
Dependability Testing of MapReduce Systems
Jo
˜
ao Eugenio Marynowski
1
, Andrey Ricardo Pimentel
1
, Taisy Silva Weber
2
and Antonio Junior Mattos
1
Department of Informatics, Federal University of Paran
´
a, UFPR, Curitiba, Brazil
2
Department of Informatics, Federal University of Rio Grande do Sul, UFRGS, Porto Alegre, Brazil
Keywords:
MapReduce, Hadoop, Dependability, Test, Fault Injection, Fault Tolerance.
Abstract:
MapReduce systems have been widely used by several applications, from search engines to financial and com-
mercial systems. There is considerable enthusiasm around MapReduce systems due to their simplicity and
scalability. However, they lack a testing approach and framework ensuring their dependability. In this work,
we propose a complete dependability testing solution for MapReduce systems. This solution is a model-based
approach to generate representative fault cases, and a testing framework to automate their execution. More-
over, we introduce a new way to model distributed components using Petri Nets, and we show the promising
results of the proposed testing framework, HadoopTest, on identifying faulty systems in real deployment sce-
narios.
1 INTRODUCTION
The amount of data stored by various applications,
such as social networks, commercial applications, and
research, have grown to over petabytes. There are
many frameworks to facilitate the analysis of large
data sets; MapReduce is one of them, with broad
adoption. It abstracts parallel and distributed issues
such as data partition, replication, distributed process-
ing, and fault tolerance (Dean and Ghemawat, 2004).
Despite a considerable number of MapReduce ap-
plications may present partial results, such as large-
scale web indexing and pattern-based searching, sev-
eral applications must present full results, such as ap-
plications in domains of business, financial, and re-
search. To make use of MapReduce in such domains,
it is essential to test its dependability (Abouzeid et al.,
2009; Teradata Coorporation, 2012; Hadoop, 2012).
Dependability test aims at validating the behavior
of fault tolerant systems, i.e., it aims at finding errors
in the implementation or specification of fault tolerant
mechanisms (Avizienis et al., 2004; Ammann and Of-
futt, 2008). For this purpose, the system is executed
on a controlled testing environment with the injec-
tion of artificial faults. Two main issues concerning
this approach are: generating representative elements
from the potentially infinite and partially unknown set
of fault cases, and automating their executions.
Testing the dependability of MapReduce systems
requires to execute fault cases capable of stimulating
all of its tolerated faults, which, by turn requires ex-
plicit control over its processing steps.
In this work, we present a solution for dependabil-
ity testing of MapReduce systems through the gener-
ation and execution of representative fault cases. We
use a Petri Net model of the fault tolerance mecha-
nism to generate these fault cases, and a framework
to automate their execution in real deployment scenar-
ios. Additionally, we introduce a new approach to in-
terpret the model components, modeling the MapRe-
duce components as dynamic items, and modeling the
independence of these components with their actions
and states.
This paper is organized as follows. The next
session introduces the basic concepts, presenting a
description of MapReduce and defining fault cases.
Section 3 presents our approach to model MapRe-
duce fault tolerance mechanism. Section 4 shows
how we generate the representative fault cases. Sec-
tion 5 presents our framework for dependability test-
ing. Section 6 describes the initial results through im-
plementation and experimentation. Section 7 surveys
related work. Section 8 concludes the paper.
165
Marynowski J., Pimentel A., Weber T. and Mattos A..
Dependability Testing of MapReduce Systems.
DOI: 10.5220/0004436101650172
In Proceedings of the 15th International Conference on Enterprise Information Systems (ICEIS-2013), pages 165-172
ISBN: 978-989-8565-60-0
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2 BASIC CONCEPTS
2.1 MapReduce
MapReduce is a simplified programming model and
the associated implementation for processing and an-
alyzing large scale data. It offers a programming envi-
ronment based on two high-level functions, map and
reduce, and a runtime environment to execute them on
a cluster. The MapReduce architecture includes sev-
eral worker components, and one master that sched-
ules map and reduce tasks to run at the workers.
Figure 1 shows a MapReduce execution in-
stance. The master receives a Job and co-
ordinates five worker components, identified by
{worker0, . .. , worker4}. It assigns the map function
to {worker0, worker1, worker2, worker3}, and each
one reads the input data from the files splitted in a Dis-
tributed File System (DFS), applies the user-defined
map function on each split, and creates several out-
puts locally. The master assigns the reduce function
to {worker4, worker1, worker0}, and each one reads
the map outputs locally or remotely, applies user-
defined reduce function, and writes the results to the
DFS.
