the costly
step of decoding and to perform the analysis directly
in the compressed domain.
Detection algorithms can therefore be divided into
two categories: pixel domain detection and com-
pressed domain detection. Thereby, pixel domain is
well-defined as the entire video content is decoded
and all video frames are available in pixel representa-
tion. Compressed domain on the other hand does not
clearly express which part of the video content has to
be decoded and which part may remain compressed.
Several compressed domain detection methods that
achieve good results by analyzing different entropy
decoded syntax elements have been presented.
The remainder of this paper is organized as fol-
lows. Section 2 introduces some state-of-the-art com-
pressed domain detection algorithms. Section 3 pro-
vides a brief overview of the H.264/AVC syntax ele-
ments that are relevant for our algorithm and their ex-
traction. It also describes how macroblock types are
grouped to categories and defines which categories in-
dicate moving regions. Section 4 describes the actual
algorithm and the segmentation process in detail. Af-
ter that, some experimental results are given in Sec-
tion 5. Section 6 concludes this paper with a summary
and an outlook.
2 RELATED WORK
Established moving object detection methods in hy-
brid video codecs are based on solely extracting and
analyzing motion vectors. For instance, (Szczerba
et al., 2009) showed an algorithm to detect objects
in video surveillance applications using H.264/AVC
video streams. Their algorithm assigns a motion vec-
tor to each 4x4 pixel block of the examined frame.
Thereto, macroblocks with larger partitions than 4x4
are divided and their motion vector is assigned to
the smaller blocks. Since intra-coded macroblocks
219
Laumer M., Amon P., Hutter A. and Kaup A..
Compressed Domain Moving Object Detection based on H.264/AVC Macroblock Types.
DOI: 10.5220/0004296602190228
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 219-228
ISBN: 978-989-8565-47-1
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

have no corresponding motion vector, the algorithm
interpolates a vector from previous and consecutive
frames. This results in a dense motion vector field.
This dense motion vector field is further analyzed to
estimate vectors that represent real motion by calcu-
lating spatial and temporal confidences as introduced
by (Wang et al., 2000).
Other object detection methods do not solely
analyze motion vectors but also exploit additional
compressed information, like macroblock partition
modes, e.g., (Fei and Zhu, 2010) and (Qiya and
Zhicheng, 2009) or transform coefficients, e.g., (Mak
and Cham, 2009) and (Porikli et al., 2010).
(Fei and Zhu, 2010), for instance, presented a
study on mean shift clustering based moving object
segmentation for H.264/AVC video streams. In a first
step, their method refines the extracted raw motion
vector field by normalization, median filtering, and
global motion compensation, whereby already at this
stage the algorithm uses macroblock partition modes
to enhance the filtering process. The resulting dense
motion vector field and the macroblock modes then
serve as input for a mean shift clustering based object
segmentation process, adopted from pixel domain ap-
proaches, e.g., introduced by (Comaniciu and Meer,
2002).
(Mak and Cham, 2009) on the other hand analyze
motion vectors in combination with transform coeffi-
cients to segment H.264/AVC video streams to fore-
and background. Quite similar to the techniques de-
scribed before, their algorithm initially extracts and
refines the motion vector field by normalization, fil-
tering, and background motion estimation. After that,
the foreground field is modeled as a Markov random
field. Thereby, the transform coefficients are used as
an indicator for the texture of the video content. The
resulting field indicates fore- and background regions,
which are further refined by assigning labels for dis-
tinguished objects.
(Poppe et al., 2009) introduced an algorithm for
moving object detection in the H.264/AVC com-
pressed domain that evaluates the size of macroblocks
(in bits) within video streams. Thereby, the size of
a macroblock includes all corresponding syntax ele-
ments and the encoded transform coefficients. The
first step of their algorithm is to find the maximum
size of background macroblocks, which is performed
in an initial training phase. During the subsequent
analysis, each macroblock that exceeds this size is re-
garded as foreground, as an intermediate step. Mac-
roblocks with less size are divided to macroblocks
in Skip mode and others. Labeling of macroblocks
in Skip mode depends on the labels of their direct
neighbors, while all other macroblocks are directly
labeled as background. Subsequent steps are spa-
tial and temporal filtering. These two steps are per-
formed to refine the segmentation. During spatial fil-
tering background macroblocks will be changed to
foreground, if most of their neighbors are foreground
as well. Foreground macroblocks will be changed to
background during temporal filtering, if they are nei-
ther foreground in the previous frame nor in the next
frame. The last refinement step is to evaluate bound-
ary macroblocks on a sub-macroblock level of size 4
by 4 pixels.
Extracting motion vectors and transform coeffi-
cients from a compressed video stream requires more
decoding steps than just extracting information about
macroblock types and partitions. Hence, attempts
have been made to directly analyze these syntax el-
ements.
