
Caching Strategies for In-memory Neighborhood-based Recommender
Systems
Simon Dooms, Toon De Pessemier and Luc Martens
WiCa group, Dept. of Information Technology, iMinds-Ghent University
Gaston Crommenlaan 8 box 201, B-9050 Ghent, Belgium
Keywords:
Recommender Systems, Cache, LRU, SMART, Speedup.
Abstract:
Neighborhood-based recommender systems rely greatly on calculated similarity values to match interesting
items with users in online information systems. Because sometimes there are too many similarity values
or available memory is limited it is not always possible to calculate and store all these values in advance.
Sometimes only a subset can be stored and recalculations cannot be avoided. In this work we focus on caching
systems that optimize this trade-off between memory requirements and computational redundancy in order to
speed up the recommendation calculation process. We show that similarity values are not equally important
and some are used considerably more than others during calculation. We devised a caching strategy (referred
to as SMART-cache) that incorporates this usage frequency knowledge and compared it with a basic least
recently used (LRU) caching mechanism. Results showed total execution time could be reduced by a factor
of 5 using LRU for a cache storing only 0.2% of the total number of similarity values. The speedup of the
SMART approach on the other hand was less affected by the order in which user-item pairs were calculated.
1 INTRODUCTION
Every day recommender systems in al kinds of do-
mains are processing huge amounts of data to match
users with items in a personalized way. Because user
adoption increases, technical requirements such as
performance in terms of execution time and memory
usage of these systems are becoming increasingly im-
portant. Especially for online scenarios (e.g., movie
recommendation website) execution time can be the
differentiating factor between real-time incorporating
user feedback and daily batch processing. In this
work we try to reduce execution time and allow flexi-
ble memory usage by introducing caching principles.
A cache enables rapid access to popular or fre-
quently accessed data (Qasim, 2011). Its use can sig-
nificantly speed up data throughput and therefore also
greatly impacts the total execution time of algorithms
that are largely data dependent (e.g., recommender
systems).
We will focus on collaborative filtering systems,
more specifically nearest neighbor (k-NN) algorithms
because they are most likely to benefit from cache en-
hancement. The general idea behind collaborative fil-
tering algorithms is that community knowledge can
be exploited to generate more accurate recommenda-
tions for individual users (Jannach et al., 2011). Near-
est neighbor algorithms try to harvest this community
information to identify similar users or items in the
system. Similarity can be computed in many ways,
but most often involves comparing the ratings either
given by users or received by items and the calcu-
lation of some kind of similarity metric. The rating
behavior of such similar neighbors can then be used
to extrapolate ratings for new users or items. These
types of algorithms will have to determine the pair-
wise similarity values for all users or items in the sys-
tem, values which will then be reused many times dur-
ing the recommendation calculations and seem there-
fore very suited for caching.
Research literature is rather limited when it comes
to the subject of caches and recommender systems.
To our knowledge, two main contributions exist that
report on enhancing recommendation response times
through the use of caches. The work of Qasim et
al. has introduced the concept of partial-order based
active cache (Qasim et al., 2009) in which they con-
struct a caching system that allows to estimate nearest
neighbor type queries from other queries in the cache.
The usefulness of the cache is thereby extended be-
yond exact previously-cached entries. The caching
structure is intended to prevent recommendation lists
435
Dooms S., De Pessemier T. and Martens L..
Caching Strategies for In-memory Neighborhood-based Recommender Systems.
DOI: 10.5220/0004351704350440
In Proceedings of the 9th International Conference on Web Information Systems and Technologies (WEBIST-2013), pages 435-440
ISBN: 978-989-8565-54-9
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

to be calculated by estimating them using only previ-
ous answers in the cache.
Another cache-enhanced recommender system
was the genSpace recommender system presented by
Sheth et al. as a prefetching cache that prefetches
all recommendations in order to prevent slow recom-
mendation calculation on-demand (Seth and Kaiser,
2011). Their approach differs from ours since their
cache rather prevents unnecessary recommendation
recalculation while we attempt to speed up the calcu-
lation of the complete recommendation process (rat-
ing prediction for all users and items) in order to re-
duce overall calculation time without compromising
recommendation accuracy.