Figure 1: A MapReduce execution overview.
The MapReduce fault tolerance mechanism iden-
tifies faulty workers by timeout, and reschedules their
tasks to a healthy worker. The fault handling differs
between tasks and their processing steps, e.g., if a
worker fails when it is executing a map task, the mas-
ter only reschedules its task for another worker; but
if a component fails after executing a map task, the
master reschedules the task for another worker and
informs all workers executing reduce tasks that they
must read the map result from the new worker.
2.2 Fault Case
A fault case is a distributed test case extension involv-
ing the components required for a complete execu-
tion and validation of a system under test while faults
are injected (Echtle and Leu, 1994; Ambrosio et al.,
2005; de Almeida et al., 2010b).
Definition 2.1 (Fault Case). A fault case is a 4-tuple
F = (C
F
, A
F
, R
F
, O) where:
• C
F
= {c
0
, c
1
, . . . , c
n
}, and it is a finite set of sys-
tem components;
• A
F
= {a
0
, a
1
, . . . , a
m
}, and it is a finite set of ac-
tions that can involve fault injections;
• R
F
= {r
a
0
, . . . , r
a
m
}, and it is a finite set of action
results;
• O is an oracle.
The oracle is a mechanism responsible for verify-
ing the system behavior during a fault case execution,
and associating its result, i.e., a verdict pass, fail or
inconclusive. Each action (a
i
) can get its result (r
a
i
):
success, failure, or timeout (without response during
a time limit). If all action results (R
F
) get success, the
F verdict is pass. If any action result is failure, the
F verdict is fail. But if at least one action execution
gets timeout, the F verdict is inconclusive, making
the test inaccurate for assigning some of the earlier
statements and, moreover, it is necessary to rerun the
fault case.
Definition 2.2 (Action). A fault case action is a 7-
tuple a
i
= (h, n,C
0
, I,W, D,t) where:
• h ∈ N|h 6 |A
F
|, and it is an hierarchical order in
which action a
i
must execute - actions with same
h execute in parallel;
• n ∈ N|n 6 |C
0
|, and it is the success number of
action executions to result success for a
i
;
• C
0
⊆ C
F
, and it is a set of components that execute
a
i
;
• I is a set of instructions or commands executed by
the components;
• W is an optional instruction or command that is a
trigger required to execute a
i
;
• D ⊆ A
F
|∀a
j
∈ D : j < i, r
a
j
= SUCCESS, and it is
a set of actions that must be successfully executed
before a
i
, otherwise the action result r
a
i
is failure;
• t is a time to execute a
i
.
3 MODELING MapReduce FAULT
TOLERANCE MECHANISM
Modeling the MapReduce fault tolerance mechanism
demands a formal model of the concurrent and dis-
tributed behavior of its components. The model must
represent the components as dynamic items, enabling
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
166

them to be easily removed or inserted, without sub-
stantial model changes. Moreover, the model should
represent the components without specifying their ac-
tions, allowing an action to be performed by any en-
abled component. This feature is essential to model
the rescheduling process of faulty map and reduce
tasks.
Finite State Machine (FSM) (Bernardi et al.,
2012) and Petri Net (PN) (Callou et al., 2012) are
the main approaches to model distributed systems in-
volving their dependability properties. FSM abstracts
the details of the system behavior and enables to a di-
rect relation to the MapReduce processing steps. Al-
though there are extensions to represent other features
(e.g., timing specs), FSM restricts the modeling of
several components that have parallel and distinct be-
haviors. Each component needs a specific set of states
and an alphabet to model its behavior.
The PN modeling enables us to take a new ap-
proach to interpret their components, modeling the
MapReduce components as dynamic items, to be eas-
ily inserted or removed. Moreover, it allows to model
the independence of these components with their ac-
tions and states, i.e., an action can be executed by any
enabled component.
Figure 2 shows a Petri Net that models
part of the MapReduce fault tolerance mecha-
nism that handles faults while running Map and
Reduce functions. Labeled transitions represent
the fault case actions, tokens represent MapRe-
duce components, and places represent their states
or processing steps. When the transition “mas-
ter.sendJOB” fires, it consumes one token from
“online master” and one from “online workers”,
and produces a new one in “worker.runningMap”.