(Verstockt et al., 2009) proposed an algorithm
for detecting moving objects by just extracting mac-
roblock partition information from H.264/AVC video
streams. First, they perform a foreground segmen-
tation by assigning macroblocks to foreground and
background, which results in a binary mask for the ex-
amined frame. Thereby, macroblocks in 16x16 parti-
tion mode (i.e., no sub-partitioning of the macroblock,
including the skip mode) are regarded as background
and all other macroblocks are labeled foreground. To
further enhance the generated mask, their algorithm
then performs temporal differencing of several masks
and median filtering of the results. In a final step,
objects are extracted by blob merging and convex
hull fitting techniques. (Verstockt et al., 2009) de-
signed their algorithm for multi-view object localiza-
tion. Hence, the extracted objects of a single view
then serve as input for the multi-view object detection
step.
A more basic detection method than moving ob-
ject detection is to detect global content changes
within scenes. (Laumer et al., 2011) designed a
change detection algorithm for RTP streams that does
not require video decoding at all. They presented the
method as a preselection for further analysis modules,
since change detection can be seen as a preliminary
stage of, e.g., moving object detection. Each moving
object causes a global change within the scene. Their
algorithm evaluates RTP packet sizes and number of
packets per frame. Since no decoding of video data is
performed the method is codec-independent and very
efficient.
The algorithm we present in this paper solely ex-
tracts and evaluates macroblock types to detect mov-
ing objects in H.264/AVC video streams. It can either
be performed as stand-alone application or be based
on the results of the change detection algorithm pre-
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
220

sented by (Laumer et al., 2011). Once a global change
within the scene is detected, the object detection al-
gorithm can be started to identify the cause of this
change.
3 MACROBLOCK TYPE
CATEGORIES AND SYNTAX
ELEMENTS
3.1 Categories and Weights
The H.264/AVC video compression standard was
jointly developed by the ITU-T VCEG (VCEG, 2011)
and the ISO/IEC MPEG (MPEG, 2010). It belongs to
the class of block-based hybrid video coders. In a
first step each frame of a video sequence will be di-
vided in several so-called slices and each slice will
be further divided in so-called macroblocks, which
have a size of 16 by 16 pixels. In a second step,
the encoder decides, according to a rate-distortion-
optimization (RDO), how each macroblock will be
encoded. Thereby, several different macroblock types
of three classes are available. The first class is used if
the macroblock should be intra-frame predicted from
its previously encoded neighbors. The second and
third classes are used in an inter-frame prediction
mode, which allows to exploit similarities between
frames. It is defined that macroblocks of the sec-
ond class are predicted by just using one predictor,
whereas macroblocks of the third class are predicted
by using two different predictors. They are called I, P,
and B macroblocks, respectively.
The same classification is defined for slices. In the
scope of this work, the H.264/AVC Baseline profile
is assumed. Within this profile, only I and P slices
are allowed. The 32 macroblock types available for
these two slice classes are grouped to six self-defined
macroblock type categories (MTC):
MB I 4x4. Intra-frame predicted macroblocks that
are further divided into smaller blocks of size 4 by
4 pixels.
MB I 16x16. Intra-frame predicted macroblocks that
are not further divided.
MB P 8x8. Inter-frame predicted macroblocks that
are further divided into smaller blocks of size 8 by 8
pixels.
MB P RECT. Inter-frame predicted macroblocks
that are further divided into smaller blocks of rect-
angular (not square) shape (16x8 or 8x16).
MB P 16x16. Inter-frame predicted macroblocks
that are not further divided.
Table 1: Macroblock type weights (MTW) of macroblock
type categories (MTC).
Slice
Type
MTC Assumption MTW
I MB I 4x4, n/a n/a
MB I 16x16
P MB I 4x4 most likely motion 3
P MB I 16x16 most likely motion 3
P MB P 8x8 likely motion 2
P MB P RECT likely motion 2
P MB P 16x16 maybe motion 1
P MB P SKIP most likely no motion 0
MB P SKIP. No additional data is transmitted for
these macroblocks. Instead, the motion vector pre-
dictor that points to the first reference frame is used
directly.
The decision of the RDO which macroblock type
will be used for encoding the block heavily depends
on the actual pixel data of this block and its difference
to previous frames. Therefore, evaluating macroblock
types can give a good guess of the location of moving
objects within the scene. In order to determine which
macroblock types indicate moving objects, an initial
macroblock type weight (MTW) has to be defined for
each category MTC first, which are shown in Table 1.
In I slices, only intra-coded macroblocks are al-
lowed. In this case, only two categories MTC are
available and no information about moving objects
can be derived. To solve this problem different solu-
tions are imaginable. One approach is to inter- or ex-
trapolate from neighboring slices if the current frame
consists of several slices. If the encoder configuration
just allows one slice per frame, the resulted fore- and
background segmentation mask of the previous frame
could be also used for the subsequent I frame. For fur-
ther enhancing this result, the mask could be interpo-
lated by also considering the mask of the subsequent
P frame, if the system configuration admits.
