
Semantic Copyright Management of Media Fragments
Roberto García, David Castellà and Rosa Gil
Universitat de Lleida, Jaume II 69, Lleida, Spain
Keywords: Digital Rights Management, Copyright, Media Fragment, Web Ontology, Semantic Web, Ontology
Engineering.
Abstract: The amount of media in the Web poses many scalability issues and among them copyright management.
This problem becomes even bigger when not just the copyright of pieces of content has to be considered,
but also media fragments. Fragments and the management of their rights, beyond simple access control, are
the centrepiece for media reuse. This can become an enormous market where copyright has to be managed
through the whole value chain. To attain the required level of scalability, it is necessary to provide highly
expressive rights representations that can be connected to media fragments. Ontologies provide enough
expressive power and facilitate the implementation of copyright management solutions that can scale in
such a scenario. The proposed Copyright Ontology is based on Semantic Web technologies, which facilitate
implementations at the Web scale, can reuse existing recommendations for media fragments identifiers and
interoperate with existing standards. To illustrate these benefits, the papers presents a use case where the
ontology is used to enable copyright reasoning on top of DDEX data, the industry standard for information
exchange along media value chains.
1 INTRODUCTION
Digitalisation and the transition to a Web full of
media, where video already amounts more than half
of online consumer traffic
1
, have introduced new
scalability requirements like bandwidth exigencies,
which technology is rapidly evolving to cope with.
However, there are other limiting factors that are not
scaling so well, especially those that have been
traditionally slow moving like copyright.
As the amount of content made available through
the Web grows, for instance 72 hours of video are
uploaded to YouTube every minute
2
, the problem of
managing its copyright becomes even more relevant.
Consequently, there is already a need to make rights
management scale to a web of media, as pointed by
recent initiatives like the PLUS Coalition
3
or the
Linked Content Coalition
4
. These initiatives, among
other things, propose ways to represent and
1
Cisco's Visual Networking Index, http://www.cisco.com/en/US/
netsol/ns827/networking_solutions_white_papers_list.html
2
YouTube Statistics, http://www.youtube.com/yt/press/statistics.
html
3
PLUS Coalition, http://www.useplus.com
4
Linked Content Coalition, http://www.linkedcontentcoalition.org
communicate rights so they can be automatically
processed in a scalable way.
However, the issues associated with copyright
management at a Web scale become even more
complex when it goes beyond simple access control
and takes into account also content reuse and the
whole content value chain. In this case, rights
representations need to be more sophisticated so
they can capture the full copyright spectrum.
In addition, as reuse is easier when considering
just fragments, spatial or temporal, of existing
content and not full content pieces. Proposed
solutions should scale not just to a Web of media but
also to a Web of media fragments. Fragments,
accompanied by scalable copyright management for
the full value chain, enable a potentially enormous
re-use market.
The main contribution described in this paper is a
Web ontology for the representation and
communication of rights and licensing terms over
media assets in terms of their fragments. The
ontology is based on Semantic Web technologies
and integrates with the W3C Media Fragments
Recommendation (Troncy et al., 2012) to define and
describe spatial and temporal media fragments.
The ontology makes it possible to underpin the
media discovery and usage negotiation process,
230
García R., Castellà D. and Gil R..
Semantic Copyright Management of Media Fragments.
DOI: 10.5220/0004493102300237
In Proceedings of the 2nd International Conference on Data Technologies and Applications (DATA-2013), pages 230-237
ISBN: 978-989-8565-67-9
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

facilitating the automation of functionalities for
rights management. Based on an explicit and
interoperable semantic representation for the
communication of rights, the ontology facilitates
assessing the reusability of a given media asset
fragment and eases bringing content onto this
flourishing market. For instance, by interoperating
with DDEX data
5
, one of the main standards for
automating the exchange of information along the
digital supply chain.
The rest of the papers is organised as follows.
First, in Section 2, related work is presented together
with the W3C Media Fragments recommendation
that makes it possible to attach licenses to media
fragments. Then, the Copyright Ontology is
presented in Section 3 and a use case showing this
ontology in practice is included in Section 4. Finally,
Section 5 presents the conclusions and the future
work.
2 RELATED WORK
The DRM Watch review on DRM standards
(Rosenblatt, 2008) shows that interoperability is a
key issue for DRM systems. For instance, it arises in
the content distribution scenario when users want to
consume content in any of the devices they own.
Interoperability is also critical in the organisation
scenario, when content flows through organisations
or external content is used in order to derive new
one.