Our contribution comprises the study of how sim-
ilarity values are used during recommendation calcu-
lations (for user-based collaborative filtering) and the
introduction of a new caching principle (i.e., SMART
cache) that takes advantage of this knowledge.
In the next sections we will define the user-based
collaborative filtering (UBCF) algorithm and show
why and how this algorithm may benefit from caching
internal values.
2 UBCF ALGORITHM
We specifically focus on in-memory recommen-
dation algorithms, which we define as algorithms
working completely in the random-access memory
(RAM) of the computer without using external data
resources (e.g., databases or files) for data storage
or retrieval during computation. Because the RAM
of a computing machine is usually limited in size,
keeping track of all internal temporary values (e.g.,
similarity values) may be impossible and some kind
of caching paradigm can be introduced. To be able
to experiment with different caching modes with
respect to in-memory recommendation algorithms,
we implemented the well known user-based collabo-
rative filtering algorithm (Jannach et al., 2011). This
algorithm is widely accepted and commonly used in
recommender systems in various domains (Jannach
et al., 2011). Here we apply it to predict a rating for
all user-item pairs, based on the ratings of similar
users (i.e., neighbors). The high-level algorithm
structure can be found in the following pseudocode
fragments.
Algorithm Recommendation calculation
for user in users
for item in items
rec value ← Calc rec value(user, item)
End ALGORITHM
Function Calc rec value(user, item)
vote ← 0
weights ← 0
neighbors ← Neighbors who rated item(user,
item)
for neighbor in neighbors
simil ← neighbor similarity
rating ← neighbor rating
vote ← vote + (simil × rating)
weights ← weights + simil
Return vote / weights
End FUNCTION
Function Neighbors who rated item(user, item)
for neighbor in {users who rated item}
neighbor similarity ← Pearson(user, neigh-
bor)
Return the 20 most similar neighbors together
with their original rating for item (neighbor rating).
End FUNCTION
Our implementation employs a simple weighted
average scheme to come up with the final recom-
mendation value. Pearson correlation (Resnick et al.,
1994) was used as similarity metric and the neigh-
borhood size was restricted to the top 20 neighbors
(as was found to be a reasonable amount (Herlocker
et al., 2002)). A straightforward linear transformation
was employed to rescale the Pearson correlation value
from [-1,+1] to [0,1] to simplify the calculations.
3 USAGE OF SIMILARITIES
To calculate the predicted rating of a user for an item,
neighboring users will have to be determined. That in
turn requires the pair-wise similarity of that user with
every other user in the system that rated the item. The
most important line of code here is:
neighbor similarity ← Pearson(user, neighbor)
Using a code profiler, we analyzed the runtime of
our recommender system and found that 78% of the
total execution time was spent calculating these simi-
larity values. Therefore, in this work, we want to con-
struct a caching system fit for the storage of exactly
these values in order to reduce recalculation overload
on the one hand and memory (RAM) requirements on
the other hand.
We start off with the hypothesis that not all cal-
culated similarity values are equally useful. So when
the recommendation values for all user-item pairs are
calculated, in the end some user similarity values will
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
436

have been used more than others.
To gain insight into the distribution of the usage of
user-user similarity values, we set up an experiment
using the MovieLens dataset
1
. This dataset has been
a popular tool for many researchers of recommender
systems because of its high density (Park et al., 2006)
and straightforward domain (i.e., movies). In our ex-
periments we used the 100K dataset, which comprises
100K ratings of 943 users on 1682 movies. More de-
tails about this dataset can be found in recommender
system literature.
We calculated the recommendation value for each
user-item pair in the dataset (without caching) and
kept track of how frequent every user-user similarity
was used. User similarity (with Pearson correlation)
is a symmetric relationship and so the total number of
calculated user-user couples can be defined as
943∗942
2
(self similarities are not taken into account). Fig. 1
shows every one of these couples on the x-axis and
their corresponding usage frequency on the y-axis.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5
x 10
5
0
200
400
600
800
1000
1200
User similarities usage frequency
User−user couples
Usage frequency
Figure 1: Every user-user couple in the system with its cor-
responding usage frequency. Couples are ordered by de-
scending frequency.