Intra-coded macroblocks are also available in P
slices. Within a P slice it is assumed that the two cat-
egories MB I 4x4 and MB I 16x16 indicate blocks
with high motion, because usually the encoder de-
cides to choose an I macroblock type if similar video
content could not be found in previous frames. There-
fore, it is most likely that an object has moved or just
entered the scene within this region.
Macroblock types of the both categories
MB P 8x8 and MB P RECT will usually be se-
lected by the encoder if blocks that are smaller than
16 by 16 pixels can be encoded more efficiently than
the entire macroblock. That usually means that these
regions are very structured and/or have been slightly
changed compared to previous frames. Hence, it is
CompressedDomainMovingObjectDetectionbasedonH.264/AVCMacroblockTypes
221

coded picture / frame
slice
macroblock
16x16
block
4x4
pixel
Figure 1: Sample hierarchical structure of block-based
video coding.
assumed that likely a moving object is present here.
Macroblocks that are not further divided (i.e., of
category MB P 16x16) indicate high uncertainty con-
cerning moving objects. On the one hand it is con-
ceivable that slowly moving objects with constant di-
rections are present in these regions, but on the other
hand the corresponding motion vector could be quite
short and this type has been selected because of a
slightly noisy source. Therefore, the assumption here
is that there is maybe motion.
The last category MB P SKIP is selected by the
encoder if the predicted motion vector points to an
area within the previous frame that is quite similar to
the current macroblock. That means that it is most
likely that there is no motion since there is nearly no
difference between the current and the previous frame
within this region.
Since objects usually extent over several mac-
roblocks, the moving object certainty (MOC) of a
macroblock highly depends on its neighboring mac-
roblocks. This is further described in Section 4.
3.2 Syntax Extraction
To be able to assign macroblocks to the previously
defined categories MTC, the macroblock types have
to be extracted from the bit stream. As already men-
tioned, H.264/AVC is a block-based video compres-
sion standard and has a hierarchical structure consist-
ing of five levels. Figure 1 illustrates this hierarchy.
The highest hierarchical level is a coded picture.
Since the Baseline profile of H.264/AVC does not
support interlaced coding, a coded picture within this
profile is always an entire frame. On the next level a
frame consists of at least one slice. If flexible mac-
roblock ordering (FMO) is not used, which is as-
sumed since FMO is rarely used in practice, a slice
consists of several consecutive macroblocks on the
third level. Each macroblock can be further divided in
smaller blocks, at which the smallest available block
has a size of 4 by 4 pixels.
H.264/AVC defines a huge number of syntax el-
ements. The most important for the presented al-
gorithm will be discussed in the following. The
nal unit type in the network abstraction layer
(NAL) unit header indicates if the contained coded
slice belongs to an instantaneous decoding refresh
(IDR) or non-IDR frame. IDR frames can only
consist of I slices while non-IDR frames are com-
posed of slices of any type. The actual type of
each slice is then encoded within its header by the
syntax element slice type. The beginning of the
slices within the current frame is encoded by the el-
ement first mb in slice, which can also be ex-
tracted from the slice headers. On macroblock level
two elements are extracted. As already mentioned, no
further information is transmitted if a macroblock is
encoded with P SKIP type. In this case, the bit stream
contains an element called mb skip run that indicates
the number of consecutive macroblocks in skip mode.
For all macroblocks in non-skip mode the algorithm
extracts the available syntax element mb type.
As soon as all these syntax elements are extracted
and parsed accordingly, the algorithm starts to evalu-
ate them, as described in the following section.
4 MOVING OBJECT DETECTION
ALGORITHM
4.1 Foreground/Background
Segmentation
The presented object detection algorithm relies on the
assumptions defined in Section 3. The H.264/AVC
syntax elements are extracted from the bit stream and
decoded, if required. The nal unit type is directly
accessible without decoding. To access the other syn-
tax elements the bit stream has to be parsed, i.e., en-
tropy decoded. Already during the parsing process
each macroblock is assigned to one of the six cate-
gories MTC and the corresponding weight MTW is
set.