The main response to DRM interoperability
requirements has been the settlement of many
standardisation efforts. The main ones are ISO/IEC
MPEG-21 (Wang et al., 2005) and ODRL (Iannella
2002), and in both cases the main interoperability
facilitation component is a Rights Expression
Language (REL).
The REL is a XML Schema that defines the
grammar of a license modelling language, so it is
based on a syntax formalisation approach. There is
also the MPEG-21 Rights Data Dictionary and a
ODRL Data Dictionary Schema (DD) that captures
the semantics of the terms employed in the REL, but
it does so without defining formal semantics (García
and Delgado, 2005).
This syntax-based approach is also common to
other DRM interoperability efforts and one of main
causes of the proliferation of interoperability
initiatives that cannot interoperate among them, like
in the e-books domain (Rosenblatt, 2009). Despite
5
DDEX, http://www.ddex.net
the great efforts in place, the complexity of the
copyright domain makes it very difficult to produce
and maintain implementations based on this
approach.
The implementers must build them from
specifications that just formalise the grammar of the
language and force the interpretation and manual
implementation of the underlying semantics. This
has been feasible for less complex domains, for
instance when implementing a MPEG-4 player from
the corresponding specification. However, this is
hardly affordable for a more complex and open
domain like copyright, which also requires a great
degree of flexibility.
Moreover, the limited expressivity of the
technical solutions currently employed makes it very
difficult to accommodate copyright law into DRM
systems. Consequently, DRM standards tend to
follow the traditional access control approach. They
concentrate their efforts in the last copyright value
chain step, content consumption, and provide limited
support for the other steps.
In fact, just Internet publishing risks are
considered and the response is to look for more
restrictive and secure mechanism to avoid access
control circumvention. This makes DRM even less
flexible because it ties implementations to
proprietary and closed hardware and software
security mechanisms.
The limited support for copyright law is also a
concern for users and has been criticised, for
instance by the Electronic Frontier Foundation
(Doctorow, 2005). The consequence of this lack is
basically that DRM systems fail to accommodate
rights reserved to the public under national copyright
regimes (Springer and García, 2008).
Consequently, the DRM world remains apart
from the underlying copyright legal framework. As
it has been noted, this is a risk because DRM
systems might then incur into confusing legal
situations. Moreover, it is also a lost opportunity
because, from our point of view, ignoring copyright
law is also ignoring a mechanism to achieve
interoperability. Therefore, DRM must evolve to
Copyright Management.
It is true that copyright law diverges depending
on local regimes but, as the World Intellectual
Property Organisation
6
promotes, there is a common
legal base and fruitful efforts towards a greater level
of copyright law worldwide harmonisation.
A new approach is necessary if we want profit
6
WIPO, World Intellectual Property Organization,
http://www.wipo.int
SemanticCopyrightManagementofMediaFragments
231

from the Internet as a content sharing medium. The
existence of this opportunity is clear when we
observe the success of the Creative Commons
initiative, whose objective is to promote content
sharing and reuse thorough innovative copyright and
licensing schemes.
However, despite the success of Creative
Commons licenses, this initiative is not seen as an
alternative to DRM. The main reason is the lack of
flexibility of the available licensing terms. There are
mainly six different Creative Commons licenses, all
of them non-commercial, and just an informal
mechanism for extension and adoption of alternative
licensing schemes, CC+
7
.
Moreover, Creative Commons licenses are
available in three formats: a legal version for
lawyers, a more readable version for average users
and as metadata for computers consumption.
However, the Creative Commons metadata is not a
formal representation of the licenses; it just provides
a reduced set of terms for building computer-
oriented licenses. There are three kinds of
permissions (reproduction, distribution and
derivative works), one prohibition (commercial use)
and four requirements (attribution, notice, share
alike and source code).
Consequently, although it is possible to provide
computer support for simple services like content
search, there are no mechanisms for customisation
and advanced computerised support that enable an
Internet-wide copyright-based alternative to DRM
systems.
2.1 Media Fragments
Media fragments are defined by spatial or temporal
boundaries in media assets. For temporal
boundaries, they are based on a start time point and
an end time point (or a duration) that define a
temporal subset of the original media. This kind of
fragments can be also defined for audio content.
Spatial boundaries are specific to visual media
(pictures or videos) and correspond to a subarea in
the original media. The subarea is usually shaped as
a rectangle defined by two points or one point plus a
height and width. The point coordinates and the
sizes are usually defined using pixels or percentages.