Now, two transitions can fire, “nothing” and
“worker.runningMap-FAIL”. If “nothing” fires, it
consumes one token from “worker.runningMap”,
and produces one in “worker.runningReduce”. If
“worker.runningMap-FAIL” transition fires, it con-
sumes one token from “worker.runningMap” and one
from “online workers”, and produces one again in
“worker.runningMap”. This behavior occurs simi-
larly if “worker.runningReduce-FAIL” fires when it
has a token at “worker.runningReduce”, but it is nec-
essary to have a token at “online workers” for firing
it.
PN allows a comprehensively modeling of the
MapReduce fault tolerance mechanism. Moreover, it
allows extensions to model other behaviors implicitly
specified in MapReduce fault tolerance mechanism,
such as the temporal faults identification and the pro-
cess interruption when it is impossible complete a job.
Figure 2: A Petri Net modeling example.
4 GENERATING
REPRESENTATIVE FAULT
CASES
The representativeness of a fault case is how impor-
tant it is to identify defects on a system under test (Ar-
lat et al., 2003; Natella et al., 2012). We consider the
representative fault cases for the dependability test-
ing of MapReduce systems as generated through an
abstraction of its fault tolerance mechanism. This ap-
proach is successfully used to test other systems (Ech-
tle and Leu, 1994; Ambrosio et al., 2005; Bernardi
et al., 2012). It guides the generation to a finite set of
fault cases that should be tolerated, and that they must
be tested to ensure the system dependability.
We generate representative fault cases from a
reachability graph of the Petri Net that models the
MapReduce fault tolerance mechanism. A reachabil-
ity graph consists of all possible sequences of tran-
sition firings from a Petri Net. Each possible path
starting from the root graph vertex composes one fault
case. This approach is applicable only in a Pure Petri
Net, i.e., that has no loops.
Figure 3 shows a reachability graph generated
from the Petri Net example at Figure 2. There are
three fault case possible: (1) without faults, execut-
ing “master.sendJOB” and “master.assertRESULT”;
(2) with one fault, adding “worker.runningMap-
FAIL”; and (3) with the other possible fault,
“worker.runningReduce-FAIL”.
Table 1 shows a set of fault case actions of the fault
case (2). The goal is to validate the MapReduce ex-
ecution while one component fails when executing a
map task. This fault case involves three components,
C
F
= {c
0
, c
1
, c
2
}, obtained from the Petri Net tokens,
and seven actions A
F
= {a
0
, . . . , a
6
}, obtained from
the reachability graph (Figure 3) and the start and stop
DependabilityTestingofMapReduceSystems
167
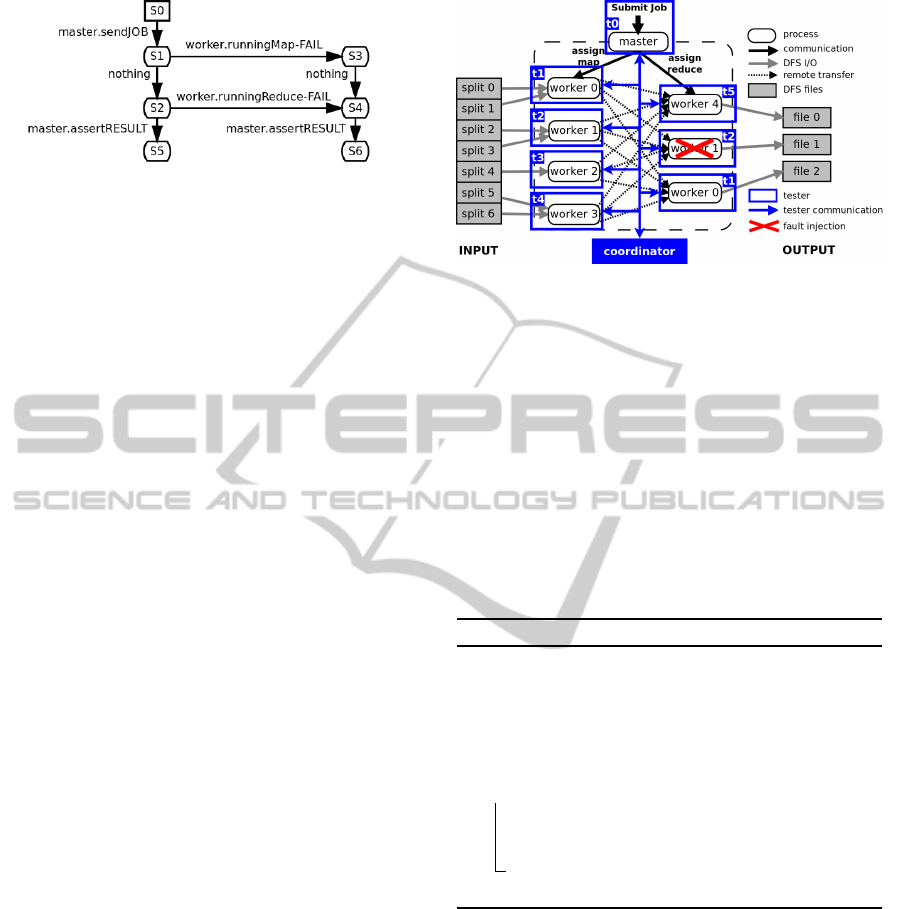
Figure 3: A reachability graph example.
