
A Software Quality Predictive Model
Elisabetta Ronchieri and Marco Canaparo
INFN CNAF, Viale Berti Pichat 6/2, Bologna, Italy
Keywords:
Quality, Model, Software Construction.
Abstract:
Software development is facing the problem of how to improve the quality of software products. The lack
of quality can easily lead to major costs and delays in the development and maintenance of the software. Its
improvement can be guaranteed by both the definition of a software quality model and the presence of metrics
that are designed and measured to plan and monitor productivity, effectiveness, quality and timing of software.
Integrating the metrics into the model contributes to collecting the right data for the handling of the analysis
process and to establishing a general view to the control of the overall state of the process. This paper aims at
introducing a mathematical model that links software best practices with a set of metrics to predict the quality
of software at any stage of development. Two software projects have been used to analyze the defined model
as a suitable predictive methodology in order to evaluate its results. The model can improve the level of the
software development process significantly and contribute to achieving a product of the highest standards. A
replication of this work on larger data sets is planned.
1 INTRODUCTION
The software development life cycle is often very ex-
pensive because of the growing overall complexity
and the average size of software products. Over the
past decades software engineering researchers have
put a lot of effort into software quality, being con-
sidered as important as the delivery of the product
within scheduled budget and time. Quality, in fact,
represents the degree of excellence that is measurable
in a given product (IEEE90, 1990). Quality require-
ments are increasingly becoming determining factors
in selecting between design alternatives during soft-
ware development. In order to appraise the quality
of any software project, quality estimation models are
necessary, which help the development team to track
and detect potential software defects during develop-
ment process and to save effort that is later required
for the maintenance of the product (Khoshgoftaar and
Seliya, 2003). Furthermore, the presence of metrics is
recommended in order to plan and monitor productiv-
ity, effectiveness, quality and timing of software. The
continuous application of measurement-based tech-
niques to the software development process supplies
meaningful information to improve products and pro-
cess (DeMarco, 1982). Integrating the metrics into
the model contributes to the assessment and the pre-
diction of software quality. In addition to that, met-
rics are input to control and management of general
planning activities. In this paper, we propose a gen-
eral approach and a particular solution to the prob-
lem of improving the software quality. The main idea
is to connect software best practices with a set of
metrics into a mathematical model in such way that
the quality of software at any stage of development
is well predicted. Best practices (Khoshgoftaar and
Seliya, 2003) in this context refers to the software
structure, the construction of the code (McConnell,
1996), deployment, testing, and configuration man-
agement (Wingerd and Seiwald, 1998) in order to ob-
tain a maximum of maintainability, in terms of adapt-
ability, portability and transferability, during the on-
going product life cycle. As concerns metrics (Cole-
man et al., 1994), they derive from both best practices
and static analysis. The following categories have
been taken into consideration: file and code conven-
tions, software portability and static analysis. As this
paper focused on the early phases of the software de-
velopment life cycle, only static metrics havebeen an-
alyzed (Chhabra and Gupta, 2010), leaving dynamic
ones (such as feasibility and NPATH evaluation) for
future work since they concern the late stage (Deb-
barma et al., 2012) and are based on the data collected
during an actual execution of the system (Chhabra and
Gupta, 2010). Two software projects that we build
186
Ronchieri E. and Canaparo M..
A Software Quality Predictive Model.
DOI: 10.5220/0004492001860197
In Proceedings of the 8th International Joint Conference on Software Technologies (ICSOFT-EA-2013), pages 186-197
ISBN: 978-989-8565-68-6
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

daily, one on storage management system (StoRM
1
)
and another on virtual resource provisioning on de-
mand (WNoDeS
2
), have been used to analyze the de-
fined model with a predictive technology called dis-
criminant analysis (Munson and Khoshgoftaar, 1992)
and based on risk-threshold (Pighin and Zamolo,
1997). Established this work, the model has been
proving so far to have all the capabilities of enhanc-
ing the development software process. We therefore
are confident that in the future project managers and
developers adopt this solution as particularly helpful
for evaluating their projects and controlling the over-
all health of the process. This paper is an oppor-
tunity to expose our ideas and share our experience
with researchers that think and try out things in the
same area. We have reached a point where we need
to involve others in a constructive manner in order to
move forward in our understanding of software en-
gineering. The paper is organized as follows: Sec-
tion 2 describes some of the software best practices
that have contributed to define the core of the model,
whilst Section 3 summarizes the metrics considered.
Section 4 provides the definition of the mathematical
model that links software data entities to a set of well-
known metrics. Section 5 illustrates the experimental
results. Section 6 describes related works and Sec-
tion 7 concludes with a brief of discussion of future
work.
2 SOFTWARE BEST PRACTICES
Developers have been striving to improve software
quality for decades. Despite this, projects keep fail-
ing from familiar causes as poor design and inade-
quate testing (Kopec and Tumang, 2007) as well as
the lack of a widespread well-known recipe (Brooks,
1995). From software development experience in sev-
eral projects (Ronchieri et al., 2009), a set of best
practices have been selected in relation to their capa-
bilities of determining projects’ success and offering
the greatest return, but that yet seem to be violated
more often than not. Some of the identified best prac-
tices have been denoted earlier either in different con-
texts or with different pre-requisites.
The best practices considered in this paper are de-
scribed below. Software Structure is the initial stage
of developing an application. Best practice includes
the usage of one of the existing software structures
known in literature (Top et al., 2004) such as con-
trol flow, data flow, file and code conventions (Merlo
1
http://storm.forge.cnaf.infn.it/
2
http://web.infn.it/wnodes/
et al., 1992), (Mengel and Tappan, 1995). Configu-
ration management involves knowing the state of all
artifacts that make up a project, managing the state
of those artifacts, and releasing distinct versions of a
system. Best practices for configuration management
consider, for example, the application of change code
on a new branch, the creation of a branch only when
necessary, the application of change propagation, and
the usage of common build tools (Wingerd and Sei-
wald, 1998). Construction of the code occupies the
central role in software development and often rep-
resents the only accurate description of the software;
hence, it is imperative that code be of the highest pos-
sible quality (McConnell, 1996). Best practices for
the construction of the code include daily builds and
continuous integration (Fawler et al., 1999). Testing
is an integral part of software development. Best prac-
tices include the planning of test cases before cod-
ing starts and the development of test cases whilst the
application is being designed and coded (Majchrzak,
2010). Deployment is the final stage of releasing an
application for users. A best practice is the usage
of a deployment procedure (Jansen and Brinkkemper,
2006), (Flissi et al., 2008), (Elbaum, 2005).