To make media fragments scale, its creation can
be automated based on media analysis techniques
capable of determining appropriate spatial and
temporal boundaries in visual media, in which a self-
contained part of the media can be found.
7
http://wiki.creativecommons.org/CCPlus
Media analysis techniques can be also used to
create semantic media fragment descriptions, which
permit the connection of self-contained media
fragments to the concepts (things, people, locations,
events...) they are perceived as representing.
Semantic descriptions can be also derived from
existing metadata generated in the media production
process and augmented by tools provided within the
media creation phase.
Semantic technology is a means to describe
media in a way that can be understood and processed
by machines. Concepts can be unambiguously
identified by URIs using Semantic Web Linked Data
principles (Hausenblas et al., 2009). Ontologies,
which define permitted terms and how they relate to
one another, are the basis for machine reasoning and
automatic derivation of new knowledge about the
media (e.g. a fragment which shows Angela Merkel
is also showing the German Chancellor).
The W3C Media Fragment URI specification
serves as a media format independent, standardised
means of addressing parts of media resources using
URIs, for instance as shown in Table 1.
The use of the Media Fragment URIs provides a
consistent identification of fragments in all stages of
the media workflow as well as re-use of current tools
and services which support the specification.
Moreover, it becomes trivial to enrich media
fragments descriptions with semantic data based on
Semantic Web technologies, which use URIs as the
way to identify resources.
For instance, the Copyright Ontology, described
in the next section, makes use of fragment URIs and
can attach to them information about their rights
situations, licensing terms, etc.
Table 1: Media Fragment URI example.
http://my.tv/video.ogv#t=60,100&xywh=12,12,42,30
Time
fragment,
from 60s.
to 100s.
Spatial fragment,
rectangle from pixel
x=12, y=12 and width
42px, height 30px
3 THE COPYRIGHT ONTOLOGY
The Copyright Ontology has been engineered
following the Methontology (Gómez-Pérez et al.,
2004) methodology for ontology engineering. It
provides guidance for ontology development process
but also for other support and management
activities. The ontology developing process it
proposes is composed by the following phases:
specification, conceptualisation, formalization,
DATA2013-2ndInternationalConferenceonDataManagementTechnologiesandApplications
232

implementation and maintenance.
The specification phase corresponds to the pre-
development aspects, where the development
requirements are identified. The maintenance phase
is a post-development activity, it is performed once
the ontology is developed. During the
conceptualisation activity, the domain knowledge is
structured as meaningful models. The static part of
the conceptualisation corresponds to the concepts
called continuants or endurants (Gangemi, 2002).
Then it is time to the dynamic part, which
corresponds to the concepts called ocurrents or
perdurants (Gangemi, 2002). The process is inspired
by the way we actually model the dynamic aspects
of the world using our main knowledge
representation tools, i.e. natural language. The
central piece is the verb, which models the dynamic
aspects and constitutes the core of natural language
sentences.
The objective is to apply this same pattern when
modelling the dynamic aspects of an ontology. The
first step is to identify the verb concepts
corresponding to the ocurrents in the domain at
hand, i.e. processes, situations, events, etc. These
concepts will constitute the main part of the model
for the dynamic part, just the same role verbs play in
NL sentences.
This first step just identifies some concepts that
are not enough to build complex knowledge
expressions. In order to do that, the inspiration is
also from how NL sentences work. In NL sentences,
the verb is connected to other sentence constituents,
i.e. participants, in order to build expressions that
model processes, events, situations, etc. This kind of
connection has been studied for long in the NL
domain and a characterisation of them has been
made. These connections are characterised as verb
fillers called case roles or thematic roles (McRae et
al., 1997).
This approach has been extensively used in the
NL research domain but there is little work about
applying case roles for knowledge representation.
There is the FrameNet (Fillmore et al., 2003)
initiative but it is mainly oriented towards
knowledge acquisition from NL sources by semi-
automatic annotation.
Two of the main proposals about the application
of case roles for knowledge representation are those
for Sowa (Sowa, 2004) and Dick (Dick, 1991). From
these sources, a selection of case roles that can be
extensively used to model the dynamic part of
ontologies has been built. The contribution of this
selection is that it is specially tailored to be
integrated as a pattern for ontology engineering.
Table 2 shows this case roles selection, which is
organised in four classes of generic case roles, which
are shown at the top, and six categories, which are
shown at the right. These categories correspond to
verb semantic facets, not disjoint classes of verbs.
Therefore, the same verb concept can present one or
more of these facets. For instance, the play verb can
show the action, temporal and spatial facets in a
particular sentence.