Since Fig. 1 does not show a horizontal flat line
but rather a long tail curve, we find our hypothesis
confirmed: Some user similarities are more frequently
used than others in the recommendation calculation
process. The question now remains on how we can
use this knowledge to our advantage. In the previ-
ous section the problem of limited RAM was already
mentioned. Because of this limitation it may be im-
possible to simply compute all user-user similarities
and keep them available in memory during the rec-
ommendation calculation. So if we can store only a
limited amount of pre-calculated similarity values in
memory, it may be a good idea to make sure the most
interesting values are stored. If we define most inter-
1
http://www.grouplens.org/node/73
esting as ‘most used’ then we need a way of predict-
ing how much a given user-user similarity value will
be used throughout the recommendation process.
The usage frequency of user similarity values will
be largely dependent on the number of ratings pro-
vided by each user. Users with a large number of
ratings may show overlap (rated the same items) with
more users and their similarity will consequentially be
needed more often. To examine the correlation of the
number of ratings of users with their similarity usage
throughout the recommendation process, we set up an
experiment with three simple usage prediction formu-
las (i.e., min, max, and sum). For each user-user sim-
ilarity value we tried to predict its usage by applying
each of the aggregation operators in Table 1 on the
number of ratings of both users.
Table 1: Aggregation operators to be applied to the num-
ber of ratings of a user-user pair in order to predict the fre-
quency usage of the similarity value throughout the recom-
mendation process.
Aggregation operators
minimum number o f ratings(user
x
, user
y
)
maximum number o f ratings(user
x
, user
y
)
sum number o f ratings(user
x
, user
y
)
Fig. 2 plots the prediction formulas applied to all
user-user similarity pairs in the system together with
the empirically measured actual usage value. As ex-
pected, we can see a correlation between the total
number of ratings of a user-user pair and its usage fre-
quency. The maximum operator seems to be the best
estimation operator but has still has a far from perfect
accuracy.
To improve this accuracy, we looked into deter-
ministically computing the usage frequency instead
of predicting it in a heuristic way. We considered the
abstract user similarity pair (u
x
, u
y
). This similarity
may be used while calculating the recommendation
pair (u
x
, i) with i an item that u
x
has not rated. To
determine the recommendation value of (u
x
, i), user