By following these best practices that seem obvi-
ous once used, a software project increases its chances
of being completed successfully. However, adopting
some of them can be very challenging, especially in
relation to the construction of the code and testing:
the former because it requires a certain amount of ef-
fort in order to perform a good initial design; the latter
on the grounds that testing is time consuming, too in-
consistent to be effective, error prone and inaccurate.
3 METRICS DESCRIPTION
Numerous empirical studies confirm that many soft-
ware metrics can be used to evaluate quality aspects
of general interest, like maintainability and correct-
ness (Fenton, 1990). The metrics considered into this
paper derives from the best practices and static analy-
sis.
From the software structure best practice, the met-
rics of file and code conventions are considered. The
main purpose of these metrics is measuring how well
a project is organized, focusing on the files and di-
rectories structure. Every software project is charac-
terized by a main directory underneath which a num-
ber of files and folders are located. Some file names
well fit into every kind of project, such as
AUTHORS
that contains the names of the authors of the project
with their roles such as developer, and project leader,
and
CREDITS
that contains a set of acknowledgments.
ASoftwareQualityPredictiveModel
187

Furthermore, the main directory can contain several
types of subdirectories, the most common of which
are named:
bin
for essential user command bina-
ries,
doc
for documentation files, and
tests
for code
to evaluate functionalities. Specific features can be
added according to the language by which the project
is implemented. For example, a software code that
needs
autotools
for the building could have a direc-
tory called
m4
with all the customized macros. In a
java web project the
WEB-INF
and
META-INF
directo-
ries might be found.
From the configuration management best prac-
tice, the software portability metric is considered that
refers to the software capability of being installed in
various platforms each of which is characterized by
a combination of operating system, kernel architec-
ture, and compiler version. Each platform can be
identified as a string of the form
os_arch_compile
:
the
os
substring is about the OS family e.g.
slc5
;
arch
stands for CPU architecture e.g.
ia32
,
x86_64
;
finally, the
compile
substring provides information
about the type and version of the compiler used, e.g.
gcc346
. The portability metric depends on how the
software project is distributed and their objective is to
measure the number of platforms on which a module
can be installed.
Finally, metrics about the static analysis of the
code are reckoned with (Chidamber and Kemerer,
1994): SLOCCount shows the number of lines of
code; Findbugs indicates the number of bugs found
during the build or test; Findbugs rate shows the per-
centage of modules that have successfully passed the
threshold defined by the user; WMC (Weighted Meth-
ods per Class) provides an index of the total complex-
ity of a class’ methods; DIT (Depth of Inheritance
Tree) provides for each class a measure of the inheri-
tance levels from the object hierarchy top (e.g., in Java
where all classes inherit Object the minimum value
of DIT is 1); NOC (Number of Children) measures
the number of immediate descendants of the class;
CBO (Coupling Between Object classes) represents
the number of classes coupled to a given class (effer-
ent couplings) that can occur through method calls,
field accesses, inheritances, arguments, return types,
and exceptions; NMP (Number of Public Methods)
counts all the methods in a class that are declared as
public. It can be used to measure the size of an API
provided by a package.
4 MODEL DEFINITION
The core of our approach is the model. In literature
UML diagrams, code, textual documents and mathe-
matical description (Harel and Rumpe, 2004) are for-
malisms to express models. This work has chosen to
only use the mathematical description formalism to
express various levels of abstraction the fundamental
concepts of software engineering, best practices, and
metrics, with a notation and concepts deriving mostly
from the set and graph theories. In the following sec-
tions a subset of the software best practices and met-
rics that are described in Section 2 and Section 3 are
taken into account for the construction of the model.
4.1 Fundamental Concepts
The fundamental concepts are file, directory, module,
and component, the hierarchy of which is shown in
Figure 1, according to which components can contain
files that are not in directories and modules, modules
can contain directories, and files cannot be contained
in either directories or modules.
Figure 1: Fundamental concepts.
A file f is a block of information, the block of
which is a set of text lines. Let L be a set of text lines
of a given file. Consider the function NumLines : SA →
N such that
NumLines( f)=l (1)
returns the number of lines l of the file f. A software
application SA = {f
1
, f
2
, ..., f
m
} is a set of files with m =
|SA| and m ∈ N.
Let SD = {d
1
, d
2
, ..., d
k
} be a set of directories
with k = |SD| and k ∈ N, and where a directory
d is defined as a collection of some files and of
other directories identified by a name - is a triple
(name,D, { f
1
, f
2
, ..., f
l
}) where name is the directory
identifier, and { f
1
, ... f
l
} is a subset of SA, and D ⊆
SD{name}.
A module m = {d
1
, d
2
, ..., d
j
} - a logical collec-
tion of directories - is a subset of SD. Let SM =
{m
1
, m
2
, ..., m
h
} be a set of modules with h = |SM| and
h ∈ N.
A component c ⊆ SD∪ SA - a logical portion of the
overall software application - is a subset of directories
or files. Let SC = {c
1
, c
2
, ..., c
b
} be a set of components
with b = |SC| and b ∈ N.
The function CompToFiles : SC → P (SA) such that
CompToFiles(c) = { f
1
, ..., f
q
} (2)
ICSOFT2013-8thInternationalJointConferenceonSoftwareTechnologies
188

gets the set of files { f
1
, ..., f
q
} that are in the compo-
nent c. Whilst the function CompToDirs : SC → P (SD)
such that
CompToDirs(c) = {d
1
, ..., d
qq
} (3)
gets the set of directories {d
1
, ..., d
qq
} that are in the
component c.
4.2 Best Practices Modeling
The selected best practices (as reported in Section 2)
are related to software structure, configuration man-
agement, construction of the code, testing and deploy-
ment.
4.2.1 Software Structure
Amongst the software structures file and code conven-
tions have been modeled.
The file structure expresses the structure of the
software design. It recommends putting files that are
associated with a component and work together into
the same directory.
A component will often contain various file types
for storing source code, object code, scripts, bi-
nary executables, data, and documentation. Let
FT = {executable, object, source code, batch,text, work
processor, library, archive} be a set of file types.
File name extensions are commonly used to dis-
tinguish amongst different kinds of files (e.g.,
.h
,
.c
,
.hpp
,
.java
,
.sh
). Let SE = {se
1
, ..., se
n
} be a set of
standard extensions (shown in Table 1) with n = |SE|
and n ∈ N that are considered for the file types.
Table 1: Standard extensions of a set of file types.