Table 2: Case roles for the NL-oriented pattern.
initiator resource goal essence
Action agent, instrument result, patient,
effector recipient theme
Process agent, matter result, patient,
origin recipient theme
Transfe
r
agent, instrument, experiencer, theme
origin medium recipient
Spatial origin path destination location
Temporal start duration completion pointInTime
Ambient reason manner aim, condition
consequence
Consequently, once the verb concepts have been
identified, the second step of the proposed pattern
corresponds to the process of determining the case
roles that are necessary to build the dynamic model.
Formal methods can be employed to constraint how
the verb concept and the case roles are related.
Therefore, this pattern allows a great range of model
detail levels. Moreover, it is a very complete set of
case roles. It includes all the case roles identified in
the refereed bibliography and, as it is shown in the
next subsection, it has been used during the
Copyright Ontology development. During this
development process no case role lack was detected
and all the verb models could be built with just the
case roles in Table 2.
3.1 Conceptualisation
This section details the Copyright Ontology
conceptualisation activity. This activity is used as an
illustrative example of the pattern presented in the
previous section, which was employed in the
Copyright Ontology engineering process.
The copyright domain is a complex one and
conceptualising it is a very challenging task. The
conceptualisation process, as it has been shown in
the pattern description, is divided into two phases.
The first one concentrates on the static aspects of the
domain. The static aspects are divided into two
different submodels due to its complexity.
First, there is the creation submodel. This model
is the basis for building the conceptual models of the
rest of the parts. It defines the different forms a
creation can take, which are classified following the
SemanticCopyrightManagementofMediaFragments
233

three main points of view as proposed by many
upper ontologies, e.g. the Suggested Upper Merged
Ontology (Niles and Pease 2001):
Abstract: Work.
Object: Manifestation, Fixation and Instance.
Process: Performance and Communication.
A part from identifying the key concepts in the
creation submodel, it also includes some relations
among them and a set of constraints on how they are
interrelated. More details for this point and the
following steps in the conceptualisation process are
available from
8
.
Second, there is the rights submodel, which is
also part of the static part model. The Rights Model
follows the World Intellectual Property Organisation
(WIPO
9
) recommendations in order to define the
rights hierarchy. The most relevant rights in the
DRM context are economic rights as they are related
to productive and commercial aspects of copyright.
All the specific rights in copyright law are modelled
as concepts. For the economic aspects of copyright
there are the following rights: Reproduction,
Distribution, Public Performance, Fixation,
Communication and Transformation Right.
Each right governs a set of actions, i.e. things
that the actors participating in the copyright life
cycle can perform on the entities in the creation
model. Therefore, it is time to move to the dynamic
aspects of the domain. The model for the dynamic
part is called the Action Model and it is built on the
roots of the two previous ones.
Actions correspond to the primitive actions that
can be performed on the concepts defined in the
creation submodel and which are regulated by the
rights in the rights submodel. For the economic
rights, these are the actions:
Reproduction Right: reproduce, commonly
speaking copy.
Distribution Right: distribute. More specifically
sell, rent and lend.
Public Performance Right: perform; it is
regulated by copyright when it is a public
performance and not a private one.
Fixation Right: fix, or record.
Communication Right: communicate when the
subject is an object or retransmit when
communicating a performance or previous
communication, e.g. a re-broadcast. Other related
actions, which depend on the intended audience,
8
A Semantic Web approach to Digital Rights Management,
http://rhizomik.net/~roberto/thesis
9
WIPO, http://www.wipo.int
are broadcast or make available.
Transformation Right: derive. Some
specialisations are adapt or translate.
At this point we have completed the first phase of
the dynamic model part, i.e. the verb concepts have
been identified. They constitute the key elements in
order to build knowledge expressions that represent
the processes, events and situations that occur in the
copyright domain.
In order to build this expression and relate the
verb concepts to the other participants, i.e. concepts
in the creation submodel or reused from other
ontologies, it is time to complete the dynamic model
and detail for each verb concept the corresponding
case roles.
Due to space limitations, this section includes
just the detailed model for the Copy action, which is
formally known as Reproduce. However, it is
commonly referred to as Copy and this term is the
one that is going to be used in the ontology in order
to improve its usability. Copies have been
traditionally the basic medium for Work
commercialisation. They are produced from a
Manifestation, from a Fixation of a Performance or
from another Instance. Therefore, these are the
theme of the Copy verb as it is shown in Table 3.
The result is an Instance that is the item
employed for the physical commercialisation of
works, i.e. when a physical item is used as the
vehicle to make the Work arrive to its consumers.