similarities of u
x
are needed for every user that has
rated item i (see UBCF algorithm in Section 2). So
the similarity pair (u
x
, u
y
) will be calculated a num-
ber of times equal to the number of items that u
y
has
rated, but that are not rated by u
x
. Since the user sim-
ilarity has symmetric properties, the user similarity of
(u
x
, u
y
) and (u
y
, u
x
) will be the same, and both should
be taken into account. To conclude we can state that
the number of times a user similarity pair (u
x
, u
y
) will
be used during the UBCF recommendation process,
will be equal to the sum of the number of items rated
by u
y
but not by u
x
and the number of items rated by
u
x
but not by u
y
. We can reformulate this as the car-
dinality of the inverse intersection of the sets of rated
CachingStrategiesforIn-memoryNeighborhood-basedRecommenderSystems
437
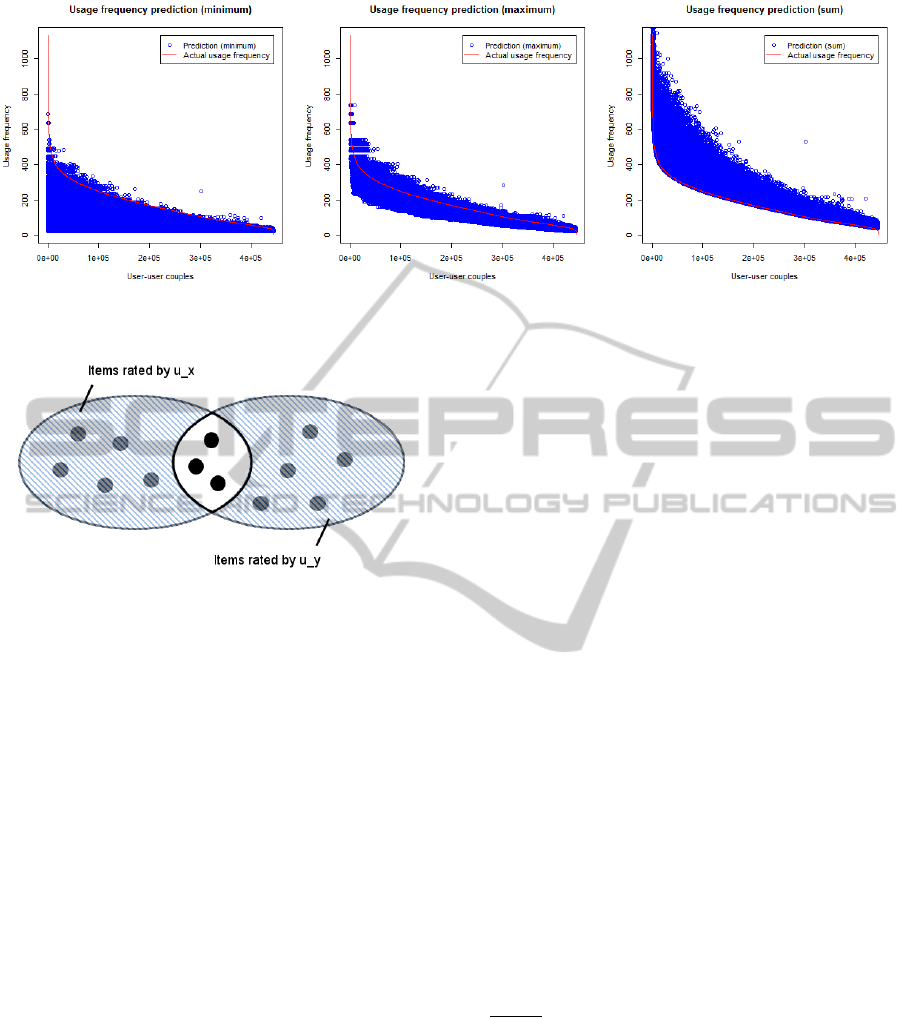
Figure 2: Prediction of the usage frequency of user-user similarity values by means of three aggregation operators together
with the actual empirically measured usage frequency.
Figure 3: Venn diagrams indicating the items rated by users
u
x
and u
y
. The cardinality of the inverse intersection cor-
responds to the usage frequency of the similarity value
(u
x
, u
y
).
items by u
x
and u
y
as shown in Fig. 3.
In the next sections we experiment with a caching
system that incorporates this usage frequency knowl-
edge and measure how it affects overall performance.
4 CACHING ALGORITHMS
To measure the impact of caching on the performance
of the UBCF algorithm, we compare two different
caching strategies. On the one hand we work with the
existing LRU (Least Recently Used) caching princi-
ple and on the other hand we present our self-designed
‘SMART’ cache.
The LRU caching principle is a commonly used
caching system where entries that have been used the
least recently will be overwritten when the cache is
full. This approach follows the temporal locality prin-
ciple that recently requested data has a high probabil-
ity to be requested again in the near future (Qasim,
2011). A disadvantage of LRU is that only the time
of the data access is considered and not the frequency.
Therefore we devised a ‘SMART’ cache which takes
this data frequency information into account.
The SMART cache is a type of priority cache that
incorporates information about how much an entry
will be accessed throughout the program life cycle.
Every cache entry is associated with a priority that re-
flects the number of times the entry will be accessed.
When the cache is full, a new entry with a larger prior-
ity (i.e., predicted number of accesses) will overwrite
an existing one with the lowest priority.