File Type Standard Extension
executable bin, jar, none
object obj, o
source code c, h, py, java, wsdl, cpp, hpp
batch sh, csh
text doc, txt, pdf, ps
word processor doc, tex, wp, rrf
library a, so
archive tar, rpm, deb
Let FN = {README,CHANGELOG, INSTALL,
LICENSE, MAINTENANCE} be a set of file names
that are recommended (i.e.,
README
file describes
the module and its use; a
CHANGELOG
file lists
what is finished and what needs to be done; an
INSTALL
file explains how to install the module;
a
MAINTENANCE
file explains how to maintain
the module files; a
LICENSE
file contains license
module information), the type of which is
text
with
txt
as standard extension. The function
IsFileFnIdentified : FN × SA → {0, 1} by taking
IsFileFnIdentified( fn, f) =
(
1 if f ∈ fn
0 otherwise
(4)
determines if the file f is called fn.
Furthermore, a component should contain at least
the following high-level directories with fixed names
in relation to the used programming language:
src
containing source code, replaced by
lib
for Perl
modules and by
<package name>
for Python mod-
ules;
test
containing test source code, replaced by
lib
for Perl modules;
interface
for public inter-
face files such as files with suffixes
.wsdl
, or
.h
;
config
for configuration and scripting files such as
files with suffixes
.conf
,
.ini
,
.sh
,
.csh
;
doc
con-
taining documentation files such as release notes, and
api references. The fixed structure allows the au-
tomation of tasks, such as directory creation, com-
pliance monitoring, file collection, and packaging.
Let DN = {dn
1
, dn
2
, ..., dn
mm
} be a set of directory
names with mm = |DN| and mm ∈ N. The function
IsDirDnIdentified : DN × SD → {0, 1} by taking
IsDirDnIdentified(dn, d) =
(
1 if d(0) ∈ dn
0 otherwise
(5)
determines if the name of the directory d(0) is called
dn.
Let PL = { java, c, c + +, perl, python, python} be a
set of programming languages that are considered in
the paper.
The code structure expresses the structure of the
software design. It recommends producing consis-
tent, clear code by using effective coding style (Oman
and Cook, 1988), following the conventions of
the adopted programming language (Li and Prasad,
2005), (SunMicrosystems, 1997), (Butler, 2012),
(Fang, 2001), (Rossum and Warsaw, 2001), (GC-
CTeam, 2012) and using formatting rules to display
the structure of the code.
Let ST = {st
1
, st
2
, ..., st
e
} be a set of styles with e =
|ST| and e ∈ N. Here the function StyleOf LangToFiles :
PL× ST → P (SA) such that
StyleOfLangToFiles(pl, st) = { f
1
, ..., f
y
} (6)
gets the set of files { f
1
, ..., f
y
} with y ∈ N that follows
the correct style st in accordance with the program-
ming language pl.
Let CT = {ct
1
, ct
2
, ..., ct
w
} be a set of conven-
tions with w = |CT| and w ∈ N. The function
ConvOfLangToFiles : PL×CT → P (SA) such that
ConvOf LangToFiles(pl, ct) = { f
1
, ..., f
o
} (7)
gets the set of files { f
1
, ..., f
o
} with o ∈ N that follows
the correct convention ct in accordance with the pro-
gramming language pl.
Let FR = { f r
1
, fr
2
, ..., f r
t
} be a set of formatting
rule with t = |FR| and t ∈ N. Finally the function
FruleOf LangToFiles : PL× FR → P (SA) such that
FruleOfLangToFiles(pl, ft) = { f
1
, ..., f
p
} (8)
ASoftwareQualityPredictiveModel
189

gets the set of files { f
1
, ..., f
p
} with p ∈ N that follows
a formatting rule fr in accordance with the program-
ming language pl.
4.2.2 Configuration Management
For this best practice the concepts of branch and build
have been modeled.
A branch b - a variant of code lines - is an element
of SA. Let SB = {b
1
, b
2
, ..., b
a
} be a set of branches with
a = |SB| and a ∈ N.
Let CC = {cc
1
, cc
2
, ..., cc
s
} be the set of code
changes with s = |CC| and s ∈ N. The function
IsChangecodeOnNewBranch :CC → {0, 1} such that
IsChangecodeOnBranch(cc) =
(
1 if cc is on a branch
0 otherwise
(9)
determines if the code change cc is on new branch.
Once branches are created to handle
code changes, the change propagation across
branches must be factored in. The function
ChangecodeOnBranchToBranches : CC × SB → P (SB)
such that
ChangecodeOnBranchToBranches(cc) = {b
1
, ..., b
ss
}
(10)
gets the set of branches {b
1
, ..., b
ss
} with ss ∈ N that
contains the code change cc.
A build is the business of constructing usable soft-
ware from original source files. It is based on source
files and the tools to which they are input, and charac-
terized by producing the same result. The build tools,
examples of which are shown in Table 2, are typically
linked to the used programming language and are able
to support several archive formats.
Table 2: Build tools.
Language Tool
java maven, ant
c++, c autotool, Cmake, make
python, perl autotool, Scons
Let BT = {bt
1
, bt
2
, ..., bt
f f
} be a set of build
tools with f f = |BT| and f f ∈ N. The function
LangToBuildtools : PL → P (BT) such that
LangToBuildtools(pl) = {bt
1
, ..., bt
x
} (11)
gets the set of build tools {bt
1
, ..., bt
x
} with x ∈ N that
are associated to the program language pl. The func-
tion SupportsCompBuildtool : BT × SC → N such that
SupportsCompBuildtool(bt, c) =
(
1 if c uses bt
0 otherwise
(12)
determines if the component c uses the build tool bt.
Furthermore, the function BuildtoolOfLangToComps :
PL× BT → P (SC) such that
BuildtoolOfLangToComps(pl, bt) = {c
1
, ..., c
g
}
(13)
gets the set of components {c
1
, ..., c
g
} with g ∈
N that use the given build tool bt with re-
spect to the programming language pl, where bt ∈
LangToBuildtools(pl) (see Eq. 11). The function
CompWithTargetArchiveToArchives : BT × SC → P (SE)
CompWithTargetArchiveToArchives(bt, c) = {se
1
, ..., se
h
}
(14)
gets the set of standard extensions {se
1
, ..., se
h
} of the
archive file type with h ∈ N that are provided by the
component c with respect to the target archive sup-
ported by its build tool bt.
Let OS be the set of operating systems. Let CMP
be the set of compilers. Finally, let MA be the set
of machine architectures. PLAT ⊆ OS × CMP × MA is
a set of platforms. The function SupportsCompPlat :
PLAT ×SC → {0, 1} such that
SupportsCompPlat(plat, c) =
(
1 if c runs on plat
0 otherwise.
(15)
gets the component c that supports the platform plat,
whilst the functionCompToPlats : SC → P (PLAT) such
that
CompToPlats(c) = {plat
1
, ..., plat
v
} (16)
gets the set of platforms {plat
1
, ..., plat
v
} with v ∈ N
that are supported by the component c.