For example, the making of copies of a protected
work is the act performed by a publisher who wishes
to distribute copies of a text-based work to the
public, whether in the form of printed copies or
digital media such as CD-ROMs.
Table 3: Copy case roles.
Case role Range Cardinality
agent
Person
(Natural or Legal)
1..N
theme
Manifestation OR Fixation OR
Instance
1
result Instance 1
pointInTime e.g. ISO8601 1
location e.g. ISO3166, URL, ... 1
... ... ...
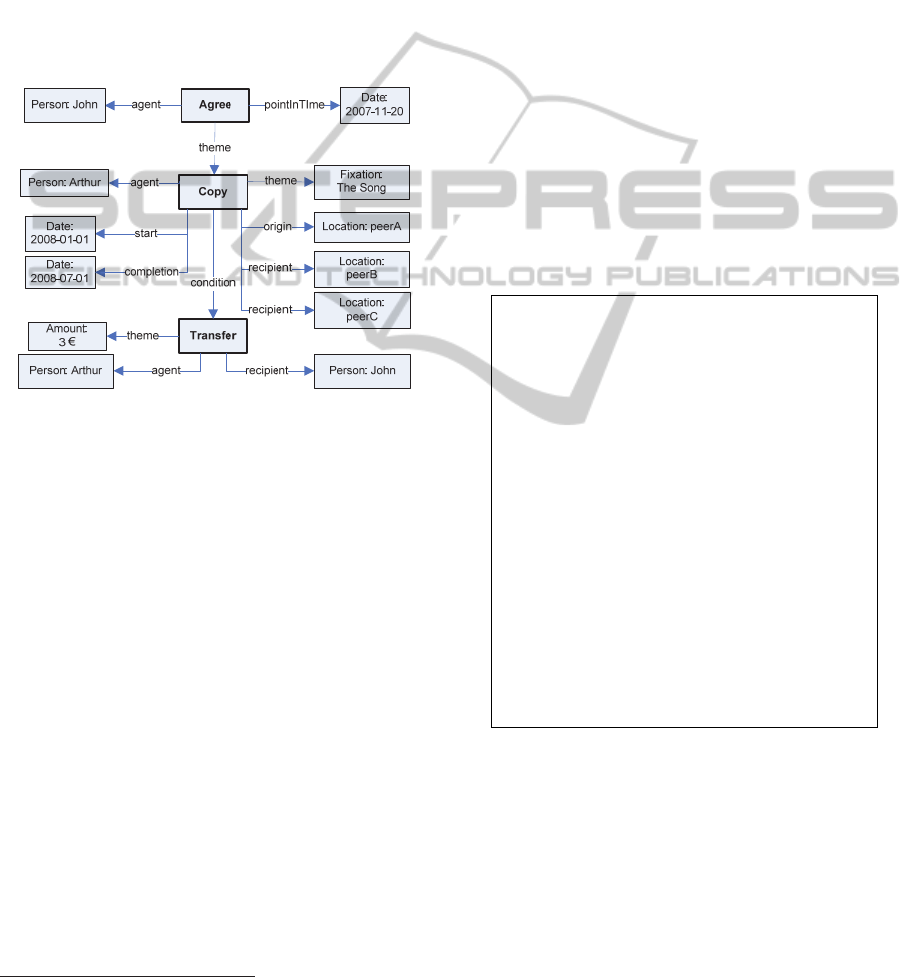
The central part of Figure 1 shows an example
model for expression build using the proposed
pattern as it is applied to the Copy verb concept.
This kind of action patterns are also used to model
licenses. Therefore, two additional verb concepts are
identified and detailed using case roles: Agree and
DATA2013-2ndInternationalConferenceonDataManagementTechnologiesandApplications
234
Disagree. They are the building block of any
license.
Figure 1 shows a license for the Copy action
previously introduced. As it is shown, the condition
case role is used in order to introduce a
compensation for the agent that grants the copy
action, a 3€ transfer from the granted agent.
As it can be observed in the figure, the condition
case role is used to model the obligation deontic
aspect inherent in copyright licenses. The permission
and prohibition deontic aspects also present in
licenses are captured by the Agree and Disagree
verb concepts and their corresponding theme case
roles.
Figure 1: Model for an agreement on a copy action pattern
plus a condition.
The agreement theme corresponds to an implicit
permission, i.e. the theme of an agreement is
permitted. The condition relation corresponds to an
obligation, i.e. in order to fulfil the theme action it is
necessary to satisfy the pattern defined by the
condition property object. Finally, it is also possible
to model prohibitions using the Disagree verb
concept and placing the prohibited action in the
corresponding theme.