actions. The component c
0
executes the action a
0
to
start the master. If action a
0
succeeds, the compo-
nents {c
1
, c
2
} execute the action a
1
to start the work-
ers. Otherwise, the action a
1
finishes and receives
the failure result. This occurs with all actions that
has a dependency relation with a failed action, recur-
sively. Without failed actions, the process continues
and the next execution is a
2
by the component c
0
, and
it submits a job. During the job execution, only the
first component (n
a
3
= 1) of {c
1
, c
2
} fails when it ex-
ecutes the map task (W
a
3
= runningMap()). At action
a
4
, the c
0
validates the job result, comparing the ex-
pected with the obtained. The next actions stop the
MapReduce execution.
5 FRAMEWORK FOR TESTING
MAPREDUCE SYSTEMS
HadoopTest is a test framework to automatically exe-
cute fault cases. It extends the PeerUnit testing frame-
work (de Almeida et al., 2010a). HadoopTest adds the
controlling and monitoring of all MapReduce compo-
nents, the injecting of faults according to its process-
ing steps, and the validation of its behavior.
The HadoopTest architecture consists of one co-
ordinator and several testers. The coordinator con-
trols the execution of distributed testers, coordinates
the actions of fault cases, and generates the verdict
from tester results. Each tester receives coordination
messages, executes fault case actions in the MapRe-
duce components, and returns their results.
Figure 4 shows the application of HadoopTest to
the MapReduce instance presented in Figure 1, and
with a fault injection while a worker executes a Re-
duce function. The coordinator individually controls
the execution of six testers, identified by t0..t5, fol-
lowing the fault case. Tester t0 controls the mas-
ter component and each other tester, t1..t5, controls
a worker instance. This architecture enables the de-
ployment of fault cases applying lower service func-
tions on testers. For instance, tester t2 injects a fault
on worker1, removing it from the system while it exe-
cutes the reduce function. This enables to put MapRe-
Figure 4: Testing a MapReduce instance with fault injec-
tion.
duce components in any state (i.e., running, idle, or
stopped) and monitors their activity at any time.
The fault case execution consists of coordinating
and controlling testers to execute actions in a dis-
tributed, parallel and synchronized way. Algorithm 1
shows the main steps to coordinate testers for execut-
ing a fault case F . For each hierarchical level h, exist-
ing in A, the coordinator sends messages to the testers
for executing actions in parallel, receives the local re-
sults, and processes them to set action results, R. Af-
ter executing all actions, the oracle O analyzes R and
assigns the fault case verdict.
Algorithm 1: Coordination Algorithm.
Input: F , a fault case; M , a map function
between A
F
and the hierarchical orders
of its actions
Data: R
t
, a set of local tester results
Output: A verdict
foreach h ∈ M (A
F
) do
SendMessages(M
−1
(h), R
F
)
R
t
←ReceiveResults(M
−1
(h))
R
F
←ProcessResults(R
t
, M
−1
(h))
return O(R
F
) ;
Algorithm 2 shows the steps to execute a fault case
action by a tester. It receives the coordination mes-
sage to execute a
i
. If the trigger W
a
i
is defined, it waits
his execution. After that, or if W
a
i
is not defined, the
tester verifies if the number of success action execu-
tions n
a
i
is greater than zero, then it executes the set of
instructions I
a
i
and returns the execution result. Oth-
erwise, it returns failure, informing to the coordinator
that it cannot execute a
i
.