4.2.3 Construction of the Code
Here, the concepts of software dependency, class,
method, function and procedure have been modeled.
The software dependencies considered in the pa-
per are amongst components (see Figure 2), inside a
given component (see Figure 3).
Dependencies amongst components DAC is a di-
rected graph composed of a set of vertices that repre-
sent components and a set of edges. Each edge con-
nects two components c
i
, c
j
and the sense of direction
from c
i
to c
j
is specified by an ordered pair < c
i
, c
j
>.
A path in DAC is a set of components < c
1
, c
2
, ..., c
n
>
such that < c
i
, c
j=i+1
> for each i from 1 to n ∈ N is an
edge in DAC.
Dependencies inside a component DIC is a di-
rected acyclic graph composed of a set of vertices that
represent files and a set of edges. Each edge connects
two files f
i
and f
j
where f
j
is adjacent to f
i
, and the
ICSOFT2013-8thInternationalJointConferenceonSoftwareTechnologies
190

Figure 2: Dependencies amongst components: c
i
depends
on c
j
with j = i+ 1.
sense of direction from f
i
to f
j
is specified by an or-
dered pair < f
i
, f
j
>. A path in DIC is a set of files
< f
1
, f
2
, ..., f
n
> such that < f
i
, f
i+1
> for each i from 1
to n ∈ N, is an edge in DIC. In this cases cycles are not
as problematic as in the previous case, due to the fact
that all dependencies are internal and therefore do not
increase the overall complexity of the system. Fur-
thermore they are common; e.g. an I/O component
may have a file F1 with routines that provide high-
level interfaces and another F2 that contains the low-
level implementation. In such a situation is it com-
mon that not only F1 depends on F2, but also that F2
depends on F1 to propagate common error situations.
Figure 3: Dependencies inside a component: d
i
depends on
f
z
and d
j
.
Circular dependencies unfortunately do happen in
real programs, and therefore they cannot be excluded,
though they reduce maintainability of a software pro-
gram due to increase interrelations among compo-
nents.
4.2.4 Others
For the testing and deployment best practices the con-
cepts of daily build, test cases and deployment proce-
dures have been modeled.
Let DH = {0, 1, 2, ..., 24} be a set of daily hours.
The function NumBuilds : DH → N such that
NumBuilds(dh) =
dh
num
(17)
returns how many builds are run daily with num ∈ N.
Let DF and BU a set of defined functionalities and
a set of discovered bugs during the build or test activ-
ity respectively, then TC = {tc
1
,tc
2
, ...,tc
z
} is a set of
test cases with z = |TS| ≥ |DF| + |BU| and z ∈ N. The
function FileToBugs : SA → P (BU) such that
FileToBugs( f) = {bu
1
, ..., bu
ww
} (18)
gets the set of bugs {bu
1
, ..., bu
ww
} with ww∈ N that are
included in the file f . The function IsTestcaseForBug :
BU × TC → {1, 0} such that
IsTestcaseForBug(bu,tc) =
(
1 if tc is for bu
0 otherwise.
(19)
gets the test case tc that is for the bug bu. Furthermore
the function CompToBugs : SC → P (BU) such that
CompToBugs(c) = {bu
1
, ..., bu
bb
} (20)
gets the set of bugs {bu
1
, ..., bu
bb
} with bb ∈ N that
are included in the component c, while the function
CompToTests : SC → P (TS) such that
CompToTests(c) = {ts
1
, ...,ts
cc
} (21)
gets the set of test cases {ts
1
, ...,ts
cc
} with cc ∈ N that
are included in the component c.
Let DP be a set of deployment procedures. The
function SupportsCompProcedure : DP × SC → {1, 0}
such that
SupportsCompProcedure(dp, c) =
(
1 if c supports a dp
0 otherwise.
(22)
gets the component c that supports the deployment
procedure dp, whilst the function CompToProcedures :
SC → P (DP) such that
CompToProcedures(c) = {dp
1
, ..., dp
vv
} (23)
gets the set of deployment procedures {dp
1
, ..., dp
vv
}
with vv ∈ N that are supported by the component c.
4.3 Metrics Modeling
Here, a subset of the metrics introduced in Section 3
have been modeled.
4.3.1 Software Structure
As concerns the software structure category, a set of
metrics have been defined.
In relation to the file structure best practice two
metrics have been defined: the former is the Total
Number of File Names (TNFN) metric that returns the
number of the recommended filenames included in
SC; the latter is the Total Number of Directory Names
(TNDN) metric that returns the number of the recom-
mended directory names included in SC.
TNFN relies on the function CompToFiles (see
Eq. 2) that returns the list of files included in a compo-
nent, and the function IsFileFnIdenti fied (see Eq. 4)
determines if the name of a given file is amongst
the recommended ones. The function NumFilenames :
SC → N such that
ASoftwareQualityPredictiveModel
191

NumFilenames(c) =
|CompToFiles(c)|
∑
k=1
|FN|
∑
j=1
IsFileFnIdenti fied( f n
j
,CompToFiles(c)
k
)
(24)
returns the number of the recommended filenames
defined in FN that are included in the component
c, the maximum value of which is |FN|, where
CompToFiles(c)
k
is the k-th file of the component c,
and fn
j
is the j-th file name ∈ FN. Therefore the func-
tion TNFN : N → N such that:
TNFN =
|SC|
∑
i=1
NumFilenames(c
i
) (25)
returns the total number of the recommended file-
names that are in SC, where c
i
is the i-th component
that belongs to SC and i = 1, ..., |SC|.
TNDN relies on the function CompToDirs (see
Eq. 3) that returns the list of directories included in
a component, and the function IsDirDnIdentified (see
Eq. 5) determines if the name of a given directory
is amongst the recommended ones. The function
NumDirnames : SD → N such that
NumDirnames(c) =
|CompToDirs(c)|
∑
k=1
|DN|
∑
j=1
IsDirDnIdenti fied(dn
j
,CompToDirs(c)
k
)
(26)
returns the number of the recommended directories
defined in DN that are included in the component
c, the maximum value of which is ≥ |DN|, where
CompToDirs(c)
k
is the k-th directory of the component
c, and dn
j
is the j-th directory name ∈ DN. Therefore
the function TNDN : N → N such that:
TNDN =
|SC|
∑
i=1
NumDirnames(c
i
) (27)
returns the total number of the recommended direc-
tory names that are in SC, where c
i
is the i-th compo-
nent that belongs to SC and i = 1, ..., |SC|.