As a result of the Copyright Ontology
development process, it has been possible to test the
first objective of the proposed ontology-engineering
pattern. It facilitates the ontology conceptualisation
because it provides a predefined pattern to face the
conceptualisation process and a predefined set of
constructs, the proposed case roles, which facilitate
building a detailed model for the dynamic model
aspects.
A part from the Copyright Ontology
conceptualisation presented in this section, there is
an implementation
10
based on the Web Ontology
10
Copyright Ontology, http://rhizomik.net/ontologies/copyrighton
to
Language (OWL), concretely on the Description
Logic (DL) variant. This implementation can be
used to develop a Semantic DRM System based on
DL reasoning (García and Gil, 2010), as detailed in
the next section.
4 USE CASE
The Copyright Ontology has been applied in a real
use case involving media fragments and existing
DDEX rights data. DDEX data is used in this case as
the way to communicate the rights associated to
assets along the value chain. However, DDEX data
does just model deals, which capture the kind of
actions that can be performed with a particular asset
or fragment in a given territory, time point, etc. They
do not capture the existing copyright agreements that
might make those particular actions legal or not.
Table 4 includes a DDEX example.
Table 4: DDEX data example.
<Deal>
<DealTerms>
<CommercialModelType>PayAsYouGoModel
</CommercialModelType>
<Usage>
<UseType>OnDemandStream</UseType>
<DistributionChannelType>Internet
</DistributionChannelType>
</Usage>
<TerritoryCode>ES</TerritoryCode>
<TerritoryCode>US</TerritoryCode>
<ValidityPeriod>
<StartDate>2013‐01‐
01</StartDate>
</ValidityPeriod>
</DealTerms>
</Deal>
Consequently, if there is a dispute because an
asset or fragment is detected under a conflicting use,
it is difficult to determine if there is legal support to
claim compensation. Many different DDEX deals
might be involved and even the agreements related
with the involved assets might have to be manually
checked. This is not feasible if the amount of
disputes to deal with grows.
DDEX has been mapped to the Copyright
Ontology, some of the mappings are shown in
Figure 3, so DDEX data can be converted into
Semantic Web data based on this ontology. This
SemanticCopyrightManagementofMediaFragments
235
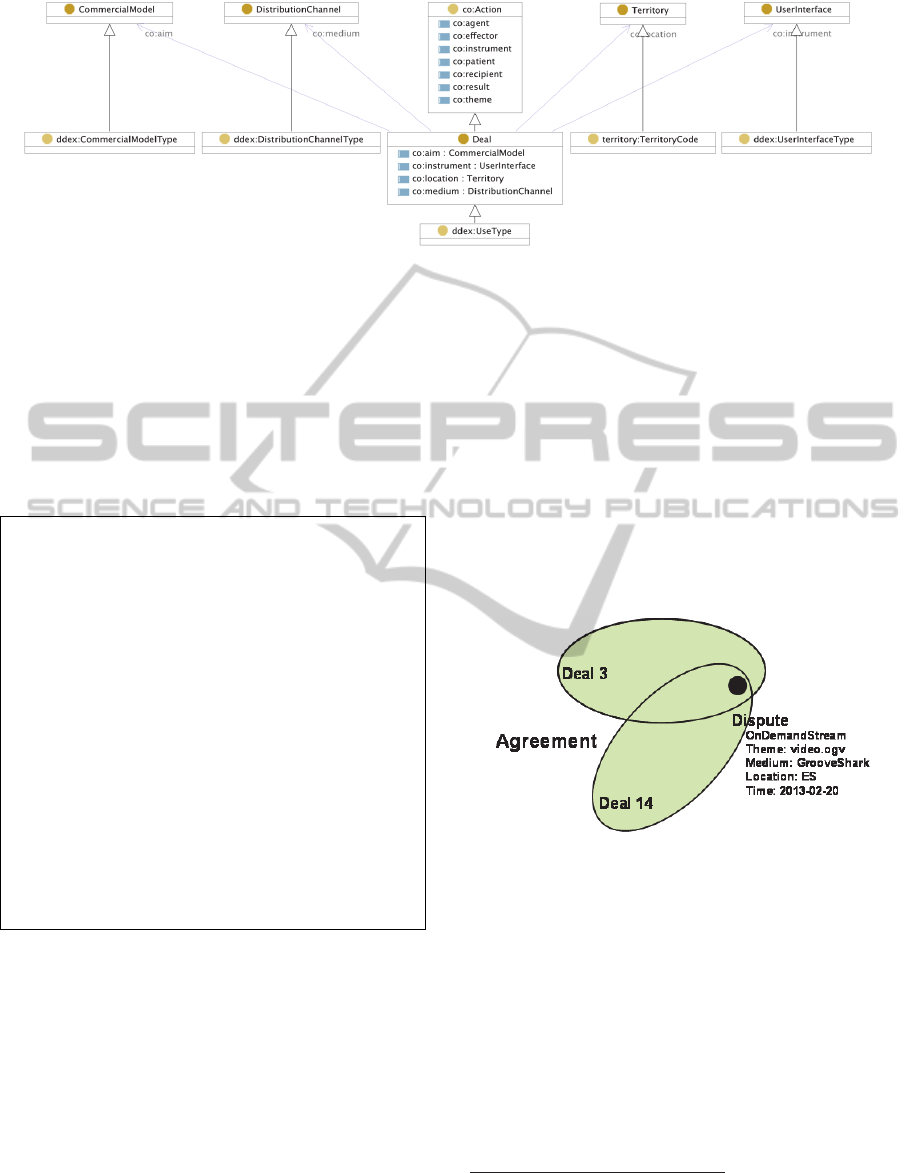
Figure 2: Illustration of Copyright Ontology-based reasoning to check if a dispute is supported by existing rights
agreements that defines two deals.
way, many different deals can be combined and
taken into account to decide a dispute. Moreover,
they can be also combined with other sources of
information, like existing agreements once they are
also formalised.
Table 5: DDEX data example modelled using the
Copyright Ontology.
<http://media.com/deals/3> owl:Class,
msp:Deal;
co:start"2013‐01‐01";
co:aimddex:PayAsYouGoModel;