5 EXPERIMENTS AND RESULTS
The first thing to measure is the performance of
the UBCF algorithm when using either the LRU or
SMART caching strategy. As baseline we consid-
ered the UBCF algorithm implementation without a
cache. In that case no user similarities are stored
and they have to be recalculated every time they are
used throughout the recommendation calculation. We
compared the execution time of this baseline algo-
rithm to the UBCF algorithm with an LRU cache or
SMART cache for storing the user similarities during
execution. Recommendation values (predicted rat-
ings) were calculated for all user-item pairs in the
MovieLens (100K) dataset. The experiment was re-
peated for cache sizes of 20%, 40%, 60%, 80% and
100%. This cache size is expressed as a percentage of
the total number of user-user similarity values (which
is
n∗(n−1)
2
for n the number of users in the system). A
cache size of 100% therefore indicates that all user-
user similarity values can be stored in memory and no
values need to be recalculated. Fig. 4 shows the re-
sults in terms of speedup (i.e., execution time reduc-
tion compared to the baseline) for the different set-
tings.
The simple LRU caching principle performed
considerably better than the SMART system for the
low cache sizes (20% and 40%). When the cache size
grows, this difference decreases, and with cache sizes
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
438
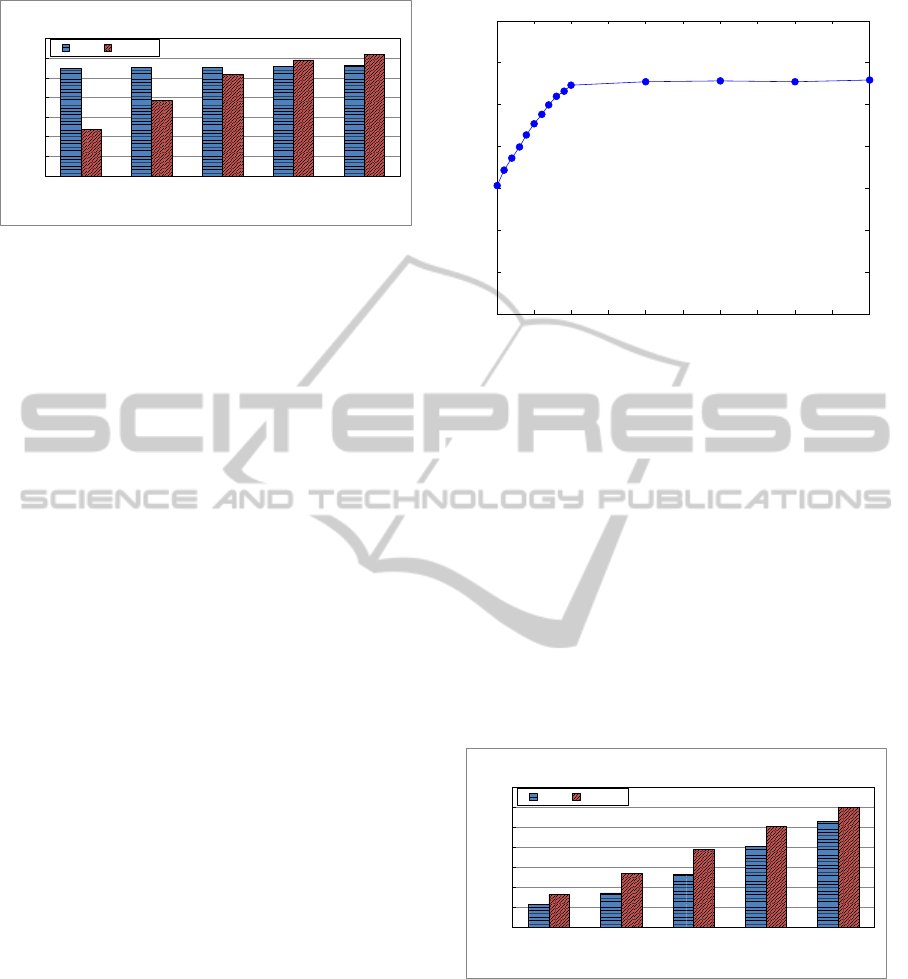
0
1
2
3
4
5
6
7
20% 40% 60% 80% 100%
Speedup
Cache Size (100% = complete cache)
Speedup results (outer-user ordering)
LRU SMART
Figure 4: Speedup results for the LRU and SMART caching
approaches towards the no-caching baseline for different
cache sizes.
nearing 100%, the SMART approach overtakes LRU
in terms of speedup towards the baseline. Interest-
ingly, the performance of the LRU system remains
stable between speedup values of 5 and 6 (in com-
parison to the SMART system) for the varying cache
sizes. This seems to indicate that the LRU caching
system has an optimal cache size (where performance
gain saturates) below the 20% limit.