In relation to the code conventions structure best
practice the defined metrics focus on determining
if files included in a component follow code styles
(IsCST), conventions (IsCCT), and formatting rules
(IsCFR). They relies on the functionCompToFiles (see
Eq. 2) that returns the list of files included in a com-
ponent, the function StyleOFLangToFiles (see Eq. 6)
that returns the files that follows a given style for a
specified language, the function ConvOFLangToFiles
(see Eq. 7) that returns the files that follows a given
convention for a specified language, the function
FruleOFLangToFiles (see Eq. 8) that returns the files
that follows a given formatting rule for a specified lan-
guage.
The function IsCST : SC → {1, 0}, given the pro-
gramming language pl and the code style st, such that
IsCST (c) =
(
1 if CompToFiles(c) ∈ StyleO f LangToFiles(pl, st)
0 otherwise
(28)
determines if the files included in the componentc fol-
low the code style st in accordance with the program-
ming language pl. Therefore the function TST : N → N
such that:
TST =
|SC|
∑
i=1
IsCST(c
i
) (29)
returns the total number of the files that follow the
code style st in accordance with the programming lan-
guage pl and that are in SC, where c
i
is the i-th com-
ponent that belongs to SC and i = 1, ..., |SC|.
The function IsCCT : SC → {1, 0}, given the pro-
gramming language pl and the code style ct, such that
IsCCT (c) =
(
1 if CompToFiles(c) ∈ ConvOf LangToFiles(pl, ct)
0 otherwise.
(30)
determines if the files included in the componentc fol-
low the conventionct in accordancewith the program-
ming language pl. Thereforethe function TCT :N → N
such that:
TCT =
|SC|
∑
i=1
IsCCT(c
i
) (31)
returns the total number of the files that follow the
convention ct in accordance with the programming
language pl and that are in SC, where c
i
is the i-th
component that belongs to SC and i = 1, ..., |SC|.
The function IsCFR : SC → {1, 0}, given the pro-
gramming language pl and the formatting rule f r,
such that
IsCFR(c) =
(
1 if CompToFiles(c) ∈ FruleO f LangToFiles(pl, fr)
0 otherwise.
(32)
determines if the files included in the component c
follow the formatting rule fr in accordance with the
programming language pl. Therefore the function
TFR : N → N such that:
TFR =
|SC|
∑
i=1
IsCFR(c
i
) (33)
returns the total number of the files that follow the for-
matting rule fr in accordance with the programming
language pl and that are in SC, where c
i
is the i-th
component that belongs to SC and i = 1, ..., |SC|.
ICSOFT2013-8thInternationalJointConferenceonSoftwareTechnologies
192

4.3.2 Configuration Management
As concerns the configuration management category,
the total number of platforms (TNP) metric is defined
relying on the function CompToPlats (see Eq. 16) that
returns the list of platforms supported by a compo-
nent. The function TNP : N → N such that:
TNP = k ∩
|SC|
i=1
CompToPlats(c
i
)k (34)
returns the total number of platforms supported.
4.3.3 Static
For the static category, a subset of the metrics de-
scribed in Section 3 are modeled below.
The Total SLOCCount (TSLOCCount) metric re-
lies on the function NumLines (see Eq. 1) that returns
the number of lines for a given file and CompToFiles
(see Eq. 2) that returns the list of files included in a
component. The function SLOCCount : SC → N such
that:
SLOCCount(c) =
|CompToFiles(c)|
∑
k=1
NumLines(CompToFiles(c)
k
)
(35)
returns the code lines of the component c, where
CompToFiles(c)
k
is the k-th file of the component c:
therefore the function TSC : N → N such that:
TSC =
|SC|
∑
k=1
SLOCCount(c
i
) (36)
returns the total code lines that are in SC.
The Total Findbugs (TF) metric relies on the set
BU that contains the discovered bugs, the function
CompToFiles (see Eq. 2) that returns the list of files
included in a component, and the function FileToBugs
(see Eq. 18) that returns the list of bugs included in a
file. The function Findbugs : SC → N such that
Findbugs(c) =
|CompToFiles(c)|
∑
k=1
|FileToBugs(CompToFiles(c)
k
)|
(37)
returns the number of bugs found in the component c,
where CompToFiles(c)
k
is the k-th file of the compo-
nent c: therefore the function TF : N → N such that:
TF =
|SC|
∑
k=1
Findbugs(c
i
) (38)
returns the total code lines that are in SC.
5 EVALUATION
The described model can be verified with the usage
of a risk-threshold discriminant analysis, the starting
point of which is the measurement of a set of param-
eters connected to the software products. In our study
the parameters are basically best practices and met-
rics that can identify faults in software components
and can be defined as risky parameters for that reason.
The identification of these risky parameters and the
components which have a high risk to contain faults
can be used to process the components before their
releasing. The validation steps of the model are spec-
ified below.
The process starts with a set of best practices SBP and
metrics SMT.
Each best practice i and metric u have been verified
in each component j as x
i, j
(1 ≤ i ≤ t, 1 ≤ j ≤ p) and
y
u, j
(1 ≤ u ≤ r, 1 ≤ j ≤ p), being t = |SBP| the number
of best practices, r = |SMT| the number of metrics and
p = |SC| the number of components.
For each best practice i, the mean value BPM
i
and the
standard deviation BPS
i
estimated on values obtained
for all components has been computed as
BPS
i
=
s
∑
p
j=1
(x
i, j
− BPM
i
)
2
p
(39)
where BPM
i
=
1
p
∑
p
j=1
(x
i, j
).
For each metric u, the mean value MTM
u
and the stan-
dard deviation MT S
u
estimated on values obtained for
all components has been computed as
MTS
u
=
s
∑
p
j=1
(y
u, j
− MTM
u
)
2
p
(40)
where MTM
u
=
1
p
∑
p
j=1
(y
u, j
).
For each best practice i and each component j, the
values
BPS
i, j
=
|x
i, j
− BPM
i
|
BPS
i
(41)
have been considered as the offset of the best practice
evaluated on the j-th component from the best prac-
tice mean value BPM
i
, normalized on the standard de-
viation of the best practice BPS
i
.
For each metric u and each component j, the values
MTS
u, j
=
|y
u, j
− MTM
u
|
MTS
u
(42)
have been considered as the offset of the metric eval-
uated on the j-th component from the metric mean
value MTM
u
, normalized on the standard deviation of
the metric MTS
u
.