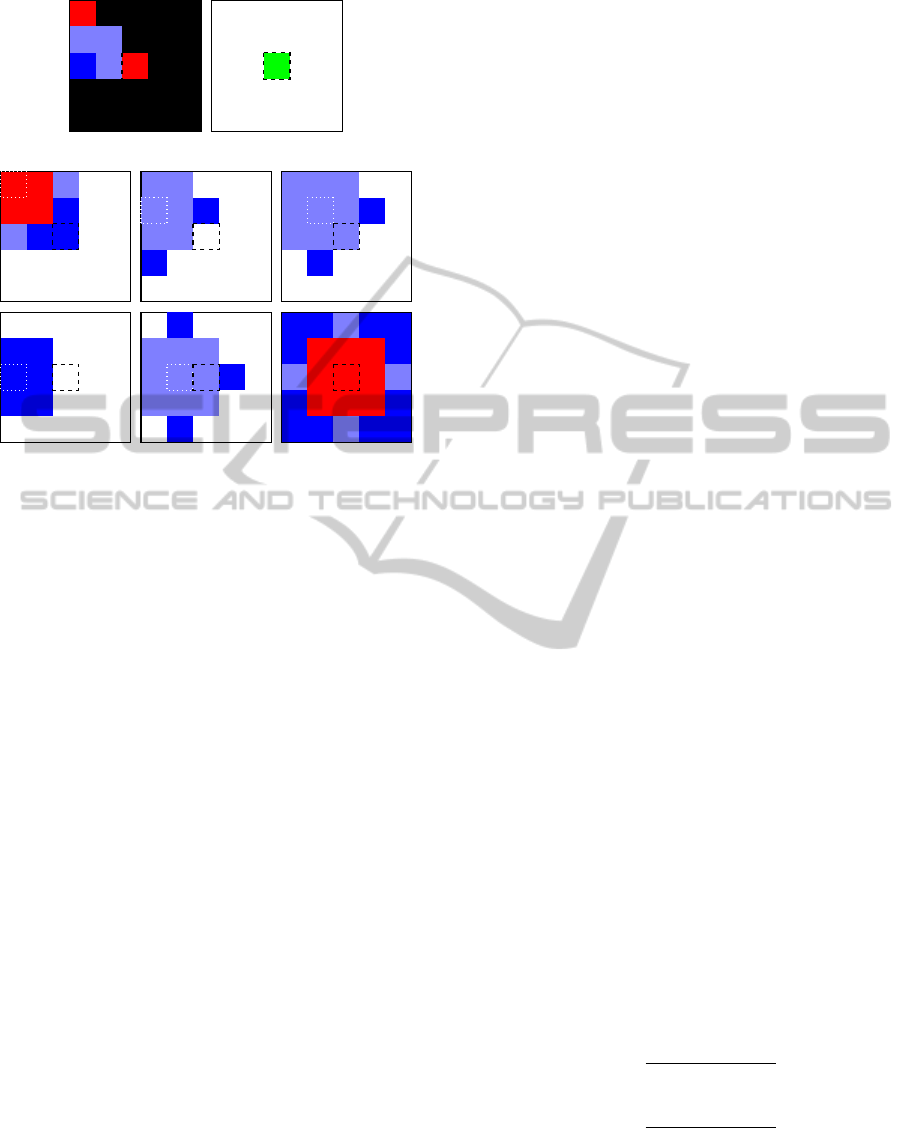
An example category MTC and weight MTW map
is shown in Figure 2(b) and Figure 2(c), respectively.
Thereby, the colors within the category MTC map are
defined as follows.
- MB I 4x4: light red
- MB I 16x16: red
- MB P 8x8: light blue
- MB P RECT: blue
- MB P 16x16: dark blue
- MB P SKIP: black
The weight MTW map (and also the certainty
MOC map in Figure 2(d)) is illustrated by a gray
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
222

(a) Original frame. (b) MTC map. (c) MTW map. (d) MOC map.
(e) Binary mask before box filtering. (f) Segmented frame before box filter-
ing.
(g) Binary mask after box filtering. (h) Segmented frame after box filter-
ing.
Figure 2: Sample maps and masks created by the algorithm (sequence: door).
-
2
-
1
0
1
2
0
1
2
3
-2
-
1
0
1
2
j
weight
i
-2 -1 0 1 2
-
2
0
0
0
0
0
-
1
0
1
1
1
0
0
0 1 1 1 0
1
0
1
1
1
0
2
0
0
0
0
0
(a) w
t
[x, y] = 1
-2
-1
0
1
2
0
1
2
3
-
2
-
1
0
1
2
j
weight
i
-
2
-
1
0
1
2
-2
0 0 1 0 0
-
1
0
2
2
2
0
0
1
2
2
2
1
1
0
2
2
2
0
2
0 0 1 0 0
(b) w
t
[x, y] = 2
-2
-
1
0
1
2
0
1
2
3
-2
-1
0
1
2
j
weight
i
-2 -1 0 1 2
-
2
1
1
2
1
1
-
1
1
3
3
3
1
0
2 3 3 3 2
1
1 3 3 3 1
2
1
1
2
1
1
(c) w
t
[x, y] = 3
Figure 3: 3-dimensional illustration of discrete kernels for different MTWs.
scale picture, at which brighter gray levels denote a
higher weight (or certainty in case of the certainty
MOC map).
The main challenge of the algorithm is to create
a robust map that indicates where within the scene
moving objects are located, or in other words to
transform category MTC/weight MTW maps to cer-
tainty MOC maps. These maps significantly differ
from each other, since weight MTW maps do not
take dependencies between neighboring macroblocks
into account while certainty MOC maps do. Mac-
roblocks have a size of 16 by 16 pixels. The as-
sumption that actual moving objects usually span over
several macroblocks requires to process them jointly.