We repeated the experiment using only the LRU
cache and tested with smaller cache stepsizes. Fig. 5
shows the results of an interesting range for cache
sizes between 0.1% and 0.6%. Zoomed in on that
range, the saturation effect of the speedup towards the
baseline is clearly visible. While the SMART caching
approach seemed to linearly improve with an increas-
ing cache size, the LRU reaches a saturated maximum
speedup value at a cache size between 0.2% and 0.3%.
This range seems to correspond with the amount of
user similarities associated with one user. For our
dataset, there are 943 users and so 942 (n − 1) user
similarities per user. To store 942 user similarities in
the cache, a cache size of 0.21% would be needed.
This 0.21% corresponds to the optimal cache size in
the range 0.1% and 0.6%.
The performance of a cache depends partly on the
order in which new entries are provided, therefore it is
interesting to see how the 2 caching systems perform
under altered job execution orderings. The order in
which the user-user similarity values will be inserted
in the cache depends greatly on how the UBCF algo-
rithm loops over the different user-item pairs. In our
reference implementation (see pseudocodefragment
in Section 2) we calculate the recommendation value
for every user for every item in that specific order.
So the user-item pairs will be sequentially (u
1
, i
1
),
(u
1
, i
2
), ... (u
1
, i
n
i
), (u
2
, i
1
), (u
2
, i
2
), ... (u
2
, i
n
i
),
... (u
n
u
, i
n
i
) for n
u
and n
i
being respectively the total
number of users and items. Since every user is han-
dled sequentially, many similarities will be re-used in
short intervals. This behavior is exactly what the LRU
caching approach takes advantage of and would ex-
0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6
0
1
2
3
4
5
6
7
LRU Speedup results (outer−user ordering)
Cache Size (in percentage)
Speedup
Figure 5: Speedup results for the LRU cache with smaller
cache sizes to reveal the performance gain saturation point.
plain its success compared to the SMART cache.
To study the impact of the job order on the caching
performance, the experiment was re-run with an al-
tered job ordering. To change the order in which sim-
ilarities would be inserted in the cache, we simply
switched the first two lines of the pseudocodefrag-
ment. Because of the switch, user-item pairs are pro-
cessed iterating over the items first. We refer to this
approach as the ‘outer-item’ order (as opposed to the
‘outer-user’ order, which we started off with). The
corresponding user-item pairs will now be sequen-
tially (u
1
, i
1
), (u
2
, i
1
), ... (u
n
u
, i
1
), (u
1
, i
2
), (u
2
, i
2
),
... (u
u
n
, i
2
), ... (u
n
u
, i
n
i
). Fig. 6 shows the speedup
results for this altered scenario.
0
1
2
3
4
5
6
7
20% 40% 60% 80% 100%
Speedup
Cache Size (100% = complete cache)
Speedup results (outer-item ordering)
LRU SMART
Figure 6: Speedup results for the LRU and SMART caching
approaches (for different cache sizes) with a reversed user-
item pair handling execution ordering.
As expected, the performance of the LRU cache is
greatly reduced and for every cache size the SMART
cache shows faster speedup values. Although the
SMART cache is faster than the LRU method, it is
still somewhat slower than the speedup values of the
SMART cache in the outer-user ordering situation.
In general the speedup values are below those of the
outer-user ordering, but the SMART cache seems less
CachingStrategiesforIn-memoryNeighborhood-basedRecommenderSystems
439

affected (than LRU) by the change in ordering. The
LRU cache shows no indication of saturation as was
the case for the outer-user situation.