owl:intersectionOf(
ddex:OnDemandStream
[aowl:Restriction;
owl:onPropertyco:theme;
owl:hasValue
<http://my.tv/video.ogv#t=60,100>]
[aowl:Restriction;
owl:onPropertyco:medium;
owl:someValuesFrom ddex:Internet
]
[aowl:Restriction;
owl:onPropertyco:location
;
owl:someValuesFrom
[a owl:Class;
owl:oneOf (territory:ES
territory:US)]
]).
Once combined, it is possible to use reasoners to
easily implement the process of checking if the
dispute being considered is supported by any of the
existing deals or agreements. To do that, deals are
modelled as classes based on the intersection or
union of restrictions on the deal action and its case
roles, as shown in Table 5.
These classes define the set of actions that are
authorised by a deal. The reasoner can be then used
to check if the dispute, modelled as an instance, is
inside the set defined by the class and consequently
it can be interpreted as supported by the deals and
the agreement under consideration, as illustrated in
Figure 2.
This process is based on the instance
classification service provided by OWL reasoners so
the implementation effor is reduced to retrieving the
classes modelling the deals where the intance has
been classified into and checking if it is part of an
agreement and thus licensed. It is also checked that
the there is no deal the instance has been classified
into that corresponds to a disagreement, the way the
Copyright Ontology models prohibitions and
exceptions. More details about copyright reasoning
are available from
11
.
Figure 3: Mappings among DDEX and Copyright
Ontology concepts.
5 CONCLUSIONS AND FUTURE
WORK
As the amount of media in the Web increases and
more sophisticated uses like reuse are considered at
that scale, a way to represent and automatically
process media rights becomes even more necessary.
This problem becomes even more relevant when not
just the copyright of pieces of content has to be
11
Copyright Reasoning Explained, presentation available from
MediaMixer Community (free membership).
http://community.mediamixer.eu/materials/presentations/copyrigh
t/view
DATA2013-2ndInternationalConferenceonDataManagementTechnologiesandApplications
236

considered, but also media fragments.
To provide a scalable solution, we propose using
highly expressive rights representations that can be
connected to media fragments. This proposal is
materialised into a Copyright Ontology, which is
based on Semantic Web technologies. The ontology
provides a common framework, based on copyright
law, capable of giving support across the whole
media value chain.
Existing data formats can be mapped to this
common framework and then benefit from formal
semantics. First of all, media fragment can be
identified using the W3C Media Fragment URI
recommendation. Moreover, existing data, like
DDEX data used by the industry to communicate
information across the value chain, can also be
mapped to the Copyright Ontology.