The certainty c[x, y] of a single macroblock m[x, y]
(with Cartesian coordinates [x, y]) that depends on the
weights w
t
[x + i, y + j] of all macroblocks in a desig-
nated neighboring area (translation indicated by (i, j))
is defined as
c[x, y] =
2
∑
j=−2
2
∑
i=−2
w
i j
[x, y] , (1)
where
w
i j
[x, y] =
w
t
[x + i, y + j] , ∀i, j ∈ {−1, 0, 1}
(w
t
[x + i, y + j] − 1)
+
,
∀(i, j) ∈ {(−2, 0), (0, −2), (0, 2), (2, 0)}
(w
t
[x + i, y + j] − 2)
+
, otherwise .
Thereby, the operator (·)
+
is defined as
+
: Z → N
0
, a 7→ (a)
+
:= max(0, a) .
According to (1) the certainty MOC of a mac-
roblock depends on the weights MTW of its eight
direct neighbors and on the weights MTW of the 16
CompressedDomainMovingObjectDetectionbasedonH.264/AVCMacroblockTypes
223
3 0 0 0 0
00022
1
2
0 0
0
0
0 0 0
0 0 0 0 0
83
(a) MTC/MTW map and MOC.
1
1
1
2
2
3
33
3
2
2
2
2
2
1
1
2 2
2 2
22
2
2
1
1
2
2
1
11
1 1
1
2
222
2 2 2
1
1
2 2
1
3 3
3
333
3
3
2
22
2
1
1 1 1 1
1
1
1111
1
3
(b) Kernels of neighboring macroblocks (white dotted box) and the mac-
roblock itself (black dashed box).
Figure 4: Sample calculation of the MOC of a macroblock
(black dashed box).
neighbors of their direct neighbors. Thereby, the val-
ues are weighted according to their distance to the
current macroblock. Direct neighbors are weighted
just like the macroblock itself. Neighbors in higher
distance factor into the certainty MOC with decreased
weight, since it is assumed that the mutual interdepen-
dence with respect to the presence of an object is also
lower.
A more illustrative description of the algorithm is
depicted in Figure 4. At each macroblock position
(white dotted boxes in Figure 4(b)) a discrete kernel
is set according to the macroblocks weight MTW. In
case the weight MTW equals 0 all points of the kernel
are also 0, i.e., the weight MTW of this macroblock
does not affect any other macroblock. The three other
kernels can be seen in Figure 3. Once the kernels of
the relevant neighboring macroblocks are set, the cer-
tainty MOC of the current macroblock is calculated
by summarizing all overlapping kernel values at its
position (black dashed box). In the example in Fig-
ure 4(a) this equals 1 + 0 + 2 + 0 + 2 + 3 = 8.
Note that if the current macroblock lies near the
frame border, some of its neighbors will not exist. In
this case the weight MTW map is extended to the re-
quired size and the weights MTW of the new border
macroblocks are set to 0.
The next step of the algorithm is to segment the
current frame to fore- and background. Thereto, the
calculated certainty MOC map is thresholded by t.
Whether a macroblock m[x, y] is part of the fore-
ground is calculated by
m[x, y] =
1 , c[x, y] ≥ t
0 , otherwise
, (2)
where 1 indicates the foreground and 0 indicates the
background of the scene, which is illustrated within
the binary masks in Figure 2(e) and Figure 2(g) by
white and black blocks, respectively.
4.2 Box Filtering
The resulting binary mask of the segmentation pro-
cess is then further refined by an nxn box filtering pro-
cess. That means if most neighboring macroblocks in
a surrounding nxn region (including the macroblock
itself) of a single macroblock are labeled as fore-
ground, the macroblock is also labeled as foreground,
and vice versa. The purpose of this step is to elim-
inate very rarely occurring holes within objects and
to filter out remaining single foreground labeled mac-
roblocks. Furthermore, object edges are smoothened,
as can be seen in Figure 2(g), which represents the
filtered version of Figure 2(e).
5 EXPERIMENTAL RESULTS
5.1 Performance Measures
The performance of the method is measured by the
following procedure. Since the analysis is frame-
based, for each frame k a manually labeled ground
truth states the set of pixels S
pix
[k] of the moving ob-
jects. The proposed algorithm segments macroblocks
to fore- and background. This is the reason why we
also defined the set of macroblocks S
mb
[k] for each
frame k as ground truth. Thereby, a macroblock is
denoted as foreground, if at least one of its pixels is
considered foreground.
Two conventional measures are used to evaluate
the results: recall and precision. For comparing set of
pixels, they are defined as
r
pix
[k] =
N
pix
c
[k]
N
pix
c
[k] + N
pix
m
[k]
, (3)
p
pix
[k] =
N
pix
c
[k]
N
pix
c
[k] + N
pix
f
[k]
, (4)
where N
pix
c
[k] is the number of correctly detected pix-
els, N
pix
m
[k] is the number of missed pixels, i.e., pix-
els that are labeled foreground in the ground truth but
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
224
Table 2: Experimental results of several test sequences.