6 EXPERIMENTAL VALIDATION
This section presents an evaluation of our proposed
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
168

Table 1: A set of fault case actions.
h n C
0
I W D t
a
0
1 1 {c
0
} startMaster()
/
0 100
a
1
2 2 {c
1
, c
2
} startWorker() {a
0
} 1000
a
2
3 1 {c
0
} sendJOB() {a
1
} 1000000
a
3
3 1 {c
1
, c
2
} FAIL() runningMap() {a
1
} 1000
a
4
4 1 {c
0
} assertRESULT () {a
2
} 10000
a
5
5 1 {c
1
, c
2
} stopWorker() {a
1
} 1000
a
6
6 1 {c
0
} stopMaster() {a
0
} 1000
Algorithm 2: Action Execution Algorithm.
Data: a
i
, a fault case action
Output: An action result
a
i
← ReceiveAction()
if W
a
i
6= NULL then
Wait W
a
i
if n
a
i
> 0 then
return Run I
a
i
return FAILURE
solution through the automatic and manual executions
of fault cases for testing Hadoop (Hadoop, 2012), an
open-source MapReduce implementation. First, we
present the results obtained by the manual execution
of the representative fault cases. Second, we evaluate
the overhead produced by HadoopTest to coordinate
the execution of fault cases. Finally, we validate the
HadoopTest effectiveness for identifying faulty sys-
tems by testing the PiEstimator, an application bun-
dled into Hadoop.
6.1 Manual Execution of Representative
Fault Cases
We manually executed some fault cases generated
from the modeling of the MapReduce fault tolerance
mechanism to confirm their representativeness in the
defect identification. One fault case consisted of four
components that execute the WordCount, while two
components failed by crash when they executed the
map task. Hadoop interrupted the execution when the
second component failed, although the data remained
in the other active component. The correct behavior
would be to schedule the tasks to the active compo-
nent, but Hadoop did not do it due to a corruption of
a control file.
In addition, we executed fault cases involving
temporal parameters. We identified that Hadoop does
not consider timeout parameters to detect fault com-
ponents, and does not interrupt the execution when
the data were no longer available, i.e., all components
that stored data failed, but Hadoop continued without
iteration by two hours.
6.2 The HadoopTest Overhead
We evaluated the HadoopTest overhead by executing
PiEstimator in two ways. In the first one, Hadoop is
executed alone, to evaluate the raw execution time.
In the second one, Hadoop is executed along with
HadoopTest, to evaluate the overhead produced dur-
ing testing. We use 10, 50, 100 and 200 machine-
nodes on the Grid’5000 plataform to realize this ex-
periment. Figure 5 shows the average execution time
of PiEstimator running on Hadoop and HadoopTest.
We vary the number of map instances in each execu-
tion.
20
30
40
50
60
70
80
90
100
110
120
130
200 400 600 800 1000 1200 1400 1600 1800 2000
time (sec)
maps
hadoop
hadooptest
Figure 5: Execution time variance of the PiEstimator.
HadoopTest presents a minimal overhead by con-
trolling Hadoop while executing fault cases. This
characteristic enables testing MapReduce systems
considering large-scale failure scenarios.
6.3 Identifying Faulty Systems
We used Mutation Testing (Offutt, 1994) to evaluate
whether HadoopTest is able to identify faulty systems.
We create a set of faulty versions (i.e., mutants) of
the PiEstimator. Mutations are changes of arithmetic
and logic operators into the original source code to
generate incorrect results. The goal is to identify the
largest possible number of incorrect results.
We generated 13 mutants of the PiEstimator class
DependabilityTestingofMapReduceSystems
169
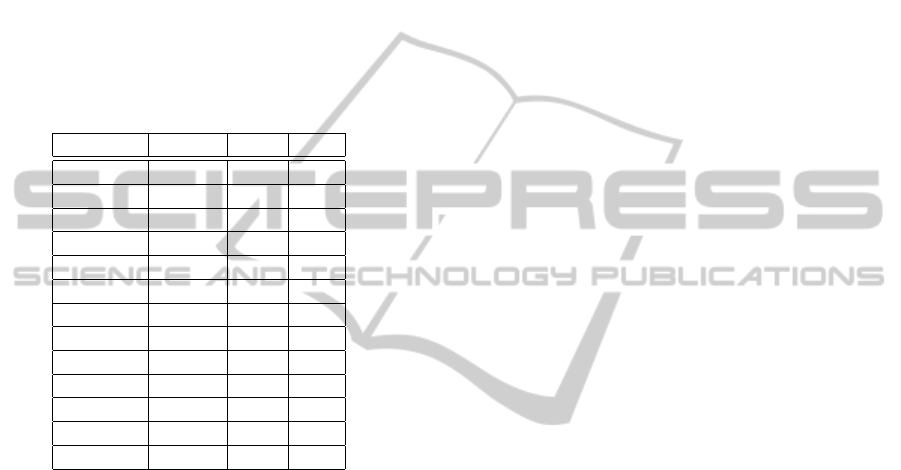
and Table 2 shows the results. The expected π value
returned by the original application was 3.1416 and
only the mutants M1, M6, M7, M9 and M12 returned
this value. These mutants have the pass verdict on
the test case execution while the other mutants M4,
M5, M10 and M11 received a fail verdict, since the π
computation parameters were modified resulting in a
different value than the expected one. In the case of
the mutants M0, M2, M3 and M8, the modifications
were in the execution parameters which interfered on
their correct execution. Hence, they returned NULL
as results.