The risk level of best practice i is calculated as
BPRL
i
=
p
∑
j=1
R
j
· BPS
i, j
(43)
ASoftwareQualityPredictiveModel
193
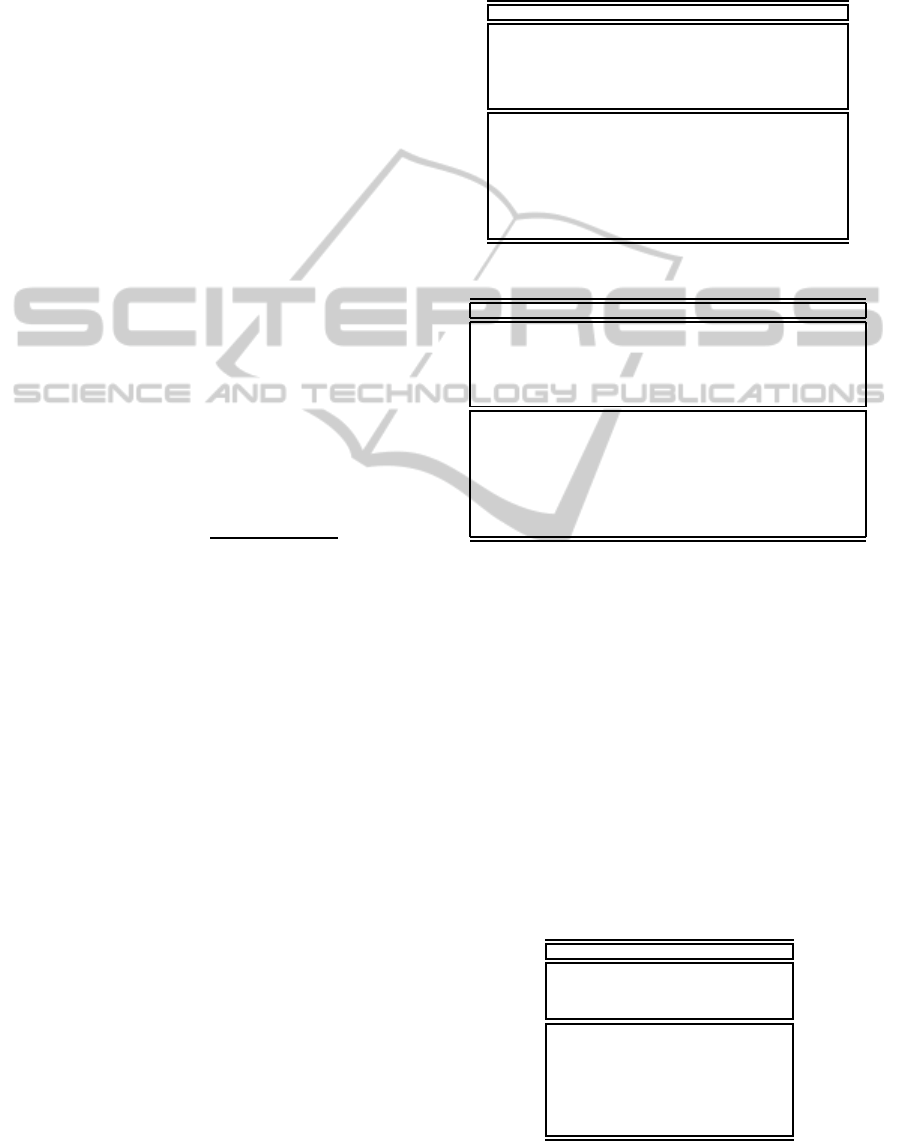
being R
j
considered 1 if the component j has reported
faults, 0 else. All the risk values have been normal-
ized with respect to the sum of all BPRL.
The risk level of metric u is calculated as
MTRL
u
=
p
∑
j=1
R
j
· MTS
u, j
(44)
being R
j
considered 1 if the component j has reported
faults, 0 else. All the risk values have been normal-
ized with respect to the sum of all MTRL.
The risk level of component j is computed as
CRL
j
=
t
∑
i=1
BPRL
i
x
i, j
+
r
∑
u=1
MRL
u
y
u, j
(45)
the sum of the best practice value with its risk level,
and the metric value with its risk level. All the risk
values have been normalized with respect to the sum
of all CRL.
The risk levels for each metric MTRL
u
and best
practice BPRL
i
are calculated on the basis of the ex-
amined components, whilst the risk level of compo-
nent CRL
j
is calculated on the basis of the risk levels
of metric MTRL
u
and best practice BPRL
i
. The risk-
threshold RT has been taken in the middle of the av-
erage values of the risk level of componentsCRL with
faults and components without faults, defined as
RT=avg(CRL
j
)
j∈ f aults
+
avg(CRL
j
)
j∈non− f aults
2
. (46)
5.1 Experiment Data Sets Description
The experiments have been carried out processing
sources from two software projects: StoRM (STOr-
age Resource Manager), an implementation of the
standard SRM interface for generic disk based on
storage system (Zappi et al., 2011), and WNoDeS
(Worker Nodes on Demand Service), a solution to vir-
tualize computing resources and to make them avail-
able through local, Grid and Cloud interfaces (Sa-
lomoni et al., 2011). These projects present files com-
ing from the same environment of development and
application fields (that are mainly related to the High
Energy Physics community). StoRM is a medium
sized system written in different programming lan-
guages (i.e.,
java
,
c++
,
c
,
python
, and
sh
), whilst
WNoDeS is a small system wholly written in
python
and
sh
. Both projects are composed of several soft-
ware components included in EMI3 Monte Bianco
distribution (Aiftimiei et al., 2012): 10 for WN-
oDeS and 21 for StoRM. For StoRM the following
components have been considred:
tStoRM
(Ronchieri
et al., 2012) that is a StoRM testing framework,
and five
sensor
components that are StoRM mon-
itoring framework. Whilst for WNoDeS there are:
Table 3: Measured best practices per component: the bt in
Eq. 12 is autotool; the values of Eq. 14 are rpm and tar; the
values of Eq. 16 are sl5, sl6 and deb; the values of Eq. 23 are
basically sl5, and sl6 with the peculiarity of the component
cli that also contains deb.
Components Eq. 12 |Eq. 14| |Eq. 16| Eq. 17 |Eq. 21| |Eq. 23|
tStoRM 1 2 3 5 10 2
sensor-api 1 2 3 2 2 2
sensor-common 1 2 3 2 0 2
sensor-host 1 2 3 2 2 2
sensor-run 1 2 3 2 0 2
sensor-service 1 2 3 2 0 2
hypervisor 1 2 3 2 0 2
bait 1 2 3 2 0 2
nameserver 1 2 3 2 0 2
manager 1 2 3 2 0 2
accounting 1 2 3 2 2 2
cli 1 2 3 4 8 3
site-specific 1 2 3 2 0 2
utils 1 2 3 2 1 2
cachemanager 1 2 3 2 1 2
Table 4: Measured Metrics per component.