We repeated the experiment with a third alternate
job ordering situation where all user-item pairs were
processed in random order. The aggregated results of
multiple runs turned out to be almost identical to the
outer-item results.
6 CONCLUSIONS
In this work we set out to find caching strategies
that allow in-memory user-based collaborative filter-
ing algorithms to store intermediate user-user simi-
larity results. First, we showed that user similarities
are not equally important, as some are used consid-
erably more than others during the recommendation
calculation process. We tried predicting this usage
frequency upfront by applying aggregation operators
on the number of ratings, but ultimately succeeded in
accurately calculating this value by determining the
cardinality of the ‘inverse intersection’ of the set of
rated items.
We then presented two caching strategies: a basic
LRU (least recently used) cache and a novel SMART
caching approach which acted like a priority cache
that incorporated the knowledge about usage fre-
quency of user-user similarities. A number of experi-
ments were run on the MovieLens dataset to compare
the performance (execution time speedup) of each of
these caches against a no-cache baseline and under
varying cache sizes and job execution orderings.
Our results showed that the order in which user-
item recommendation values are calculated can dra-
matically impact the LRU cache performance and
therefore also the total execution time. Optimal re-
sults were obtained when calculating the recommen-
dation values of each user for every item sequen-
tially before moving on to the next user (outer-user
strategy). The LRU-enhanced UBCF algorithm per-
formed between 5 and 6 times better in that situation
than the no-cache baseline and required a cache size
of only 0.2% (vs. the SMART approach which re-
quired a cache size of 60% to obtain similar results).
For a random job (and outer-item) execution ordering
on the other hand, the SMART approach came out
best in terms of stability and performance.
Although this work focussed mainly on in-
memory algorithms, these results may as well be
useful for other situations where caching strategies
can be applied to user-based collaborative filtering
algorithms (e.g., caching similarity values to reduce
database access).
7 FUTURE WORK
As future work we would like to investigate the gener-
alizability of the obtained results to other datasets and
recommendation algorithms. We also intend to im-
prove results in terms of speedup by further refining
the job execution ordering and involving other cache
algorithms like LFU and ARC.
ACKNOWLEDGEMENTS
The described research activities were funded by a
PhD grant to Simon Dooms of the Agency for Innova-
tion by Science and Technology (IWT Vlaanderen).
REFERENCES
Herlocker, J., Konstan, J. A., and Riedl, J. (2002). An em-
pirical analysis of design choices in neighborhood-
based collaborative filtering algorithms. Inf. Retr.,
5(4):287–310.
Jannach, D., Zanker, M., Felfernig, A., and Friedrich, G.
(2011). Recommender Systems An Introduction. Cam-
bridge University Press.
Park, S.-T., Pennock, D., Madani, O., Good, N., and De-
Coste, D. (2006). Na
¨
ıve filterbots for robust cold-start
recommendations. In Proc. ACM SIGKDD Conf. on
Knowledge discovery and data mining (KDD 2006),
pages 699–705, New York, NY, USA.
Peralta, V. (2007). Extraction and integration of movielens
and imdb data. Technical report, Technical Report,
Laboratoire PRiSM, Universit
´
e de Versailles, France.
Qasim, U. (2011). Active Caching For Recommender Sys-
tems. PhD thesis, New Jersey Institute of Technology,
New Jersey.
Qasim, U., Oria, V., fang Brook Wu, Y., Houle, M. E., and
¨
Ozsu, M. T. (2009). A partial-order based active cache
for recommender systems. In Proc. ACM Conf. Rec-
ommender systems (RecSys 2009), pages 209–212.
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P.,
and Riedl, J. (1994). Grouplens: an open archi-
tecture for collaborative filtering of netnews. In
Proc. ACMF Conf. on Computer supported cooper-
ative work (CSCW ‘94), pages 175–186, New York,
NY, USA. ACM.
Seth, S. and Kaiser, G. (2011). Towards using cached
data mining for large scale recommender systems. In
Proc. Conf. Data Engineering and Internet Technol-
ogy (DEIT 2011).
WEBIST2013-9thInternationalConferenceonWebInformationSystemsandTechnologies
440