Sequence r
pix
p
pix
r
mb
p
mb
door 0.96 0.81 0.95 0.88
room1pFreeBlk 0.99 0.40 0.98 0.60
room2pXingDiagBlk 0.97 0.47 0.95 0.65
room2pXingEqMix 0.58 0.50 0.57 0.64
room2pXingDiagMix 0.84 0.48 0.83 0.60
campus4-c0 0.75 0.48 0.71 0.74
campus7-c1 0.98 0.65 0.95 0.82
laboratory4p-c0 0.99 0.38 0.98 0.57
laboratory6p-c1 0.98 0.16 0.97 0.29
terrace1-c0 0.98 0.40 0.96 0.66
terrace2-c1 0.98 0.41 0.97 0.68
have not been detected, and N
pix
f
[k] is the number of
pixels that have falsely been considered foreground.
Similarly, recall and precision on macroblock
level are defined as
r
mb
[k] =
N
mb
c
[k]
N
mb
c
[k] + N
mb
m
[k]
, (5)
p
mb
[k] =
N
mb
c
[k]
N
mb
c
[k] + N
mb
f
[k]
. (6)
The final step to get recall and precision measures
for a whole sequence is an averaging process. The
pixel measures are defined as
r
pix
=
1
N
frame
∑
k
r
pix
[k] , (7)
p
pix
=
1
N
frame
∑
k
p
pix
[k] , (8)
and the macroblock level measures are defined as
r
mb
=
1
N
frame
∑
k
r
mb
[k] , (9)
p
mb
=
1
N
frame
∑
k
p
mb
[k] , (10)
where N
frame
is the number of frames of the sequence.
5.2 Test Sequences and Setup
The algorithm has been tested with several
H.264/AVC video sequences, including sequences
from the data set of CVLAB (Berclaz et al., 2011)
and self-created sequences. A detailed description
for each test sequence is given in the Appendix.
The sequences have been encoded with variable
bit rate by an own implementation of the H.264/AVC
Baseline profile. The GOP size has been set to ten
frames. During the segmentation process we set t =
6, which fits best to the defined macroblock weights
MTW. For box filtering we applied a 3x3 filter.
5.3 Result Discussion
An overview of the results is given in Table 2.
The first column r
pix
represents the recall values
of comparison between the ground truth in pixel accu-
racy with the results of the algorithm in macroblock
accuracy. Although the resulting foreground masks
are block-based, for the majority of sequences the
method achieves 96% and above. That means that al-
most all foreground pixels could be detected correctly
and only very little have been missed. This can also
be seen in the third column r
mb
, which represents the
recall values of comparison between the results of the
algorithm with the ground truth in macroblock accu-
racy. Macroblock accuracy in this scope means that
each macroblock with at least one foreground pixel
is regarded as foreground. In many cases, e.g., if the
object is located at the edge of a macroblock row or
column, this consideration will lead to more pixels la-
beled as foreground as their actual amount. That is
the reason why values in the third column are always
slightly smaller than in the first column.
For a few sequences in Table 2 the algorithm
does not achieve very high recall values. This oc-
curs when objects stop moving within the scene. In
case an annotated object stops but is still visible, it
is correctly labeled foreground in the ground truth,
but most encoders will decide to use Skip mode
for its macroblocks. Hence, our algorithm is not
able to detect these objects anymore because they
do not differ from the background. This happens in
sequences room2pXingEqMix, room2pXingDiagMix,
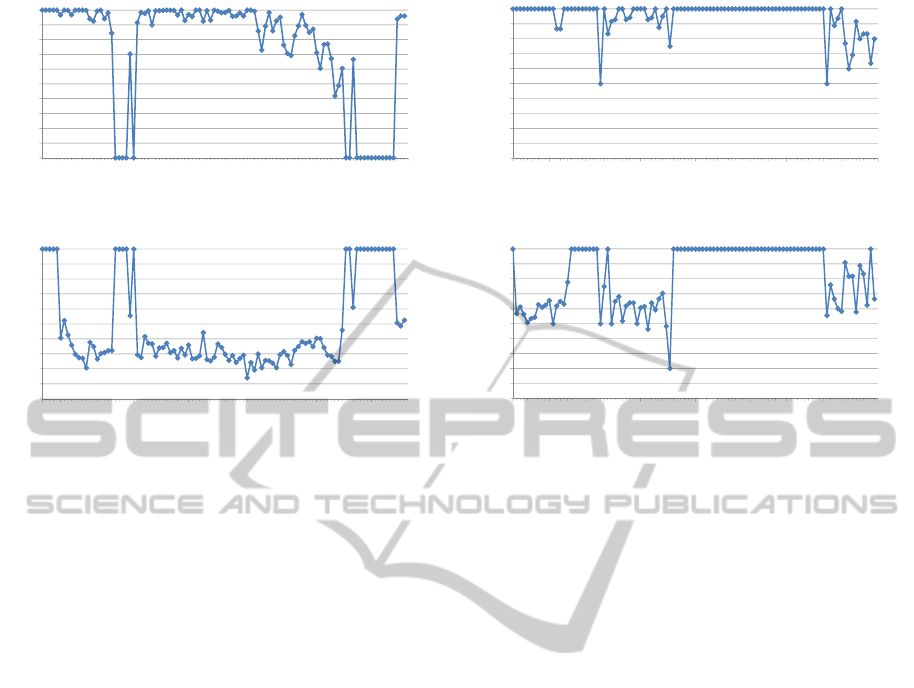
and campus4-c0. Figure 5 illustrates the recall r
pix
and precision p
pix
values for each frame with avail-
able ground truth of sequence campus4-c0. Approx-
imately between frames 200 and 250 the only visible
person stops moving. During this period, recall val-
ues drop to almost 0, while corresponding precision
values increase to 100%. This means that on the one
hand this object can admittedly not be detected cor-
rectly, but on the other hand also no false detections
occur. The same behavior can be seen at the end of
the sequence, where the three visible persons stop one
after another to talk to each other.