Components Eq. 26 Eq. ?? Eq. 28 Eq.30 Eq. 32 Eq. 35 Eq. 37
tStoRM 4 3 1 1 1 14,011 97
sensor-api 3 0 1 1 1 233 0
sensor-common 3 1 1 1 1 158 3
sensor-host 3 1 1 1 1 166 1
sensor-run 3 1 1 1 1 192 0
sensor-service 3 1 1 1 1 191 6
hypervisor 3 2 1 1 1 1,635 12
bait 3 2 1 1 1 1,924 14
nameserver 3 2 1 1 1 1,094 12
manager 3 2 1 1 1 859 12
accounting 3 3 1 1 1 382 0
cli 4 3 1 1 1 1,386 1
site-specific 3 2 1 1 1 352 2
utils 3 3 1 1 1 2,265 26
cachemanager 3 3 1 1 1 2,558 20
hypervisor
that contains code to interact with the
virtualization system,
bait
that requests the instan-
tiation of virtual machines if enough resources are
available,
nameserver
that is a sort of information
management,
manager
that is an administrative com-
mand line,
accounting
that is responsible for provid-
ing accounting information of the provided resources,
cli
that is the cloud command line,
cachemanager
that takes care of the cloud resources provision-
ing,
site-specific
that is the site administrator re-
solver, and
utils
that contains common code shared
amongst the other WNoDeS components.
The experimental data set (see Table 3, Table 4,
and Table 5) have been collected with heterogeneous
Table 5: Parameters and basic statistical data.
Parameters Total Mean
TArchives 30 2
TNumBuild 35 2.333
TNumTestCases 26 1.733
TProcedures 31 2.066
TNFN 47 3.133
TNDN 29 1.933
TST 15 1
TCR 15 1
TFR 15 1
TNP 45 3
TSC 27,406 1,827.066
TF 206 13.733
ICSOFT2013-8thInternationalJointConferenceonSoftwareTechnologies
194

source types in order to highlight similarities and dif-
ferences amongst development scenarios. Therefore
we have selected software components mainly written
in
python
and
sh
for each project that have been pro-
duced over a period of five years. The analysis have
been done on 1, 513 files in 15 components amounting
to a total code lines TSC of 27, 406. The considered
best practices and metrics to create the data sets have
been estimated by using a prototype tool that codes
the presented model. The data related to faults have
been used as the dependent variable of the following
study. Here, a software model has been considered
fault if at least a fault has been recorded. On account
of the complexity of the model, no further inspection
on the relationships amongst faulty component, met-
rics and best practices have been carried out.
5.2 Experimental Results
In this section, a short description of the procedures
adopted for the data analysis is reported. The ob-
jective has been to validate our model with exist-
ing software projects in order to estimate their fault-
proneness. The main idea is to start from the analysis
of the whole set of best practices and metrics so as
to identify the most important ones, relying on their
contribution in estimating component concentration
of failures. At this stage, all the best practices and
metrics measured in Table 3 and Table 4 have been
considered. However, no limitation on their number
has been adopted. Experiments have been performed
by using the parameters mentioned in Table 5, for
which the total number of occurrences, and the mean
value have been calculated.
The followed steps are specified below: the risk-
coefficient has been calculated for each component of
the set; the mean values have been computed for fault
and no-fault; the risk-threshold has been fixed be-
tween the two means with a "neutral" range centered
in the threshold value so to exclude critical value from
the classification; the set has been grouped according
to the same nature on the basis of complexity and size;
the discriminant analysis has been performed on best
practice and metric groups and results have been pro-
duced; the model identified by discriminant analysis
has been evaluated.
The best practices and metrics have been consid-
ered as the main subject of the analysis in order to pro-
duce an acceptable rate for fault-proneness estimation
(about 85%). By using the whole best practices and
metrics set contribution, the model classified all the
components in the groups with a correctness of about
83%. In this case our set partly failed in producing
a suitable fault proneness prediction due to both the
number and low risk level of some metrics and best
practices.
6 RELATED WORKS
A number of useful related projects have been re-
ported in the literature. (Briand et al., 1993) proposed
the construction of a modeling process aiming at pre-
dicting which components of a software project are
likely to contain the highest concentration of faults.
Such a modeling process is based on the Optimized
Set Reduction (OSR) approach. With respect to this
work, ours leverages not only on measurements re-
lated to the code but also on best practices. (Khosh-
goftaar and Seliya, 2003) introduced two new estima-
tion procedures for regression modeling, comparing
their performance in the modeling of software qual-
ity in terms of predictive quality and the quality of fit
with the more traditional least square and least abso-
lute values estimation. The major difference between
our research and this one is in the use of best practices,
as already noticed in Section 2. (Kim et al., 2007)
proposed a model to predict the most fault prone en-
tities and files. Caching the location where faults are
discovered a developer can detect likely fault-prone
locations. This is used in order to prioritize veri-
fication and validation resources on the most fault
prone files or entities. With respect to this work, ours
uses best practices and metrics to build the predictive
model.
7 CONCLUSIONS
Over the last years we have been gathering concep-
tual elements that helped us in facing the complex-
ity of the activity of making software. We have dis-
tilled our insights and by trying to invent as less
as possible we have stabilized relationships amongst
some basic concepts of software engineering. In this
paper we have presented a model to predict soft-
ware quality, which has been designed leveraging on
our experience on software development in European
projects (Ronchieri et al., 2009). As a peculiarity of
the model, we havecombined best practices with met-
rics in order to contrive the improvement of software
development process focusing on the early planning
phases. The described best practices and metrics con-
sider several aspects of the software life cycle such
as configuration management and testing belonging
to the best practices, and static analysis metrics. Our
approach has consisted of evaluating a subset of those
best practices and metrics that have been assessed as
ASoftwareQualityPredictiveModel
195

crucial for achieving our fulfillment. Furthermore,
we have analyzed the quality model by using simi-
lar modules of StoRM and WNoDeS projects charac-
terized by having in common programming language
and build tool. We have decided to present our work
at this stage to share our thoughts with researchers in-
terested in modeling. We hope that some parts of our
works might help to understand the evolution of soft-
ware engineering models. In the near future this work
should be repeated by involving more heterogeneous
modules of the stated projects, and, hence, increasing
the validity of the described model. By doing this,
larger data sets could be produced leading to a better
estimation of our work. To enlarge the input data of
the used predicting technology, on one hand the set
of metrics will be extended with the dynamic one; on
the other hand other best practices included in their
set will be modelled.
ACKNOWLEDGEMENTS
This research was supported by INFN CNAF. The
findings and opinions in this study belong solely to
the authors, and are not necessarily those of the spon-
sors.