Table 2: Results and verdicts generated by 13 PiEstimator
mutants.
Mutants Result Pass Fail
M0 NULL X
M1 3.1416 X
M2 NULL X
M3 NULL X
M4 3.0776 X
M5 3.1312 X
M6 3.1416 X
M7 3.1416 X
M8 NULL X
M9 3.1416 X
M10 3.1408 X
M11 3.1408 X
M12 3.1416 X
We evaluated the HadoopTest effectiveness by the
number of detected mutants. When mutation analy-
sis is applied to a system code and generates several
mutants, some of them are equivalent to the origi-
nal source code, due to different reasons, such as the
modified part is never executed, and the binary oper-
ators used have the same result. We considered the
equivalent mutants those that obtained the same out-
put as the original system. The initial implementa-
tion of HadoopTest demonstrated promising results
by identifying all the non-equivalent mutants of PiEs-
timator.
7 RELATED WORK
The fault case generation is commonly done ran-
domly or by the Test Engineer (Benso et al., 2007;
Chandra et al., 2007; Henry, 2009; Bernardi et al.,
2012; Jacques-Silva et al., 2006; Lefever et al., 2004).
These approaches are inadequate for the dependabil-
ity testing of MapReduce systems because they dis-
regard the internals of the fault tolerance mechanism,
i.e., they ignore the behavior of fault recovery pro-
tocols regarding the different processing steps, e.g.,
they inject faults in some machines (fails 3 of 10) for
some period (from 30 to 40 sec). They can evaluate
the system behavior, but they cannot test system de-
pendability. Others evaluate the dependability by gen-
erating, systematically, fault cases from source code.
Such approaches are costly, even after applying prun-
ing techniques, and they limit the fault case genera-
tion to few concurrent cases (Joshi et al., 2011; Fu
et al., 2004; Marinescu et al., 2010).
Some testing frameworks provide solutions to
control distributed components and to validate the
system behavior, but they do not inject faults nei-
ther consider the components processing steps (Pan
et al., 2010; Dragan et al., 2006; Zhou et al., 2006;
de Almeida et al., 2010a). Related fault injection
frameworks enable to inject multiple and various
faults, but they do not control the system dynami-
cally to inject faults according the processing steps
(Jacques-Silva et al., 2006; Pham et al., 2011; Stott
et al., 2000; Lefever et al., 2004; Hoarau et al., 2007).
Moreover, none of the cited frameworks presents re-
sults about MapReduce dependability.
MapReduce related testing frameworks are not ap-
plicable to the dependability testing. Herriot (Boud-
nik et al., 2010) provides a set of interfaces that val-
idates small system parts, e.g., a method or a func-
tion. Csallner et al. (Csallner et al., 2011) system-
atically search the bad-defined map and reduce func-
tions, possibly identified by component faults. Oth-
ers, evaluate MapReduce execution by log analysis to
detect MapReduce performance problems (Tan et al.,
2008; Pan et al., 2009; Tan et al., 2009; Huang et al.,
2010). Although, these approaches evaluate MapRe-
duce functionality and performance, they do not auto-
matically execute fault cases and validate the system
dependability.
8 CONCLUSIONS
We exposed and analyzed the issue of testing MapRe-
duce system dependability. We presented a solution
based on the generation and execution of represen-
tative fault cases. We generated fault cases from
a formal model of the MapReduce fault tolerance
mechanism. We evaluated two modeling approaches
and adopted the Petri Net because its adequacy. We
presented a new way to model distributed compo-
nents using Petri Nets. We modeled the MapRe-
duce components as dynamic items and the indepen-
dence of them with their actions and states. Moreover,
we showed the HadoopTest framework, that executes
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
170

fault cases in real deployment scenarios without over-
head and identifying faulty systems.