The second and fourth columns in Table 2 repre-
sent the precision of the algorithm. The values for
pixel accuracy comparison p
pix
do not achieve that
high percentage than their corresponding recall val-
ues. The main reason for this is that it is not possible
to completely eliminate false detections with an ac-
curacy of macroblock size. Therefore, comparing the
detection results to ground truth in macroblock accu-
racy, as can be seen in column p
mb
, achieves a signifi-
cantly increased precision, up to 27 percentage points.
CompressedDomainMovingObjectDetectionbasedonH.264/AVCMacroblockTypes
225
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
15 65 115 165 215 265 315 365 415 465 515 565 615 665 715 765 815 865 915 965 1015
r
pix
[k]
Frame k
(a) Recall.
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
15 65 115 165 215 265 315 365 415 465 515 565 615 665 715 765 815 865 915 965 1015
p
pix
[k]
Frame k
(b) Precision.
Figure 5: Recall and precision in pixel accuracy of sequence
campus4-c0.
Even though macroblock accuracy comparison
improves the results, precision values mostly do not
exceed 70%. There are mainly two reasons: object
shadows and image noise.
Mainly in outdoor sequences moving objects have
shadows that will move accordingly. The algorithm
detects these shadows as moving regions as well, be-
cause it is not possible to distinguish between ac-
tual objects and shadows on macroblock level. This
leads to an increased number of false detections. Fig-
ure 6 shows recall and precision values of sequence
campus7-c1. Within this scene, approximately be-
tween frames 175 and 250 and frames 455 and 865
no visible moving objects occur. During this period
of frames both recall and precision are constantly at
100%. The latter demonstrates that during the ab-
sence of moving objects no macroblocks are falsely
detected as moving regions, i.e., in this setup mostly
false detections are caused by shadows.
The second reason for false detections is im-
age noise. The video content of the sequences
laboratory4p-c0 and laboratory6p-c1 is quite noisy.
In such sequences the difference between frames with
similar content is significantly larger than in high-
quality sequences. Therefore, macroblocks in not par-
titioned or Skip modes are rarely used during the en-
coding process, i.e., the algorithm will not only detect
the actual objects as moving regions but significantly
noisy regions as well.
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
15 65 115 165 215 265 315 365 415 465 515 565 615 665 715 765 815 865 915 965 1015
r
MB
[k]
Frame k
(a) Recall.
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
15 65 115 165 215 265 315 365 415 465 515 565 615 665 715 765 815 865 915 965 1015
p
MB
[k]
Frame k
(b) Precision.
Figure 6: Recall and precision in macroblock accuracy of
sequence campus7-c1.
5.4 Processing Speed
The processing speed of the algorithm depends on the
video resolution of the test sequence and the number
of moving objects that are present within the scene.
Several measurements pointed out that our C++ im-
plementation (without code optimizations or paral-
lel processing) is able to process about 3600 frames
per second of sequences in CIF resolution and 1900
frames per second of sequences in VGA resolution,
measured on an Intel
R
Core
TM
i5-2520M CPU @ 2.5
GHz with 4 GB RAM. The average number of pro-
cessed frames per second for each sequence is given
in Table 3.
6 CONCLUSIONS
In this paper, we presented a novel compressed do-
main moving object detection method based on ana-
lyzing macroblock types only. The frame-based al-
gorithm extracts and evaluates the type of each single
macroblock. Thereby, the macroblocks get assigned a
moving object certainty that is calculated by factoring
in the types of neighboring macroblocks. The results
could demonstrate that this approach reaches suit-
able detection rates within the limits of compressed
domain processing, despite its very low complexity.
This enables its use as an adequate preselection step
within a multi-tier parallel processing system. It is
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
226

Table 3: Average number of processed frames per second.