REFERENCES
Aiftimiei, C., Ceccanti, A., Dongiovanni, D., Meglio, A. D.,
and Giacomini, F. (2012). Improving the quality of
emi releases by leveraging the emi testing infrastruc-
ture. Journal of Physics: Conference Series, 396(5).
Briand, L. C., Basili, V. R., and Hetmanski, C. J. (1993).
Developing interpretable mmodel with optimized set
reduction for identifying high-risk software compo-
nents. IEEE TRANSACTIONS ON SOFTWARE EN-
GINEERING, 19.
Brooks, F. P. (1995). The mythical man-month. Addison-
Wesley Boston.
Butler, S. (2012). Mining java class identifier naming con-
ventions. In Software Engineering (ICSE), 2012 34th
International Conference, pages 1641–1643.
Chhabra, J. and Gupta, V. (2010). A survey of dynamic
software metric. Journal of Computer Science and
Technology, 25:1016–1029.
Chidamber, S. R. and Kemerer, C. F. (1994). A metrics suite
for object oriented design. Transactions on Software
Engineering, 20(6):476–493.
Coleman, D., Ash, D., Lowther, B., and Auman, P. (1994).
Using metrics to evaluate software system maintain-
ability. IEEE Computer, 27(8):44–49.
Debbarma, M. K., Kar, N., and Saha, A. (2012). Static
and dynamic software metrics complexity analysis in
regression testing. In International Conference on
Computer Communication and Informatics (ICCCI),
Coimbatore, India. IEEE, IEEE.
DeMarco, T. (1982). Controlling Software Project. Prentice
Hall.
Elbaum, S. (2005). Profiling deployed software: Assessing
strategies and testing opportunities. IEEE Transac-
tions on Software Engineering, 31.
Fang, X. (2001). Using a coding standard to improve pro-
gram quality. In Quality Software 2001. Proceedings
Second Asia-Pacific Conference, pages 73–78.
Fawler, M., Beck, K., Brant, J., Opdyke, W., and Roberts,
D. (1999). Refactoring: Improving the Design of Ex-
isting Code [Hardcover]. Addison-Wesley Profes-
sional.
Fenton, N. (1990). Software metrics: theory, tools and val-
idation. Software Engineering, 5(1):65–78.
Flissi, A., Dubus, J., Dolet, N., and Merle, P. (2008). De-
ploying on the grid with deployware. In Cluster Com-
puting and the Grid, 2008. CCGRID ’08. 8th IEEE
International Symposium, pages 177–184.
GCCTeam (2012). Gcc coding conventions.
Harel, D. and Rumpe, B. (2004). Meaningful modeling:
What’s the semantics of "semantics"? Computer,
37(10):64–72.
IEEE90 (1990). IEEE Standard Glossary of Software En-
gineering Terminology, ieee std 610.12-1990, institute
of electrical and electronic engineers, inc., new york,
ny, edition.
Jansen, S. and Brinkkemper, S. (2006). Evaluating the
release, delivery, and deployment processes of eight
large product software vendors applying the customer
configuration update model. In WISER ’06 Proceed-
ings of the 2006 international workshop on interdisci-
plinary software engineering research, pages 65–68.
Khoshgoftaar, T. M. and Seliya, N. (2003). Analogy-based
practical classification rules for software quality es-
timation. Empirical Software Engineering Journal,
8(4):325–350.
Kim, S., Zimmermann, T., Jr, E. W., and Zeller, A. (2007).
Predicting faults from cached history. pages 489–498.
IEEE Computer Society Washington DC, USA.
Kopec, D. and Tumang, S. (2007). Failures in complex
systems: case studies, causes, and possible remedies.
SIGCSE Bulletin, 39(2):180–184.
Li, X. S. and Prasad, C. (2005). Effectively teaching coding
standards in programming. In SIGITE’05, pages 239–
244, Newark, New Jersey, US. ACM New York, NY,
USA.
Majchrzak, T. A. (2010). Best practices for technical as-
pects of software testing in enterprises. In Informa-
tion Society (i-Society), 2010 International Confer-
ence, pages 195–202.
McConnell, S. (1996). Who cares about software construc-
tion? IEEE Software, 13(1):127–128.
Mengel, S. A. and Tappan, D. A. (1995). Program de-
sign in file structures. In Frontiers in Education Con-
ference, 1995. Proceedings., 1995, pages 4b2.11 –
4b2.16 vol.2.
ICSOFT2013-8thInternationalJointConferenceonSoftwareTechnologies
196

Merlo, E., Kontogiannis, K., and Girard, J. (1992). Struc-
tural and behavioral code representation for pro-
gram understanding. In Computer-Aided Software
Engineering, 1992. Proceedings., Fifth International
Workshop, pages 106–108.
Munson, J. C. and Khoshgoftaar, T. M. (1992). The detec-
tion of fault-prone programs. IEEE Transactions on
Software Engineering, 18(5):423–432.
Oman, P. W. and Cook, C.-P. (1988). A paradigm for pro-
gramming style research. ACM SINGPLAN Notices,
23(12):69–78.
Pighin, M. and Zamolo, R. (1997). A predictive met-
ric based on discriminant statistical analysis. In The
19th International Conference on Software Engineer-
ing, ICSE’97, pages 262–270, Boston, Massachusetts,
USA.
Ronchieri, E., Dibenedetto, M., Zappi, R., Aiftimiei, C.,
Vagnoni, V., and Venturi, V. (2012). T-storm: a storm
testing framework. In PoS(EGICF12-EMITC2), num-
ber 088, pages 1–11.
Ronchieri, E., Meglio, A. D., Venturi, V., and Muller-Wilm,
U. (2009). Guidelines for adopting etics as build and
test system.
Rossum, G. V. and Warsaw, B. (2001). Style guide for
python code.
Salomoni, D., Italiano, A., and Ronchieri, E. (2011). Wn-
odes, a tool for integrated grid and cloud access and
computing farm virtualization. Journal of Physics:
Conference Series, 331(331).
SunMicrosystems (1997). Java code conventions.
Top, S., Nørgaard, H. J., Krogsgaard, B., and
Jørgensen, B. N. (2004). The sandwich code
file structure - an architectural support for software en-
gineering in simulation based development of embed-
ded control applications. In Press, A., editor, IASTED
International Conference on Software Engineering.
Wingerd, L. and Seiwald, C. (1998). High-level best
practices in software configuration management. In
Eighth International Workshop on Software Configu-
ration Management Brussels.
Zappi, R., Ronchieri, E., Forti, A., and Ghiselli, A. (2011).
An Efficient Grid Data Access with StoRM. Lin,
Simon C. and Yen, Eirc, Data Driven e-Schience.
Springer New York.
ASoftwareQualityPredictiveModel
197