We identified some bugs in Hadoop with the man-
ual execution of representative fault cases, but we in-
tend to automatically execute them with HadoopTest.
We plan to automatically generate representative fault
cases from a Petri Net model, and test other MapRe-
duce systems, such as HadoopDB and Hive.
ACKNOWLEDGEMENTS
This work is partially sponsored by CAPES and the
experiments presented were carried out using the
Grid’5000 experimental testbed.
REFERENCES
Abouzeid, A., Bajda-Pawlikowski, K., Abadi, D., Silber-
schatz, A., and Rasin, A. (2009). HadoopDB: An
architectural hybrid of MapReduce and DBMS tech-
nologies for analytical workloads. In VLDB - Inter-
national Conference on Very Large Data Bases, pages
922–933. VLDB Endowment.
Ambrosio, A. M., Mattiello-Francisco, F., Vijaykumar,
N. L., de Carvalho, S. V., Santiago, V., and Martins, E.
(2005). A methodology for designing fault injection
experiments as an addition to communication systems
conformance testing. In DSN-W - International Con-
ference on Dependable Systems and Networks Work-
shops, Yokohama, Japan.
Ammann, P. and Offutt, J. (2008). Introduction to Software
Testing. Cambridge University Press.
Arlat, J., Crouzet, Y., Karlsson, J., Folkesson, P., Fuchs, E.,
and Leber, G. (2003). Comparison of Physical and
Software-Implemented Fault Injection Techniques.
IEEE Transactions on Computers, 52(9):1115–1133.
Avizienis, A., Laprie, J.-C., Randell, B., and Landwehr,
C. E. (2004). Basic Concepts and Taxonomy of De-
pendable and Secure Computing. IEEE Transactions
on Dependable and Secure Computing, 1(1):11–33.
Benso, A., Bosio, A., Carlo, S. D., and Mariani, R. (2007).
A Functional Verification based Fault Injection Envi-
ronment. In DFT - International Symposium on Defect
and Fault-Tolerance in VLSI Systems, pages 114–122.
IEEE.
Bernardi, S., Merseguer, J., and Petriu, D. C. (2012). De-
pendability Modeling and Assessment in UML-Based
Software Development. The Scientific World Journal,
2012:1–11.
Boudnik, K., Rajagopalan, B., and Murthy, A. C.
(2010). Herriot. https://issues.apache.org/jira/browse/
HADOOP-6332.
Callou, G., Maciel, P., Tutsch, D., and Ara
´
ujo, J. (2012).
A Petri Net-Based Approach to the Quantification of
Data Center Dependability. In Pawlewski, P., editor,
Petri Nets - Manufacturing and Computer Science,
page 492. InTech.
Chandra, T. D., Griesemer, R., and Redstone, J. (2007).
Paxos Made Live: An Engineering Perspective. In
PODC - Symposium on Principles of Distributed
Computing, pages 398–407, New York, New York,
USA. ACM Press.
Csallner, C., Fegaras, L., and Li, C. (2011). New
Ideas Track: Testing MapReduce-Style Programs. In
ESEC/FSE’11, Szeged, Hungary.
de Almeida, E. C., Marynowski, J. E., Suny
´
e, G., and Val-
duriez, P. (2010a). PeerUnit: a framework for testing
peer-to-peer systems. In ASE - International Confer-
ence on Automated Software Engineering, pages 169–
170, New York, USA. ACM.
de Almeida, E. C., Suny
´
e, G., Traon, Y. L., and Valduriez,
P. (2010b). Testing peer-to-peer systems. ESE - Em-
pirical Software Engineering, 15(4):346–379.
Dean, J. and Ghemawat, S. (2004). MapReduce: Sim-
plified Data Processing on Large Clusters. In OSDI
- USENIX Symposium on Operating Systems Design
and Implementation, pages 137–149, San Francisco,
California. ACM Press.
Dragan, F., Butnaru, B., Manolescu, I., Gardarin, G.,
Preda, N., Nguyen, B., Pop, R., and Yeh, L. (2006).
P2PTester: a tool for measuring P2P platform perfor-
mance. In BDA conference.
Echtle, K. and Leu, M. (1994). Test of fault tolerant dis-
tributed systems by fault injection. In FTPDS - Work-
shop on Fault-Tolerant Parallel and Distributed Sys-
tems, pages 244–251. IEEE.
Fu, C., Ryder, B. G., Milanova, A., and Wonnacott, D.