Resolution Sequence Frames per
Second
CIF door 7587.82
campus4-c0 4636.33
campus7-c1 4878.68
laboratory4p-c0 1953.28
laboratory6p-c1 1366.58
terrace1-c0 2496.29
terrace2-c1 2628.99
Average: 3649.71
VGA room1pFreeBlk 1693.33
room2pXingDiagBlk 1921.42
room2pXingEqMix 2202.27
room2pXingDiagMix 1820.84
Average: 1909.47
envisioned to further enhance the method by refining
the segmentation process to be able to eliminate in-
appropriate objects caused by, e.g., shadows, and ex-
ploiting temporal dependencies between consecutive
frames. The latter also enables the algorithm to track
moving objects.
ACKNOWLEDGEMENTS
The research leading to these results has received
funding from the European Union’s Seventh Frame-
work Programme ([FP7/2007-2013]) under grant
agreement no. 285248 (FI-WARE).
REFERENCES
Berclaz, J., Fleuret, F., Turetken, E., and Fua, P. (2011).
Multiple Object Tracking Using K-Shortest Paths Op-
timization. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 33(9):1806–1819.
Comaniciu, D. and Meer, P. (2002). Mean Shift: A Ro-
bust Approach Toward Feature Space Analysis. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 24(5):603–619.
Fei, W. and Zhu, S. (2010). Mean Shift Clustering-based
Moving Object Segmentation in the H.264 Com-
pressed Domain. IET Image Processing, 4(1):11–18.
Laumer, M., Amon, P., Hutter, A., and Kaup, A. (2011). A
Compressed Domain Change Detection Algorithm for
RTP Streams in Video Surveillance Applications. In
Proc. IEEE 13th Int. Workshop on Multimedia Signal
Processing (MMSP), pages 1–6.
Mak, C.-M. and Cham, W.-K. (2009). Real-time Video Ob-
ject Segmentation in H.264 Compressed Domain. IET
Image Processing, 3(5):272–285.
MPEG (2010). ISO/IEC 14496-10:2010 - Coding of Audio-
Visual Objects - Part 10: Advanced Video Coding.
Poppe, C., De Bruyne, S., Paridaens, T., Lambert, P., and
Van de Walle, R. (2009). Moving Object Detec-
tion in the H.264/AVC Compressed Domain for Video
Surveillance Applications. Journal of Visual Commu-
nication and Image Representation, 20(6):428–437.
Porikli, F., Bashir, F., and Sun, H. (2010). Compressed
Domain Video Object Segmentation. IEEE Transac-
tions on Circuits and Systems for Video Technology,
20(1):2–14.
Qiya, Z. and Zhicheng, L. (2009). Moving Object Detection
Algorithm for H.264/AVC Compressed Video Stream.
In Proc. Int. Colloquium on Computing, Communica-
tion, Control, and Management (CCCM), volume 1,
pages 186–189.
Szczerba, K., Forchhammer, S., Stottrup-Andersen, J., and
Eybye, P. T. (2009). Fast Compressed Domain Motion
Detection in H.264 Video Streams for Video Surveil-
lance Applications. In Proc. Sixth IEEE Int. Conf.
on Advanced Video and Signal Based Surveillance
(AVSS), pages 478–483.
VCEG (2011). H.264: Advanced Video Coding for Generic
Audiovisual Services.
Verstockt, S., De Bruyne, S., Poppe, C., Lambert, P., and
Van de Walle, R. (2009). Multi-view Object Local-
ization in H.264/AVC Compressed Domain. In Proc.
Sixth IEEE Int. Conf. on Advanced Video and Signal
Based Surveillance (AVSS), pages 370–374.
Wang, R., Zhang, H.-J., and Zhang, Y.-Q. (2000). A Confi-
dence Measure Based Moving Object Extraction Sys-
tem Built for Compressed Domain. In Proc. IEEE
Int. Symp. on Circuits and Systems (ISCAS), volume 5,
pages 21–24.
APPENDIX
A detailed description for each test sequence is given
in Table 4 and Table 5. Column ’GT Distance’ in-
dicates the distance of frames with available ground
truth.
CompressedDomainMovingObjectDetectionbasedonH.264/AVCMacroblockTypes
227

Table 4: Detailed description of self-created test sequences.
Sequence N
frame
Resolution FPS GOP Size GT Distance Sample Frame
door 794 352x288 30 10 1
room1pFreeBlk 423 640x480 30 10 1
room2pXingDiagBlk 196 640x480 30 10 10
room2pXingEqMix 246 640x480 30 10 10
room2pXingDiagMix 174 640x480 30 10 10
Table 5: Detailed description of CVLAB test sequences.
Sequence N
frame
Resolution FPS GOP Size GT Distance Sample Frame
campus4-c0 1005 352x288 25 10 10
campus7-c1 1005 352x288 25 10 10
laboratory4p-c0 1005 352x288 25 10 10
laboratory6p-c1 1005 352x288 25 10 10
terrace1-c0 1005 352x288 25 10 10
terrace2-c1 1005 352x288 25 10 10
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
228