Once integrated and formalised, it becomes
easier to implement solutions at the Web scale using
existing Web ontologies reasoners. This approach
has been put into practice in a real use case, where
existing DDEX data is converted into semantic data
and connected to the Copyright Ontology. Then,
reasoners have been used to help decide if a dispute
on a media fragment is supported by the existing
DDEX data and copyright agreement and thus it is
possible to ask for compensation.
Future work now is to bundle this solution into
an existing asset management system like Fedora
Commons
12
, which is also incorporating semantic
technologies and media fragments capabilities. This
setting would help further evaluation the Copyright
Ontology in real use cases, pushing boundaries to
test its scalability and incorporating other rights data
sources, like rights agreements automatically
processed using Natural Language techniques.
ACKNOWLEDGEMENTS
The work described in this paper has been partially
supported by the European project MediaMixer
(Community and Networking for the Remixing of
Online Media, FP7-ICT-318101) and the Spanish
project InDAGuS (Infrastructures for Sustainable
Open Government Data with Geospatial Features,
TIN2012-37826-C02).
REFERENCES
Troncy, R., Mannens, E., Pfeiffer, S., Van Deursen, D.
12
http://fedora-commons.org
2012. Media Fragments URI 1.0 (basic). W3C
Recommendation, 25 September 2012.
http://www.w3.org/TR/media-frags/
Rosenblatt, B.: 2008 Year in Review: Part 1. DRM Watch,
December 28, 2008. http://www.drmwatch.com/drmte
ch/article.php/3793156
Wang, X., DeMartini, T., Wragg, B., Paramasivam, M.,
Barlas, C.: The MPEG-21 rights expression language
and rights data dictionary. IEEE Transactions on
Multimedia, 7(3), 408-417, 2005.
Iannella, R.: Open Digital Rights Language (ODRL),
Version 1.1, 2002.
García, R., Delgado, J.: An Ontological Approach for the
Management of Rights Data Dictionaries. In Moens,
M., Spyns, P. (Eds.): Legal Knowledge and
Information Systems. IOS Press, Frontiers in Artificial
Intelligence and Applications, 134, 137-146, 2005.
Rosenblatt, B.: 2009 Year in Review: Part 1. DRM Watch,
December 28, 2009. http://copyrightandtechnology.co
m/2009/12/28/2009-year-in-review-part-1/
Doctorow, C.: Critique of NAVSHP (FP6) DRM
Requirements Report. Electronic Frontier Foundation,
2005. http://www.eff.org/IP/DRM/NAVSHP
Springer, M., García, R.: Promoting Music Sampling by
Semantic Web-Enhanced DRM Tools. In Grimm, R.;
Hass, B. (Eds.): Virtual Goods: Technology, Economy,
and Legal Aspects. Nova Science Publishers, 2008.
Hausenblas, M., Troncy, R., Bürger, T., Raimond, Y.
(2009) Interlinking Multimedia: How to Apply Linked
Data Principles to Multimedia Fragments. LDOW
Workshop 2009, CEUR Workshop Proceedings, 538.
Gómez-Pérez, A., Fernández-López, M., Corcho, O.:
Ontology Engineering. Advanced Information and
Knowledge Processing Series. Springer, 2004.
Gangemi, A., Guarino, N., Masolo, C., Oltramari, A.,
Schneider, L.: Sweetening Ontologies with DOLCE.
In A. Gómez-Pérez, A. & R. Benjamins (Eds.):
Knowledge Engineering and Knowledge Management,
pp. 166-181, Springer, 2002.
McRae, K., Ferretti, T. R., Amyote, L.: Thematic Roles as
Verb-specific Concepts. Language and Cognitive
Processes Journal, 12(2), 137-176, 1997.
Fillmore, C. J., Johnson, C. R., Petruck, M. R. L. 2003.
Background to FrameNet. International Journal of
Lexicography, 16(3), 235-250.
Sowa, J. F. 2004. Common Logic Controlled English.
Draft, 24 February 2004. Available from
http://www.jfsowa.com/clce/specs.htm
Dick, J.P. 1991. A conceptual, case-relation
representation of text for intelligent retrieval. PhD
Thesis. University of Toronto, Canada.
Niles, I., Pease, A. 2001. Towards a Standard Upper
Ontology. In C. Welty & B. Smith (Eds.) Proceedings
of the 2nd International Conference on Formal
Ontology in Information Systems, FOIS (pp. 2-9).
Maine, USA.
García, R., Gil, R. (2010). Content value chains modelling
using a copyright ontology. Information Systems
,
35(4), 483–495.
SemanticCopyrightManagementofMediaFragments
237