(2004). Testing of java web services for robustness.
In ISSTA - International Symposium on Software Test-
ing and Analysis, pages 23–33.
Hadoop (2012). The Apache Hadoop. http://hadoop.
apache.org/.
Henry, A. (2009). Cloud Storage FUD: Failure, Uncertainty
and Durability. In FAST - USENIX Symposium on File
and Storage Technologies, San Francisco, California.
Hoarau, W., Tixeuil, S., and Vauchelles, F. (2007). FAIL-
FCI: Versatile fault injection. Future Generation
Computer Systems, 23(7):913–919.
Huang, S., Huang, J., Dai, J., Xie, T., and Huang, B. (2010).
The HiBench benchmark suite: Characterization of
the MapReduce-based data analysis. In ICDEW - In-
ternational Conference on Data Engineering Work-
shops, pages 41–51. IEEE.
Jacques-Silva, G., Drebes, R., Gerchman, J., F. Trindade, J.,
Weber, T., and Jansch-Porto, I. (2006). A Network-
Level Distributed Fault Injector for Experimental
Validation of Dependable Distributed Systems. In
COMPSAC - International Computer Software and
Applications Conference, pages 421–428. IEEE.
Joshi, P., Gunawi, H. S., and Kou (2011). PREFAIL: A
Programmable Tool for Multiple-Failure Injection. In
OOPSLA - Conference on Object-Oriented Program-
ming, Portland, Oregon, USA.
Lefever, R., Joshi, K., Cukier, M., and Sanders, W. (2004).
A global-state-triggered fault injector for distributed
system evaluation. IEEE Transactions on Parallel and
Distributed Systems, 15(7):593–605.
DependabilityTestingofMapReduceSystems
171

Marinescu, P. D., Banabic, R., and Candea, G. (2010).
An extensible technique for high-precision testing
of recovery code. In USENIXATC - Conference
on USENIX Annual Technical Conference, page 23.
USENIX.
Natella, R., Cotroneo, D., Duraes, J. A., and Madeira, H. S.
(2012). On Fault Representativeness of Software Fault
Injection. TSE - IEEE Transactions on Software En-
gineering.
Offutt, A. J. (1994). A Practical System for Mutation Test-
ing: Help for the Common Programmer. In ITC - In-
ternational Test Conference, pages 824–830. IEEE.
Pan, X., Tan, J., Kalvulya, S., Gandhi, R., and Narasimhan,
P. (2009). Blind Men and the Elephant: Piecing To-
gether Hadoop for Diagnosis. In ISSRE - International
Symposium on Software Reliability Engineering.
Pan, X., Tan, J., Kavulya, S., Gandhi, R., and Narasimhan,
P. (2010). Ganesha: blackBox diagnosis of MapRe-
duce systems. In SIGMETRICS Performance Evalua-
tion Review, page 8. ACM Press.
Pham, C., Chen, D., Kalbarczyk, Z., and Iyer, R. K. (2011).
CloudVal: A framework for validation of virtualiza-
tion environment in cloud infrastructure. In DSN -
International Conference on Dependable Systems and
Networks, pages 189–196. IEEE.
Stott, D., Floering, B., Burke, D., Kalbarczpk, Z., and
Iyer, R. (2000). NFTAPE: a framework for assessing
dependability in distributed systems with lightweight
fault injectors. In IPDS - International Computer Per-
formance and Dependability Symposium, pages 91–
100. IEEE Comput. Soc.
Tan, J., Pan, X., Kavulya, S., Gandhi, R., and Narasimhan,
P. (2008). SALSA: analyzing logs as state machines.
In WASL - Conference on Analysis of System Logs,
page 6, CA, USA. USENIX.
Tan, J., Pan, X., Kavulya, S., Gandhi, R., and Narasimhan,
P. (2009). Mochi: visual log-analysis based tools for
debugging hadoop. In Proceedings of the 2009 confer-
ence on Hot topics in cloud computing, pages 18–18.
USENIX Association.
Teradata Coorporation (2012). MapReduce, SQL-
MapReduce Resources and Hadoop Integration –
Aster Data. http://www.asterdata.com/resources/
mapreduce.php, 09/02/12.
Zhou, Z., Wang, H., Zhou, J., Tang, L., and Li., K. (2006).
Pigeon: A Framework for Testing Peer-to-Peer Mas-
sively Multiplayer Online Games over Heterogeneous
Network. In CCNC - Consumer Communications and
Networking Conference. IEEE.
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
172
